
基于改进的BP神经网络的输油管道内腐蚀速率预测*
2021-03-05 07:15:28徐鲁帅余建平
传感器与微系统 2021年2期
凌 晓,徐鲁帅,余建平,梁 瑞
(兰州理工大学 石油化工学院,甘肃 兰州 730000)
0 引 言
随着输油管道的长时间且不间断运行,管道事故频发。因此研究输油输送管道腐蚀状态,对保障居民安全,社会及企业稳定发展具有重大意义。张河苇等人[1]基于互信息理论方法,建立了管道腐蚀等级与各相关因素之间的关联模型,确定了影响管道腐蚀速率的主要因素。Noor N M[2]使用半概率法对海底管道发生内腐蚀后的剩余强度进行预测。Senouci A[3]使用神经网络模型对管道的内外监测数据进行分析,预测管道腐蚀状态以及管道衰退情况。章玉婷等人[4]提出了基于反向传播神经网络(BPNN)模型对长输管道的内腐蚀速率进行预测,但由于单一的BPNN模型具有易陷入局部最优的缺陷,因此预测误差相对较大。
本文引入GA优化BPNN模型,有效克服了单一的BPNN模型易陷入局部最优的缺点,从而更准确地对输油管道腐蚀速率进行预测[5]。GA按照适应度函数及选择、交叉、变异等遗传操作对BPNN模型的权值及阈值优化筛选,确定其最优初始值。利用优化后BPNN模型进行学习训练及验证,得出的管道腐蚀速率预测结果接近真实值。
1 BPNN预测模型
1.1 BPNN
BPNN模型根据已知数据类型与预期输出数据类型确定输入层和输出层节点个数[6]。输入层将数据信号传输给神经网络中间的隐含层,隐含层学习并处理数据,将处理后的信号结果传输给输出层[7]。如果输出的结果与期望输出值不一致,便将误差反向传播给隐含层,并对隐含层的权值和阈值进行修正,如此反复,直到输出结果与期望输出值相符为止[8]。在使用BPNN模型分析预测时,一般采用如图1所示的三层网络拓扑结构。
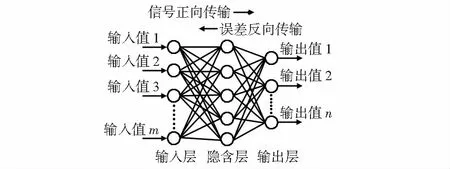
图1 BPNN模型网络拓扑
1.2 BPNN模型的建立及算法
图1所示的BPNN模型输入层节点数m;隐含层为有l个节点的单层结构;输出层为节点数n个。设BPNN模型的输入值为xi(i=1,2,…,M),隐含层第j个节点的输入值为sj、输出值为aj,输入层到隐含层的权值为wij,隐含层的阈值为bj,输出层第k个节点的输入值为pk,输出值为tk。隐含层到输出层的权值为wjk,输出层的阈值为bk。f(x)为BPNN模型的激励函数。隐含层和输出层的输入、输出满足[9]
(1)
aj=f(sj)
(2)
(3)
tk=f(pk)
(4)
根据上式对输入层的输入数据进行相应处理,最后由神经网络的输出层输出处理后的数据信号,这个过程为神经网络的正向输入过程;将神经网络的输出的结果误差大小反向修正各个节点权值和阈值的数值,这个过程为神经网络的反向传播过程。误差函数Ep与期望输出值yk和tk之间的关系及权阈值修正系数分别如以下[9]
(5)
(6)
(7)
(8)
(9)
式中η为学习速率系数,隐含层到输出层和输入层到隐含层的权值修正系数分别为Δwjk,Δwij,输出层和隐含层的阈值修正系数分别为Δbk,Δbj。BPNN模型的正向信号输入,误差反向传播的过程不断地进行迭代,直到输出值满足期望输出。将BPNN模型用于输油管道腐蚀内速率预测,将管道的内检测数据作为输入层的输入信号,并将管道腐蚀速率作为输出层的输出信号,不断比较BPNN模型输出的管道腐蚀速率预测值与期望输出值之间的误差,当满足误差精度要求时或达到预设最大迭代次数后终止训练,再用测试数据集对该BPNN模型进行验证测试。
1.3 隐含层节点数的选择
如果隐含层节点数过少,则在神经网络预测过程中获取的有效的信息较少,致使其难以达到准确的预测。但如果隐含层节点数过多,会使神经网络的训练时间加长、容错性变差、泛化能力下降。所以隐含层节点数的选择是BPNN模型建立的重要一步。
设某一BPNN模型为三层网络结构中输入节点数为m个,即输入向量可表示为X=(x1,x2,…,xm)T∈Rm,输出层节点数为n个,神经网络的隐含层节点数l个。其中隐含层的节点数主要由经验公式(式(1))确定[10]
(10)
式中a为1~10的常数。
隐含层节点数确立步骤为:首先依据式(10)确定隐含层节点数的取值区间;其次将区间内的整数作为BPNN模型中隐含层节点的个数,训练样本;最后记录每次训练结果的误差,误差最小时所对应的隐含层节点个数便为最终确定的BPNN模型中隐含层节点数。
2 GA优化BPNN模型设计
2.1 GA优化BPNN算法
常规的BPNN模型训练时易陷入局部最优,为避免上述情况的发生,引入GA优化BPNN模型[11],可有效提高管道内腐蚀速率预测的精度。GA按照适应度函数及选择、交叉、变异等一系列遗传操作对BPNN模型的起始权值及阈值进行优化筛选。当满足一定条件时,适应度最高的染色体的输出即为BPNN模型初始权值和阈值。GA-BPNN模型通过GA优秀的全局搜索能力找到最优的BPNN模型起始权值和阈值,再利用BPNN模型进行训练及验证,进而提高输油管道内腐蚀速率的预测精度。GA-BPNN模型算法流程见图2。
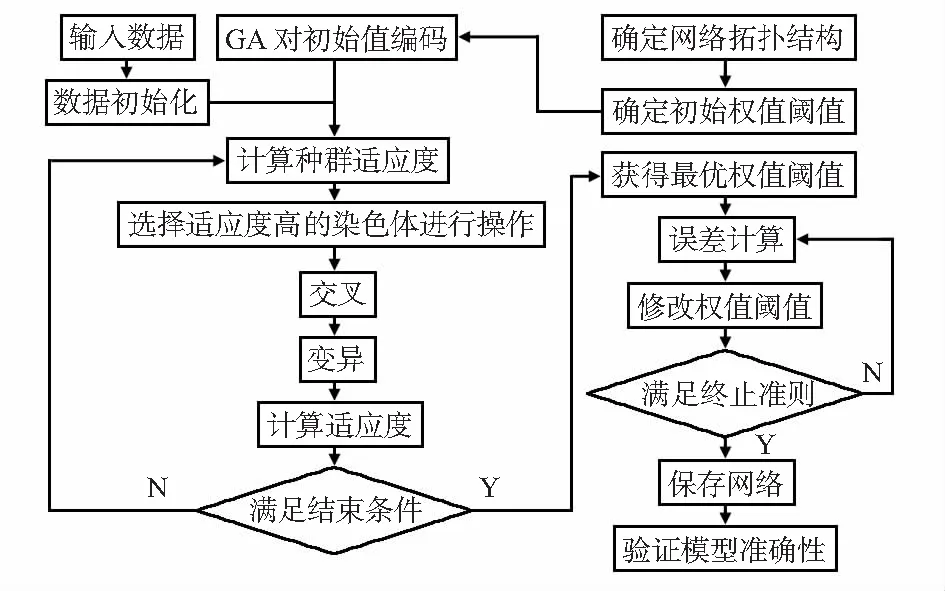
图2 GA-BPNN算法流程图
2.2 GA优化BPNN模型步骤
步骤1确定BPNN模型的网络拓扑结构(神经网络层数及各层节点数)、学习规则以及GA中染色体长度。其中,GA的染色体编码规则选用浮点数编码,以便扩大搜索范围,确保BPNN模型中初始权值和阈值的精度能够满足需求。染色体编码长度s为
s=n1×n2+n2×n3+n2+n3
(11)
式中 输入层、隐含层和输出层的神经元个数分别为n1,n2,n3。
步骤2确定GA中使用的适应度函数。GA优化BPNN的目标是得到BPNN模型的平方和最小的网络权重,即GA的适应度函数为
(12)
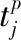
步骤3选择一定数量的满足适应度函数要求的染色体作为新种群的父本染色体。设群体总量为n,其中个体i的适应度为fi,则i被选择的概率为
(13)
步骤4通过GA的交叉操作、变异操作对父本染色体进行相应处理,产生新一代染色体种群。
(14)
式中a为区间[0,1]内均匀分布的随机数。
2)利用某一区间中均匀分布的随机数,以某一较小概率替换个体编码串中原有的基因实现变异,增强GA的局部随机搜索能力,防止出现早熟现象。设初始个体的最大值和最小值分别为xmax和xmin则变异后的新基因值为
xk=xmin+β(xmax-xmin)
(15)
式中β为区间[0,1]内均匀分布的随机数。
步骤5重复步骤3、步骤4,使染色体不断进行选择、交叉以及变异操作,直到达到预设训练目标,将染色体解码后赋值给BPNN模型的初始权值和阈值。
3 预测实例与分析
3.1 数据来源
数据来源于某输油管道[12],管道材质为20#钢,于1990年建成投产,运行压力为1.0~5.0MPa。采集了含硫量、pH值、温度、流速、压力这五种管道腐蚀速率主要影响参数。采集数据集共25组,选取其中15组作为BPNN模型及GA-BPNN模型的训练集,具体管道参数见表1。剩余10组为两种机器学习算法的测试集,以对比其预测的准确性。
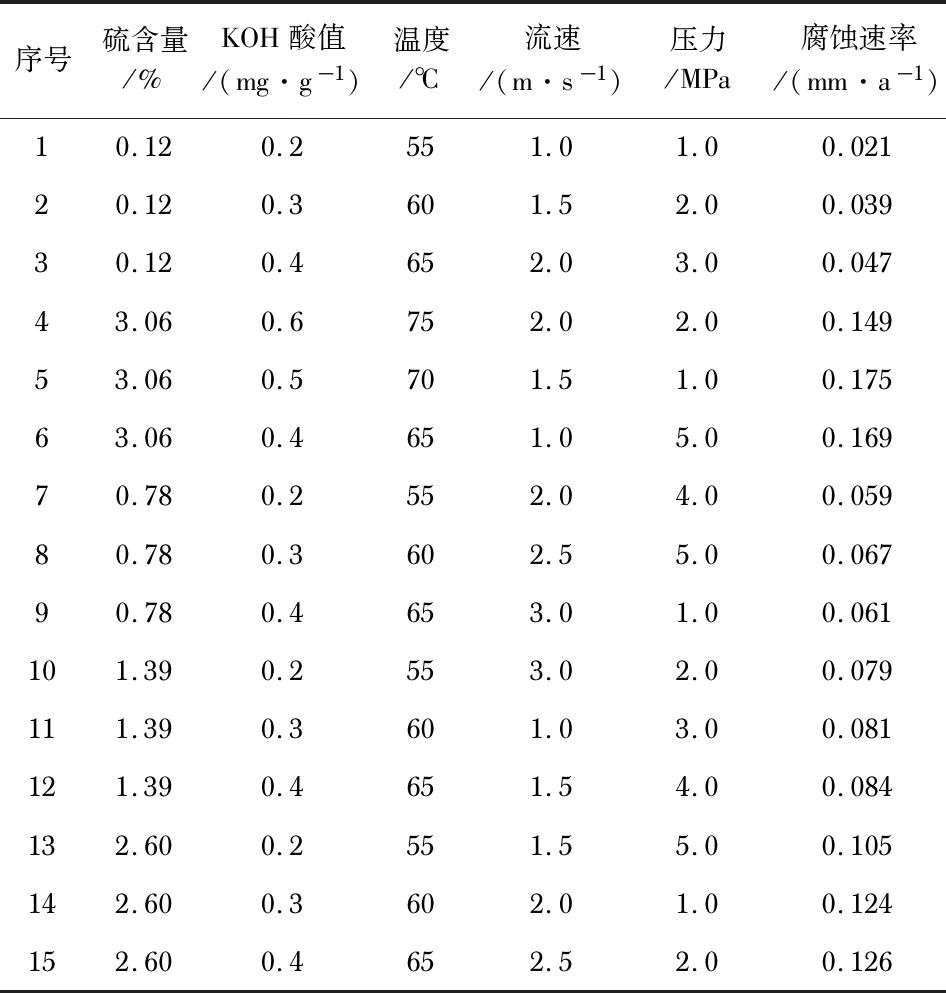
表1 输油管道检测数据表
3.2 预测模型构建
BPNN输入变量为五个管道腐蚀速率的主要影响参数,输出值为输油管道腐蚀速率。选用三层网络拓扑结构的BPNN模型,输入层节点为5个,分别对应5种输入参数(硫含量、KOH酸值、温度、流速、压力)。输出层节点数为1个,对应管道的腐蚀速率。根据经验公式确定隐含层节点数取值区间为[2,12],把区间内各节点数带入MATLAB中训练,得到各隐含层节点数的训练结果的平均相对误差与隐含层节点关系如图3所示。
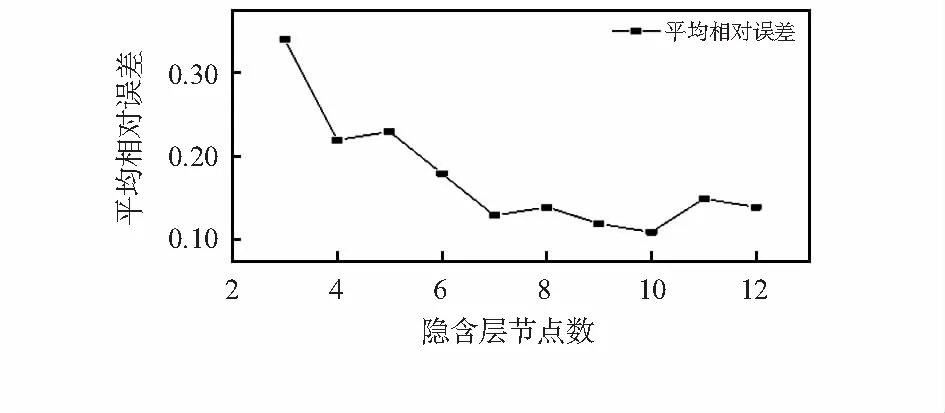
图3 平均相对误差与隐含层节点关系
可见,节点数较少时平均相对误差比较大,这是因为节点数过少,获取的有效的信息较少,导致误差偏大。随着节点数增加,获取的有效信息增多,平均相对误差逐渐减小。当隐含层节点数增加到10时,平均相对误差达到最小,为0.111 3。所以最终BPNN的隐含层节点数确定为10。隐含层节点转移函数为Logsig,其表达式为
(16)
式中x,y分别为节点输入量和输出量。
输出层节点转移函数为Purelin,其表达式为
y=x
(17)
式中x,y分别为节点输入量和输出量。
神经网络训练目标为10-6,利用GA对BPNN模型进行优化。GA中染色体长度为66,种群规模为80,迭代次数为120次,个体范围为[-1,1],交叉和变异概率分别为0.5和0.02。
3.3 预测结果分析
检验集10组数据的腐蚀预测结果对比图如图4所示。

图4 腐蚀速率预测对比图
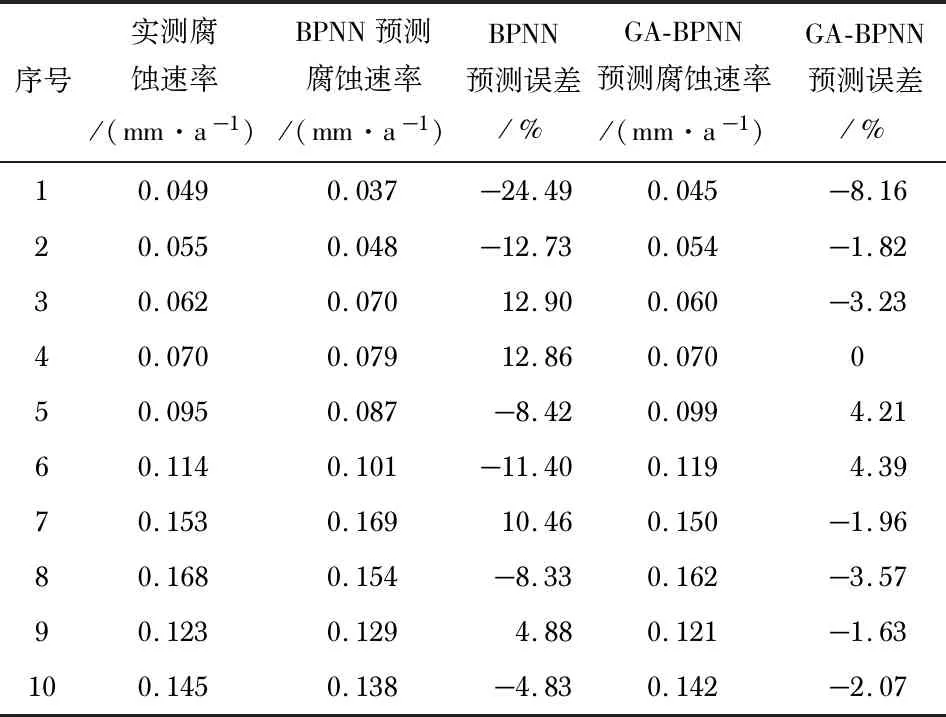
本文选取平均相对误差作为两种机器学习算法的预测准确度的评定指标,其计算公式为式(18)。GA-BPNN模型与BPNN模型预测的相对误差如表2所示。式(18)如下
(18)
从表2可知,单一的BPNN模型预测结果较差,误差远高于GA-BPNN模型。BPNN模型的最高相对误差达24.49 %,平均相对误差为11.13 %,这是因为BPNN模型在训练时陷入了局部最优所导致的。相较于BPNN模型,GA-BPNN模型的预测精度有了较大幅度的提高,最大相对误差仅为8.16 %,平均相对误差为3.10 %,预测精度比较符合实际需求。GA-BPNN模型预测精度的提高是因为GA优化了BPNN模型的权值和阈值,提高了神经网络的训练能力和预测精度,同时避免了BPNN模型容易陷入最优问题的发生,使预测结果更为准确可靠。
4 结 论
本文运用GA优化BPNN模型的初始权值和阈值,有效避免了单一的BPNN模型容易陷入局部最优问题的发生。同时结合了GA和BPNN模型各自的优势,从而有效地提升了输油管道内腐蚀速率的预测精度。使用GA-BPNN模型预测结果的平均相对误差为3.10 %,明显优于单一BPNN模型预测的平均相对误差11.13 %。因此使用GA-BPNN模型预测管道腐蚀速率可为管道的检测维修提供可靠的依据。由于金属管道的腐蚀情况的检测较为困难,未来仍需加强对管道腐蚀速率预测模型的研究,以提高其预测精度及效率。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
制造技术与机床(2019年9期)2019-09-10 07:36:54
科学之谜(2019年3期)2019-03-28 10:29:44
西南交通大学学报(2018年6期)2018-12-18 02:22:28
科学之谜(2018年8期)2018-09-29 11:06:46
河北遥感(2017年2期)2017-08-07 14:49:00
自动化学报(2017年7期)2017-04-18 13:41:02
恋爱婚姻家庭·养生版(2016年9期)2016-09-07 11:25:01
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
