
代码特征自动提取方法
2021-03-11 06:20史志成
计算机与生活 2021年3期
史志成,周 宇,3+
1.南京航空航天大学 计算机科学与技术学院,南京210016
2.南京航空航天大学 高安全系统的软件开发与验证技术工信部重点实验室,南京210016
3.南京大学 软件新技术国家重点实验室,南京210023
在“大代码”背景的驱动下,如何高效地提取代码特征并对其进行编码以快速地处理海量数据的需求已日益迫切。如今,深度学习在自然语言处理的很多领域已经取得了突破性的进展,人工智能也逐渐从“感知智能”迈向“认知智能”,机器不仅能够感知客观世界所释放的信息,更能够对这些信息像人一样进行理解和分析。Hindle等人[1]已经论证了程序语言和自然语言类似,具备众多可供分析的统计属性,代码语言可以和自然语言一样能够被机器理解和分析。因此,许多学者简单地将代码作为自然语言来处理。例如,代码被表示为一个字符串序列应用在克隆检测[2-3]、漏洞定位[4]以及代码作者分类(code authorship classification)[5]的任务当中。尽管代码和自然语言有很多共性的特征,都是由一系列单词组成且都能表示成语法树的形式,然而代码有许多自己专有的特性,代码具有更强的逻辑结构,自定义的标志符,且标志符之间存在长距离依赖等。简单地将代码视作自然语言进行处理难免会造成信息丢失。为了使模型更适合处理代码语言,部分学者借助软件工程的领域知识,制定了一些启发式规则来静态地提取代码特征,例如在应用程序接口(application programming interface,API)推荐领域,Zhou 等人[6]就将用户查询后得到的反馈信息作为构建API 向量的一维特征来提高查询效果,然而这些静态提取代码特征的方式有以下三个弊端:
(1)完全依赖研究人员的先验知识来提取特征,所提取的特征数目有限。
(2)当代码库过于庞大和复杂,特征规则的制定也会相应变得复杂,难以适用于对海量且结构复杂的代码数据进行处理。
(3)规则的制定往往是面向特定任务的,可迁移性差。
因此,近几年许多研究使用深度学习模型来自动提取代码的特征[7-10],以摆脱对人工提取特征的依赖。这些模型很多借助代码的抽象语法树(abstract syntax tree,AST)来提取特征,通过对AST 内部节点之间的依赖关系进行提取,来获得代码的结构信息,而不是简单地根据代码的标志符序列提取语义信息。然而这些方法有一个明显的弊端,就是都将树的二维结构转化成一维的序列结构进行预处理,如Alon 等人[10]将AST 处理成一个路径集合,Hu 等人[8]以及White等人[9]直接使用先序遍历的方式获得AST节点的展开序列作为模型的输入,这些降维的处理方式一定程度上会造成节点之间某些依赖关系的丢失。
因此,为了更充分地提取代码的结构信息,部分学者提出了一些不降维而直接处理AST的树形深度学习模型。如Wan等人[11]使用Tree-LSTM(tree-structured long short-term memory networks)进行注释生成,Mou等人[12]使用TBCNN(tree-based convolutional neural network)模型进行代码分类。然而这些树形深度学习模型仍然有两个局限性:(1)与自然语言的长文本类似,在AST规模十分庞大的情境下,很容易在模型的训练过程中出现梯度消失的情况[13-15],因此无论是Wan等人使用Tree-LSTM或者Mou等人使用的TBCNN都会很容易丢失那些存在长期依赖关系节点之间的部分信息。(2)Wan 等人使用的Tree-LSTM 要将AST先转化为二叉树再进行编码,该预处理操作破坏了AST 原始的结构且转化后树的深度将会大幅增加,加剧梯度消失问题。
本文结合TBCNN以及Zhang等人[16]提出的ASTNN(AST-based neural network)模型构建了一个基于卷积和循环神经网络的自动代码特征提取模型(convolutional and recurrent neural network,CVRNN)。模型的输入是代码的AST,为了提高AST 初始词向量的质量,还针对AST 设计了一个专门的词向量预训练模型,预训练词向量不仅能提升后面实验部分代码分类以及相似代码搜索的实验结果,还能在模型的训练过程中加速模型的收敛。借鉴ASTNN 切割AST的思想,模型并未直接对整棵AST进行处理,而是根据“if”“while”“for”以及“function”这4 个代表程序控制块的AST 节点将AST 切割成一系列子树,再利用TBCNN 模型对这些子树进行卷积运算。子树的规模远小于原先的AST,因此可以有效地解决节点长期依赖导致的梯度消失问题。之后,采用双向循环神经网络[17],内部神经元采用LSTM[18],来提取代码块之间的序列信息,将每个时间步生成的代码向量存放到一个向量矩阵中,最终采用最大池化得到代码向量。为了验证CVRNN 模型生成的代码向量的质量,还在CVRNN模型基础之上设计了两个具体的应用模型,代码分类以及相似代码搜索模型。实验结果表明,CVRNN模型不仅能够高效地自动提取代码的特征,且所提取的特征具有很强的迁移能力,不仅适用于代码分类任务,其分类训练后得到的编码器在相似代码搜索任务上也有很好的效果。
本文的主要贡献是:
(1)提出了一个基于AST的词向量训练模型。
(2)提出了一个基于卷积和循环神经网络的自动代码特征提取的深度学习模型。
(3)构建了一个高效的用于搜索相似代码的系统,且该项目所使用的数据集以及代码已在github上开源(https://github.com/zhichengshi/CVRNN)。
1 代码特征提取模型
这部分主要分为两个子模型进行介绍:
(1)基于树的词向量训练模型。
(2)基于卷积和循环神经网络的特征提取模型。
1.1 基于树的词向量训练模型
词嵌入技术是将自然语言文本中的单词嵌入到低维空间的一种向量表示方法[19]。近几年,许多学者也将该方法成功应用在处理代码的任务中,如API推荐[20-21]、漏洞检测[22]等。然而这些词嵌入技术简单地将代码视为序列化的文本进行处理,往往采用类似Word2vec[23]滑动窗口的方式建立特定单词的上下文情境,并以此为依据来生成相应的词向量,如Zhang等人[16]就通过先序遍历的方式获得AST的节点序列,然后使用Word2vec 生成词向量,而代码元素之间的依赖关系其实是一种二维的树形结构,应用这种方法获取词的情境难免会导致代码的部分结构信息难以编码进最终生成的词向量中。Mou 等人[12]在对AST中节点进行编码时只将当前节点的孩子节点作为情境,这种情境信息的提取方式仍然不完备。因此本文借鉴Pérez等人[24]构造树中节点上下文情境的方法,结合当前节点的祖先节点、兄弟节点以及子孙节点作为情境,在提取祖先节点以及子孙节点作为情境的过程中分别设置一个向上以及向下探测的参数来控制提取情境的深度,并设计了一个词向量训练模型根据提取的情境来生成AST 节点的词向量。为了提高相似代码搜索的准确率以及提高模型的训练速度,将不考虑AST 叶子节点的信息即代码中的标志符信息,因此该模型更侧重于对代码结构信息的提取。相似代码搜索任务使用的数据集来源于leetcode 编程网站,代码分类任务所使用的数据集是Mou 等人[12]提供的104 数据集,该数据集共包含104个类别的代码,每个类别下包含500个样本。在分类训练的过程中并没有使用AST叶子节点的信息,原因有二:(1)由于代码中的标志符是程序员自定义的,而据观察104数据集中的词汇与leetcode上的词汇并不重叠,使用叶子节点反而会引入噪音。(2)leetcode 上的代码所使用的变量名仅仅起一个命名的作用并没有语义表示的功能,更多的是采用a、b、temp 等不携带语义信息的单词作为变量名。AST的生成工具使用的是srcml(https://www.srcml.org/),该工具不检查代码的正确性,因此即使编译不能通过的代码也能生成AST,提高了模型的容错性。在代码分类以及相似代码搜索的任务中所使用的代码都是C/C++编写的,而srcml 用来表示这两种语言所定义的节点只有60 个,加入叶子节点后词汇表的大小将扩充至上万,因此不使用叶子节点将大大提高模型的收敛速度。
图1展示了整个词向量的训练过程。选取节点b作为当前节点,向上探测寻找祖先节点的深度设置为1,向下探测子孙节点的深度设置为2,因此得到祖先节点情境信息a,兄弟节点情境信息c,以及子孙节点情境信息(d,e,f,g,h),将这三类情境节点合并得到(a,c,d,e,f,g,h)作为节点b的情境信息。在模型的训练过程中,首先使用正态分布对词汇表矩阵进行初始化,得到矩阵D∈Rn×f,其中n表示词汇表的大小,f表示词向量的维度。模型的输入分为两部分,情境节点以及当前节点在词汇表中的索引,通过查找词汇表可以得到情境节点以及当前节点的词向量表示,分别对应图1中的context embedding以及current vector,之后context embedding 经过两层全连接神经网络得到变换后的情境向量context vector,使用交叉熵作为损失函数,Adam作为优化器进行梯度下降。为了使生成的context vector 能够与current vector进行交叉熵运算,输出层输出向量的维度与词汇表中向量的维度相同。整个计算过程的数学公式如下:
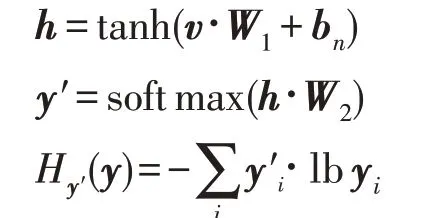
其中,v∈R1×f表示情境向量,h表示经过隐层后得到的输出向量,W1∈Rf×k是隐层的权值矩阵,用来将维度是f的向量映射成k维向量,b∈R1×k是隐层网络的偏置项。W2∈Rk×v是输出层的权值矩阵,y′∈R1×v是输出层的输出向量,y∈R1×v是当前节点的词向量,表示向量y′在第i个维度上的值,yi同理。
1.2 基于卷积和循环神经网络的CVRNN模型
1.2.1 AST切割
为了防止AST 规模过大,带来梯度消失问题。并未直接将AST 作为模型的输入,而是先将AST 进行切割,得到AST的子树序列输入到模型之中,详细步骤如下。
首先,定义一个用于存储AST 分裂节点的集合S={if,while,for,function,unit}。其中“if”用来提取条件子树,“while”“for”用于提取循环子树,“function”用来提取方法体子树,“unit”是未切割前AST的根节点,AST 剩余的节点都在“unit”子树上,如下展示了具体的切割算法:
算法1split AST

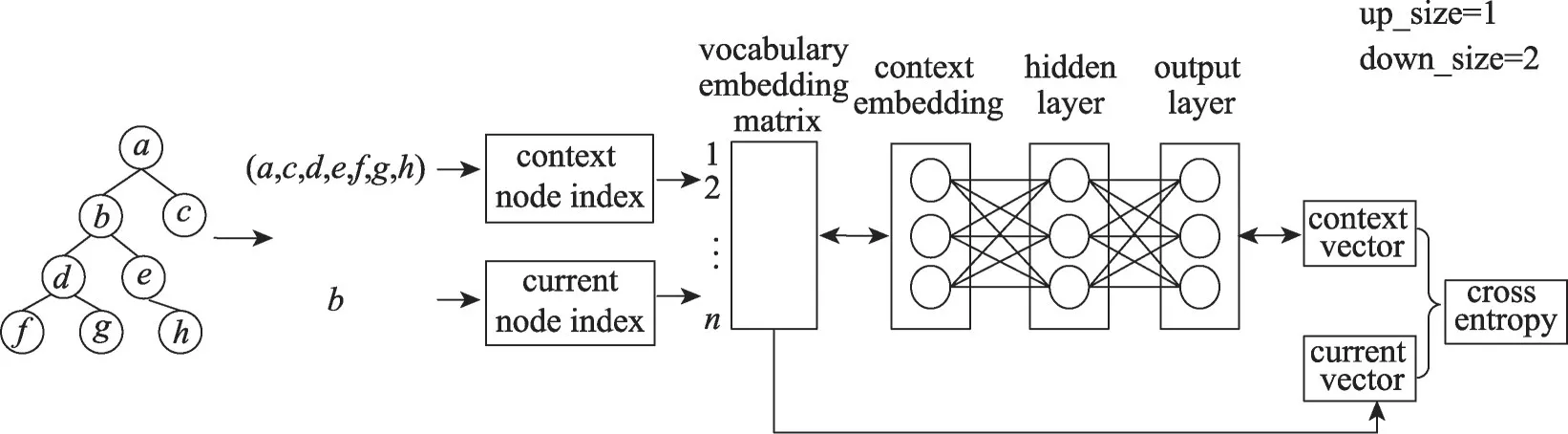
Fig.1 Node embedding training model图1 词向量训练模型

该算法以AST的根节点作为输入。首先用根节点初始化一个数组T,然后通过深度优先遍历获得节点序列N,对N中的节点进行遍历,若节点属于集合{function,if,while,for},该节点连同其子节点将会被切割取出存储到T中。值得注意的是,当出现嵌套的情况,例如“if”子树中还包含“for”子树,“for”子树将会从“if”子树上提前切割下来,因为深度优先遍历将先访问“for”再访问“if”节点,两个独立的子树根节点将按序存储到T中。
1.2.2 卷积以及循环神经网络模型
在介绍CVRNN 模型之前,先详细地阐述一下Mou 等人[12]提出的基于树的卷积神经网络TBCNN。图2 展示了该模型执行的具体流程。首先应用词嵌入技术将AST中的节点转化成向量表示,不同的是,该方法只使用了被表示节点的孩子节点作为情境,没有考虑到兄弟节点以及祖先节点的信息,具体的词嵌入公式如下:
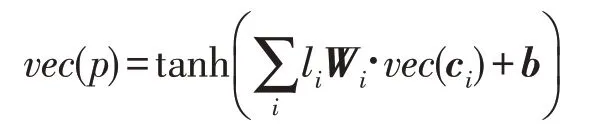
其中,p表示双亲节点,ci表示p的第i个孩子节点,Wi是ci的权值矩阵,(孙子节点的数目除以孩子节点的数目)是系数,b是偏置项。然后通过设置一个固定深度的滑动窗口遍历整个AST,再引入最大池化得到一个形状与原先一样的AST,接着使用动态池化[25]以及两层全连接神经网络得到最终的代码向量。图3 展示了CVRNN 的模型架构,以下是该模型的算法执行逻辑:
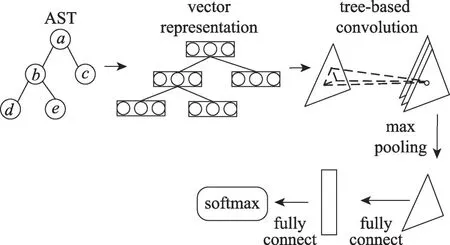
Fig.2 TBCNN model图2 TBCNN模型
首先根据1.1 节得到的词向量表将AST 中的节点表示为向量,再使用TBCNN模型对AST进行卷积得到编码后的向量,然后使用双向循环神经网络并以LSTM 作为神经元对得到的向量序列进行编码以提取代码的序列信息。标准的循环神经网络(recurrent neural network,RNN)是单向的,其编码受限于过去的信息,采用双向RNN 则能够同时使用过去和未来两个方向的信息。在后面的实验中,将会对这两种不同的策略进行对比。给定一棵代码的AST,假设该AST 被切割成n棵子树,这些子树经过TBCNN编码后将得到一个向量序列TV∈Rn×k,k表示向量的维度,n表示子树的数目。在某个时间步t,LSTM的计算公式如下:
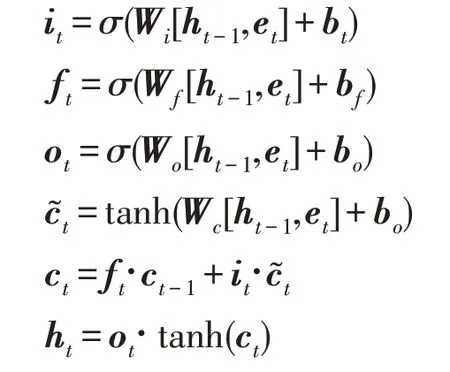
其中,σ是sigmoid 激活函数,ct表示新状态,ht∈R1×m表示输出向量,由当前时间步两个方向的向量拼接而成的向量,Wi、Wf、Wo是权值矩阵,bt、bf、bo是偏置项。it表示输入门,决定et中哪一部分将被保留添加到ct中,ft表示遗忘门,决定et的哪一部分将被遗忘,ot是输出门用来计算输出向量。整个双向RNN的计算可以形式化如下:
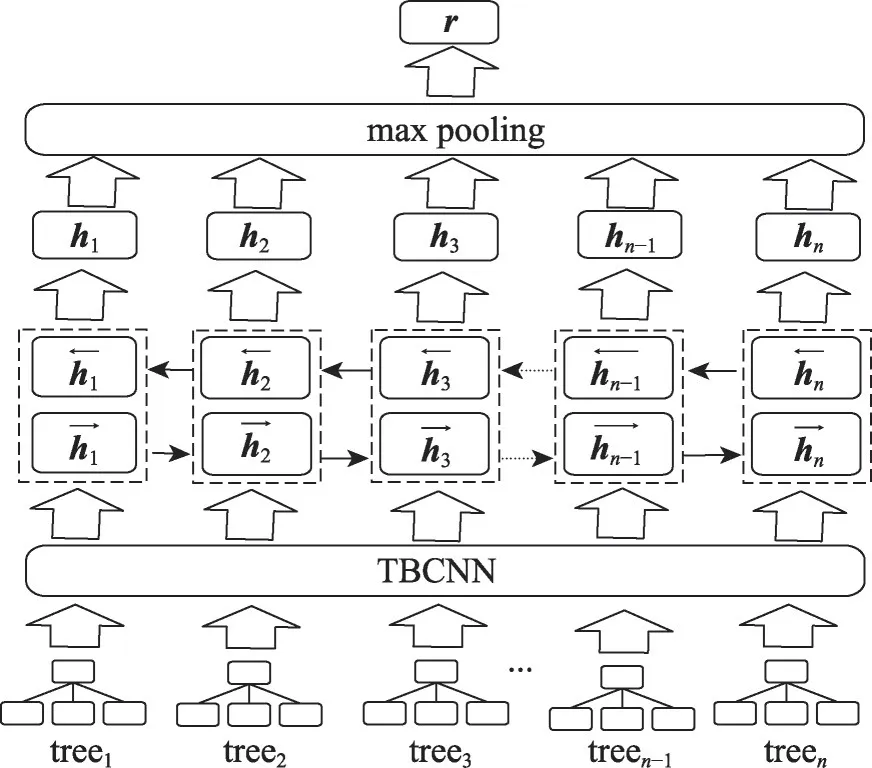
Fig.3 CVRNN model图3 CVRNN模型
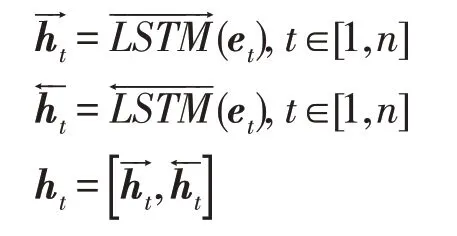
至此,每棵子树将会被转化成一个向量b∈R1×2m。这些向量将会被存放到一个矩阵BV∈Rn×2m中,考虑到不同的子树的重要程度可能不同,例如“if”代码块中的语句要多于“for”代码块中的语句,直观上该“if”子树所携带的信息将高于“for”子树,采用均值池化则两个代码块所赋予的权值相同,因此该模型使用最大池化得到代码向量r∈R1×2m,而没有选择均值池化。
算法2CVRNN

2 验证模型
这部分主要介绍两个基于CVRNN 的具体的应用模型,代码分类模型以及相似代码搜索模型,而相似代码搜索模型所使用的编码器是经过代码分类任务训练之后得到的CVRNN。
2.1 代码分类模型
代码分类所使用的数据集是Mou 等人[12]构建的104 数据集。原始数据集共包含52 000 条数据。训练数据是随机从中抽取的51 000 条数据,剩余的1 000 条作为验证数据,来监控训练过程中是否发生过拟合。
代码分类模型如图4 所示,经过CVRNN 的编码,任意代码段都能转换成一个固定长度的向量表示r,为了使模型适配104 代码分类任务,在该模型的基础之上再添加了一层全连接网络,将r映射成维度是104的向量r′。使用one-hot方法生成每个代码的标记向量l,l的维度104,若代码属于第5类,则l位置5 上的值为1,其余位置为0。选取交叉熵作为损失函数,使用Adam作为优化器。
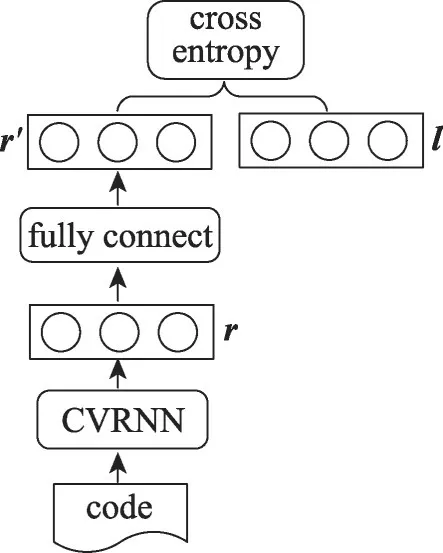
Fig.4 Code classification图4 代码分类
2.2 相似代码搜索模型
相似代码搜索使用的数据集来源于leetcode,没有在实际生产环境中去寻找功能相似的代码的原因是这种人为的筛选方式具有很强的主观性,功能划分的粒度很难把握。比如同样是一个排序代码,一个使用快速排序实现,另一个使用归并排序实现,很难判定两个是否是同一个类别。而使用leetcode 编程网站上同一个题目的不同题解作为判断功能是否相似是一个很客观的标准。为了保证功能绝对一致,每个题解都输入到在线的IDE(integrated development environment)中进行了测试,该网站会提供几百到上千个测试用例,所筛选得到的题解能通过全部的测试用例。选择其中一个题解用作查询,另一个用作匹配对象放入数据库中,该数据库对应图5中的正样本。在真实环境下,数据库中会包含更多的代码,因此,为了使相似代码搜索任务更贴近真实环境,该实验对代码的搜索空间进行了扩充。使用了104 数据集中的52 000 条数据作为负样本加入到待搜索的数据库中。
图5左边是代码向量的生成过程,应用训练好的CVRNN模型对数据库中的代码进行编码,最后将代码向量存放到一个数据库中。图5 右边是代码查询的过程,模型的输入是一个用作查询的题解,经过CVRNN 编码后得到代码向量。借助Facebook 所提供的faiss[26]工具将数据库中的代码向量基于与查询向量之间的欧式距离进行排序,选择前10 个搜索结果作为结果统计样本。因为在搜索时,数据库中的代码都已经是向量的形式,所以搜索时间很快,时间可以忽略不计,在普通笔记本上的搜索时间小于2 ms。
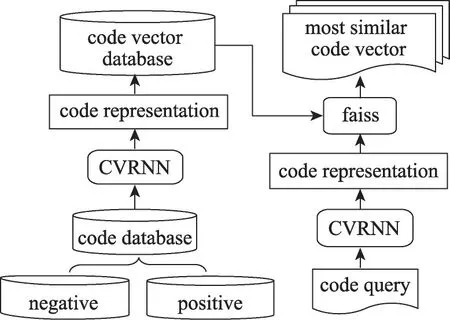
Fig.5 Similar code search图5 相似代码搜索
3 实验评估
本章将基于4 个研究问题对CVRNN 模型的性能进行评估。
(1)CVRNN模型在分类任务上的效果如何?
(2)CVRNN生成的代码向量是否满足相似度越高,彼此之间的几何距离就越短的性质?
(3)CVRNN在相似代码搜索任务上的实验结果如何?
(4)CVRNN预训练词向量以及双向RNN模块对模型产生怎样的影响?
3.1 对比模型
TBCNN是第一个用于处理104代码分类任务的深度学习模型。前文已经详细介绍过TBCNN 模型的执行流程。因为TBCNN模型内嵌在CVRNN模型之中,为了对比的公平性,在实验过程中,TBCNN与CVRNN 中使用的TBCNN 在参数配置上完全相同,卷积层的数目、卷积维度都相同。在相似代码搜索任务中,TBCNN 模型生成的代码向量对应图2 中倒数第二个全连接神经网络的输出向量,维度是400。
ASTNN模型是当下在104分类任务上取得最好结果的模型。该模型与CVRNN 模型的主要区别就是对AST序列进行编码的方法不同。该模型主要采用如下公式对AST中的节点进行自下而上的编码:
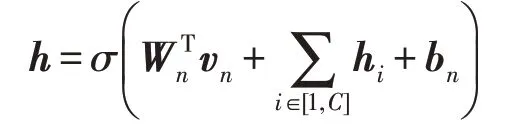
其中,h表示当前节点更新后的状态,Wn是权值矩阵,是Wn的转置矩阵,vn表示当前节点的初始化词向量,hi表示当前节点第i个孩子节点的状态,C表示当前节点孩子节点的数目,bn是偏置项。然后对AST中的所有节点使用最大池化获得AST的向量表示。接着将得到的AST 向量序列输入到双向RNN 中,再经过最大池化得到整棵AST 的向量表示。因为CVRNN也使用双向RNN来提取代码的序列信息,为了对比的公平性,ASTNN、CVRNN均使用LSTM作为神经元,且隐层单元都设置为200,因此两个时间方向拼接之后得到的代码向量维度也都是400。
为了对比公平,CVRNN、TBCNN、ASTNN 共享同一张预训练词向量表。除了深度学习模型,CVRNN模型还与3个业界常用的相似代码检测工具进行了对比,分别是moss(measure of software similarity)(https://theory.stanford.edu/~aiken/moss/)[27]、jplag(https://jplag.ipd.kit.edu/)以及sim(https://dickgrune.com/Programs/similarity_tester/)。moss是斯坦福开发的利用文件指纹技术来确定程序相似性的系统。jplag 以程序覆盖率作为代码相似的度量指标,在覆盖的过程中,代码被分为多个相似的片段,通过计算平均覆盖率和最大覆盖率作为最终代码相似度的值。sim 主要根据代码所使用的词汇来计算代码之间的相似度,该工具广泛应用于检查大型软件项目中的重复代码。此外数据还被部署在一个开源的代码搜索引擎search code(https://github.com/boyter/searchcode-server)上进行测试,该搜索引擎也是以代码作为查询语句在数据库中搜索相似的代码,然而所有反馈结果都是0,因此没有在后面的实验结果统计表中列出。
3.2 度量指标
在代码分类任务中,仅选取准确率作为度量指标。在相似代码搜索中,应用以下3个在搜索领域广泛使用的度量指标来衡量搜索结果:
(1)top(k)
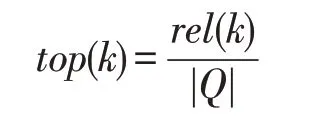
式中,Q表示查询样本,|Q|表示查询样本的数目,若前k个候选样本中有一个与查询匹配,则认为该查询命中结果,rel(k)表示命中的查询样本的数目。
(2)MRR(mean reciprocal rank)
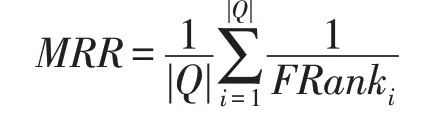
式中,FRanki表示第i个样本第一个命中的位置,Q以及|Q|的定义同上。
(3)NDCG(normalized discounted cumulative gain)
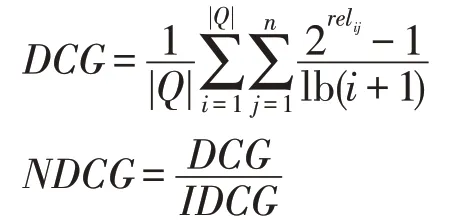
式中,n表示为限定反馈数目所设置的阈值,默认为10。relij表示第j个候选样本与查询样本i的相关程度,在相似代码搜索任务中,若候选样本与查询样本匹配则值为1,反之为0。Q以及|Q|的定义同上。IDCG(idea discounted cumulative gain)表示DCG的最优计算结果,假设n为5,前5个搜索结果与查询样本的相关程度分别为(0,0,1,0,0),则使用(1,0,0,0,0)计算IDCG的值,(0,0,1,0,0)计算DCG的值,以此得到NDCG的值。
3.3 实验结果
研究问题1CVRNN 模型在分类任务上的效果如何?
图6 展示了经过每一轮训练之后,3 个深度学习模型在验证集上的分类准确率。可以看出CVRNN模型相对于其他两个模型收敛速度更快,经过1轮训练之后,CVRNN模型分类的精度就达到了76.5%,而ASTNN 以及TBCNN 则分别是45.2%和65.0%(对应图6 纵轴的截距)。经过30 轮训练之后,CVRNN 模型的分类精度达到94.4%,而ASTNN以及TBCNN则分别是90.7%和80.9%。在这30轮的训练过程中,可以看出,CVRNN的每一轮的验证精度均高于另外两个深度学习模型。因此,CVRNN在代码分类任务上对比这两个深度学习模型有明显的优势。
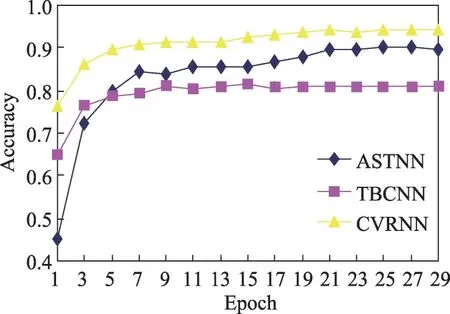
Fig.6 Valid accuracy of three deep learning models in each epoch图6 3个深度学习模型每训练一轮的验证精度
研究问题2 生成的代码向量是否满足相似度越高,彼此之间的几何距离就越短的性质?
图7 为leetcode上100 个问答对生成的代码向量使用TSNE(t-distributed stochastic neighbor embedding)方法降维打印后的图片,可以看出很多问答对生成的代码向量之间的距离很近,因此也回答了研究问题2,使用CVRNN模型可以将功能相似的代码向量聚集在一起,相似度越高,彼此之间的几何距离就越短。

Fig.7 leetcode code vector图7 leetcode代码向量
研究问题3 CVRNN 在相似代码搜索任务上的实验结果如何?
表1 展示了各个模型在相似代码搜索上的实验精度,3个深度学习均采用第30轮训练结束之后的编码器。在使用jplag 模型进行测试时,本文统计了该模型由平均相似度以及最大相似度分别得到的实验结果。实验结果表明:深度学习模型的实验效果相对于3 个传统的相似度检测工具有明显的优势,CVRNN 在各项度量指标上均高于其他任何一个模型。尽管在分类精度上TBCNN 要劣于ASTNN,ASTNN 要高出9.8 个百分点,然而除了Top1 二者的精度相等之外,TBCNN 其他几项的精度均高于ASTNN。这说明,尽管可以借助代码分类任务训练编码器,然而模型在两个任务上的性能并不是正相关的,即在代码分类任务上精度越高并不代表相似代码搜索的效果越好,然而从表1 以及图6 可以看出,CVRNN模型在两个任务上的效果都是最优的。
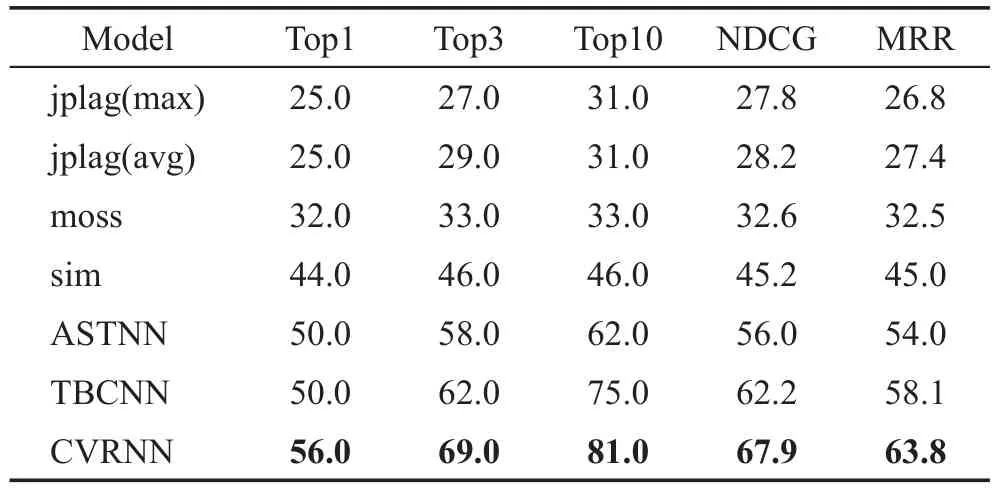
Table 1 Similar code search accuracy表1 相似代码搜索准确率 %
研究问题4CVRNN 预训练词向量以及双向RNN模块对模型产生怎样的影响?
定义如下4个模型:
模型1(without biRNN)将双向RNN直接从模型移除。
模型2(RNN)将双向RNN替换成双层单向RNN。
模型3(random)使用正态分布随机初始化词向量。
模型4(CVRNN)默认配置,使用双向RNN以及预训练的词向量。
模型1直接将双向RNN移除,表示整个CVRNN模型将不提取代码的序列信息,而模型2将双向RNN替换成双层单向RNN则表示削弱模型提取序列信息的能力。表2 展示了各个模型在代码分类上取得的精度,可以看出模型1在失去提取代码序列信息模块之后,分类精度直接从94.4%降到了73.8%,对比模型2的92.5%有很大的差距。表3展示了各个模型在相似代码搜索任务上的结果,可以发现,模型1 虽然在失去提取序列信息的模块之后在代码分类任务上要明显逊色于模型2,在相似代码搜索各项度量指标上的值却都高于模型2,该结果也与问题3 得到的结论相符合,模型在代码分类以及相似代码搜索上的性能并不是成正相关的。从表2以及表3可以看出,模型4 在两个任务上的性能都要高于模型1 和模型2。图8展示了模型3以及模型4在训练过程中每一轮在验证集上的分类精度。可以看出使用预训练词向量的模型4将收敛得更快,经过第一轮训练之后,模型3的分类精度为72.00%,而模型4精度能达到76.50%。并且在每一个训练轮次之中,使用预训练向量的模型都有更高的精度,使用预训练词向量的模型4最终达到94.4%的分类精度,而随机初始化词向量的模型最终的分类精度是91.4%。从表3 也可以看出,预训练词向量对提升相似代码搜索的性能也有贡献。
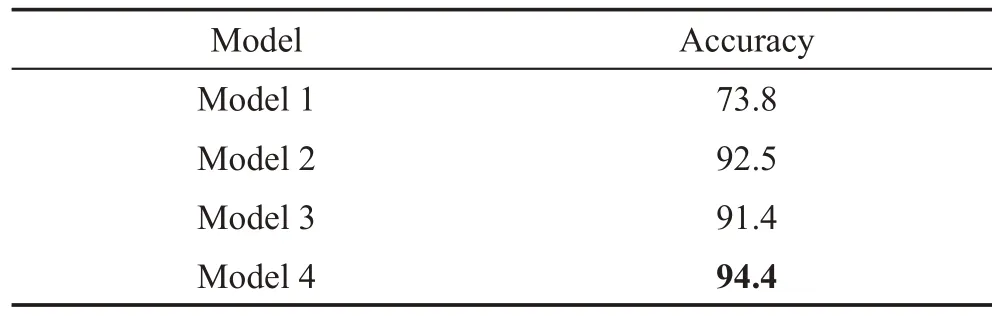
Table 2 CVRNN ablation research in code classification表2 CVRNN代码分类消融实验 %
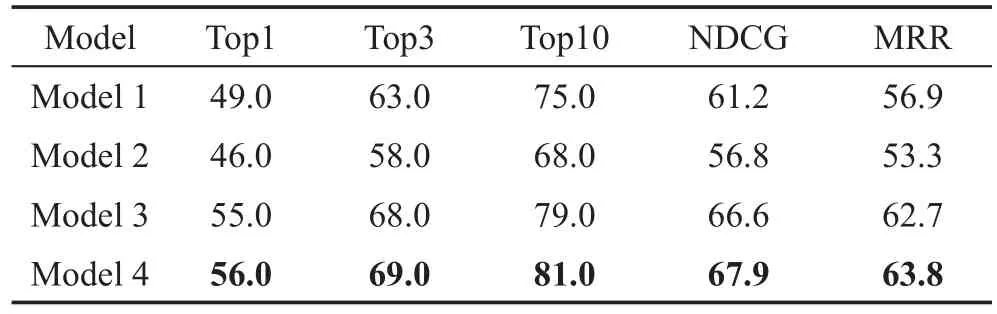
Table 3 CVRNN ablation research in similar code search表3 CVRNN相似代码搜索消融实验 %
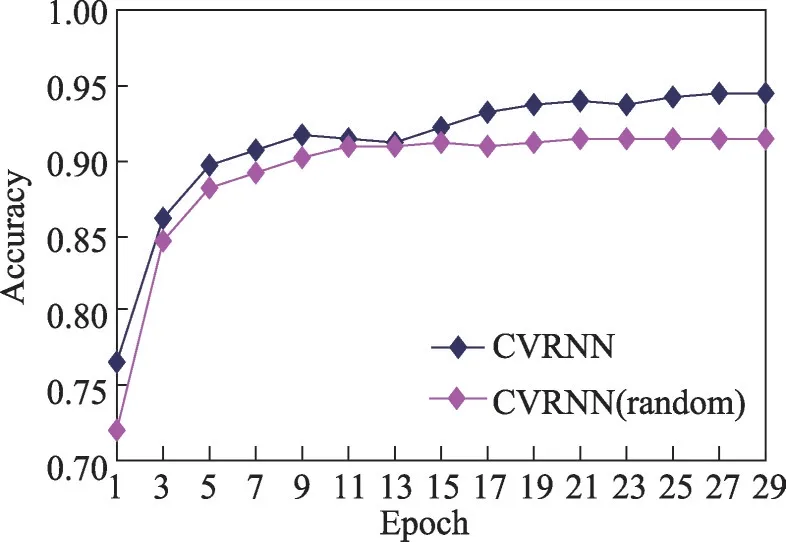
Fig.8 Valid accuracy comparison between random initializing node embedding and pre-training embedding in each epoch图8 随机初始化词向量以及使用预训练词向量每一轮验证精度对比
4 相关工作
如何对代码进行表示一直是软件工程领域研究的一个重要的问题。
传统的信息检索以及机器学习方法主要将代码作为纯文本进行处理。输入到模型之中的是一个被规范化处理好的标志符序列[2],SourcererCC[3]在此基础上增强了对代码语义的挖掘,使用一种反向索引(inverted index)技术对标志符的序列信息进行挖掘。与SourcererCC不同的是,Deckard[28]模型选择增强对代码结构信息的挖掘,在输入的数据中加入了代码的语法结构信息。
不少研究人员借助AST所提供的代码元素之间的依赖关系来增强对代码信息的提取。例如:Zhou等人[7]借助AST 来扩充方法体内部元素的情境信息以增强代码段的语义,提高注释生成的效果。Yan等人[29]应用类似方法进行代码推荐工作。除了借助AST 扩充代码元素语义之外,更多的模型选择将AST整体或切分后得到的子结构序列输入到模型之中。例如:Hu 等人[8]就通过添加括号的方式来限定AST 中节点的作用域,将AST 转化成一个节点序列来生成代码对应的注释;Alon 等人[10]借助函数体的AST 路径来生成相应的函数名;White 等人[9]则分别根据代码的标志符序列以及AST节点序列得到代码的语义向量和结构向量,根据这两个向量对代码克隆检测展开研究。
然而这些借助AST的方法都是将树形结构转化为一维的序列结构,破坏了元素之间的依赖关系。因此,部分学者提出了不降维而直接处理AST 的树形深度学习模型。与White 的方法类似,Wan 等人[11]也将代码分为两部分作为输入,使用RNN 对代码的标志符序列进行编码得到语义向量;不同的是,Wan等人使用Tree-LSTM模型[30]去处理AST,而并没有简单地通过将AST转化成节点序列的方式得到代码的结构向量。Wei 等人[31]同样使用Tree-LSTM 对克隆检测展开研究。Mou 等人[12]提出了一种基于树的卷积神经网络模型TBCNN,该模型直接在AST上进行卷积计算,然后使用动态池化技术将不同规格的AST 压缩成代码向量,该向量能够很好地提取代码中的结构信息,在104 类代码分类任务上能够达到94%的精度。为了解决上述树神经网络的问题,一种方法就是获得代码的控制流图以及数据依赖图,静态地建立节点与节点之间的联系,将代码表示成一种图的数据结构,最终使用图嵌入技术[32]对代码进行表示。例如Allamanis等人[33]就通过相同的函数名以及变量名来静态地建立这些函数以及变量之间存在的依赖关系,Tufano等人[34]则直接构建程序的控制流图来补充节点之间的控制关系。然而程序中元素的依赖关系往往要借助编译后代码的中间表示或者字节码才能得到[35]。在现实环境中,很多代码不能够被编译,因此这些方法所适用的范围将会受到很大的限制,而且代码图结构的定义以及对于图特征的提取也十分依赖专家的领域知识,模型往往很复杂,设计代价较高。
对比这些工作,本文的工作集中于借助AST 对代码的结构以及序列信息进行提取。此外本文提出了一种新的获得代码向量的方法,该方法不使用完整的训练好的代码分类模型,仅截取模型中的一部分来生成代码向量,得到的代码向量可满足功能越相似,几何距离就越短的性质。
5 结论
本文提出了一个基于卷积以及循环神经网络的自动代码特征提取模型CVRNN。通过对已经标记类别的代码训练编码器,编码器将自动地学会如何提取代码特征,对比当下两个前沿的代码分类模型有显著的优势,在此过程中嵌入的预训练词向量不仅能提高分类的精度,更能够加快整个模型的拟合速度。在相似代码搜索任务上,CVRNN无论是对比近几年提出的前沿的深度学习模型还是广泛应用于业界的代码相似度检测工具都有显著的优势。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
新高考·高一数学(2022年3期)2022-04-28
现代电子技术(2022年4期)2022-02-21
计算机应用与软件(2021年10期)2021-10-15
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
高中生学习·高三版(2016年9期)2016-05-14
