
基于随机森林回归算法的用水总量影响因素解析
——以广东省为例
2021-03-09 10:15汪丽娜
华南师范大学学报(自然科学版) 2021年1期
李 宁, 汪丽娜
(华南师范大学地理科学学院,广州 510631)
水资源短缺是世界各地面临的风险,虽然许多地区采取了应对措施,但由于影响用水总量的因素较为复杂,且因地而异,导致效果参差不齐[1]. 例如,在上海市闵行区实行用水定额管理、淘汰落后产能的措施成功使得万元工业增加值用水量下降了56%[2]. 但在保定市徐水区实行相同策略时,仅使得万元工业增加值用水量下降了35%[3]. 学者们采用不同的方法分析用水总量的影响因素,如:利用聚类线性回归模型对太湖流域区域用水量的影响因素进行评价研究,结果表明区域经济发展的用水刚性需求是太湖流域区域用水量的主要驱动因素[4];运用对数平均迪氏指数法(LMDI)将中国用水量变化的影响因素分解为人口效应、区域人口分布效应、区域经济发达效应、区域产业结构效应和区域技术进步效应,发现技术进步和产业结构调整是抑制用水量上升的影响因素[5];运用灰色关联分析法,对影响太原市用水量的因子进行排序,结果表明水的重复利用率是影响太原市用水量的主要因子[6];运用结构分解分析的方法研究了我国1999—2002年和2002—2007年期间用水量变动的影响因素,结果显示:(1)在结构层面,人均 GDP的增长是导致用水量增加的主要因素;(2)在最终需求层面,最终需求总量变化是用水量变动的主要因素[7].
上述研究方法大多数为纯数学模型,存在计算繁琐、对缺失值与异常值较为敏感以及易过拟合与欠拟合的问题. 随机森林回归算法是2001年开发的一种自然的非线性建模工具[8],可以解释多个自变量对因变量的作用,具有训练速度快、模型泛化能力强和实现较为简单的特点[9],目前已被广泛应用于医学、生物学、管理学和经济学等众多领域[10-14]. 基于此,本文主要通过构建包含人口、水资源、技术和经济4项因素以及常住总人口、人口密度、水资源总量、降雨量、万元GDP用水量、万元工业增加值用水量、第一产业生产总值、第二产业生产总值和第三产业生产总值9个元素的指标层次结构,利用熵值法和随机森林回归算法,解析2018年广东省21个地级市用水总量的影响因素,为水资源的可持续利用提供参考.
1 材料与方法
1.1 研究区域及数据来源
以广东省21个地级市为研究区域. 广东省属热带和亚热带季风气候区,地处低纬度,气候温暖湿润,降水量比较丰富. 全省2018年的平均水资源总量为1 895.1 亿m3,其中,地表水资源量为1 885.2 亿m3,地下水资源量为460.6 亿m3,年平均降雨量为1 843.1 mm,用水总量为420.95 m3[15]. 由广东省2018年各地级市用水总量的空间分布图(图1)可知:广东省的用水总量具有时空分布不均的特征,以广州市为中心的珠三角地区以及粤西地区的茂名市和湛江市的用水总量较多,而粤西地区的云浮市、阳江市以及粤东地区的汕头市、潮州市、汕尾市的用水总量相对较少. 本文所用数据来源于2018年的《广东省水资源公报》和《广东省统计年鉴》.

图1 广东省2018年各地级市用水总量的空间分布图
1.2 指标选取
用水总量受多种因素的影响和制约,本文结合广东省的用水特点及相关文献[4-7],遵循科学性、可量化性原则,选取9个元素和4项因素(表1),构建影响用水总量的指标层次结构.
1.3 研究方法
1.3.1 随机森林回归算法的基本原理及变量的重要性评价 随机森林回归算法是通过集成学习的思想将多棵树集成的一种算法,其基本单元是决策树,每棵决策树都依赖于一个随机向量,且所有向量独立分布[8]. 随机森林回归算法的建立可通过调用R语言中的“randomForests”程序包[16]来实现. 设原始数据集的样本数为N,自变量个数为m. 通过自助法(Bootstrap)重采样技术在原始数据集中有放回地抽取ntree个样本,从而构建ntree棵决策树,并在每棵树的每个节点上随机抽取mtry(mtry≤m)个预选变量. 每棵树最大限度生长,不做任何剪枝,然后将所生成的ntree棵决策树组成随机森林. 每次Bootstrap重采样未被抽取的数据称为袋外数据(Out-of-Bag,OOB),作为评价随机森林回归算法的测试数据集[17].

表1 用水总量影响因素Table 1 The factors for total water consumption
在建立随机森林回归算法的过程中,有2个重要的自定义参数:mtry和ntree. 一般地,mtry的值在变量个数的三分之一附近选取[18].ntree的值越大,算法表现越好. 随着ntree值的增大,袋外数据误差在显著降低后基本保持稳定. 为节省时间,取达到稳定时的ntree值即可[19].
随机森林回归算法可以对变量的重要性进行评价,其基本思想与过程是:(1)对于每一个变量,计算每棵树对应的袋外数据误差,记为ErrOOB1. 每个样本未被抽取的概率为(1-1/N)N,当N足够大时,(1-1/N)N将收敛于1/e≈0.368,即有将近37%的样本不会被抽取[11]. (2)对袋外数据的变量加入噪声干扰,即随机地进行序列改变,再次计算袋外数据误差,记为ErrOOB2. 则可通过分析袋外数据序列改变时袋外数据误差的增加情况来估计某一变量的重要程度.设变量重要性为M,则M=∑(ErrOOB2-ErrOOB1)/ntree. 这个数值能够说明变量的重要性是因为加入随机噪声后,袋外数据的准确率大幅度下降(即ErrOOB2上升),表明这项变量对于样本的预测结果有很大影响,即重要程度比较高[20].
1.3.2 熵值法原理及计算步骤 熵来源于物理学中的热力学概念,主要反映系统的混乱程度,现应用于统计学的各个领域[21]. 在信息论中,熵是一种不确定性的度量,而信息是对有序性的度量,二者绝对值相等,符号相反. 在由t个方案、s个评价指标所构成的指标数据矩阵X={xij}t×s中,数据评价指标的值差异越大,信息熵越小,则该指标提供的信息量越大,从而权重越大;反之,数据指标的值差异越小,信息熵越大,则该指标提供的信息量越小,从而权重越小[22]. 用熵值法确定指标权重,不易出现主观赋权法无法避免的随机性、臆断性问题,更具科学性和说服力.
熵值法计算步骤如下:
(1)指标的无量纲化. 本文选择极值法作为评价用水总量影响因素指标无量纲处理的方法,使指标数值全部转化在0~1的区间内.
正向指标运算公式为:

(1)
负向指标运算公式为:

(2)
其中,xij为第i个样本、 第j项指标的原始数值,Sj为xij的最大值,sj为xij的最小值,x′ij为无量纲处理后的数值.
(2)平移. 为使熵值法运算有意义,将无量纲化的数据全部平移一个最小单位值,以满足运算要求:
Zij=x′ij+A,
(3)
其中,Zij是平移后的数值,A为平移幅度.
(3)计算在第j项指标下,第i个城市的指标值占所有城市指标值之和的比重:

(4)
其中,t为样本城市个数,s为指标个数.
(4)计算第j项指标熵值:

(5)
其中,k=1/lnt,ej≥0.
(5)计算第j项指标的差异系数:
gj=1-ej.
(6)
(6)对差异系数归一化,计算第j项指标的权重:

(7)
(7)计算第i城市用水总量的影响因素综合得分:

(8)
(8)为了更直观地观察各城市用水总量影响因素的相对水平,本研究对各城市综合得分进行一定程度的区间控制,将广东省21个地级市的用水总量影响因素得分(F′i)按照中位数原则调整到1~10之间[23]:
(9)
2 结果分析
2.1 元素重要性分析
采用随机森林回归算法,对广东省21个地级市影响用水总量的9个元素(常住总人口、人口密度、水资源总量、降雨量、万元GDP用水量、万元工业增加值用水量、第一产业生产总值、第二产业生产总值、第三产业生产总值)进行重要性排序. 本文的元素层共9个元素,可得:m/3=3,mtry分别取2、3、4进行试算,得到最优试算参数(mtry=3). 然后,根据mtry的值确定ntree的值,由广东省用水总量影响元素的决策树数量与误差关系(图2)可知:当ntree=500时,误差趋于稳定且达到最小.

图2 广东省用水总量影响元素的决策树数量与误差关系
使用随机森林回归算法可以得到2018年影响广东省用水总量的元素相对重要性(图3),可知:(1)常住总人口对广东省用水总量影响最大,相对重要性占比为21.61%. 广东省具有人口总量大、增量高的特点:自2006年以来,广东省常住人口数连续13年位列全国第一;2018年达11 346万人,比2017年增加177万人,是全国唯一一个常住人口增量突破百万大关的省份[24]. 而人口规模对用水量的上升具有明显的推动作用[25]. (2)对广东省用水总量影响较大的元素为第三产业生产产值,说明服务业的发展对广东省用水总量影响程度较高. 广东省是我国重要的服务业基地. 2018年,全省第三产业产值为55 689 万元,位列全国第一,且在全省GDP占比达55.12%[24]. 第三产业对区域经济发展具有强大的辐射带动作用的同时,亦需消耗大量的水. (3)降雨量对广东省用水总量影响最小,相对重要性占比仅为1.85%. 有研究[26]表明部分地区的用水总量很大程度上与气候的湿润度有关,具体表现为气候越湿润,用水总量越少. 这与本文所得结果不一致,表明用水总量的关键驱动因素是因地而异的.
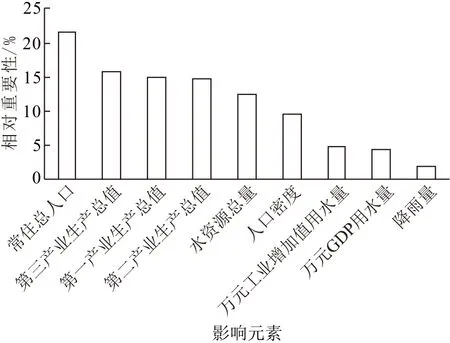
图3 广东省用水总量影响元素的相对重要性
2.2 因素重要性分析
为了从宏观上更好地把握广东省用水总量的驱动因素,本文对4项因素进行重要性排序. 由于4项因素并没有直接的数据,所以先对4项因素进行量化,将得到的具体数值作为随机森林回归算法的输入. 根据熵值法计算步骤,对2018年广东省21个地级市9个用水总量影响元素的数据进行标准化处理,从而得到其熵值及在4项因素中所占的权重(表2),并进一步量化出广东省21个地级市用水总量影响因素的得分情况(图4).

表2 各元素熵值及权重Table 2 The entropy value and weight of each element

图4 广东省21个地级市用水总量的影响因素得分
将广东省21个地级市用水总量的4项影响因素(人口因素、水资源因素、技术因素、经济因素)的综合得分输入到随机森林回归算法中,得到因素相对重要性的排序结果(图5). 本文共有4项影响因素,则m/3≈1,mtry分别取1和2进行试算,得到最优模型参数(mtry=1). 由于此次输入数据量较小,ntree取默认值(即ntree=500).

图5 广东省用水总量影响因素的相对重要性
由广东省用水总量影响因素的相对重要性(图5)可知:(1)经济发展水平对广东省用水总量的影响最大. 广东省是改革开放的前沿阵地,长期以来的经济发展稳中有升,多项经济指标位居全国前列[24]:2018年,广东省的地区生产总值为9.73万亿元(排名全国第一),人均地区生产总值为86 412元(排名全国第六)[24]. 一方面,对于产业而言,经济发展离不开生产要素的投入,而水资源是重要要素之一[5];另一方面,对于家庭而言,高人均地区生产总值带来用水电器的普及,从而消耗大量水[27]. (2)人口因素在广东省用水总量影响因素相对重要性中排名第二,仅次于经济因素. 人口规模越大,需要消耗的生活用水量越大,亦需消耗更多生产及消费的产品,即需要消耗更多的水资源. (3)排在第三位的是水资源因素. 广东省河流众多,以珠江流域、韩江流域和粤东沿海、粤西沿海诸河为主,集水面积占全省面积的99.8%[28];气候类型为热带亚热带气候,降水充沛. 而水资源越丰富的地区,用水所受限制越小,用水总量越高[25]. (4)技术因素对广东省用水总量的影响最小. 一个地区的技术水平越高,用水总量越少[7]. 尤其对于工业等用水总量较多且技术水平具有较大提升空间的用水领域,采用更加优良高效的技术会在一定程度上减少用水总量. 而经济水平高的地区会在技术方面投入更多的节水设备,从而有助于用水总量的减少. 例如:广东省的珠三角地区是全国科技创新与技术研发基地,也是全国经济发展的重要引擎. 深圳市作为珠三角地区经济发展的龙头,2018年每万元GDP的用水量仅为9 m3,但同时期梅州市这一指标是其21倍[29],说明经济对技术具有显著的正反馈作用,而技术水平的提高会使得用水总量减少. 就目前而言,技术因素对广东省用水总量的影响程度较低,具有较大的发展潜力,提高技术水平可作为未来广东省降低用水总量的重要途径之一.
3 结论
本文通过构建熵值法和随机森林回归算法相结合的综合评价体系来分析广东省用水总量的影响因素,对2018年广东省21个地级市用水总量进行实证分析. 主要结论如下:
(1)从元素层角度分析,常住总人口、第三产业生产总值和第一产业生产总值是广东省用水总量的主要影响元素,而降雨量对广东省各地级市用水总量影响最小.
(2)从因素层角度分析,4项因素对广东省用水总量的影响由大到小依次为:经济因素、人口因素、水资源因素和技术因素.
(3)综合元素层和因素层的分析,在人口、 水资源、 技术、 经济因素中,影响广东省用水总量最大的元素分别为常住总人口、 水资源总量、 万元工业增加值用水量和第三产业生产总值.
对区域用水总量进行合理规划,可为水资源的可持续利用提供参考. 本研究选择用水总量影响因素时主要参考了其他文献的指标选取方式,如何更全面、客观、因地制宜地选取评价指标,是后续研究需要进一步考虑的因素.
猜你喜欢
计算机仿真(2022年4期)2022-05-14
今日农业(2021年3期)2021-12-05
今日农业(2021年10期)2021-11-27
今日农业(2021年16期)2021-11-26
建材发展导向(2021年18期)2021-11-05
财经(2021年22期)2021-10-28
小学科学(2021年5期)2021-06-24
发明与创新·大科技(2017年8期)2017-08-17
法人(2014年4期)2014-02-27
中学英语之友·高二版(2008年2期)2008-04-08
