
基于BiLSTM-IDCNN-CRF模型的生态治理技术领域命名实体识别
2021-03-16 13:57:56马建霞
计算机应用与软件 2021年3期
蒋 翔 马建霞 袁 慧
1(中国科学院西北生态环境资源研究院 甘肃 兰州 730000) 2(中国科学院兰州文献情报中心 甘肃 兰州 730000) 3(中国科学院大学经济与管理学院图书情报与档案管理系 北京 100190) 4(中国移动通信集团北京有限公司 北京 100007)
0 引 言
自然语言处理(Nature Language Processing,NLP)是一门融语言学、计算机科学、数学于一体的交叉学科。在大数据时代的背景下,自然语言处理已广泛应用于各个任务中,如:信息检索、机器翻译、舆情分析、知识图谱构建等。命名实体识别(Named Entity Recognition,NER)是自然语言处理的基本任务之一,其目的在于从文本中识别出专有名词和有意义的短语,是上述较高层次自然语言处理任务中不可缺少的一部分基础工作。
在生态治理技术领域中,有大量的文献数据没有得到充分的开发与利用。对生态治理技术领域的论文数据进行充分的挖掘和利用,首先需要自动、准确、快速地识别和抽取生态治理文献中的相关实体,如生态治理技术名称、实施时间、实施地点等。抽取出的实体将应用于生态治理技术领域后续的自然语言处理任务(如:关系抽取、事件抽取、领域知识图谱构建等)。使用神经网络技术从大量文献中识别出生态治理技术领域的命名实体,不仅有助于生态治理技术领域的研究人员开展相关的科研工作,也促进了文本抽取技术在资源环境情报分析方面的应用。
生态治理技术领域中的文献存在书写规范不统一、专有名词较多等问题,在分词时会加入大量的噪声,降低实体的识别效果。本文提出BiLSTM-IDCNN-CRF模型,通过神经网络抽取出不同粒度的特征进行互补,使用更加丰富的特征信息提高命名实体识别的效果。同时,使用了基于字嵌入的方法以避免加入错误的分词信息,缓解上述问题。
1 相关研究
命名实体识别任务最早于MUC-6[1]会议作为信息抽取任务的子任务被提出。信息抽取任务的目标是从文本中抽取出结构化的信息,抽取结构化信息的前提是必须将文本中的相关实体(如人名、地名、机构名等)准确地识别和抽取。之后的MET会议、ACE评测和CoNLL会议都将命名实体识别作为一项重要的测评任务。目前实现命名实体识别的方法主要有基于规则的方法、基于统计机器学习的方法和基于深度学习的方法等。
基于规则的方法需要专家手工构建规则模板,通过提取相关文本中的特征(如:词频信息、关键词、指示词、位置词、方向词和中心词等)构造对应的规则集。基于规则的方法是根据某一种具体的语言,在某一特定的领域中提取相关特征,导致其可移植性较差;而且手工抽取特征模板的过程十分耗时,抽取的规则之间可能会产生干扰。基于统计机器学习的方法是利用人工标注的训练语料对模型进行训练,通过使用训练好的模型识别出文本中命名实体,包括基于分类模型的方法和基于序列模型的方法。基于统计机器学习的方法能够处理未出现过的文本,识别出没有标注过的实体,可移植性强。但是与深度学习相比性能较低,需要大量的训练数据保证模型的训练质量。
1.1 基于深度学习的命名实体识别方法
深度学习对于硬件设备的运算性能要求较高,随着近年来硬件设备的快速发展,深度学习方法逐渐成为主流。深度学习早期主要用于图像处理领域,近年来在语音识别、自然语言处理等领域的应用也取得了大量成果。Collobert等[2]提出使用卷积神经网络(Convolutional Neural Networks,CNN)对文本中的句子进行建模,结合CRF层进行序列标注实现命名实体识别。Zeng等[3]提出了使用CNN将词汇向量和词位置向量作为输入,通过卷积层、池化层和分类层得到句子的表示。Huang等[4]使用循环神经网络(Recurrent Neural Network)作为文本建模工具,提出了LSTM-CRF模型和BiLSTM-CRF模型,首次将双向长短期记忆神经网络模型(Bi-directional Long Short-Term Memory)结合CRF层的BiLSTM-CRF模型用于命名实体识别任务。Ma等[5]引入了一种将BiLSTM、CNN和CRF结合的神经网络架构,可以从词和字符级别提取文本中的深层特征,不需要特征工程和预处理。袁慧[6]使用相关领域论文中的摘要进行词向量训练,结合BiLSTM-CRF模型对生态治理技术领域进行了命名实体识别研究,从数据集中抽取出了时间实体、地点实体和生态治理技术实体。Zeng等[7]使用LSTM-CRF实现了生物医学文献中药物名称的准确识别。为解决BiLSTM模型无法充分利用硬件设备导致训练速度较慢的问题,Strubell等[8]提出使用迭代膨胀卷积神经网络(Iterated Dilated Convolutions,IDCNN)替代BiLSTM,与CRF层结合组成IDCNN-CRF模型,在提高了训练速度的同时获得了更好的性能表现。Qiu等[9]在膨胀卷积神经网络的每一层中加入原始信息,组成残差膨胀卷积神经网络(Residual Dilated Convolutional Neural Networks,RDCNN)对文本进行建模,最后结合CRF层对中文病历进行命名实体识别。表1对三种不同类型的命名实体识别方法和模型进行了整理。
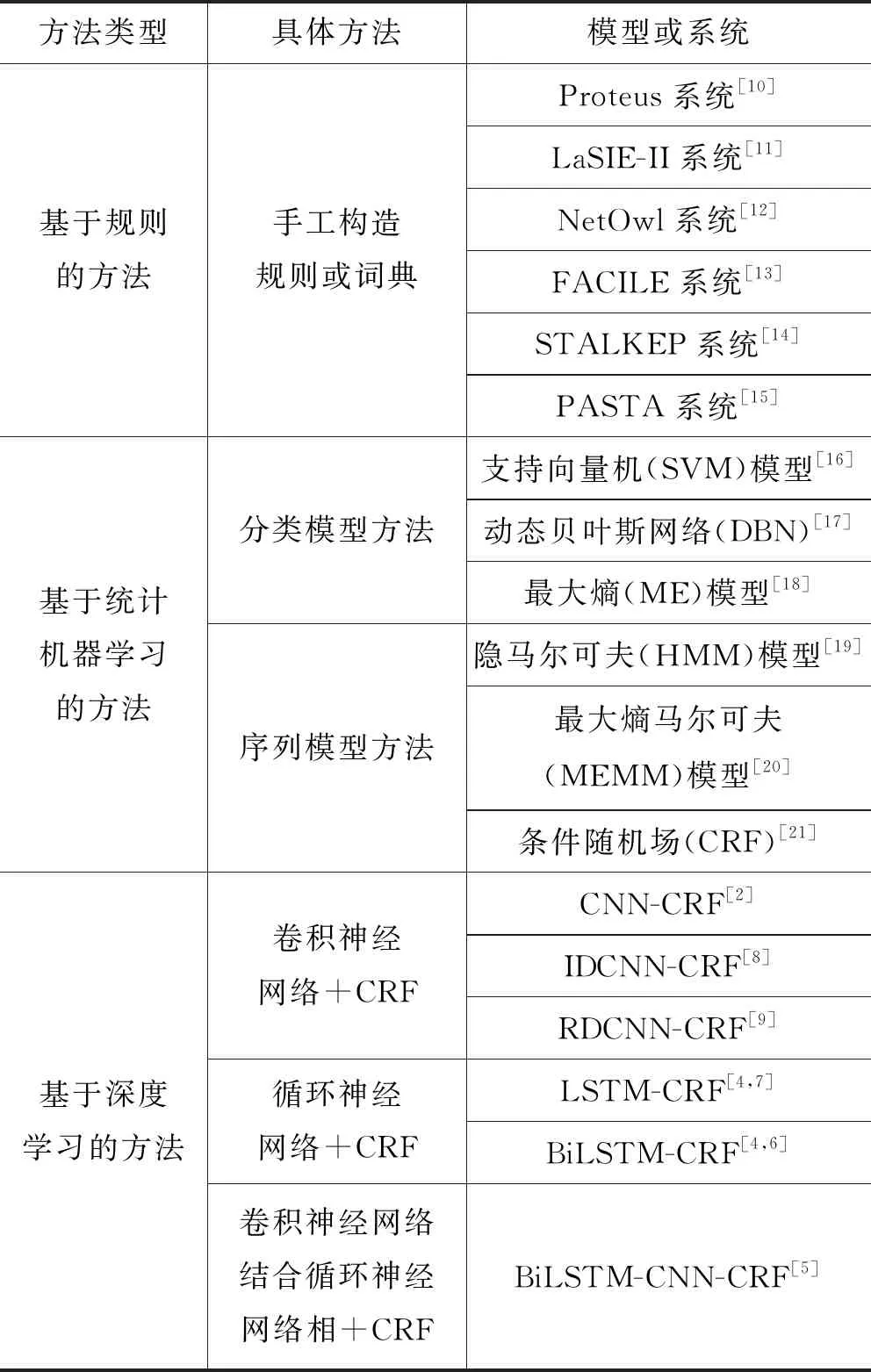
表1 命名实体识别相关研究
随着算法的进步以及计算机运算性能的提高,命名实体识别的主流方法从早期的基于规则的方法转变为基于统计机器学习的方法,再由基于统计机器学习的方法转变为基于深度学习的方法。本文在前人研究的基础上,将基于字嵌入的BiLSTM-CRF模型和IDCNN-CRF模型应用于生态治理技术领域的命名实体识别任务中,都超过了文献[6]方法在相同数据集上所取得的最好成绩。通过将BiLSTM模型和IDCNN模型分别抽取到的不同粒度的文本特征进行融合,再结合CRF层构成BiLSTM-IDCNN-CRF模型,相比前两个模型获得了更好的性能。
1.2 BiLSTM模型
循环神经网络(Recurrent Neural Network,RNN)由Elman[22]于1990年提出,该模型可以对序列数据进行处理,按照时间序列将数据逐条输入模型。但RNN输出的语义会偏向于较为靠后输入的数据,而且由于RNN中的权重矩阵复用,当序列长度过长时会出现梯度消失或梯度爆炸的问题。为解决上述问题,Hochreiter等[23]于 1997年提出了长短期记忆模型(Long Short-Term Memory,LSTM),以RNN单元为基础,通过输入门、输出门和遗忘门实现对历史信息的选择性利用,可以有效地捕获较长序列数据的信息。
令X=[x1,x2,…,xT]为输入的文本, LSTM神经元内部结构的实现如下:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(2)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(3)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(4)
ht=ottanh(ct)
(5)
式中:it、ht、ft、ct、ot分别为记忆门、隐藏层、遗忘门、细胞核和输出门在输入第t个文本时的状态;W为模型的参数;b为偏置向量;σ为Sigmoid函数;tanh为双曲正切函数。
双向长短期记忆网络(Bidirectional LSTM,BiLSTM)通过两层LSTM神经元分别从左至右和从右至左对序列数据进行学习,可以学习到某一字或词的历史信息和未来信息。将两种信息进行结合,可以更好地描述上下文内容。
1.3 IDCNN模型
卷积神经网络(Convolutional Neural Networks,CNN)与RNN相比,能够充分利用GPU的并行性,从而获得更快的训练速度。于是越来越多的研究人员将CNN模型用于NLP领域的任务中。
为了使一次卷积能够获取更多的上下文信息,同时避免由于卷积核的窗口过大导致内存溢出和运算效率降低等问题,Yu等[24]提出了膨胀卷积神经网络(Dilated Convolutions Neural Network,Dilated CNN)。膨胀卷积神经网络并不是使用膨胀的卷积核,而是在卷积核中增加了一个膨胀距离d。令卷积核的权重矩阵k=[k-l,k-l+1,…,kl],卷积操作可写作:
(6)
Strubell等[8]将膨胀卷积神经网络应用到命名实体识别任务中,提出了IDCNN-CRF模型。在IDCNN网络中包含多个膨胀卷积块,一个膨胀卷积块为一个多层的膨胀卷积神经网络。令X=[x1,x2,…,xT]为输入的文本,膨胀卷积块的内部结构的实现如下:
(7)
(8)
(9)
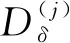
2 方法设计
2.1 字向量表示
神经网络输入的数据格式是向量或者矩阵,所以在训练之前需要将文本中的字或词使用向量进行表示,这个过程称为嵌入。
由于生态治理技术领域专有名词较多,且不同论文在书写规范上不统一,使得分词工具无法正确对实施地点、技术名词等进行正确分词,数据被加入了大量的错误分词信息。在具有大量错误分词信息的数据集中使用目前主流的Word2vec模型[25]训练出的词向量质量较低,无法有效表达词语之间的语义联系。而且Word2vec默认忽略频次小于5的词,而大量有效词汇的出现频次较少,导致很多词汇没有对应的词向量生成,无法准确获取大量低频词和未登录词的上下文语义。经测试,文献[6]训练的词向量仅能覆盖数据集中约24%的词汇。
Gridach[26]为解决生物医学领域文本的专业性较强、词汇复杂多变导致的低频词和未登录词等问题,提出使用BiLSTM神经网络获取单词的字符级信息,并与预训练的词向量结合,使得词向量能同时包含词汇的语义学信息和形态学信息,减少了无法准确获取低频词和未登录词上下文语义所带来的影响。本文借鉴其思路,使用字嵌入结合分词信息的方式对生态治理技术领域的文本进行表示,不仅能减少错误分词带来的影响,而且也不需要额外的时间进行词向量的训练。
2.2 标注文本
在生态治理技术领域中,需要抽取的实体类型包括:技术实施时间、技术实施地点和技术名称,分别使用Time、Plcae和Tech标签进行标注。本文使用IOBES标注法,相较于目前主流的IOB2标注法具有更多的标签信息。实体分类及标注方法如表2所示。
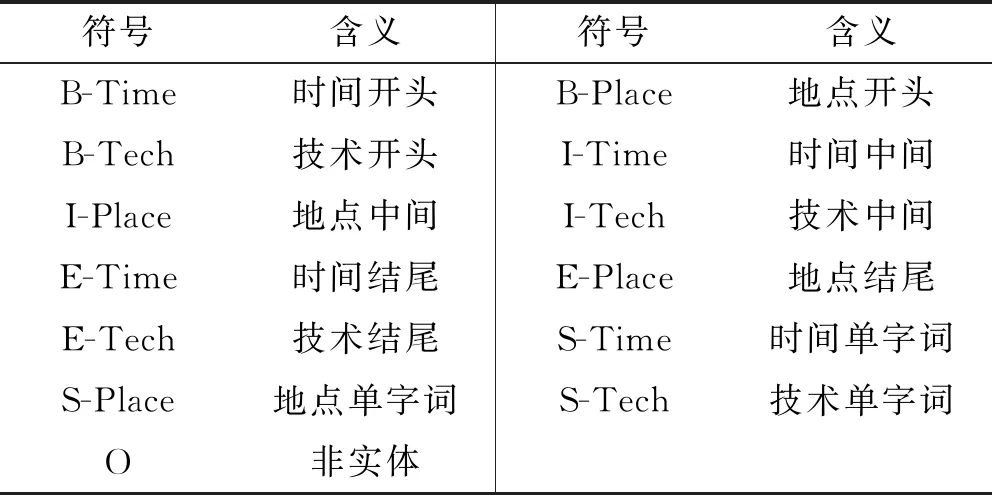
表2 数据集实体分类及标注体系
本文使用了jieba分词,将分词信息作为特征加入数据集中辅助实体识别,使用0代表单字词,1代表一个词的第一个字,2代表词的中间部分,3代表词的末尾字符。
以句子“在毛乌素沙漠应推行灌草桥相结合以…” 为例,数据集的具体标注方法如表3所示。
将文本的分词信息映射为低维向量,与文本的字向量进行拼接得到每个字的表示。图1以一个字向量为4,分词信息向量为1的文本矩阵为例,矩阵的每一行是一个字的向量表示。
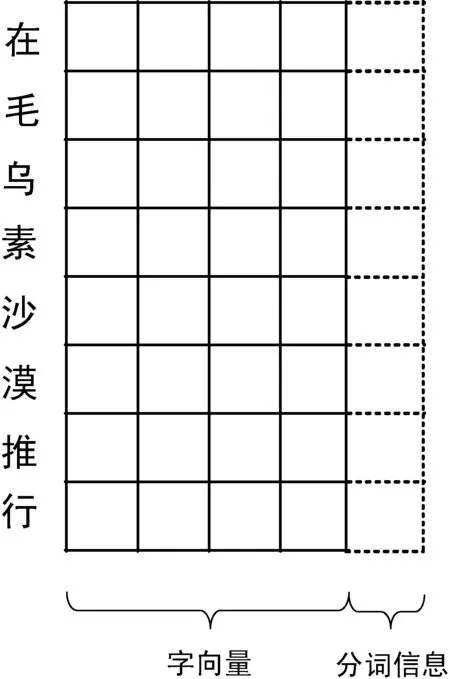
图1 文本的向量表示
2.3 BiLSTM-IDCNN-CRF模型
BiLSTM网络和IDCNN网络分别对不同粒度的文本进行特征提取,如果将两种模型获取的特征进行整合,相对于单一模型而言可以利用更充分的信息用于实体的识别。对每一个字的标签进行预测的过程可以看作是一个分类任务,即每一个字或词应该被分为哪个标签的类。在分类时需要考虑到文本的上下文特征以及长距离依赖,一般使用由Lafferty等[21]提出的条件随机场(Conditional Random Fields,CRF)实现序列标注任务。本文提出BiLSTM-IDCNN-CRF模型,首先使用BiLSTM-IDCNN神经网络对文本信息中的特征进行抽取,将BiLSTM-IDCNN神经网络学习得到的结果作为特征,再使用CRF对每一个字或词进行分类。
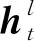
(10)
式中:⊕表示向量的拼接。
BiLSTM网络整体可写作:
H=fθ(X)
(11)
式中:矩阵fθ(X)为BiLSTM网络的输出;θ为BiLSTM网络中的参数。
由于BiLSTM网络和IDCNN网络的神经元数量可能不一致,为尽量减少feature map数量变化导致的分辨率损失,因此将BiLSTM网络学习到的上下文特征H使用一层卷积神经网络进行卷积(输入通道数量为BiLSTM的神经元数量,输出通道数量为IDCNN的神经元个数),将卷积结果H′=[h′1,h′2,…,h′T]作为IDCNN网络的输入。
(12)
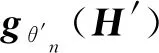
gθ′(H′)=gθ′1(H′)⊕gθ′2(H′)⊕…⊕gθ′N(H′)
(13)
得到特征gθ′(H′)后再通过一个全连接层便可得到每个标签的打分。
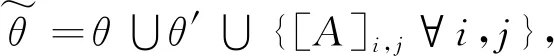
(14)
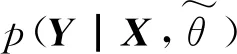
(15)
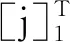
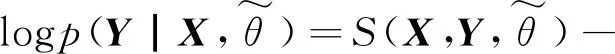
(16)
模型在训练时使用动态规划算法[27]对[A]i,j以及最佳标记序列进行计算和推理。
图2以“甘肃省准备…”为例,展示BiLSTM-IDCNN-CRF模型的结构以及标签预测流程。
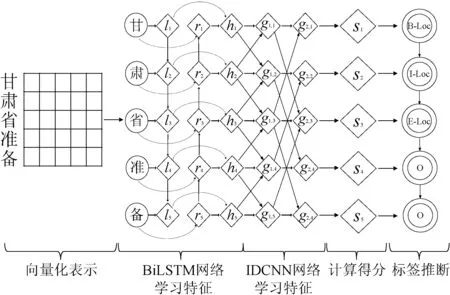
图2 BiLSTM-IDCNN-CRF模型总体结构
3 实 验
3.1 实验数据
生态治理技术数据集中共包含6 304个句子,总共标注了实体11 667个。其中:时间实体有1 687个;地名实体3 892个。生态治理技术实体5 894个。将数据集按照18∶1∶1的比例分为训练集、验证集和测试集,句子数和实体数详见表4。
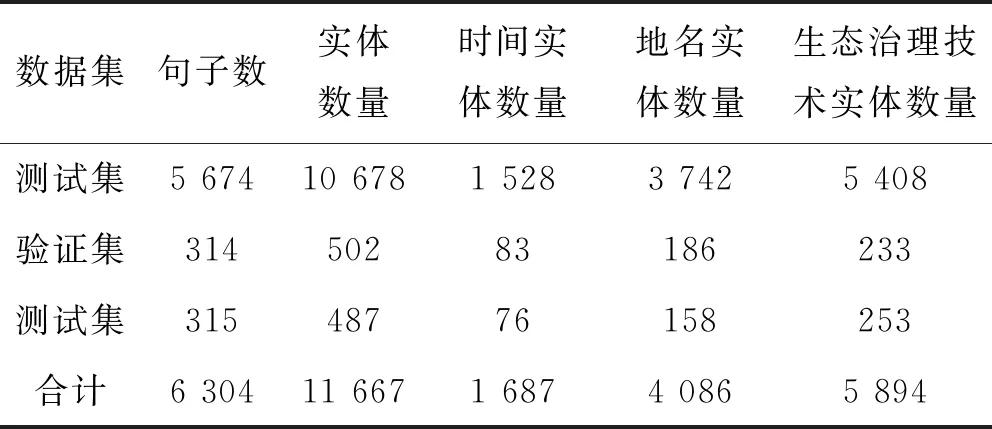
表4 数据集详细信息
3.2 实验流程
本文首先将基于字嵌入的模型和基于词嵌入模型的训练时的损失变化进行对比,分析字嵌入方法对模型训练速度的影响。然后分别将有无分词信息的BiLSTM-IDCNN-CRF模型的训练损失和测试结果进行对比,分析分词信息对模型的准确性和训练速度的影响。最后将基于字嵌入的BiLSTM-CRF模型[4]和IDCNN-CRF模型[8]与基于词嵌入模型[6]的测试结果进行对比,以验证基于字嵌入的文本表示方法和IOBES标注法带来的性能提升。同时,本文将BiLSTM-IDCNN-CRF模型应用于生态治理技术领域的命名实体识别任务,并将其与目前主流模型的识别结果进行对比,以验证该模型的有效性。本文实验的总体框架如图3所示。
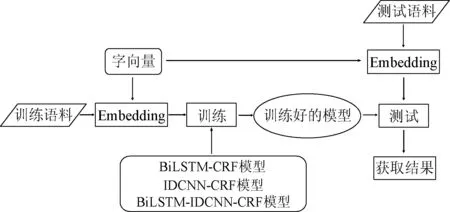
图3 实验总体框架
训练语料中包含训练集和验证集。首先将训练语料的文本进行字嵌入,再将文本矩阵分别输入BiLSTM-CRF模型、IDCNN-CRF模型或BiLSTM-IDCNN-CRF模型中进行训练,经过不断迭代得到训练好的命名实体识别模型;将测试集语料映射为文本矩阵,使用训练好的命名实体识别模型进行测试,得到最终的实验结果用于对比。
3.3 实验设置
本次实验使用目前较为常用的准确率(Precision,P)、召回率(Recall,R)和综合评价指标(F1-Measure,F1)作为实验结果的评价指标。
实验环境为Tensorflow[28]1.11.0版本,使用Adam优化器进行训练。BiLSTM-IDCNN-CRF模型的超参数设置如表5所示。膨胀卷积块层数、膨胀距离、膨胀卷积块个数等参数通过验证集调参得到。
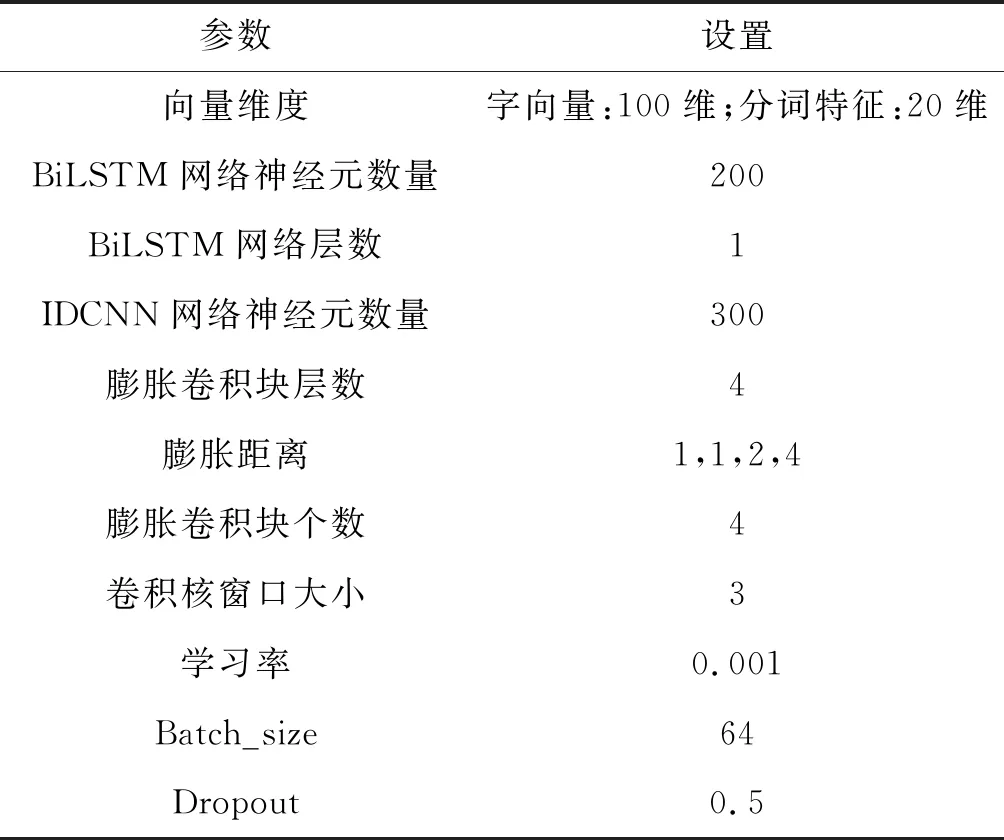
表5 BiLSTM-IDCNN-CRF模型超参数设置
3.4 模型训练损失的变化
将基于词嵌入的BiLSTM-CRF模型、基于字嵌入的BiLSTM-CRF模型和BiLSTM-IDCNN-CRF模型训练时的损失变化进行对比。
词是一个或多个字的组合,因此基于字嵌入模型的每一个句子的长度远远大于基于词嵌入模型的句子长度,导致基于字嵌入的模型在训练时损失的值相对较大,下降速度也相对较慢。但总体而言,基于字嵌入模型的训练速度仍然是比较快的。当迭代到第50轮时,两种基于字嵌入的模型的损失均下降到1以下。训练损失的具体变化如图4所示。
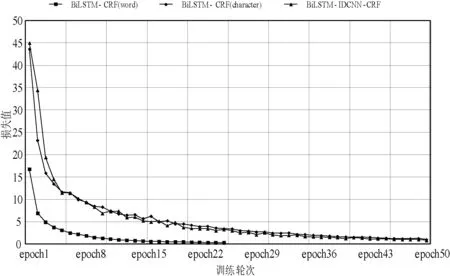
图4 损失变化图
为避免过拟合,同时提高训练效率,节约训练时间,本文将实验的迭代轮次设置为600,同时设置提前停止机制:当模型在验证集中连续50轮性能没有提升时,停止训练并在测试集中进行测试。
3.5 分词信息的影响
本节将无分词信息的BiLSTM-IDCNN-CRF模型与有分词信息的BiLSTM-IDCNN-CRF模型的训练损失和训练结果进行对比,分析分词信息的加入对模型训练时间和识别效果的影响。
首先对两种训练策略的损失变化进行分析。在前20轮迭代中,有分词信息的模型在训练时的损失明显低于无分词信息的模型;在20轮之后两种模型的损失均下降到较低的水平,但有分词信息的模型的训练损失仍略低于无分词信息的模型。两种模型的损失变化如图5所示。
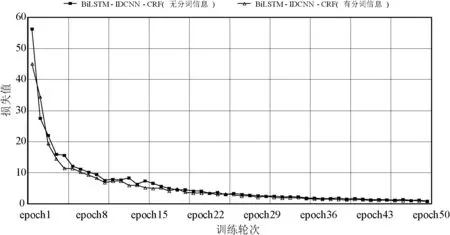
图5 分词信息对损失的影响
将两种模型在测试集中的表现进行对比。与无分词信息的模型相比,有分词信息模型的准确率提高了0.025 2,召回率提高了0.002,F1值提高了0.013 6。对比结果如表6所示。

表6 分词信息对结果的影响
分词信息的加入丰富了模型可以利用的文本特征,使模型可以在更少的训练轮次中取得更低的训练损失。同时,分词信息有效地辅助了模型对实体的推断,使实体识别的准确率和召回率得到了提高。
3.6 实验结果及对比分析
将基于词嵌入的BiLSTM-CRF模型、基于字嵌入的BiLSTM-CRF模型、IDCNN-CRF模型和BiLSTM-IDCNN-CRF模型的测试结果进行对比(基于字嵌入的模型均包含分词信息),并对结果进行分析和讨论。对比结果如表7所示。
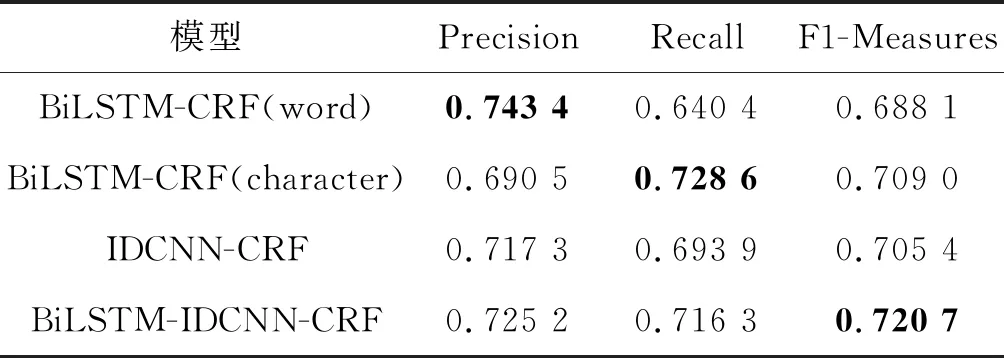
表7 模型结果对比
基于词嵌入的BiLSTM-CRF模型在准确率上取得了较高的成绩,其中时间和地点两类实体的识别准确率(0.786 3和0.820 2)均高于其他3个模型。通过对模型进行分析发现,基于词嵌入的模型在对文本进行分词时加入了外部词典,包括时间、地名和实施技术等词汇,使得各个实体的边界更加清晰。但是该模型对生态治理技术实体识别的准确率较低(仅为0.660 2,远低于时间实体的0.786 3和地点实体的0.820 2),原因在于文献中对于生态治理技术的写法标准不统一,加入的实施技术词典无法有效地对于技术实体进行准确分词,引入了大量噪声信息。基于字嵌入的BiLSTM-CRF模型避免了引入噪声的问题,使得模型可以有效地对文本进行特征学习,结合上下文信息和分词信息实现命名实体识别,在召回率上相对于基于词嵌入的模型得到了明显的提升,因此在综合评价指标F1值上超过了基于词嵌入的模型。
在基于字嵌入的模型中,BiLSTM-CRF模型对整个句子的特征进行学习,从而能从整体上把握实体的上下文信息,从句子中识别出更多的实体,取得了更高的召回率;而IDCNN-CRF模型更关注于实体周围的信息和特征,能够更好地区分实体的边界,因此在准确率上获得了相对更高的结果。
BiLSTM神经网络和IDCNN神经网络获取到的不同粒度的特征可以相互补充,从BiLSTM-IDCNN-CRF模型的实验结果中也可以得到验证。BiLSTM-IDCNN-CRF模型虽然在召回率上相对前两个模型得到了一个折中的结果,但是由于获得的特征更加丰富,因此准确率高于前两种模型,最后的F1值也超越了前两种模型。IDCNN网络的输入为BiLSTM网络得到的具有上下文语义的特征,因此在对某一个字的周围字符信息进行学习时会同时得到上下文信息和该字周围的语义信息。也就是说,模型在预测某个字是否是实体的一部分时,不仅会利用整个句子的语义特征,还将重点关注该字周围字符的语义特征,因此在整体性能上取得了更好的成绩。
4 结 语
命名实体识别可以快速、准确、自动地从大规模文本中抽取出有意义的实体。本文提出了基于字嵌入的BiLSTM-IDCNN-CRF模型,可以充分学习到上下文信息和局部信息中的特征,将两种特征进行互补提高实体的抽取效果。目前已经抽取出的实体可用于进行统计分析,如:生态治理实践分布分析、生态治理地域分析和生态治理技术名称分析等。如何得到生态治理的实施时间、实施地点和生态治理技术之间的关系将是下一步重点探索和研究的方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中国外汇(2019年18期)2019-11-25 01:41:54
智富时代(2019年6期)2019-07-24 10:33:16
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
高中生·天天向上(2016年9期)2016-11-22 09:10:34
电视技术(2014年19期)2014-03-11 15:38:20
