
基于动态软聚类的航空电子部件LMKELM诊断模型
2021-03-02 06:09:40戴金玲许爱强
系统工程与电子技术 2021年3期
戴金玲,许爱强
(海军航空大学,山东 烟台 264001)
0 引 言
随着航空电子设备不断信息化与智能化,故障诊断技术作为维修保障体系的重要组成部分,急需进一步被研究。然而航空电子设备故障模式多样、样本规模偏小、交联关系复杂,给故障诊断带来了极大的困难。
针对模块级电子部件的故障诊断方法,国内外学者进行了大量研究,相比于深度学习[1-4]需要大量的样本,基于核的学习算法[5]则不需太多样本,因此适用于本文的小样本前提条件[6-7]。其中,多核学习[8-9](multiple kernel learning,MKL)通过核函数及其参数的选择,具有较强的泛化性能。文献[10-12]研究了多核函数的选择、组合与优化,得到了更强的非线性表达能力与稳定性,同时也导致更高的计算复杂度。为解决这一问题,文献[13]提出了增量MKL方法,有效控制了计算量。考虑到MKL的优点,多核超限学习机(multiple kernel extreme learning machine,MKELM)被应用到了模拟电路、变压器、局域网等故障诊断领域[14-17],极大提高了多种复杂故障的诊断精度,而如何在继承样本局部特征与防止过度学习之间寻找一个平衡点则成为了新的研究热点。
为进一步体现基核函数在不同样本空间的可用性差异,文献[18-21]提出了局部MKL (local MKL,LMKL),包括面向样本的LMKL(sample-based LMKL,S-LMKL)算法[22-23]和面向群组的LMKL(group-based LMKL,G-LMKL)算法[24-25]。S-LMKL算法充分体现了样本类内多样性,例如文献[26]将样本的近邻信息纳入每个样本的学习过程,有效提高了诊断效果,但也带来了较高的计算复杂度和过度学习的风险。相比之下,G-LMKL可以控制聚类数目,具有更高的灵活性[27]。文献[28]采用了近邻传播聚类的方法,将局部权重拟合到各个样本上,可有效抵御过拟合的风险,但粗暴的“硬聚类”也可能损失样本的多样性特征。文献[29]针对文献[28]的“硬聚类”,引入了隶属度的概念对样本进行“软聚类”,更好地考虑了聚类内部基核的可用性差异,但其聚类数目需要凭经验与实验提前自行确定,即“静态聚类”,在确定聚类数目的过程中花费的成本是较高的。同时,文献[18]最早提出的局部多核模型中,带来了困难的局部权重二次非凸问题,一种解决方法[18,28]是通过构造一系列选通函数,经过两步交替优化策略近似求解局部权重,如何选择选通函数成为一大难点;另一种方法[25,29]则是根据初始对偶优化问题,对参数进行3步交替优化,以获得参数解,但其结果准确性有待研究。
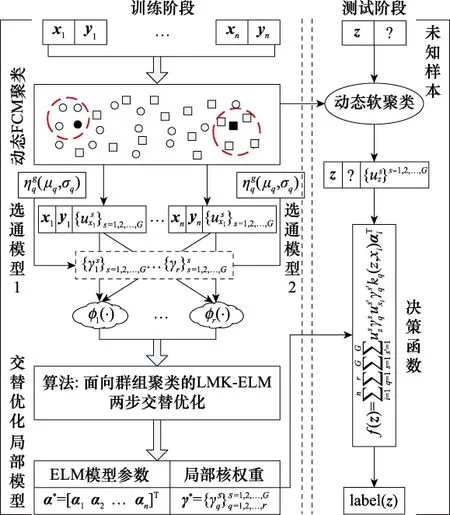
在故障诊断的过程中,以下3个关键问题制约着优化问题的求解:① 依赖经验决定聚类数目的“静态聚类”方法是否为最佳;② 硬聚类可能带来诊断准确性的下降;③ 关于局部权重的求解是困难的二次非凸问题。因此,本文结合航空电子设备及其故障诊断的特点,提出了一种基于动态软聚类的局部多核超限学习机(dynamic fuzzy clustering LMKLELM,DFC-LMKELM)诊断模型,主要贡献如下:
(1) 区别于需要提前确定聚类数目的“静态聚类”,受文献[30-31]启发,提出基于局部密度的动态均值聚类算法(density-based fuzzy C-means algorithm,DB-FCM),依据性能代价函数自适应确定最佳聚类数目,并将该信息融入模糊C均值聚类算法(fuzzy C-means algorithm,FCM)中。在继承G-LMKL的局部特征表达能力及ELM高效计算特点的同时,根据样本特点自适应地确定聚类数目,发掘各聚类之间的差异,优化了诊断效果。
(2) 面向二次非凸的局部权重求解问题,通过两步交替策略优化问题,分别从输入与特征空间的聚类特征出发,构造两种选通函数模型参数近似得到局部权重。将局部权重融合FCM的隶属度信息,在保持聚类特征的同时,完成了LMKELM关于局部权重的求解。
1 问题描述
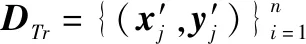

(1)

将式(1)的Lagrange函数分别对βq与ξi求偏导,同时使偏导结果为0,从而得到式(1)的对偶优化形式为
(2)
式中,αi为Lagrange乘子,对应于ELM的模型参数,并且αi=[αi1,αi2,…,αim]T,α=[αi,α2,…,αn]T。
求解式(2)所示对偶优化问题,一般通过交替优化的方法,不断更新Lagrange乘子与局部核权重,并获得以下决策函数
(3)
2 基于DB-FCM的LMKELM模型
2.1 基于局部密度的动态聚类方法
为实现动态软聚类,本文提出DB-FCM。该算法首先通过局部密度算法得到了按局部密度降序排列的聚类中心,并限定了聚类中心数目,以性能代价函数为依据来获得最佳聚类数。将该最佳聚类数目代入FCM中,从而获得故障样本对于各个聚类的隶属度。
定义 1样本xi的局部密度ρi定义为
(4)
式中,dij表示样本xi和xj之间的距离;dc表示截断距离。dc为所有dij按降序排列,第p%(其中p∈[2,5])的距离。文中距离均为Euclidean距离。

定义 3假设两个样本xi、xj之间的距离dij 定义 4假设在数据集X之中包含有t个样本xs,xs+1,…,xt-1,xt,若对任意i∈[s,t-1],均有xi+1对xi是直接密度可达,则称xs对xt为密度可达。 定义 5将直接密度可达或密度可达的两个样本称为邻居。 定义 6将没有邻居的样本点称为边缘点。 初始聚类中心选择原则是:局部密度大、即被越多邻居包围的点,如图1中A点为局部密度最大的点,若A不属于任何聚类,则A为聚类中心,B、C、D为A的直接密度可达点,E为间接密度可达点,F为边缘点。 图1 局部密度图Fig.1 Picture of local density 通过对p的限定确定最大聚类中心数目,采用迭代求解的过程获得隶属度矩阵及最佳聚类数目,具体步骤如下: 步骤 2计算样本距离矩阵D=(dij)n×n及dc,根据式(4)得到样本点局部密度ρ=(ρi)n,idx为局部密度按降序排列的名次标签。 步骤 3按idx标签依次选取样本点xidx(j),若xidx∉V且Neighbor(xidx(j))的数量大于1,则xidx(j)为下一个聚类中心点,更新V和Cmax,并将xidx(j)及其所有邻居标签为已分类。 步骤 4若所有样本点已标签或迭代结束,执行步骤5;否则执行步骤3。 步骤 5输入训练数据集,设定模糊聚类数目kn=2。 步骤 7若kn 隶属度矩阵Ukn={uij}(1≤i≤n;1≤j≤C),其中,uij表示第i个样本落入第j个聚类的隶属度,即第i个样本属于第j个聚类的可能性。且Ukn满足: (5) (6) 显然,J(α,γ)是一个关于α和γ的多目标函数。求解该函数采取两步交替优化的方法交替更新Lagrange乘子α与局部核权重γ,然后通过选通函数近似得到α和γ的值。 2.2.1 固定γ并更新α (7) 图2 增广矩阵K′Fig.2 Augmented matrix K′ 将式(7)中目标优化函数对α′求偏导,并使结果为0,可得 α′=(K′+I/C)-1y′ (8) 式中,I是一个m×n阶的单位矩阵。通过对α反向量化操作可得α=Vec-1(α′)。 2.2.2 固定α并更新γ 结合聚类信息后,简化式(6),令 (9) (10) 式(10)是关于γ的二次非凸问题。参考文献[28]中的做法,本文将分别根据训练数据在输入空间与特征空间的统计特性,采用两种选通函数来解决二次非凸问题。 2.2.3 选通函数 (1)面向输入空间选通函数M1 定义输入空间中第g个聚类在第q个基核上的选通函数为 (11) (12) (13) 由式(12)、式(13)可得目标函数J(γ)关于模型参数的梯度,通过梯度下降法不断迭代各个参数,则有 (14) 式中,τ11(t)和τ12(t)表示迭代步长,在迭代过程中通过线性搜索的方法可得。 (2)面向特征空间选通函数M2 定义特征空间中第g个聚类在第q个基核上的选通函数为 (15) (16) (17) (18) 由式(17)、式(18)可得目标函数J(γ)关于模型参数的梯度,然后同样通过梯度下降法迭代各个参数,即 (19) 式中,τ21(t)和τ22(t)为迭代步长,在迭代过程中采用线性搜索方法得到。 (20) DFC-MKELM决策模型如图3所示,整体框架总结如图4所示。假设模型中测试样本的输出为f(z)={f(1)(z),f(2)(z),…,f(m)(z)},其中m为输出节点的数量,f(l)(z)表示第l个节点的输出结果,最终测试样本z的故障诊断如下: (21) 图3 DFC-MKELM决策模型图Fig.3 Decision-making model of DFC-MKELM 为简化表达,将DFC-MKELM在不同选通函数下的诊断模型分别表示为M1-DFCMKELM和M2-DFCMKELM。故障诊断模型的具体流程图如图4所示,具体算法步骤如下。 图4 DFC-MKELM诊断模型流程图Fig.4 Flowchart of DFC-MKELM diagnosis model 步骤 5令t=1,根据式(10)计算可得目标函数表达式Jt(γ)。 步骤 7执行步骤4~步骤6;通过式(10)计算Jt+1(γ);如果|Jt+1(γ)-Jt(γ)|>10-3,t=t+1,返回步骤7;否则执行步骤8。 为了验证算法的有效性,将算法应用于两个数据集中。将SimpleMKL[9]、GMKL-ELM[17]、l1-FCLMKELM[29]、M2-LCMKELM[28]作为比较算法。进行实验前,所有数据均进行Z-score标准化处理,把非高斯核矩阵正规化为具有单位迹,即tr(Kq)=1。正则化因子采用5倍交叉验证的方式从{10-2,0.1,1,10,102,103,104}中选出;所提方法中涉及的DB-FCM算法中参数设置为p=5,m=2,Tmax=100;AP算法中λ=0.8,最大迭代次数设置为1 000。实验平台为Matlab 2018 a,电脑配置为2.27 GHz Pentium Dual-Core CPU,2GB RAM。 本节首先验证算法在Gauss4人工数据集[25]上的有效性。该数据集共1 200个样本,包含两种类别,各类别分别服从两种高斯分布,具体先验概率、均值、协方差信息如下: ρ11=0.25,ρ12=0.25,ρ21=0.25,ρ22=0.25 随机选择数据集中的2/3作为训练样本,剩余1/3为测试样本,实验共进行10次。首先根据DB-FCM算法对训练样本进行聚类,参数p=5的条件下,最佳聚类数目为3。基核设置为线性核、多项式核(参数为2)、高斯核(参数为1)。作为评价指标,将分类精度、F1值和G-mean以“均值±标准差”的形式记录于表1。 表1 Gauss4数据集指标值Table 1 Index values of Gauss4 static 由表1可知,与其他方法相比,本文诊断模型的性能指标值均为最优。原因如下: (1) 同样作为LMKL方法,与SimpleMKL将局部核权重拟合到每个确定样本不同,本文模型考虑了每个样本的局部特征信息,一定程度上抑制了过学习问题; (2) 同样作为G-LMKL方法,与GMKL-SVM、M2-LCMKELM的“硬聚类”方法相比,本文模型中融入了隶属度信息,实现了“软聚类”,从而更完整地描述了聚类内部多样性,使诊断精度更高; (3) 同样作为基于“软聚类”的LMKL方法,与l1-FCLMKELM的“静态软聚类”方法相比,本文模型所提的“动态软聚类”方法自适应地确定了最佳聚类数目,进一步提高了诊断精度。 如图5为SimpleMKL、l1-FCLMKELM、M2-LCMKELM与本文M2选通模型的接收者操作特征(receiver operating characteristic,ROC)曲线。显然,本文模型的曲线下方面积(area under the curve,AUC)大于其他曲线,更直观地展现了性能优势。 图5 Gauss4数据集的ROC曲线Fig.5 ROC curves of Gauss4 data 为验证“动态软聚类”所确定的最佳聚类数目的有效性,本文随机设置了10个聚类数目进行训练与测试,将其关系折线图绘制于图6中。由图6可见,当聚类数目为3时,诊断精度达到了第一个极高值,说明了“动态软聚类”算法的有效性;而后随着聚类增加而呈现不规律的波动;当聚类与样本数相同时,本文方法演变为面向样本的LMKL方法,产生了过学习的风险,诊断精度也因此下降。 图6 聚类数目与诊断精度关系Fig.6 Relationship between of clusters number and diagnosis accuracy 本节以旋转变压器激励发生电路为例验证算法的性能,其组成框图如图7所示。自动测试系统(automatic test system,ATS)共包括9个测试项目,±15 V电源电压值、+5 V与+10 V电源电压值、信号频率与幅值、正弦模块输入电压值、信号频率稳定度和电路板工作温度。旋转变压器共分为4个模块,由电源模块供电,由正弦信号模块产生磁绕组所需的正弦信号以提供激励,由频率控制模块、幅值调理及驱动能力调节模块来控制激励的类别输出。 图7 旋转变压器电路图Fig.7 Circuit diagram of rotary transformer 用F0,F1,F2,F3及F4分别表示正常模式、控制模块故障、幅值调理及驱动能力调节模块故障、电源模块故障以及正弦信号产生模块故障。ATS共采集5种模式下的原始数据样本数为32,22,20,24及28。 随机选择原始数据中的1/2作为训练样本,剩余1/2为测试样本。设置多核及其参数分别为:线性核,多项式核(参数2),高斯核(参数2,10,20,30,40,50)。首先采用DB-FCM获得最佳聚类数目为4,并对训练样本进行聚类,可得表2所示隶属度矩阵。 表2 隶属度矩阵Table 2 Membership matrix 本节将本文模型与SimpleMKL、GMKL-ELM、l1-FCLMKELM、M2-LCMKELM 4种方法分别基于采集数据进行训练与诊断,图8为各方法的混淆矩阵,图9为本文模型聚类方法的局部权重分布,表3为各方法的性能指标值,可见: (1) 作为局部多核学习方法,所有方法均实现100%的训练诊断精度,验证了该类方法的有效性。 (2) 相比于SimpleMKL、GMKL-ELM、l1-FCLMKELM 3种方法,M2-LCMKELM本文模型实现了零漏警与零虚警,表现优异,验证了选通函数的良好性能。 (3) 相比于4种比较算法,M1-DFCMKELM分别将诊断精度提高了6.35%、3.17%、0和1.59%;M2-DFCMKELM则提高了7.94%、4.76%、1.59%和4.37%,验证了本文模型的有效性。数据显示l1-FCLMKELM的诊断率也是偏高的,而该方法也融入了隶属度信息,进一步验证了隶属度信息的融入能更充分地挖掘类内多样性。 (4) 本文模型中,M2选通函数的诊断精度略高于M1选通函数,原因在于M1选通函数的局部权重为稀疏解,而M2选通函数则是非稀疏解,如图9所示。相比于稀疏解,非稀疏解包含了更全面的权重信息,因此诊断精度更高。 为进一步验证本文模型有效性,表4给出了各方法的F1值与G-mean的性能指标值,显然本文模型依然表现最优。此外,为比较各方法的时间开销,通过分别实验10次并以“均值±标准差”的形式记录于表5,由表可见: (1) 相比于一般的MKL方法,LMKL方法的训练时间普遍更长;4种LMKL方法花费的时间则相似,其中相比于采用范数约束的LMKL(即l1-FCLMKELM),采用选通函数的LMKL方法训练时间甚至更短。 (2) 相比于其他4种方法,本文模型所用测试时间均为最低;由于M1-DFCMKELM局部权重为稀疏解,其测试时间最短。 (3) 相比于在线故障诊断方法,线下诊断方法对实时性的要求较低,少量时间的代价以换取更高的诊断精度是值得的,同时由于面向的样本规模较小,在时间上的开销差别是可忽略的。 图8 各方法混淆矩阵Fig.8 Confusion matrices of different algorithms 图9 DFC-MKELM的局部权重分布图Fig.9 Localized weights distribution of DFC-MKELM 表3 各方法指标值Table 3 Index of methods % 表4 各方法的F1分数和G-meanTable 4 F1 score and G-mean of the methods 表5 各方法的时间消耗Table 5 Time cost of methods s 针对航空电子部件模块级故障诊断问题,本文提出了基于DFC-LMKELM故障诊断模型。以Gauss4数据集及旋转变压器激励发生电路为例,验证了本文模型的性能,结果表明: (1) 在聚类数目方面,相比于根据经验或反复试验确定聚类数量的l1-FCMKELM,基于局部密度的动态软聚类方法能够自适应获得最佳聚类数目,节约了时间与经验成本,并验证了有效性。 (2) 在诊断时间方面,相比于一般的MKL方法,本文模型所用训练时间有所增加,但测试时间有所减少,用少量时间的代价换取了诊断精度的提高。 (3) 在诊断精度方面,相比于一般的MKL方法(SimpleMKL、GMKL-SVM)、基于“静态软聚类”的LMKL方法(l1-FCMKELM)和基于“硬聚类”的LMKL方法(M2-LCMKELM),本文模型在漏警和虚警方面表现的更加优异,并将诊断精度平均值分别提升了2.78%和4.37%。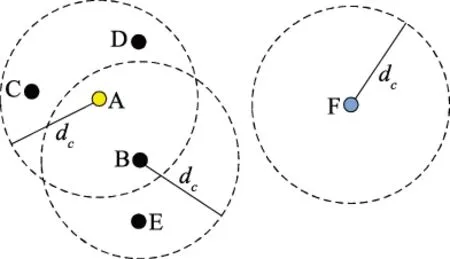



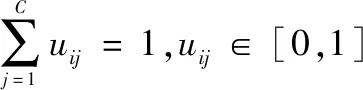
2.2 基于动态软聚类的诊断模型优化


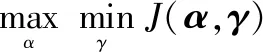

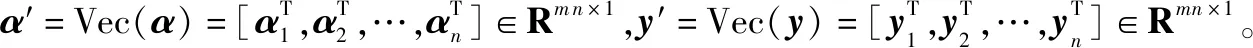






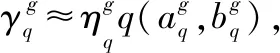
2.3 诊断决策


3 算法流程
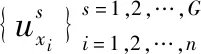
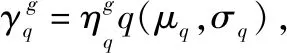
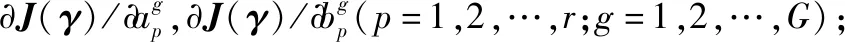

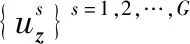
4 实验分析
4.1 人工数据集验证

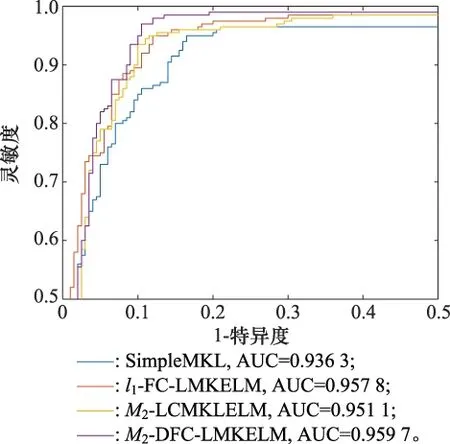

4.2 旋转变压器激励发生器故障诊断实例

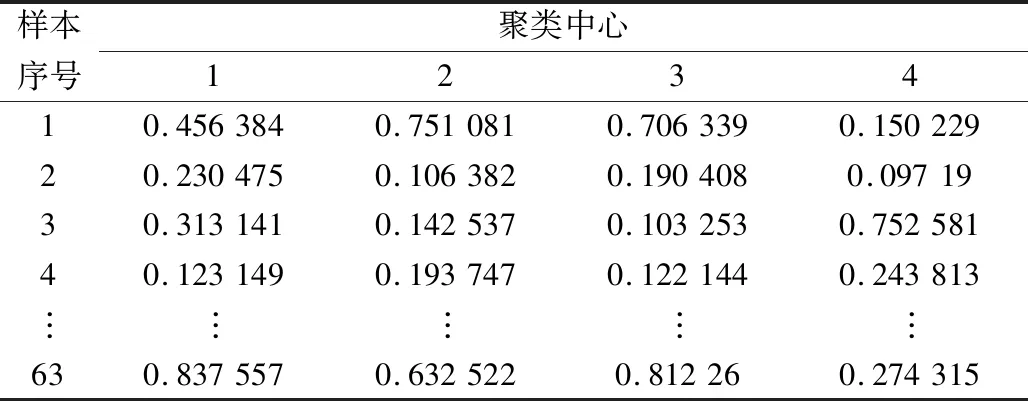

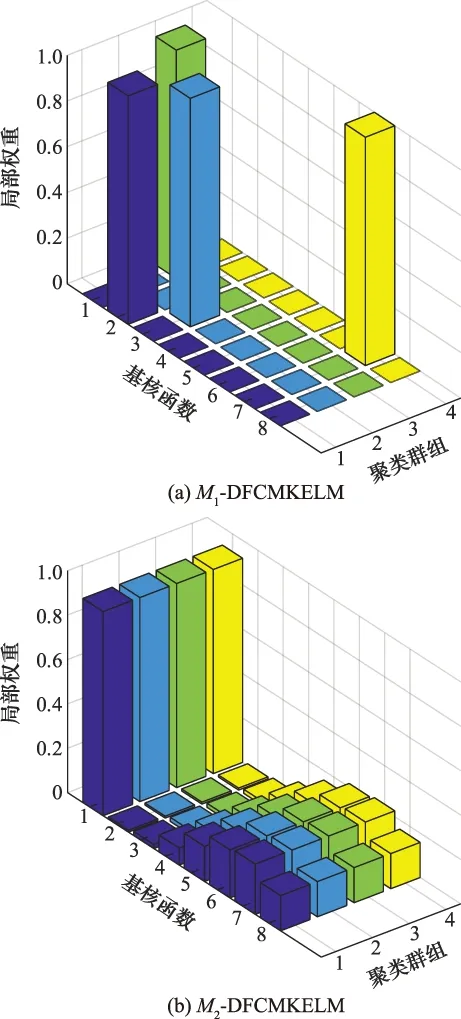
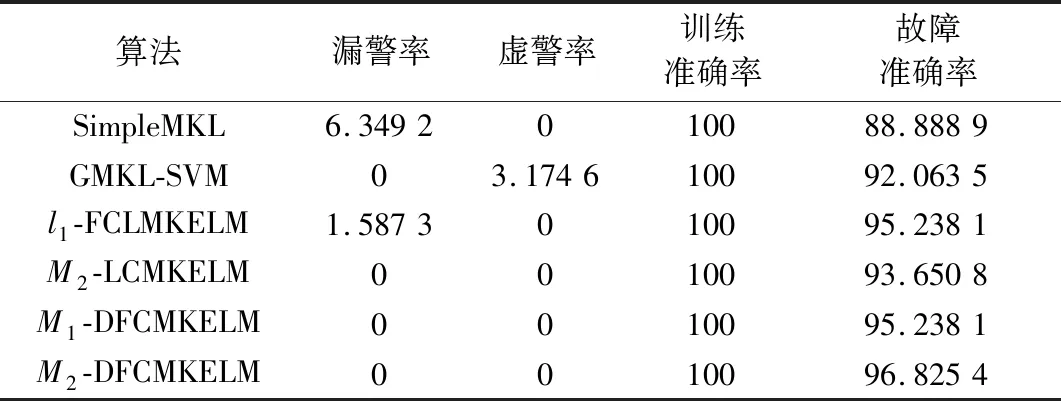


5 结 论
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35电子测试(2017年15期)2017-12-18 07:19:27中国民族医药杂志(2016年5期)2016-05-09 07:43:50作文大王·低年级(2016年3期)2016-03-11 00:48:53重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58智能系统学报(2015年4期)2015-12-27 09:38:39电子设计工程(2015年6期)2015-02-27 12:04:53振动、测试与诊断(2014年5期)2014-03-01 01:14:21机械与电子(2014年1期)2014-02-28 02:07:31河南科技(2014年3期)2014-02-27 14:05:48
