
数据迁移与清洗的策略研究及其在政务基础数据的应用
2021-03-17 03:25:06杨光吴明芬李敬民
五邑大学学报(自然科学版) 2021年1期
杨光,吴明芬,李敬民
(五邑大学 智能制造学部,广东 江门 529020)
数据的质量是数据分析和数据挖掘的基础. 海量数据在收集后常常存在着数据分散和数据重复等情况,这些数据也包含了大量的错误值、缺失值、异常值以及可疑数据等,如何将这些“脏”数据,变成可以进行分析和挖掘的“干净”数据,是大数据预处理不可缺少的环节[1].
大数据预处理主要包括数据迁移与数据清洗,数据迁移是指不同存储格式、数据类型以及硬件设备之间的数据移动过程. 数据清洗是指对不准确、不完整或不合理数据进行修补或移除以提高数据质量的过程[2]. 当前,数据的质量越来越引起人们的重视[3],许多学者针对这两种技术也开展了一系列研究,郝爽等[4]指出数据清洗是对“脏”数据进行检测和纠正的过程,是进行数据分析和管理的基础. 陆叶杉[5]在某系统建设中设计了一套基于ETL 工具的数据迁移流程,并通过组合和串联得到了完整的数据迁移流程线,完成了新旧系统的数据对接. 目前,数据迁移与清洗技术取得了很多成果,但以下方面还有待进一步改进.
1)数据清洗技术主要处理重复、异常、逻辑错误和不一致的数据等. 目前大部分的研究都是针对某项或几项清洗内容独立进行,如果按照每一类数据单独清洗,那么其清洗效率会非常低,因为在数据库里,有可能包含几类需要清洗的数据,需要按列的内容进行清洗.
2)在数据分析与挖掘的过程中,数据迁移与清洗往往要花费整个过程60%~80%的时间[6],当数据量很大时,迁移与清洗的效率是需要重点研究的问题.
针对以上问题,本文设计了数据迁移与清洗策略及流程,并应用在某市政务服务基础数据上,该策略能在不改变原数据的情况下,提高数据的质量,提升清洗速度,同时可以定时自动清洗,迁移和清洗完成后还能自动统计迁移与清洗结果并生成报告.
1 数据迁移策略及流程
1.1 数据迁移策略
数据在迁移之前,需要详细调研并确定原数据库的数量n、目标数据库的数据m以及用何种方式迁移. 现在有两种比较通用的迁移方式,一种是全量迁移,另一种是增量迁移,具体如图1 所示.
1)当n=m= 1,就是从一个原数据库迁移到一个目标数据库,容灾备份就属于这种情况.
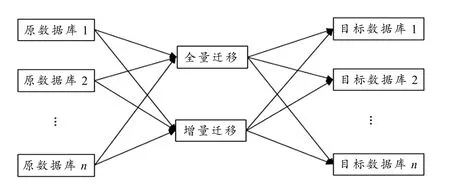
图1 数据迁移方式
2)当n> 1,m= 1,就是将多数据库迁移到一个数据库,方便数据的分析、挖掘和共享.
3)当n> 1,m> 1,当数据量很大时,将多原数据库迁移到多个数据中心进行分类分级管理,既保障数据的安全,又达到数据共享的目标.
确定了迁移的数据后,迁移方式也是至关重要的一步. 全量迁移适用于时间戳没有明显界限的数据,需要做全量备份. 这种方式迁移的数据量较多,每次迁移都需要迁移全部数据,但全量迁移不需要更新数据库,只需要将原来的数据清空,再插入数据. 增量迁移则适用于时间戳有明显界限的数据,每次迁移只需将时间戳变动的数据迁移到目标库即可,但需要进行数据库的更新. 与增量迁移相比,全量迁移的操作比较简单,但当需要迁移的数据量比较大时,迁移的时间比较长. 如果数据每周变动比较少,而且时间戳界限比较明显,那么采用增量迁移的方式会更高效.
1.2 数据迁移流程
数据在进行迁移时,可以按照串行和并行的方式进行迁移. 串行迁移需要执行完一个流程再执行下一个流程,并行迁移是一起并发执行. 串行迁移作业和并行迁移作业如图2、3 所示,图中的作业方式都是针对n个原数据库迁移到一个目标数据库,迁移到多个目标数据库时,原理相同.

图2 串行迁移作业
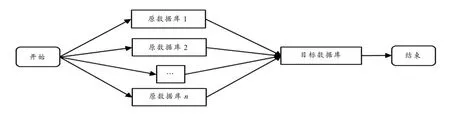
图3 并行迁移作业
串行作业和并行作业都是由多个转换组成的,作业的主要作用是调用多个转换或者作业形成一个完整的流程以方便执行. 在数据迁移时,最影响迁移速度的是单个表的迁移转换. 在编写单个表的迁移转换时,须进行多次调优,才能使迁移速度达到比较理想的状态,最常使用的是增加线程的方式.
数据迁移流程步骤如下:
1)清空目标表:用于清空目标表里面的数据,适用于全量迁移的过程,若是增量迁移则不需要清空目标表,只需插入更新目标表数据即可;
2)迁移表:连接需要迁移的数据源;
3)目标表:用于将需迁移表的数据导入到目标表中,为了加快导入的速度,会使用多个线程,在线程的选择上,通过设置多个线程可以加快程序的运行速度,但过多的线程会造成阻塞和资源浪费,过少的线程达不到速度的优化,通过计算最佳线程[7]可以使程序的运行速度达到最佳,同时也不会过多地占用计算机资源,公式如下:

其中,Nthreads指最佳线程数量,Ncpu指CPU 的数量,Twaiting指线程等待时间,Tcpu指线程CPU 执行时间. 在平常的迁移中将线程数设置成与本机CPU 数量一样,即可达到较优的迁移速度.
本策略的迁移表和目标表能够支持Oracle、MySQL、SQL server、MongoDB、Hbase 等常用的数据库. 对关系型和非关系型数据也可以支持,这就较好地解决了异构数据库的问题,仅使用表输入表输出就可以将不同服务器、不同数据库、不同表输出到符合要求的目标表,且在输入和输出时,还可选择Excel、CSV、TXT 等格式的数据进行数据输入或输出.
数据迁移流程要根据实际应用情况,通过多次测试和调优迁移速度才能达到较满意的效率.
2 数据清洗策略及流程
2.1 数据清洗策略
数据清洗是确保数据质量最重要的环节,它对利用基础标准库进行反向清洗、数据分析和建立数据模型起着至关重要的作用. 通过对大量不同行业的数据进行调研和分析,设计了数据清洗策略流程图,如图4 所示.
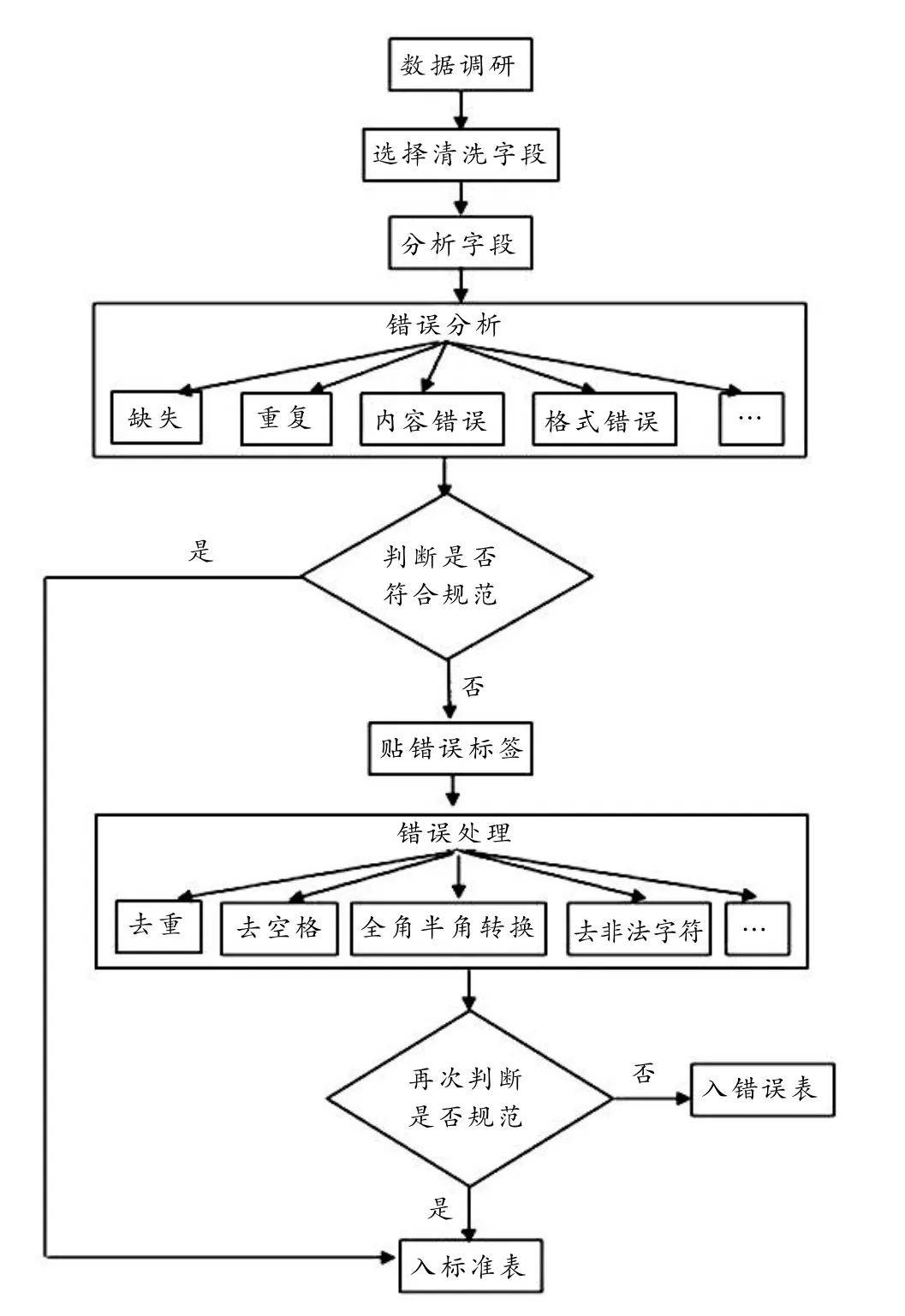
图4 数据清洗策略流程
1)数据调研:在数据清洗之前需要对数据进行充分的调研,这一部分直接决定数据清洗的结果. 如对证件号码调研,18 位身份证号码编码规则和15 位身份证号码的编码规则都是正确规则. 在证件字段中,除了居民身份证号码,护照号码等也应包含在正确字段内.
2)分析字段:针对不同的字段有不同的清洗规则.
3)错误分类:目前将错误分成缺失、重复、内容错误和格式错误等. 可对错误进行编码,比如将“缺失”编码为0100,“重复”编码为0200. 对编码进一步细分,重复编码又可以分为身份证重复0201,统一社会信用代码重复0202 等,具体的划分可以根据需求来制定. 通过划分可以方便统计错误,并有针对性地清洗.
4)判断字段是否符合规范:符合规范的数据可以直接迁入标准库. 如果不符合规范,则要对错误数据贴标签,并对错误进行处理,错误处理主要有去重、去空格、全角半角转换、去非法字符等. 错误处理完成后对数据再次进行验证,如果满足规范就迁入标准库,否则导入错误库.
2.2 数据清洗流程
设计清洗流程需要先对字段进行调研,根据字段的内容格式以及错误情况制定相应的清洗方法.图5 是本文设计的数据清洗流程,该流程易于操作和拓展.
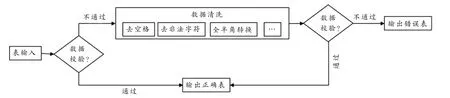
图5 数据清洗流程
数据清洗流程如下:
1)用表输入连接要清洗的表.
2)用数据校验检查字段存在的问题,在校验时主要用的是正则表达式,把满足校验条件的数据直接插入到正确表,不满足条件的执行清洗路线.
3)清洗路线主要对全角半角、非法字符、空格等进行清洗.
4)清洗完毕后,再次执行数据校验,校验将数据分为已更改和未更改,已更改数据直接写入正确表,未更改数据输出到错误表,以便进一步观察数据错误原因,并反馈给相关负责部门.
在清洗流程中,最重要的是数据校验这个功能. 数据校验是判断数据是否正确的重要手段. 通过编写不同的校验规则,可以很快地发现数据中存在的问题,并进行清洗.
在具体应用中设计了4 种数据校验方式.
1)数据字典校验
数字字典是不同类型数据的集合,它可以对数据进行分类管理. 比如行业代码,行政区域代码,这些代码都有专门的字典表. 当需要校验的数据在此字典表中,则校验通过,否则不通过.
2)正则表达式校验
正则表达式[9]校验被广泛应用于检验字段值是否正确、替换符合某个模式(规则)的文本. 在本文中,正则表达式主要用于检查字段是否正确,以及去除一些非法字符. 但不是所有情况都适用正则表达式,比如校验身份证号码、统一社会信用代码等,不能单从是否满足正则表达式就判断其是正确的,还要进行一些规则验证.
3)JavaScript 代码校验
JavaScript 常用于字段清洗中对数据内容格式的错误纠正,比如全角半角转换、去除一些复杂字段的内容. JavaScript 同样可以应用于校验数据是否正确,比如验证企业成立时间是否晚于企业注销时间、验证企业成立时间是否晚于当前日期、验证企业人数是否合理等.
4)JavaScript 和正则表达式结合校验
JavaScript 和正则表达式结合,可以解决很多复杂字段问题,比如校验身份证、校验统一社会信用代码、校验注册号等等. 如身份证号码由于历史原因现在有15 位和18 位的,需要对这两种格式进行校验.
以上4 种数据校验方式要结合具体的字段内容进行选择,通过大量的数据调研了解哪些字段格式是正确的,再选择适合的数据校验方法,对于太过于复杂的字段,可以通过Java 程序进行清洗.
3 数据迁移与清洗速度对比及结果分析
本文把相应的数据迁移和清洗策略应用于某市政务服务基础数据库. 以下分别从程序处理速度、数据迁移结果和数据清洗结果等3 个方面进行对比分析.
3.1 程序处理速度对比
实验数据来自MySQL 数据库,一张表里有1120012 条数据,60 个字段,数据表共534 Mb,Windows Server 2012 R2 操作系统,Intel(R) Xeon(R) CPU E7-4850 v2 @2.30 GHz(8 CPUs)处理器,8 Gb 运行内存,Python 版本为3.7.0,Python 编译器为PyCharm Community Edition 2018.2.4 x64,Kettle[7]版本为5.4,MySQL 版本为5.7,Navicat Premium 版本为15.0.14. 实验将MySQL 数据库的数据从一台服务器迁移到另一台服务器,也就是跨服务器、跨数据库、跨数据表迁移.
因同一个字段里面有多种错误类型,需要对每种错误类型,比如重复、内容错误、格式错误、逻辑错误等进行清洗. 而数据的读取和写入是数据迁移与清洗中必不可少的一步,也是影响整个程序运行快慢的最重要一步,故在速度对比上通过表输入和表输出进行对比. 分别以文献[10]的Navicat 处理方式和文献[11]的Python 处理方式与本策略进行对比,处理时间见表1.
表1 的用时是取5 次实验平均值,从处理用时可以看出本文策略的用时约为Python 和Navicat的1/4,这仅仅是表输入和表输出的用时. 在清洗时需要单独对每个字段进行清洗,清洗完后每个字段再单独插入,在时间、操作性、简易度等方面本文提出的迁移和清洗策略都会比Python 和Navicat有较明显的优势.

表1 处理时间比较
3.2 数据迁移结果分析
实验环境配置为Linux 操作系统,4 个物理4 核CPU,每个CPU 有4 个线程,逻辑CPU 有16个,1 Tb 硬盘,处理器是AMD Opteron(tm) Processor 6172,Kettle 版本为5.4,Python 版本为3.7.0.
在实际工作中,已经完成数据迁移量约为1080 万条,目标计划迁移4000 多万条的数据,每周定时全量迁移. 迁移1080 万条数据,用时约16 min 40 s,数据来源的详细用时如表2 所示.
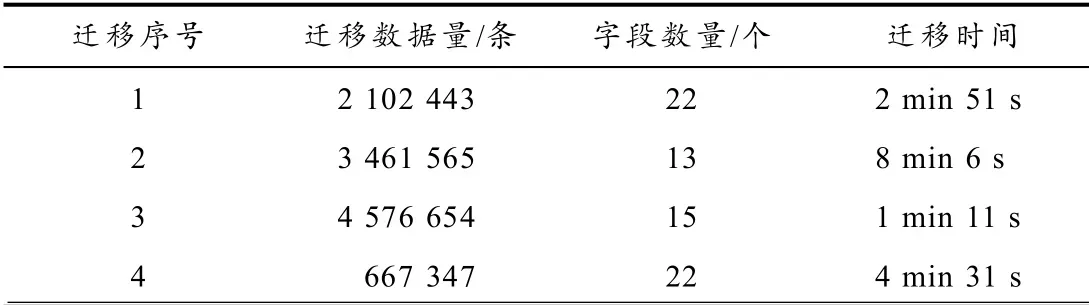
表2 迁移用时比较
通过实验发现,不一定数据量越多,迁移速度越慢,迁移的速度也和每条字段的数量、字段的长度以及字段的内容有关系.
3.3 数据清洗结果分析
对表2 序号1 的210 多万条数据进行清洗,清洗后的数据将作为某市政务服务基础信息数据的标准数据,进而反向清洗其他部门的数据. 表3 是清洗数据量的统计,由于在一个流程里每个表每个字段的清洗时间难以计算,因此用总的时间来作为结果分析. 表3 累计清洗约2861 万次,用时1 h 8 min.
表4 是对清洗结果的统计,错误条数是指含有空格、非法字符、重复、全半角转换等总的错误条数,已更改是指将字段中存在的错误已经清洗成满足条件的数据,也就是正确的数据,未更正条数是指通过程序无法更正的错误,如企业名称错误、身份证录入错误和空白错误.
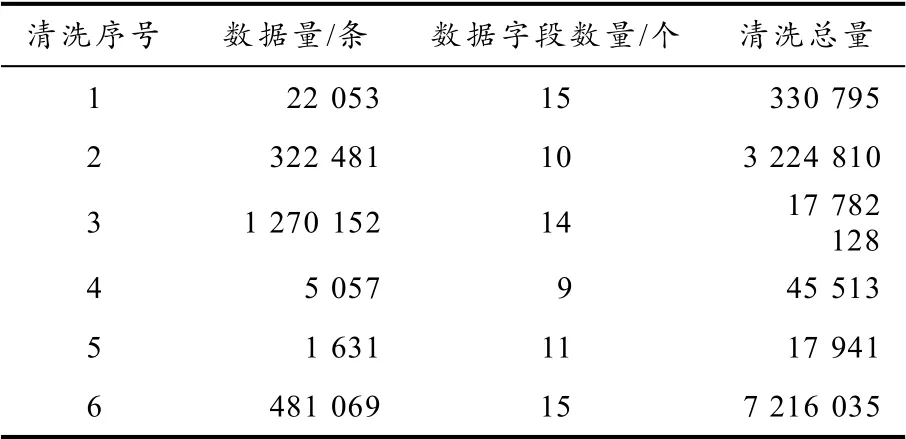
表3 清洗数据量
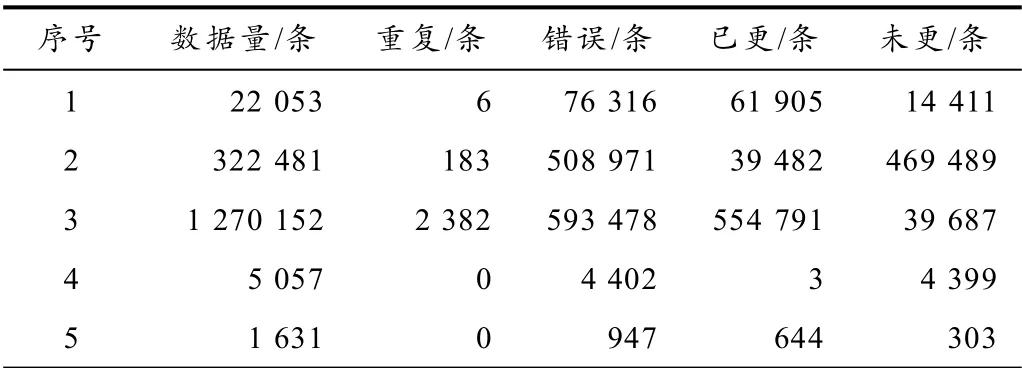
表4 清洗结果
针对表4 序号3 做未更改分析,未更改主要分为字段为空和内容错误,字段为空是指字段本身缺失无法通过其他字段进行填充,内容错误是指去重、去空格、去非法字符后仍是错误,无法通过程序进行更改,需要人工去确定是否需要更改. 通过对清洗结果分析可知,涉及到格式错误的数据已全部修改,涉及到内容错误的数据需结合人工确定是否需要更改,清洗结果总体达到要求.
迁移与清洗结果是在Linux 平台利用Crontab 定时自动执行迁移和自动执行清洗,迁移与清洗形成了一个总的执行作业,迁移作业完成时,立即进行清洗作业.
4 总结与展望
为了加强对数据的管理和提高数据的质量,本文构建了一种通用的数据迁移与清洗策略,设计了数据迁移与清洗流程,并在某市政务服务基础数据库上实施应用. 在清洗速度和清洗质量上都有明显提升,同时可以实现定时清洗、自动生成统计报告,全自动、可并行、速度快,可广泛应用于各种数据迁移与清洗领域.
用本文策略迁移表21080 万条数据并清洗表3210 万条数据,总用时仅为1 h 30 min,数据迁移完成的同时,直接进行数据清洗入库.
上述数据只是实际迁移与清洗的一部分,到2020 年底需要处理的全部数据已经达到几千万条,如果每个表有十几甚至几十个字段,就需要处理上亿的数据,虽然已经通过各种调优技术和手段,加快处理的速度,但处理速度还不是特别理想. 接下来,计划结合用Hadoop 平台和Spark 技术,以追求更快的迁移速度以及更好的数据清洗结果.
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
中国铸造装备与技术(2017年6期)2018-01-22 01:50:04
环球市场(2017年36期)2017-03-09 15:48:21
电测与仪表(2015年1期)2015-04-09 12:03:02
电测与仪表(2015年19期)2015-04-09 11:32:44
设备管理与维修(2015年9期)2015-03-16 02:24:04
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
图书馆建设(2014年3期)2014-02-12 15:41:35
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
