
基于词云和文章主题的校园综合新闻聚类
2021-03-01 02:48:04郝秀慧方贤进杨高明
安徽理工大学学报(自然科学版) 2021年6期
郝秀慧,方贤进,杨高明
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
随着互联网技术的高速发展和数据采集、存储技术的日益进步,人们可以很方便地在网上查找各类信息来满足个人的知识需求。面对大量的数据,人们总是希望能从快速地从这些数据中获取有价值的信息,由此产生了数据挖掘技术。一般而言,数据挖掘可由数据是否含有类别标签分为两种:第一种是有监督的数据挖掘,主要是利用数据建立对一个特定属性进行描述的模型,包括分类,预测等任务;另外一种是无监督的数据挖掘,主要是在数据属性间寻找某种关系,包括关联规则和聚类任务。本文是属于无监督的数据挖掘。在事先不知道数据类别的情况下,对校园综合新闻进行聚类。聚类属于数据挖掘的一个很重要的方向,而对文本进行挖掘,从中提取有价值的信息需要对文本进行处理,即文本聚类也属于自然语言处理的范畴。
数据挖掘技术应用广泛,可应用在医疗、电子商务、金融、交通、教育等领域。文献[7]将数据挖掘应用到电子病历文本上,文献[8]将数据挖掘应用在基于网页导航日志的电子商务系统用户偏好相似度挖掘上,文献[9]将数据挖掘技术应用到财务风险分析中,文献[10]将数据挖掘应用在交通事故严重程度的风险分析上,文献[11]将数据挖掘技术应用在智慧教育上。同时,聚类算法也在其他领域有广泛的应用。如将聚类算法应用在图像分类上,以及将聚类算法应用在彩色图像分割中等。
本文将k
-means算法应用在校园新闻聚类上,以方便对校园综合新闻的分析,快速了解新闻的大致内容。先将校园新闻关键词可视化,再将单篇文章topk
关键词作为单篇文章的主题,以主题作为分词结果。对比原来对整篇文章分词后直接进行聚类的方法,本文方法效果更好。1 相关工作
数据挖掘的一般流程是:准备数据、建立模型、评估模型。文本数据挖掘的一般流程是:准备文本数据,将文本转化为计算机可识别的符号,通常是转变为数值的形式即数据预处理,然后建立模型,评估模型。本文建立模型是使用k
-means算法。1.1 文本分析数据预处理过程
一般情况下作文本分析,都需要经过以下几个阶段,包括文本分词、文本的数据清洗、提取特征、计算词频以及构造词向量,过程如下图1所示。

图1 文本分析预处理过程图
1.2 分词
词是最小能运用的语言单位。在英文中,词一般都是用空格分开,在中文里可将句子转化为词的表示。这个切分的过程称为中文分词。分词之后,一般可将词语分为两大类,第一类是无意义的词,包括代词、介词、量词等,如“这”“那”“他们”“一个”和“一群”等。一般将这种词作为停用词处理。第二类是有意义的词,这种词又可以细分为两种:一种是在整个语料库中,词语出现的频次较高的,一般将这种词作为整个语料库的主题关键词;另一种是在整个语料库中出现的频次不高,但是在单篇文章中出现频次较高的,一般将这种词作为单篇文章主题词。
1.3 关键词提取技术
关键词提取技术中的词频—反文档频率(term frequency-inverse document frequency,TF- IDF)是基于统计学的方法,它是由词频 (term frequency,TF)发展而来,解决不同词语有相同词频的重要性问题。
1)词频TF 词频TF用于衡量一个词在一个文件中出现的频率。tf
表示词i
在j
文档中出现的频率,其计算公式如下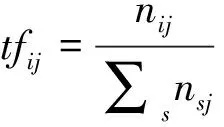
(1)
其中:n
表示词i
在文档j
中出现的频次,∑n
表示在j
文档中的总词数。从上述公式可以看出,同一个词在不同文档中的词频可能是不同的。一般来说,一个词在一篇文档中出现的次数越多,那表示这个词越重要。但是有一种特殊情况,有些词,如“的”“是”等这些词即使在文档中出现的次数最多,但是并不重要。对于这种词,一般会当作停用词处理。2)反文档频率(inverse document frequency,IDF) IDF用于衡量一个词对某篇文章的重要性。idf
表示词i
的反文档频率,其计算公式如下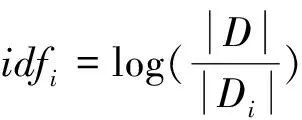
(2)
式中:|D
|表示文档集合中的总文档数,|D
|表示词i
在文档集合中出现的文档数。但是为了避免某些词在文档中出现的次数为零,导致上述公式分母没有意义的情况,引入了拉普拉斯平滑,即在分母加1,增强算法的健壮性。其计算公式如下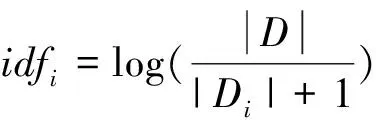
(3)
3)词频-反文档频率(TF-IDF)计算公式如下
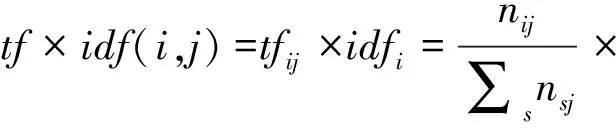
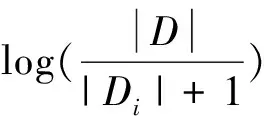
(4)
TF-IDF越大表示这个词越重要。大致表示的含义是:在所有的文档中,若一个词出现的频率在少数几篇文档或者一篇文档中比较高,但在所有的文档中出现的频率比较低,那么,这个词对这几篇或这一篇文章比较重要,这个词对文档有很好的区分度,对应的词频-反文档频率(TF-IDF)就越高。
1.4 k-means聚类算法
聚类是指由无标记数据中训练模型,从聚类结果来研究数据的规律或揭示数据的内在信息。对于给定的一组数据D
={a
,a
,a
…a
},聚类算法是通过某种相似度来把数据聚为不同的类别的。聚类期望的结果是:类内越相似越好,类间越不相似越好。目前的研究,对于文本相似度的衡量,可以用距离来衡量,也可以用余弦相似度来衡量。若是用距离来衡量,一般用欧式距离,距离越小越相似,距离越大越不相似。若是用余弦相似度来衡量,计算的结果越大越相似,越小越不相似。本实验计算相似度的方式是前者。本文中涉及到的k
-means聚类是将数据D
={a
,a
,a
...
,a
}聚为划分到k
个类中,C
={C
,C
,...C
}中,目标是最小化平方误差E
,计算公式如下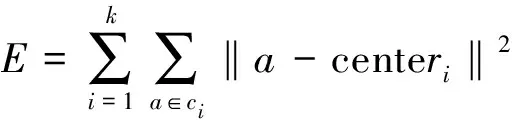
(5)
式(5)中center
是聚类中心,是第i
类的均值向量,先计算每一类中的数据到这个类中心的欧式距离和,然后再将计算的每个类的和相加,最后得到E
的值。即这个E
值刻画了类内样本围绕聚类中心的紧密程度,E
的值越小则类内样本的相似度越高,反之,则越低。k
-means聚类算法的过程如下:1)初始化聚类中心;
2)计算数据a
与不同聚类中心的距离,将数据a
划分到距离聚类中心最近的那个聚类中;3)通过计算均值更新聚类中心;
4)重复步骤2和3,直至聚类中心不再改变,或者达到最大的迭代次数。
本文采用的k-means聚类算法是应用到文本聚类上。因此,对于上述需要聚类的数据a
,它是一个一维的向量,也就是每一个文本a
=(a
1,a
2,a
3...a
),其中m
是文档总词语数或特征个数。例如在文本聚类中,每篇文章经过文本预处理后就转变成了一个个一维向量。如对10篇文章进行文本分析,若每一篇文章都是20个词,那么得到的就是一个10行20列的矩阵。2 实验分析
2.1 平台和数据
本实验所使用的平台是百度ai实验室,用到的CPU为2core、RAM为8GB、Disk为100GB,环境是jupyter notebook和python3.7、pandas、numpy、jieba.posseg,sklearn中的feature.extraction以及word-cloud。
本实验所使用的数据是安徽理工大学新闻网中的综合新闻,网址是:http://news.aust.edu.cn/zhxw.htm。实验使用爬虫程序来采集新闻文本数据,采集的过程如图2所示。本实验一共采集了综合新闻中的11 456条新闻,采集的数据保存格式包含标题、链接、日期和正文。

图2 采集新闻数据过程
2.2 根据词频得到的词云结果
通过对采集的文本数据进行分词和清洗,包括去除停用词和选取特定词性的词语,得到比较干净的样本后,再对采集到的所有数据进行词频统计,得到能对文本进行主题提取的词,并将词频最高的前50个词以词云的形式可视化出来,如图3所示。

图 3 词云结果图
词云结果图中的字越大,表示的含义是在整个新闻分词后的数据中出现频率越高。从图3大致可以看出:出现频率比较高的词有“交流”“毕业生”“领导”“精神”“会议”“教学”“创业”“生活”“培训”“座谈会”“调研”“服务”“管理”“信息”等词语。根据可视化的词云结果,这些词语大致可以将采集到的数据分为交流会议类、毕业就业类、思想精神政治类、教育教学类、学习培训类、比赛活动类和管理服务类等类别。
2.3 新闻主题词提取结果
一般来说,一篇文本的主题内容至少需要3个或3个以上的词才能概括,因此本实验经过关键词提取后保存每篇文章前3个主题,部分数据如下表1所示。

表1 部分新闻top3主题词提取结果表
2.4 聚类结果
实验根据11 456条新闻文本数据的词频得到的词云结果进行分析,将k
-means聚类算法中的聚类数k
值设置为7。然后根据每篇文章的前3个主题词对所有文档进行二次建模,并用k
-means算法对11 456条新闻文本数据进行聚类操作,得到的新闻文本聚类结果如图4所示。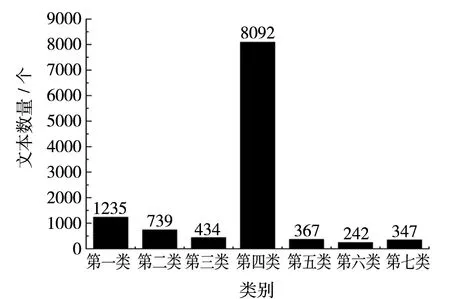
图4 新闻文本聚类结果图
其中横轴表示聚类的类别数,纵轴表示每一类的新闻文本数量。由图4可知,在聚类分析之后,得到的第四类的文本数量最多,其他类别的文档数量都比较少。
将实验中每一类的前3个关键词给展现出来,并将大致所属的类别表示出来,如表2所示。

表2 不同类别top3主题词表
根据图4和表2可以得出,校园综合新闻中关于第四类教育类的新闻数量是最多的,关于第六类学习培训类的新闻是最少的。
3 实验评估
3.1 评估指标
戴维森堡丁指数(Davies-Bouldin Index,DBI )计算公式如下
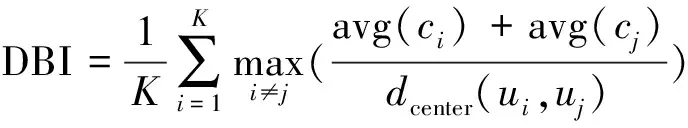
(6)
式中:avg(c
)指类内平均距离,即类内凝聚度;d
(u
,u
)指的是i
类的聚类中心与j
类的聚类中心之间的距离。聚类中希望聚类效果比较好的前提是类内凝聚度越高越好,即类内平均距离越小越好,类间越分离越好,也就是类间凝聚度越低越好。从式(6)可以看出分子越小越好,分母越大越好。整个DBI越小,表示聚类的效果越好。3.2 聚类效果对比
本实验将聚类数从二到十类依次进行实验,对比了基于文章主题的聚类方式和不基于文章主题的聚类方式,得到的DBI值图如图5所示。
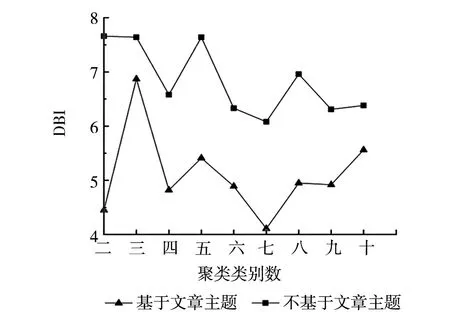
图5 DBI值
从图5可得,不管是基于文章主题的聚类还是不基于文章主题的聚类,DBI指标的值都是在聚类数为7时DBI最小。说明当聚类数为7类时,聚类的效果比较好;聚类类别数相同时,基于文章主题得到的聚类,DBI指标比不基于文章主题的DBI小。因此,基于文章主题的聚类整体上比不基于文章主题的聚类效果稍好。
4 结论
本文采用了将k
-means聚类算法应用在校园新闻聚类上,并根据校园综合新闻的词频展现词云,将词云作为聚类数k
值的参考。提取每篇文章的前3个关键词作为文章主题进行聚类,一方面降低了整体聚类数据的维度,另一方面,实验表明本方法得到的聚类结果的DBI值比不基于文章主题得到的聚类DBI小,效果更好。同时,从实验中可以看出,k
-means算法将11 456条校园综合新闻数据大都聚为了同一类,其中一类文本数量比较多,其他类别的文本数量比较少。将校园综合新闻的类别大致可分为7类,分别为:毕业就业类、交流会议类、思想政治类、教育教学类、比赛活动类、学习培训类和培养管理类。