
图像篡改检测技术综述
2021-03-11 03:34宋炎寒苏红旗
电子技术与软件工程 2021年21期
宋炎寒 苏红旗
(中国矿业大学(北京)机电与信息工程学院 北京市 100083)
随着摄影技术和互联网的发展,数字图像在日常生活中扮演了越来越重要的角色。在新闻报导、法庭取证、医学、科学研究、社交等领域中,数字图像已经成为不可或缺的一部分。当用数码设备拍摄照片时,我们希望照片能真实的记录实际发生的场景,但是随着图像处理软件 (如 Photoshop, GIMP) 的快速发展,对数字图像的处理越来越容易。例如,在 Photoshop 中可以轻易的完成尺寸调节、对比度调节、模糊等图像操作,甚至可以比较容易的完成图像特定区域的选择和修改。这些图像处理在一些场景下是必不可少的,可以使得拍摄的数字图像更为美观。但是一些图像处理以传递虚假的信息为目的,对图像的内容进行“移花接木”等操作。这些恶意造假事件,有可能对社会造成不良的影响。
对数字图像的修改可以分成三类[1],如图1所示。第一类是图像处理 (image manipulation),指通过计算机软件,对数字图像完成的所有操作的集合,又叫图像编辑。第二类是图像篡改 (image forgery),其是图像处理的一个子集,指为了传递欺骗性的信息,而对图像所做的修改。第三类是图像伪造 (image tampering),是为了在场景中隐藏一个对象,或者加入一个新的对象,而改变图像的一部分。图像篡改检测针对的即是图像篡改,采用主动或者被动检测方法,来对图像的真伪性做出判别。
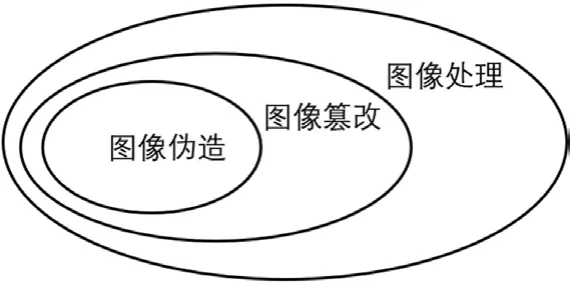
图1:数字图像操作分类
1 图像篡改检测技术分类
经过篡改后的图像会传递错误的信息。在新闻、法庭取证、科学研究等特定领域中,这些篡改操作是不被允许的。因此,有必要对图像篡改进行检测。图像篡改检测作为图像取证 (image forensics)领域的一个分支[2],很早就受到了关注。图像篡改检测任务有两个不同的目的:一是对图像是否经过篡改进行判断,即对图像进行二分类;二是对篡改区域进行定位,得到篡改区域的掩膜 (mask)。篡改检测技术以实现第一个目的为基本要求。对篡改区域的定位则更为复杂,根据所采用的算法和针对的篡改操作类型不同,一部分算法可以实现篡改区域的定位。
已有的图像篡改检测方法,可以分为主动方法和被动方法。主动方法需要事先向图像中插入额外的信息,如数字水印和数字签名。在篡改检测时,需要通过这些额外的信息来判断图像是否经过了修改。由于网络上图片数目巨大,很难要求所有的图像都添加这些额外的信息,因此主动方法应用的范围受到了限制。在无法接触到原始图片的情况下,研究者提出了被动检测方法。被动方法区别于主动方法,是在仅有一张图像的前提下,通过对图像的特征进行分析,判断该张图像是否经过了篡改。由于被动方法不依赖于额外添加到图片中的信息,因此又被叫做盲检测 (blind detection)。虽然经过篡改后的图片有可能在视觉上没有明显的篡改痕迹,但是在图像的统计指标上还是会产生异常[3]。被动方法即利用图像篡改操作留下的线索来对图像真伪性进行检测。图像篡改检测技术分类如图2所示。
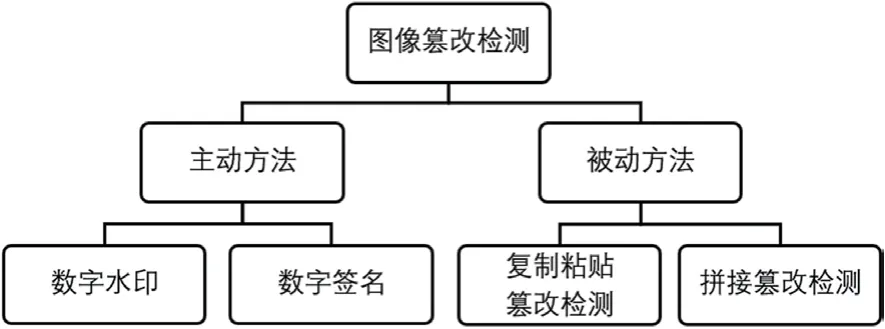
图2:图像篡改检测技术分类
由于图像篡改检测问题的复杂性,早期的检测算法并不是通用的,一般只能适用于某一特定的篡改类型。研究较多的篡改类型是复制粘贴篡改 (copy-move forgery) 和拼接篡改 (splicing forgery)。复制粘贴篡改是指把图像中的一部分内容复制,并粘贴到同一张图像中。拼接篡改新生成的图像由两张图像组合而成,是把一张图像中的内容复制,并粘贴到另外一张图像里。两种篡改方式示例如图3所示。两种篡改类型都可以包含适当的后处理操作 (post-processing),目的是为了隐藏篡改痕迹,使得篡改图片视觉上更为自然,常用的后处理操作有:旋转、缩放、模糊、对比度调整等。在图像篡改检测领域中,针对这两种常见的篡改方法的特点,进行了针对性的研究。
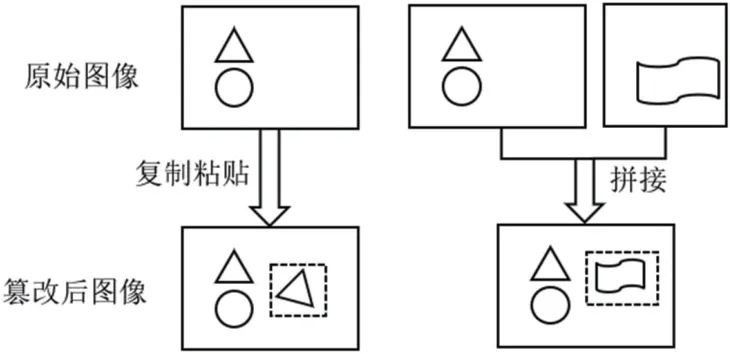
图3:复制粘贴篡改(左)和拼接篡改(右)
在传统的方法中,主要根据复制粘贴篡改和拼接篡改的特点手动选取特征,来对图像的真伪性进行判断。利用传统方法来进行复制粘贴篡改检测和拼接篡改检测的研究领域非常活跃,已经有了大量的研究。近几年,随着深度学习的发展,特别是深度学习在计算机视觉领域取得的成功,使得研究者开始关注基于深度学习的图像篡改检测。
2 传统检测方法
2.1 复制粘贴篡检测
复制粘贴篡改检测是该领域中最早受到关注的,主要是因为其有明确的检测思路。复制粘贴操作把图像中一部分复制并粘贴到图像的另一个区域中,最终的篡改图像内一定含有重复区域。根据这一特点,复制粘贴篡改检测问题可以转变为图像中的重复区域检测问题[4]。把图像分成不重叠的图像块,在图像块之间进行匹配,即是早期算法的检测思路。但是检测难点在于复制粘贴篡改并不是图像内容的完全复制粘贴,而是伴随着后处理操作。经过后处理,篡改图像更为真实,但是也使得图像中的重复区域在像素值上并不是完全的一致。简单的像素值匹配算法无法在存在后处理操作的情况下进行检测。为了提高检测算法对后处理操作的鲁棒性,已经提出了基于不同图像特征的检测算法。
复制粘贴篡改检测算法的流程如图4所示。Christlein 等人[5]提出把已有的算法分成基于块的方法和基于关键点的方法,基于块的方法会把图像分块,以每个图像块为单位提取特征向量;基于关键点的方法会在图像内高熵区域内提取关键点。在匹配阶段,会对提取到的特征向量检测相似度,检测到高相似度的特征向量可以看作图像中存在重复区域。过滤在于移除错误匹配,例如移除错误匹配的在空间上接近的图像块。
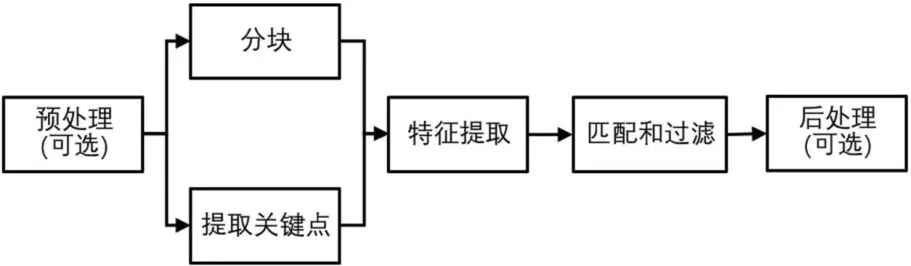
图4:复制粘贴篡改检测的流程
早在2003年,Fridric 等人[4]提出通过滑动窗口方法和DCT 来对图像中重复区域进行检测。该方法首先把图像分成不重叠的图像块;然后对每一个图像块进行离散余弦变化;接下来对量化后的DCT 因子进行排序,以找到相似的图像块。之后的基于块的检测算法大致延续了这个思路,改进主要集中在块的特征提取和特征匹配步骤。在论文[1]中,把基于块的方法所提取的特征分成了6 大类,分别是图像块的像素值、统计指标、频率域因子、不变矩、图像局部特征、PCA 与SVD。
基于关键点的检测算法主要是为了解决滑动窗口方法计算量大和对后处理鲁棒性差的问题。尺度不变特征变换 (scale invariant feature transform, SIFT) 和加速稳健特征 (speeded up robust feature,SURF) 是基于关键点方法中常用的特征。Pan 等人[6]提出用 SIFT算法,提取了图像中的关键点并实现对篡改区域的定位。Xu 等人[7]提出使用SURF 特征的图像复制粘贴篡改检测算法,其对于旋转、缩放、模糊等后处理操作具有鲁棒性。基于关键点的算法主要缺点在于无法在光滑的区域提取关键点。
2.2 拼接篡改检测
在拼接篡改的图像中,被篡改区域的内容来自于另一幅图像。由于图像不存在重复的区域,无法使用与复制粘贴篡改检测相同的方法。拼接篡改检测主要利用的是图像中篡改区域和未篡改区域来源不同,所导致的图像统计特征上存在的差别。因此对图像的统计特征进行建模,检测肉眼不可见的篡改痕迹,是拼接篡改检测的主要方法。常用的篡改痕迹有边缘不一致、双重JPEG 压缩效应、光线不一致、与相机成像过程有关的不一致。
当图像的格式是 JPEG,并且篡改后的也存储为JPEG,那么篡改图像会出现双重量化效应 (double quantization, DQ)。Popescu 等人[8]开发了识别双重压缩图像的工具。由于篡改区域来自于另一幅图像,有可能与未篡改部分的光线方向不一致。Johnson 等人[9]通过估计图像中对象的光线方向来进行检测,如果有对象的光线方法有差异,就认为存在图像篡改。与相机成像过程有关的不一致主要利用的有:相机响应函数 (camera response function, CRF),色彩滤波阵列 (color filter array, CFA) 和光响应非均匀性(photo response non-uniformity, PRNU)。
传统的图像篡改检测方法针对的是单一的篡改操作和特定的后处理操作,因此局限性主要是鲁棒性差。复制粘贴篡改检测需要在经过后处理的图像中检测重复区域,但是目前算法针对的后处理操作有限,无法应对复杂的后处理情况。拼接篡改检测方法有较强的假设和前提条件,在现实的应用场合中,无法提前预知待检测的图像是否满足这些算法的基本假设。如何处理现实场景中的复杂情况,是传统方法面临的问题。
3 基于深度学习的检测方法
由于深度学习在其他领域取得的成功,图像篡改检测领域也开始关注篡改检测技术与深度学习技术的结合。深度学习模型在训练时,可以自动学习复杂的特征,从而一定程度上避免了手工选取特征适应范围小、鲁棒性差的问题。和传统检测方法不同,基于深度学习的检测方法,直接在拥有多种篡改类型、多种后处理操作的训练集上进行训练。在基于深度学习的篡改检测算法发展过程中,卷积神经网络 (convolutional neural network, CNN) 尤其受到关注。通过利用 CNN 来自动提取特征,可以实现通用的篡改检测算法。
Zhang 等人[10]为了解决传统的图像篡改检测方法鲁棒性差的问题,提出了二阶段的层次特征学习方法。该算法可同时对复制粘贴操作和图像拼接操作进行检测,并且有一定的篡改区域定位能力。其首先把图像分成 32×32 的不重叠块,对每一个图像块进行小波变换,获得图像块的基本特征作为原始输入。在第一阶段中,利用栈式自动编码器对每个原始输入的复杂特征进行学习;在第二阶段,结合了相邻块的信息,来计算每个块的最终检测结果。其在 CASIA数据集上制作了训练集和测试集,在测试集对块进行分类的准确度达到了91.09%。但是该方法是对整个图像块进行分类,方法得到的定位结果和实际的篡改区域有较大的差距。
Bayer 等人[11]提出了一种基于CNN 的通用的图像操作检测算法。算法检测的图像操作包括:中值滤波、高斯模糊、加性高斯白噪声、重采样。其创新点在于对 CNN 模型进行了修改。CNN 倾向于学习表示图像的内容特征,而不是与检测图像操作有关的特征。因此他们参考了已有的图像取证方面的研究,对第一个卷积层的滤波器添加了额外的约束。对第一层的12 个滤波器添加的约束为:中心值为-1, 四周的所有值之和为1。其实验结果显示该算法可以对多种图像操作进行检测,平均准确度达到了99.1%。
Rao 等人[12]提出用 CNN 来检测拼接篡改和复制粘贴篡改。其提出的算法步骤较多。该算法用 CNN 提取尺寸为128×128×3 的图像块的层次化特征,差异在于CNN 的参数并没有全部采用随机初始化的方法,而是把第一层初始化为30 个高通滤波器,以计算残差。接着对图像应用滑动窗口方法并经特征融合步骤得到整个图像上的特征。最后需要应用SVM 分类器来对整张图像的特征进行分类,以判断整张图像是否经过篡改。算法在CASIA v1.0 的准确度达到了98.04%,在CASIA v2.0 数据集上的准确度达到了97.83%。虽然准确度较高,并且可以同时实现复制粘贴、拼接篡改检测,但是无法实现篡改区域的定位。
Bondi 等人[13]提出用CNN 提取图像块中与相机型号有关的特征,以实现拼接篡改检测与定位。如果一个图像中检测出了两种相机型号,说明图像经过了拼接篡改。该算法把图像分成不重叠的64×64 大小的图像块,利用CNN 得到图像块对应的相机模型特征。接着在整张图像上进行 K-means 聚类,得到篡改区域的掩膜估计。其在测试集中,不仅有CNN 训练过程中使用到的相机型号,而且还额外添加了 8 个没有在训练时使用过的相机型号,以测试方法对未知相机型号的鲁棒性。该方法利用相机型号来进行拼接篡改检测,证明 CNN 可以得到图像块的相机型号特征,而且对未知的相机型号也有检测能力。
Marra 等人[14]提出了端到端的图像篡改检测方法。该方法直接把整幅图片输入到卷积神经网络中,进行端到端的训练。其目的一方面是为了避免图像块尺度上的低错误率导致的整张图像上的高错误率,另一方面是为了让 CNN 在整张图像上进行学习。其和已有的算法在多个数据集上进行了对比实验,选取的指标为 AUC。其实验结果中,端到端方法在每个数据集上都取得了比其它方法更好的结果。
4 图像篡改检测数据集
无论是传统方法,还是基于深度学习的方法,都离不开图像篡改数据集。数据集一方面提供了所需要的篡改图像,另一方面也使得不同算法之间的比较更为方便。在图像篡改检测领域中,有不少常用的数据集,但是由于这些数据集发布的时间不同并且创建目的不同,也存在着不少的差异性。例如在图像尺寸、格式、数量、篡改操作、后处理操作等方面,各个数据集不尽相同。
早期的数据集针对的是传统检测方法,往往图像数量少,尺寸小,也没有后处理操作。随着对检测算法鲁棒性的关注,数据集中开始包含不同格式、不同后处理操作的图像。为了实现篡改区域的定位,有的数据集还会包含篡改区域的掩膜。详细的图像篡改检测数据集信息见表1。
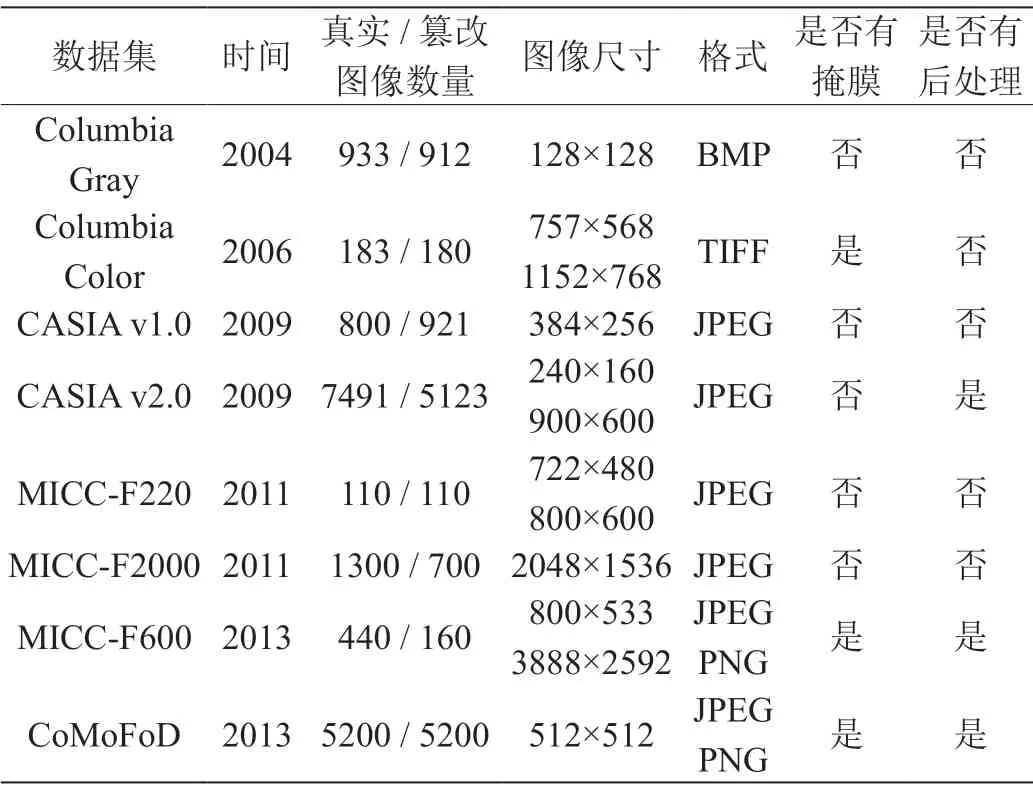
表1:图像篡改检测数据集
5 结束语
图像篡改检测在近几年受到了越来越多的关注,也有大量的篡改检测方法提出。本文总结了图像篡改检测的分类,对传统方法中的复制粘贴篡改检测和拼接篡改检测做了介绍,并分析了目前基于深度学习的检测方法。
传统方法利用手工提取的特征进行检测,算法鲁棒性差。基于深度学习的方法借鉴并进一步发展了传统方法,例如对CNN 的卷积层设置为受限的高通滤波器;利用CNN 学习图像块的相机型号特征。这些方法已经取得了一定的进展。但是基于深度学习的图像篡改检测方法还是需要利用图像块来实现篡改区域的定位,篡改区域定位算法还需要进一步的发展。
猜你喜欢
今日农业(2020年20期)2020-12-15
智族GQ(2020年7期)2020-08-20
农业机械学报(2020年2期)2020-03-09
计算机与网络(2019年3期)2019-09-10
中华建设(2019年7期)2019-08-27
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
发明与创新(2015年30期)2015-02-27
汽车与新动力(2013年3期)2013-03-11
