
基于改进MnasNet网络的低分辨率图像分类算法*
2021-03-05 07:15:30杨国亮吴志刚
传感器与微系统 2021年2期
杨国亮,朱 晨,李 放,吴志刚
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引 言
图像识别作为计算机视觉的基本任务之一,已被广泛应用于安防[1]、交通[2]、医疗等领域。低分辨率图像作为一种数据量小、易于传输的数据表达形式,占据了全部图片相当大的比重。常见于商品Logo,社交账号头像等对图像细节要求不高的领域,或者是摄像时镜头与目标距离较远,导致物体在整张图片中占用像素点较少的目标图像,例如地理系统的遥感图像、航拍图像等。
研究发现卷积层的数量(深度)在神经网络中扮演至关重要的角色,VGG,GoogLeNet,ResNet[3]等具有更深层结构的神经网络相继出现,刷新神经网络的分类精度,而与之伴随的是算法中参数量的巨大增加,无法应用于容量有限的嵌入式设备中,实际应用受限。为解决这一问题,研究者们提出了如MobileNet[4],MobileNetV2[5],MnasNet[6]等人轻量化卷积神经网络,大量减少网络计算的参数量,并能够保持与ResNet等算法相近的准确度,降低网络的复杂度。部分轻量化卷积神经网络的应用也有限制,据文献[6]所述,MnasNet网络在常用分辨率图像(224×224)中识别速度快、精度高,但是识别低分辨率图像的精度一般。
本文针对MnasNet网络在无法高效识别低分辨率图像内容问题,对网络模块进行改进,将改进后的网络模块在CIFAR—10数据集中做消融实验,寻找最优的网络架构,并于CINIC—10数据集中验证。
1 算法介绍
1.1 轻量化卷积结构
利用深度可分离卷积结构的MobileNet网络不同于标准卷积将输入特征图计算、输出一次完成,深度可分离卷积将这一过程分解成深度卷积(depthwise)和逐点卷积(pointwise)两个步骤完成。
深度卷积将输入的每张特征图进行单独计算,逐点卷积就是1×1的卷积用于将每个深度卷积的输出组合为一个整体。假设输入一个H×W×M的特征图X,输出特征图Y为H×W×N,卷积核的尺寸为K,则普通卷积的计算量为
K2×M×N×H×W
(1)
而深度可分离卷积的计算量为
K2×M×H×W+M×N×H×W
(2)
将两种卷积的计算量进行比对
(3)
假设卷积神经网络使用K=3的卷积核,则相对标准卷积结构,可分离卷积将计算量降低了8~9倍。
1.1.1 倒置残差瓶颈块
MobileNetv2网络创新性提出了线性瓶颈和倒置残差块两种改进方法,主要表现为在MobileNet网络的可分离卷积模块的输入端加入1×1的逐点卷积;引入膨胀系数t,控制卷积模块的卷积通道数;构造残差模块。倒置瓶颈块的应用进一步降低了网络的复杂度,其将模块中第一个1×1卷积层对输入特征图的通道做t倍的膨胀,最后一个1×1卷积层将膨胀的通道收敛,降低模块的计算量。可分离卷积(SepConv)模块和倒置残差瓶颈(Bottleneck)块的结构如图1所示。
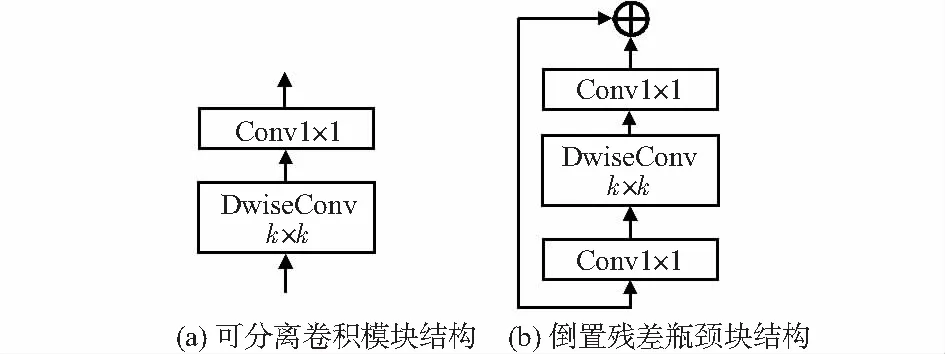
图1 深层可分离卷积的结构
1.1.2 MnasNet
MnasNet网络的结构由标准卷积、深度可分离卷积和倒置残差瓶颈块等共同组成,主体结构的排布和MobileNetv2网络相似。不同的是,MnasNet网络在部分卷积层中使用5×5的卷积核,加大网络的感受野,提升算法的识别精度;调整深度可分离卷积的通道扩张系数,缩减算法的运行时间;网络浅层部分的卷积层增加,减少深层部分的卷积层,网络的深度不变。这些改进使MnasNet网络在ImageNet数据集测试结果更加优秀,检索速度是MobileNetv2网络的1.5倍而且分类精度不降低。
1.2 改进的MnasNet网络
1.2.1 金字塔型轻量化卷积瓶颈块
Yang M等人[7]提出利用密集的金字塔结构(DenseASPP)可以提取更为丰富的图片特征,在场景分割中取得了优秀的表现结果。受其启发,本文将MnasNet网络中瓶颈块的单一的深度可分离卷积构建为具有金字塔结构的多个深度可分离卷积的组合。
文献[7]中使用的DenseASPP结构由5个密集连接的空洞卷积[8]组成,通过改变每个空洞卷积的空洞系数扩张滤波器的尺寸,实现扩大卷积层感受野的目的;另一方面,每个滤波器的输出通过“concat”连接[9]方式组合成一个整体,构建具有金字塔结构的多尺度特征图。本文没有将空洞卷积运用到深度可分离卷积中改变滤波器的尺寸,因为空洞卷积虽然可以减少网络的参数量,但是滤波器中补‘0’的部分仍旧参与计算,并且限制了滤波器输出的连接方式。文献[10]提出使用更小的滤波器级联代替较大的滤波器可以极大地减少神经网络的参数量和计算复杂度,但考虑到当前批规范方法已经结合到深度可分离卷积模块中,这样的方式已经不再适合。本文假设基于金字塔结构瓶颈(PSBottleneck)块的输入特征图尺寸为H×W×M,输出特征图尺寸为H×W×N,其中一组为5×5的滤波器,另一组为2个级联的3×3滤波器
C5×5=H×W×M×(25+N)
(4)
C3×3=H×W×M×(9+N)
(5)
⟹C5×5<2×C3×3,当N>7时
由式(4)和式(5)知,对于感受野大小相同的情况下,当N>7时,一个5×5的滤波器的计算量略低于两个级联的3×3滤波器的计算量。因此,本文采用直接改变滤波器尺寸的方式构建滤波器的金字塔结构—金字塔的每层仅有一个滤波器;金字塔最上层的滤波器尺寸最小,为3×3,由小到大向下排列,第i层滤波器的尺寸为Kn,Kn=2n+1;滤波器的输出既可以采用残差连接的元素和方式组合,亦可以采用通道拼接的方式组合,送入下一个PSBottleneck块。PSBottleneck块的结构如图2所示。

图2 PSBottleneck块结构
由于PSBottleneck块内的每层滤波器都共享逐点卷积的输出作为输入,极大地增加了网络的参数量和计算量,本文引入超参数β控制逐点卷积的输出,减小网络的空间复杂度和时间复杂度;β作用于每个PSBottleneck块的第一个逐点卷积,调节输入滤波器的特征通道数。引入超参数β后的PSBottleneck块的计算量为
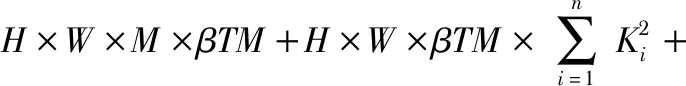
H×W×βTM×N
(6)
调节超参数β,可以实现比原瓶颈块更小的计算量和参数量。相较于原瓶颈块,改进的PSBottleneck块从结构上扩展了深度可分离卷积的层数,并重新设定深度可分离卷积的卷积核尺寸,其构成形式类似于Inception的多级卷积核并行结构;在参数方面,引入超参数β,灵活调整网络的空间复杂度和时间复杂度,在准确率和速度间实现平衡。改进后的PSBottleneck块结构依然保持着瓶颈块的形式,使用简单、可控。
1.2.2 PSMnasNet网络
本文首先将MnasNet网络参数设置依照MobileNetV2网络的设置逐步更改,然后在CIFAR—10数据集上测试,实验结果表明过多的下采样次数和在网络深层部分过大的卷积核尺寸是原MnasNet网络不适用于对低分辨率图像进行特征区分的主要原因。
PSMnasNet网络结构基于调整下采样后的MnasNet网络架构,使用PSBottleneck块替换原网络中的倒置残差瓶颈块并根据特征图尺寸设置匹配的池化层。PSMnasNet网络结构如表1所示。
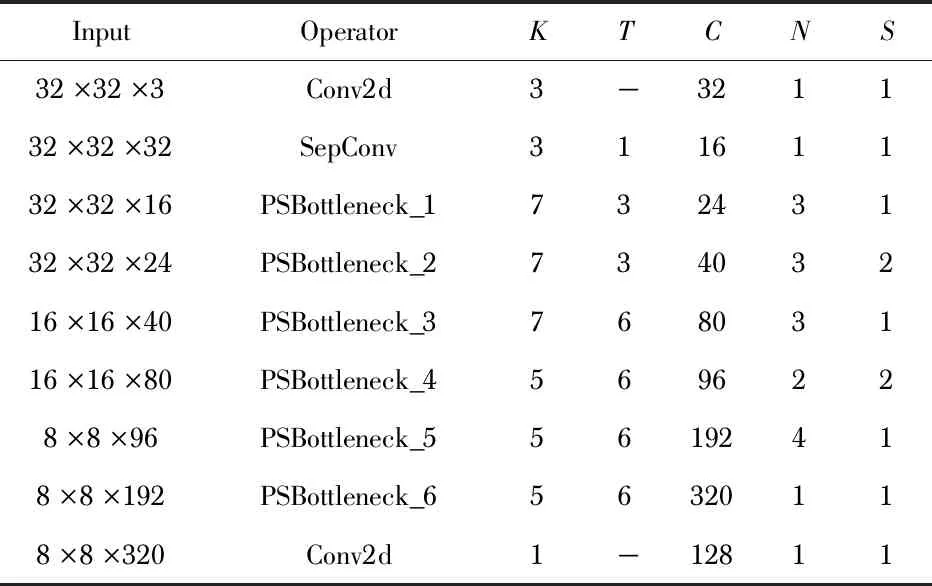
表1 PSMnasNet网络结构
表1中K指代PSBottleneck块中滤波器的最大尺寸,特征图分辨率大于等于16时,采用滤波器尺寸分别为(3,5,7)的3级PSBottleneck块;特征图分辨率大于等于8时,采用滤波器尺寸为(3,5)的2级PSBottleneck块。T指代通道的膨胀系数;C指代网络的通道数;N指代模块的重复次数;S指代卷积模块的步长,S作用于每个重复的PSBottleneck块的第一个模块中,其余模块的步长均为1。PSMnasNet网络全部使用PSBottleneck块,网络下采样2次,最终输出分辨率为8×8的特征图;另外,PSMnasNet的网络结构与原MnasNet网络保持一致,包括网络中瓶颈块的排列方式、组合次数和特征图通道数、通道的膨胀系数等等。
2 实验与分析
本文的实验条件为Ubuntu14.04系统,GTX 1070 8G显卡,PyTorch0.4.1。
2.1 CIFAR—10
CIFAR—10数据集包含有60 000张32×32的低分辨率图像,其测试结果是网络验证自身算法性能的一项重要指标。本文将改进后的网络在CIFAR—10数据集上测试,分析超参数β和PSBottleneck块的滤波器尺寸对网络的影响。
本文遵循文献[11]使用的训练策略:优化器使用随机梯度下降方法;初始学习率为0.1,150次迭代后学习率下调10倍,225次迭代后再次下调10倍;设定动量为0.9;权重衰减为1×10-4;batch size设定为128;共计迭代320个周期。
本文首先测试MnasNet网络的实验结果作为基线:MnasNet网络的下采样次数是5,参数量有3.19M,获得了84.92 %的分类精度;调整后得到的MnasNet-FT网络的下采样次数为2,参数量不变,计算量上升,网络的分类精度提高到93.90 %。
然后,本文比较PSBottleneck块中特征的连接方式‘Add’和 ‘Concat’对网络性能的影响。设定β=0.25,混合使用k=5/7的PSBottleneck块,使用‘Add’方式的网络参数量为0.94M,分类精度达93.97 %;而使用‘Concat’方式的网络参数量为1.31M,分类精度达94.37 %。综合比较后,本文在PSBottleneck块中选用‘Concat’连接方式。
本文固定PSBottleneck块的滤波器混合使用K=5(二层滤波器)和K=7(三层滤波器),分别设定β为0.10,0.25,0.50,0.75,如图4所示,通过实验日志记录网络准确率变化过程。由图3观察可知:当β=0.10时,PSMnasNet网络的参数量不到原网络的1/5,但分类精度却提高了8 %,比MnasNet-FT网络减少约0.9 %;当β=0.25时,PSMnasNet网络的分类精度已经超出MnasNet-FT网络约0.5 %,而且参数量减少约60 %;β对网络精度的影响存在上限,当β=0.75时,网络精度随迭代次数的变化和β=0.50时的基本重合,网络的参数量增加,但分类效果不再提升,此时的最佳分类精度为94.85 %。
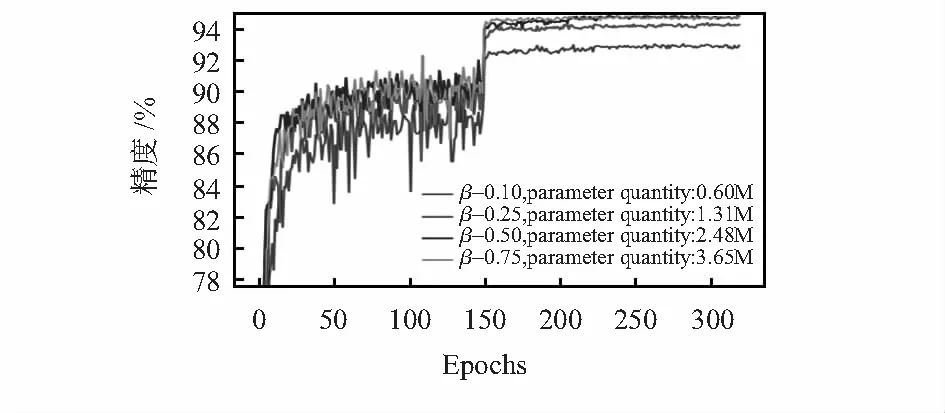
图3 超参数β的网络分类精度
图4是固定β=0.25后,PSBottleneck块的滤波器尺寸k影响网络分类精度变化的折现图。PSBottleneck块的滤波器尺寸k同样影响网络的参数量和分类性能,但幅度不大。通常而言,PSBottleneck块的滤波器尺寸k越大,网络的参数量越大,分类精度也越高;但是需要注意的是,特征图尺寸经过下采样减小后,滤波器尺寸应随着下降,否则为了保持卷积操作前后特征图尺寸的不变,需对特征图进行过多的填充,影响提取特征的鲁棒性。如图4中所示,混合使用2层PSBottleneck块(k=5)和3层PSBottleneck块(k=7)超过全部使用3层PSBottleneck块(k=7)约0.2 %的分类精度。
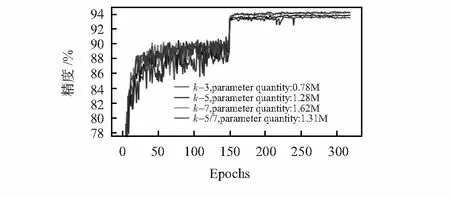
图4 PSBottleneck块的滤波器尺寸k的网络分类精度
在CIFAR—10数据集的实验中,PSMnasNet网络的分类精度比MnasNet网络提升了10 %,其中9 %来源于网络下采样次数的调整,另外的1 %则源自PSBottleneck块的应用。PSBottleneck块采用更大的感受野和并行级联的滤波器结构,提取更为丰富的图片特征,实现网络准确率的提升。PSMnasNet网络精度的提升存在上限,当β=0.50时,网络的分类精度已接近极值点;β继续增大,只能使网络的空间复杂度增加,而网络的分类精度增加非常微小。另外,超参数β与网络的参数量呈现线性关系:y=βx+b。其中y为网络的参数量,x是β=1时所有PSBottleneck块的参数量,约为4.7 M,b是网络中非PSBottleneck块网络层的参数量,约为0.13 M。
2.2 CINIC—10
随着深度学习的快速发展,图片数量限制了CIFAR—10数据集[12]评价指标的置信度。作为CIFAR—10数据集的扩充,CINIC—10[7]数据集有图片27万张,均为32×32的低分辨率图像,和CIFAR—10数据集相同的10个分类;图片平均分布于训练集、验证集和测试集中;图片一部分来源于CIFAR—10数据集,另一部分来源于下采样的ImageNet图像,图像的识别难度加大,算法在真实背景下物体识别能力的置信度更高。如图5所示,本文从CINIC—10数据集的每个分类中随机抽取5张图片,从左向右依次是飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。

图5 CINIC—10数据集10个子类图
本文将CINIC—10数据集的验证集图像融入到训练集中,此时的CINIC—10数据集训练集中含有18万图片,测试集有9万张图片。CINIC—10数据集官方给出的训练策略和超参数为:优化器为随机梯度下降方法;学习率为初始为0.1,余弦退火下降至0;moment为0.9;权重衰减为1×10-4;批为训练批64,测试批50;迭代次数为300。
本文采用在CIFAR—10数据集上分类精度和网络参数量均衡的PSMnasNet网络(β=0.25,混合使用滤波器最大尺寸为5和7的PSBottleneck块)应用于CINIC—10数据集,并与当前一些经典的卷积神经网络比对,实验结果如表2所示。
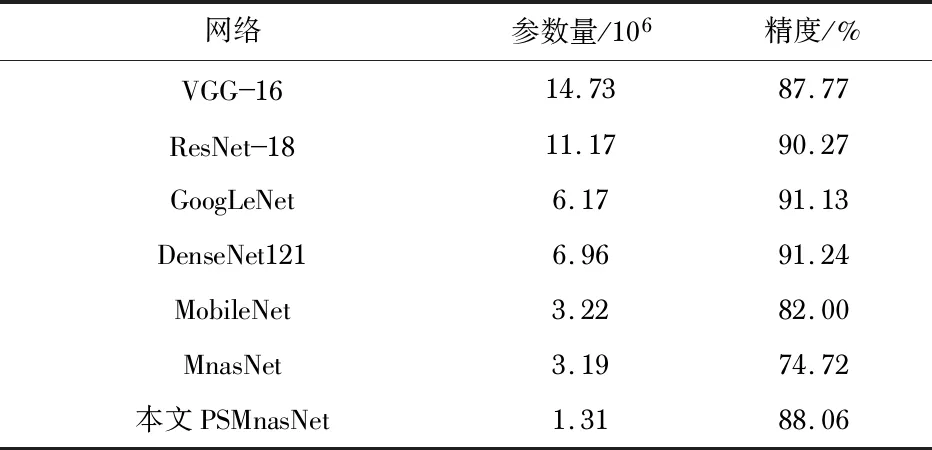
表2 CINIC—10数据集中部分经典网络的性能表
如图6所示,PSMnasNet网络对CINIC—10数据集中10个子集的分类精度的排序与原MnasNet网络一致,从高到低依次是青蛙、飞机、船、马、汽车、鸟、卡车、鹿、猫和狗,但各子集的分类精度有着较大的改善,尤其是识别效果最差的狗类子集图像,PSMnasNet网络提高了约25 %的分类精度。
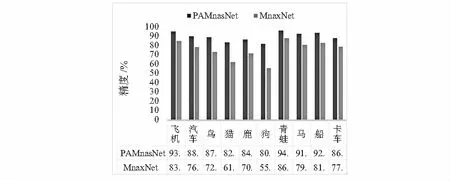
图6 CINIC—10数据集10分类精度直方图
3 结 论
MnasNet网络作为当前一种高效的轻量化卷积神经网络,由于自身的部分结构限制,不适合运用于低分辨率图像识别领域。本文根据低分辨率图像的特点,适当调整网络的结构,并在CIFAR—10和CINIC—10数据集中进行验证,实验结果表明,PSMnasNet网络对低分辨率图像有着良好的识别效果,而且网络的参数量更少,空间复杂度更低,可以用于代替MnasNet网络执行低分辨率图像的分类。
猜你喜欢
无线互联科技(2024年23期)2024-12-18 00:00:00
计算技术与自动化(2024年3期)2024-10-10 00:00:00
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年16期)2018-09-26 03:26:50
艺术科技(2018年2期)2018-07-23 06:35:17
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
火控雷达技术(2016年2期)2016-02-06 02:29:00
