
基于深度特征融合生成的密集人群计数网络
2021-03-16 13:58:00李鹏博王向文
计算机应用与软件 2021年3期
李鹏博 王向文
(上海电力大学电子与信息工程学院 上海 200090)
0 引 言
在国内外的各项大型活动中,突发的人群踩踏事件,已经造成了许多伤亡事故。例如2015年上海外滩发生的踩踏事件,已经达到了我国重大伤亡事故级别。如果能基于视频图像来估计人群密度,并合理地安排相应的安保措施,就可以有效减少和避免类似事件的发生。这也使得估计人群密度成为了计算机视觉领域的一大热点问题。
最初人群计数采用的是基于检测的方法[1],通过滑动窗口检测器来检测场景中的人群,并统计出相应的人数。但是无论是采用检测人整体的方法[2-3],还是基于人体局部信息的检测方法[4],在人群密集场景中的应用效果均不太理想。
由于窗口检测方法很难解决人群密集情况下的遮挡等问题,很多学者提出利用回归的方式来解决人群计数问题。回归方法主要是利用回归算法学习出一种由低级特征到人群人数的抽象映射[5-6]。回归方法可以分为两个步骤,首先提取图片的边缘、纹理、梯度等特征,然后基于这些特征训练一个回归模型以估计最终的人数。但是由于这种回归方法需要事先人为地构建人群图像特征,因此对于特征的有效性有较高的要求,最终的结果也不是非常好。
近些年,由于深度学习的不断发展,其被广泛地应用到计算机视觉的各个领域,并且针对一些问题取得了突破性的进展。同时许多基于深度学习的人群密度估计算法被提出来,这些已经提出的模型可以分为两类。第一类是以MCNN[7]和Switch-CNN[8]为代表的多列多尺度结构。但是该结构会造成参数冗余,而且多列多尺度结构相比单列结构并没有明显的优势[9]。面对人群密度的多变性,多尺度特性对于提高人群计数性能具有积极意义。因此本文提出基于空洞卷积的多尺度特征融合结构,通过多个空洞卷积在不同尺度下的融合不仅不会增加模型参数量,而且可以得到场景的多尺度信息。将其作为整个网络结构的中间部分能够很好地解决不同人群密度场景下卷积感受野单一固定带来的问题。第二类是以CSRNet[8]为代表的单列结构。这类结构前端用来获取基本的语义信息,后端用来生成人群密度信息。但是文献[8]中后端只是单一地通过堆叠卷积层数来实现,并没有很好地利用由前端得到的语义信息。因此本文提出语义重建块,每一个语义重建块学习到的是输入到输出的残差。借助于这种残差的思想,本文提出的语义重建块,能够更好地理解并利用前端的语义信息。最后无论是哪一种主体结构,由于在卷积的过程中加入了多次最大池化操作,导致图像的分辨率被下采样多次。但是之前的文献[7-9]并没有在生成人群密度信息的同时上采样重建,而是到生成密度图后再进行上采样。而本文通过提出的语义重建块,在生成人群密度信息的同时进行上采样,解决了最后生成人群密度图分辨率不高的问题以及由于图像分辨率问题带来的人群计数误差。
通过上述分析,本文提出的人群计数方法主体采用单列结构,其中前端用来实现基础的语义信息获取,后端采用本文提出的多尺度融合块和语义重建块进行多次上采样重建语义信息来得到最终的人群密度图像和人群数量。将本文提出的人群密度估计网络与其他历年主流的人群密度估计方法在多个公开数据集上对比,本文提出的密集人群计数网络不仅在人群计数精度上体现出了更优异的性能而且网络能够生成质量更佳的人群密度图。
1 模型设计
1.1 模型整体架构
由于卷积神经网络对于图像具有很好的特征提取能力,因此可以通过深度卷积网络获得图像的高层次语义信息,这对于生成高质量的人群密度图像具有重要的作用。本文提出的方法先基于深度卷积网络得到深度语义特征,然后通过深度语义特征进一步表达和生成人群密度。其主要模型结构如图1所示。其中所有的卷积层都采用补零操作以保持图像之前的尺寸,所有的卷积层参数可以表示为“Conv-卷积核尺寸-卷积核个数-膨胀率”。所有的最大池化层的窗长和移动步长都为2。
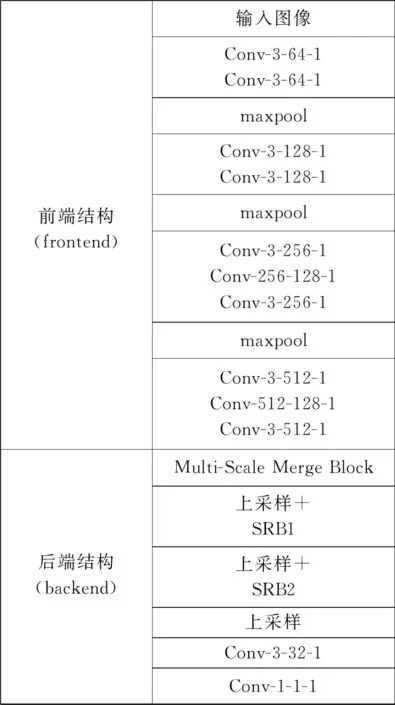
图1 模型主要结构
本文提出的模型由前端结构和后端结构组成,前端结构主要用来从原始图像中提取深度语义特征,后端结构用来逐步融合语义信息并生成最后的人群密度图。由于VGG16[10-11]网络具有优秀的特征提取能力而且便于迁移学习,因此本文移除了VGG16网络中用于分类的全连接网络部分,只保留全卷积结构作为模型前端来获取图像深度语义特征。但是由于VGG16网络只有一个固定且单一的卷积核,因此在后端结构中为了更好地整合前端网络学习到的深度语义特征,本文提出用多尺度融合块(Multi-Scale Merge Block, MSMB)网络来进一步丰富和改善由前端网络得到的深度语义特征。
由于原始图像在经过前端网络以后图像语义特征尺寸变为原来的八分之一,而生成的人群密度图的尺寸大小对最后的人数统计和密度图质量有直接的影响,因此本文模型利用图像深度语义特征逐步上采样生成的方式来表达人群密度信息。
为了减小模型的大小,本文所有的上采样采用双线性插值方法,每次上采样为原来的两倍。考虑到经过上采样以后特征会变得稀疏,所以本文提出语义重建块(Semantic ReconstructionBlock, SRB)来对上采样后的语义信息进行降维重建。多尺度融合语义特征经过连续两次上采样和语义信息降维重建后,再通过一个上采样将人群特征图尺寸恢复到原来图像一样,最后通过两个卷积层回归得到人群密度。
1.2 多尺度特征融合块
由于卷积神经网络的卷积核大小决定了卷积网络的感受视野的大小,而不同的感受视野可以获取到图像不同尺度的语义信息,因此为了获取更加丰富的语义信息,常见的方法都会设置多路不同卷积核尺寸的卷积网络[7],最后通过将多路语义信息融合来获取更多的语义信息。设置多路不同卷积核尺寸的卷积网络必然会使用到大尺寸的卷积核以达到扩大卷积感受野的目的。但是卷积核的尺寸越大,模型所需要学习的参数就越多,而且单纯增大尺度也会导致参数冗余。
由于如图2所示的空洞卷积[12-13]通过设置卷积核的膨胀率可以在不增加参数量大小的情况下,增大卷积核感受野,当空洞卷积的扩张率=1时,空洞卷积和正常的卷积相同,当扩张率≠1时,空洞卷积在相同的参数下,具有更大的感受野。基于此,本文设计了如图3所示的多尺度融合块(Multi-Scale Merge Block, MSMB)结构,通过设置多列不同膨胀率的空洞卷积来获取不同尺度下的深度语义信息。并将不同尺度下的深度语义信息在深度上堆叠之后,再利用一个常规较小尺寸卷积核的卷积层去融合生成新的深度语义特征。
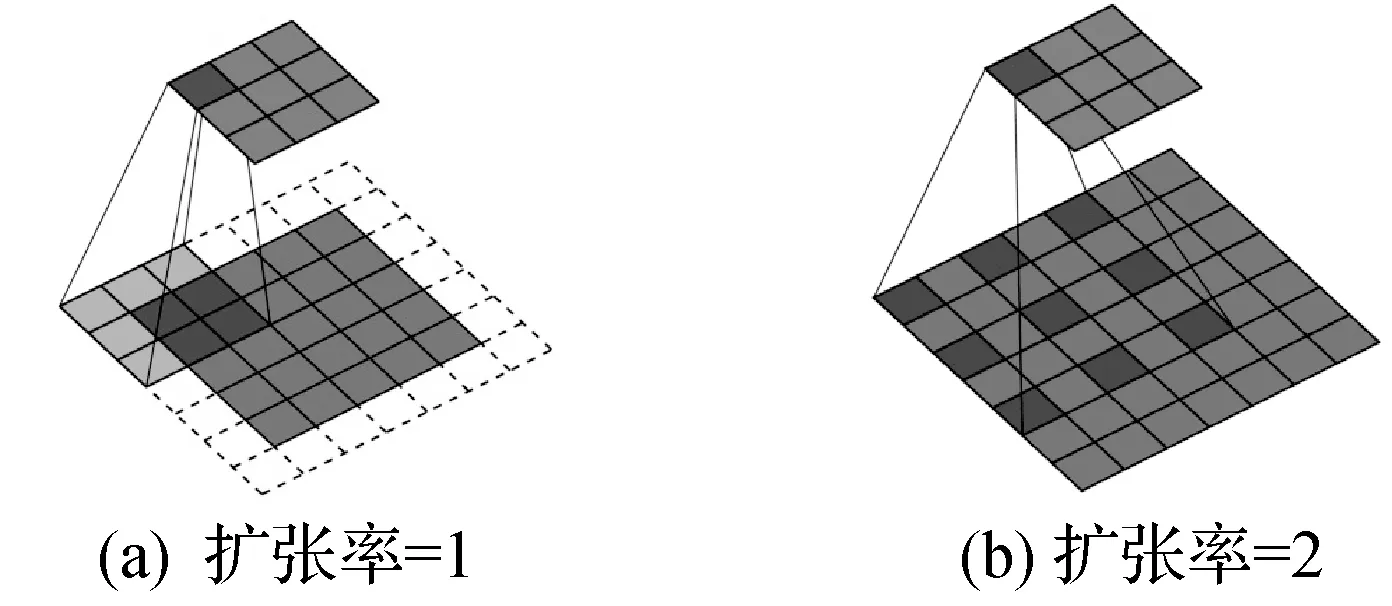
图2 空洞卷积
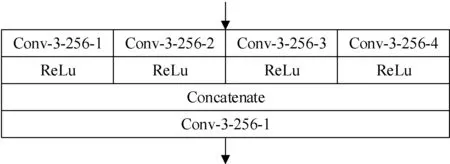
四个空洞卷积的膨胀率依次为1,2,3,4
值得注意的是,虽然空洞卷积具有不增加参数量的情况下,增大感受野的功能,但是其过大的膨胀率设置会导致网络对于图像细微的变化不敏感,因此在设置多尺度空洞卷积时,选择较小的膨胀率效果会更好。另外针对人群密集场景,要求网络对于图像的细节变化要更加敏感,而空洞卷积膨胀率为1时,其与正常卷积相同,可以弥补空洞卷积对于细节不敏感的缺点。基于此,本文将多尺度空洞卷积的膨胀率设置为1~4。
1.3 语义重建
为了生成质量更好的人群密度图,本文采用上采样重建操作,逐步将图片尺寸恢复到原始图像的尺寸。为了利用深度语义特征更好地表达所需要的人群密度信息,需要将每次上采样后稀疏的特征进行降维重建。而残差结构有助于解决深度卷积网络的梯度弥散问题和退化问题的同时,能够更好地利用语义信息[14]。因此本文提出语义重建块(Semantic Reconstruction Block, SRB)来使得稀疏特征变得更加密集, 其主要结构如图4所示。其中:U表示上采样,C表示将特征在深度上进行堆叠;+表示将两个特征直接相加;SRB1:m=256,n=128;SRB2:m=128,n=64。
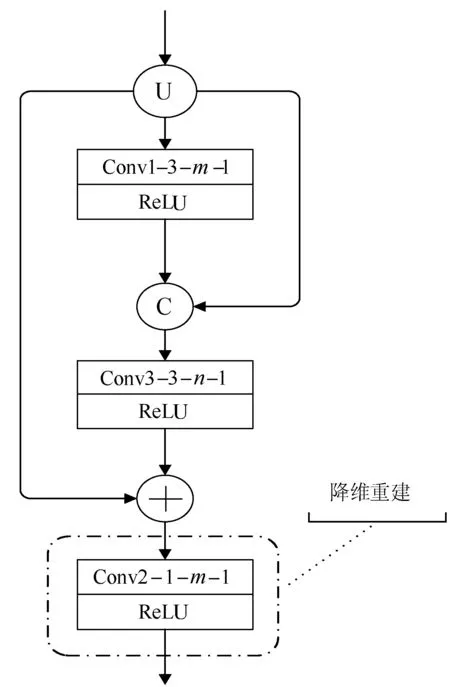
图4 语义重建块
卷积神经的网络输出的深度信息是网络中不同滤波器对输入信息的滤波结果。因此,为了使稀疏的特征变得更加密集,就需要对卷积神经网络的深度特征进行处理。基于此,语义重建块主要由两部分构成。第一部分,输入信息对两个卷积层的输出分别进行深度上的语义堆叠和相加操作来使得语义信息更加密集。虽然通过在深度上进行堆叠等操作可以更好地利用语义信息,但是堆叠之后会使得整体参数过多,而且简单地进行深度特征堆叠,其效果也一般。第二部分通过一个卷积核较小的卷积层来对前面堆叠生成的语义信息进行融合,并降低输出深度。
2 实 验
2.1 评价标准
本文与其他文献一样[7],对于人群统计的准确度采用式(1)和式(2)定义的绝对误差(MAE)和均方误差(MSE)作为评价标准。
(1)
(2)
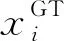
(3)
式中:H和W分别表示模型生成密度图的高和宽;z(h,w)则表示模型生成密度图在(h,w)处的像素值。
高质量的人群密度图,对于确定人群的实际空间位置分布很有助益。因此对于模型生成的密度图质量采用图像的峰值信噪比(PSNR)和结构相似性(SSIM)来评价。
2.2 训练细节
2.2.1数据处理
1) 真实密度图标签。与文献[7]中的生成人群密度图的方式一样,采用自适应几何核解决人群密集场景。通过高斯核函数模糊图片中每一个标注来生成密度图。通过这种方式可以更好地考虑在图像中的几何分布。其中几何自适应核由式(4)定义。
(4)
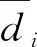
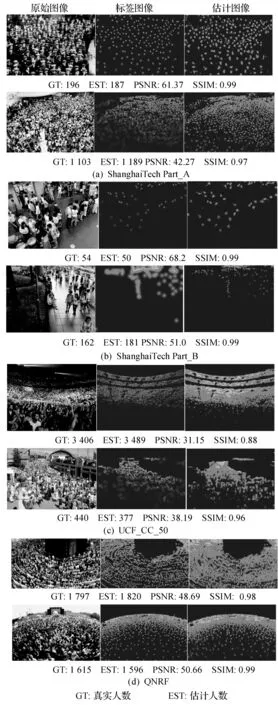
图5 人群密度可视化
2) 图像增强。图像数据增强以后,不仅可为深度卷积神经网络提供大量的训练数据,还可以提高模型的鲁棒性。因此对本文实验提到的数据集都进行了下述方式的图像增强:
(1) 对原始图片进行不重叠的四等分。
(2) 对原始图片随机裁剪五次,且裁剪尺寸为原始图像的四分之一。
(3) 对(1)和(2)中得到的图片进行镜像操作。
2.2.2损失函数
模型生成的人群密度图和目标密度图之间的差距可以通过计算两幅图中每个对应像素之间的欧氏距离来表示,因此损失函数可由式(5)定义。
(5)

2.2.3训练参数配置
在训练网络之前用在ImageNet数据集上预训练的VGG16模型对前端卷积网络参数初始化。对于后端的卷积层采用标准差为0.01的高斯分布初始化。通过多次实验对比,确定了如表1所示的其他参数。
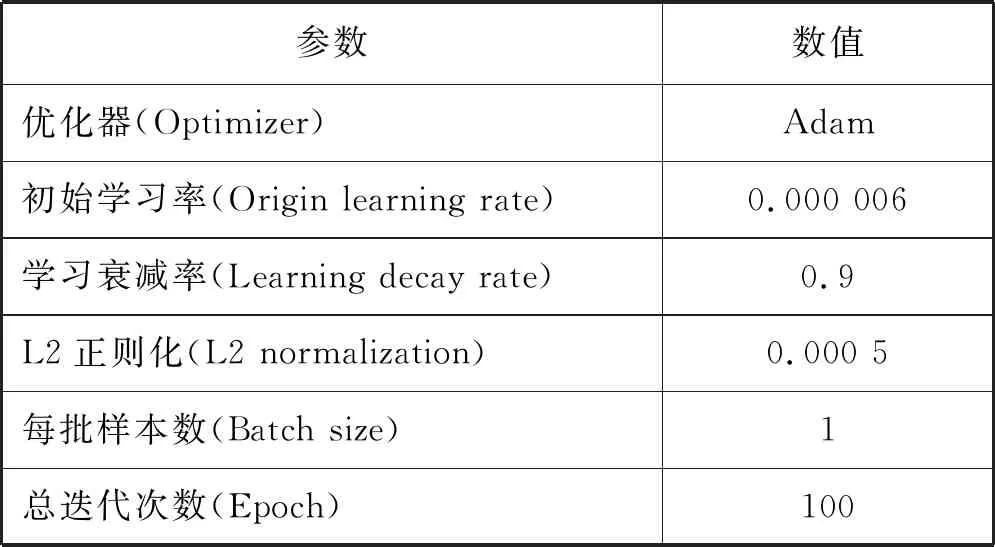
表1 训练参数配置
2.3 评价和对比
2.3.1ShanghaiTech数据集
ShanghaiTech数据集[7]包含1 198幅标注的图片,共有330 165人,并分为Part_A和Part_B两部分,Part_A包含482幅从互联网随机下载的高拥挤场景图片。Part_B包含716幅拍自上海街区的人群较为稀疏的图片。将本文所提出的模型分别在Part_A和Part_B上进行训练和验证。
本文所提模型的实验结果与其他历年主流方法在ShanghaiTech数据集相比较,在Part_A上表现出了更好的性能,在Part_B上虽然并未像在Part_A上实现两个指标的超越,但是仍体现出了不错的性能。具体的对比结果如表2所示。其中生成的ShanghaiTech人群密度图如图5(a)、(b)所示。另外从表3的密度图质量评价指标可以看出本文方法可以生成更好的人群密度图。
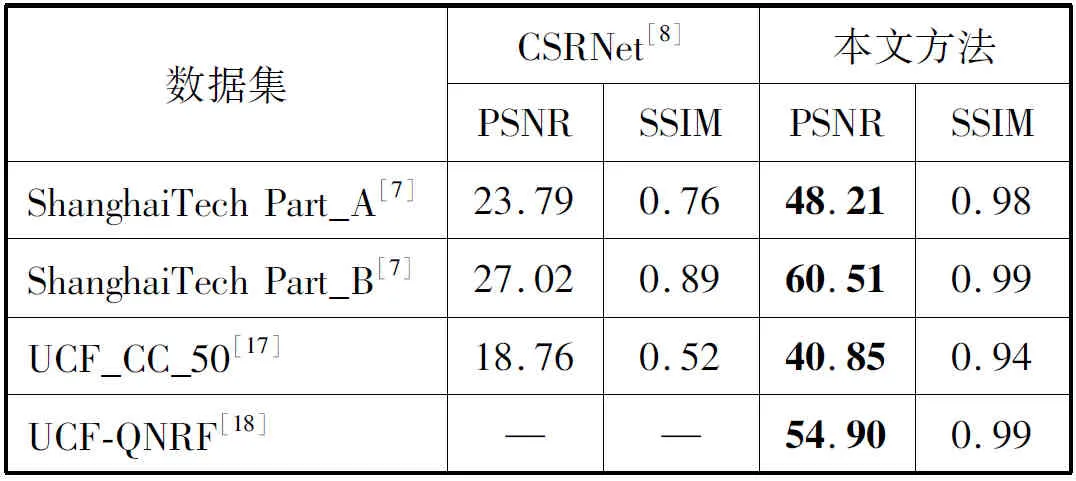
表2 ShanghaiTech估计误差
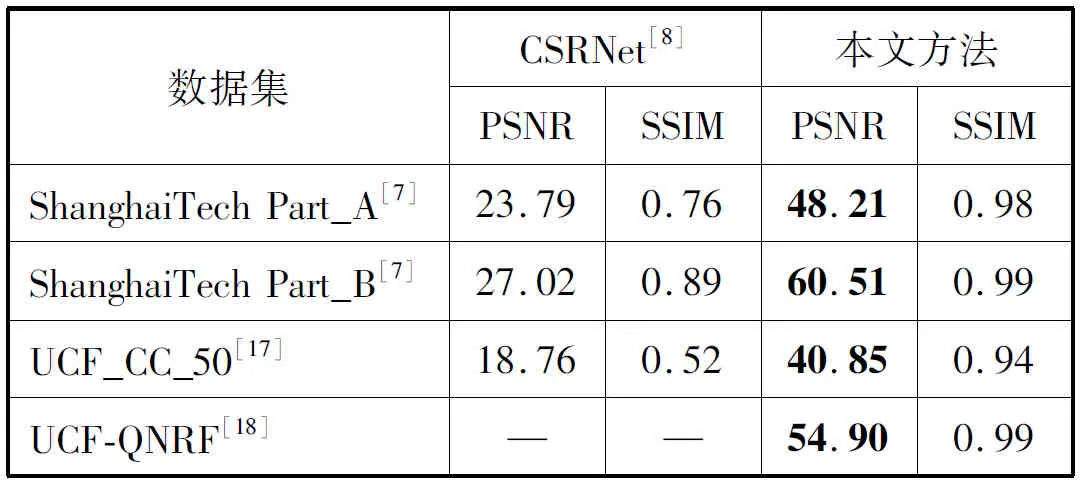
表3 密度图质量
2.3.2UCF_CC_50数据集
UCF_CC_50数据集包含50幅不同视角不同分辨率的图片。每幅图片标注的人数范围从94到4 543不等,平均人数达到了1 280。通过如前所述方法进行数据增强以后,由于数据集本身图片数量较少,因此用与文献[17]一样的方法,采用五折交叉验证来验证模型的性能。
通过对比本文所提方法与其他主流人群计数方法在该数据集上的实验结果,本文所提的方法表现出了更好的人群计数性能。具体对比结果如表4所示。另外UCF_CC_50数据集人群密度可视化结果如图5(c)所示。由表3的人群密度图质量评价标准说明,本文方法能产生质量更好的人群密度图。
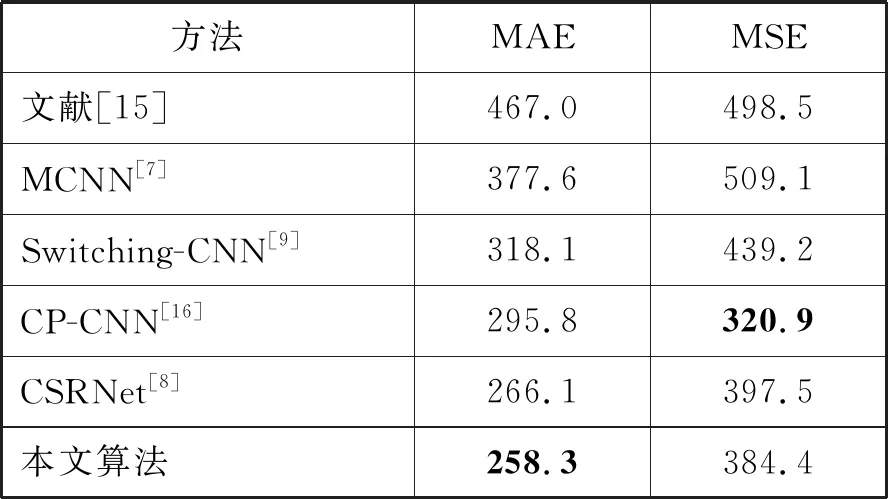
表4 UCF_CC_50估计误差
2.3.3UCF-QNRF数据集
UCF-QNRF数据集[18]是目前标注人群最大的数据集。它包含最多样化的视角、密度和照明变化场景。由于数据图像是在野外现实场景中捕获的,所以UCF-QNRF数据集包含建筑物、植被、天空和道路,使得图像的内容更加丰富,挑战难度也随之增大。该数据集共包含1 535幅图片,其中1 201幅作为训练集,334幅图像作为测试集。
通过比较本文方法与其他方法的实验结果可以看出,本文方法表现出了更好的人群计数性能。具体结果如表5所示。除此之外,UCF-QNRF数据集人群密度可视化结果如图5(d)所示。通过对比表3的人群密度质量评价结果可知,本文方法能够获得更好的人群密度图像质量。
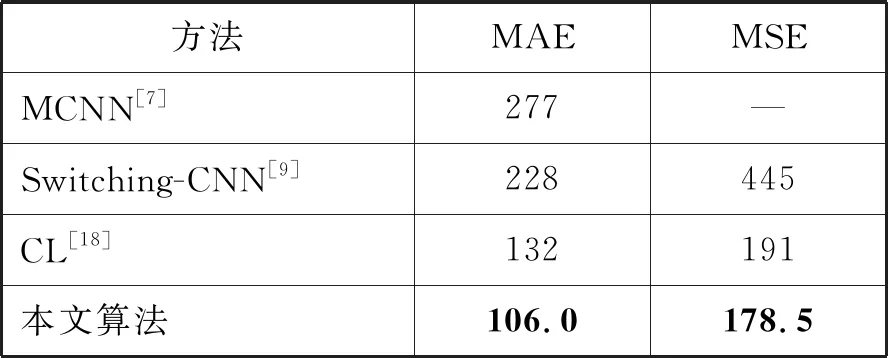
表5 UCF-QNRF估计误差
3 结 语
为了提高密集人群计数精度和人群密度图的质量,本文提出一种基于深度语义特征多级融合的人群计数网络。该方法通过不断地上采样降维重建高阶语义信息,在提高人群计数精度的同时还提高了模型生成的密度图质量。另外通过在一些公共数据集上与其他人群计数算法对比可知,本文提出的人群计数网络取得了更好的计数精度的同时,在多个数据集上也展现出了很好的鲁棒性。
猜你喜欢
科普童话·神秘大侦探(2022年11期)2022-05-30 03:21:35
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
恋爱婚姻家庭(2020年27期)2020-10-09 04:16:18
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
百花洲(2018年1期)2018-02-07 16:34:52
瞭望东方周刊(2017年45期)2017-12-08 21:37:48
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
