
基于知识库的政务数据质量评价
2021-03-11 03:35:08骆文辉陈钢毛建水新莹
电子技术与软件工程 2021年21期
骆文辉 陈钢 毛建 水新莹
(长三角信息智能创新研究院 安徽省芜湖市 241000)
1 引言
政府在大数据时代扮演重要角色,政府既是大数据的生产者,也是大数据的消费者。国务院印发的《促进大数据发展行动纲要》指出,大数据已成为“提升政府治理能力的新途径”。从狭义上说,政务大数据是指政府为履行职能在业务开展过程中所拥有、产生和管理的数据,通常源自于城市管理和公共服务,如社保数据、税务数据、教育数据等。从广义上说,政务大数据是政府将自身的业务数据和收集的外部社会数据进行汇聚、融合和治理后形成[1],是政府部门权力和责任在政务服务领域的应用实践。
俗话说:“垃圾数据进,垃圾数据出”。数据质量是政务大数据的重中之重,事关提升城市治理能力的最终成效。科学的数据质量评价体系不但能够提升政务大数据的可用性,而且还能为有效分析数据、反哺数据提供便利。为了能够让政务大数据解决更多业务问题,在理想情况下数据维度越多越好,数据准确性越高越好。基于此,本文探讨如何通过构建知识库从数据目录、数据项和数据值这三个不同层次来对政务大数据进行质量评价。
2 评价模型
2.1 数据指标知识库
智慧城市所服务的主体是自然人和法人,城市大数据的核心是关于自然人和法人的数据。因此,有必要建立一个能够全面描述自然人和法人且能够反映其历史状态变化的数据体系。虽然有些省市制定了市民信息和企业信息的地方标准(如贵州制定了人口基础数据和法人单位基础数据标准),但我国当前没有完善的自然人和法人数据体系标准,在各类涉人和涉企的信息系统建设中没有考虑全生命周期特征,无法形成全维度、跨层级、跨系统、跨部门、跨业务的数据指标体系[2]。基于此,本文利用自然语言处理技术,结合多个城市政务服务网站数据,形成数据指标知识库,包括数据目录、数据项和数据来源部门。
2.2 知识库构建方法
根据《2021 省级政府和重点城市网上政务服务能力调查评估报告》[3],选取一体化政务服务能力较高的10 个重点城市(深圳、广州、南京、杭州、宁波、合肥、青岛、武汉、哈尔滨、南昌)的政务服务网站作为数据指标知识库形成的来源。数据指标体系主要包括四个部分:权力清单与政务服务目录匹配、自然人和法人事件构建,政务服务目录与事件匹配和目录数据项构建。
2.2.1 来源部门构建
首先,对中文RoBERTa 预训练语言模型采用政务领域语料库进行无监督训练,获取拥有政务领域知识的RoBERTa 预训练语言模型。其次,使用政务领域知识的RoBERTa 预训练语言模型对政务服务清单文本和权力清单文本进行语义提取,得到政务服务清单文本词向量和权力清单文本词向量。最后,计算服务清单文本词向量和权力清单文本词向量的余弦相似度,选取相似度最高的文本进行匹配,形成来源部门。
2.2.2 数据目录构建
首先,获取上述10 个城市政务服务网中个人办事和法人办事的网页数据。使用xpath 和BeautifulSoup 以及JSON 数据解析方法对网页进行数据清洗和相关数据的数据提取,提取出对应的自然人事件和法人事件。将提取的数据进行规整,通过pymysql 技术连接到本地MySQL 数据库,将规整后的数据存入数据库中。运用词向量计算文本相似度,设定指定阈值,对相似自然人事件和法人事件进行融合,形成数据目录。
2.2.3 数据项构建
首先,获取10 个城市办事结果表格、证书图片等。对表格数据直接处理得到目录对应的数据项;对证书图片应用OCR 算法进行文本提取,获取具体文本后再进行文本处理获取数据项,具体算法如下:
Step1.使用卷积神经网络(VGG、ResNet、DenseNet 等)作为特征提取网络,提取事项申请材料(证照)图片中信息生成特征图;
Step2.使用文本检测模型(Faster-RCNN、RRPN、CTPN、TextBoxes 等)处理特征图定位到文字框;
Step3.使用CRNN+CTC、CNN+RNN+Attention 或CNN+Seq2Seq+Attention 模型实现对文字框中的文字内容识别。
Step4.文字内容进行数据清洗,并过滤掉与业务事项相关性弱的数据项,保留核心数据项。
Step5.将数据项按照数据目标进行组合,形成数据项标准。
在完成数据目录、数据项和来源部门构建后,数据指标知识库就构建完成了,以此对政务数据按数据目录、数据项和来源部门进行匹配和识别。该方法基于词向量计算相似度,若相似度超过指定阈值,则认为数据目录或数据项或来源部门匹配成功。
3 数据质量评价方法
3.1 评价流程
基于数据指标知识库对政务数据质量的评价流程如下:
3.1.1 确定评价对象
以数据指标知识库为基础,对政务数据按数据目录进行识别(基于词向量计算相似度,若相似度超过指定阈值,则认为数据目录匹配成功),把在数据指标知识库覆盖范围内的数据目录及其数据项作为质量评价的对象。
3.1.2 确定评价指标
对于数据目录、数据项和来源部门而言,以覆盖率作为评价指标。对于数据值而言,根据《GB/T 36344-2018 信息技术数据质量评价指标》[4],选取选取规范性、完整性、准确性、一致性、时效性和可访问性作为评价指标。
3.1.3 确立每个评价维度权重
政务数据质量最终取决于两个因素:覆盖率和数据值质量。在实际操作中,可以按照“均等权重”来设置,也可根据实际需要来设置权重。本文主要采取“均等权重”来计算。
3.1.4 计算分值
基于数据质量的各个评价维度,运用内置度量规则和检核方法对对政务大数据进行多角度分析计算,得出每个评价维度下的分值。
3.1.5 结果输出
输出分析结果及评价报告,给出政务数据质量提升建议。
3.2 覆盖率评价
对于数据目录、数据项和来源部门进行覆盖率评价,不但可以清楚地了解地市政务服务事项覆盖度,还有助于精确定位问题数据产生的源头部门,给出问题数据的所属分类及解决办法,以数据质量工单的方式反馈源头部门。在覆盖率评价时,政务数据目录、数据项和来源部门命名可能与数据指标知识库存在差异,为此需要判断名称之间的相似度。本文采用word2vec 模型将词向量化,比较两个词(短文本)的相似度,设置相似度阈值,规定大于阈值的两词具有一致的语义,如图1所示。
图1:基于词向量的相似性检测
覆盖率评价公式如下所示:
数据目录覆盖率 = 匹配成功的数据目录÷数据指标知识库中数据目录的数量×100%
数据项覆盖率 = 匹配成功的数据项÷数据指标知识库中数据目录中数据项的数量×100%
部门覆盖率 = 匹配成功的部门÷数据指标知识库中数据目录中部门的数量×100%
3.3 数据值评价
《GB/T 36344-2018》定义了共计20 个二级评价指标。基于可实现角度考虑,方案选取其中12 个二级评价指标设置具体规则(R代表规则)。
3.3.1 规范性
规范性是待评价数据集中各数据项的名称、描述、类型值域等内容必须符合元数据定义的度量。
R1:数据目录和数据项具有可理解的中文注释。
3.3.2 完整性
完整性是待评价的数据集中数据元素应被赋值的程度。
R2:按配置表来检测表数据,首先根据表名查询数据总量,记录下来,第二天在查询同一个数据库,检测数据总量并与昨日数据量进行相减,若差值小于指定阈值,则认为数据完整,否则,认为该表数据不完整。
3.3.3 准确性
准确性是待评价数据元素与期望的数据元素之间的真实程度,即待评价数据元素是否错误或异常。准确性指的是数据合规性、数据重复率和数据唯一性。数据合规性主要检查待评价数据的数据格式包括数据类型、数值范围、数据长度、精度等是否满足预期要求。数据重复率主要评价数据集中数据元素意外重复的度量。数据唯一性是指特定数据项、数据元素唯一性的度量。
R3:待评价数据集中各数据项必须对应指定数据项类型,如姓名必须varchar 格式,日期数据项可以为date 或varchar 格式。
R4:待评价数据集中各数据项必须在正确值域内取值。
R5:待评价数据集汇总各数据项的数据精度不得过长,必须符合给定配置表规则的长度和数据类型。
R6:根据配置表规则,选中指定数据目录、指定数据项进行重复率检测,数据集中不出现两行所有属性都一样的数据,即认为是数据集非重复。
R7:根据配置表规则,一个表中指定数据项中的每个数据必须唯一。
3.3.4 一致性
一致性是用于描述数据与数据之间在某一特定条件下满足某一相同的条件或状态。一致性指标包括相同数据一致性和关联数据一致性。
R8:根据指定配置表规则,找出同一部门同一类业务数据之间的一致性,即同部门数据表之间相同或关联数据项必须一致。
R9:单个数据目录中一致性约束规则检查关联数据的一致性。如根据身份证数据项可以关联到年龄、籍贯、性别、出生日期等数据项。
3.3.5 时效性
时效性是按照业务规则,数据在时间变化中的正确程度。时效性指标包括基于时间段的正确性、基于时间点的及时性和时序性。本文仅评价基于时间段的正确性和基于时间点的及时性。
越南当地时间11月22日上午9点30分(北京时间10点30分),“2018香港古董车滇越行”在越南海防正式发车,8辆世界级古董车从这里开启了从大海出发到达云贵高原世界之“滇”昆明的旅程。
R10:基于时间戳的记录数、频率分布或延迟时间符合业务需求的程度。根据配置表规则,查询指定业务表中指定业务时间数据项的最大值,计算该值与计算时间(当天)的差值,将差值与阈值进行比较,若小于阈值,则认为该表数据及时。
R11:基于时间段的正确性:基于日期范围的记录数或频率分布符合业务需求的程度。根据配置表规则,查询指定业务表中指定业务时间数据项的取值范围,然后计算该取值范围在指定阈值中的符合程度。
3.3.6 可访问性
可访问性是数据能被访问的程度。
R12:在获取数据记录时是否如期返回所有数据项值。获取数据日志,根据日志进行打分。
3.4 分值计算
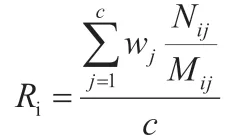
其中Ri为第i 个指标的评价结果,c 为指标i 对应的评价规则总数(在本文中为c 为12),wj为指标i 各规则的权重;Nij为数据集上符合第i 个指标的第j 条规则的数据记录数或数据元素数;Mij为总数据记录数或数据元素数。数据值数据质量综合评价的得分计算公式为:
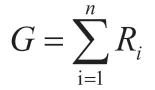
假设某个政府部门有N 张数据表,每张数据表数据质量得分为Gi,则该部门数据值质量平均得分为:
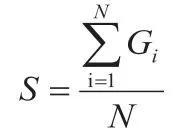
4 实例分析
4.1 测评对象
选择某地市494 个数据目录、9655 个数据项所产生的67843797 条实体数据作为数据质量测评对象。根据某地市政府权力清单和责任清单,这些数据来自19 个部门。
4.2 总体质量评价
4.2.1 覆盖率质量得分
在实际评价过程中,对于数据目录覆盖率、数据项覆盖率和部门覆盖率赋予同等权重。
覆盖率得分 = 数据目录覆盖率分值86.43×33.33% +数据项覆盖率分值69.16×33.33% +部门覆盖率分值76.00×33.34% = 77.20
4.2.2 数据值质量得分
在实际评价过程中,对于准确性、完整性、一致性、时效性、规范性和可访问性赋予同等权重。
数据值质量得分 = 准确性分值77.12×16.66% + 完整性分值79.81×16.66% + 一致性分值89.76×16.66% + 时效性分值99.99×16.66% + 规范性得分 89.71×16.66% + 可访问性得分97.35×16.70% = 88.96
4.3 部门质量状况
表1展示了4 个典型部门的数据目录和数据项覆盖率情况及相应的数据值问题率。可以看出,有些部门的数据目录覆盖率和数据项覆盖率都比较好,但相应的数据值问题率比较高。有些部门虽然目录覆盖率达到了100%,但目录中的数据项较为匮乏,由于数据项较少的原因,其数据值问题率也较低。图2展示了部门D 部分数据项的错误率情况。
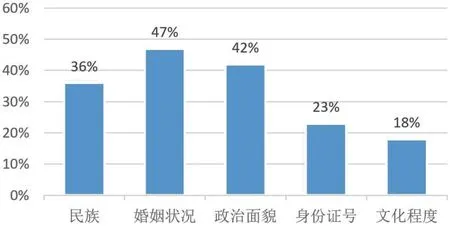
图2:部门D 部分数据项的错误率情况
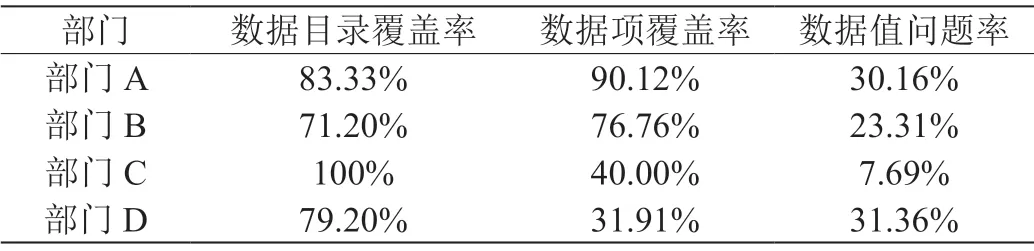
表1:部分部门数据质量状况概览
5 结语
通过完成政务数据质量评价,加强数据质量与数据应用之间的联结,驱动地市政府完善并修正相关数据目录、数据项和数据值。与此同时,输出可理解性和可操作性较强的数据质量评价报告,提升政府领导对数据质量的感知度。随着政务大数据不断完善,不但能够满足单一政府部门业务的需要,还能够满足“三融五跨”的要求,真正实现基于数据的业务协同。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
今日农业(2021年21期)2021-11-26 05:07:00
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
制造技术与机床(2019年6期)2019-06-25 10:17:46
中国交通信息化(2016年9期)2016-06-06 07:42:23
西南交通大学学报(2016年6期)2016-05-04 04:13:05
图书馆研究(2015年5期)2015-12-07 04:05:48
计算机工程(2014年6期)2014-02-28 01:28:03
