
英语发音通过嵌入式实时系统的识别设计及功能实现
2021-03-02 14:46:30赵丽娜
中阿科技论坛(中英文) 2021年1期
赵丽娜
(西安培华学院,陕西 西安 710125)
英语作为全球通用语言,一直也是我国各高校的教学重点。虽经过多年的英语学习,高校学生仍然存在英语交际能力较弱的问题。因此,快速发展完善的计算机网络信息技术,为英语口语辅助学习提供技术支撑,通过多媒体及网络技术设计并完善英语口语发音学习系统已成为研究的重点之一。随着嵌入式技术及自动测试技术的发展,为英语发音识别系统的优化设计提供了有效地实现路径,进而有利于提高英语听力教学的自动化及智能化水平。本次研究中主要基于嵌入式信息技术,对实时英语发音识别系统进行优化设计,通过嵌入式系统硬件平台完成了发音识别算法程序及发音误差自动检测方法的设计[1]。
1 需求分析
由于嵌入式实时英语发音识别系统的使用者较多,需提升系统运行时的抗噪声能力,确保系统具备良好的稳定性,满足对不同用户的英语发音识别需求。目前市场现有的英语发音识别系统普遍存在语言识别准确性不足的问题,发音中不同的口音及方言会对英语发音识别过程产生较大的影响,一定程度上降低了语音识别系统的精准度,嵌入式技术通过融合当前快速发展的信息化技术得以在众多领域(包括工业、农业、教育信息化等)广泛应用。通过在芯片中写入设备控制程序实现芯片在相关设备中的嵌入,然后使用该嵌入式芯片对设备完成相关控制操作。在语音识别系统中应用嵌入式技术具备较大的优势,嵌入式芯片具有耗能低、可靠性高、体积小等优势,可显著提升系统的设计性能,在节约发音识别系统设计及使用成本的同时,系统对于特定人发音的识别精度可达到97 %以上,设计实时英语发音识别系统时通过嵌入式芯片的使用实现了系统体积及性能的优化,人际交互模式的简化。基于嵌入式技术的实时英语发音识别系统可根据用户的讲话内容,对接收到的发音信号进行实时传输处理,同时将相应的发音识别算法嵌入识别系统中,实现对英语发音的快速实时识别功能,进而使英语发音的识别速度及准确率得到显著提升。通过该识别系统能够有针对性地满足不同用户的使用需求[2]。
2 嵌入式实时英语发音识别系统设计
2.1 系统的总体架构及主要功能模块设计
目前市场上已经有较多的英语学习软件应用到实际教学中,但现有软件大多只是简单的集成各类资源,对于英语发音识别方面普遍存在识别效率及准确率较低,且反馈不及时等方面的问题。本系统主要由(嵌入式)中央处理器、只读及可读写存储器、外围控制电路及外围设备等构成,为尽量缩小该嵌入式实时英语发音识别系统的体积,系统在对发音信号进行转换时采用了相应的语音解码芯片,再通过使用S3C240对语音信号进行计算和处理完成其到控制指令的转换,并采用二极管对输出内容进行检测,从而提升系统发音识别正确率。
该系统的主要功能模块包括两方面。(1)发音训练功能模块。该英语发音识别系统接收到用户的英语发音后,通过使用嵌入式算法完成对用户发音机械能的多次训练,并在此基础上对发音进行预处理,完成对该英语发音特征参数的有效提取,从而使系统英语发音的识别精度得到有效提高。(2)发音识别功能模块。针对输入的发音,系统将提取出的发音特征矢量参数同参考模型库进行相似性度比较,从中挑选出相似性高的特征矢量作为系统识别结果的输出[3]。
2.2 嵌入式发音识别算法
针对该嵌入式实时英语发音识别系统,通过基于隐马尔科夫模型(HMM)的使用完成对嵌入式发音识别算法的构建,对英语发音信号统计特性的变化情况使用马尔科夫链进行模拟,具体使用三元的参数函数进行描述,函数关系表达式如下:

A表示隐含状态转移概率矩阵,B表示观测状态转移概率矩阵,对隐马尔科夫模型中的参数进行简化,模型中的Markov链由N表示,由S表示其状态集合,由π表示初始状态的概率分布矢量,关系式如下:
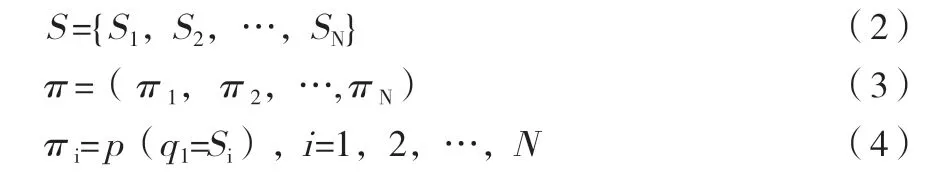
初始状态分布满足条件如下:

由π,A对隐马尔科夫模型中的Markov链进行描述,并产生对应的状态序列。通过将HMM算法芯片嵌入该实时英语发音识别系统中实现对语音信号的准确高效的处理(包括预加重、分帧、FFT变换等),在此基础上完成英语发音信号的实时提取操作,从而完成英语发音的实时识别 。
3 系统设计与实现
3.1 系统硬件设计
该嵌入式系统的硬件设计主要针对主控核心及发音识别两个关键功能,对于实时英语发音识别系统的主控核心功能的实现主要采用嵌入式微处理器芯片,主控制器则选用STM32FC8T6芯片(ST公司),包含高速存储器的STM32芯片中的增强I/O端口可有效满足系统的发音识别需求[4]。对于发音识别功能则通过使用LD3320芯片(ICRoute公司)实现,该芯片包含丰富的发音识别算法(经过集成优化处理),可使发音实时识别的准确率得到有效提高。
3.2 英语发音识别软件代码实现
在设计该实时英语发音识别系统的软件功能时,主要通过C语言的使用完成系统功能代码的编写,case1~case6分别表示没有检测出声音、需要重新训练一遍、环境太吵、数据库满、检测出声音不同、序号错误等6种情况,RSP_NAMEDIFF和RSP_CMDDIFF分别表示两次输入名称不同、两次输入命令不同。部分主要代码如下 :
发音输入:


3.3 系统发音误差自动检测功能的实现
3.3.1 特征分解和关联维特征配准
系统发音误差自动检测过程是通过时频特征分解方法的使用,完成对英语发音信号的降噪处理。本文在此基础上通过综合运用时频分析和提取关联信息熵特征的方式,进一步优化设计发音误差自动检测方法,提高发音识别的误差检测能力。输入状态参数N(j)用于表示输入信号(第j层滤波器组)的长度表示小波系数(指系统声调的发音长度内),w(j)表示小波子带,为w(j)的长度[5],对输出的经过降噪处理的英语发音信号进行特征分解和配准,分解滤波器组由AFB表示,语音识别系统的软阈值函数由c(j)表示、硬阈值函数由w(j)表示,信号的小波变换表达式如下 :

其中,1≤j≤J。
在特征分解和关联维特征配准过程中的发音信号重组通过结合使用小波多层重构方法完成,系统的重构滤波器组由SFB表示,获取的信号滤波的逆变换表达式如下:
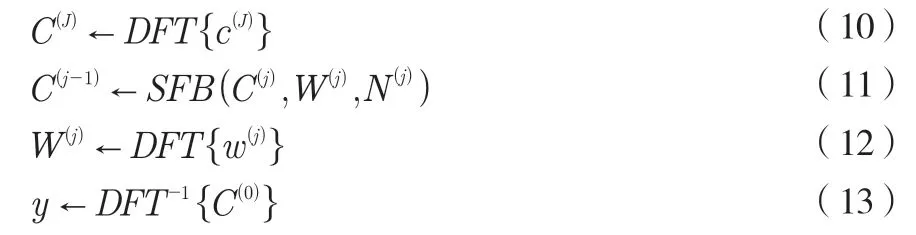
其中,1≤j≤J。
接下来对发音信号进行滤波检测(属于一个迭代过程),具体采用自相关匹配滤波方法实现,对声调特征序列进行离散傅里叶变换(DWT)处理,k表示发音信号的长度,具体表达式定义如下:

然后提取发音发音信号的关联特征量,再对发音信号通过级联滤波方法的使用完成盲源分离处理过程,完成不同分辨率(由j表示)语音信号的重构,具体表达式如下:
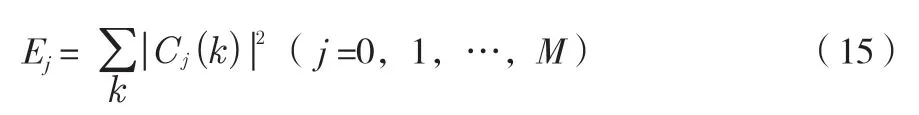
再将信号经傅里叶变换后完成从时域到频域的过渡,发音信号的长度由N表示,帧的频率由J表示,在自适应增强含噪的发音信号的基础上,获取各子信号输出的小波系数表达式如下:
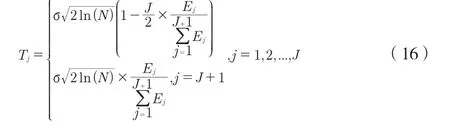
提取发音语音信号的关联特征量,通过使用新的阈值函数判别发音准确性,表达式如下:
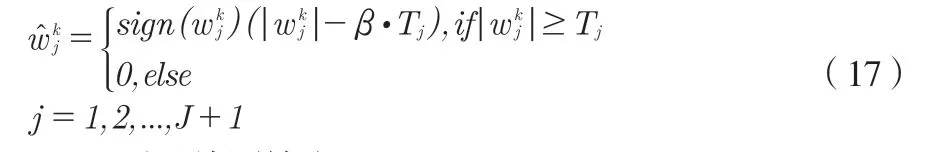
3.3.2 误差检测输出
重组发音信号结合小波多层重构方法完成后,对信号的关联信息熵特征进行提取,采用时频分析方法将发音信号从时域转换到频域,语音信号的瞬时频率的估计表达式如下:

时频分析过程综合运用WVD时频分布和Hough变换完成,对发音信号的特征进行提取和分类识别,采用合同矩阵产生发音特征目标函数,表达式如下 :

计算信号的自适应功率谱密度特征,给定发音状态特征向量集合表示如下:

发音的信号谱平均频率通过使用动态反馈方法获取,表达式如下:

针对英语发音信号通过时频分析Viterbi算法的使用完成检测过程,对发音信号进行时频分析及其特征量提取,得到发音误差自动检测硬、软阈值函数,表达式分别如下 :

4 系统测试及结果分析
本文通过实验对系统的发音识别率进行测试,分别在安静以及嘈杂环境下使用5条英语发音指令对系统进行对比测试,每条发音指令分别测试10次,在不同环境下针对特定人进行试验,记录系统成功识别的次数[6]。采样频率设为12 500 Hz,发音识别过程中的信噪比范围在-5 dB~20 dB(可通过递增产生不同的信噪比),基于MVDR波束对系统的识别率进行采样分析。本文的嵌入式实时英语发音识别系统的正确识别率(89 %)明显高于传统声音识别系统(60 %),使用系统中语音识别算法,能够实现对英语发音实时高效的识别,具有较高的英语发音识别速度及识别准确率。对所设计的系统发音误差自动检测性能进行测试,采样Matlab进行仿真实验,仿真时长为1 000,特征采样的归一化初始及终止频率分别为0.3、0.05,检测的信号长度为1 200,迭代次数为100,噪声干扰信噪比分别为-5 dB和-8 dB,之后得到采集系统的发音信号。将该发音信号作为测试样本,采用时频特征分解方法完成降噪处理、特征分解和关联维特征配准,对发音信号的分辨能力、检测的准确率、系统发音误差自动检测功能的有效性进行验证后发现,该系统以英语发音为依据做出相关控制命令,能够对英语发音进行快速识别,显著提升了检测的准确度,具有较高的应用价值 。
5 结语
本文通过多媒体控制及发音控制技术的综合运用,完成对发音识别系统的设计,通过运用提取关联信息熵特征和时频分析实现系统发音误差自动检测,设计并实现了嵌入式实时英语发音识别系统,针对复杂的英语发音信号可结合专家系统分析方法完成特征的识别和分析,在此基础上完成英语发音的误差纠正,对英语发音信号采用时频特征分解方法进行降噪处理,再对处理后的信号进行特征分解和配准,提取发音信号的关联信息熵特征,并据此进行自动匹配完成误差的自动识别,从而使英语发音教学质量及效率得到显著提升[7]。
猜你喜欢
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
现代计算机(2019年6期)2019-04-08 00:46:50
铁道通信信号(2018年2期)2018-04-18 12:18:23
电镀与环保(2016年3期)2017-01-20 08:15:32
舰船科学技术(2015年8期)2015-02-27 15:38:48
电测与仪表(2014年17期)2014-04-04 11:56:48
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:13
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
自动化博览(2014年4期)2014-02-28 22:31:15
