
深度矩阵分解推荐算法*
2021-02-25 12:16潘腊梅
软件学报 2021年12期
田 震,潘腊梅,尹 朴,王 睿,2
1(北京科技大学 计算机与通信工程学院,北京 100083)
2(北京科技大学 顺德研究生院,广东 佛山 528300)
众多协同过滤推荐算法中,矩阵分解(matrix factorization,简称MF)算法因简单、易于实现,得到了广泛的应用.但是矩阵分解通过简单的线性内积方式无法建模用户和物品之间复杂的非线性关系,限制了模型的推荐性能.虽然许多工作从多个方面对矩阵分解算法进行改进,但是仍然采用线性内积方式建模用户和物品之间的交互,使得模型的性能提升有限.He 等人提出的广义矩阵分解模型(generalized matrix factorization,简称GMF)[1]利用神经网络,通过一个激活函数和不全是1 的连接权重赋予了MF 非线性学习能力,将MF 推广到非线性集合,提高了模型的表达能力.GMF 的浅层结构使得它在建模用户和物品的二阶交互关系上有很好的表现,然而却并不能很好地捕捉到包含更丰富信息的用户和物品之间的高阶交互关系.随着深度神经网络技术的不断成熟,许多研究人员逐渐意识到深度神经网络强大的非线性学习能力和抽象特征学习能力,并开始将其应用到矩阵分解过程.但是现有研究要么对于协同过滤部分仍采用线性内积,要么只建模了用户和物品的二阶交互关系,忽略了包含更多信息的高阶交互,导致模型性能受限.
针对以上问题,本文提出了一种深度矩阵分解推荐算法,算法在广义矩阵分解算法的基础上,通过在非线性内积得到的用户和物品的二阶交互之上引入隐藏层,利用深度神经网络建模用户和物品之间复杂的高阶非线性交互关系.实验结果表明,提出的深度矩阵分解推荐算法对于模型推荐性能具有显著的提升.
1 相关工作
在众多协同过滤推荐算法中,矩阵分解算法因其可扩展性和易于实现,成为最为普遍和最受欢迎的一种协同推荐算法.通过一组潜在的特征因子,把用户评分矩阵分解为user-factor matrix 和item-factor matrix.矩阵分解利用潜在因子向量描述用户和物品,即:将用户和物品映射到共享的潜在向量空间中,并通过映射向量之间的内积来表达用户与物品间的交互关系[2,3].为了进一步提升推荐性能,许多的工作对矩阵分解算法进行改进,并取得了显著的成果.Steffen 等人对于BPR-OPT 的学习模型提出了基于随机梯度下降和bootstrap 抽样的一般学习算法LearnBPR,并将其用于矩阵分解过程[4].Badrul 等人[5]提出了奇异值分解(SVD)来学习特征矩阵,但由SVD学习的MF 模型容易过拟合.之后,Pan 等人提出一种带案例权重的正则化最小二乘优化算法WR-MF[6].此外,Mohsen 等人提出了SocialMF 算法[7],根据用户信任关系,利用信任用户的潜在特征向量来增强矩阵分解,得到的用户潜在特征向量,从而提升模型推荐性能.但是,这种方法只使用信任关系的表面信息进行推荐,没有考虑社交网络中信任关系是由多种因素形成的,所以郭等人在SocialMF 的基础上提出了StrengthMF[8],将信任关系网络与评分信息联合用于矩阵分解过程,从而优化了推荐结果.同时,孙等人[9]提出了SequentialMF 推荐算法,该算法通过对用户时序行为建模发现用户邻居,从而将邻居信息融合到矩阵分解过程.虽然这些算法从不同的方面改进矩阵分解过程,使得模型推荐性能得到改善,但是这些算法的性能仍然受到因采取内积的方式建模用户和物品交互的限制,这种线性乘积的结合方式可能并不足以有效地捕捉交互数据中的非线性结构.即:简单和固定的内积有其局限性,会对模型造成一定的限制.
为了解决上述问题,He 等人在GMF 中利用神经网络的非线性学习能力,在MF 之上引入神经网络赋予模型学习用户和物品之间的非线性交互关系的能力,进一步提升了模型的表达能力.但是,GMF 中仅包含嵌入层和输出层,在得到用户和物品潜在特征向量后,通过在向量对应元素相乘的结果上添加一层全连接输出层就输出了结果,只是建模了用户和物品之间的二阶交互,并不能有效地捕捉到包含更丰富信息的用户和物品之间的高阶交互关系.即:GMF 的浅层结构能够建模用户和物品间交互的低层特征,但是并不能有效地捕捉到包含许多丰富信息、更抽象的高阶交互,高阶交互信息的缺失一定程度上会限制模型的推荐性能.
近些年,深度神经网络开始成为学术界和工业界的研究重点.深度神经网络通常拥有更多层次的隐藏层,单层隐藏层能够把输入数据的特征抽象到另一个维度空间,来展现其更抽象化的特征;而多隐藏层能够对输入特征进行多层次的抽象,最终帮助模型更好的线性划分不同类型的数据.深度神经网络因为其对更高层次、更抽象特征的学习能力,使得越来越多的工作开始尝试将矩阵分解与深度神经网络结合进行推荐任务.文献[10]结合了矩阵分解和深度卷积网络,将通过应用WMF[11]得到的潜在因子向量作为训练预测模型的基真值来训练深度卷积神经网络,从而进行音乐的推荐任务.Zhang 等人利用异构网络嵌入和深度学习嵌入方法,从知识库的结构知识、文本知识和视觉知识中自动提取语义表示,然后结合协同过滤中的矩阵分解模型来进行推荐[12].Wang等人提出了CDL 模型[13],通过对内容信息进行深度表示学习和对评分矩阵进行协同过滤,使得模型具有很好的表达能力.这些方法通过深度神经网络很好地建模用户和物品之间的复杂的非线性高阶交互,赋予了模型学习用户和物品之间更抽象关系的能力,很好地提升了模型的表达能力,但是对于协同过滤部分仍采用MF,通过简单的线性内积结合用户和物品的特征向量,一定程度上限制了模型的推荐性能.
此外,针对以往的MF 方法大多只采用显式评分进行个性化推荐,忽略了用户和信息项的隐式反馈的重要性问题,Zhou 等人[14]提出了基于深度神经网络的矩阵分解模型HDMF.同时利用显式评分和隐式反馈作为输入,并结合深度神经网络获取潜在因子.同时,应用递归神经网络(RNN)将文本数据转换为辅助因子特征,以促进项目的表达,进一步提升了矩阵分解模型的推荐性能.为了方便、高效地集成各种辅助信息,Yi 等人提出了深度矩阵分解模型DMF.基于提出的隐式反馈嵌入(IFE)方法和one-hot 编码,DMF 能够获取融合多种辅助信息的用户和物品的向量表示,然后通过多层感知器(MLP)分别对用户和物品向量进行特征转换,最终完成基于矩阵分解的推荐任务[15].为了充分学习用户和物品的特征表示向量,Ma 等人[16]提出了偏置深度矩阵分解模型BDMF,该模型利用深层神经网络强大的表示学习能力,建模用户和项目的抽象特征表示,同时借鉴BiasedSVD 将偏差引入用户和项目的特征表示中,进而将用户和项目从评分矩阵映射到低维空间.尽管以上3 个模型结合深度神经网络对矩阵分解算法性能进行了进一步的改善,但是他们的关注重点是利用深度神经网络强大的非线性学习能力帮助模型去学习用户和物品的抽象特征表示,在建模用户和物品的交互关系时,仍然只考虑了用户和物品的二阶交互,导致包含更多抽象信息的高阶交互被忽略.所以,本文提出了深度矩阵分解模型,通过在GMF 之上添加隐藏层,既能解决矩阵分解简单线性内积对模型的限制问题,又能利用深层神经网络来建模用户和物品之间的非线性高阶交互.
2 深度矩阵分解模型
2.1 问题定义
基于可读性,我们在表1 中列出了本文使用的重要数学符号.
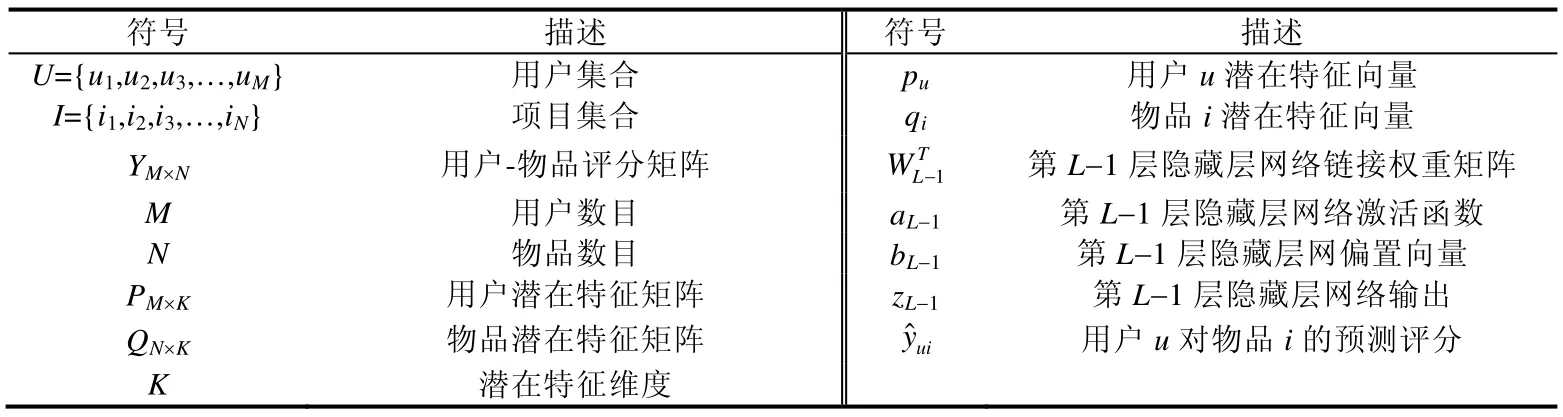
Table 1 Symbol definition表1 符号定义
基于这些符号,我们对问题进行了形式化定义.
问题定义.假设有用户集U={u1,u2,u3,…,uM},项目集I={i1,i2,i3,…,iN},其中,M为用户数目,N为物品数目.YM×N为用户-物品评分矩阵.现给定用户u∈U、物品i∈I,其中,用户u未与物品i产生交互.我们的目标是根据用户评分矩阵YM×N中用户u的历史评分记录,建模用户u的偏好,进而预测用户u对物品i的偏好评分,再根据预测值对商品排名,最终为用户推荐前n个物品.
2.2 DMF模型
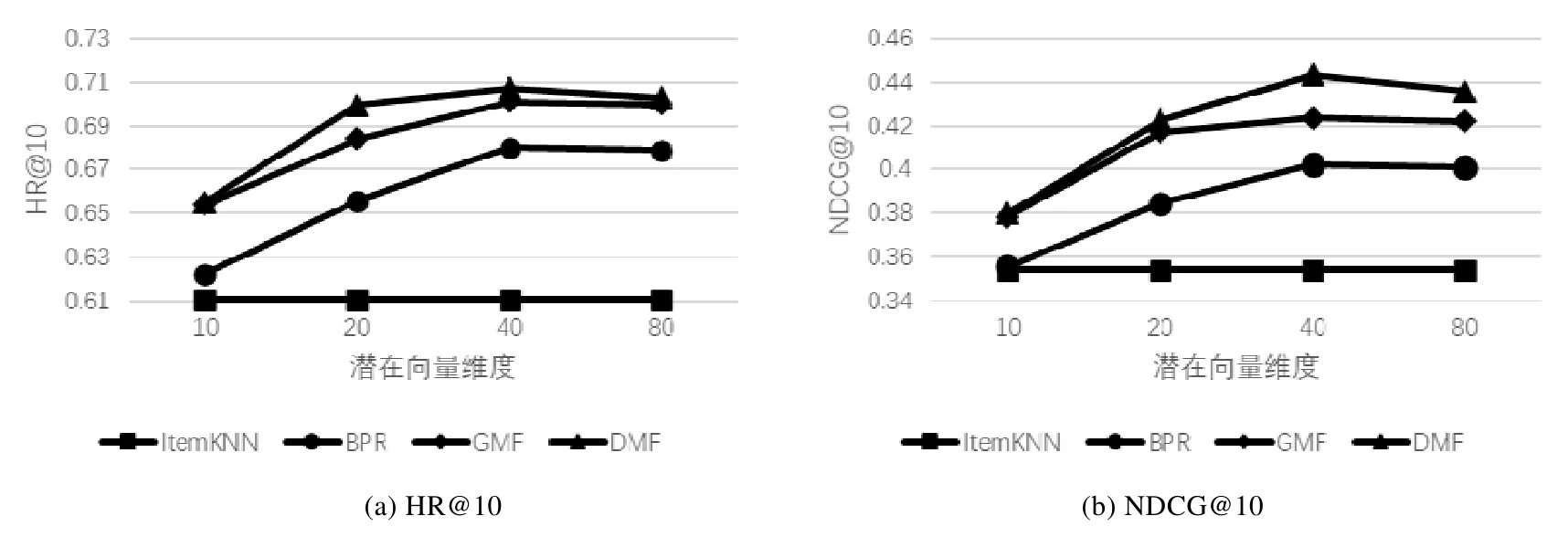
为了学习用户和物品之间复杂的高阶非线性交互关系,本文提出了深度矩阵分解模型,该框架如图1 所示.
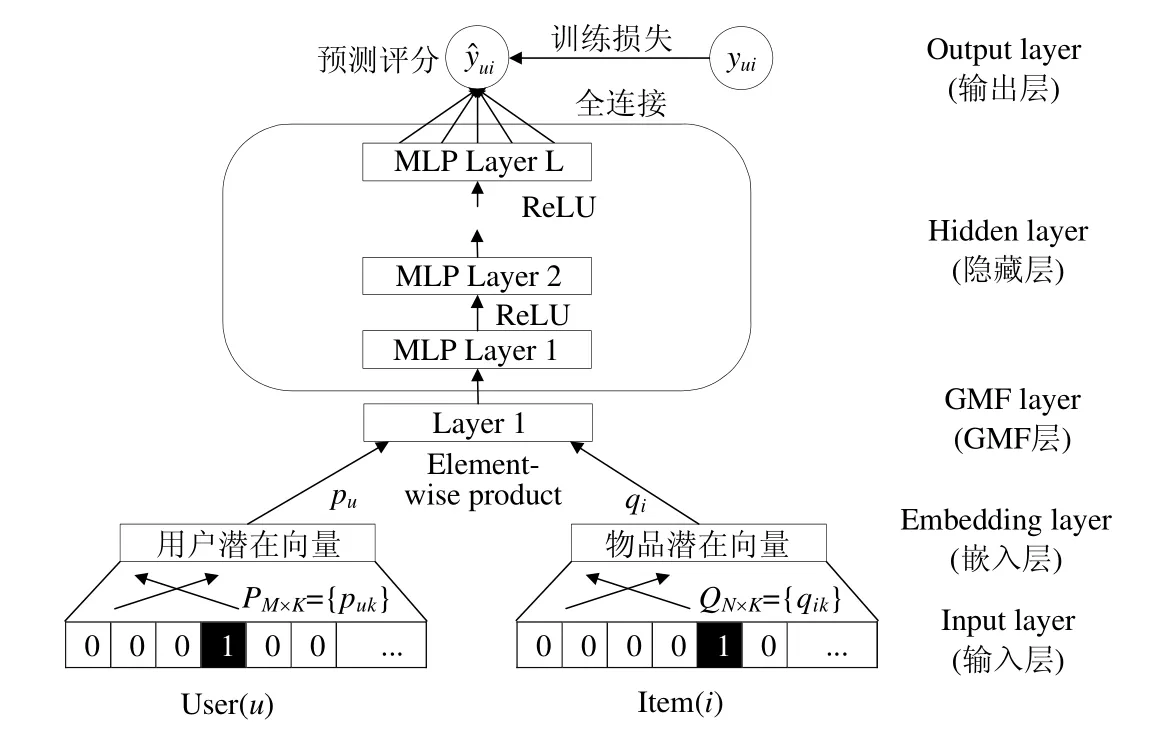
Fig.1 Deep matrix factorization model图1 深度矩阵分解模型
该框架主要由为5 个部分组成:Input Layer(输入层),Embedding Layer(嵌入层),GMF Layer(GMF 层),Hidden Layer(隐藏层)和Output Layer(输出层).输入层获取用户和物品数据;在嵌入层,通过嵌入技术得到用户和物品的潜在特征向量;随后,在GMF 层通过向量间对应元素相乘建模用户和物品的二阶交互关系;再将结果输入到隐藏层中,利用深度神经网络对结果进行迭代训练,从而建模用户和物品之间的高阶交互关系;最后,在输出层得到用户对物品的评分预测.下面分别对模型各个组成模块进行详细阐述.
• Input Layer(输入层)
对于用户(物品)的原始数据,一般通过编码的方式把它转换为数值数据.通常分为两步,即整数编码和one- hot 编码.整数编码会给每一个用户和物品都分配一个整数值,比如用1 表示user1,2 表示user2.但是整数之间自然的排序方式会让模型假设用户(物品)之间也具有某种次序关系,从而可能会影响模型的性能.所以,还需要对整数表示进行one-hot 编码,为每个整数值创建二值表示:除了整数的索引为1 外,其他都是0,即one-hot 编码在任意时候只有一个有效位置.本文将用户编号和物品编号视为两个不同的离散特征进行处理,并且将用户编号和物品编号分开,分别采用one-hot 编码进行编码.所以输入层用户表示为001000…,其中,编码长度为用户数目M;输入层物品表示为01000…,其中,编码长度为物品数目N.
• Embedding Layer(嵌入层)
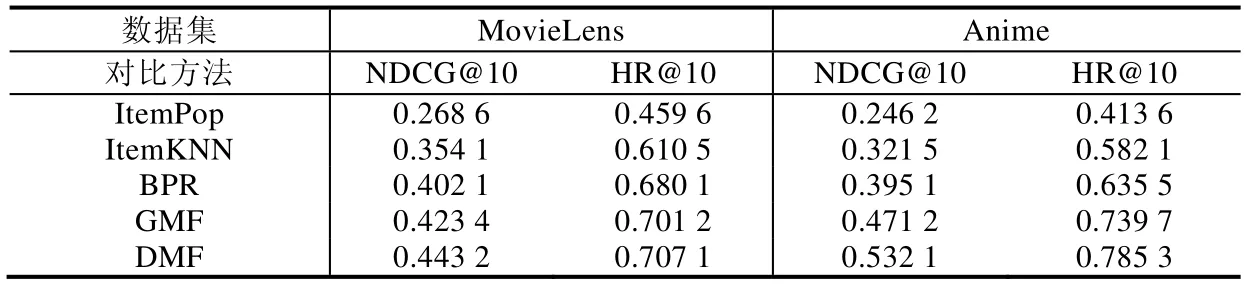
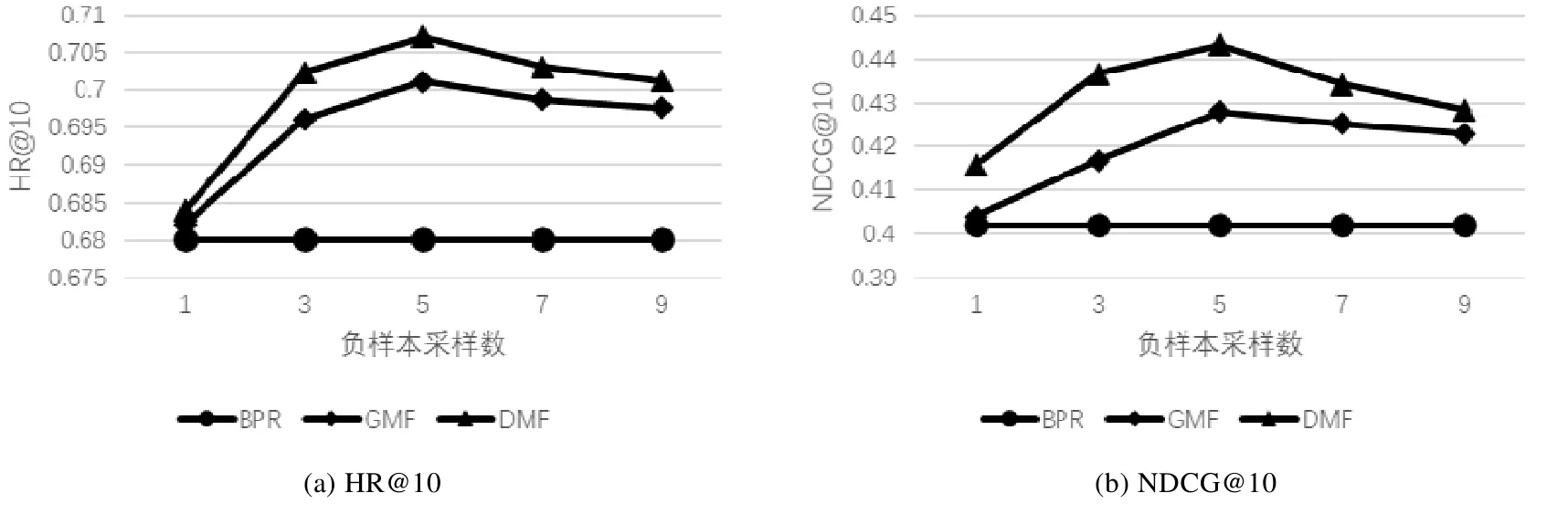
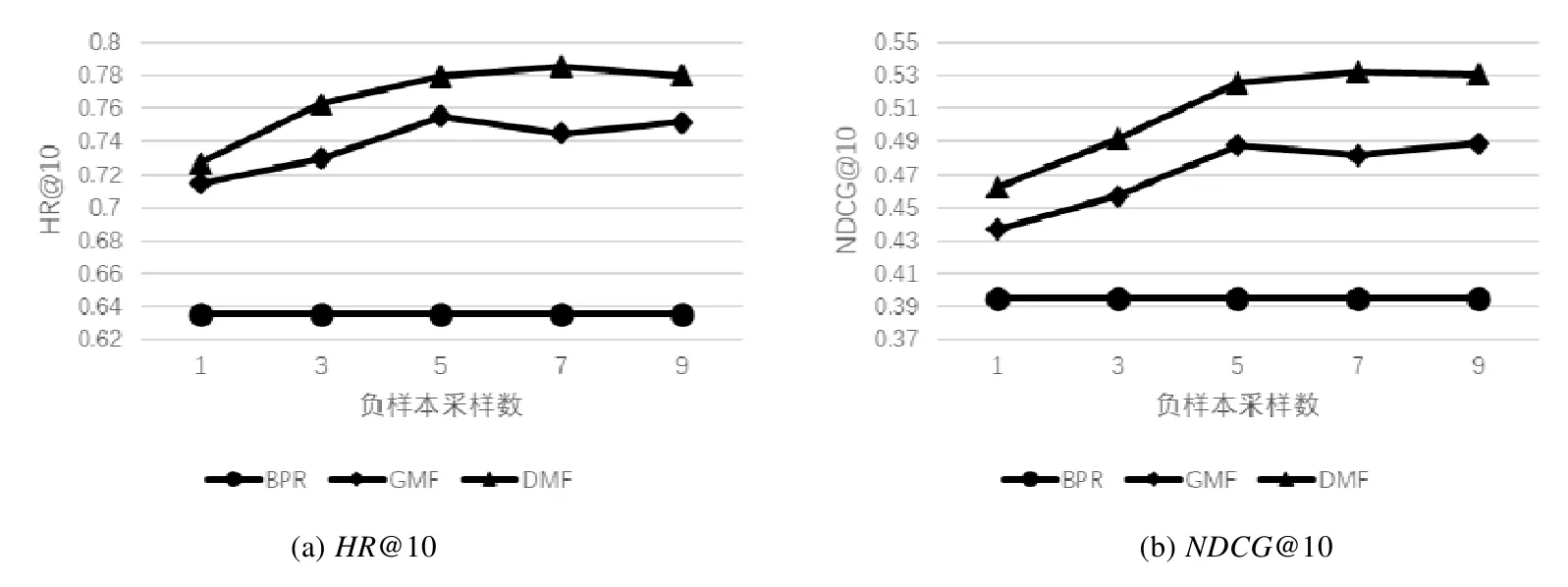
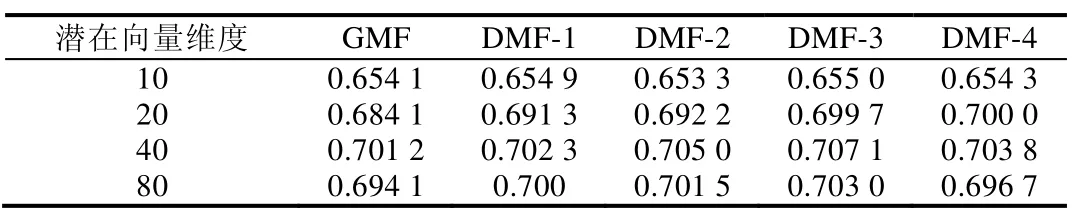
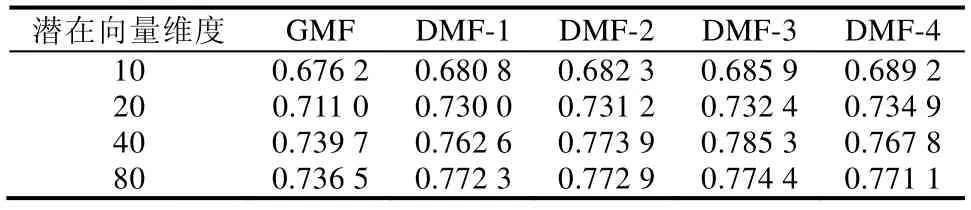
从输入层得到的one-hot 编码是高维稀疏的,会严重影响模型训练效率,所以在嵌入层通过one-hot 编码与潜在特征矩阵相乘将用户(物品)表示映射到低维密致空间,从而得到潜在特征向量.其中,PM×K为用户潜在特征矩阵,M为用户数目,K为潜在特征维度,K< • GMF Layer(GMF 层) 将嵌入层得到的潜在特征向量pu和qi对应元素相乘,得到K维的向量,如公式(1)所示: 虽然通过内积得到用户和物品的二阶交互,但是简单的线性内积不足以建模用户和物品之间复杂的非线性结构,所以再将内积结果输入到一层神经网络中,如公式(2)所示,由此来学习二阶交互的非线性关系,这就是GMF 模型: 其中,a1为激活函数,W1和b1别为连接权值和偏置值. • Hidden Layer(隐藏层) GMF 层在特征向量pu和qi对应元素相乘得到的K维向量之上设置了一层神经网络,通过激活函数和偏置项赋予了模型建模用户和物品之间的非线性交互关系的能力,能够有效地拟合用户和物品的非线性二阶交互信息.但是GMF 是一个浅层模型,尽管能够有效地建模用户和物品交互的低层特征,然而并不能有效地捕捉到包含许多丰富信息更抽象的特征.比如:输入用户对音乐的交互信息,通过一层神经网络训练学习最后捕捉到用户更偏好古典音乐;接着,将获取的结果输入到下一层神经网络进行学习,捕获到用户更倾向于听古典音乐中莫扎特的音乐曲.所以,这里在GMF Layer 的基础上引入更多的隐藏层,通过深层神经网络能够捕捉更抽象特征的特点,来建模用户和物品之间的高阶交互关系.因此,有: 其中,zL-1为第L-1 层网络的输出,a2,aL-1为各个隐藏层的激活函数,和b2,bL-1分别为各个隐藏层的连接 权值和偏置项. • Output Layer(输出层) 得到第L-1 层神经网络的训练结果zL-1后,再将其输入到一个全连接的隐藏层,最终得到用户对于物品的预测评分.如公式(4)所示: 本节主要工作是在两个真实世界数据集MovieLens 和Anime 上训练模型,利用NDCG 和HR 两个性能指标,通过与对比方法性能指标的对比分析来验证模型的可行性和有效性.主要围绕一下4 个方面来进行分析. 1) 深度矩阵分解模型推荐性能表现; 2) 深度矩阵分解模型中潜在向量维度对模型性能影响; 3) 训练集中负样本采样数对模型性能影响; 4) 隐藏层层数对模型性能影响. 3.1.1 数据集 本文主要在两个公开数据集MovieLens[17]和Anime[18]上对模型的推荐性能进行分析验证.具体数据集特征见表2. • MovieLens 数据集是广泛应用于推荐系统的电影数据集,主要由电影评分数据、用户人口统计学数据以及电影属性数据,含有多个不同数据大小的版本.这里,我们使用 MovieLens 1M 数据集,记为MovieLens.MovieLens 1M 数据集含有来自6 000 名用户对4000 部电影的100 万条评分数据,分值范围为1~5; • Anime 是一个公开的推荐数据集,包含73 516 名用户对12 294 部动漫的7 813 738 条评分数据.该数据集包含3 个分类:用户id、动漫id 和用户对动漫的评分,其中,评分范围为1~10.为了缓解数据集稀疏问题,对数据集进行过滤处理,过滤后的数据集包含8 289 个用户对6 335 部动漫的2 964 160 个评分. 这里,我们采用隐式反馈的数据,所以需要把显式评分数据转化为隐式数据.即:对于MovieLens 数据来说,将评分矩阵中有评分记录的1~5 的值记为1,没有评分记录的记为0.同时选取每个用户最近一次的交互记录作为测试样本,并和随机抽样的99 个未交互的样本组合成测试数据集,其余的数据作为训练样本组成训练集.对Anime 数据集做同样处理. Table 2 Dataset description表2 数据集描述 3.1.2 评估指标 由于为每个用户预测其对所有未产生交互的物品的偏好过于耗费时间,所以这里遵循一般的策略[2,19].通过第3.1.1 节中描述的采样方式,为每个用户采集1 个正样本和99 个负样本组成的测试集,并为用户预测其对这100 个物品的偏好,并按照预测值从大到小排序,生成Top-10 的排名列表. 推荐性能由命中率HR(hit ratio)与NDCG(normalized discounted cumulative gain)[20]来衡量. • HR 直观地评估测试物品是否在Top-10 列表中:若存在于Top-10 列表中,则为1;否则为0.对所有的用户求平均,则命中率代表了命中用户偏好的概率.计算公式如公式(5)所示: 其中,K表示排名列表长度,分子为生成的排名列表中包含测试正样本的用户数,分母为用户的总数. • NDCG 用来衡量测试样本命中的位置,该值越大,则说明测试物品出现在排名列表中更靠前的位置.为每个用户计算该指标值,并且求取平均.计算公式如公式(6)所示: 其中,K表示排名列表的长度,N为用户总数.i为排名列表中测试正样本命中的位置,i∈[1,K].可以看出:测试正样本在排名列表中的位置越靠前,即i越小,该值越大. 3.1.3 对比方法及参数设置 我们将DMF 模型与以下4 个基准方法进行分析对比,从而验证模型的有效性. • ItemPop 是一种非个性化推荐方法[21],它将物品与用户交互次数作为物品的流行度,按照物品的流行度产生物品排名列表,并将排名列表中的前N项推荐给用户; • ItemKNN 是一种协同过滤推荐方法[22],它根据用户与物品的交互记录计算物品间的相似度,再结合待推荐物品与用户已有评分交互的邻居物品来预测用户对待推荐物品的预测偏好; • BPR-MF[4]是一种具有代表性的基于成对学习的MF 模型,损失函数关注的是成对排序损失,即最大化正样本与负样本之间的排序[4,23],而不是减少预测值与真实值之间的误差,正负采样率控制为1:1; • GMF 是一种改进后的矩阵分解算法[1],通过激活函数和权值不全为1 的连接权重泛化了矩阵分解模型,使得模型能够建模用户和物品之间非线性二阶交互. 以上方法模型和所提出的方法模型DMF 都基于Tensorflow 实现.对于基于神经网络的模型,通过均值为0、方差0.01 的截断的正态分布来初始化模型参数,并通过交叉熵损失函数和Adam 梯度下降算法来优化模型.模型批次大小为256,初始学习率为0.001,隐藏层的激活函数设置为ReLU,输出层的激活函数设置为Sigmoid. 我们从以下4 个方面进行性能评价和比较分析. • Result 1:模型HR@10 和NDCG@10 性能指标比较 为了回答问题1,我们比较了提出的DMF 模型和ItemPop,ItemKNN,BPR,GMF 这4 个基准方法的性能.分别在MovieLens 和Anime 两个数据集上训练了这5 个模型,表3 显示了这5 个模型在每个数据集中HR@10 和NDCG@10 的表现情况. Table 3 Performance comparison of deep matrix factorization andbaselines表3 深度矩阵分解与基准方法性能对比 通过表3 不难看出:在两个数据集上,HR@10 和NDCG@10 指标都是DMF>>GMF>>BPR>>ItemKNN>>ItemPop.我们提出的DMF 模型在两个数据集上的性能表现都优于基准方法模型. • 相比较于GMF 模型,其在Anime 数据集上的HR@10 和NDCG@10 指标分别提升了0.045 6 和0.060 9;而在MovieLens 数据集上,两个指标分别提升了0.005 9 和0.019 8; • 相比较于ItemPop 方法,DMF 在MovieLens 数据集上两个指标分别提升了0.247 5 和0.174 6;而在Anime 数据集上,HR@10 和NDCG@10 指标分别提升了0.371 7 和0.285 9. 在这些模型中,ItemPop 表现最差.这可能是由于ItemPop 是根据物品在所有用户中受欢迎程度来推荐的,不能满足用户的个性化需求,无法提供个性化推荐.这表明,非个性化的推荐方法不能有效地用来预测用户偏好.ItemKNN 方法基于用户和物品的历史交互矩阵来计算物品相似度进行物品推荐,虽然能一定程度上满足用户个性化需求;但是由于交互矩阵的稀疏性问题,导致物品相似度的计算偏差大,所以整体影响了最终模型的推荐性能,因此推荐性能虽然相对于ItemPop 方法有了很大提升,但是性能还是低于BPR,GMF 和DMF.同时,DMF和GMF 推荐性能强于BPR,这可能是因为DMF 和GMF 有着更灵活的正负采样率,对于每个正训练样本采样更多的合适负样本,更准确建模现实世界用户和物品交互的场景.同时,结果表明:相比较于BPR 中采用简单线性内积建模用户和物品之间的交互,采用神经网络赋予模型非线性的学习能力的DMF 和GMF 具有更突出的表达能力.而DMF 的HR@10 和NDCG@10 指标在两个数据集上表现都优于GMF,这可能是因为添加的隐藏层将在GMF 得到的二阶交互映射到更深层次的抽象空间中,从而学习到用户和物品间更高阶交互关系.这表明:通过添加隐藏层,利用深层神经网络学习高阶抽象特征的特点,使得模型能够建模用户和物品之间的高阶非线性交互关系,由此模型具有更突出的表达能力. • Result 2:潜在向量维度影响 为了回答问题2 潜在向量维度对模型性能的影响,我们比较了潜在向量维度为10,20,40 和80 下,ItemKNN,BPR,GMF 和DMF 这4 个模型在MovieLens 和Anime 两个数据集上的性能表现,如图2 和图3 所示.由于ItemPop方法性能相对于其他方法表现差距较大,这里不予以比较. 由图2 和图3 首先可以看到:随着潜在维度的不断增加,4 个模型的HR@10 和NDCG@10 指标不断提升,模型的推荐性能不断改善.这是因为在到达最佳潜在向量维度之前,随着维度的增加,潜在向量可以包含更多的信息量,对于用户和物品特征描述更加全面具体,能够更有效地建模用户和物品的潜在特征,所以模型具有更突出的表现能力,推荐性能得到显著改善.但是维度并不是越大越好,因为当潜在向量维度过大时,会导致模型过拟合,这也是为什么当在MovieLens 数据集上,潜在向量维度达到40 后,HR@10 和NDCG@10 指标开始下降;同样地,在Anime 数据集上,潜在向量维度达到40 后,HR@10 和NDCG@10 指标也开始下降.同时,我们从图2和图3 可以得出结论,DMF 模型在MovieLens 和Anime 数据集上最佳潜在向量维度都为40.其次,可以看到:在MovieLens 和Anime 两个数据集中,DMF 模型在不同维度下,HR@10 和NDCG@10 指标都明显高于其他3 个模型.而在图3 中,甚至在潜在维度为10,DMF 模型性能最差的时候,其HR@10 和NDCG@10 指标仍然高于BPR模型,这表明我们提出的DMF 模型的有效性. Fig.2 HR@10 and NDCG@10 of models with different potential vector dimension in MovieLens图2 MovieLens 数据集下不同潜在向量维度模型的HR@10 和NDCG@10 Fig.3 HR@10 and NDCG@10 of models with different potential vector dimension in Anime图3 Anime 数据集下不同潜在向量维度模型的HR@10 和NDCG@10 • Result 3:负样本采样数影响 BPR 损失函数关注的是成对排序损失,即最大化正样本与负样本之间的排序.构造训练集时,正负样本采样率固定为1:1 来采集数据样本.而DMF 和MLP 采用Log Loss,其关注重点为逐点损失,一般通过最小化预测值ˆy和目标值y之间的平方误差来更新参数,具有灵活的负样本采样特点.为了探究负样本采样数对模型推荐性能的影响,我们在负样本采样数为1,3,5,7 和9 的情况下,分别将BPR,GMF 和DMF 这3 个模型在MovieLens 和Anime 两个数据集上进行了训练,得到了模型的HR@10 和NDCG@10 指标表现情况,结果如图4 和图5 所示. Fig.4 HR@10 and NDCG@10 of models with different number of negative samples collected in MovieLens图4 MovieLens 数据集下不同负样本采集数模型的HR@10 和NDCG@10 Fig.5 HR@10 and NDCG@10 of models with different number of negative samples collected in Anime图5 Anime 数据集下不同负样本采集数模型的HR@10 和NDCG@10 首先,由图4 和图5 不难看出:拥有更灵活负样本采样的DMF 和GMF 模型相比较于BPR 模型来说,在两个数据集上具有更好的表现;同时,随着负样本采样数的增加,DMF 模型的HR@10 和NDCG@10 指标在逐步增加.这表明,灵活的采样使得模型具有更突出的表达能力.这是因为:通过向训练集中添加负样本,使得训练集更符合真实世界用户和物品交互的稀疏场景;此外,通过采集负样本,使得在训练模型过程中更新参数时只更新部分参数,其他参数全部固定,从而减少整个训练过程计算量,并加速了模型的收敛过程.其次还可以看出:当负样本采样数达到某个值之后,随着采样数的增加,模型的推荐性能反而下降了.这是因为负样本采样数过大,导致训练数据集出现正负样本不均衡,从而影响了模型的表现能力.例如:一个训练集中正负样本比为1:99,如果模型的预测结果全都是负样本,那么模型的准确率就能够达到99%;同时,损失值会非常小,但是这样的模型是没有实际意义的,模型的推荐效果是很差的.所以,适当地控制负样本的采样数,能够提升模型的推荐性能.对于DMF 模型来说,在MovieLens 数据集上的最优负样本采样数是5,在Anime 数据集上的最优负样本采样数是7. • Result 4:隐藏层数量影响 通过前面的实验与分析,我们不难得出结论:通过向GMF 模型添加隐藏层,能够建模用户和物品之间更高阶的交互关系,采用更深层次的神经网络来学习更抽象的用户和物品特征,使得模型具有更好的表达能力.为了探究隐藏层层数对模型推荐性能影响,我们分别设置了隐藏层层数为0,4 的对照模型,其中,层数为0 的模型也就是GMF 模型,层数为1 的模型记为DMF-1,以此类推,并在潜在向量维度为10,20,40 和80 情况下,分别利用MovieLens 和Anime 两个数据集训练各个模型,得到最终5 个对照模型在不同维度下的HR@10 和NDCG@10指标的表现,结果见表4~表7. Table 4 HR@10 of models with different layers in MovieLens表4 MovieLens 数据集下不同层数的模型的HR@10 Table 5 NDCG@10 of models with different layers in MovieLens表5 MovieLens 数据集下不同层数的模型的NDCG@10 Table 6 HR@10 of models with different layers in Anime表6 Anime 数据集下不同层数的模型的HR@10 Table 7 NDCG@10 of models with different layers in MovieLens表7 Anime 数据集下不同层数的模型的NDCG@10 由表4 和表5 可以看出:在不同潜在向量维度下,随着隐藏层层数从0 开始不断增加,模型的HR@10 和NDCG@10 指标不断提升,模型性能得到明显改善.这是因为单层隐藏层能够将输入数据映射到另一个抽象空间,学习更抽象的特征;而通过增加隐藏层层数,能够学习更丰富更抽象的信息,从而更好地建模用户和物品之间的交互.此外,通过引入隐藏层,利用神经网络模型赋予学习非线性的能力,使得模型具有更突出的表达能力.这表明:通过添加单层隐藏层,利用神经网络建模用户和物品之间复杂的非线性交互,能够提升模型推荐性能.而通过添加更多的隐藏层,利用更深层的神经网络能够学习用户和物品之间更高阶的交互关系,从而进一步提升模型推荐性能.但是,随着隐藏层层数进一步增加,模型HR@10 和NDCG@10 指标提升幅度减小,甚至在潜在向量维度为10,40 和80 的时候,隐藏层层数从3 改为4 后,模型在MovieLens 数据集上,HR@10 指标出现了下降的情况;同样,在潜在向量维度为40 和80 时,隐藏层层数由3 变为4 后,模型在Anime 数据集上,HR@10 指标也出现了下降.这表明对于模型来说,并不是隐藏层层数越多、神经网络越深,模型推荐性能越好.这是因为隐藏层层数过多,会导致模型出现过拟合问题,这样不仅不会提升模型性能,反而会限制模型推荐性能.同时,由于神经网络中过多的隐藏层会使得模型参数指数式增长,增加训练难度导致模型难以收敛. 因此,隐藏层层数的增加使得模型获得更深层神经网络,能够建模用户和物品之间高阶非线性交互关系,但是并不是越多越好,隐藏层层数过多反而会影响模型性能.这里,我们所提出的模型最优隐藏层层数为3.此外,通过表4~表7 进一步表明,DMF 在MovieLens 和Anime 两个数据集上的最优潜在向量维度为40. 在众多的协同过滤推荐算法中,矩阵分解由于简单、易于实现的特点,获得了广泛的应用.矩阵分解算法利用潜在的特征因子把评分矩阵分解为user-factor matrix 和item-factor matrix,将用户和物品用潜在因子向量表示,并且通过向量之间的内积来建模用户与物品间的交互关系.但是这种简单的内积不足以建模用户和物品间的非线性关系.由于神经网络的非线性建模能力,一些工作尝试将矩阵分解和神经网络结合进行推荐任务,虽然推荐性能有一定提升,但是涉及到矩阵分解的关键,即建模用户和物品的交互函数时,仍然采用简单的内积来建模用户和物品之间的线性关系. GMF 模型中利用神经结构代替矩阵分解中所用的内积,来从数据中学习得到用户和物品的交互函数.通过神经网络结构为内积引入非线性成分,从而提高模型的表达能力.但是GMF 模型得到的仅仅是用户和物品交互的二阶关系,忽略了可能包含更丰富交互信息的高阶交互.基于此,我们提出了深度矩阵分解模型DMF,通过在GMF 之上引入隐藏层,利用更深层的神经网络在非线性内积所得到的用户与物品间的二阶交互的基础之上,建模用户与物品间的非线性高阶交互,为模型引入用户与物品间的非线性高阶交互信息,从而辅助模型更准确、全面的建模用户和物品间的交互.同时,我们在两组真实世界的数据集上进行了大量的实验,证实了模型的可行性和有效性.本文只考虑了用户和物品的交互信息,没有考虑可能包含更多可以用来建模用户和物品特征的丰富知识的辅助信息,例如用户年龄、性别、工作和物品类别等,这可能是未来的工作方向.同时,不同种类信息对于推荐结果的贡献程度也是不一样的,如何合理地为不同信息赋予权重,也是值得关注的的问题.


3 实验结果与分析
3.1 实验设置



3.2 性能比较和分析



4 总 结
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·初中天地(2021年11期)2021-02-16
电子制作(2019年19期)2019-11-23
少年漫画(艺术创想)(2019年2期)2019-06-06
电子制作(2019年24期)2019-02-23
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
