
基于显著性检测的图像隐写分析方法
2021-03-07 05:16黄思远张敏情毕新亮
计算机应用 2021年2期
黄思远,张敏情*,柯 彦,毕新亮
(1.武警工程大学密码工程学院,西安 710086;2.网络与信息安全武警部队重点实验室(武警工程大学),西安 710086)
(*通信作者电子邮箱aqi_zmq@126.com)
0 引言
长期以来,图像隐写术和图像隐写分析一直在相互斗争中发展[1-2]。图像隐写术致力于将秘密信息尽可能地隐藏在图像中,并尽可能减少图像在视觉质量和统计特征方面的变化;图像隐写分析则利用图像处理和机器学习理论来分析隐写图像和载体图像之间的统计差异,并通过增加特征数量和增强分类器性能来提高检测精度。图像隐写分析的困难在于隐写分析模型无法完全有效地建模隐写操作在图像中嵌入秘密消息时发生的细微差异。近几年提出的图像自适应隐写术利用最小失真函数用优先选择图像的纹理复杂区域进行嵌入,秘密信息更巧妙地隐藏在难以建立隐写分析模型的区域中,加大了检测的难度,提高了隐写技术的安全性,给图像隐写分析带来了严峻的挑战。
为了对抗图像自适应隐写术,传统的图像隐写分析需要考虑更复杂、更高维的图像统计特性。Fridrich 等[3]提出的富模型将多种相异特征融合于一体,使用集成分类器进行训练,取得了不错的效果。但是也面临诸多困难:首先,算法设计的复杂度高、难度大;其次,特征参数的调节需要花费大量的时间和精力,导致实验效率低下。
近年来,深度学习的发展使得传统的图像隐写分析中提取特征和分类这两个步骤统一起来并实现自动化,使端到端的方法成为可能,并取得了很好的效果。2015年,Qian等[4]提出一个具有5个卷积层的网络结构,使用KV 核作为预处理层对图像进行预处理,使得模型能够直接对残差图像进行学习,降低了图像内容对训练的干扰。2016 年,Xu 等[5]提出的Xu-Net 使用KV 核作为高通滤波器(High-Pass Filter,HPF)层对图像进行预处理操作。该网络中使用5 个卷积层:为了防止网络模型过拟合,前两个卷积层的卷积核为5× 5,而随后的卷积层中则使用1× 1大小的卷积核;每个卷积层中均使用了批量标准化(Batch Normalization,BN)操作;前两个卷积层后使用双曲正切(Hyperbolic Tangent,TanH)激活函数,其他卷积层使用修正线性单元(Rectified Linear Unit,ReLU)激活函数;每个卷积层通过均值池化来减小特征图的维度。2017 年Ye 等[6]提出了Ye-Net,该网络使用了更深的10 层卷积网络结构,并且使用30个空域富模型(Spatial Rich Model,SRM)卷积核作为预处理层来让模型学习更多的特征。Ye 等在文献中设计了新的截断线性单元(Truncated Linear Unit,TLU)作为激活函数,通过适当地设置参数T(一般取3 或7)使网络能够更好地适应隐写噪声分布;Ye-Net还通过通道选择,进一步改善了 该模型的检测效果。2018 年,Boroumand 等[7]提出了SRNet,该模型整体由四部分不同作用的卷积层模块组成,有效地利用了BN 层和残差网络,并且加入通道选择,提高了模型对隐写算法的检测准确率。2019 年,Zhu 等[8]提出的Zhu-Net使用3× 3核代替传统的5× 5核,并在预处理层优化卷积层,提高了对空域隐写术的检测精度。
然而,现有的基于卷积神经网络(Convolutional Neural Network,CNN)的模型提取的特征仍然存在大量冗余,这意味着特征的大部分维度都是无用的,尤其在检测图像自适应隐写算法时,嵌入变化通常被限制在难以建模的复杂纹理和边缘区域,而并非图像的所有区域。针对此问题,本文提出了一种基于显著性检测的图像隐写分析方法,通过对数据进行预处理引导模型在训练时提高对图像隐写区域特征的关注度,从而提高模型的训练效果以及检测准确率。
本文的主要工作包括:
1)提出了一种基于显著性检测的图像隐写分析方法,引导模型对图像隐写区域特征进行针对性的学习;
2)对训练集进行数据统计分析,并在训练中采取不同的训练策略,对比各种策略给训练效果带来的影响;
3)在空域和JPEG 域上针对不同嵌入率和自适应隐写算法进行验证,实验结果表明本文提出的方法可以有效地提升隐写分析模型的检测性能;
4)对模型在不同载体源、不同隐写算法及不同嵌入率的情况下进行了失配测试,测试结果表明本文方法具有较好的泛化能力和实用性。
1 相关工作
1.1 图像自适应隐写术
图像自适应隐写术是现代图像隐写术方案中安全性最高的技术,它通过基于嵌入成本调整嵌入位置来提高抗检测能力[9]。许多目前可用的自适应隐写算法,如HUGO[10]、WOW[11]、S-UNIWARD[12]、UED[13]和J-UNIWARD[12],都具有很高的抗检测能力,并且它们中的大多数是在最小化失真函数的框架下设计的。在该框架中,首先根据失真函数为每个覆盖元素的改变分配成本,然后通过使用一些编码技术,如STC(Syndrome Trellis Code),根据失真情况,综合考虑确定最终要改变的元素,从而使整体失真最小化。
文献[2]对图像自适应隐写进行了形象的描述,如图1 所示,由于在图像纹理复杂区域进行隐写操作可以减少图像在视觉质量和统计特征方面的变化,所以图像中位于纹理复杂区域的元素被修改概率较大。因此,对隐写算法修改概率更高的区域进行更有侧重的检测,将有利于提升隐写分析的效果。自适应隐写算法修改概率的损失函数计算方法为

其中:βi,j为位于图像位置(i,j)的元素被修改的概率值;λ为大于零的数值,具体数值由隐写的相对嵌入率决定。

图1 原始图像及其对应的隐写点图和嵌入修改概率图Fig.1 Cover image and the corresponding stego image and embedding probability image
1.2 显著性检测
显著性检测是计算机视觉中的一个重要且具有挑战性的问题,其目的是自动发现并定位与人类感知一致的视觉感兴趣区域。近年来,显著性检测在目标跟踪[14]、图像压缩[15]、图像分割[16]、场景分类[17]等任务中得到了广泛的应用。
每个图像的特征可以在低级、中级、高级三个不同的层次上表示:低层特征与原始图像的颜色、边缘、纹理有关;中层特征主要对应于物体的轮廓、形状和空间环境信息;高层特征与背景、对象识别以及对象间的内在语义交互有关。如何在统一的学习框架下对上述因素进行有效的建模,是显著性检测中需要解决的关键和具有挑战性的问题。
传统的显著性检测通过纯数学的方法,在不需要训练模型的情况下识别出显著性区域。如Itti 等[18]受灵长类动物启发,在KU 视觉注意模型的基础上提出了一种经典的显著性检测方法:针对多尺度图像,不同的空间位置通过竞争获取显著性,然后通过显著图融合获得显著性区域,并且在模型后端设计了一种winner-take-all 激活网络,模拟人类视觉动态更新关注点的位置。Cheng 等[19]使用稀疏直方图简化图像颜色表示,采用基于图的分割方法将图像划分为多个区域,根据空间位置距离加权的颜色对比度之和计算图像区域的显著性。在人工智能兴起之后,深度学习技术也广泛地应用于显著性检测。Zhang 等[20]提出了控制浅层和深层特征的双向传递,以获得准确的预测;Chen 等[21]采 用HED(Holistically-nested Edge Detection),通过使用逆向注意模型迭代地细化其输出;Liu 等[22]通过上下文注意网络预测像素级注意图,将其与U-Net 结构结合起来检测显著性区域。虽然这些方法提高了显著性检测的标准,但在精细结构段质量和边界精度方面仍有很大的改进空间。针对此问题,Qin 等[23]提出了一种基于边界感知的显著性检测模型BASNet,该模型通过融合二值交叉熵(Binary Cross Entropy,BCE)、结构相似性(Structural SIMilarity,SSIM)和交并比(Intersection-over-Union,IoU)三种损失函数,引导网络更加关注边界质量,精确分割显著性区域,并且使显著性区域边界更加清晰,如图2所示。

图2 BASNet处理效果图Fig.2 Processing renderings of BASNet
2 基于显著性检测的图像隐写分析方法
在BASNet模型的启发下,本文提出了一种基于显著性检测的图像隐写分析方法,利用显著性检测技术对训练数据进行预处理,引导模型增加对隐写区域特征的关注度,并且减少训练中不利特征的干扰,从而提高模型的训练效果和检测性能。本文提出的方法整体框架如图3 所示,主要由显著性检测模块、区域筛选模块和判别器模块组成。
首先由显著性检测模块分割出判别错误图像的显著性区域,形成显著性图。其次,由区域筛选模块对符合预处理要求的图像进行筛选,保证处理的合理性和有效性,而后将筛选出的符合要求的图像与其对应的原始图像进行图像融合,形成显著性融合图;不符合要求的显著性图则用其对应的原始图像替换。最后,将符合要求图像的显著性融合图和不符合要求图像的对应原始图像合并,形成更新后的数据集,输入判别器模块进行训练,使判别器对与隐写区域重合度较高的区域进行有针对性的特征学习,从而提高模型的训练效果和检测精度。

图3 基于显著性检测的图像隐写分析方法整体框架图Fig.3 Framework of the method for image steganalysis based on saliency detection
2.1 显著性检测模块
显著性检测模块用于生成待测图像的显著性区域。对于不同内容和纹理的图像,隐写分析算法的检测能力是有限的,然而现有的检测方法通常不区分不同内容和纹理的图像,将它们放在同一个数据集中进行训练和分类。如果判别器对图像中高强度的隐写噪声敏感,那么也可能对图像中低强度的隐写噪声敏感;但是,如果判别器对图像中低强度的隐写噪声敏感,则不确定是否对图像中高强度的隐写噪声也敏感[24]。如图4 所示,对于内容和纹理较为简单的原始图像I1,噪声强度量化为S1;隐写后的图像为I1′,噪声强度为S1′,这里满足表达式S1′>S1。同时,对于另一幅原始图像I2,它的内容和纹理比I1略为丰富和复杂,噪声强度量化为S2,有S2>S1,则存在S1′≈S2的情况,即本来没有隐写的原始图像,其特征复杂度与隐写图像达到了同一程度,并且从I1′提取的特征也近似等于从I2提取的特征。最终,原始图像和隐写图像就会被判别器误认为是同一类。

图4 误判原因示意图Fig.4 Schematic diagram of error detection
针对上述问题,本文从特征提取方面入手,分析了图像自适应隐写嵌入区域的特征与显著性检测标注区域的特征之间的关联。图像自适应隐写通过STC使图像在经过隐写后的失真最小化,而其最直观的表现为秘密信息嵌入在图像纹理复杂的区域,从人类视觉的角度分析,这部分区域就是与周围区域有较强对比度或明显不同的区域,即图像中最为显著的区域;显著性检测则通过对人类视觉的模拟,将有限的计算资源分配给图像中更重要的信息,即使模型对图像中的显著性区域进行标注,所以图像自适应隐写的嵌入区域与显著性检测的标注区域在其特征内容上存在很大程度的相关性。
基于上述分析,本文将计算机视觉领域的显著性检测模型引入图像隐写分析,使模型能够将图像中最可能进行隐写的区域标注出来,其他区域则忽略。因此,模型在训练中更容易学习原始图像和隐写图像在噪声强度上的差异特征,减少出现误判的情况,从而提高其训练效果和检测能力。
在显著性检测模块,本文将文献[23]中BASNet的预测模块和多尺度残差优化模块引入网络。
预测模块的设计灵感来源于U-Net[25],该网络的主要目的是通过处理得到一个粗糙的显著性图。多尺度残差优化模块首先对比粗糙显著性图和真实标注之间的残差,而后通过学习来进一步优化粗糙显著性图,最终提高显著性图的图像质量,其结构如图5 所示。本文通过对多尺度残差优化模块的利用,使模型能够更准确地分割出隐写区域,为下一步的图像融合提供更好的实施基础。
该模型算法的中心思想在文献[22]中表示为:

其中,Scoarse、Sresidual和Srefined分别表示预测模块的残差、显著性图和真实标注的残差以及优化后的残差。该模型主要架构由输入层、编码器、桥接层、解码器和输出层组成。编码器和解码器都有四个阶段(如图5 虚线框标注),每个阶段由一个卷积层和64 个大小为3× 3 的过滤器组成,采用批量归一化(BN)和ReLU 激活。桥接层设置一个卷积层,参数与其他层相同。编码器中的下采样用最大池化层(maxpool),解码器用双线性上采样层(bilinear upsample)。显著性检测模块输出模型的最终显著性图。为了获得高质量的区域细分和清晰的边界,文献[22]还对该模型在训练时定义了一种混合损失ℓ(k),表示为:

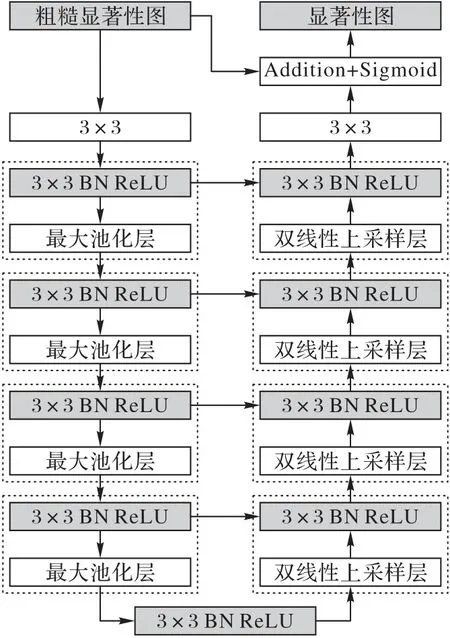
图5 多尺度残差优化模块结构Fig.5 Structure of multi-scale residual refine module
该损失结合了BCE、SSIM 和IoU 损失,有助于减小交叉传播在边界上学习信息而产生的虚假误差,使边界更加精细化。为了提高实验效率,本文采用迁移学习的方式调用在显著性检测数据集ECSSD[26]上预训练的BASNet模型来进行实验。
在经过显著性检测模块处理后,本文对图像的显著性区域与隐写区域进行对比分析,如图6 所示。从对比分析中可以看出,区域重合度存在两种情况:第一种是图像中显著目标较为明确时,经过处理后的显著性区域与隐写区域重合度较高;第二种是图像中显著目标较为模糊时,经过处理后的显著性区域与隐写区域重合度较低。因为显著性区域与隐写区域重合度较低的图像不符合实验要求,所以需要设计一个区域筛选模块,将符合要求的图像筛选出来,保证处理的合理性和有效性。
2.2 区域筛选模块
区域筛选模块用于将符合处理要求的图像筛选出来。在进行图像自适应隐写操作时,由于其最小化失真函数的框架,所以秘密信息会优先选择纹理较为复杂的区域进行嵌入,即图像中最显著的区域,因而显著性检测技术中会将这部分区域标注出来。
本节首先利用数据集BOSSbase1.01[27]对显著性区域与隐写区域的重合度进行数据的统计与分析。进行分析的图像数量为10 000,质量因子为75,自适应隐写算法为J-UNIWARD,嵌入率为0.4 bpnzAC(bits per none zero AC)。为了对数据分布情况进行整体的分析,本文设计了一种显著性区域和隐写区域的重合度η的计算方法:
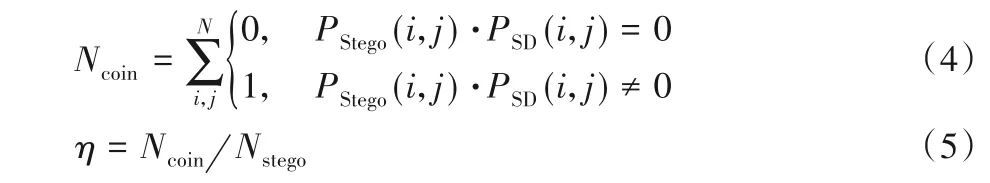
其中:N表示图像中像素点的总数,Ncoin表示重合区域的像素点的个数,Nstego表示隐写区域的像素点个数,PStego(i,j)和PSD(i,j)分别表示隐写点图和显著性图在位置(i,j)的像素值。本文利用该算法将10 000张图像的显著性区域和隐写区域的重合度进行数据统计,如表1所示。
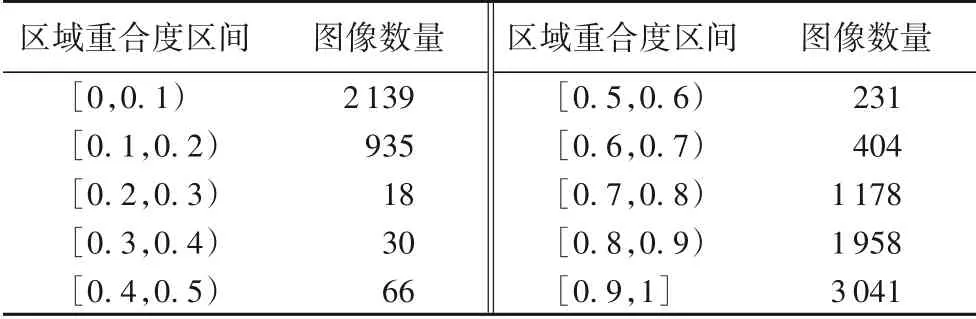
表1 显著性区域和隐写区域的重合度统计Tab.1 Statistics of coincidence rate of saliency regions and steganography regions
由表1 可以看出显著性区域和隐写区域的重合度主要分布在[0,0.2)和[0.5,1],而重合度小的图像并不适合进行显著性处理,因此,需要利用区域筛选模块对图像进行筛选,保证处理的有效性。

图6 显著性图与隐写点图的对比Fig.6 Comparison of saliency images and stego image
本文通过实验对比分析,将区域筛选模块中筛选区域的阈值K设为0.7,即筛选出显著性区域和隐写区域的重合度集中在[0.7,1]的图像,具体在3.3 节详细阐述。而后利用图像融合技术,将显著性图与原始图像进行融合,其目的是将图像中显著性区域以外的像素置0,引导模型只关注显著性区域的图像特征,如图7所示。
2.3 判别器模块
初始检测错误的图像以及更新后数据集的重新训练都需要判别器模块来进行处理。图8 展示了由文献[7]提供的判别器模型SRNet的细节。
SRNet 模型共有四部分:前两个部分为1~7 层,主要功能是提取噪声的部分残差;第三部分为8~11 层,主要功能是降低特征图的维数;第四部分包括全连接层和Softmax 分类器。第12 层计算每个特征图的统计矩,并将特征向量输入分类器。其中,卷积层都采用3× 3 的卷积核;1~7 层不采用池化层;8~11 层采用3× 3 的池化层,步长为2;非线性激活函数均为ReLU。
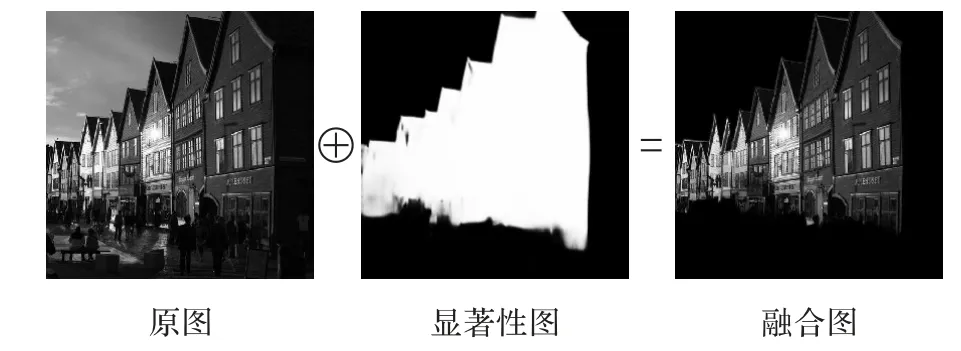
图7 图像融合示意图Fig.7 Schematic diagram of image fusion
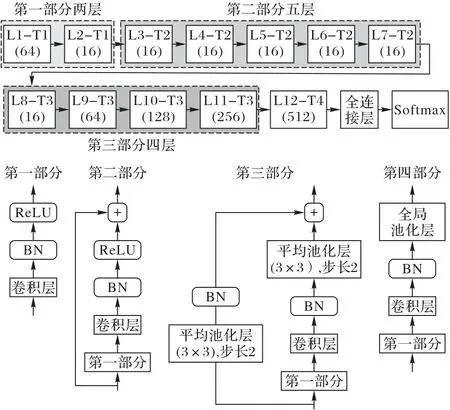
图8 SRNet模型结构Fig.8 Structure of SRNet
3 实验与分析
3.1 数据集及实验平台
本实验在Windows 10 操作系统下运行,深度学习框架为TensorFlow-gpu 1.15.2,编程语言为Python 3.6.6,显卡为NVIDIA V100(32 GB),计算架构为CUDA 10.0,依赖包为cudnn7。实验数据集采用的是BOSSbase1.01,分别在空域和JPEG 域进行实验验证:对于空域,使用S-UNIWARD、HUGO、WOW 和HILL[28]自适应隐写算法进行隐写,嵌入率为0.1~0.4 bpp(bits per pixel);对于JPEG 域,首先对空域图像进行JPEG 压缩,转换为质量因子为75 和95 的JPEG 图像,而后使用J-UNIWARD 和JC-UED[29]自适应隐写算法对图像进行隐写,嵌入率为0.1~0.4 bpnzAC。
3.2 实验参数
为了保证显著性检测的质量和效果,与文献[7]不同,本文对于数据集不作任何尺寸的调整,使用分辨率为512 × 512的原始图像进行实验,实验中,随机选取4 000 张图像作为训练集,1 000 张图像作为验证集,5 000 张图像作为测试集,设置训练集每一批次(batchsize)为32,验证集为40,判别器使用SRNet模型,初始学习率(learning_rate)为0.001,运用Adam[30]优化器,最大迭代次数为50 0000。在对比实验过程中,本文提出的方法以及对比方法采用相同的训练集、验证集和测试集,并且三个数据集的图像互不重复。
3.3 实验结果与分析
3.3.1 不同训练策略的实验结果对比
为了验证本文方法的隐写分析性能,在使用J-UNIWARD自适应隐写算法进行隐写,嵌入率为0.4 bpnzAC,图像质量因子为75 的情况下,分别对替换所有图像、替换所有检测错误的图像、替换经过区域筛选模块后合适的图像这三种训练策略进行对比实验,结果如图9 所示。第一种训练策略为替换所有图像,实验结果显示模型的训练效果很差,检测准确率很低,并且难以收敛,因为模型在训练时无法很好地学习图像本身的特征;第二种训练策略为只将判别器检测错误的图像替换为显著性图,这种训练策略的检测准确率较第一种训练策略有明显提升,因为模型对学习错误的特征进行了针对性的训练;第三种训练策略为只将经过区域筛选模块处理后合适的图像替换为显著性图,实验结果表明,第三种训练策略的效果最优,并且收敛较快。
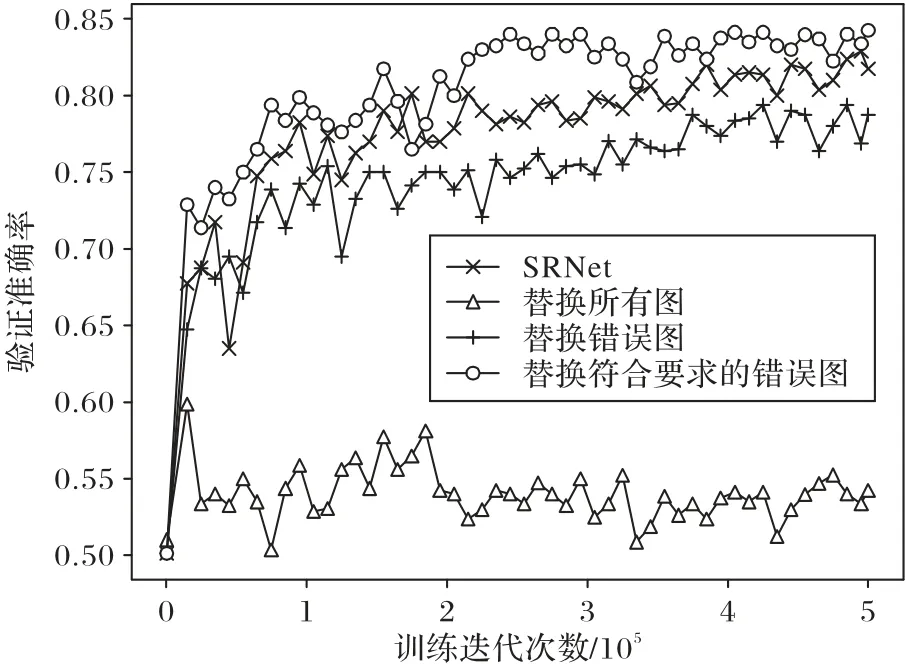
图9 不同训练策略的实验对比Fig.9 Comparison of different training strategies
对于区域筛选模块的筛选阈值K,本文也进行了实验分析,通过实验比较了在不同区域筛选阈值下训练的模型性能,其中K取0.6,0.7,0.8 三个值,实验结果见表2。从实验结果可以看出区域筛选阈值对检测性能有着一定的影响。当K=0.6 时,检测准确率下降较多,其原因是部分显著性区域与隐写区域重合度较低的图像存在一定的冗余,不利于模型对特征的学习;当K=0.8时,检测准确率略微下降,其原因是部分显著性区域与隐写区域重合度较高的图像被原始图像替换,导致模型并不能很好地对有利区域进行针对性的学习;当K=0.7时,模型的检测准确率达到最佳。

表2 不同区域筛选阈值K下的检测准确率Tab.2 Detection accuracies of different region filter thresholds K
ROC(Receiver Operating Characteristic)曲线是一种衡量隐写分析模型的重要指标,可以通过纵轴正阳率(True Positive Rate,TPR)和横轴假阳率(False Positive Rate,FPR)的关系反映模型在数据集正负样本分布不均匀的情况下的判别能力,即模型的鲁棒性。AUC 值为ROC 曲线所覆盖的区域面积,AUC 值越大,模型检测效果越好。图10 展示了本文方法和SRNet在不同嵌入率和自适应隐写算法下的ROC曲线以及对应的AUC 值,图像质量因子(Quality Factor,QF)为75。其中:“AUC-本文方法-JUNIWARD-0.4 bpnzAC=0.885 3”表示嵌入算法为JUNIWARD,嵌入率为0.4 bpnzAC 的实验参数下,本文方法能够达到的AUC值为0.8853。
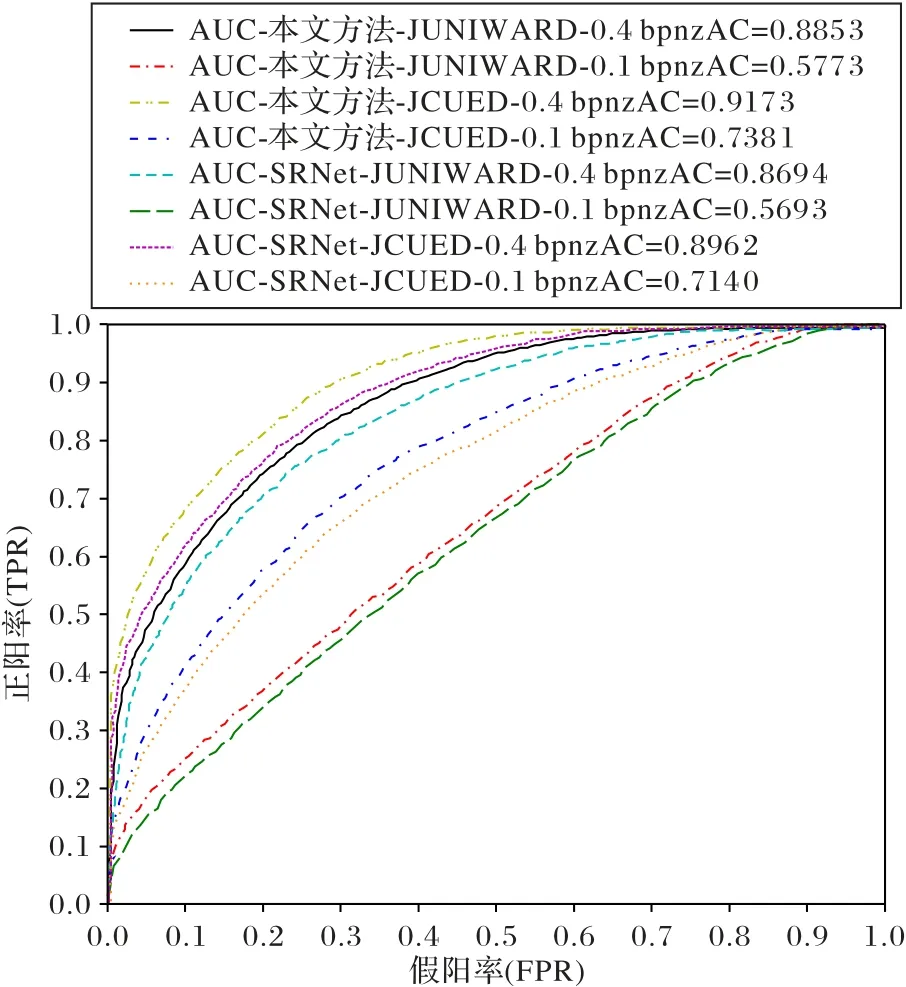
图10 不同嵌入率和隐写算法下的ROC曲线Fig.10 ROC curve of different embedding rates and steganography algorithms
3.3.2 不同隐写算法的实验结果对比
为了验证本文方法对于自适应隐写算法检测的有效性,分别对用空域和JPEG 域的自适应隐写算法嵌入的数据集进行隐写分析,如表3、4 所示。从实验结果可以看出,本文的方法在空域和JPEG 域通用,并且整体表现良好,但是在嵌入率较低时,该方法展现不出太大的优势,并且在图像质量较高,自适应隐写算法较复杂的情况下,存在一定的劣势,这方面在今后的工作中有待进一步提升。
3.3.3 不同隐写分析模型的实验结果对比
为了验证实验的可靠性,本文对比了当前在JPEG域隐写分析有一定竞争力的J-XuNet[31]、PNet[32]、SCA-GFR[33]以及在空域隐写分析有一定竞争力的Ye-Net、Xu-Net、SRM[34],在训练集和测试集数量相同的情况下,分别对用J-UNIWARD、JC-UED、HUGO、HILL 隐写算法进行嵌入的图像进行隐写分析,如图11 所示。从检测准确率可以看出,本文方法的性能有明显的优越性。
本文提出的基于显著性检测的图像隐写分析方法相对于当前隐写分析模型的优势体现在其利用显著性检测技术对图像中最有可能进行隐写的区域进行针对性地特征提取与学习,使模型最大限度地学习到隐写区域的特征,并且和非隐写区域的特征产生较强的特征差异性,更加有利于提高模型的判别性能,从而在模型的训练效果以及检测准确率方面产生显著的提升。
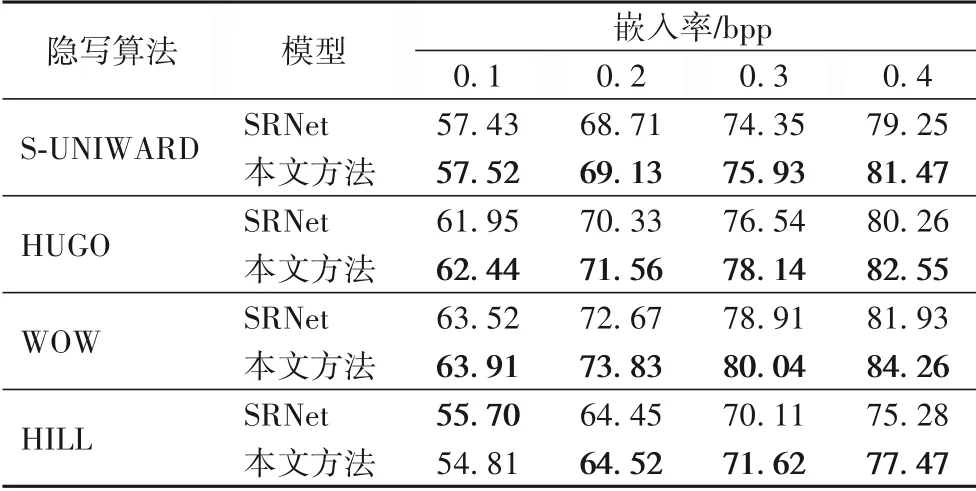
表3 空域不同隐写算法的检测准确率 单位:%Tab.3 Detection accuracies of different steganography algorithms in spatial domain unit:%

表4 JPEG域不同隐写算法的检测准确率 单位:%Tab.4 Detection accuracies of different steganography algorithms in JPEG domain unit:%
3.3.4 模型的失配测试
在实际应用的环境下,许多图像隐写分析方法具有很强的针对性,它们通常针对一种特定的隐写算法,这可能会导致某些隐写分析算法在检测特定的隐写算法时有非常好的结果,但可能无法检测到其他隐写术。对于训练集和测试集来自不同源的情况,不同成像设备会造成载体量化后噪声分布不一致,检测结果会造成失配;在隐写图像生成过程中,不同隐写方法和嵌入率也会造成失配,这种问题为模型的实用性带来了极大的考验。为了进一步验证模型的泛化能力及提升其应用价值,本文对模型进行了失配测试。
IStego100K 数据集[35]中的图像与BOSSbase1.01 数据集来源不同,并且采用不同的成像设备。本文利用在BOSSbase1.01 数据集下训练好的模型,对IStego100K 数据集进行检测。在实验中,将IStego100K 数据集中的原始图像先处理为分辨率为512 × 512的灰度图像,然后在空域用隐写算法S-UNIWARD、HUGO、WOW 和HILL 进行隐写,在JPEG 域用隐写算法J-UNIWARD 和JC-UED 进行隐写。表5 展示了本文提出的方法在不同嵌入算法上进行训练和测试的结果;表6 展示了本文提出的方法在不同嵌入率上进行训练和测试的结果,图像质量因子为75。从表中可以看出,本文方法在应对载体库源失配情况时表现良好,对于不同的隐写算法和不同嵌入率,虽然由于训练的特征与测试的特征分布不同而导致检测准确率降低,但仍能够达到与直接训练相近的检测准确率,在实际应用情况下,不会因为失配问题而导致严重的检测偏差,说明本文提出的方法具有良好的泛化性能和实用性。
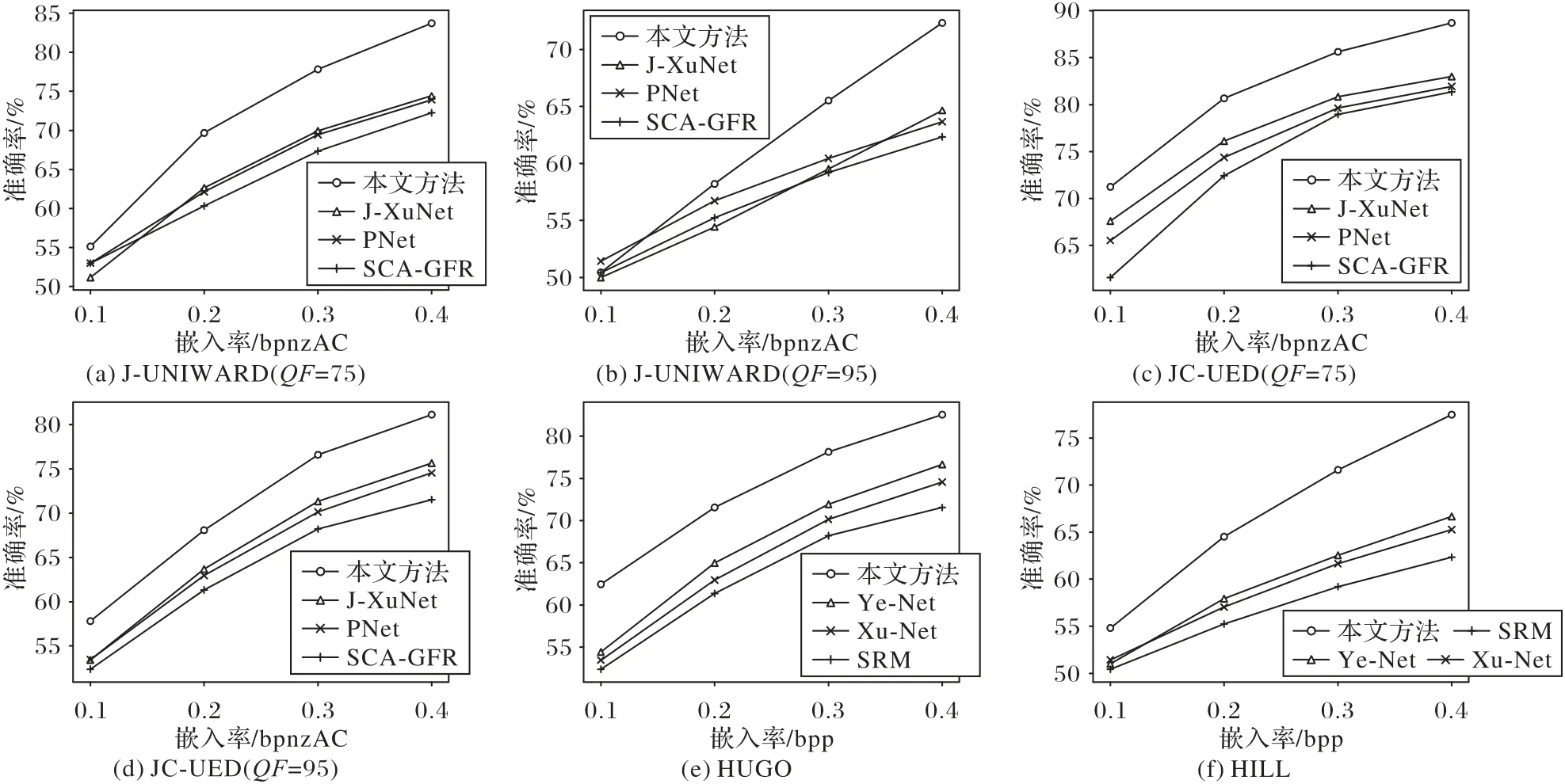
图11 不同隐写分析模型的实验对比Fig.11 Comparison of different steganalysis models
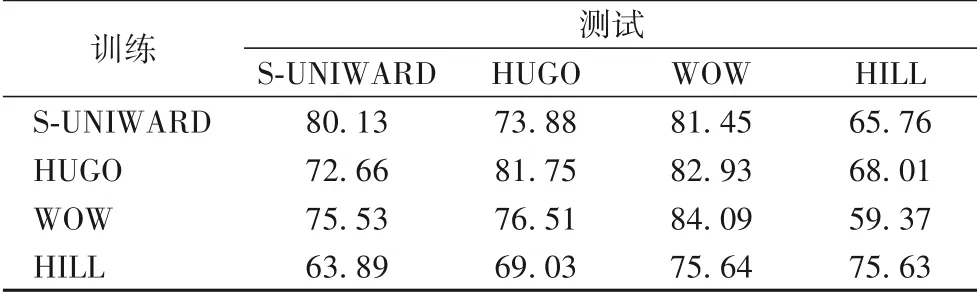
表5 在不同隐写算法上进行训练和测试的准确率 单位:%Tab.5 Results of different steganography algorithms on train and test unit:%
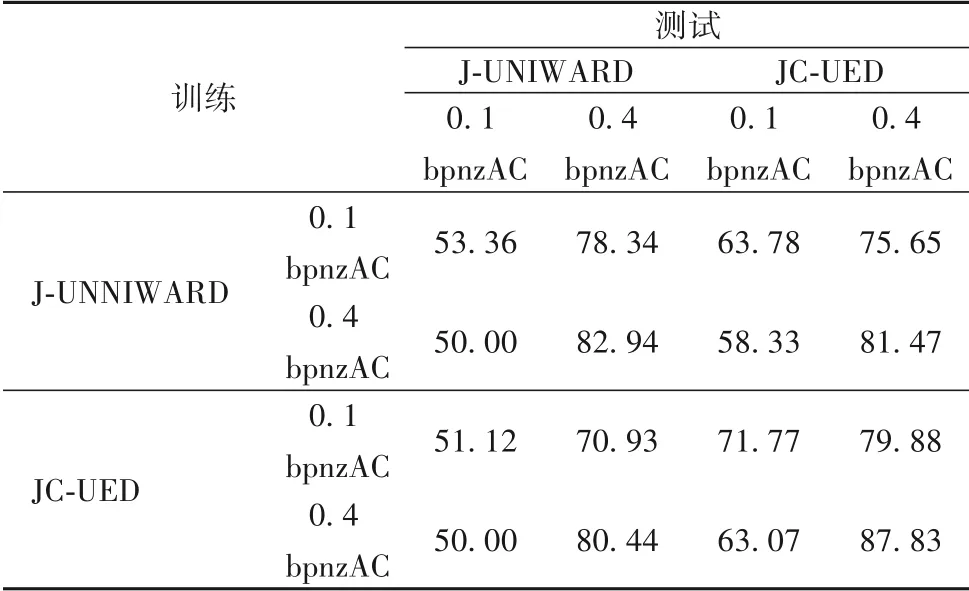
表6 在不同嵌入率上进行训练和测试的准确率 单位:%Tab.6 Results of different payload on train and test unit:%
4 结语
考虑到图像自适应隐写以不同的概率在图像中不同区域隐藏秘密信息,然而现有的隐写分析方法大多不加区分地从不同区域提取隐写分析特征的问题,本文提出了一种基于显著性检测的图像隐写分析方法,通过显著性检测模块和区域筛选模块引导隐写分析模型更加关注图像的隐写区域,提高训练的效果和检测准确率,准确率最多可提高3 个百分点。在BOSSbase1.01 数据集上通过对不同的隐写算法和嵌入率的图像进行检测,验证了该方法的有效性;并且对模型进行了失配测试,该模型在失配情况下检测准确率不会产生严重偏差,验证了方法的泛化性和实用性。下一步的研究方向是改善本文方法对于嵌入率较低图像的检测能力,以及进一步提升图像隐写分析的检测准确率和训练效率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中国知识产权(2018年12期)2018-12-29
中国知识产权(2017年5期)2017-05-25
