
基于改进TF-IDF可疑人员文本表示方法
2021-02-25 05:50:48何隽飞何学明
计算机工程与设计 2021年2期
何隽飞,赵 慧,何学明
(1.武汉科技大学 机器人与智能系统研究院,湖北 武汉 430080;2.武警海警学院 机电管理系,浙江 宁波 315801)
0 引 言
承办重大国际活动时,在不影响人民群众正常工作生活的前提下,通常会在的人群聚集区域入口设立严密的视频监控和安保闸口,通过监控闸口的身份识别信息,对人员进行数据库信息比对[1]。研究表明,在实际案例中暴恐组织记录在案的人员一般不直接参与暴恐活动,而是通过发展亲友、组织新人直接制造暴恐活动,这给安保任务对可疑人员进行威胁等级研判带来了新的技术挑战[2]。目前现有的较为完备的人员信息库一般是半结构化的文本数据库;情报研判需要情报人员大量的人工参与才能进行,效率十分低下[3]。如何自动从大量的文本中提取出有用的信息,为后续研判提供支撑是首要待解决的技术问题。
本文通过对文本表示模型和文本分类方法的研究,提出了面向情报研判的可疑人员文本表示方法。方法通过引入文本类别参数改进TF-IDF文本特征提取算法,使文本表示模型能够充分表征可疑人员属性特征,从而提高威胁研判的效率。研究表明,潜在的可疑人员一般具有和暴恐份子相似或者重叠的行为规律和属性特征。利用这一规律,本文基于历史数据库的可疑人员信息进行文本类别特征学习,通过提取可疑人员的行为规律和属性特征,并进行文本表示,然后通过文本分类算法不断加深对文本特征的学习,训练出能对可疑人员进行研判的分类模型,从而实现对可疑人员的威胁等级研判。
1 相关工作
从大量文本中提取关键特征并进行研判分类是属于文本分类的范畴。文本分类是自然语言处理领域极其重要的子任务,有绝大多数的场景都可以归纳为文本分类任务,比如:情感分析、领域识别、意图识别等等[4]。文本分类的过程就是通过提取文本中能够表达文本特征的关键词来表征文本,然后通过关键词的特征对文本进行类别的划分[5]。在机器学习领域,文本分类属于有监督学习,它通过对已标签的文本数据集进行特征学习,寻找文本标签和文本特征之间的关系,建立分类模型,然后使用这个模型对未知类别文本进行分类。
文本分类的核心问题是文本表示和分类模型。文本表示在分类模型之前,对分类模型的效果起着至关重要的作用。在自然语言处理领域,词袋和词嵌入是两种最常用的文本表示模型[6]。它们通过不同的方式将文本表示为向量,然后通过分类模型对向量进行分类。词袋模型是从文本文档中提取特征最简单但又最直接的技术。这个模型的本质是将每个文档转化成相应的向量,文档向量表示在所有文档空间中全部不同的单词在该文档中的频率[7]。ZHANG等利用One-hot把文本表示为向量,这种文本表示方法在应对文档单词比较单一且数量不大时有非常好的性能表现;但是在应对包含大量单词的文档时,这种表达方式容易造成维度灾难且不能展示词语之间的语义关系。提取文本特征词的好坏对词袋模型的文本表示效果有着直接的影响[8]。TF-IDF是传统的特征词提取算法,它通过筛选文本中的高频词并使用逆文档频率对高频词进行加权得到文本特征词[9]。它在表征文本特征方面达到了较高的精度,但是基于文本分类的场景,由于未考虑文本类别的参数,并不能有效提取出对文本分类具有关键作用的特征词。词嵌入模型是自然语言处理中语言模型与表征学习技术的统称。Paccanaro等提出了Distributed representation概念,它基于神经网络学习文本词语的分布式表示。该方法用词语之间的“距离”概念表示词语的语义关系,从而达到将词向量降维的目的[10]。其中,Word2vec[11]是Google在2013年开源的一款词向量工具,其原理基于深度学习算法,是目前较为成熟的词向量模型,适用于复杂文本的词向量表示[12]。文本向量化表示之后,就可以通过文本分类模型进行训练学习特征,从而得到可以对未知文本进行分类的分类模型。目前,应用于文本分类的技术和算法很多,例如朴素贝叶斯算法、K最近邻算法、神经网络、支持向量机(SVM)等[13]。大量研究表明SVM分类算法有很好的泛化能力与学习能力,被广泛用于文本自动分类、人脸识别、基因表达、手写体的识别等领域[14]。
2 属性加权的可疑人员文本表示
2.1 基于文本表示的研判方案
鉴于现有的可疑人员情报文本数据特征,通过本文提出的属性加权文本表示方法对可疑人员情报进行文本向量化表示,然后在SVM分类模型中建立可疑人员情报与威胁等级之间的映射关系,实现对可疑人员的研判分类,情报研判方案如图1所示。
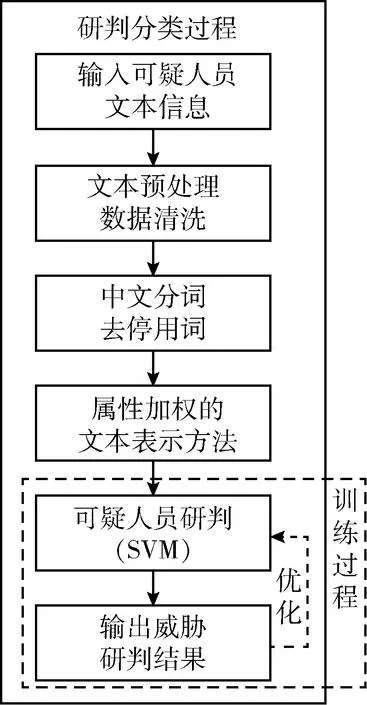
图1 情报研判方案流程
2.2 可疑人员信息库特点
目前,历史可疑人员信息库是在自然语言的基础上提炼出的半结构化文本数据库,它对比自然语言处理领域的应用对象有自身的特点。例如,可疑人员各属性之间的关联性相较于自然文本语言的词语间的关联性呈现出弱关联的特点;但单个属性的文本又具有自然文本语言的特点;可疑人员情报信息是基于可疑人员的属性特征进行统计的,造成了属性特征之间的相对独立;半结构化的文本数据库让文本特征更加的简明,但涉及特殊属性例如‘负债情况’、‘征信情况’等则是通过复杂的文本表述进行特征表示。随着可疑人员信息库的逐渐扩展,单条可疑人员的文本信息量增多,主要表现为属性数量的增加以及属性信息更为复杂。将半结构化的可疑人员文本数据进行文本向量化表示是首要的也是直接影响威胁研判效果的关键一步。
2.3 属性加权表示方法
One-hot和TF-IDF是目前最为常见的基于词袋模型提取文本特征的方法。由于词袋模型的缘故,词与词之间的顺序特征未纳入学习范围,这恰好符合可疑人员信息库中属性相对独立的特点;通常One-hot方法制作的向量是高维稀疏的,容易造成分类模型训练过程中内存爆炸,但情报研判领域中由于现有信息库属性数量限制,后续可以通过人为控制属性数量输入来保证模型训练的顺利进行。
通常使用词袋模型,考虑词频作为文本特征是比较合适的,但是向量完全依赖于单词出现的绝对频率,这会影响其它出现相对不频繁但对文本分类更有意义和有效的单词,因此本文通过改进TF-IDF词频-逆文档频率来对One-hot向量进行加权优化,以此来改善情报研判模型的效果。
One-hot向量基于词袋模型表征可疑人员情报信息结果见表1。表格展示了3个可疑人员的One-hot向量,其中各属性权重参数均为1,无法判断属性相对于威胁等级的重要性。

表1 基于词袋模型的One-hot文本向量
TF-IDF是一种统计方法,用以评估单词对于文本集合中某一文本的重要程度。它的核心思想是单词的重要性与它在某篇文档中出现的次数成正比,与它在所有文档中出现的次数成反比。数学上,TF-IDF是两个度量的乘积,可以表示为TF-IDF=TF×IDF,其中词频(TF)和逆文档频率(IDF)是两个度量,TF-IDF的计算公式如式(1)所示。对于传统的TF-IDF而言,它通过对高频词的统计,提取出文档集合中特定文档里所包含的区别于其它文档的特征词。但是在面向文本分类场景时,仅仅依赖每篇文档区分度强的特征词并不能达到理想的分类效果。尤其在可疑人员情报文本表示中,由于存在文本类别参数未纳入考量,以及可疑人员信息文本长度相对固定的情况,这将导致属性特征词出现频率TF值将是一个恒定不变的值,无法达到有效提取特征词的作用

(1)
本文尝试改进TF-IDF算法,引入文本类别的考量,提出属性加权表示方法。将特定文档内的词频率TF改为同类别文档内的词频率,面向情报研判领域即各类威胁等级的可疑人员信息中各属性特征词出现的频率;由于传统算法中IDF部分只考虑了特征词与它出现的文档数量之间的关系,而忽略了特征词在文本类别之间的分布情况,本文将包含特征词的特定类别文档数引入IDF算法来优化IDF权重,即引入包含特征属性的特定威胁等级的可疑人数来优选影响研判的最佳权重。属性特征词的重要性随着它在特定威胁等级的可疑人员信息中出现的频率成正比增加,同时会随着它在可疑人员信息数据库中出现频率成反比下降。本文改进算法中,TF词频基于词袋模型以及文本集类别计算得出,表示该词在特定类别文档中出现的频率值。词频公式为
(2)
其中,i表示单词在词袋中的位置,j表示文本类别数。ni,j表示词袋中第i个词在dj类文档中出现的次数,∑knk,j表示该类文档中所有词条数目。逆文档频率是每个单词的文档频率的逆,传统算法中该值由文本集中全部文档数量除以包含该单词的文档数量,然后将结果取对数得到。本文引入类别文本数的逆文档频率公式为
(3)
其中,|D|表示文本集中全部文档数量,{m:ti∈dj}表示包含该单词且属于dj类文档数量,|{x:ti∈dx}+1|表示所有包含该单词的文档数量。
整合改进后的TF-IDF算法公式为式(4)所示,表示第i个词对dj类文档的重要程度
(4)
为简化分类模型训练参数,防止过拟合,将整合后的类别特征词属性进行均值化处理如式(5)所示,得到了词袋模型每个单词的权重
(5)
将每个单词权重按词袋顺序依次连接,合成为属性特征词向量,见表2,通过属性特征词向量对One-hot向量进行属性加权,即对可疑人员情报文本信息进行改进的TF-IDF操作,得到了最终的可疑人员情报特征向量,见表3。
改进的TF-IDF方法制作的特征向量相较于One-hot向量,表征了更多的特征信息,不仅包含了One-hot的优点区分了每个可疑人员的信息,还引入了属性加权区别了各属性对可疑人员信息的权重,为后续研判提供了重要的参考。

表2 属性特征词向量

表3 可疑人员情报特征向量
3 实验设计与分析
3.1 实验设计
本文在Anaconda环境中使用Python3.7进行数据清洗操作,并通过scikit-learn机器学习库对可疑人员历史数据信息进行文本表示和特征学习的模型训练。
通过使用One-hot编码和改进的TF-IDF特征词提取方法制作可疑人员特征向量,然后将可疑人员特征向量输送给SVM分类模型,通过模型预测结果对分类模型进行性能评估,并分析实验结果。实验设计流程如图2所示。

图2 实验设计流程
3.2 数据来源与预处理
本实验数据来源于公安部重点人员信息库,实验所用数据进行了非密化处理,保留了原始数据的自然属性和可疑人员的行为规律以及属性特征。如图3所示,每个可疑人员有13个特征属性,涵盖了威胁研判所需要的基本信息,包括年龄、性别、民族、宗教信仰、教育程度、籍贯、婚姻状况、涉案类型、出行情况、征信情况、在案情况、负债情况、亲友情况等。原始数据中,可疑人员被标签为3个威胁等级,因为存在样本不均衡的问题,需要通过数据预处理减轻不均衡对分类模型的影响,处理完的数据比例如图4所示。其中,高威胁人员数据中宗教信仰分布和民族分布如图5和图6所示。

图3 重点人员信息库部分属性截图

图4 可疑人员类别比例

图5 高威胁人员宗教信仰分布
3.3 实验结果评价指标
训练、调优和建立模型是整个分析生命周期的重要部分,但更重要的是知道这些模型的性能如何。分类模型的性能一般基于模型对新数据的预测结果。本文使用精确率(precision)、召回率(recall)、F均值等指标来评估模型的性能,指标定义见表4。
其中,c为正样本被正确预测为正类的数量,d为负样本被错误预测为正类的数量,e为正样本被错误预测为负类的数量。F均值通过同时考虑分类精确率和召回率,可以用来整体描述模型的分类精度。
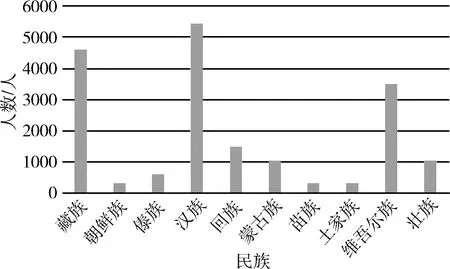
图6 高威胁人员民族分布

表4 分类器性能指标
3.4 实验结果及分析
通过对比实验得到改进前后TF-IDF文本表示方法与One-hot文本表示方法应用在可疑人员信息数据库上的研判模型评估结果,如图7所示,从结果可知,在使用SVM分类算法作为研判分类模型中,改进的TF-IDF属性加权文本表示方法相较于传统文本表示方法能达到更高的研判精度。

图7 研判分类结果评估对比
其中,改进后的TF-IDF算法引入了类别参数后精确率达到了98.8%,相较于传统的文本表示方法提高了将近4%,且完全符合安保任务对智能系统研判精度的要求标准。传统的TF-IDF方法在该可疑人员数据集上的表现稍优于One-hot方法。
图8展示了算法在各威胁等级测试集上的研判准确率。通过对比分析可知,改进的TF-IDF算法对中威胁等级的分类准确率更高,这源于本文算法引入类别参数后进行了类别权重的均值化操作,优化了算法对中威胁等级可疑人员的敏感度,并且没有损失对高威胁等级的分类精度。传统TF-IDF和One-hot算法对高威胁等级的分类准确率更高,但是对中威胁和低威胁的研判准确率相对就较低,这缘于数据集样本均衡的前提下,特征提取算法没能提取到区分类别的权重信息。
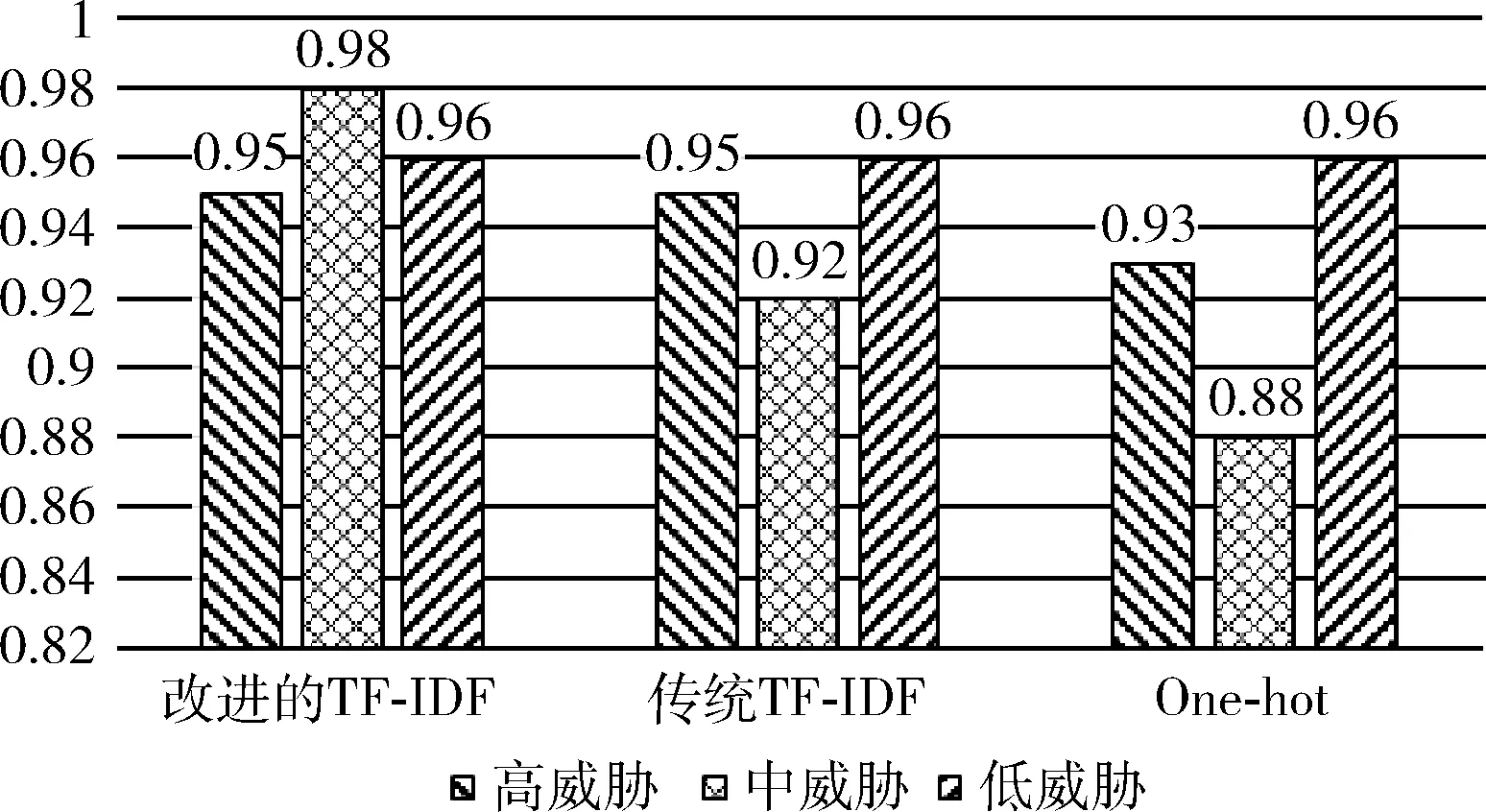
图8 各威胁等级的研判准确率
算法的运算效率受制的因素有很多,其中算法的复杂程度、计算平台以及数据本身占据着主要因素,本实验所用平台是Intel(R)Core(TM)i5-3210双核CPU@2.5 GHz的RAM为8 GB的笔记本电脑。从图9可以看出,由于在TF-IDF中引入了类别文本数,使改进的TF-IDF权重表征能力加强,改进后的文本表示方法能够更好表征可疑人员信息,具有更多信息的特征向量导入研判模型的训练时间相应也随之增加,但在提高研判精度的前提下整体训练耗时都在正常可控范围内。
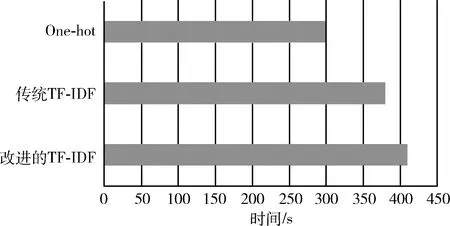
图9 算法训练时间对比
此外,本文还对目前主流的文本表示方法Word2vec模型进行了相应对比实验,并控制不同的训练集比例进行多组对照。如图10所示,当训练数据较少时,使用本文改进的TF-IDF算法进行特征提取,可以得到更好的分类特征,从而达到更高的研判准确率;由于Word2vec模型基于简单神经网络模型设计而来,需要大量的数据来训练权重矩阵,因此随着训练集比例的增大,Word2vec模型的效果会有较大的提升,而改进的TF-IDF算法效果会有轻微下降,这缘于TF-IDF算法本身存在对数据集大小的限制,当数据集过大时,分类特征的提取受制于TF值的变化程度减弱,相应的表征能力会出现下降。

图10 算法相对训练集比例的准确率对比
4 结束语
本文提出了一种基于改进TF-IDF的可疑人员文本表示方法,通过实验结果分析,验证了方法的可行性,改进算法在可疑人员信息表征中可以提取到更多类别信息,有助于研判的分类准确率。同时,通过对比本文改进的TF-IDF属性加权文本表示方法与传统文本表示方法在SVM分类算法中的性能表现,可知在可疑人员情报研判任务中,鉴于目前可疑人员信息库的特点,以及实际应用场景考虑,本文算法在充分满足研判任务需求的同时,提供了高质量的研判参考信息,提高了情报人员的研判效率。
但随着未来可疑人员信息数据库逐步壮大,也需要研究更高效的文本分类模型。深度神经网络在提取复杂文本信息方面有着更强大的表征能力,未来面向安防领域,可疑人员情报研判将纳入更多的属性信息,利用深度神经网络将为安保任务提供更优质的技术保障。
猜你喜欢
江苏安全生产(2022年3期)2022-04-19 10:47:18
中国新闻周刊(2021年26期)2021-07-27 04:02:12
中国外汇(2019年20期)2019-11-25 09:54:52
中国外汇(2019年18期)2019-11-25 01:41:48
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
中国交通信息化(2017年12期)2017-06-06 07:23:55
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2015年4期)2015-04-21 08:29:12
