
智能机器的认知学习机理及计算模型研究
2021-03-11 03:34吴丽华龙海侠冯建平
电子技术与软件工程 2021年21期
吴丽华 龙海侠 冯建平
(海南师范大学 海南省海口市 571158)
1 机器学习及背景
学习是人类具有的一种重要智能行为,机器学习(ML, Machine Learnning)是研究如何使用机器来模拟人类学习活动的一门学科,它研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能并不断改善自身的性能。机器学习是人工智能技术的核心,它根据生理学、认知科学等对人类学习机理进行研究,建立人类学习过程的认知模型或计算模型,并且通过学习算法建立具有特定应用的学习系统。近年来采用机器学习方法的计算机程序被成功用于机器人下棋程序、语音识别、信用卡欺诈监测、自主车辆驾驶、智能机器人等应用领域,同时机器学习的理论方法还被广泛用于大数据集的数据挖掘。人工智能(AI)的概念在1956年达特茅斯会议被提出时,就是希望实现机器智能和制造智能机器人,实现机器具有人的感知、行动、推理与决策的智力,能够用机器来模仿和执行人脑的某些智能功能。2006年深度学习、卷积神经网络取得突破性进展,2016年的人机大战AlphaGO 以4:1 战胜围棋世界冠军李世石,机器智能(Machine Intelligence)开始受到世界关注,机器学习成为了产业和学术界的研究热点。
当前机器学习行业应用有三种主要场景:
(1)第一种场景,机器能够部分替代人工甚至完全替代人工作。这种场景机器在得到数据完全输入情况下就可以准确输出结果。如科大讯飞的智能语音识别技术,识别准确率已超过97%;香港中文大学教授团队研发的DeepID 人脸识别技术的准确率也超过99%,比人类肉眼识别更加精准。
(2)第二种场景,机器无法完全替代人而是辅助人进行工作。在这一种场景下人和机器相互协作,输入数据需要理解与知识推理、思维判断的工作。2019年8月北京师范大学研究团队发布了《2019全球教育机器人发展白皮书》,经过统计问卷调研结果发现,将不同用户群体提出的需求汇总归纳出教育机器人可扮演 17 种角色,它们分别是机器人学习助理、机器人学习伙伴、机器人教具、机器人健康助理、机器人生活伙伴等,其中“智慧学伴”机器人作为学习伙伴可以参与学习者的学习过程、协助学习时间管理以及情感支持等。
(3)第三种场景,机器完全可以取代人进行创意和想象力的工作。这种场景下没有输入数据,主要靠机器创意的工作,创意的过程变为数据形成某种模型,这种模型运算之后产生的结果再进行评估,再迭代这种运算。比如儿童成长机器人就是“能理解会思考”,五米内语音识别率为97%,可识别25 种语言类情感,它具备自学的功能。但是当前所谓智能机器人可以绘图、作曲和写诗,都是数据驱动下编码生成的作品。智能机器人会部分取代人类工作,可以在25 秒内生成稿件写出一篇速报,但是它无法完全取代和做到像人一样的有情感流露、想象力的创意写作。
2 机器学习的三个认知层次
我们从智能机器学习认知的视角,当前机器学习演化发展的三个层次分别是:运算智能(底层计算)、感知智能(浅层感知)和认知智能(深度理解),各个层次都有实现达成的认知智能目标,如图1所示。
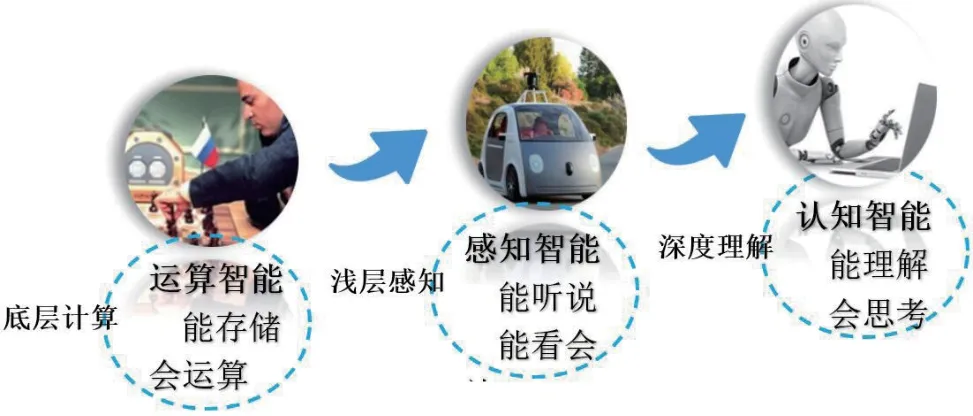
图1:机器智能的三个认知层次
第一层,运算智能(CI,Computational Intelligence)即机器具备超常的存储能力和超快的计算能力,可以基于海量数据进行深度学习,利用历史经验指导当前环境。自1997年IBM Deep Blue(深蓝)计算机击败了国际象棋冠军卡斯帕罗夫,机器在强运算力、大数据存储能力方面就战胜了人类。现阶段随着计算力不断提升,存储手段的不断升级,机器的运算智能(底层认知)已经实现了。
第二层,感知智能(PI,Perceptual Intelligence)即视觉、听觉、触觉等感知能力,人和动物都具备能够通过各种智能感知能力与自然界进行交互。机器在感知世界方面比人类更有优势,人类都是被动感知的,但是机器可以主动感知,如自动驾驶汽车就是通过激光雷达、红外雷达等感知设备和深度学习算法来实现感知智能,现在的智能机器人可以做到语音识别率为99%,可识别25 种语言类情感。无论BigDog 感知机器人还是自动驾驶汽都充分利用了深度神经网络(DNN,Deep Neural Network)和大数据的成果,机器在感知智能(中层认知)方面已经接近于人类。
第三层,认知智能(CI,Ccognitive Intelligence)是让机器像人一样“能理解会思考”即机器思维,如专家系统、机器学习、计算机下棋、计算机作曲绘画、计算机辅助设计、计算机证明定理等。迄今最新版AlphaGo Zero 自我学习能力,使用强化学习(RL,Reinforcement Learning)将价值网络和策略网络整合为一个架构,3 天训练后就以100 比0 击败了上版AlphaGo。智能陪伴儿童成长的机器人当你问了一个它不懂的问题,第二次再问时它就学会了,这就是它自我学习的能力。
人工智能技术经过多年迭代发展,大数据、超运算力和深度学习算法将机器学习能力不断提升,在运算能力和存储能力、“听、说、看”等感知智能领域已经达到或超越了人类水准,但在需要外部知识、逻辑推理或者领域迁移的深层认知智能领域还处于初级阶段。未来机器的认知智能将从认知心理学、脑科学及人类社会经验中获取灵感,并结合跨领域知识图谱(KG)、因果推理(CR)、持续学习等技术,建立稳定获取和表达知识的有效机制,让知识能够被机器理解和运用,实现机器学习智能从浅层感知识别到深层认知理解的提升。
3 机器感知的计算模型
机器感知(MP, Machine Perception)研究如何用机器来模拟、延伸和扩展人的感知能力,主要包括:机器听觉、机器视觉、机器触觉等内容,如计算机视觉(CV)、模式识别和自然语言理解,而机器感知智能就是让机器具备视觉、听觉、触觉等感知能力,将多元数据结构化或形式化并用人类熟悉的方式去沟通和互动。
3.1 感知器神经元模型
感知计算(PC,Perceptual Computing)作为AI 领域最新机器学习的热点技术,着重于模拟复制人类思维过程,它基于对海量大数据的处理,理解符号化、概念化的信息,可以和人类进行最自然的人性化交互,模拟人类的思考和记忆方式,从而达到更高层的数据理解,比如苹果Siri 和亚马逊Alexa 等人工智能助理。感知器是由美国心理学家Frank Rosenblatt 于1957年提出的一种具有单层计算单元的神经网络。感知器可谓是最早的人工神经网络,如图2所示给出了单层感知器神经元模型图,单层感知器是一个具有一层神经元、采用阈值激活函数的前向网络。1958年提出了模式分类问题的感知器(Perceptron)模型;1984年霍普菲尔德网络被推出让人工神经网络具备了记忆功能;2006年深度学习、卷积神经网络取得突破性进展。用于解决分类问题的感知器是一种二类线性模型,如图3所示。感知器模型选择f(x)为二值输出,感知器的分类与参数{W,θ}紧密相关,要实现对输入分类,就是确定如何调节参数{W,θ},这实际上就是一种学习的过程,如无监督学习的Hebb 学习规则模型、有监督学习的Delta 学习规则模型等。
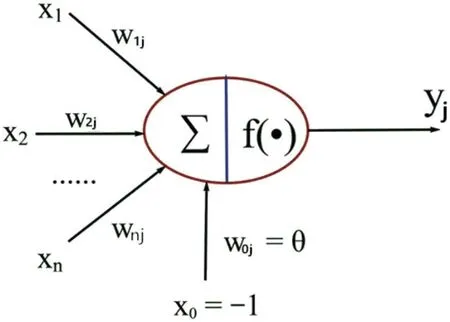
图2:单层感知器神经元模型图

图3:二类线性的感知器模型
赫布提出的Hebb学习规则为神经网络的学习算法奠定了基础,在此基础上研究提出了各种学习规则和算法。Hebb 学习规则与心理学“条件反射”机理一致,赫布理论认为在同一时间被激发的神经元间的联系会被强化,变化的量与两个神经元的活性之和成正比,并且已经得到了神经细胞学说的证实。Delta 学习规则是一种简单的有导师学习算法,根据神经元的实际输出与期望输出差别来调整神经元到神经元之间的连接权。
3.2 机器听觉的语音识别模型
基于人工智能的语音交互技术能够使机器像人一样“能听会说”,它的主要底层技术包括:语音合成、语音识别和自然语言理解,如图4所示。语音合成也称文字转语音(TTS),它是将计算机自己产生的或外部输入的文字信息转变为可以听得懂、流利的汉语或其他口语输出技术。语音合成包括的步骤有:

图4:语音识别与语音合成的示意图
(1)语义分析,主要模拟人对自然语言的理解过程,使机器对输入的文本能完全理解,如文本规整、词的切分、语法分析和语义分析等;
(2)韵律处理,为合成语音规划出音段特征,使合成语音能正确表达语意并更加自然;
(3)声学处理及合成语音。
语音识别(ASR, Automatic Speech Recognition)是将人类的语音中的词汇内容转换为计算机可读的二进制编码或者字符序列,语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等。语音识别的方法主要有三种:基于声道模型、语音知识和模板匹配以及人工神经网络方法,其中模板匹配方法要经过特征提取、模板训练、模板分类、判决这四个步骤。语音识别常用的技术有:动态时间规整(DTW)、隐马尔科夫(HMM)理论和矢量量化(VQ)技术,其中最重大突破是隐马尔科夫模型(HMM,Hidden Markov Model)的应用。1952年贝尔实验室实现了10 个英文数字的识别,其识别方法是跟踪语音中的共振峰,早期的语音识别系统是简单的“孤立词识别系统”。1960年人工神经网络被引入了语音识别,两大突破是线性预测编码(LPC)及动态时间规整(DTW)技术。80年代语音识别开始从孤立词识别系统向“大词汇量连续语音识别系统”发展,两个关键技术是隐马尔科夫模型(HMM)理论和NGram 语言模型的应用,其中HMM 模型是用来描述隐含未知参数的统计模型,如图5所示。2009年开始转向基于深度神经网络(DNN)的语音识别系统(DNN-HMM)的研究,其中DNN 的优势在于:

图5:隐马尔可夫模型的状态变迁图(例子示意)
(1)使用DNN 估计HMM 的状态后验概率分布,不需要对语音数据分布进行假设;
(2)输入特征可以是多种特征的融合;
(3)可以利用相邻的语音帧的结构信息,如图6所示。
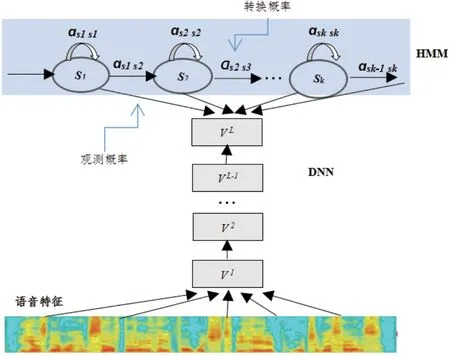
图6:深度神经网络的语音识别模型
3.3 机器视觉的图像识别模型
机器视觉(Machine Vision )是用机器模拟人类视觉,从图像识别检测实际生活中三维物体的形态及其运动情况。机器视觉的研究是从20世纪60年代中期美国学者L.R.罗伯兹关于理解多面体组成的积木世界研究开始的,罗伯兹在图像分析过程中采用了自底向上的图像分割方法。在图像理解研究中A.古兹曼提出运用启发式知识,表明用符号过程来解释轮廓画的方法不必求助于诸如最小二乘法匹配之类的数值计算程序。
70年代机器视觉形成几个重要研究分支:
(1)目标制导的图像处理;
(2)图像处理和分析的并行算法;
(3)从二维图像提取三维信息;
(4)序列图像分析和运动参量求值;
(5)视觉知识的表示;
(6)视觉系统的知识库。
机器视觉技术主要包括图像增强、数据编码和传输、平滑、边缘锐化、分割、特征抽取、图像识别与图像理解等。机器视觉系统能自动获取一幅或多幅目标物体图像,对所获取图像的各种特征量进行处理、分析和测量,并对测量结果做出定性分析和定量解释。
3.3.1 图像理解
如图7所示,图像理解有三个层次:一是分类,将图像结构化为某一类别的信息,用实例ID 来描述图片。二是检测,关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。三是分割,包括语义分割和实例分割,机器视觉技术会模拟人的视觉功能,并从所监测区域内的事物中采集、挖掘相关数据信息,并进行数据二次分析、提炼处理。机器视觉的应用有机器人视觉、人脸识别、无人驾驶汽车、文字识别和追踪定位等。
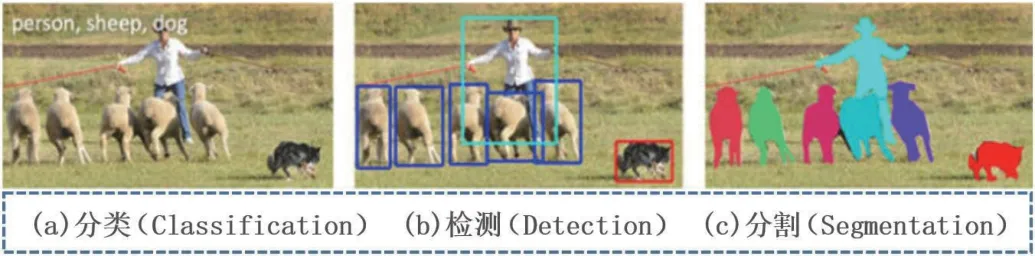
图7:图像理解的三个层次
3.3.2 机器人的“像素”颜色分类识别
机器人的视觉识别主要是利用颜色、形状等信息来识别环境目标,以机器人对颜色的识别为例:当摄像头获得彩色图像以后,机器人上的嵌入计算机系统将模拟视频信号数字化,将“像素”根据颜色分成两部分:感兴趣的像素(搜索的目标颜色)和不感兴趣的像素(背景颜色),然后对这些目标颜色的像素进行RGB 颜色分量的匹配,如图8所示。
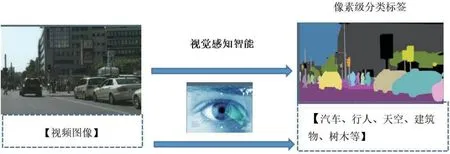
图8:视频图像的像素级分类
“像素”颜色分类常用的方法有线性色彩阈值法、最近邻域法和阈值向量法等。
(1)线性色彩阈值法是用线性平面把色彩空间分割开来,其阈值的确定可采用直接取阈值或通过自动训练来获取,也可以采用神经网络和多参数决策树方法来进行自学习获得合适的阈值;
(2)最近邻域分类法分割图像时,则利用隶属度函数,根据最大的隶属度来判断这个颜色属于的类别;
(3)阈值向量法是先使用一组事先确定的阈值向量来把色彩值在色彩空间中的位置来判断其属于哪种颜色。通常以上方法在色彩分类识别之后要对分类后的像素进行一次扫描,即将相邻的同种颜色的像素连成色块。但是相对于人类的视觉能力,这种视觉感知智能方法只有分类类别,缺乏对实例内涵与外延的抽象与延伸,缺乏对不同概念之间关系的理解,缺乏基于知识的推理及对常识经验的利用等。
3.4 自然语言理解的词向量模型
(1)词袋模型:在自然语言处理(NLP)和信息检索中作为一种简单假设,词袋模型把文本(段落或者文档)看作是无序的词汇集,忽略语法和单词的顺序,计算每个单词出现的次数,常被用在文本分类中,如贝叶斯算法、LDA 和LSA 等。
(2)词向量模型:深度学习带给自然语言处理最大的突破是词向量(Word Embedding)技术。词向量技术是将词语转化成为稠密向量。在自然语言处理应用中,词向量作为机器学习、深度学习模型的特征进行输入。词对文本内容的处理简化为K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相相似度。Hinton 在1986年提出了考虑语义距离的词向量表示方法,它是一种低维实数向量,最大的贡献就是让相似的词在距离上更接近。
常用的词向量模型主要有:
(1)LSA 矩阵分解模型,采用线性代数中的奇异值分解方法,选取前几个比较大的奇异值所对应的特征向量将原矩阵映射到低维空间中,从而达到词矢量的目的。
(2)PLSA 潜在语义分析概率模型,从概率学的角度审视矩阵分解模型,并得到一个从统计概率角度上推导出来的词矢量模型。
(3)LDA 文档生成模型,按照文档生成的过程,使用贝叶斯估计统计学方法,将文档用多个主题来表示,不仅解决了同义词的问题,还解决了一次多义的问题,如差分贝叶斯方法及Gibbs Samplings 采样算法。
(4)Word2Vec 模型,通过训练将每个词映射成K 维实数向量(超参数),通过词之间的距离来判断它们之间的语义相似度。其采用一个三层的神经网络,核心的技术是根据词频用Huffman 编码,使得所有词频相似的词隐藏层激活的内容基本一致,出现频率越高的词语,他们激活的隐藏层数目越少,这样有效的降低了计算的复杂度。Word2Vec 算法就是将词表征为实数值向量的一种高效的算法模型,其利用深度学习的思想,通过训练把对文本内容的处理简化为K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。Word2Vec 输出的词向量可以被用来做很多NLP 相关的工作,如聚类、找同义词、词性分析等。由于数据大幅度增强、计算力大幅度提升,以卷积神经网络(CNN)、循环神经网络(RNN)为代表的深度模型,可以随着模型复杂度的增大而增强数据的映射关系,因此深度学习方法开始大量引入到自然语言处理技术(NLP)领域,在机器翻译、问答系统、自动摘要等方向取得成功应用。
4 机器认知的计算模型
人类有了语言才有概念、意识、观念和推理等人类认知智能的表现,概念是一个知识框架的组成部分。机器认知(MR,Machine Recognition)是研究如何用机器来模拟、延伸和扩展人的认知能力。实现认知计算要解决三个问题:
(1)提出一个既符合认知机理又与计算对应的认知计算模型,通过算法描述人类认知过程的细节。
(2)认知表征的描述和量化,心理学家注重外部世界的心理表征,而计算机科学家注重物理特征的抽取和表示。
(3)建立物理特征和心理表征的映射,能够实现认知计算模型(Cognitive Computing),如借鉴心理学基础理论和认知机制可构建视觉认知负荷、视觉显著特征、舒适度与视频特征、情感词语等这些映射。
关于认知模型(CM, Cognitive Model)通常可以分为三类:概念模型、数学模型和计算模型。其中,认知心理学领域的认知模型是以概念模型为主,概念模型采用非形式语言定性描述事物的本质、关系和过程;而数学模型利用数学公式描述变量之间的关系。目前主流的认知计算模型主要分为:
(1)符号模型(功能模拟,认知心理学),以人脑的心理模型为基础将问题或知识表示成某种逻辑网络,采用符号推演的方法来实现搜索、推理和学习,模拟人脑的思维。如ACT-R,EPIC,SOAR 等符号模型通常用产生式规则去解释、描述和支配脑部活动,因此只是从宏观上近似地描述人类的认知过程和结果。
(2)神经网络模型(结构模拟,认知神经科学),以人脑的生理结构和工作机理为基础,对人脑的神经细胞及其构成的神经网络进行研究,采用神经计算的方法来实现学习、联想、识别和推理。2016年深度学习(DL, Deep Learning)作为一种类似于人脑结构的人工智能算法,应用于图像和语音识别已经产生了突破性的研究进展。深度学习采用了学习分层特征表示方法,以深度卷积神经网络(DCNN)为基础带来接近于人类的视听觉感知能力,以及超越人类的棋类动态博弈能力,如AlphaGo 以深度强化学习与蒙特卡洛树搜索的结合方法开启了认知智能探索,且无需大数据支持且可自主进行学习。
目前“认知即计算”已经成为认知科学的主流,认知科学家们将人脑的认知过程与计算机处理信息的过程进行类比,从而构建认知的计算理论,使机器模拟人类认知过程成为可能。综合认知心理学和认知神经科学关于认知加工阶段和加工通路的研究,将人类的认知机理归纳为一个可计算的认知阶段-通路模型,如图9所示的PMJ 认知架构模型,建立了完整的信息加工过程和通路架构,给出了认知与计算的对应关系,图中虚线框内可以为认知模型,概括了认知的主要过程,包括感知、记忆和判断等三个阶段和快速加工、精细加工和反馈加工三类通路。

图9:PMJ 认知框架模型
5 结束语
目前机器学习在感知、认知方法方面还面临着挑战问题:
(1)缺乏认知水平的理解能力;
(2)缺乏知识推理能力;
(3)缺乏利用常识经验举一反三的小样本学习能力;
(4)缺乏可解释性以及高层规划、决策与组织能力。
自2013 以来大数据和人工神经网络(ANN)计算驱动的深度学习已成为计算机视觉、语音合成、自然语言处理和大数据分析的主流方法,深度卷积神经网络使大数据感知智能取得突破性进展,获得更加接近于人类水平的视觉听觉感知能力和自然语言处理能力。当前急需发展下一代结合知识驱动的认知智能方法,迫切需要将数据驱动方法与知识驱动方法相结合,探索具有理解与知识推理能力的新一代认知智能理论与通用的赋能研究范式。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
传感器与微系统(2021年7期)2021-07-15
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
中国矿业(2019年7期)2019-07-26
电子制作(2019年9期)2019-05-30
环球时报(2019-04-26)2019-04-26
小说界(2018年5期)2018-11-26
电影(2018年8期)2018-09-21
