
面向语音识别应用的开源软件演化技术
2021-03-11 03:34段杰鹏
电子技术与软件工程 2021年21期
段杰鹏
(北方工业大学信息学院 北京市 100144)
开源生态,成长与挑战并存。根据《2020 中国开源年度报告》,全球开源都呈现一个大的发展趋势,以Git Hub 和Git ee 为例,无论是活跃代码仓库,还是活跃用户数,高速增长表现强劲[1]。这种结果除了因为开源势头外,还有一个原因就是受疫情影响,采用远程办公的方式。体量的快速增加,伴随而来的问题也越发凸显。在《开源生态白皮书(2020)》中,不仅指出开源知识产权及合规风险,还着重谈到本课题关心的开源软件(Open Source Software,OSS)风险[2]。技术更新迭代快、运维成本高、安全漏洞威胁严重都是亟待解决的开源软件应用问题。这些风险一定程度上都需要通过软件演化这一环去解决。
开源环境对软件演化提出新的挑战。软件演化的核心问题是软件如何适应改变,软件的演化能力主要体现在4 个方面[3]:可分析性;可修改性;稳定性;可测试性。针对软件动态演化,学术界主要从以下几个方面展开工作:程序设计语言、模型、软件体系结构、平台。随着软件开源社区的出现,基于开源代码的软件开发成为新的软件开发生态[4]。众所周知,群智开发是开源软件的一大特点,这就造成软件演化过程不可控。开源项目往往是核心开发人员把自己的初步成果和想法发布在社区,由数量庞杂的贡献者进行项目的完善、测试和维护。从项目计划开始的整个软件生命周期,都没有完整的文档对软件演化过程进行指导和记录;软件演化的发生也更多发生在离散的开发、测试、维护过程中。Scacchi W 等人[5]研究指出,当前对OSS 系统的研究没有对软件演化过程中有时超线性,有时次线性的增长曲线提供适当的解释。有些情况下,OSS 系统是否符合演化的规律也尚不清楚。因此,对开源生态中软件演化技术的研究,重新思考开源环境下软件演化的理论和模型,可以帮助理解、推理和解释开源软件系统的演化。
1 相关研究
Neteler 等人[6]提出了基于远程和连续分析的OSS 演化方法。为了提供减轻软件退化和风险的服务,该方法运用了诸如CVS 版本系统库、承诺日志文件和交换邮件等可用数据源。核心成果包括增长、复杂性和质量控制机制、反馈驱动的通信服务和OSS 演化仪表板服务。Arafat 等人[7]将给定源代码中的评论量作为可维护性的指标,从而进一步了解开源软件开发的过程和行为。Capiluppi 等人[8]研究了OSS 系统的结构衰减是否会受到保存该项目的存储库的影响。Beecher等人[9]通过研究OSS更多存储库,拓展了这项工作。他们根据不同类型的OSS 存储库建立了相应的过度框架。为OSS开发人员选择在哪里主持项目以及让项目成功演化提供了指导。Robles[10]等人介绍了研究人员可以在OSS 项目中找到的最重要的可供研究的数据源:源代码、源代码管理系统、邮件列表和bug 跟踪系统。他们提出了可根据分析数据源遇到的问题给出建议的演化分析工具。Bachmann[11]等人通过定义数据源的质量和特征度量标准来比较不同的OSS 项目。Koponen[12]等人创建了开源软件演化的评估框架。该框架可以用来评估开源软件演化过程的活性、效率、可追溯性和敏捷性。Capiluppi[13]等人通过对比传统软件和OSS 项目的软件演化的共性和差异,对传统软件演化模型进行了调整,提出了适用于OSS 系统的软件演化模型。李颖[14]研究了开源移动应用项目的演化特征,分析了开源移动项目动态演化过程及规律,提出了代码关联推荐算法,当开发者修改代码时,面向开发者提示需要同步修改的代码块。Nakagawa[15]等人研究指出软件体系结构与OSS 质量直接相关,开发人员在OSS 演化中需要充分考虑软件体系结构知识体系,包括软件体系结构风格,体系结构模式和体系结构演化方法。
赵会群[16]等人最早提出了体育计算的概念,随着机器学习的发展,在竞技体育中无论是比赛训练,还是技战术分析,越来越多地运用了人工智能的辅助手段,体育人工智能成为重要的研究方向。Iyer[17]等人使用神经网络根据每个板球运动员过去的表现预测其未来表现,结果表明,神经网络确实可以在团队选择过程中提供有价值的决策支持。Grunz[18]等人引入人工神经网络分层架构,基于足球运动员的位置数据,得到合适的战术模式。结果表明,分层架构能够识别不同的战术模式和各模式之间的变化。Hassan[19]等人通过注释手球比赛723 个动作序列的位置数据,利用非线性混合神经网络,成功预测了个人和团队的战术位置。Kempe[20]等人利用动态可控神经网络正确检测出预选的战术模式。王杰[21]利用改进的人工神经网络对乒乓球技战术进行诊断、评估和预测。
综上所述,对OSS 演化的研究都集中在演化过程,演化体系结构,演化确认等方面,鲜有对特定领域演化技术的具体研究和分析。体育人工智能的研究多集中于神经网络在计算机视觉与技战术分析和预测上。本文将结合开源语音识别在乒乓球技战术采集中的应用,展开对OSS 演化技术的研究。
2 模型驱动演化算法
在语音识别应用层面,从输入、处理过程、输出,无论是识别流程,还是训练流程,对于应用人员相当于是一个黑盒,输入和输出则是用户可以感知到的。基于机器学习的语言识别技术可以分为训练过程和识别过程两个阶段,在识别语音之前需要对识别模型进行训练,以便建立环境参数,为大量语音识别进行分类处理。训练过程输入为语音数据,输出为语音参数模型;识别过程输入为语音数据和输出为识别结果。识别过程是一个“黑盒”形态的语音模型,语言模型等要素无法改变的前提下,识别效果的改变,取决于可变因素语音参数模型。语音参数模型受语料特征的影响,比如数据量,说话人特征,语音内容,语义背景等。根据不同的语料库,可以训练得到不同的语音参数模型。为了适应环境的变化以及提高识别效果,这就要求在识别流程中可以根据实际状态动态调整语音参数模型。模型驱动演化就是根据语音环境的变化动态调整模型训练和识别过程的软件过程。
模型驱动演化中对识别结果进行嗅探,即判断识别结果的正确性,它是触发一系列模型驱动演化动作的前提。如图1所示的时序图中反射式中间件从应用层探知用户对识别结果的修改活动,获取正确结果,依据此正确结果并结合该段语音的识别结果,计算当前语音参数模型对用户语音的识别词错率WER。当词错率达到阈值时,反射式中间件开始探知系统的运行状态state,满足空闲状态后,跟据用户语音特征,从方法库中筛选符合条件的语音参数模型。分别加载备用语音参数模型,并计算获得语音数据wav 的识别结果result,将词错率WER 存储到对应语音参数模型之下。比较所有备用语音参数模型在当前环境下的词错率WER,返回词错率WER 最小的语音参数模型Model。加载Model,判断是否可以识别语音数据,满足条件则继续进行语音识别。现存语音参数模型无法满足要求时,开启数据驱动演化。
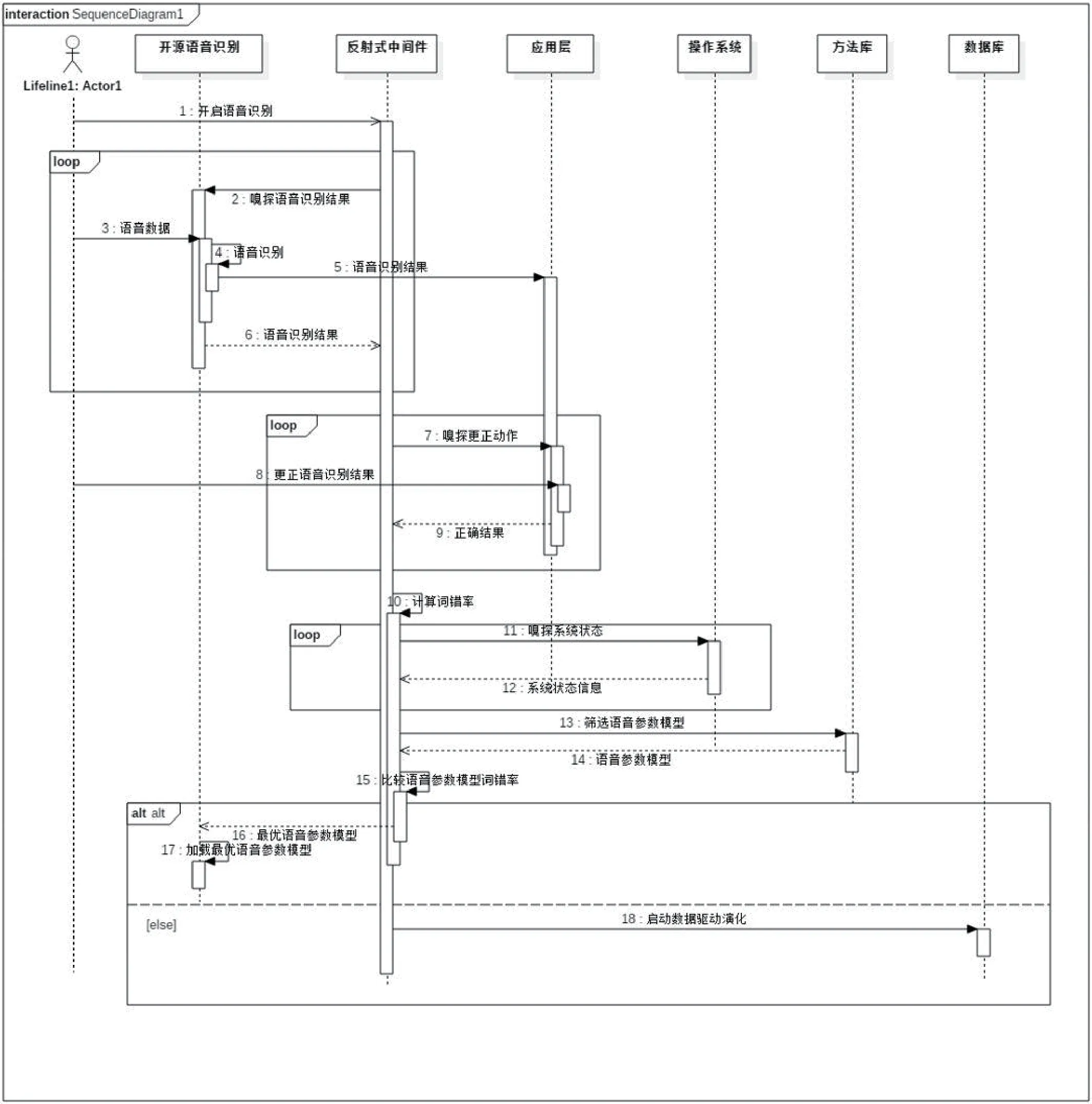
图1:模型驱动演化时序图
在开源语音识别系统辅助应用的过程中,回望开源语音识别模块为了适应环境和提高识别效果所作的工作,凝练模型驱动演化算法如下:
算法1 ModelEvo()



算法1 在执行过程中,需要等待系统满足空闲状态,所以等待的时间T 是该算法时间复杂度组成的重要一环。算法的执行时间还依赖有多少个备用语音参数模型,每个备用语音参数模型都要进行加载、识别和计算,此过程时间复杂度为N。当现存语音参数模型都无法满足应用需求时,需要启动数据驱动演化DataEvo(),在进行数据驱动演化时时间复杂度为I,综上所述,算法1 的总体时间复杂度为O(T+N+I)。算法1 的空间复杂度主要取决于对语音参数模型的筛选过程,此过程的空间复杂度为S(n)=O(N),所以算法1整体的空间复杂度为O(N)。
3 数据驱动演化算法
在实际应用过程中,存在通过方法库和模型库筛选语音参数模型后,模型驱动演化加载最优语音参数模型仍然无法满足当前复杂的应用需求。为了解决以上问题,本文提出了数据驱动演化模型:依据新的语料训练满足当前复杂环境的语音参数模型,并将该语音参数模型加载到语音识别模型库中。
数据驱动演化模型依赖于满足当前应用环境的新的语料,该语料的获得途径有两种方式:首先可以从外部导入满足应用环境的语料;其次可以在该环境的应用过程中采集语音数据,对语音数据进行预处理,形成训练语料,语料数据量达到阈值时,启动训练过程,训练新的语音参数模型,加载语音参数模型到语音识别中,以此来提高适应性。
如图2所示的时序图直观的展示了数据驱动演化的执行过程。当模型驱动演化结束后,在接下来的应用过程中,词错率依然低于阈值时,反射式中间件开始对数据库进行嗅探。在当前应用时段中,如果应用人员从外部导入了新的语料库,或者采集人员不断采集语音数据,语音数据量达到可以训练的阈值时,反射式中间件开始对系统资源状态进行嗅探。当应用程序处于空闲状态以及系统资源充足时,语音识别模块从数据库获取语料库,进行新语音参数模型的训练。训练结束后,将语音参数模型加载到语音识别系统中,并且依据语音特征更新方法库和模型库。

图2:数据驱动演化时序图
依据数据驱动演化模型,在语音辅助识别应用过程中,本文提出了数据驱动演化算法如下:
算法2 DataEvo()

算法2 中的输入Cor 表示在语音识别辅助应用开始,依据当前环境在数据库中新创建的一个语料库。算法2 的执行过程主要是对数据库和系统资源的探查。假设对数据库嗅探了N 次,则此while语句的时间复杂度为O(N);假设对系统资源嗅探了M 次后,满足语音参数模型训练要求,则此过程的时间复杂度为O(M)。所以综上所述,算法2 的时间复杂度为O(N)。因为要训练新的语音参数模型,所以算法2 的空间复杂度取决于训练一个批次所使用的数据量,假设训练一个批次需要使用L 条数据,那么算法2 的空间复杂度为O(L)。
4 实验分析
本节结合实际应用案例,首先,分别对上述模型驱动演化模型和数据驱动演化模型所提出的算法进行验证,最后对得出的实验结果进行分析说明。
4.1 应用案例
本文以开源语音识别辅助乒乓球技战术采集为背景,首先模拟采集过程中,因为乒乓球技战术语言的特异性,识别效果无法满足要求,验证系统实行模型驱动演化,实现最优语音参数模型的替换;其次模拟当前模型库中的语音参数模型仍无法满足乒乓球技战术采集要求,验证数据驱动演化启动后对数据库和系统资源的成功嗅探,最终实现语音参数模型的训练和加载。
4.2 实验结果
本节给出三组实验结果,分别是:识别结果和正确结果的嗅探;参数模型筛选比较替换;数据库数据量的嗅探。
4.2.1 识别结果和正确结果的嗅探
在模型驱动演化过程中,某段语音的词错率是否满足要求是启动模型驱动演化的前提条件,所以嗅探器首先要对识别结果和人工更正后的正确结果进行嗅探,以此来计算词错率。
在语音识别辅助乒乓球技战术采集中,首先语音识别模块加载默认语音参数模型;然后采集人员在应用层录入一段乒乓球技战术语音,本文以speechDataA=“接相持段摆失”这一语音数据为例。语音识别模块对speechDataA 进行识别,识别结果为A=“接向十段白失”。嗅探器从语音识别模块嗅探识别结果A 的同时,语音识别模块将识别结果A 反映到应用层,以供采集用户进行更正。嗅探器从应用层探知采集用户的更正动作和用户进行下一段语音数据speechDataB 的录制动作后,获得正确结果A′=“接相持段摆失”,最后开始计算speechDataA 的词错率。
因为两个嗅探动作的成功执行(从语音识别模块嗅探识别结果A;嗅探采集用户更正动作和嗅探speechDataB 的录制动作,最后获取正确结果A′)和词错率的成功计算存在前后因果关系,所以本文以speechDataA 词错率计算后的结果展示来验证算法1 中嗅探器的成功执行。如图3,speechDataA 的词错率为50%,所以默认语音参数模型的识别准确率为50%。

图3:词错率计算
4.2.2 参数模型筛选比较替换
根据本文对乒乓球技战术语言的研究,采集一条标准的乒乓球技战术信息,其中最多含有7 个汉字,识别结果最多错一个的前提条件下,词错率为14%,据此,本文将词错率的比较阈值设置为20%,方便之后的实验研究。
显然speechDataA 的词错率明显大于阈值,所以嗅探器开始对系统运行状态进行嗅探,当系统处于空闲状态后,依据语音特征,从方法库(技术路线是:技战术采集→山西口音普通话)和模型库中检索最优语音参数模型备选模型。语音参数模型准确率比较筛选后得到三个语音参数模型如表1所示。

表1:模型信息
语音识别模块分别加载上述模型,依据speechDataA 和它的标签文本A′计算当前环境下的词错率。如图4所示,Model10 的词错率为66%左右,Model21 为33%左右,Model30 的词错率为40%左右。Model21 与默认语音参数模型相比,准确率明显提高。综上所示,现有语音参数模型中,适应当前环境的最优语音参数模型为Model21。

图4:词错率比较
本文通过对系统资源的监控,首先验证了嗅探器对系统空闲状态的探查。如图5为系统资源使用情况随时间的变化图,图中对系统的资源监控起始于算法1 中备选语音参数模型的适应性比较,结束于最优语音参数模型加载前。所以根据图中给出的CPU 使用率变化情况,在0ms 之前,系统监控结束之后,CPU 使用率在30%以下,说明系统处于空闲状态,证明嗅探器对系统空闲状态的嗅探结果是成功的。

图5:系统资源图
CPU 作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元,所以当软件运行时,CPU 使用率第一时间发生变化。从图5可以发现:0-50ms,50-100ms,100-150ms 分别出现了一次波峰,因为有三个候选语音参数模型,所以每个时间段都表示算法在执行一次加载语音参数模型、识别语音数据、计算词错率、更新数据的过程。因为人工智能对GPU 的使用是其在硬件资源使用上的一大特点,同样,进行语音识别时需要占用GPU 资源。如图5绿色折线表示演化过程中,GPU 使用率变化情况,因为进行了三次语音参数模型加载和语音识别过程,所以在时间线上也出现了三次波峰。图5中橙色折线表示内存使用情况,内存主要负责暂时存储CPU 的计算结果以及和外部存储器交换资源。每个波峰都表示对识别结果和词错率的计算和存储,并将词错率结果存储到数据库中。
4.2.3 数据库数据量的嗅探
数据驱动演化的目的是利用适应当前环境的语音数据,训练新的语音参数模型,提高之后语音辅助采集的语音识别效果。应用过程中采集的语音数据达到一定数据量或者有新的语料库导入才能开始训练新的语音参数模型。
如图6所示为嗅探器对系统创建的语料库中语音数据量的嗅探。嗅探器每隔一段时间对语料库中的数据量进行嗅探,当达到阈值时,停止嗅探。本文为方便测试,在实验过程中设置嗅探语音数据量的阈值为100 条语音数据,设置嗅探间隔为30min。在图6中有两条折线,表示本文分别作了两次实验,实验变量为是否人工导入新的语料库。蓝色折线表示随着语音辅助应用的进行,嗅探器感知到语料库中的语音数据量在不断增加,在210min 嗅探到117 条数据时,停止了嗅探活动。橘色折线在120min 之后,就没有新的嗅探数据,表明120min 之后,嗅探器停止了对系统创建的语料库中数据量的嗅探,这是因为,嗅探器嗅探到了由外部导入了新的语料库,所以结束了对现有语料库中数据量的嗅探。
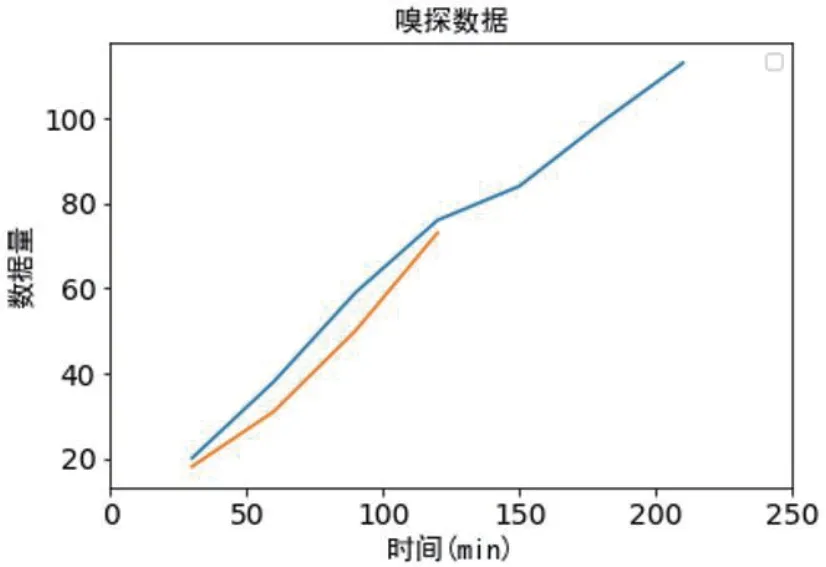
图6:语音数据量随时间变化图
5 结束语
面对开源语音识别辅助应用过程中因为识别环境和语音特征不同造成识别效果不佳,以及语音模型对采集人员的黑盒问题,本文提出了模型驱动演化算法和数据驱动演化算法,通过替换和训练语音参数模型实现识别效果的提高。本文通过实验验证了模型驱动算法和数据驱动演化算法的有效性,利用开源软件演化技术可以提高语音识别辅助系统对环境的适应性。最后通过语音辅助乒乓球技战术采集系统的实现和应用,进一步验证了本文提出的开源语音软件演化技术在实际应用中的效果。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
天津外国语大学学报(2020年1期)2020-03-25
电子制作(2019年13期)2020-01-14
创新作文(1-2年级)(2019年3期)2019-09-03
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
上海理工大学学报(社会科学版)(2015年3期)2015-11-30
语言与翻译(2015年4期)2015-07-18
