
基于Spark的实时AIWERS的设计与实现
2021-03-08 10:20杨齐成
安徽开放大学学报 2021年1期
杨齐成
(安徽广播电视大学 滁州分校,安徽 滁州 239000)
一、引言
随着互联网和云技术的快速发展,我国依托大数据技术支持,正大力推进教育大数据平台(E-Learning Platforms)的建设。目前全国各省市为适应教育信息化时代发展需求,纷纷建设基于web的学习管理系统(Learning Management Systems,LMS)。但是,这些系统仅单纯提供视频课程在线播放、学习资料下载、在线讨论、考试等功能,缺少个性化推荐和智能分析能力,不能满足社会需求。
为帮助教育决策者更高效地判断当前课程安排的合理性,实时洞察学生对当前课程的学习程度,分析学生学习行为,帮助学生制定个性化的学习计划,出现了许多具有自适应性和智能性的教育系统(Adaptive and Intelligent Web-based Educational Systems, AIWES), 此类系统通常基于大数据分析算法、数据挖掘算法和AI算法设计。例如,2017年LI Yuqian等人利用Spark技术建立了高等教育监测平台,为其学校教育决策提供依据;2016年,ZHANG Guigang等人提出了“Online Education Big Data Platform”;2019年,沈贵庆利用Hadoop技术对教育资源进行分析和处理,结合挖掘分析算法和云计算技术深入分析学生行为数据并预测学生表现。基于以上研究可知,教育大数据的分析和挖掘已经得到社会的广泛认可。但是,目前这些研究仅仅是分析学生行为数据,缺少基于web端的学生个性化课程推荐。
因此,本文的出发点是为电大学生提供个性化的课程推荐指导,辅助学生找到更合适的学习教程。而推荐系统核心就是推荐算法,目前主流的推荐算法有协同过滤算法(Collaborative Filtering)、基于知识(Knowledge-based)的推荐、基于关联规则(Association Rule)的推荐、基于内容(Content-based)的推荐和混合(Mixed)推荐。
二、Spark生态系统
Spark是一种专为大规模数据处理而设计的快速通用计算引擎,2009年由美国Berkeley AMP 实验室设计问世,最初仅仅是学术项目。Spark与Hadoop一样,也有生态系统,包括SparkCore、Spark SQL、Spark Streaming、MLlib和GraphX等组件。Spark特有的RDD策略保障了实时计算的高效性,省去了MapReduce框架计算过程的临时数据先落地步骤,有效减少IO开销。其中Spark MLlib包含了许多主流的AI算法,针对集群上不同的迭代计算具有先天优势。
三、AIWERS系统设计
(一)系统架构
本文设计并实现结合大数据Spark平台构建基于web的教育自适应智能推荐系统(Adaptive and Intelligent Web-based Educational Recommend Systems, AIWERS),系统架构如图1所示。
在该AIWERS中,当一个学员访问系统时,会为其提供更合适的学习视频推送信息。当未注册的学生浏览本系统时,如果学生没有明确想学习的视频,可以在首页关键词搜索,系统分析搜索记录和视频评分,实时给出推荐视频。当老学员登录时,根据其数据库信息,结合已存储的离线训练模型,直接为老学员推荐其感兴趣的课程视频。
架构设计主要包括3个部分:(1)WebUI 和实时数据接收层,采用Flume实时数据采集工具,将网页用户行为数据传输到kafka消息队列中,供计算层使用。(2)基于Spark的计算处理层,该层架构分为两个组成模块,离线模型训练模块和实时推荐模块,离线模型训练基于数据库表中存储的学生和评分数据关系训练推荐模型,并将模型保存在HDFS上,方便调用。实时推荐模块,根据网页学生关键词搜索情况,实时推荐关键词相关的课程给学生。(3)数据存储模块,MySQL和HDFS,关系型数据库负责记录学生、课程和评分等基本信息,HDFS负责存储离线训练模型,实时推荐算法模型和学生视频评分矩阵。
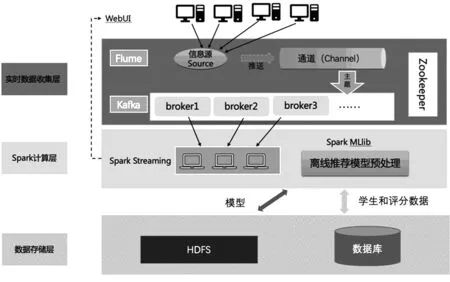
图1 基于Spark的实时推荐AIWERS架构
(二)设计内容
1.Spark实时数据采集设计
本模块结合基于Spark Streaming,Flume和Kafka,Zookeeper大数据组件,实时采集学生网页的行为数据,例如当前学生搜索关键词,网页停留时间和视频观看时长等,传输实时数据进入推荐模块,并将结果实时返回给网页端。
Spark Streaming先按时间为切分单位,将实时的“输入数据流”DStream划分块,再将该块作为一个RDD,使用RDD函数处理每一条数据。本架构中先创建Java Streaming Context和 Java Spark Context对象,读取Spark集群相关信息,然后创建输入数据流KafkaStream对象,读取指定brokerlist的IP和端口号,实现主题队列中消息的逐条消费。相应的DStream转换过程如图2所示。KafkaRDD 是Kafka Direct Stream按照时间段划分而成,通过Map函数将消息映射到集群节点中,再通过Coalesec函数对每个RDD计算推荐结果汇集到指定分区保存,最后将SaveRDD的结果保存在HDFS中。实时采集的数据信息如图3所示。
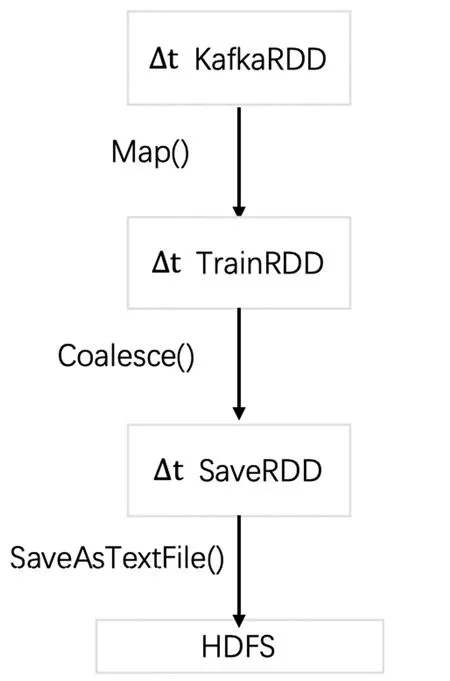
图2 Spark实时采集和推荐的DStream转换

图3 实时数据
2.推荐模块设计
本架构中推荐模块的设计如图4所示。
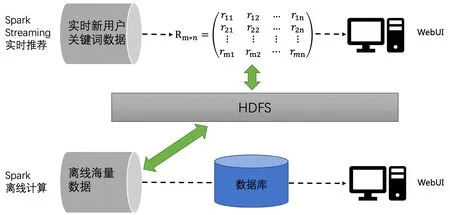
图4 推荐模块架构
(1)离线模型训练
在系统的开发中,将预先导入60多万条数据到MySQL数据库中,其中包括2000名学员对300个视频课程的评分。本架构采用Spark MLlib中的协同过滤算法。基于ALS模型,公式如下所示:
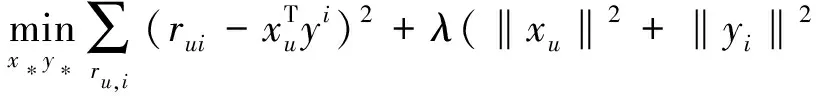
x
,y
和r
分别是学员偏好矩阵、视频偏好矩阵和预测矩阵,我们的目标是寻找最优x
和y
,使得预测矩阵和r
之间误差最小。通过使用ALS.train()训练模型,并通过计算均方差MSE
来评估推荐模型,步骤如下:1)加载数据集并转换成RDD; 2)对RDD进行Transformation和Action处理;3)设置模型model中其他参数:潜在因子个数rank
(默认值10),算法的迭代次数numiterations
(默认值10)和正则化参数lambda
(默认值1); 4)ALS.train()函数对RDD进行模型训练,给出预测评分;5)根据实际评分,计算MSE
值;6)选择MSE
最小的模型作为推荐模型。该部分核心算法基于scala语言如下所示。SparkMLlib离线ALS模型训练核心代码
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.
MatrixFactorizationModel
import org.apache.spark.mllib.recommendation.Rating
//Load
and
parse
the
data
val data = sc.textFile("data/mllib/als/test.data")
val ratings = data.map(_.split(',') match { case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
//Build
the
recommendation
model
using
ALS
val rank = 10
val numIterations = 10
val model = ALS.train(ratings, rank, numIterations, 0.01)
//Evaluate
the
model
val usersProducts = ratings.map { case Rating(user, product, rate) =>(user, product)
}
val predictions =
model.predict(usersProducts).map { case Rating(user, product, rate) =>((user, product), rate)
}
val ratesAndPreds = ratings.map { case Rating(user, product, rate) => ((user, product), rate)
}.join(predictions)
val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println(s"Mean Squared Error = $MSE")
//Save
and
load
model
on
HDFS
model.save(sc, "hdfs://target/ ALS")
(2) 实时推荐
实时推荐部分主要针对实时数据流,涉及的数据均是在线实时产生,需要及时给出结果,相对离线计算部分,对时间性要求比较高,但是仅适合处理少量数据和比较简单的算法。因此本部分采用基于用户的协同过滤算法(User-Based CF),并将此用户提交的视频评分存入数据库。UBCF主要思想是通过学生间的关联关系,找出与新用户兴趣相近的学生,并根据他们的喜好来进行视频的推荐。例如A,B和C三个学生,分别对视频(a,b,c,d)给出评分(5,,5,),(1,5,,)(5,1,5,5),其中“”表示未评分,观察可知A和C均喜欢视频a和c,可以认为A的邻居是C,且C还喜欢d视频,由此可以把视频d推荐给A。UBCF基于学员对学习视频课程的打分,评分数据可以采用矩阵形式作为文件存储在HDFS上。如图5所示。
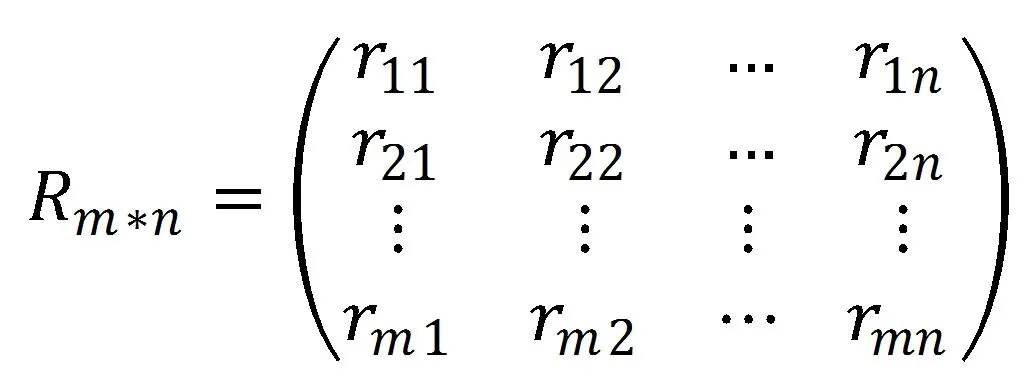
图5 UBCF矩阵
矩阵R
*指的是m个学生,n个视频。每个学员对所学视频的评分,可以看成是n维的空间向量,这样计算学员相似性的问题转换成计算空间向量的相似度。公式如下所示: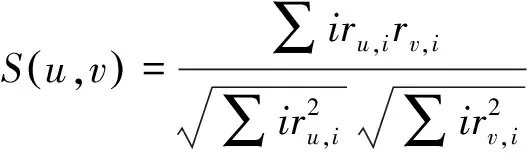
(1)
其中r
表示学生u的评分集合,r
表示学生v的评分集合,i
表示视频。基于公式(1),结合KNN最近邻算法可以得到与目标学生最近的n个学生,从而获得推荐结果。核心代码如下所示。
基于UBCF实时推荐核心代码
Public double[]getsimilarityMatrix(int [][] preference, int i){
Double[]similarityMatrix = new double [PREFOWCOUNT];
For(int j=0;j< PREFOWCOUNT;j++){
If(j==(i-1)){
Countine;
}
SimilarityMatrix[j]= new ComputeSimilarity().computeSimilarity(preference[i-1],preference[j]);
}
ReturnsimilarityMatrix;
Public List
List
Double[] matrix =new double[COLUMNCOUNT];
Int[] id =new int[KNEIGHBOUR];
Double [tempSimilarity]= new double[similarityMatrix.length];
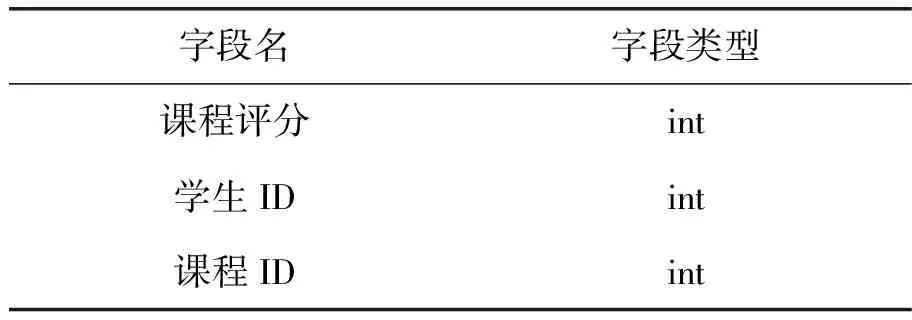
for(int j=0;j tempSimilarity[j]=similarityMatrix[j]; } Arrays.sort(tempSimilarity); Int flag=0; Double [] similarity =new double[KNEIGHBOUR]; For(int m=tempSimilarity.length -1;m>=tempSimilarity.length- KNEIGHBOUR;m--){ For (int j=0; j If(similarityMatrix[j]==tempSimlarity[m]&& similarityMatrix[j]!=0.0){ Similarity[flag]=temSimilarity[m]; Id[flag]=j; flag++; } } } 当把近似学员变量设定为10时,并把推荐视频结果设置为3时,如图6所示。以学员ID号3050为例,同样选择340课程的学生相关近似度推荐并给出了可能的预测评分。 图6 学员ID=3050号学员实时推荐结果 3.数据存储模块 存储部分主要包括学员信息表,视频课程信息表和课程评分数据表的存储等。数据库的设计采用MySQL关系型数据库,主要包括学生信息表和课程信息表,如表1~3所示。数据基于滁州电大分校(含6个县级工作站)10 000余名学生样本和2000多视频课程。 HDFS(Hadoop Distributed File System)来源于GFS,采用三幅本容错技术保障集群系统的高可用性,主要负责存储本架构中的离线算法模型和实时推荐模型。 表1 学生信息表 表2 课程信息表 表3 课程评分信息表 AIWERS在开发过程中,采用完全分布式部署方式配置了Spark集群环境,包括5台计算机,其中1台作为Master节点,剩余4台均为Slaves,Zookeeper、Flume、Kafka组件分别在不同节点上。 本文设计并实现了基于Spark框架技术的实时AIWERS架构,并且针对主要模块给出了详尽的阐述,为开放大学的自适应智能推荐系统技术方案提供一定的参考和借鉴价值。


四、结语
