
用于接触网可视化接地识别的改进VGG—16模型*
2021-03-05 07:15:26陈剑云完颜幸幸
传感器与微系统 2021年2期
吉 鑫,陈剑云,完颜幸幸
(华东交通大学 电气与自动化工程学院,江西 南昌 330013)
0 引 言
地铁由于检修的需要导致接触网频繁接挂地线。接触网可视化接地系统,可以大大减少接触网接挂地线的时间、增加天窗作业时间,提高作业效率、确保工作人员的人身安全,达到运营安全、可靠、经济的目的。通过站内监控主机,工作人员可以实现对站内接地装置的集中管理和操作,此系统可以实现本地电动接地操作并辅以远程验电及视频确认等功能。系统的视频确认功能,其目的是实现接地刀闸开关状态的自动判断,结合行程开关的状态以及远程验电操作,可以增加系统冗余度,进一步提高系统的可靠性。首先,系统需要从长时间的实时监控中截取刀闸运动过程的视频,再通过对所截取的图像分析得到刀闸的开关状态。
对于电力系统部件的图像识别方法,目前的研究多数采用机器学习的方法,流程大致是人为设计特征、计算特征、训练模型,如今已取得一定的研究成果。文献[1]采用多特征融合的方法,将梯度方向直方图(histogram of oriented gradient,HOG)特征、Lab颜色空间、边缘轮廓组成开关设备的特征描述集,基于决策树模型实现了开关状态的识别。文献[2]选用基于SIFT特征的局部识别算法实现高压隔离开关分合状态的自动识别,但前提条件是光线充足,画质不理想时可能带来误判。
随着现代科技的发展,特别是拥有强大计算能力的图形处理单元(graphics processing unit,GPU)等硬件的不断更新迭代,使得以卷积神经网络(convolutional neural network,CNN)为代表的深度学习技术在图像识别和目标检测领域表现出色。先后出现了AlexNet、VggNet、GoogleNet、ResNet等优秀的网络模型。CNN的优势是不需要人为设计特征,由深度网络进行特征学习。近些年来,迁移学习技术在深度学习领域的大量应用表明,其在模型训练中非常高效。因此,本文开展基于迁移学习的接地刀闸开关状态图像识别方法研究。
1 基于VGG—16的刀闸状态识别模型
1.1 VGG—16网络
VGG—16网络是继AlexNet之后,又一应用较为成功的CNN[3],其特点在于加深了CNN的深度,配合较小的卷积核,能够提取出更多细小的特征。它包含了16个权重层(13个卷积层和3个全连接层),接受3通道RGB图像作为输入,经过一系列2个或3个卷积层堆叠而成的卷积序列,采用3×3大小的卷积核;每个卷积序列之后都跟随2×2窗口大小、步长为2的最大值池化层;后3个全连接层的通道数分别为4 096,4 096,1 000;最后由一个具有1 000个标签的SoftMax分类器进行分类输出。本研究只需分类三个类别(闭合、断开、异常),故首先对VGG—16网络做出适应分类类别数量的结构调整,即将全连接层的输出层神经元个数调整为3个。其模型结构示意图由图1(a)所示。
1.2 对VGG—16网络的结构改进
深度网络的改进重点在于如何防止过拟合,减少网络参数是重要方法之一,VGG—16网络的参数绝大部分集中在后3层全连接层中,故对全连接层进行调整。
采用稀疏自编码器(sparse automatic encoder,SAE)[4]替换网络末端的全连接层能够显著减少网络参数,在不损失识别率的同时保证了网络的稀疏性,增强模型泛化能力,修改后的VGG—16网络结构如图1(b)所示。稀疏自编码器是一种无监督学习BP算法,通过稀疏的隐含层节点来表示输入层的特征。通过无监督学习,使输出特征尽可能等于输入特征,以获得更好的高层语义性,其结构示意图如图2所示,输入层Layer L1设置4 096个神经元,隐含层Layer L2设置3 072个神经元,输出层Layer L3设置4 096个神经元。
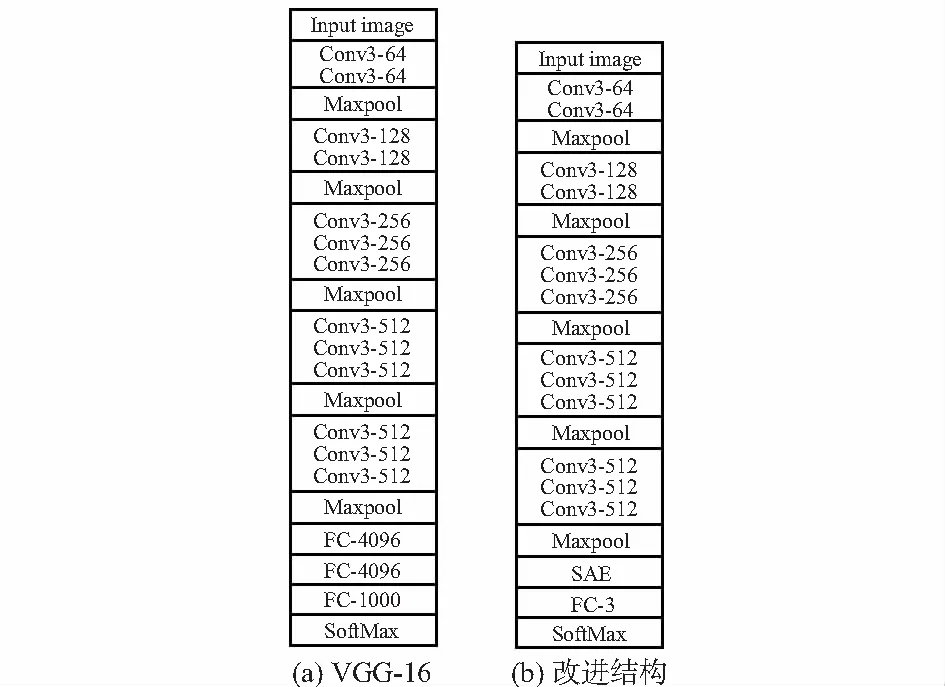
图1 VGG—16和改进后的结构
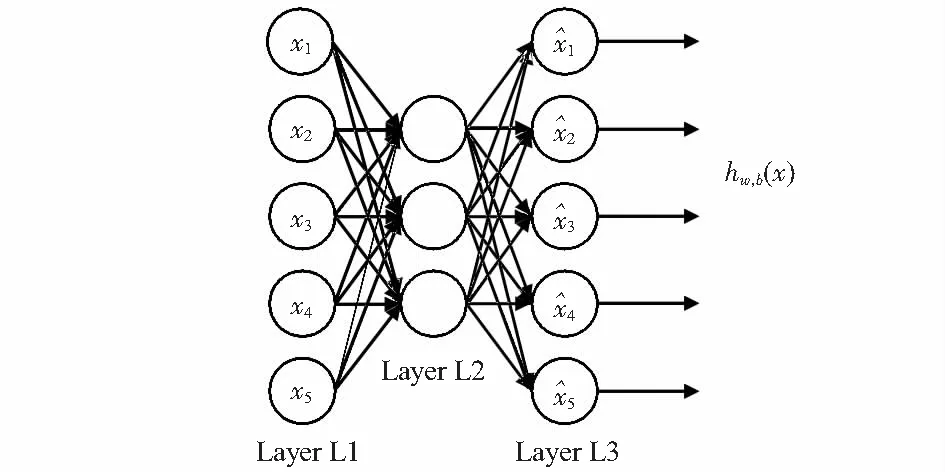
图2 SAE的网络结构


1.3 总体框图
训练识别模型的流程框架如图3所示。
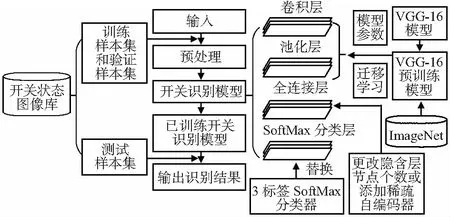
图3 流程框图
主要经过以下5个步骤:1)输入训练数据;2)数据预处理;3)搭建模型;4)迁移学习;5)模型测试。
2 数据增强与模型训练策略
2.1 主成分分析
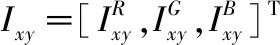
[P1,P2,P3][α1λ1,α2λ2,α3λ3]T
式中Pi和λi为每张RGB图像第i个通道像素矩阵的协方差矩阵的特征向量和特征值,αi为均值为0,标准差为0.1的高斯随机变量。
此外,本文使用的数据增强方法还包括加噪、随机截取、水平翻转等。
2.2 迁移学习
深度CNN通常需要诸如ImageNet[5]的大型图像数据集来满足训练需求,否则将陷入严重的过拟合而使得模型不具有泛化性[6]。迁移学习允许使用少量数据以预训练模型为起始,并固定特征提取层,只对网络后端参数进行微调[7]。这种策略既避免了过拟合的问题,又能使训练时间大大缩短,最终模型的准确率、泛化性能都较高。
3 实验过程与结果分析
3.1 数据集的准备
采集刀闸状态原始数据574幅图像,使用数据增强将总量扩增到2 950幅。随机划分训练集2 650幅、验证集300幅。保证训练集和验证集同分布,便于更好地评估训练好的模型性能[8]。得到数据集分布情况如表1所示。
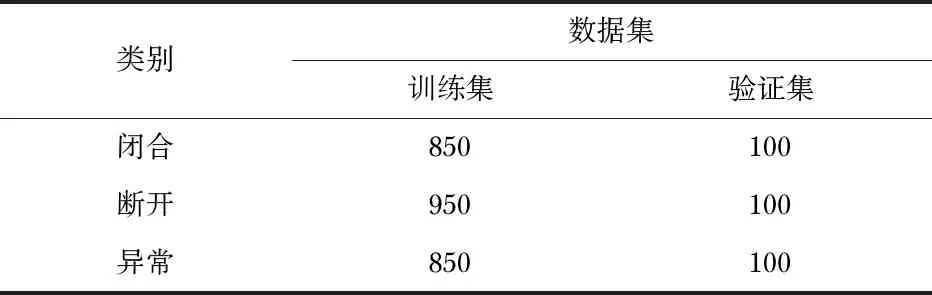
表1 数据集各类别数据量情况
3.2 实验平台
本研究使用的计算机为戴尔图形工作站,显卡型号为NVIDIA Quadro P4000,显存为8GB,计算能力为6.1。基于Python语言及PyTorch[9]深度学习框架。还需安装CUDA和cuDNN用于GPU加速[10]。
3.3 超参数配置
VGG—16网络全连接层参数采用随机初始化方法(高斯分布,μ=0,σ2=1);损失函数使用交叉熵,优化器采用Adam优化器[11];初始学习率设为0.000 01;BatchSize设为16;DropOut权重设为0.5;共训练5个Epoch(即830个Batch)。
3.4 实验结果与分析
3.4.1 VGG—16改进方法比较
本文提出的VGG—16改进模型与不同中间隐层节点数的5个VGG—16模型进行对比,这5个模型的中间隐层数分别为0,30,300,3000,4 096,其中,4 096为原型的节点数,训练过程的Loss曲线如图4所示,训练集准确率曲线如图5所示。
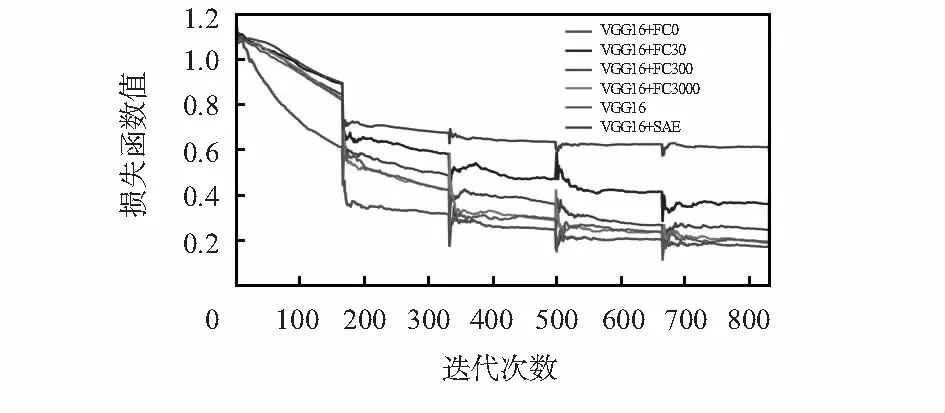
图4 训练过程的Loss曲线
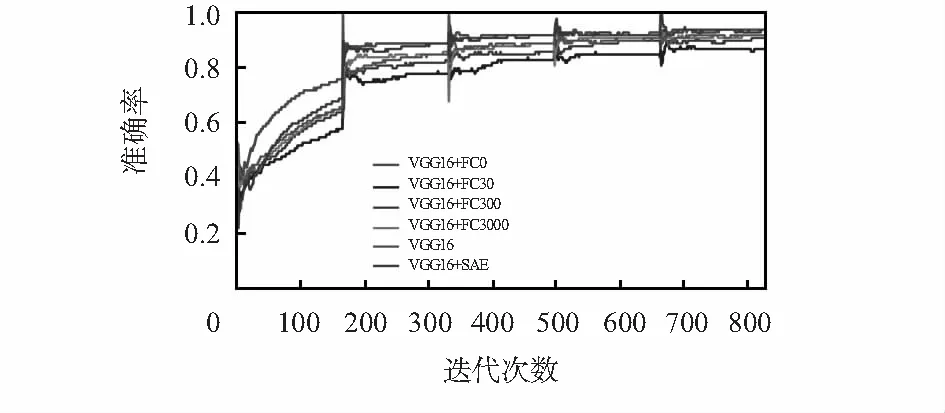
图5 训练过程的准确率曲线
对于Loss曲线,随着迭代的进行,6个模型均不同程度收敛。其中,VGG16+FC0模型的收敛速度最快,在第1个Epoch中,Loss值迅速下降,并最终在经过了5个Epoch之后,其值收敛于0.170 3,为6个模型中最小的;对于训练集准确率曲线,亦是VGG16+FC0模型的上升速度最为迅速,并在最终达到了最高的94 %。
再看本文提出的改进模型VGG16+SAE,其准确率最终也收敛于94 %,但是其Loss值为6个模型中最高的,说明其他5个模型均陷入了不同程度的过拟合,VGG16+FC0过拟合最为严重。表2给出的验证集准确率也能够印证这一点,训练集准确率与验证集准确率差距过大。

表2 各VGG16模型验证集准确率 %
3.4.2 与传统算法的比较
本文算法与传统的CNN模型(AlexNet,VGG16,ResNet50,DenseNet)在验证集上做了对比,表3给出了各模型的验证集准确率。由表中数据可知,传统算法中,VGG—16在验证集准确率上达到了最高的88 %,而ResNet50和DenseNet121则低于80 %;本文提出的VGG16+SAE的算法识别准确率为92 %。

表3 传统算法与本文算法的验证集准确率 %
文献[2]提出的算法需要人为设计特征,虽然有能力克服平移、尺度对识别的影响,但在复杂光线条件中并不具备良好的适应性,需要经常校正模板图,在本实验中仅有70 %的识别率。
3.5 识别结果展示
图6展示了本文算法的部分识别结果,可见在复杂的地铁工况中,即使图像画面质量不高,该算法也达到了优秀的识别效果。

图6 刀闸状态识别结果
4 结 论
本研究基于VGG—16CNN,使用了一种改进的结构,将原型网络与SAE相结合,并运用SAE优化卷积特征,有效缓解了深度网络易于陷入过拟合的问题。实验中使用了VGG—16不同隐含层节点的变型。训练策略上,使用迁移学习技术进行模型的微调训练,卷积层参数从预训练模型中迁移而来,这保证了优秀的特征提取能力,又节省有限的计算资源,提高模型训练速度。此外还应用了数据增强、Dropout等多种正则化方法提高模型的泛化性能。在对复杂光线条件下图像数据的识别中,该模型的验证集准确率达到92 %,表现出优异的准确率和泛化性,能够为地铁运维人员提供可靠参考。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科学技术创新(2021年14期)2021-05-28 06:18:46
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
环球市场(2021年13期)2021-01-16 00:28:43
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子测试(2016年8期)2016-07-29 08:28:53
