
基于改进YOLOv3的站口行人检测方法
2021-02-26 03:54:34康庄杨杰李桂兰南柄飞曾璐
铁道科学与工程学报 2021年1期
康庄,杨杰,李桂兰,南柄飞,曾璐
基于改进YOLOv3的站口行人检测方法
康庄1,杨杰1,李桂兰1,南柄飞2,曾璐1
(1. 江西理工大学 电气工程与自动化学院,江西 赣州 341000;2. 中国煤炭科工集团 北京天地玛珂电液控制系统有限公司,北京 100013)
针对YOLOv3算法在行人检测上准确率低和漏检率高的问题,提出一种改进型YOLOv3的行人检测方法,并将其定义为GA-Wide-YOLOv3。该方法首先以行人头肩小目标为检测对象,进行重构数据集,利用遗传算法重新对目标先验框进行聚类,优化anchor参数,提高先验框与数据集的重合程度;其次改进YOLOv3,通过加宽网络宽度、减少网络深度,获得针对小目标检测的较大视野阈,避免梯度消失;最后,将多尺度检测算法3个yolo层前的1*1,3*3的卷积组各去掉2组,减少头肩小目标在复杂背景下的漏检率。在收集的数据集HS6936上进行对比实验,结果表明,基于遗传算法改进的K-means算法,平均交并比为81.89%,提高了0.8%;改进的YOLOv3算法检测平均准确率(mAP)为75.35%,召回率为81.20%,查准率为99.99%,较原始YOLOv3算法分别提高了2.53%,0.88%和2.75%。
行人检测;深度学习;YOLOv3;遗传算法;计算机视觉
行人检测作为辅助驾驶系统、车辆监控系统和预警防护系统的基本任务之一,在多种领域扮演着重要角色。尤其在地铁及火车站口等人群密集的环境中,行人检测技术与客流统计、客流疏导和安全预警工作息息相关,在站口安全和数据处理方面发挥着重要作用。随着深度学习和大数据的蓬勃发展,基于深度学习研究行人检测已经成为一种新兴的方案,对于提高站口客流安全具有重要意义。针对行人检测问题,国内外学者已经开展了相关研究,且已经取得了一定的效果。目前基于传统方法的行人检测方法可分为几类:背景差分法、帧间差分法、模板匹配法和光流行人识别技术,存在检测实时性差、抗干扰能力弱等缺陷。曾接贤等[1]针对行人遮挡问题进行了研究,通过SDP-DPM和SP- DPM模型将行人分为单独、混合分布2种类别进行检测,能精确识别日常交通环境的行人,抗环境干扰能力较传统方法有所提升。龚露鸣等[2]提出了一种基于混合高斯背景建模结合方向梯度直方图和SVM的行人检测模型,通过前景分割、特征降维和信息更新等步骤将误检率降到4%,在复杂场景中有很好的实时性和精确度。程德强等[3]提出了一种基于CLBC和HOG特征融合的行人检测算法,在Caltech行人数据库和INRIA行人数据库中表现出比传统方法更高的精度和更强的环境抗干扰能力。胡亚洲等[4]针对高点监控应用场景,提出了基于背景建模和帧间差分法相结合的高点行人检测方法,提高了检测精度,降低了误检率。上述文献在检测精度、误检率和环境干扰等做了很多努力,且在效果上有一定的提高,但对不同运动状态的行人将产生较大差异的检测效果。基于深度学习的行人检测技术在静止和运动的行人上都有较好的检测效果,因此本文将其作为研究方向。随着目标检测技术的发展,各种技术日新月异,目前使用的代表性目标检测算法主要分为2类,一类是以R-CNN,Fast RCNN[5],Faster RCNN[6],MR-CNN,HyperNet和Mask R-CNN为代表的基于候选区的两阶段的目标检测算法,另一类是以SSD,G-CNN,RON和YOLO为代表的基于回归的一阶段目标检测算法。前者目标检测精度高,但检测速度低,实时性方面受限;后者在目标检测上实时性好,检测速度快[7]。本文为地铁、火车站口的行人检测,人群流动量大,对实时性和速度要求很高,基于此考虑,选用一阶段的目标检测算法进行研究,在原有优势上提高精度。近年来,用目标检测算法进行行人检测的研究取得了一系列突破性成果[8−11]。盛智勇等[12]针对地铁监控场景提出了一种端到端的头肩检测方案,基于Faster RCNN模型训练分类器,精度较传统算法提高0.44%,在不同的场景和视角具有较好的检测效果,但实时性较差,且误检率高。YANG等[13]提出了一种基于分层卷积的行人检测算法,实时检测速度高达20 fps,行人漏检率降低11.88%,提高了不同规模的行人检测召回率,但在镜头角度的把握和环境干扰方面仍需改进,且对小物体的漏检率较高。Heo等[14]通过将YOLO与ABMS构建的显着性特征图结合,使用夜间拍摄的热图像进行实时行人检测,针对光线环境干扰情况提出方法,能有效避免夜间行人车辆的撞车事故,但难以识别小物体,且误识别率较高。HAN等[15]提出了一种集成激光雷达和彩色摄像机的探测融合系统,通过改进YOLO算法,提高了检测精度,且有效减少了漏检率。但交通场景的覆盖范围相对较窄,受光的影响很大,且对小物体检测效果较差。KUANG等[16]通过扩展原始的YOLOv3结构和新定义损失函数,有效提高了行人检测的性能,进一步减少了小目标的漏检率,它们虽然在小物体的漏检率和检测速度方面有很大程度的提高,但是存在一定的问题,改进后的网络结构层数过多,容易造成特征消失或致使内存过大而无法进行有效的训练。本文提出了一种改进型YOLOv3网络结构(GA-Wide-YOLOv3)的行人检测方法。首先利用遗传算法对K-means算法进行改进,减少随机初始值对算法造成的影响,优化anchor参数,提高先验框与数据集的重合程度;其次将Darknet-53特征提取网络进行更改,通过加宽宽度的方法减少网络的深度,获得针对小目标检测的较大视野阈,避免梯度消失;最后对YOLOv3的卷积组进行结构修改,减少头肩小目标在复杂背景下的漏检率,以此提高网络对小目标的检测率。
1 YOLOv3算法
1.1 YOLOv3网络结构
YOLOv3算法的网络结构可分为Darknet-53和yolo层2个部分,Darknet-53网络用于特征提取,yolo层用于多尺度预测, Darknet-53通过5次下采样实现由大小为416*416*3的输入得到13*13*1024的输出,能在保证实时性(fps>36)的基础上追求性能。yolo层得到Darknet-53输出的特征图后,通过concat机制扩充张量维度,实现上采样与浅层特征图的相连,从而输出13*13,26*26和52*52 3种尺寸大小的特征图,通过这种多尺度的方法,可以更好地对小物体进行检测。其整体网络结构图见图3(a)所示。
1.2 YOLOv3锚点框计算
YOLOv3算法首先将输入的图像全部缩放到416*416的尺度进行训练,然后统一划分为×的网格,在每个网格中预测出边界框,以进行目标检测,每次预测输出每类目标的边界框位置、类别,且分别计算每个边界框的置信度(即重叠面积)。若物体的中心点落在某个网格上,这个网格就负责预测该物体,并且在该物体上生成3个锚点框,如图1所示。
每个网格借助3个锚点框,通过维度聚类,将设为9,逻辑回归后预测出3个边界框。负责预测每个物体的网格都需要预测5个值,分别为自身位置和该物体的概率值。其中自身位置需要4个值来确定,包括预测框的中心点坐标和预测框的宽与高,分别记做t,t,t,t,其中后2项与值有关。若中心目标在单元格中相对图像左上角偏移(c,c),锚点框的高度和宽度记做p和p,则修正后的边界框具体计算公式见式(1)。具体示意图如图2所示。
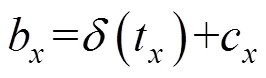
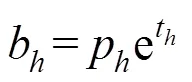

图2 边界框相对位置示意图
1.3 YOLOv3损失函数计算
YOLOv3训练损失函数主要包括3个方面的损失,分别为预测框、置信度和类别的损失,其损失函数计算式见式(2)。
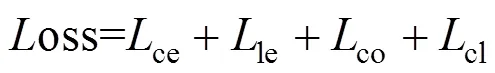
其中:ce和le表示预测框损失部分,分别为预测框的中心点坐标损失与预测框的宽高损失,其详细公式如式(3):


co为置信度损失,包括有目标和无目标2种情况。其详细公式为(4):
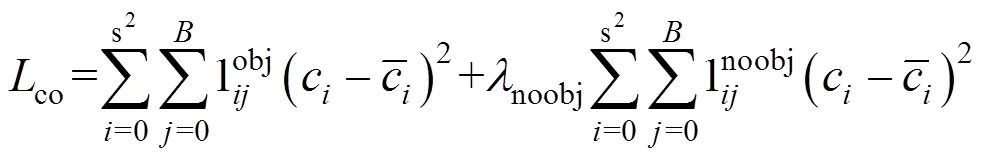
式中:第1项为有目标的预测置信度损失,回归目标为预测框与真实框的IOU值。第2项为无目标的预测置信度损失,noobj为其惩罚系数。
cl为类别损失,其详细公式为(5):
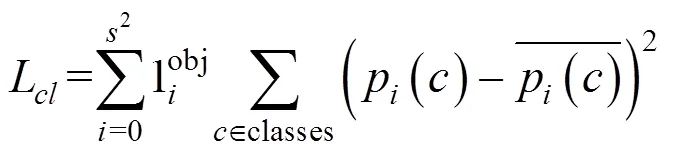
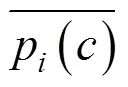
2 YOLOv3网络算法改进
2.1 YOLOv3特征提取网络与多尺度检测算法改进
YOLOv3特征提取网络采用Darknet-53结构,同时利用多尺度检测的思想,提高对小目标的检测精度。Darknet-53共有23个残差块,共52层卷积层,1个全连接层,其凭借Resnet使得网络不断加深来提高准确率,但是过深的网络导致冗余参数、梯度消失、感受野小等问题,为了解决这一问题,SHI等[17]在2019年通过加宽网络模型,代替了原来的深度网络,从而提升模型的性能,在图像超分辨率上取得了优秀的性能。
本文针对地铁及火车站口的行人检测,检测对象为头肩,都为小目标,随着网络的深入,视野阈变小,不利于小目标的检测。在特征提取网络方面,基于Wide Residual Networks提出了Wide-Darknet- 33新型特征提取网络,该网络共有13个残差块,32层卷积层,1个全连接层,通过减少Darknet-53的卷积层来减少深度,同时加宽网络,使得在宽度上特征提取更加准确,本文采取的加深宽度做法为通过增加输出通道数的数量来使模型变得更wider,为了减少过多的冗余参数,Wide-Darknet-33中的K取2,将输出通道数扩大一倍;在多尺度检测方面,为了减少头肩小目标在复杂背景下的漏检率,本文将YOLOv3多尺度检测算法3个yolo层前的1*1和3*3的卷积组各去掉2组,以此来提高网络对小目标的检测率[18],原始的YOLOv3共106层,本文提出的改进型YOLOv3算法缩减到了64层,详细特征提取网络与多尺度算法改进结构如图3所示。
2.2 YOLOv3网络参数的优化算法改进
YOLOv3算法共有13*13,26*26和52*52 3个尺度,每个尺度最终有3个锚点框做预测,锚点框可以在预测时进行辅助检测目标边界,本文检测对象是地铁及火车站行人,由于目标遮挡严重,采用头肩检测思想,都为小目标检测,检测目标占整个检测图片的比例很小。而公共数据集上检测物体的尺寸从大到小都有分布,原始算法的锚点框无法满足本文的需求,需要重新计算,原始算法的K-means聚类对初始值的依赖大,无法聚类得到准确的锚点框值,本文采用种群仿生原理,对锚点框计算方法进行改进,本文采用基于K-means的遗传算法聚类。适应度函数中以IOU值进行聚类,本文的遗传算法具体流程框图如图4所示,其中最重要的是适应度函数的设计。本文利用GA算法进行聚类的适应度函数采用IOU距离进行约束,因为IOU值越大越好,程序里面一般处理为最小,故用1-IOU最为适应度函数,求取它最小,IOU值计算如下。
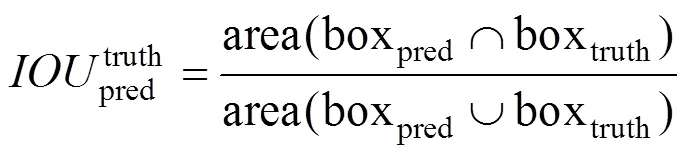
距离函数:
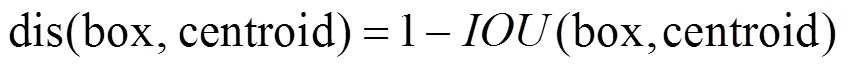
目标函数:
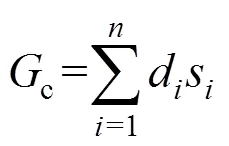
适应度函数:
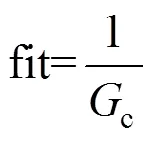

(a) YOLOv3网络结构图;(b) 改进型YOLOv3网络结构图

图4 遗传算法流程图
3 实验结果
本文搭建的实验平台:电脑配置为i5-6500 CPU,8GRAM,64位window7操作系统,服务器配置为Tesla-P100,本文在算法框架Darknet上实现。
3.1 数据准备与标签制作
本文的数据来源于实地拍摄与网络两部分,选取了6 196张不同时间、不同地点、不同光线下在火车站、地铁站等站口的行人照片,使用LableImg软件对图片中的行人头肩目标进行标注,平均每张照片中有效标注对象10个左右,总计有效检测目标为83 072个,得到VOC格式的xml文件,作为火车及地铁站口行人检测的数据集标签。
3.2 评价指标
针对站口行人检测,检测准确率很重要,本文选取平均准确率(mAP)作为评价指标,其准确率和召回率的定义如式(10)所示。
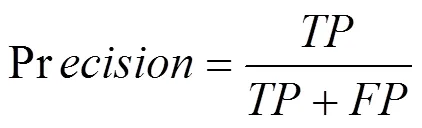

本文以站口行人检测为例,为将行人检测为行人的数量,为将背景检测为行人数量,为误把行人检测为背景的数量。同时以1作为对准确率和召回率综合衡量指标,接近1,则效果越好,以召回率为横坐标,以准确率为纵坐标,绘制-曲线,利用积分求取的值,如式(11)所示。
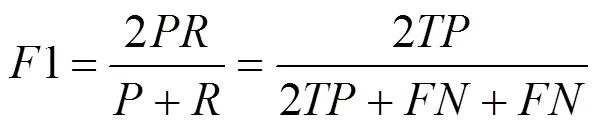
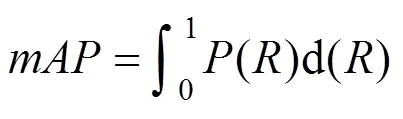
3.3 基于遗传算法改进的K-means聚类实验
本文设置合理的种群规模与进化代数,分别做计算,其聚类结果如表1。
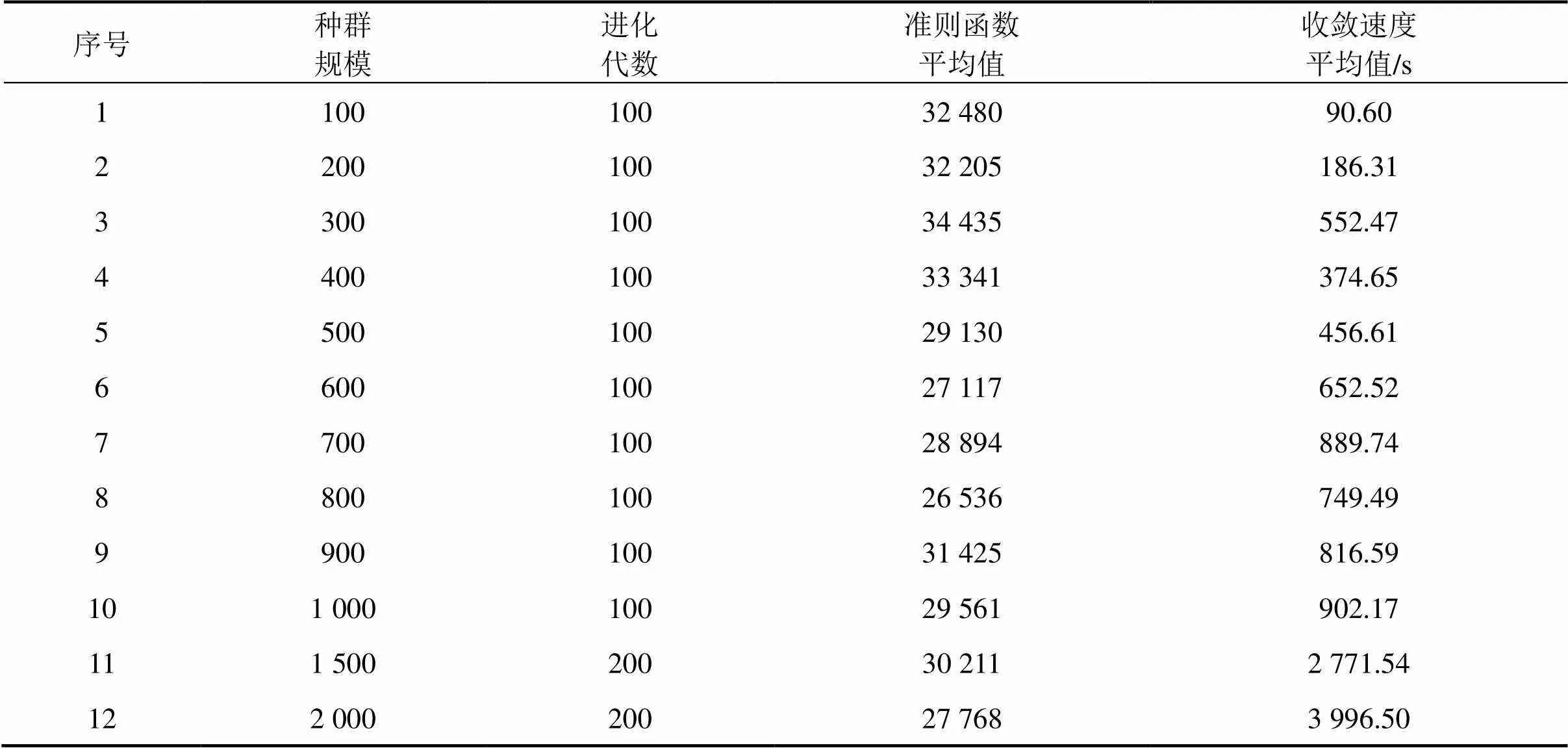
表1 遗传算法聚类表
通过表1分析,在第8个点处准则函数平均值取得最小值,故取种群规模为800,进化代数为100,其适应度曲线如图5所示, 聚类结果见图6。
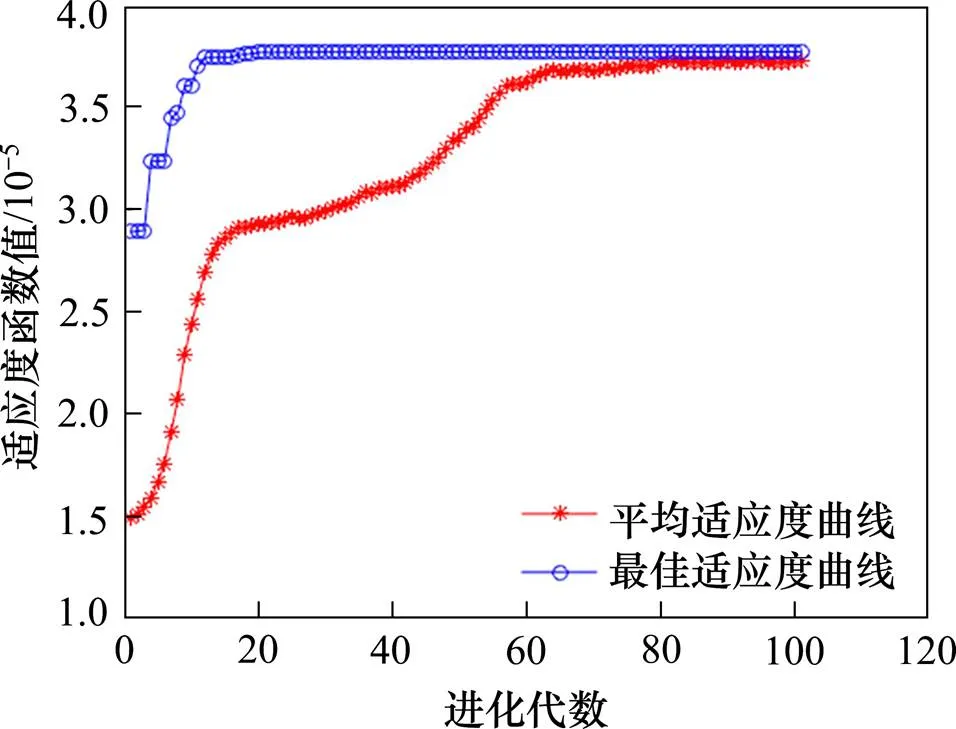
图5 Maxgen=100,sizepop=800适应度曲线
由图5~6可以看出,在种群规模为800,进化代数为100时,其平均适应度函数与最佳适应度函数收敛时重合度最高,聚类清晰准确,一共聚类为9类,效果最优。
最终的聚类结果如表2,得到基于本文HS6196数据集的最佳锚点框。
本文分别运行K-means聚类与改进的遗传算法,为了保证算法的准确性,分别将每种聚类方法聚类5次,其结果如表3,可以看出,单独每次的聚类结果GA算法都比K-means聚类算法优秀,其最终平均值也较K-means方法高出0.88的正确率。
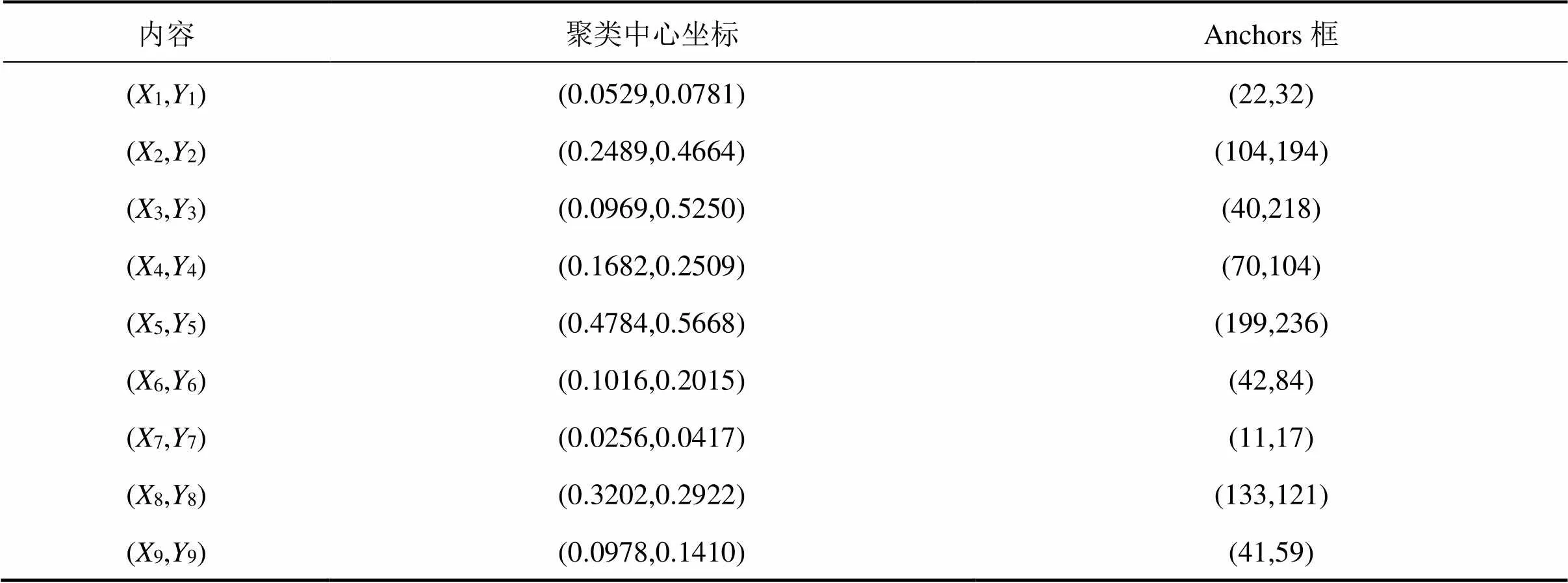
表2 遗传算法聚类锚点框

表3 K-means与GA聚类正确率对比
3.4 基于改进型YOLOv3的实验
在训练模型阶段,采用的动量为0.9,初始学习率为0.001,衰减系数为0.005。共训练50 000次,训练时将算法的损失值等各项指标保存到日志文件,训练结束后,调用保存的日志文件,绘制各项指标动态变化图,其中平均交并比变化趋势如图7所示,平均损失函数变化趋势如图8所示。

图7 平均交并比变化曲线
图8 平均损失变化曲线
由图7可见,开始平均交并比较小,随着训练次数的增加,平均交并比迅速增大,模型的检测精度随之上升,训练至50 000步时,平均交并比在0.9以上,达到训练的要求。
由图8可见,开始损失值较大,但随着训练次数的增加,损失值很快降低,逐渐收敛,训练至 50 000步时,损失值一直稳定在0.1左右,模型收敛程度达到了理想的效果,模型训练稳定。
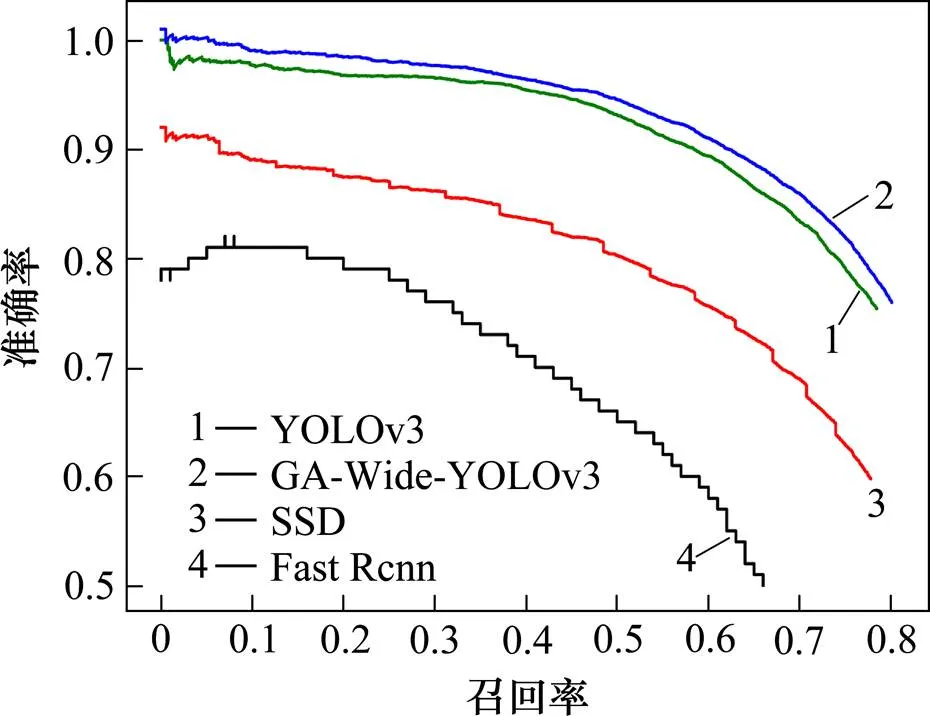
图9 各算法的PR对比图
3.5 效果对比
为了准确评价模型,将改进后的网络与Fast RCNN,SSD和YOLOv3 3种算法进行对比,分别计算各种算法的召回率与准确率,绘制训练的PR曲线,见图9,实验发现,改进后的算法在召回率与准确率均有提升,本文利用mAP作为模型准确度的评估指标,分别对比3种算法的的mAP与改进后算法的mAP,实验发现,改进后算法的mAP最高,达到了75.35%,具体数据见表4。

表4 模型检测结果
3.6 基于改进型YOLOv3的识别测试实验
调用训练完成的权重文件进行测试,同时标出检测的对象位置,如图10所示。可以看出,改进后的模型对站口的行人检测较为精准,在目标小、遮挡严重的情况下,有效地避免了漏检的问题。

图10 识别测试效果图
4 结论
1) 提出了GA-Wide-YOLOv3站口行人检测的方法,实现了该对象端到端的检测,同时,针对站口行人头肩数据集缺乏的问题,自己采集、制作了HS6196数据集。
2) 利用遗传算法对K-means算法进行改进,减少初始值对算法造成的影响,优化anchor参数,提高了先验框与数据集的重合程度。实验验证,重合程度从81.08%提高到了81.89%。
3) 优化Darknet-53网络,通过加宽宽度的方法减少网络的深度,获得针对小目标检测的较大视野阈,避免网络过深带来的特征消失。
4) 将YOLOv3多尺度检测算法3个YOLO层前的1*1,3*3的卷积组各去掉2组,减少头肩小目标在复杂背景下的漏检率。
5) 改进的网络mAP达到75.35%,准确率为99.99%,召回率为81.20%,分别较改进前提高了2.53%,0.88%和2.75%。
由于本文所提算法对遮挡严重、行人特别密集的情况检测效果仍然有所欠缺,论文下一步将侧重研究遮挡严重的行人的检测,进而提高检测精度。
[1] 曾接贤, 程潇. 结合单双行人DPM模型的交通场景行人检测[J]. 电子学报, 2016, 44(11): 2668−2675. ZENG Jiexian, CHENG Xiao. Pedestrian detection of traffic scenes combined with single and double pedestrian DPM models[J]. Chinese Journal of Electronics, 2016, 44(11): 2668−2675.
[2] 龚露鸣, 徐美华, 刘冬军, 等. 基于混合高斯和HOG+SVM的行人检测模型[J]. 上海大学学报(自然科学版), 2018, 24(3): 341−351. GONG Luming, XU Meihua, LIU Dongjun, et al. Novel model of pedestrian detection based on Gaussian mixture model and HOG+SVM[J]. Journal of Shanghai University (Natural Science Edition), 2018, 24(3): 341− 351.
[3] 程德强, 唐世轩, 冯晨晨, 等. 改进的HOG-CLBC的行人检测方法[J]. 光电工程, 2018, 45(8): 77−85. CHENG Deqiang, TANG Shixuan, FENG Chenchen, et al. Extended HOG-CLBC for pedstrain detection[J]. Opto-Electronic Engineering, 2018, 45(8): 77−85.
[4] 胡亚洲, 周亚丽, 张奇志. 基于背景建模和帧间差分法的高点监控行人检测[J]. 实验室研究与探索, 2018, 37(9): 12−16. HU Yazhou, ZHOU Yali, ZHANG Qizhi. High point monitoring pedestrian detection based on background modeling and inter frame difference method[J]. Research and Exploration in Laboratory, 2018, 37(9): 12−16.
[5] WANG Kelong, ZHOU Wei. Pedestrian and cyclist detection based on deep neural network fast R-CNN[J]. International Journal of Advanced Robotic Systems, 2019, 16(1): 1−10.
[6] XIAO Feng, LIU Baotong. Pedestrian detection using visual saliency and deep learning[J]. Acta Microsc, 2018, 27(4): 242−251.
[7] 吴帅, 徐勇, 赵东宁. 基于深度卷积网络的目标检测综述[J]. 模式识别与人工智能, 2018, 31(4): 335−346. WU Shuai, XU Yong, ZHAO Dongning. Survey of object detection based on deep convolutional network[J]. Pattern Recognition and Artificial Intelligence, 2018, 31(4): 335− 346.
[8] 郑冬, 李向群, 许新征. 基于轻量化SSD的车辆及行人检测网络[J]. 南京师大学报(自然科学版), 2019, 42(1): 73−81. ZHENG Dong, LI Xiangqun, XU Xinzheng. Vehicle and pedestrian detection model based on lightweight SSD[J]. Journal of Nanjing Normal University (Natural Science Edition), 2019, 42(1): 73−81.
[9] 刘丹, 马同伟. 结合语义信息的行人检测方法[J]. 电子测量与仪器学报, 2019, 33(1): 54−60. LIU Dan, MA Tongwei. Pedestrian detection method based on semantic information[J]. Journal of Electronic Measurement and Instrumentation, 2019, 33(1): 54−60.
[10] 郝旭政, 柴争义. 一种改进的深度残差网络行人检测方法[J]. 计算机应用研究, 2019, 36(5): 1569−1572, 1584. HAO Xuzheng, CHAI Zhengyi. Improved pedestrian detection method based on depth residual network[J]. Application Research of Computers, 2019, 36(5): 1569− 1572, 1584.
[11] 高宗, 李少波, 陈济楠, 等. 基于YOLO网络的行人检测方法[J]. 计算机工程, 2018, 44(5): 215−219, 226. GAO Zong, LI Shaobo, CHEN Jinan, et al. Pedestrian detection method based on YOLO network[J]. Computer Engineering, 2018, 44(5): 215−219, 226.
[12] 盛智勇, 揭真, 曲洪权, 等. 基于改进锚候选框的甚高速区域卷积神经网络的端到端地铁行人检测[J]. 科学技术与工程, 2018, 18(22): 90−96. SHENG Zhiyong, JIE Zhen, QU Hongquan, et al. End-to-end faster-recurrent convolutional neural network subway pedestrian detection based on improved anchor proposal[J]. Science Technology and Engineering, 2018, 18(22): 90−96.
[13] YANG Dongming, ZHANG Jiguang, XU Shibiao, et al. Real-time pedestrian detection via hierarchical convolutional feature[J]. Multimedia Tools and Applications, 2018, 77(19): 25841−25860.
[14] Heo Duyoung, Lee Eunju, Ko Byoungchul. Pedestrian detection at night using deep neural networks and saliency maps[J]. Journal of Imaging Science and Technology, 2017, 61(6): 1−9.
[15] HAN Jian, LIAO Yaping, ZHANG Junyou, et al. Target fusion detection of LiDAR and camera based on the improved YOLO algorithm[J]. Mathematics, 2018, 6(10): 213.
[16] KUANG Ping, MA Tingsong, LI Fan. Real-time pedestrian detection using convolutional neural networks [J]. International Journal of Pattern Recognition and Artificial Intelligence, 2018, 32(11): 1−16.
[17] SHI Jun, LI Zheng, YING Shihui, et al. MR image super-resolution via wide residual networks with fixed skip connection[J]. IEEE Journal of Biomedical and Health Informatics, 2019, 23(3): 1129−1140.
[18] 崔文靓, 王玉静, 康守强, 等. 基于改进YOLOv3算法的公路车道线检测方法[J/OL]. 自动化学报: 1− 9[2021−01−19].https://doi.org/10.16383/j.aas.c190178. CUI Wenliang, WANG Yujing, KANG Shouqiang, et al. Road lane line detection method based on improved YOLOv3 algorithm[J/OL]. Acta Automatica Sinica: 1− 9[2021−01−19]. https://doi.org/10.16383/j.aas.c190178.
Pedestrian detection method for station based on improved YOLOv3
KANG Zhuang1, YANG Jie1, LI Guilan1, NAN Bingfei2, ZENG Lu1
(1. School of Electrical Engineering and Automation, Jiangxi University of Science and Technology, Ganzhou 341000, China;2. Beijing Tiandi-Marco Electro-Hydraulic Control System Co., Ltd., China Coal Technology & Engineering Group Corp, Beijing 100013, China)
Aiming at the problem of low accuracy and high missing rate of pedestrian detection in yorov3 algorithm, an improved yorov3 pedestrian detection method was proposed, which was defined as GA-Wide-YOLOv3. Firstly, the small head and shoulder targets of pedestrians were used as the detection objects to reconstruct the data set. The priori frames of the targets were clustered again by genetic algorithm. The anchor parameters were optimized to improve the priori frames and the weight of the data set. Secondly, YOLOv3 was improved. By widening the width of the network and reducing the depth of the network, the larger visual field threshold for small target detection was obtained to avoid the disappearance of the gradient. Finally, the convolution groups of 1 * 1 and 3 * 3 in front of the three Yolo layers of the multi-scale detection algorithm were removed from two groups respectively to reduce the missed detection rate of head shoulder small target in complex background. The comparative experiment was carried out on the collected data set hs6936, and the results were summarized. The results show that the improved K-means algorithm based on genetic algorithm has an average intersection and union ratio of 81.89%, which is 0.8% higher. The improved YOLOv3 algorithm has an average detection accuracy of 75.35%, recall rate of 81.20%, and precision rate of 99.99%. The proposed approach is 2.53%, 0.88%, and 2.75% higher than that of the original YOLOv3 algorithm.
pedestrian detection; deep learning;YOLOv3; genetic algorithm; computer vision

TP391.4
A

1672 − 7029(2021)01 − 0055 − 09
10.19713/j.cnki.43−1423/u.T20200236
2020−03−25
江西省03专项及5G项目(20204ABC03A15);国家重点研发计划先进轨道交通专项(2017YFB1201105-12);中国煤炭科工集团有限公司科技创新创业资金专项重点项目(2018ZD006)
杨杰(1979−),男,安徽蚌埠人,教授,博士,从事轨道交通和计算机视觉研究;E−mail:yangjie@jxust.edu.cn
(编辑 阳丽霞)
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
扬子江(2019年1期)2019-03-08 02:52:34
电子测试(2017年15期)2017-12-18 07:19:27
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
