
结合自编码器和卷积神经网络的推荐系统
2021-02-25 09:14:32刘钟涛刘兰淇
计算机工程与设计 2021年2期
刘钟涛,刘兰淇
(河南财经政法大学 现代教育技术中心,河南 郑州 450046)
0 引 言
许多研究人员对协同过滤方法进行了有价值的研究[1-3],有效地缓解了稀疏评分矩阵的问题,但是受限于评分信息的数量,依然难以准确预测出缺失的评分信息。
随着电子商务的广泛应用,每条交易信息包含了用户评论内容、晒图、用户档案、商品介绍、商家档案等一系列数据,传统基于评分的协同过滤方法已经难以准确地评估出用户相似性和项目相似性。除了协同过滤推荐方法,基于内容的推荐方法成为了推荐系统领域的研究热点。
为了充分利用用户评论的信息,设计了方面级的观点挖掘算法[4,5],分析用户对产品每个方面的情感极性。当前的观点挖掘算法大多为观点的每个方面分配相等的权重[6],但在推荐系统问题中,用户对不同方面的重视程度有所差异,某些用户可能偏爱外观好的产品、某些用户可能偏爱物流快的产品,因此分配相等权重很难提取出用户的细粒度兴趣。为了更加契合现实的产品推荐场景,提出了新的方面级加权观点挖掘方法,利用深度学习技术提取产品的每个方面及其情感极性,再估计出用户对不同方面的权重,最终结合观点的分析结果为用户提供推荐的项目列表。
1 方面级的评论分析方法
现有的观点挖掘算法直接从文字评论提取观点[7],未能很好地和推荐系统相结合,本文设计了基于深度学习的观点提取技术,使用张量分解法计算每个方面的加权调和评分值,最终预测出用户的评分。假设推荐系统的项目集为P={p1,p2,…,pn},用户集为V={v1,v2,…,vn}。设R表示用户-项目评分矩阵,矩阵元素rij表示用户vi对项目pj的评分。另外创建一个标识矩阵M=[mij]I×J,每个变量mij表示评分rij是否具有评论内容。


图1 推荐系统的完整框架
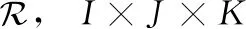
1.1 基于MCNN的评价对象抽取
方面级观点挖掘包含4个要素:方面、观点持有者、观点语义和情感,可描述为持有者对某一方面给出具有情感的语义。CNN在观点挖掘问题上表现出较好的性能,本文设计了双通道CNN结构提取产品的方面级观点。
图2是CNN的总体结构。CNN包括两个输入通道:词嵌入(Word Embedding)通道和词性(Part of Speech)标注嵌入通道。词嵌入通道的目标是学习评论内容的语义和上下文信息,该通道采用成熟的word2vec[8]模型实现,该模型采用CBOW框架在大规模Google新闻语料库上训练而来。CNN的词嵌入通道将每个词映射到低维向量,生成矩阵X∈Rn×k。词性标注嵌入通道也采用了成熟的Stanford POS Tagger编码[9],以一个45维向量表示词性,词性表示为:wz∈Rn×45。

图2 CNN的总体结构
(1)卷积层
卷积层从产品评论中提取最显著的特征。该层通过两个大小不同的filter生成局部特征,词嵌入通道和标注通道的filter大小不同。设wx∈Rh×k为词嵌入通道的filter,h为filter的高度,X为词嵌入通道的矩阵。卷积层提取特征的数学式可表示为
Ci=f(w·xi+h+b)
(1)
式中:f为非线性函数,b为偏置项。通过滑动窗口寻找X中的所有可能词,获得一个特征图
(2)
式中:cx∈Rn-h+1。
标注嵌入通道的filter设为wz∈Rh×l,其对应的特征图表示为
(3)
式中:cz∈Rn-h+1。
(2)池化层
通过最大池化层提取出卷积结果的最大元素,池化层的数学模型可表示为
(4)
(5)
式中:n和m分别为语义特征和标注特征的数量。
(3)输出层
最终运用softmax函数生成输出标签。输出层的数学式可表示为
O=w·(c∘r)+b
(6)
式中:r=Rn+m服从伯努利分布。
1.2 方面聚类
在许多产品评论中用户涉及了多个方面,但有些方面可以归纳为一组,例如:“快递速度快!”和“发货神速!”这两个评价属于同一个类型。因此需要对CNN提取的方面信息进行归纳处理,但用户评论中存在大量不规范的语言表述方式,难以通过现有的聚类算法和距离度量方法直接进行分组。为此本文设计了基于自编码器的方面级评论归纳方法。
评论归纳的目标是将词语(方面)映射到实向量空间,使两个词之间的距离转化成实向量空间中的距离,然后使用K-means方法对方面进行聚类(方面数量K值由实验确定)。映射函数F()需服从两个约束条件:①在实向量空间中,一个特定词和它的不规范词之间的距离应当小于该词和其它不规范词之间的距离。②在实向量空间中,意义相似的词之间距离应当小于意义不相似词的距离。本文使用降噪自编密码器实现第①个约束。采用上下文编码器实现第②个约束,编码器假设上下文相同的词意相似。
(1)降噪自编码器设计
自编码器的结构包括输入层、隐藏层和输出层3个部分。假设x为一个训练样本,自编码器的目标是学习一个函数id(x)≈x。如果对自编码器设置约束条件,那么函数id()能够学习数据的特征和结构。为输入数据增加噪声也是一种约束,自编码器识别出最相关的特征,该类型的自编码器称为降噪自编码器。
h(v(mj))=o(Wv(mj)+b)
(7)
其中,W为权重矩阵,o为激活函数,b为偏置项。W的每个元素wpq表示v(mj)第p个元素和自编码器第q个隐层单元间连接的权重。
(8)


(9)
其中,函数d()表示在实向量空间的距离度量函数。
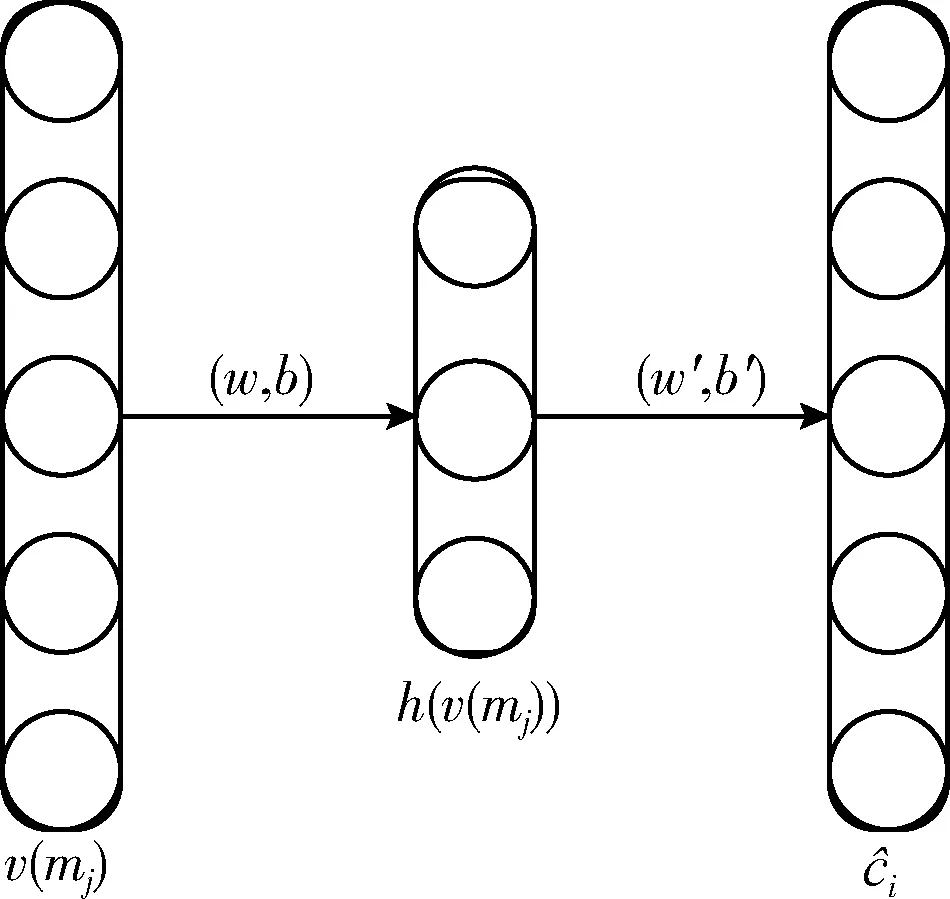
图3 降噪自编码器的网络结构
(2)上下文编码方法
将自编码器与上下文环境连接起来,上下文定义为一个词语序列a1,a2,…,aT,其中at∈A。上下文编码器的目标是学习一个概率函数g(),g()能反映每个词在给定上下文的概率,g()定义为词at出现在序列at-1,…,at-s-1之后的可能性,表示为g(at,at-1,…,at-s-1)=P(at|at=1,…,at=s=1)。将g()分成两个子函数:①将词语ai∈A映射成向量的函数:u(ai),表示词ai在词集中相关联的词向量。②词向量空间的概率函数:f(),f()根据上下文的词向量序列(u(at),u(at-1),…,u(at-s-1)),计算出下一个词at的条件概率分布:g(at,at-1,…,at-s-1)=f(u(at),u(at-1),…,u(at-s-1))。
函数g()是u()和f()的复合函数,通过上下文编码器学习函数g(),编码器的网络结果如图4所示。图中矩阵U为词向量矩阵,f()的参数设为ω。通过最大化以下的对数似然来训练神经网络
(10)
f()采用softmax输出层,定义为
(11)
其中,y为神经网络隐层的输出,y的计算式为

(12)

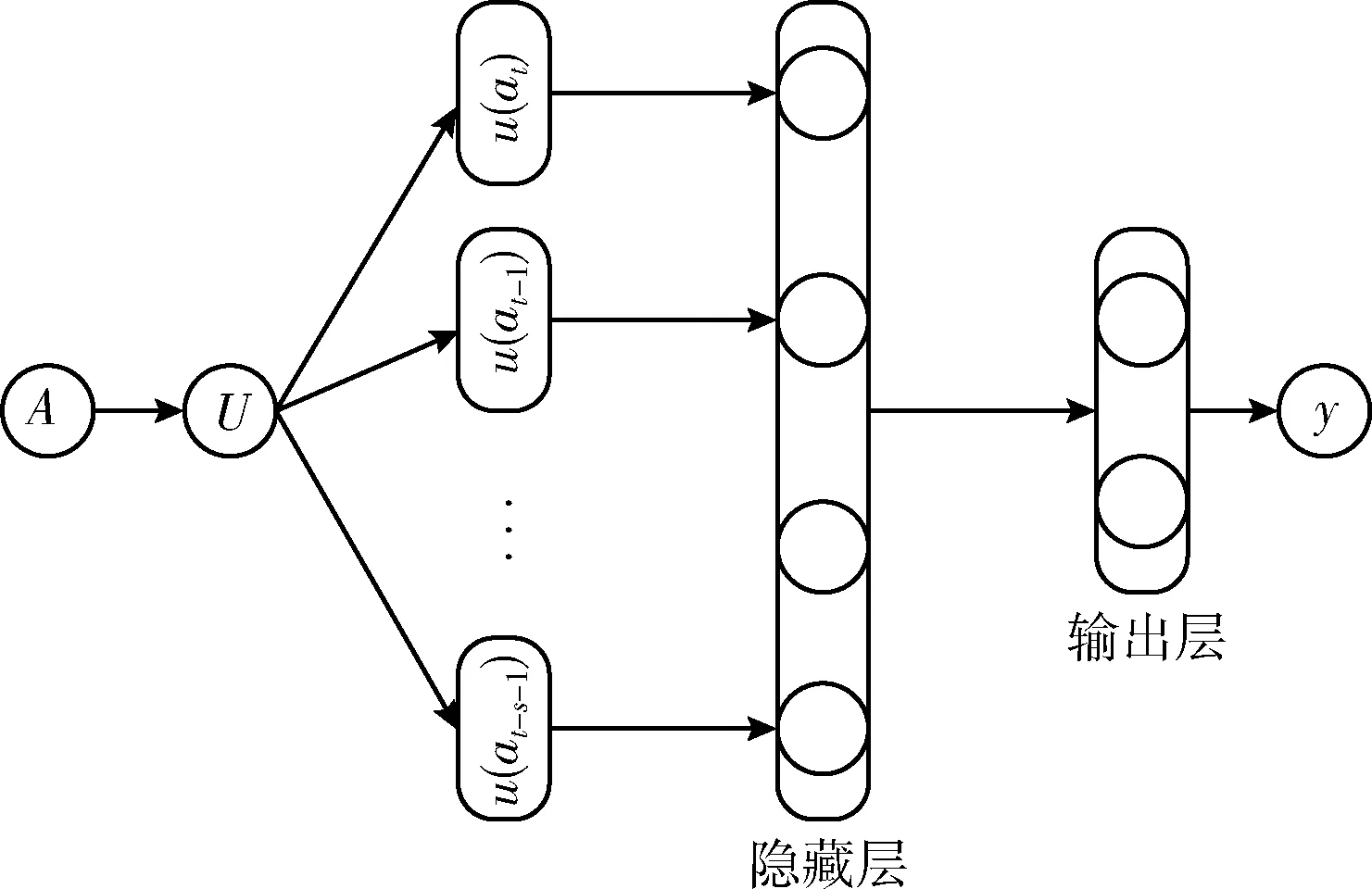
图4 上下文编码器的网络结构
(3)词空间的距离
如果h和v为双射函数,那么降噪自编码器h(v(ai))也满足从词空间C到h(v(C)⊂n的双射关系。由此可得词ai和aj自编码器表示之间的距离函数Da在空间词空间C中也具备距离度量能力,Da距离定义为
Da(ai,aj)=d(h(v(ai)),h(v(aj)))
(13)
图5是降噪自编码器和上下文编码器混合的深度网络结构,初始化函数v是词的独热编码,考虑自编码器和上下文编码相结合获得映射函数F,因此包含上下文关系的距离度量方法为
Dc(ai,aj)=d(F(ai),F(aj))
(14)
其中,Dc可视为对Da的扩展,Dc含有词的上下文关系。

图5 混合编码器的网络结构
自编码器的目标是最小化正确词和非标准词向量表示之间的距离,上下文编码器则同时学习了矩阵U中标准词和不规范词的向量表示。
2 观点挖掘和推荐系统的结合方法
2.1 计算方面级的评分
上文获得了归纳后的方面集和观点集,然后估计方面级的评分矩阵R1,R2,…,RK,K为方面数量。首先采用语义Wordnet方法[10]计算每个方面的情感极性评分,假设ak是评论Dij的一个方面,那么该方面评分的计算式为
(15)
式中:Wk表示Dij中与方面ak相关的词集,OP(w)表示词的极性评分。
2.2 估计方面级的权重

(16)
式中:R为一维张量元素的数量,运算符“∘”表示向量外积运算,xr、yr和zr分别为矩阵X、Y和Z的列向量,I×R、J×R和K×R分别为X、Y和Z的大小。式(16)的元素级计算式为
(17)
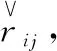
(18)
通过对以下目标函数进行最小化处理,计算出矩阵X、Y和Z的最优值
(19)
约束条件为
gijk≡-wijk≤0
(20)
(21)
式中:i=1,…,I,j=1,…,J,k=1,2,…,K,gijk和hij为约束条件。使用梯度下降法[11]估计式(17)的最佳矩阵X、Y和Z。
(22)

2.3 预测用户评分
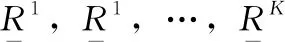
(23)
式中:D为张量的维数。
3 仿真实验与结果分析
本文利用方面级观点挖掘技术以提高推荐系统的性能,因此对系统的方面级观点挖掘技术和总推荐系统分别进行了验证实验。
3.1 方面提取实验
采用观点挖掘问题常用的Amazon数据集[13]作为benchmark数据集,从该数据集选择3种产品的文字评论,分别为DVD,Canon和Cell phane。数据集的每个句子被标注了方面和观点极性。表1是数据集的介绍。

表1 实验数据集的统计信息
(1)对比方法和参数设置
本次实验采用了4组对比模型:①基于字典学习的观点挖掘算法(DLC)[14],②基于循环深度学习的观点挖掘(DLM)[15],③基于CNN和SVM的观点挖掘算法(CNN-SVM)[16],④基于种群优化聚类的观点挖掘算法(SwarmC)[17]。本文观点挖掘算法包含聚类技术和卷积神经网络技术,通过CNN-SVM[16]可评估本文改进CNN模型的性能。
本文的CNN模型嵌入层和卷积层均采用大小为(3,4,5)的filter。每个filter包含100个特征图,dropout率为0.5。将ReLU作为激活函数,隐层单元数量为128。采用随机梯度下降法训练CNN模型,基于5折交叉验证方法确定网络的参数。鉴于F1-score指标综合了精度指标和召回率指标,采用F1-score作为总评价指标。
(2)方面提取实验的结果
图6是5个观点挖掘算法的F1-score结果,实验结果的置信度为95%。图中显示,DLC和SwarmC两个算法的性能低于其它3个算法,由此可看出当前的深度学习技术在观点挖掘问题上具有较好的效果。另外比较DLM和CNN-SVM两个算法,CNN-SVM的结果略好于DLM,CNN-SVM通过经典CNN提取评论的观点和词性,再通过SVM对观点进行归纳。DLM所采用的循环神经网络包含忘记机制导致提取的特征集稀疏性较高,因此未能达到CNN-SVM的性能。本文系统的性能则略高于CNN-SVM,由此总结出:本文的CNN双通道结构有效地增强了方面级观点检测的性能,基于混合编码器的观点归纳方法也有效地提高了观点挖掘的性能。

图6 观点挖掘实验的结果
3.2 推荐系统实验
基于内容的推荐系统通常需要具备评分预测能力和良好的推荐结果,在此对本文系统的评分预测能力和推荐性能进行了实验评估。使用McAuley[18]收集的Amazon数据集,该数据集包含大量产品的评论内容和评分信息,原数据集十分庞大,选择其中两个产品类别进行实验:乐器类产品和影音类产品。筛选出评论数量在5条以上的用户以及被评论数量在5条以上的产品,将其它不满足条件的数据删除。将数据集随机选择80%作为训练集、10%作为测试集、10%作为验证集,验证集用于微调神经网络的超参数。表2是最终实验数据集的统计信息。

表2 实验数据集的统计信息
(1)性能评价指标和对比模型
采用RMSE和MAE两个指标评估评分预测的性能,RMSE指标定义为
(24)
MAE指标定义为
(25)
式中:T为测试集的实例数量。
采用pre@10和平均精度均值(MAP)指标评估推荐结果的性能。pre@10统计了推荐系统返回的10个项目中包含了多少个相关项,定义为
(26)
MAP指标则重点评价了推荐项目列表的排列质量,相关度高的项目应当被优先推荐。设查询qi∈Q的相关项为{i1,…,im},Rjk为推荐系统返回的前ik个项,MAP的计算方法为
(27)
本次实验采用了4组对比模型,基于模糊系统的评分预测和推荐系统(SAwareRP)[19],基于图模型和特征向量的评分预测和推荐系统(GraphRP)[20],结合循环神经网络和反向传播神经网络的评分预测和推荐系统(RNN&BPNN)[21],基于观点挖掘的协同过滤推荐系统(CFOM)[22]。SAwareRP和GraphRP是和本文系统不同类型的评分预测技术,通过这两个模型观察不同系统类型的性能差异。RNN&BPNN是一个采用多层深度深度学习技术的评分预测技术,通过该模型观察本文所采用的卷积神经网络是否有效。CFOM也是基于观点挖掘的评分预测技术,该技术仅对评论观点的极性进行了粗粒度的分析,通过该模型观察本文方面级的评论挖掘技术是否有效。
(2)参数K实验
本系统将CNN挖掘的观点分为K个分组,选择不同的K值进行了实验,观察K值对系统性能的影响。图7是值为{5,10,15,20,25,30}时,推荐系统在验证集上的平均RMSE结果和平均MAE结果。图7中结果显示,两个数据集在K=15-20之间的预测性能最佳,K值过高会破坏方面和潜在因子矩阵之间的一对一映射关系,从而导致预测性能下降。在下文的实验中将K参数设为15。

图7 在验证集上的试错实验
3.3 评分预测性能
图8是不同系统在测试集上的平均预测实验结果。综合图中的全部结果,RNN&BPNN并未利用产品的评论信息,而是分析了用户的个人档案和评分信息,其评分预测的性能略低于其它4个系统。此外,基于观点挖掘的评分算法CFOM和本文系统优于其它3个算法,由此可确定挖掘产品的评论信息具有明显的效果。CFOM对评论内容给出总体的极性判断,如消极、中性和积极等,而在实际情况下,某些用户可能偏爱外观好的产品、某些用户可能偏爱物流快的产品,因此通过总体极性判断很难提取出用户的细粒度兴趣。本文系统则深入分析了评论的方面级观点,并通过三阶张量分解技术估计用户对每个方面的权重值,通过细粒度的观点分析提高了评分预测的准确性。
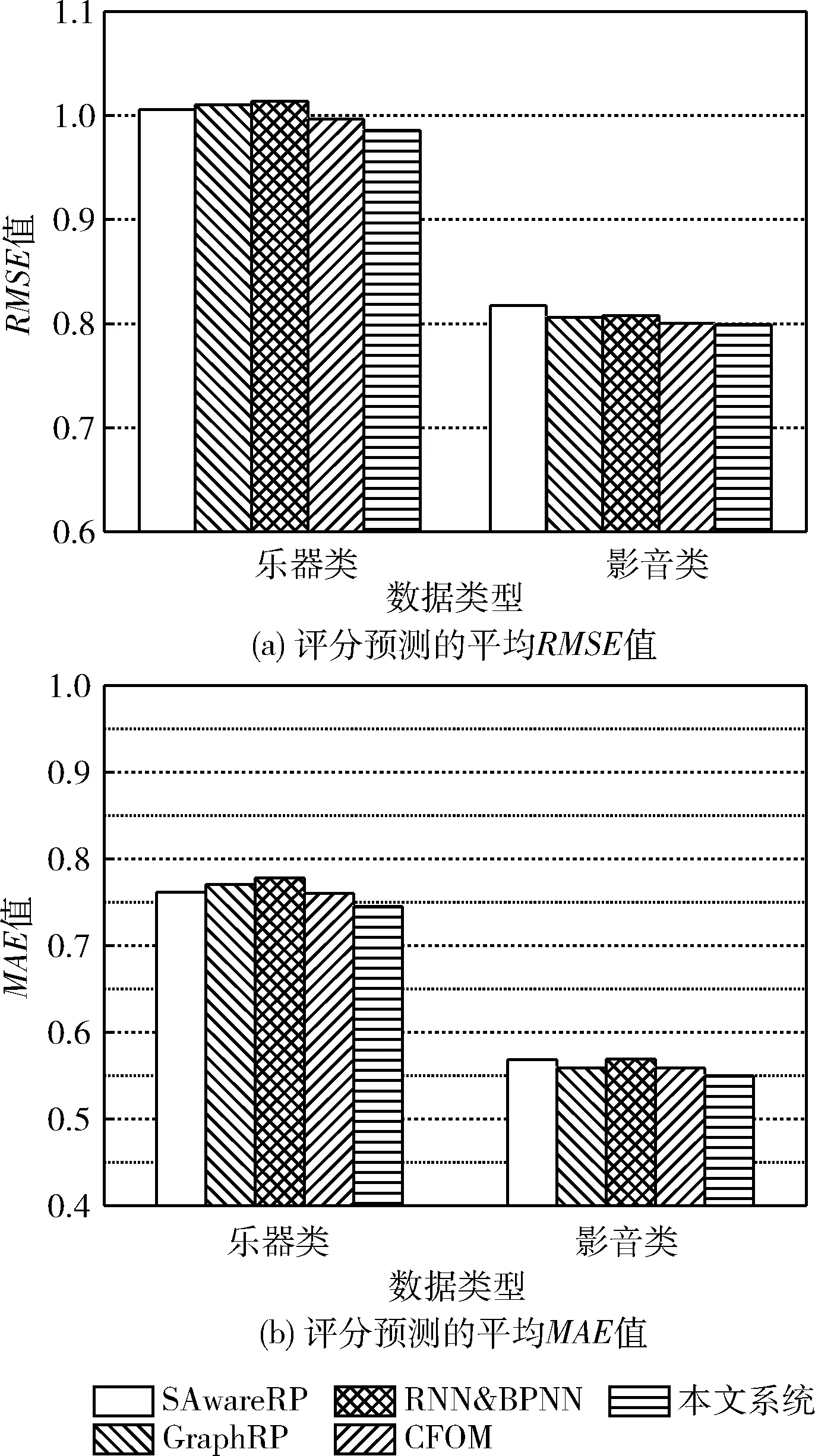
图8 在测试集上的实验
本文系统的优势在于加强了对评论不同方面的观点挖掘,提高了评分预测的鲁棒性和总体质量,该实验也表明高质量的观点挖掘技术能够促进推荐系统的推荐性能。
3.4 推荐结果的质量评价
基于预测的评分为每个测试用户产生一个Top-10的推荐项目列表,列表的项目按用户的偏好降序排列。图9是每个推荐系统的推荐列表pre@10指标和MAP指标。

图9 每个推荐系统的推荐列表质量
图9中CFOM的评分预测性能较好,但是该系统经过协同过滤的矩阵分解之后推荐的精度有所衰减,但CFOM的项目排列质量较为理想。SAwareRP的评分预测性能略低于其它模型,但该系统通过在矩阵分解过程中设立了约束,有效地提高了推荐系统的推荐质量。SAwareRP系统对乐器类产品的MAP指标较好,与本文系统较为接近。本文系统的pre@10指标和MAP指标明显高于其它4个推荐系统,由此可看出本文系统加强了对评论不同方面的观点挖掘,提高了评分预测的鲁棒性和总体质量,该实验也表明高质量的观点挖掘技术能够促进推荐系统的推荐性能。
4 结束语
为了更加契合现实的产品推荐场景,提出了一种方面级加权观点挖掘方法,并将该方法应用于推荐系统。系统通过卷积神经网络学习评论内容在方面级的情感和观点,然后基于降噪自编码器对方面级的观点集合进行归纳和分组,以三阶张量分解技术为基础,推断出用户对项目的综合评分。实验结果表明,该系统有效地提高了推荐系统的推荐性能,优化了推荐项目的顺序。本文系统的优势在于加强了对评论不同方面的观点挖掘,提高了评分预测的鲁棒性和总体质量,实验结果也表明高质量的观点挖掘技术能够促进推荐系统的推荐性能。未来将研究双通道CNN模型在中文环境和中文语料库的实现方法,并且收集中文的产品评论实验数据集,进一步完善本文的研究工作。
猜你喜欢
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
军营文化天地(2018年1期)2018-08-15 00:44:08
电子设计工程(2017年20期)2017-02-10 03:39:29
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
电子器件(2015年5期)2015-12-29 08:42:24
南都周刊(2015年1期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年4期)2015-09-10 07:22:44
营销界(2015年22期)2015-02-28 22:05:04
清风(2014年10期)2014-09-08 13:11:04
