
棉/涤混纺织物近红外简化分析模型构建方法研究∗
2021-03-13 07:18张国丽王
传感技术学报 2021年12期
张国丽王 武
(天津理工大学中环信息学院,天津 300380)
纺织品成分标签是纺织品技术法规严格控制的内容之一,是纺织品出口和指导消费者正确使用的重要参考指标。 目前,混纺织物成分的定量检测方法主要有化学溶解法和显微镜法[1],其中,化学溶解法需要依据不同的分析组分选择相应的溶剂,操作专业性强且易污染环境;显微镜法检测效率低,而且分析的准确性很大程度上取决于测试人员分辩混合物中不同纤维的能力。 因此,亟需探索一种高效、绿色且易于操作的分析方法及仪器为纺织品成分的快速分析提供服务。
近红外光谱分析技术 ( Near-infrared spectroscopy,NIRS)作为一种高效、无损、绿色的分析方法被广泛应用于众多领域[2]。 在纺织领域,NIRS 被用于鉴别废旧织物、检测织物纤维含水率及含量的检测[3-4]。 孙通等采用NIRS 和竞争性自适应重加权算法对棉麻混合织物中棉含量进行了检测研究[5]。 Sun 等利用近红外技术结合变量选择法快速测定棉/涤混纺织物中含棉量[6]。 季惠等采用NIRS 对棉、涤纶、锦纶、羊毛的纯纺纺织品进行鉴别,识别率达90%以上[7]。
NIRS 在纺织品检测中的应用大多采用商业化的分析仪器,建模变量较多,要求分析人员具有一定的化学计量学知识,模型较复杂;而且,较宽的分析波段对分析仪器光源和检测器有较高要求,仪器价格较昂贵。
论文采用NIRS 对棉/涤混纺织物中棉含量进行无损快速分析。 蒙特卡罗无信息变量消除(Monte Carlo uninformative variable elimination,MCUWE)、竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)和迭代保留信息变量(iteratively retaining informative variables,IRIV)三种特征变量优选方法结合偏最小二乘回归(partial least squares regression,PLSR)用于棉/涤混纺织物中棉含量的近红外简化分析模型构建。 研究结果将为开发纺织品成分便携式近红外分析仪器光源和探测器的选用提供理论参考。
1 实验部分
1.1 样品与仪器
试验样品由山东、江苏、广州等出入境检验检疫局提供,共255 个棉/涤混纺织物样本。 实验样品具有不同组织结构和不同颜色构成,根据国标GB/T 2910.11—2009 方法测定样本的棉含量,得到棉的质量百分数含量范围为5.30%~99.50%。 255 个试验样品按照棉含量由低到高排列,其中棉含量最大和最小的样品作为校正集样品,连续的3 个样品中取1 个作为预测集样品。 因此,校正集样品有170 个,预测集样品有85 个。
瑞士步琦公司NIRFlex N-500 型傅立叶变换近红外光谱仪用于样品近红外光谱的采集,光谱范围为4 000 cm-1~10 000 cm-1。 实验过程中,为了减少纺织品厚度、孔隙等结构对织物的近红外光的反射影响[8],对面密度大于100 g/m2的样品折叠为4层,面密度小于100 g/m2并大于50 g/m2的样品折叠为8 层,面密度小于10 g/m2的样品折叠为16层。 为了消除实验过程出现的偶然误差,对每一个样品进行重复检测3 次,取平均光谱做最终检测光谱。
1.2 数据处理方法
标准正态变量变换(SNV)预处理用于消除纺织品间由于颜色、纹理和厚度等差异引起的光散射和光谱基线漂移效应[9];混纺织物样品的近红外光谱包含1 501 个变量,包含了大量的相似冗余信息和噪声变量。 拟采用变量优选方法去除冗余和噪声信息,筛选出光谱数据中有效变量,建立简化分析模型。
MCUVE 是基于蒙特卡罗重复采样结合UVE 变量排序的特征变量优选方法[10-11]。 UVE 是基于PLSR 系数向量X的变量选择方法,用来消除不提供信息的变量。 回归系数矩阵在第n次迭代后计算得到的回归系数矩阵XW=[X1,X2,…,Xn],系数的稳定性定义为:
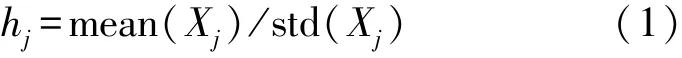
式中:mean(Xj)和std(Xj)为模型回归系数的均值和标准差;Xj为回归系数矩阵X的第j列向量,j=1,2,…,n。
CARS 是一种快速有效的变量选择算法[12-13]。该方法基于蒙特卡罗采样,随机抽取校正集样本的一部分建立PLSR 模型,得到每个波长的回归系数。通过指数衰减函数( exponentially decreasing function,EDF)去除回归系数较小的波长点。 基于自适应重加权采样(adaptive reweighted sampling,ARS)技术进一步对变量进行筛选。 当蒙特卡罗采样次数达到预先设定的值时,比较每次蒙特卡罗采样得到变量子集的交叉验证的均方误差(root mean square error of cross-validation,RMSECV)值,选择RMSECV 值最小时对应的变量子集作为CARS 的最优变量子集。
IRIV 是一种基于二进制矩阵重排过滤器(binary matrix shuffling filter,BMSF)的特征变量选择算法[14-15]。 通过生成了一个仅包含1 或0 的二元矩阵M,其维度为K×P的。 矩阵M的每一行依次用于PLSR 方法建模。 5 折交叉验证的RMSECV用于评估每个变量子集的模型结果。 因此,可以获得K×1 大小的向量记为为RMSECV0。 将M的第i列中的所有1 变为0,并将第i列中的所有0 变为1,同时保持M的其他列不变来获得矩阵M1。 矩阵M1的每一行建立PLSR 模型,得到K×1 大小的向量记为RMSECVi。 定义φ0和φ1以评估每个变量的重要性,公式如下:
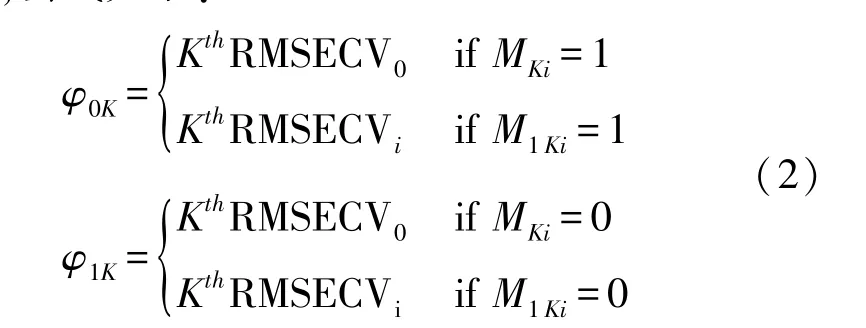
式中:MKi是M的第K行i列的值,M1Ki是M1的第K行i列的值,KthRMSECV0和KthRMSECVi分别表示向量RMSECV0和RMSECVi中第K行的值。 定义P=0.05 为阈值进行Mann-WhitneyU检验[16]。 通过迭代保留有用信息变量,剔除无信息变量和干扰变量。 对保留变量进行反向消除,剩下的变量为最终选取的特征变量。
光谱预处理后,采用MCUVE,CARS 及IRIV 方法对光谱变量进行优选,剔除冗余的变量。 在MCUVE,CARS 及IRIV 分析中,采用5 折PLSR 交叉验证建模,最大因子数为20。 经变量优选后,应用PLSR 方法建立棉/涤混纺织物中的棉含量预测模型。
1.3 模型评价准则
AIC(Akaike information criterion)信息准则[17]是建立在熵的概念基础上,可以权衡所估计模型的复杂度和模型拟合数据的优良性。

式中:k是变量的数量,n为样本数,RSS(residual sum of squares)为残差平方和。 AIC 值是模型构建变量数和精度的综合评价指标,AIC 值越小代表建模的变量数越少,且具有较好的拟合精度。
2 结果和分析
2.1 棉/涤混纺织物样品近红外光谱分析
图1 所示(a)为棉/涤混纺织物样品的近红外光谱图。 从图1(a)可以看出,4 000~10 000 cm-1范围内的光谱分布非常相似,由于样品厚度、纹理、颜色等差异导致黑色棉/涤织物、牛仔布及其他棉/涤样品谱图存在较大差异,同时还显示出系统的基线漂移[18]。 光谱在4 000 cm-1~7 000 cm-1之间存在较多明显的波峰与波谷,光谱波峰分别位于4 104 cm-1、4 484 cm-1、4 972 cm-1、5 388 cm-1和6 172 cm-1左右,波谷分别位于4 040 cm-1、4 260 cm-1、4 740 cm-1、5 256 cm-1和6 052 cm-1左右。 其中6 172 cm-1左右的波峰为涤纶特征峰,峰值与涤的含量变化趋势一致,当涤纶含量小于10%时,此特征峰几乎观察不到。
采用SNV 方法对原始近红外光谱数据进行处理消除纺织品间由于颜色、纹理和厚度等差异引起的光谱散射和基线漂移效应。 预处理后的近红外光谱如图1(b)所示。 从图中可以看出,预处理后不同样品光谱间的非组分信息引起的变动得到明显改善。
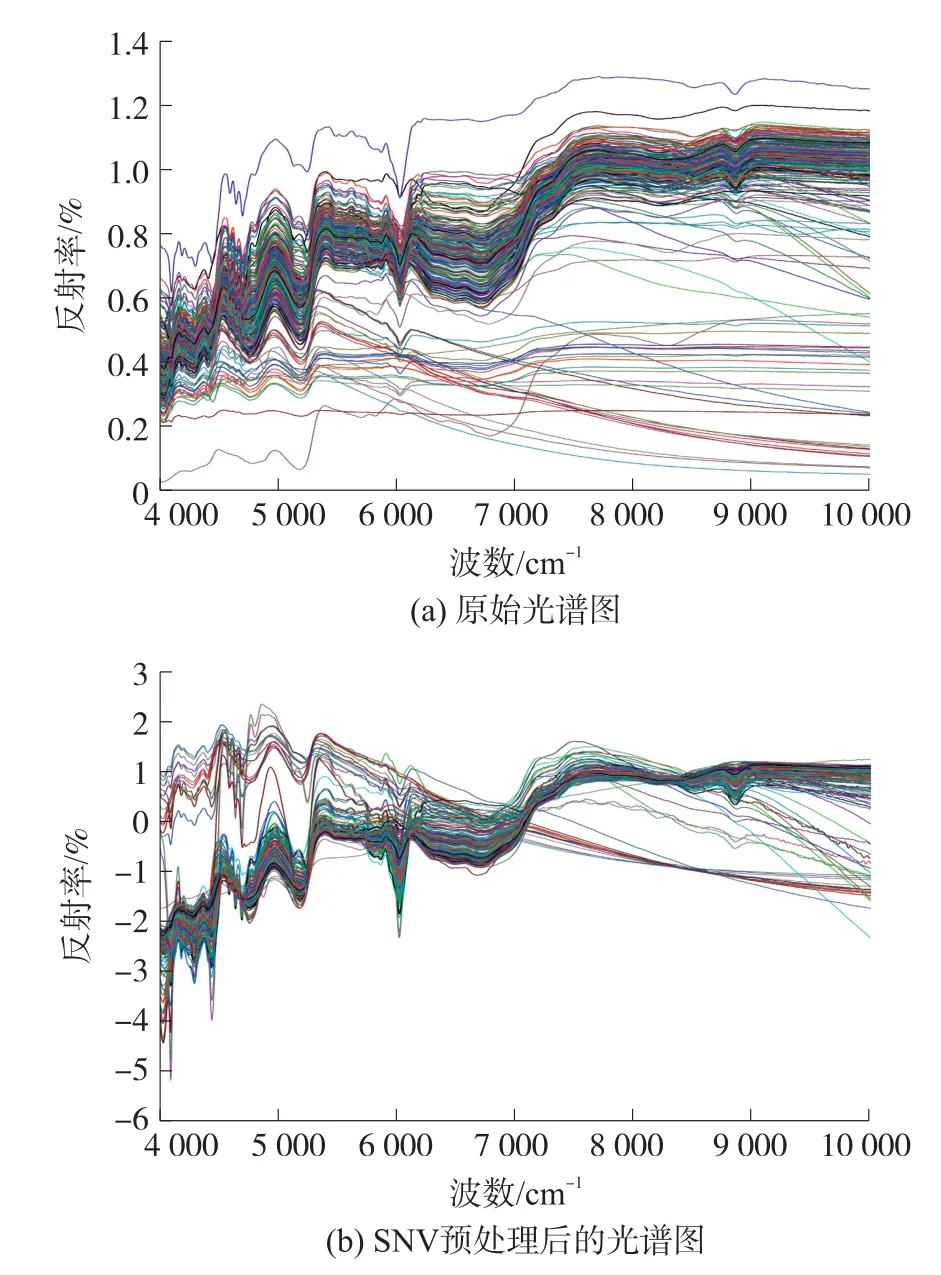
图1 棉/涤混纺织物样品近红外光谱图
2.2 棉/涤混纺织物近红外光谱特征变量优选
MCUVE 算法的变量选择结果,如图2(a)所示,在迭代采样中,RMSECV 的值的整体变化趋势是先下降后上升,最小值点出现在第32 次采样,之后的RMSECV 逐渐增大,说明引入了冗余变量。 保留第32 次迭代采样对应的650 个变量,其分布如图2(b)所示。
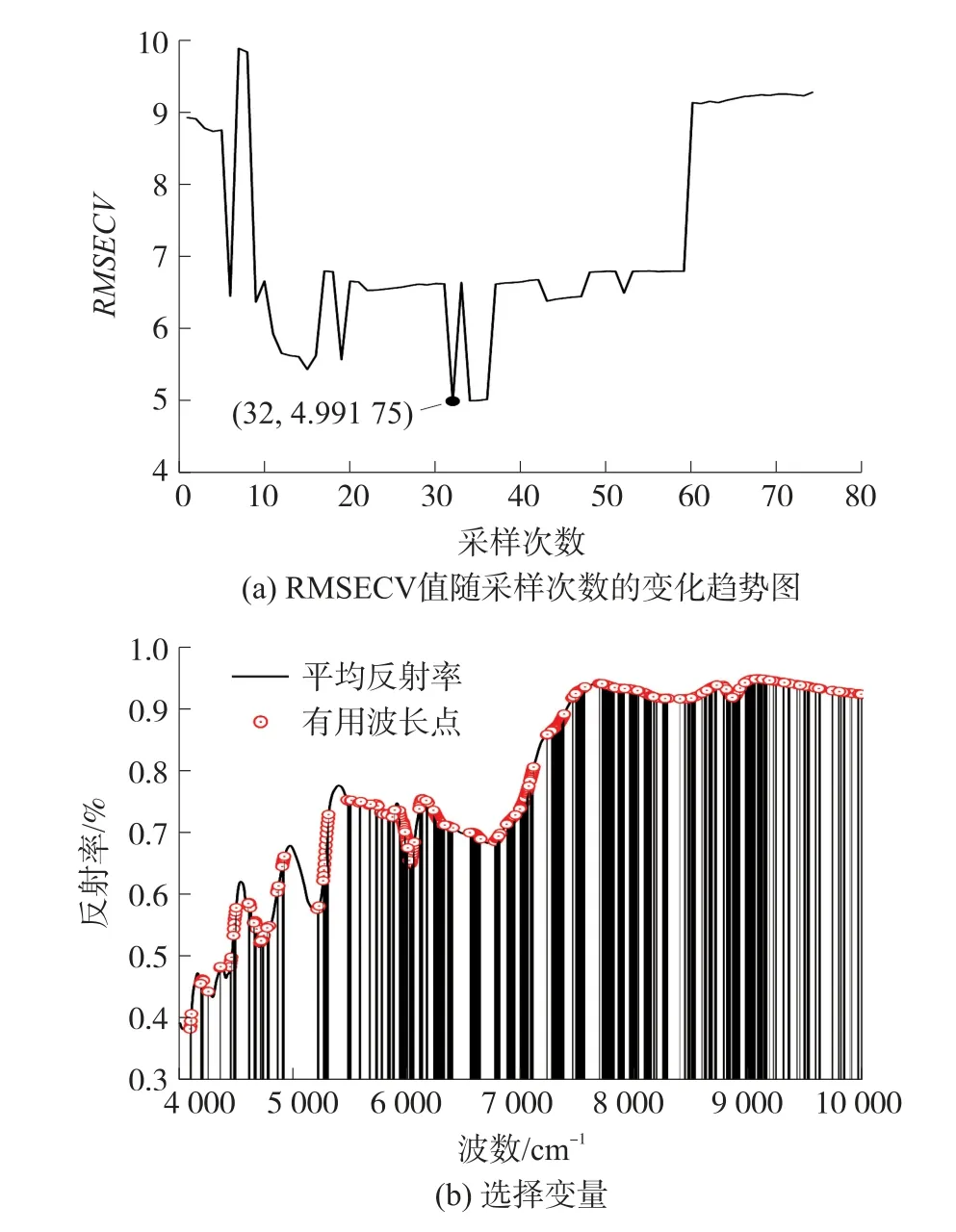
图2 MUVCE 方法变量优选结果
CARS 算法的变量选择结果,图3(a)反映出由于EDF 的作用,随着蒙特卡罗采样次数的增加,RMSECV 值呈先减小后增大的趋势,并且在第24 次采样时达到最小值,因此选择该点对应的67 个特征变量,作为CARS 算法筛选的特征变量,如图3(b)所示。
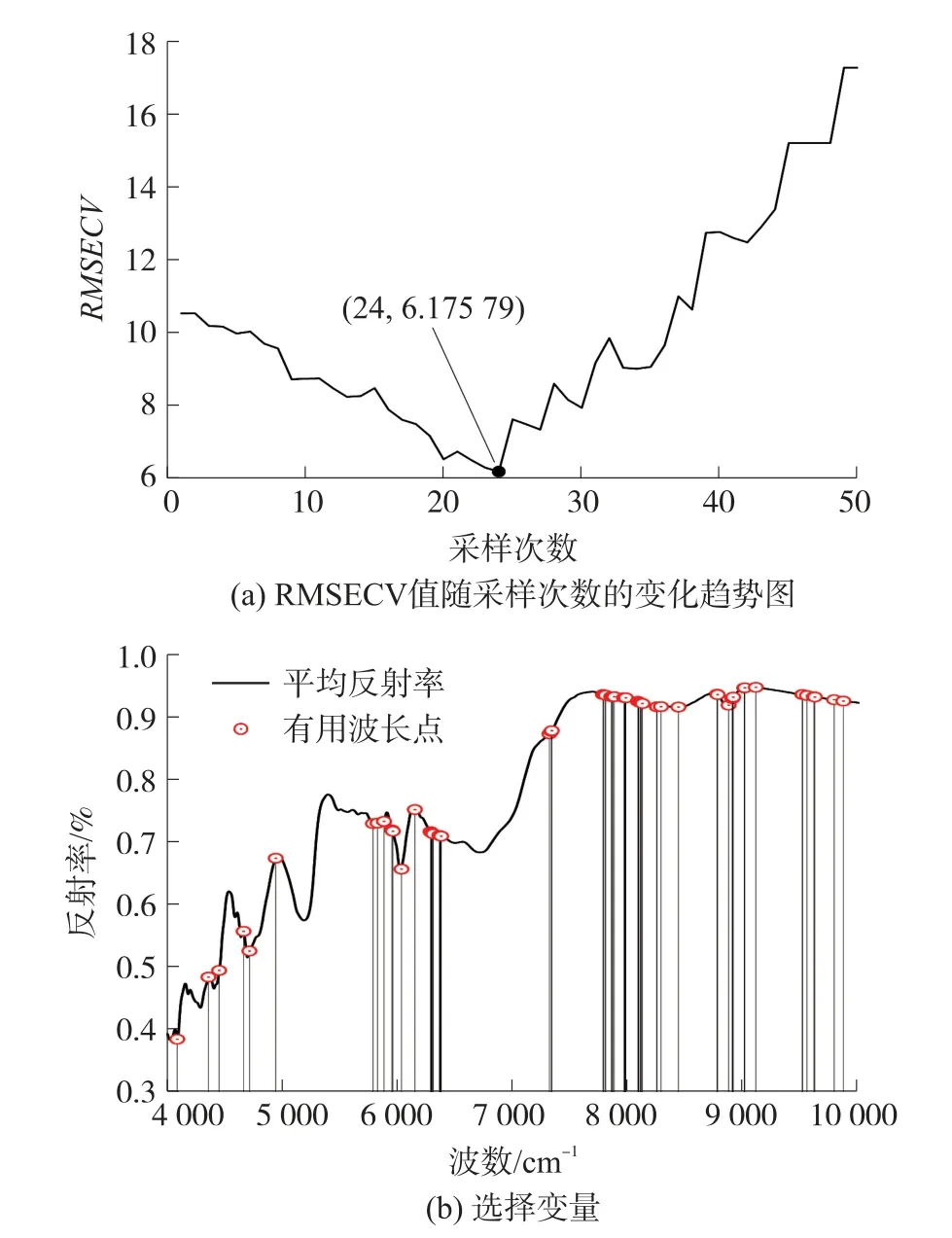
图3 CARS 方法变量优选结果
IRIV 算法一共进行了13 轮,如图4(a)所示为IRIV 算法迭代次数与优选变量的变化关系图,由图可知,前3 轮迭代变量个数迅速减少,从1 501 个变量减少到了370 个,然后变量个数减少的速度放缓,第12 轮迭代后完全剔除了无信息变量和干扰变量,并进行反向消除操作。 经过第13 轮的反向消除最终选择了6 个特征变量,如图4(b)所示。
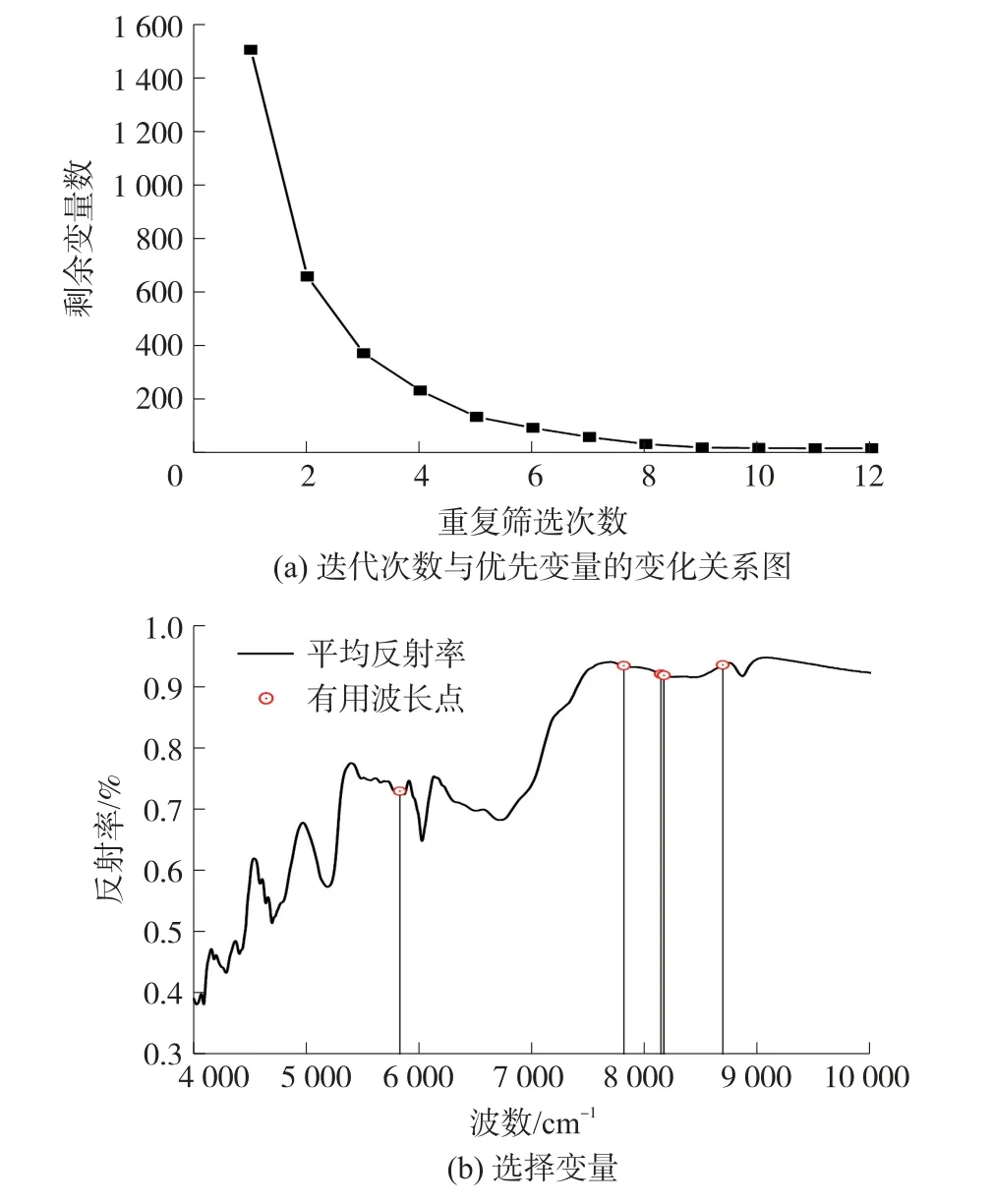
图4 IRIV 方法变量优选结果
2.3 混纺织物棉含量简化光谱分析模型构建
全谱和变量优选后混纺织物棉含量的PLSR 模型结果如表1 所示。 通过与SNV-全谱-PLSR 模型比较,SNV-MCUVE-PLSR 模型的变量数减少了851个,RC和RP分别提高了0.065 和0.042,RMSECV 和RMSEP 分别降低了4.247 和2.471。 SNV-CARSPLSR 模型的变量数减少了1 434 个,RC和RP分别提高了0.066 和0.037,RMSECV 和RMSEP 分别降低了4.418 和2.197。 SNV-IRIV-PLSR 模型的建模的变量数仅为6,RC和RP分别提高了0.013 和0.004,RMSECV 降低了0.651,RMSEP 增大为0.025,与全谱模型比较,预测误差稍有增加,然而建模的有效变量数显著下降。 由此可知三种变量选择法都能够在保证较高分析精度的前提下有效地选择特征变量。

表1 不同建模变量的混纺织物棉含量PLSR 模型结果
模型的AIC 结果如表1 所示。 全谱模型的AIC值最大为3 758,经过变量优选方法处理后模型AIC值都得到大幅度降低,其中CARS-PLSR 和IRIVPLSR 模型的AIC 值分别为668.8 和743.1,但是IRIV-PLSR 模型在保证预测精度较好的前提下,建模变量最少,因此IRIV-PLSR 棉含量分析模型复杂度最小,模型最简化。 图5 所示为85 个预测集样本棉含量真实值与IRIV-PLSR 模型预测值的相关图,两者具有较好的相关性。
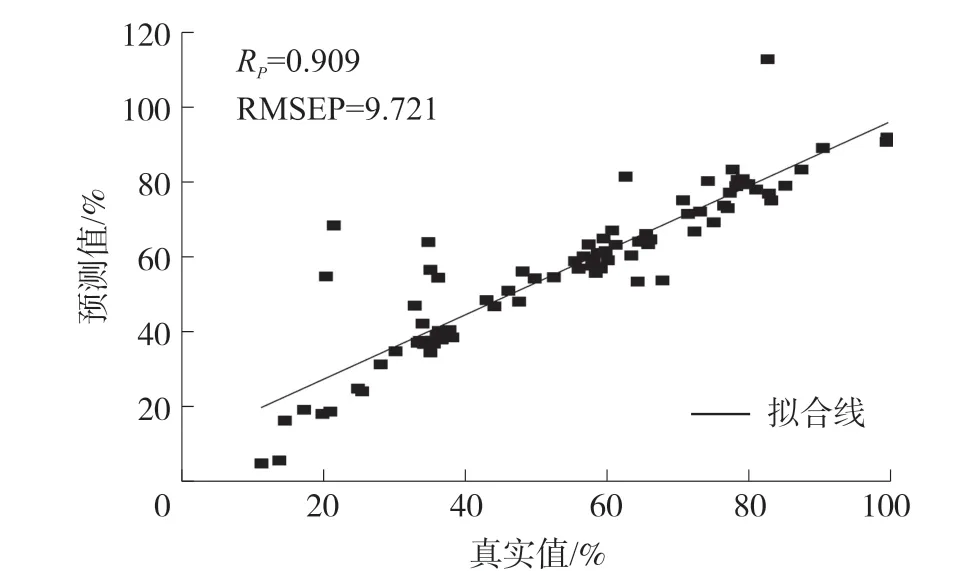
图5 棉含量真实值与IRIV-PLSR 模型预测值相关图
3 结论
近红外光谱结合变量优选方法对棉/涤混纺织物中棉含量进行简化模型的构建方法研究,研究结果表明三种变量选择方法均可以在保证模型具有较好分析精度的前提下优选出建模变量,降低模型构建的复杂度,其中,IRIV 方法将原始光谱的1 501 个变量缩减为6 个,对应的波长分别为5 824 cm-1、7 808 cm-1、8 136 cm-1、8 160 cm-1、8 164 cm-1和8 684 cm-1,极大地简化模型,研究结果将为开发纺织品成分便携式近红外分析仪器光源和探测器的选用提供理论参考。
猜你喜欢
纺织标准与质量(2022年5期)2022-10-27
北京航空航天大学学报(2022年8期)2022-08-31
毛纺科技(2021年8期)2021-10-14
纺织科技进展(2021年3期)2021-06-09
化工管理(2021年7期)2021-05-13
知识经济·中国直销(2018年4期)2018-04-18
纺织服装流行趋势展望(2016年4期)2016-05-04
中国光学(2015年5期)2015-12-09
中国洗涤用品工业(2015年9期)2015-02-28
食品工业科技(2014年23期)2014-03-11
