
基于神经网络的车辆识别代号识别方法
2021-02-26 12:44孟凡俊
光电工程 2021年1期
孟凡俊,尹 东*
基于神经网络的车辆识别代号识别方法
孟凡俊1,2,尹 东1,2*
1中国科学技术大学信息科学技术学院,安徽 合肥 230027;2中国科学院电磁空间信息重点实验室,安徽 合肥 230027
在车辆识别和车辆年检时,正确识别车架上金属刻印的车辆识别代号(VIN)是非常重要的环节。针对VIN序列,本文提出了一种基于神经网络的旋转VIN图片识别方法,它由VIN检测和VIN识别两部分组成。首先,在EAST算法基础上利用轻量级神经网络提取特征,并结合文本分割实现快速、准确的VIN检测;其次,将VIN识别任务作为一个序列分类问题,提出了一种新的识别VIN方法,即通过位置相关的序列分类器,预测出最终的车辆识别代号。为了验证本文的识别方法,引入了一个VIN数据集,其中包含用于检测的原始旋转VIN图像和用于识别的水平VIN图像。实验结果表明,本文方法能有效地识别车架VIN 图片,同时达到了实时性。
车辆识别代号;神经网络;文本分割;机器视觉

1 引 言
车辆识别代号,也叫车架号,是汽车厂商为了识别一辆车而给车指定的一组号码。由于车架上金属刻印的车架号具有全球唯一性,同时不易篡改,因此在车辆年检和车辆身份识别中具有重要的意义。
近年来,图像文本识别取得了突飞猛进的发展,许多公司已经开发了用于文档文本图像的光学字符识别(OCR)[1-2]系统。这些OCR技术多应用于扫描图像识别,而且有很高的正确率,但是这种文本检测和识别方法只适用于限定的扫描图像识别的场景,这种场景下图像背景单一,文字黑色,纸张白色,而且文字几乎水平排列,同时文字前景和背景有很明显的区分度,给文字检测和识别带来很大的便利性,但是OCR系统识别速度慢,难以满足实时性处理任务的需要。本文研究的车辆识别代号图像如图1所示,显然车架上的车辆识别代号图像的背景更为复杂多样,文字序列方向不固定,为任意方向角度,而且字体大小、颜色、对比度都有很大变化,跟普通的印刷体文本差距很大。VIN图片的文字部分跟背景的颜色难以区分,不像普通的文本有很高的辨识度,使得文字的定位变得很复杂,普通的OCR技术难以检测和识别这种字体。
随着深度学习的兴起,基于神经网络的文字识别方法也层出不穷。神经网络已经应用到了图像中的很多领域,例如图像分类、目标检测、目标跟踪等。本文基于神经网络,提出了一种复杂场景下的车辆识别代号的图像识别方法。首先利用轻量级神经网络提取特征,结合像素级的文本分割实现了快速而准确的VIN检测,快速定位任意角度任意背景下的VIN文字,满足实时性的需要。其次,在检测的基础上,面对复杂背景,结合序列分类器实现对VIN文字的识别,不仅速度快而且准确度高。最后,采用的是基于深度学习的方法,这种方法依赖于大量的训练数据集,虽然关于文字识别的数据集很多,但是由于这些数据集跟我们的VIN图片存在巨大的特征分布差异,因此也手动采集了一个新的VIN数据集用于训练神经网络。
2 文字识别相关理论
文本的识别通常分为文本检测和文本识别两个步骤。文本检测的目的是在有边框或多边形的图像中定位单词或文本行,而文本识别则是在定位后从规则裁剪的文本区域中识别出文字。过去许多年出现了很多优秀的文本检测和识别的方法,在文本识别的精度和速度上有了很大的提升。同时随着深度学习的兴起,很多基于神经网络的文字识别算法涌现出来。
2.1 卷积神经网络
随着深度学习的快速发展,卷积神经网络在图像分类、目标检测、图像分割、跟踪以及人体姿态估计等计算机视觉任务中变得越来越重要。在所有这些领域中,深度卷积神经网络是从大量的图像中自动学习深度特征,这跟之前的很多方法有很大的区别。为了正确地分类图像,VGGNet[3]用来加深卷积神经网络的深度,在目标检测和图像分类方面取得了较好的性能。当网络越深入,网络越难训练,越难收敛,ResNet[4]采用残差块连接不同层次的神经网络进行深度学习,进一步提高了神经网络性能。

图1 复杂背景以及任意角度方向的车辆识别代号图片
2.2 文字检测
传统的文本检测方法主要是两种:基于连通域分析的方法和基于滑动检测窗的方法。这些方法首先获得文本候选区域,然后采用手工设计的特征对候选区域分析,提取文本定位。其中,基于连通域的方法,例如MSER[5-7]、SWT[8]等采用自底向上的方法,从边缘以及像素的角度出发,最后连接在一起。在论文[9]中对图像使用直方图均衡化和二值化处理结合,连通域分析找出字符区域。而基于滑动检测窗[10-11]的方法自顶向下利用滑动检测窗的方式对整幅图像进行扫描,获得候选区域。
由于手工设计特征的分类能力不足,随着深度学习的兴起,近些年出现了很多基于神经网络的文本检测方法,这些方法通过神经网络学习和深度特征,从而快速而有效地检测图像中的文本。基于深度学习的文本检测方法主要包括基于区域建议的方法和基于分割的方法。基于区域建议方法一般遵循目标检测的框架,例如CTPN[12]的方法在Faster RCNN[13]基础上采用了竖直的小的锚点框去预测连续的文本区域,最后连接在一起;TextBoxes[14]采用修改SSD[15]目标检测框架中锚点框的大小和长宽比,同时修改了卷积核的大小来检测水平文本,取得了不错的效果;TextBoxes++[16]进一步扩展了文本框的文本检测性能,实现了对旋转文本的检测;SegLink[17]基于SSD检测框架,同时预测文本片段和文本连接关系,并在网络中加入角度信息,对任意角度的文本进行检测;RRPN[18]在Faster RCNN基础上添加了旋转角度的锚点框,以解决检测任意角度文本的问题。同样,近年来也出现了许多基于图像分割的文本检测方法,图像分割试图在像素级基础上对每一个像素分配一个标签以实现分割不同区域。EAST[19]将FCN[20]网络方法与像素分割相结合,直接预测文本的边界;PixelLink[21]采用了一种新的文本检测方法,它可以预测像素是否属于文本,以及文本像素之间的连接,将同一实例中的像素连接起来,分离不同的文本实例,然后直接从分割结果中提取文本框。
2.3 文字识别
以前的很多文字识别方法首先检测文本行中的每个字符,然后将每个字符单独分割,最后通过自下而上的拼装方法将字符组合成一个单词或句子。近些年来,随着深度学习的兴起,逐渐将文本识别看作一个序列化识别的问题。CRNN[22]将文本识别作为一个序列识别问题,首先利用深度卷积神经网络提取文本特征,然后学习文本的空间上下文信息,最后利用CTC层[23]对文本序列进行解码;论文[24]提出了一种基于注意力机制的序列到序列框架来识别文本。通过这种方式,神经网络能够从训练数据中学习隐藏在字串中的字符级语言模型。
3 本文方法
本文提出了一种基于神经网络的旋转VIN图片识别方法。整体框架如图2所示。
3.1 VIN图片文字检测
受到之前发布的目标检测和文本检测论文方法的启发,本文在EAST的算法上采用MobileNet[25]作为基础网络,这是一种轻量级的网络,使得在性能损失很少的情况下推理速度加快,模型参数更少,能满足识别任务的实时性要求。为了检测不同大小和比例的VIN图片,采用与特征金字塔网络(FPN)[26]相似的方法,将低级特征图和高级语义特征图连接起来。FPN是一种能够提取多尺度特征图进行融合的特征提取网络,从而提高了检测性能。同时,本文通过将由下而上的网络横向连接来学习一个金字塔型强语义特征,如图3所示。
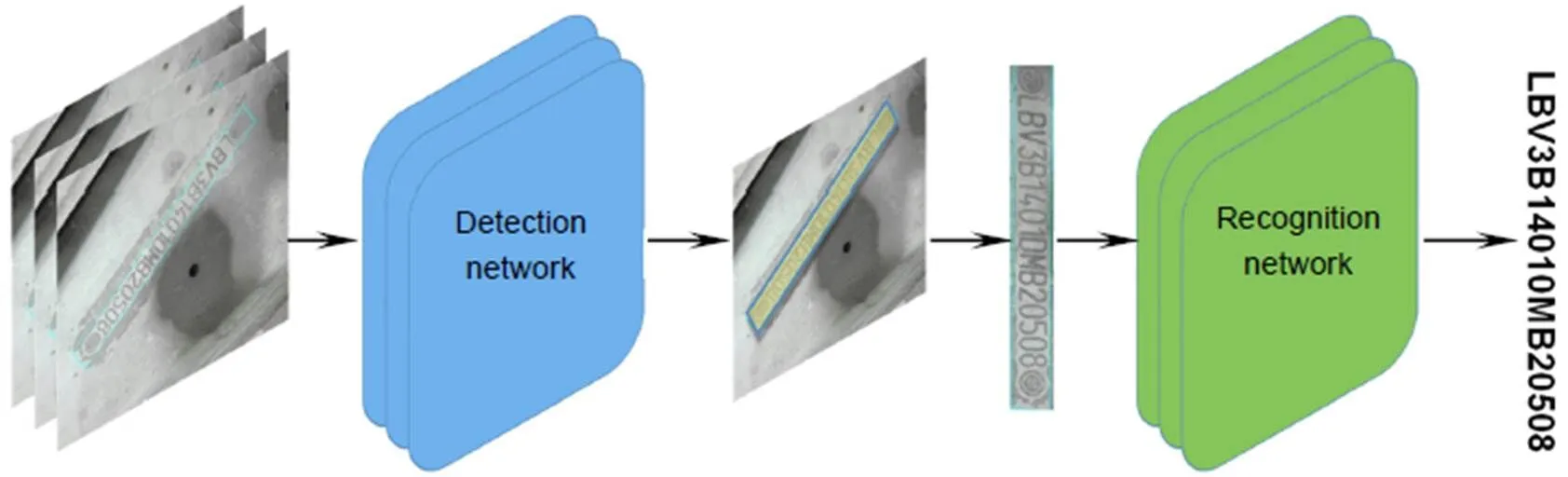
图2 基于神经网络的VIN识别框架
为了实现更精细化的文字区域预测,在卷积神经网络抽取输入图片特征之后,全卷积网络FCN在最后一层卷积层上实现像素级的预测。全卷积网络是一种用于图像语义分割的网络,这种网络实现像素级的目标分割,同时不受图片输入大小的限制。
文字检测可以作为一个二元分类问题。在最终的预测结果中,如图4所示,输出层的一个通道1输出预测的像素在文本区域内的概率,同时设置一个阈值来滤除可能位于背景区域内的概率较低的像素。对于预测在文本区域内的每个像素,有4个通道2,3,4,5输出预测的该像素到文本段四条边的距离。最后,还有一个通道6输出预测的倾斜文本区域内的方向。
VIN检测模型损失函数包括VIN文本分类损失和VIN边界计算损失。由于VIN文本与背景像素分布不平衡,背景像素远远大于文本像素,故采用dice[27]系数来计算VIN文本分类损失,dice系数公式为
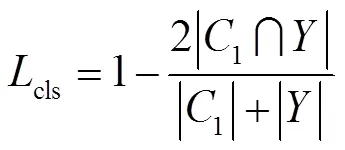
其中:通道1为预测的像素在文本区域内的概率,为训练时图片中VIN文本区域的真实标签。
VIN检测模型边界损失函数包括倾斜角度损失和边界框回归损失,如式(2)~式(4)所示:
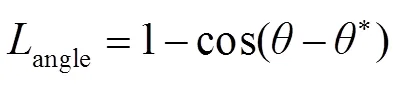

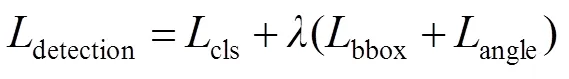
3.2 VIN图片文字识别
考虑到文本在图像中的任意方向,首先检测图像中的文本,然后将文本旋转到水平位置后将文本区域裁剪出来,进行下一步的识别。
受到CRNN的启发,本文采用了一种新的VIN识别方法,即把VIN的识别当作序列相关的分类,同时直接忽略不想识别的其他边缘字符,例如有的VIN图片中含“*”等不相关字符,如图5(a)所示。由于VIN的固定长度为17位字符,在输出端设置17个分类器,输入网络的图像的大小固定为400×40,提取特征后得到输入大小的1/16的特征图。图5(b)展示了用于VIN特征提取的主干网络结构VGGNet,3×3卷积核用于提取图片特征,Maxpool层是一个特征池化层,主要目的是2倍下采样,本文中网络在下采样时采用向下取整。接下来,计算VIN识别网络的损失函数如式(5)、式(6)所示:

图3 VIN检测网络基本框架

图4 VIN 检测网络中的后处理以及输出


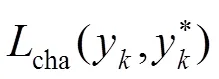
3.3 数据增强
在训练VIN检测网络时,对训练图片以任意方向旋转以提升检测多角度图片的效果,如图6所示,同时旋转原图片和四边形文本框标签。
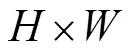
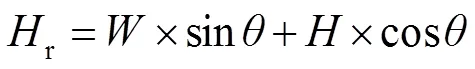
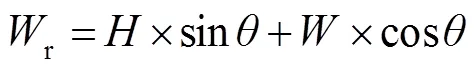
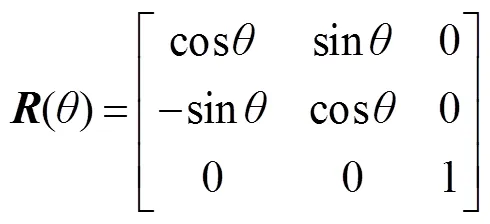

图5 VIN 识别算法网络。(a) 网络整体框架;(b) VGGNet内部结构

图6 任意方向旋转图片和文本框标签
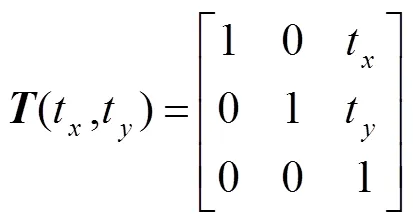
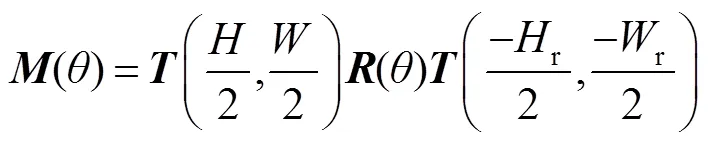
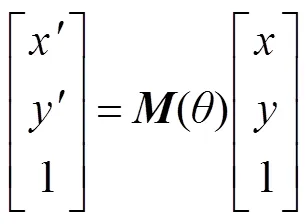
在识别阶段,检测定位旋转到水平之后,有些文字可能方向是反的,也就是旋转了180°,为了识别旋转了180°的图片,在训练识别网络的时候以50%的概率随机旋转图片180°。
4 实验结果与数据分析
本文提出了针对复杂环境下旋转VIN 图片的识别算法,在基于Ubuntu 16.04系统GPU(Titan Xp显卡)服务器的环境上开展了训练和测试实验。实验所需的编程语言为python3.6版本,深度学习环境为pytorch0.4版本,CPU型号为Intel Silver 4110 2.1 GHz。
4.1 数据集

4.2 实验结果与数据分析
在VIN检测阶段,用旋转VIN数据集进行实验,使用1000张图片用于训练,1000张用于测试。在模型训练中,使用Adam作为优化器,并将训练图片裁剪为(512´512)的大小。此外,在训练时随机以任意角度无损旋转图片。实验结果如表1所示,本文所提出的检测方法在速度和精度上均优于其它方法,精度可达98%。

图7 VIN训练数据集

表1 在VIN数据集上不同方法的检测效果
在VIN识别阶段,以80000张图片用于训练、10000张用于测试。识别结果如表2所示,本文提出的VIN识别算法在两个精度指标上比其他算法具有更好的识别效果,达到了122 f/s的识别速度和93%相似度匹配的识别精度。这里测试图片大小统一为320´32,‘F’代表全字符匹配的准确率,‘A’代表字符相似匹配的准确率。
此外,值得注意的是,输入图片的不同大小在VIN识别中的实验效果是不同的。如表3所示,图像越大,实验性能越好。同时,针对数据增强,也做了对比实验。实验结果表明,对于图片中文字方向反的情况,数据增强可以有效解决这一问题。表中‘aug’表示我们在训练识别网络时添加了图片180°旋转。
作为补充,图8展示了本文方法在实际复杂环境下的VIN图片的识别效果。图9展示了在测试中检测失败以及识别率低于0.7的图片。经过多张图片的分析,发现图片中的长条格状物体容易被错误识别为VIN文字序列,实际上只是类似于文字。而且在文字和背景没有明显区分的时候很容易造成检测不到文字的存在。在识别方面,显然模糊刻印的文字以及不明显的字体是造成识别率低的原因。

表2 在VIN数据集上不同方法的识别效果

表3 在不同尺寸输入图片大小上的识别效果

图8 实际复杂环境下VIN图片识别效果

图9 实际复杂环境下检测和识别效果不好的图片
5 结 论
本文提出了在复杂环境下识别旋转型VIN图片的有效方法,并且创建了一个新的VIN数据集来评估我们的方法。结合轻量级卷积神经网络和输出层的逐像素分割实现了VIN检测。同时,提出了用于VIN识别的序列分类器。实验结果表明,本文所提出的方法能有效地检测和识别图片中刻印的VIN字符。目前,本文方法已经应用在中国的城市车辆年检系统中。
[1] Smith R. An overview of the Tesseract OCR engine[C]//, 2007: 629–633.
[2] Mori S, Suen C Y, Yamamoto K. Historical review of OCR research and development[J].1992, 80(7): 1029–1058.
[3] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[Z].arXiv:1409.1556, 2014.
[4] He K M, Zhang X Y, Ren S Q,. Deep residual learning for image recognition[C]//2016: 770–778.
[5] Tang Y B, Bu W, Wu X Q. Natural scene text detection based on multi-level MSER[J].2016, 50(6): 1134–1140.
唐有宝, 卜巍, 邬向前. 多层次MSER自然场景文本检测[J]. 浙江大学学报(工学版), 2016, 50(6): 1134–1140.
[6] Jiang H Y, Zhu L P, Ou Z P. Text recognition of natural scene image based on MSER and Tesseract[J]., 2017, 13(33): 213–216.
蒋弘毅, 朱丽平, 欧樟鹏. 基于MSER和Tesseract的自然场景图像文字识别[J]. 电脑知识与技术, 2017, 13(33): 213–216.
[7] Zhang K Y, Shao K Y, Lu D. MSER fast skewed scene-text location algorithm[J].2019, 24(2): 81–88.
张开玉, 邵康一, 卢迪. MSER快速自然场景倾斜文本定位算法[J]. 哈尔滨理工大学学报, 2019, 24(2): 81–88.
[8] Zhang G H, Huang K, Zhang B,. A natural scene text extraction method based on the maximum stable extremal region and stroke width transform[J]., 2017, 51(1): 135–140.
张国和, 黄凯, 张斌, 等. 最大稳定极值区域与笔画宽度变换的自然场景文本提取方法[J]. 西安交通大学学报, 2017, 51(1): 135–140.
[9] Nan Y, Bai R L, Li X. Application of convolutional neural network in printed code characters recognition[J]., 2015, 42(4): 38–43.
南阳, 白瑞林, 李新. 卷积神经网络在喷码字符识别中的应用[J]. 光电工程, 2015, 42(4): 38–43.
[10] Wang K, Belongie S. Word spotting in the wild[C]//, 2010, 6311: 591–604.
[11] Wang K, Babenko B, Belongie S. End-to-end scene text recognition[C]//, 2011: 1457–1464.
[12] Tian Z, Huang W L, He T,. Detecting text in natural image with connectionist text proposal network[C]//, 2016, 9912: 56–72.
[13] Ren S Q, He K M, Girshick R,. Faster R-CNN: towards real-time object detection with region proposal networks[C]//, 2015: 91–99.
[14] Liao M H, Shi B G, Bai X,. TextBoxes: a fast text detector with a single deep neural network[Z]. arXiv:1611.06779, 2016.
[15] Liu W, Anguelov D, Erhan D,. SSD: single shot multibox detector[C]//, 2016: 21–37.
[16] Tian Z, Huang W L, He T,. Detecting text in natural image with connectionist text proposal network[C]//, 2016, 9912: 56–72.
[17] Liao M H, Shi B G, Bai X. TextBoxes++: a single-shot oriented scene text detector[J]., 2018, 27(8): 3676–3690.
[18] Ma J Q, Shao W Y, Ye H,. Arbitrary-oriented scene text detection via rotation proposals[J]., 2018, 20(11): 3111–3122.
[19] Zhou X Y, Yao C, Wen H,. EAST: an efficient and accurate scene text detector[C]//, 2017: 2642–2651.
[20] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//, 2015: 3431–3440.
[21] Deng D, Liu H, Li X,. PixelLink: detecting scene text via instance segmentation[Z]. arXiv:1801.01315, 2018.
[22] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]., 2017, 39(11): 2298–2304.
[23] Graves A, Fernández S, Gomez F,. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//, 2006: 369–376.
[24] Lee C Y, Osindero S. Recursive recurrent nets with attention modeling for OCR in the wild[C]//, 2016: 2231–2239.
[25] Sandler M, Howard A, Zhu M L,. MobileNetV2: inverted residuals and linear bottlenecks[C]//, 2018: 4510–4520.
[26] Lin T Y, Dollár P, Girshick R,. Feature pyramid networks for object detection[C]//, 2017: 936–944.
[27] Milletari F, Navab N, Ahmadi S A. V-Net: fully convolutional neural networks for volumetric medical image segmentation[C]//, 2016: 565–571.
[28] Li X, Wang W H, Hou W B,. Shape robust text detection with progressive scale expansion network[Z]. arXiv:1806.02559, 2018.
[29] Liu X B, Liang D, Yan S,. FOTS: fast oriented text spotting with a unified network[C]//, 2018: 5676–5685.
[30] Thakare S, Kamble A, Thengne V,. Document Segmentation and Language Translation Using Tesseract-OCR[C]//. IEEE, 2018.
[31] Shi B G, Yang M K, Wang X G,. ASTER: an attentional scene text recognizer with flexible rectification[J]., 2019, 41(9): 2035–2048.
Vehicle identification number recognition based on neural network
Meng Fanjun1,2, Yin Dong1,2*
1School of Information Science Technology, University of Science and Technology of China, Hefei, Anhui 230027, China;2Key Laboratory of Electromagnetic Space Information, Chinese Academy of Sciences, Hefei, Anhui 230027, China
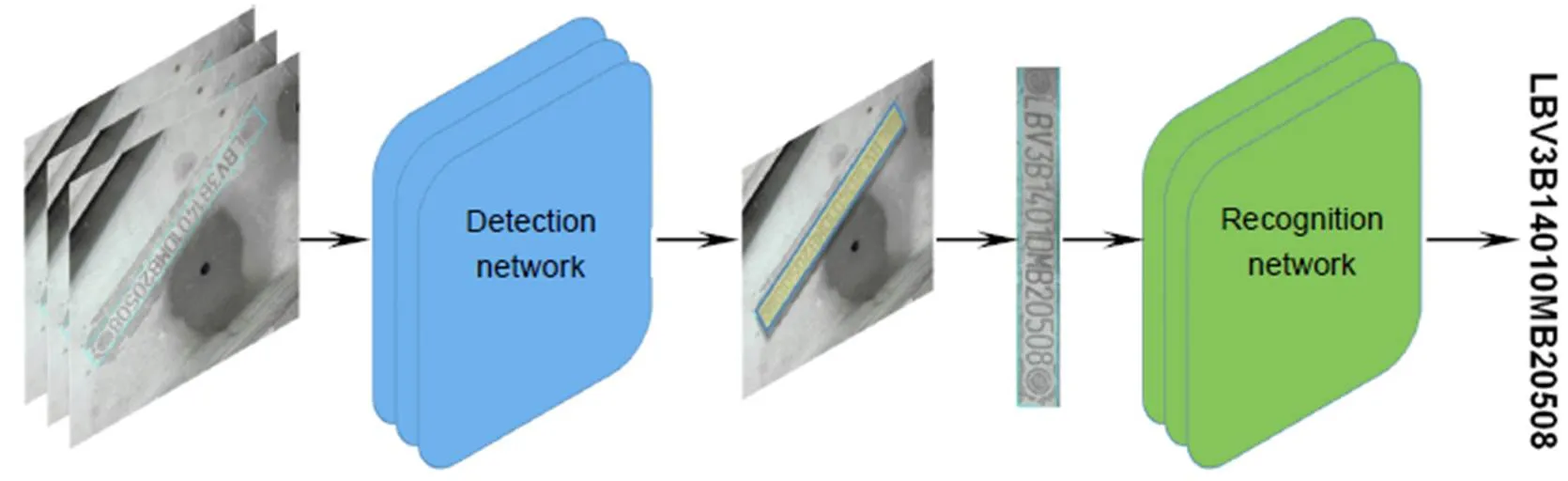
The overall architecture of our proposed VIN recognition algorithm
Overview:It is far essential to properly recognize the vehicle identification number (VIN) engraved on the car frame for car surveillance and vehicle identification. Vehicle identification number is unique globally, which is assigned by car manufacturers to a car for identifying it. The vehicle identification number is usually engraved on the metallic car frame which is uneasy to tamper with, so it is of great significance for vehicle annual surveillance and vehicle identification. Although many important achievements have been made in text recognition, especially the wide application of OCR in document recognition in images, the complex background, arbitrary angle and fuzzy font of the engraved text in the images have made it difficult to identify the vehicle identification number automatically. In vehicle identification and annual car inspection, a large number of VIN pictures need to be manually reviewed every day, which is very inefficient. With the application of deep learning, we can make use of deep learning to accelerate this process, improve the efficiency of auditing greatly, and realize automated auditing. We introduce an algorithm for recognizing vehicle identification number in images based on neural network, which incorporates two components: VIN detection and VIN recognition. Firstly, in the VIN detection part, the lightweight Network is used as feature extraction network in order to accelerate the inference speed and reduce the network cost. Combined with FCN and FPN, the network is able to adapt to any size of input images and focus on the distribution difference between foreground text pixels and background pixels. In order to improve the performance on rotational VIN, the images are rotated at any angle lossless in the training stage to augment datasets. Secondly, in the VIN recognition stage, we take VIN recognition task as a sequence classification problem, using VGGNet as the feature extraction network, and the final vehicle identification number sequence is predicted through the position-related sequential classifier without character segmentation to simplify the recognition processing. Also, the text direction in images may be reversed in dataset, and in order to solve the situation, picture is rotated at 180 degrees randomly in network training. Finally, we introduce a VIN dataset, which contains raw rotational VIN images and horizontal VIN images for validating our algorithm, and all of our experiments are conducted on the dataset. Experimental results show that the algorithm we proposed can detect and recognize the VIN text in images efficiently in real time.
Meng F J, Yin DVehicle identification number recognition based on neural network[J]., 2021, 48(1): 200094; DOI:10.12086/oee.2021.200094
Vehicle identification number recognition based on neural network
Meng Fanjun1,2, Yin Dong1,2*
1School of Information Science Technology, University of Science and Technology of China, Hefei, Anhui 230027, China;2Key Laboratory of Electromagnetic Space Information, Chinese Academy of Sciences, Hefei, Anhui 230027, China
It is far essential to properly recognize the vehicle identification number (VIN) engraved on the car frame for vehicle surveillance and identification. In this paper, we propose an algorithm for recognizing rotational VIN images based on neural network which incorporates two components: VIN detection and VIN recognition. Firstly, with lightweight neural network and text segmentation based on EAST, we attain efficient and excellent VIN detection performance. Secondly, the VIN recognition is regarded as a sequence classification problem. By means of connecting sequential classifiers, we predict VIN characters directly and precisely. For validating our algorithm, we collect a VIN dataset, which contains raw rotational VIN images and horizontal VIN images. Experimental results show that the algorithm we proposed achieves good performance on VIN detection and VIN recognition in real time.
vehicle identification number; neural network; text segmentation; machine vision
TP391.41
A
10.12086/oee.2021.200094
Key Research and Development Projects of Anhui Province (804a09020049)
* E-mail: yindong@ustc.edu.cn
孟凡俊,尹东. 基于神经网络的车辆识别代号识别方法[J]. 光电工程,2021,48(1): 200094
Meng F J, Yin DVehicle identification number recognition based on neural network[J].2021, 48(1): 200094
2020-03-20;
2020-06-28
安徽省2018年度重点研究与开发计划项目(1804a09020049)
孟凡俊(1994-),男,硕士研究生,主要从事图像处理的研究。E-mail:fanjunm@mail.ustc.edu.cn
尹东(1965-),男,副教授,主要从事图像处理的研究。E-mail:yindong@ustc.edu.cn
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2021年9期)2021-09-22
小雪花·小学生快乐作文(2020年6期)2020-10-13
文苑(2020年12期)2020-04-13
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
