
基于下推自动机的细粒度锁自动重构方法*
2021-02-25 12:15张冬雯
软件学报 2021年12期
张 杨,邵 帅,张冬雯
(河北科技大学 信息科学与工程学院,河北 石家庄 050018)
锁是并发程序中用于保护程序状态和数据访问正确性的必备措施,然而锁竞争问题是目前多核/众核时代影响并发程序性能的主要问题之一.锁竞争是指当临界区被一个互斥锁保护时,如果一个线程获得了该锁,那么其他请求访问该临界区的线程都将被阻塞,直到持有该锁的线程释放该锁.锁竞争问题的存在,会严重降低程序并行度,损害程序的可伸缩性,降低多核/众核处理器的执行效率.
不恰当的并发控制方式通常会进一步加剧锁竞争,程序开发人员有时习惯于使用粗粒度锁,例如在方法的修饰符中加入synchronized 关键字,使整个方法处于锁的保护之中.这种加锁方式虽然可以降低程序开发的复杂性,然而由于粗粒度锁控制的临界区代码较长,导致其他想获取该锁的线程等待时间增加,往往会加剧锁竞争.许多开发人员尝试使用细粒度锁,相比于粗粒度锁,细粒度锁只对一小部分代码进行加锁,可以有效减少锁的持有时间和线程等待时间,减少锁竞争问题的影响.
与粗粒度锁比较,使用细粒度锁并非一件容易的事.要想实现细粒度的加锁方式,通常可以采用升级锁、降级锁、优化读锁等加锁方式,也可以采用将粗粒度读写锁分解为细粒度读写锁的方式.程序开发人员不仅需要对代码模式进行分析以确定使用何种细粒度锁的加锁方式,而且还需要在同一种方式的不同实现机制之间进行选择,例如在JDK 中,读写锁和邮戳锁分别提供了降级锁,这两种锁提供的降级锁的实现方法截然不同,程序开发人员需要在两种锁机制之间进行选择,增加了细粒度锁的使用难度.在传统的方法中,为了使用细粒度锁,开发人员通常需要手工地对并发程序中使用粗粒度锁的代码进行重构.然而这种重构方式既费时费力,还可能会给代码引入新的错误,因此迫切需要对面向细粒度锁的重构方法进行研究.
目前,针对锁重构的研究有很多:Tao 等人[1]提出了针对Java 程序根据类属性域划分锁保护域的自动锁分解重构方法;Yu 等人[2]在进行优化同步瓶颈的研究中提出了一种锁分解方式;Emmi 等人[3]提出了一种自动锁分配技术,推断获取锁的位置并确保加锁的正确性,避免发生死锁;Kawachiya 等人[4]提出一种锁保留算法,该算法允许锁被线程保留;Schafer 等人[5]针对重入锁及读写锁提出了一种自动重构算法,并实现了重构工具Relocker; Zhang 等人提出了面向可定制锁[6]和邮戳锁[7]的自动重构方法;Arbel 等人[8]提出了并发数据结构的代码转换,他们的转换采用基于锁的代码,并用乐观同步替换其中的一些加锁代码以减少争用;Bavarsad[9]针对软件事务性内存,提出了一种读写锁分配技术来克服全局时钟的开销.在工业界,集成在IntelliJ IDEA 上的重构插件LockSmith[10]和基于Eclipse JDT 的并发重构插件[11]都可以实现锁重构.从目前国内外的研究现状来看,许多学者已经认识到锁竞争问题以及并发控制方式在程序设计中的重要性,并对锁粒度问题以及锁机制相关的问题进行了研究.但大部分研究是对锁进行消除和对同步锁进行分解,对细粒度锁的重构方法还有待深入研究.
要想实现面向细粒度锁的自动重构,需要解决以下几个问题:(1) 代码分析时需要对临界区中的每一条语句进行读写操作分析,而不能像Relocker[5]工具那样将整个临界区代码作为一个整体进行分析;(2) 在获取读写模式分析后,需要研究如何对读写操作模式进行识别,进而推断出使用哪一种细粒度锁;(3) 需要研究如何构建由粗粒度锁到细粒度锁的重构代码.
为了解决上述问题,本文提出基于下推自动机的细粒度锁自动重构方法,通过访问者模式分析、别名分析、锁集分析、负面效应分析等程序分析方法获取临界区代码的读写模式,然后使用下推自动机构建不同锁模式的识别方法,根据识别结果进行代码重构.基于此方法,在Eclipse JDT 框架下,以插件的形式实现了一个自动重构工具FLock.在实验中,从重构个数、改变的代码行数、重构时间、准确性和重构后程序性能等方面对FLock进行了评估,并与已有重构工具Relocker[5]和CLOCK[7]进行了对比,对HSQLDB,Jenkins 和Cassandra 等11 个大型实际应用程序的重构结果表明:FLock 共重构了1 757 个内置监视器对象,每个程序重构平均用时17.5s.该重构工具可以有效实现粗粒度锁到细粒度锁的转换,与手动重构相比,有效提升了细粒度锁的重构效率.
本文的主要贡献有3 个方面.
1) 提出了一种面向细粒度锁的自动重构方法;
2) 以Eclipse 插件的形式实现了自动重构工具FLock,可以实现源码级别的重构,帮助开发者完成从粗粒度锁到细粒度读写锁的自动转换;
3) 使用11 个大型实际应用程序对FLock 进行了评估,并与现有工具Relocker 和CLOCK 进行了对比.
本文第1 节介绍本文的研究动机.第2 节介绍面向细粒度锁的自动重构方法.第3 节展示自动重构工具FLock 的使用界面.在第4 节给出对本文所提出的方法和工具的实验评估.第5 节对相关工作进行介绍.第6 节是本文的总结.
1 研究动机
读写锁是JDK 1.5 版本中引入的一种锁机制,它包含一对相互关联的锁:读锁和写锁.写锁是一个排它锁,只能由一个线程持有;读锁是一个共享锁,在没有线程持有写锁的情况下,读锁可以由多个线程同时持有,读锁允许在访问共享数据时有更大的并发性.Pinto 等人[12]通过研究SourceForge 上的2 227 个含有并发结构的Java工程发现:Java 并发包还没有得到良好的应用,只有大约23%有并发编程结构的Java 工程在使用.
为了说明细粒度锁重构的必要性,我们在代码结构上进行了说明.图1 展示了processCached(·)方法的3 种实现方式,该程序段选自读写锁的Java API 文档[13],是一种典型的缓存处理操作.方法processCached(·)模拟了对数据库及缓存的操作,首先判断数据是否存在于缓存中:如果存在,则直接从缓存中读取数据;如果不存在,则从数据库中把数据写入缓存.在图1(a)中,该方法使用synchronized 进行同步控制,整个方法都处于该锁的保护下,是一种粗粒度的保护.图1(b)为使用Relocker[5]进行重构后的代码,由于该方法中包含对缓存的写入操作,按照Relocker 的锁推断策略,将使用写锁对其进行重构.然而我们发现:写操作的执行仅仅发生在if 语句的条件成立时,如果条件不成立,写锁根本不会执行,只需要执行读操作.如果把全部代码使用写锁进行保护,可能会降低程序的性能.如果使用读锁,将允许多个线程同时读,可以提高程序的并发性.图1(c)为改进后的代码,是一种细粒度的加锁方式.该方式首先获取读锁并判断cacheValid(第3 行、第4 行):如果if 条件不成立,则直接读取并释放读锁(第16 行~第20 行);如果成立,则释放读锁获得写锁(第5 行、第6 行).为了保证程序状态的一致性,这里需要重新对状态进行判断(第8 行),因为其他线程可能已经对缓存进行了修改.当从数据库中写入缓存之后,获得读锁再释放写锁,完成锁降级操作(第9 行~第14 行).从图1(c)可以看到:该方式将一直使用读锁,直到写入的时候再加写锁.
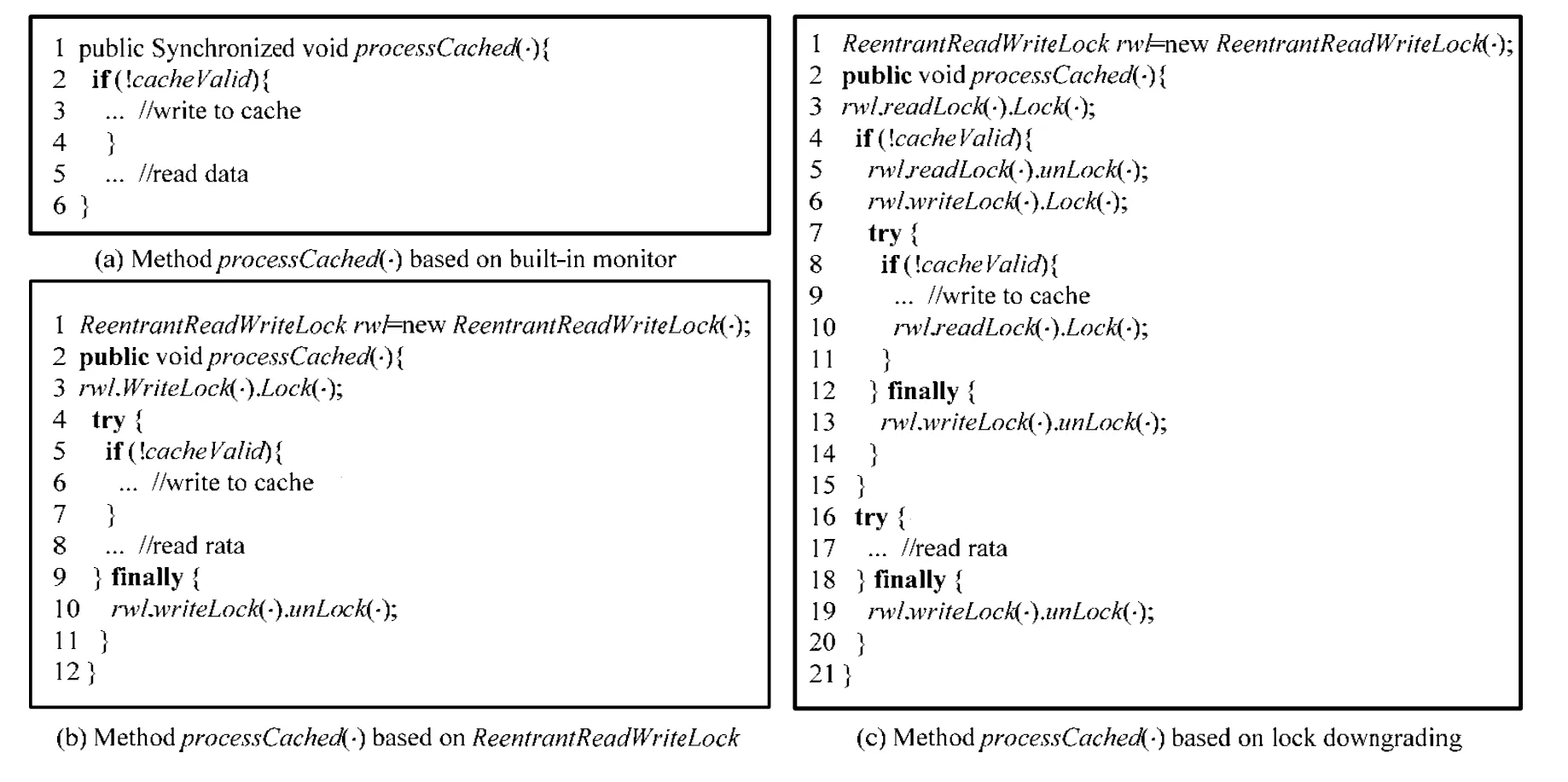
Fig.1 Three implementations of the method processCached(·)图1 processCached(·)方法的3 种实现方式
从上面的例子可以看出:使用锁降级实现了对临界区的细粒度保护,加锁方式更为合理,并且可以在一定程度上减少了锁竞争.由于读锁是共享锁,允许多个线程同时访问,在不发生写入时可以增加程序的并发性.
2 面向细粒度读写锁的重构
本节首先给出了重构的整体框架,之后对程序分析方法、基于下推自动机的锁模式推断以及重构算法进行了介绍.
2.1 重构框架
在重构过程中,首先通过访问者模式对源码对应的抽象语法树进行遍历,主要用到的程序静态分析方法包括锁集分析、别名分析和负面效应分析:锁集分析用来对监视器对象进行收集,并存储监视器对象和锁对象的对应关系;别名分析用来解决锁集中的别名问题;负面效应分析用来分析临界区是否产生负面效应,并生成对应的临界区读写模式序列.下推自动机对临界区读写模式序列进行识别,进而进行锁推断,在读锁、写锁、锁降级、锁分解这4 种加锁模式中选择相应的加锁模式并进行重构.在重构之后,需要对重构前后的一致性进行检测,以保证重构的正确性.面向细粒度锁的重构框架如图2 所示.
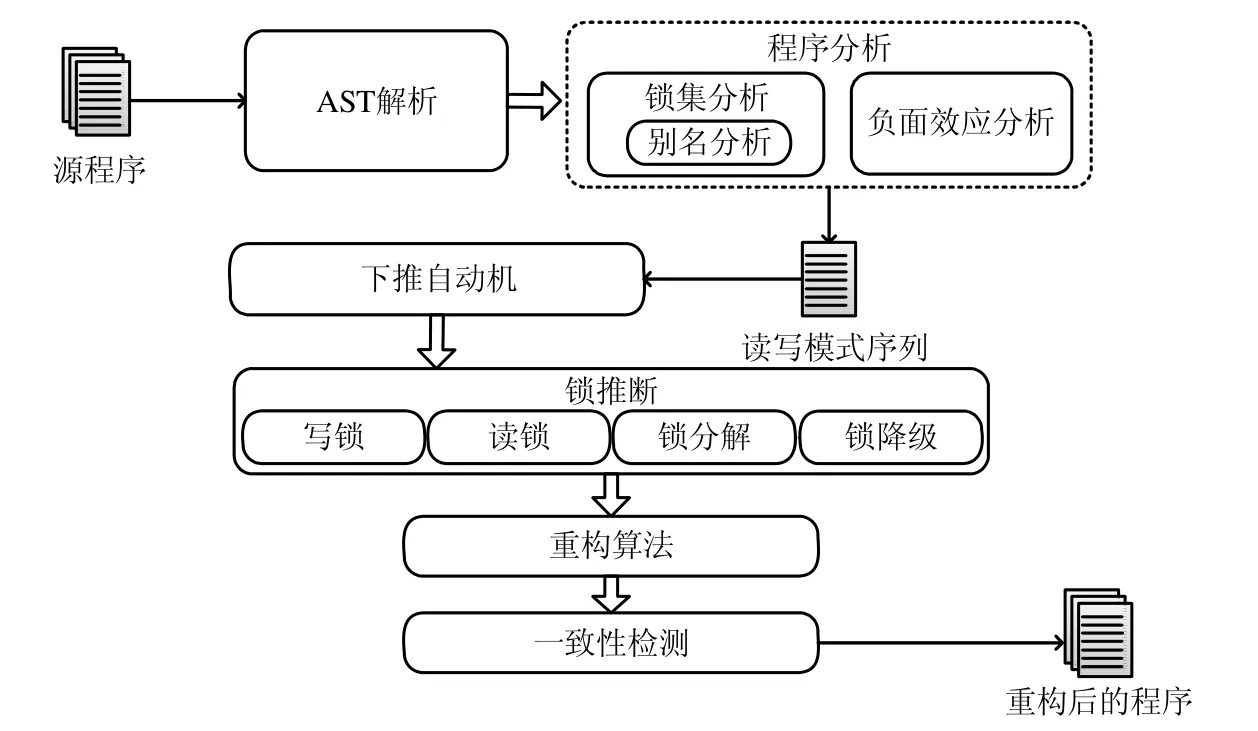
Fig.2 Refactoring framework图2 重构框架图
2.2 AST解析
在重构框架中,首先对源程序进行解析,生成一个抽象语法树(abstract syntax tree,简称AST).在具体的解析过程中,首先通过Eclipse JDT[14]获取用户在进行重构操作时所选择的对象,然后将用户选择的对象存放到ICompilationUnit 对象中,最后将ICompilationUnit 对象对应的元素解析成AST.AST 节点的类型很多,每个节点表示一个源程序中的一个语法结构,包括类型、表达式、语句、声明等.使用访问者模式分析对AST 上的同步方法节点以及同步块语句进行遍历,找到同步方法和同步块.在具体的实现过程中,通过继承EclipseJDT 中提供的抽象类ASTVisitor 实现了一个子类作为具体访问者,用于具体类型节点的遍历.
2.3 程序分析方法
2.3.1 锁集分析
在进行重构之前,首先通过访问者模式遍历程序中所有的方法,并对监视器对象进行收集.在重构过程中,还需要对监视器对象是否产生别名进行判断,进行别名分析.别名是指监视器对象名称不同,但是同时指向相同的内存地址.对于监视器对象不同的临界区,需要使用不同的锁对象进行重构;对监视器对象相同的临界区,则使用相同的锁对象进行重构.使用一个键-值对集合对监视器对象和读写锁锁对象的映射关系进行存储,监视器对象作为键-值对集合的键,监视器对象对应的读写锁对象为键-值对集合的值.
监视器集合定义为MonitorSet={m1,m2,…,mn},其中,mi为监视器对象,i∈{1,2,…,n}.监视器mi的指向集定义为PoniterSeti,如果对于任意的mi和mj,i≠j,存在PoniterSeti∩PoniterSetj≠∅,则认为mi和mj互为别名,并把mi和mj作为别名对〈mi,mj〉存储在可能别名集AliasSet中.在进行重构之前,首先通过别名集AliasSet构建锁集LockSet,对别名对中的监视器对象对应的锁对象进行实例化,并存入锁集LockSet中.别名对中两个监视器对象应对应相同的锁对象,例如别名对〈mi,mj〉在LockSet中表示为两个键值对组合〈mi:lockk〉,〈mj:lockk〉,其中,lockk为锁对象;而没有产生别名问题的监视器对象在重构过程中对锁对象进行实例化,并存入锁集LockSet中.
2.3.2 负面效应分析
负面效应是指对非本地环境的修改[15],例如一个操作、方法或表达式在执行过程中修改了内存单元,则程序将产生负面效应.由于本文提出的重构方法不仅要重构读锁和写锁,而且还要进行细粒度的锁重构,因此负面效应分析需要对整个临界区进行分析,并生成一个临界区读写模式序列来表示临界区的读写操作.在生成临界区对应的读写模式序列时,使用字符r表示临界区的一个读操作,使用字符w表示一个写操作,使用字符c表示一个if 条件判断语句的开始且条件判断为读操作,使用字符e表示一个if 判断语句的结束.
本文的负面效应分析通过WALA[16]的中间表示IR 对方法中的指令进行遍历分析,判断指令是否修改内存单元.在对方法调用指令进行分析时,为了保证重构工具的执行效率,将方法调用进入的层数限制为5 层.具体分析算法如算法1 所示.
1) 首先获得临界区所对应的指令集,调用sideEffectAnalysis方法对每一条指令进行遍历分析(第1 行~第4 行);
2) 在sideEffectAnalysis方法中,首先对方法调用进入的层数限制进行判断(第6 行),如果大于限制层数5层,为了保证临界区安全,将其认定为一个写操作,返回字符w(第23 行);
3) 之后,对每条指令进行分析,如果指令修改了静态字段,或修改了实例字段,或修改了堆内存,则当前指令产生了负面效应,返回字符w(第7 行、第8 行);
4) 如果指令是方法调用指令,首先对调用层数的计数器加1(第11 行),之后,递归调用sideEffectAnalysis方法对被调用方法里的指令进行分析:若被调用方法包含写指令,则当前方法调用指令产生了负面效应,返回字符w(第11 行~第15 行);如果当前被调用方法没有产生负面效应,则返回字符r(第16 行);
5) 如果是if 判断语句且判断语句为读操作,返回字符c;如果指令是if 条件判断结束指令,则返回字符e(第17 行~第20 行);
6) 其他指令均返回字符r(第21 行).
算法1.负面效应分析算法.


2.4 锁推断
在负面效应分析中,使用字符c表示一个if 语句的开始,e表示一个if 语句的结束.由于判断语句每一个开始对应着一个结束,负面效应分析会产生类似cnAen(A代表其他操作)的字符序列,其中,n>0.在匹配过程中,需要记录c和e的对应关系,因为n的值是不确定的,导致状态的个数也是不确定的,所以我们使用下推自动机对负面效应分析产生的临界区读写模式序列进行模式匹配,以确定程序重构后的加锁模式.
定义1.用于推断细粒度锁模式的下推自动机Mfg=(Q,Σ,Γ,δ,q0,Z0,F)是一个七元组模型,其中,
•Q={q0,q1,…,q7}是一个有穷状态集;
• Σ={r,w,c,e}是输入字母表,其中,r代表一个读操作,w代表一个写操作,c代表一个if 条件判断语句的开始且条件判断为读操作,e为一个if 条件判断语句的结束标志;
• Γ={Z0,C,R,W,D,A,B,V}是有限的堆栈字母表;
• δ=δ(q,x,X)是转移函数,一般使用规则〈q,x,X,q′,T〉代表转移函数,其中:q为状态符号;x为输入符号;X和T为栈符号,表示当下推自动机处于状态q、当前输入字符为x且栈顶符号为X时,则下推自动机的状态变为q′,并用符号串T代替栈顶符号X.符号串T有3 种形式,分别为X′,X′X,ρ,其中,X′表示用字符X′替换栈顶元素,X′X表示将X′压入栈中,ρ表示弹出当前栈顶元素;
•q0为初始状态;
•Z0为初始栈顶符号;
•F={q1,q3,q4,…,q7}为终态集.
下推自动机Mfg的状态转换图如图3 所示,其中,规则〈q,x,X,q′,T〉在图中表示为〈x,X/T〉,状态q到状态q′的转移用直线箭头表示.
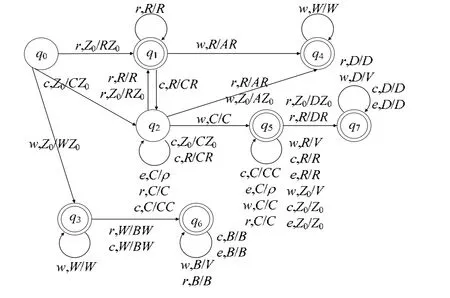
Fig.3 State transition diagram of pushdown automaton Mfg图3 下推自动机Mfg 状态转换图
例如:图3 中,当下推自动机处于状态q0、当前输入字符为r且栈顶符号为Z0时,则下推自动机由状态q0转移到q1,并把字符R压入栈中.
在锁模式定义之前,为了简化表示终态所识别的符号集,首先定义符号串集合Src={r,c}+为字符r和c组成的正闭包,Src={r,e}+为字符r和e组成的正闭包,Swc={r,w,c}+为字符r,w和c组成的正闭包,Swe={r,w,e}+为字符r,w和e组成的正闭包,S={SwcSwe},其中,字符c和字符e数量相等.
定义2(写锁模式的定义).一个临界区被推断为写锁,当且仅当读写模式序列被终态q3所接受.
终态q3所识别的序列为Sw1={w}+,表示临界区只包含写操作,将使用写锁进行同步保护.
定义3(读锁模式的定义).一个临界区被推断为读锁,当且仅当读写模式序列被终态q1所接受.
终态q1所接受的序列集为Sr={SrcSre}+,其中,字符c和字符e的数量相同.序列集Sr不包含字符w,表示临界区没有产生负面效应,所以使用读锁.
定义4(锁降级模式的定义).一个临界区被推断为锁降级,当且仅当读写模式序列被终态q7所接受.
终态q7所接受的序列集为Sd={r*cS+er+},表示临界区首先包含读操作或没有,之后是一个if 判断语句块,其中,判断语句为读操作,语句块内包含其他操作但至少有一个写操作,if 块之后包含至少一个读操作且只包含读操作.
定义5(锁分解模式的定义).一个临界区被推断为锁分解,当且仅当读写模式序列被终态q5,q4,q6所接受.
终态q5识别的序列集为Ss1={r*cS+e},表示临界区首先包含读操作或没有,之后是一个if 判断语句块,判断语句为读操作,语句块内包含其他操作但至少有一个写操作;终态q4和q6识别的序列表示读写操作分离的临界区,终态q4所识别的序列集为Ss2={SrSw1},代表临界区前半部分为读操作后半部分为写操作,终态q6所识别的序列集为Ss3={Sw1Sr},代表临界区前半部分为写操作后半部分为读操作.
定义6(下推自动机停机的定义).当输入读写模式序列为空,或栈顶符号为V时,下推自动机停止对读写模式序列的识别.
当读写模式序列为空时,表示临界区没有操作,则对临界区使用读锁;当栈顶符号为V时,所识别的序列集为Sw2={CS(Sw1∪Sr∪Sd∪Ss1∪Ss2∪Ss3)},表示读写模式序列不符合细粒度锁规则,临界区将使用写锁进行同步保护.
2.5 重构算法
本节给出了重构算法的设计,首先对相关代码建立AST;之后遍历AST 的所有方法节点,找到同步方法和包含同步块的方法节点;最后,根据负面效应分析得到的读写串对应的锁模式进行重构.重构算法如算法2 所示.具体流程如下.
1) 首先获取当前的监视器对象(第1 行),并判断锁集LockSet中是否存在监视器对象所对应的锁对象(第2 行):如果存在,则从锁集LockSet中获得监视器对象对应的锁对象(第3 行);否则生成一个新的锁对象,并把监视器对象与锁对象的对应关系存入锁集LockSet中(第5 行、第6 行);
2) 通过负面效应分析获得c对应的临界区读写模式序列str(第8 行);
3) 如果c为同步方法或同步块,则移除synchronized 锁,并通过下推自动机识别临界区读写模式序列str,根据识别结果进行重构(第9 行~第13 行);
4) 最后对重构前临界区c和重构后的c_r进行一致性检测(第17 行):如果符合一致性检测规则,返回重构结果c_r(第15 行);否则,将使用写锁对临界区c进行重构(第16 行~第19 行),其中,Consistency 方法基于一致性检测规则进行定义(第3 节给出).
算法2.重构算法.
输入:临界区c;
输出:临界区c的重构结果.


3 一致性检测
FlexSync[17]是一个可以通过施加不同标记在不同同步机制之间进行重构转换的工具,FlexSync 中定义了一致性检查规则,以此来检查在不同同步机制之间转换的一致性.为了尽可能地保证重构的正确性,本节参照FlexSync 的一致性检测规则,给出了FLock 重构前后的一致性检测规则.在给出规则之前,我们首先对相关的内容进行了定义.
定义7(临界区集合).一个应用程序P中所有临界区的集合定义为C={c1,c2,…,cn}.对于∀ci∈C(1≤i≤n),ci={ci1,ci2,…,cik}表示ci被划分为k个细粒度的临界区.
由于P中的代码是有限的,因此C是一个有限集合,对于∀ci∈C(1≤i≤n),ci表示某一个临界区.ci中可以包含若干读写操作opi1,opi2,…,opir,表示为{opi1,opi2,…,opir}⊆ci.
Cbefore和Cafter分别表示重构前和重构后的临界区集合,由于FLock 在重构时需要分割临界区,因此|Cbefore|< |Cafter|,其中,|C|表示集合C元素个数.
定义8(重构前锁集合).一个应用程序P中所有用于保护临界区的锁集合定义为集合S={s1,s2,…,sm}.
由于C是有限集合,所以S也是一个有限集合.由于一个锁可以保护多个临界区,故m≤n.对于∀se∈S,se表示既包含加锁操作又包含解锁操作.
定义9(锁保护).对于∀ci∈C(1≤i≤n),∃se∈S(1≤e≤m),如果临界区ci处于锁se的保护中,则定义保护关系为se⊙{ci}.进一步,一个锁可以保护多个临界区,定义为se⊙Ck,其中,Ck是Cbefore的子集,即Ck⊆Cbefore.
定义10(重构后锁集合).一个应用程序P中重构之后所有的锁集合定义为集合L={l1,l2,…,lt}.对于∀la∈L(1≤a≤t),la⊙Cv,Cv是Cafter的子集,即Cv⊆Cafter.
定义11(锁状态原子性保持).对于∀la∈L,如果la在没有释放锁的情况下完成锁状态切换,则说明锁状态原 子性没有被破坏,定义其为▷la,否则定义为.
定义11 说明了锁状态的原子性问题,举例来说:读写锁在由写锁切换为读锁时,可以不用释放该锁,在该锁的内部完成锁状态的切换.
定义 12(重构前后锁的对应关系).重构前,对于∀ck∈C(1≤k≤n),∃se∈S(1≤e≤m),se⊙Ck;重构后,对于∀cv∈C(1≤v≤n),∃la∈L(1≤a≤t),la⊙Cv.如果Cv⊆Ck,则se和la之间存在一一对应关系,记为se≡la.
定义13(Happens-before 关系).对于∀ci∈C,{opi1,opi2,…,opir}⊆ci,∃u,v(1≤u≤r,1≤v≤r),如果opiu先发生于opiv,则定义Happens-before 关系为opiu≥opiv.依据Happens-before 关系的传递性,如果opiu≥opiv并且opiv≥opiw,则opiu≥opiw.
Happens-before 关系的定义是建立在Java 内存模型基础上的读写操作发生序关系,是Java 语言内存一致性的重要准则.该关系建立的方式之一是通过程序中的同步关系,解锁操作之前的操作先发生于解锁之后获取该锁的操作.
基于如上的定义,下面给出了重构的一致性检测规则.
规则1.对于重构前,∀ci∈C(1≤i≤n),∃se∈S(1≤e≤m),使得se{⊙ci};重构后,ci={ci1,ci2,…,cik},对于∀cij(1≤i≤n,1≤j≤k),∃la∈L(1≤a≤t),使得la{⊙cij}.
规则1 说明了重构之前处于锁保护的临界区,在重构之后仍处于锁的保护中.
规则2.对于重构前,∀ci∈C(1≤i≤n),∃se∈S(1≤e≤m),使得se{⊙ci};重构后,ci={ci1,ci2,…,cik},对于∀cij(1≤i≤n,1≤j≤k),∃la∈L(1≤a≤t),如果有la{⊙cij},则se≡la.
规则2 说明:如果重构前临界区ci在se的保护中,即使重构后ci被分割为多个临界区,保护这些临界区的锁la和se之间存在一一对应的关系.如果所有的锁都可以被重构,那么重构前后的锁集合应满足|S|=|L|.需要说明的是:对于FLock 重构前后锁的一一对应关系,通常表现在同步锁的监视器对象和读写锁对象的一一对应关系上.
规则1 和规则2 从重构前后代码结构上进行了一致性说明,保证了代码结构的完整性.
由于FLock 在进行面向细粒度锁重构时主要采用了降级锁和锁分解两种方式,下面主要针对这两种方式进行规则定义.
规则3.重构前,对于∀ci∈C(1≤i≤n),∃se∈S(1≤e≤m),使得se{⊙ci};重构后,ci={ci1,ci2,…,cik},如果∃la∈L(1≤a≤t),使得se≡la,对于∀cij(1≤i≤n,1≤j≤k),有(la{⊙cij})∧()成立,则锁降级重构前后可以保证一致性.
规则3 主要针对降级锁的重构进行了约束.虽然锁降级过程中会由写锁降级为读锁,但该过程是在锁的内部进行转换的,期间并没有释放锁,可以保证锁的原子性,所以锁降级重构前后是一致的.
规则4.重构前,对于∀ci∈C(1≤i≤n),∃se∈S(1≤e≤m),使得se{⊙ci};重构后,ci={ci1,ci2,…,cik},如果∃la∈L(1≤a≤t),使得se≡la,且对于∀cij(1≤i≤n,1≤j≤k),有(la{⊙cij})∧().当{opi1,opi2,…,opir}⊆ci时,对于∀opip,opiq(1≤p≤r,1≤q≤r),如果在Cbefore中opip≥opiq,则在Cafter中仍有opip≥opiq.
规则5.重构前,对于∀ci∈C(1≤i≤n),{opi1,opi2,…,opir}⊆ci,∃se∈S(1≤e≤m),使得se{⊙ci};重构后,ci={ci1,ci2,…,cik},如果∃la∈L(1≤a≤t),有se≡la,且对于∀cix,ciy(1≤i≤n,1≤x≤k,1≤y≤k,x≠y),有(la{⊙cix,ciy})∧().对于 ∀opip,opiq(1≤p≤r,1≤q≤r),如果{opip}⊆cix,{opiq}⊆ciy,opip和opiq访问同一内存位置并且opip或opiq是写操作,则不能进行锁分解.
规则4 和规则5 共同保证了锁分解重构的一致性.规则4 对锁分解的重构进行了约束,该规则通过检查临界区读写语句的Happens-before 关系,确保该关系在重构前后没有改变.在FLock 工具的重构对象中,重构前后代码都涉及同步关系,可以在同步关系的基础上建立Happens-before 关系,进而进行规则判定.规则5 从保持原有临界区的原子性角度对锁分解进行了约束,确保原有临界区的原子性没有被破坏.如果存在opip和opiq访问同一内存位置,有可能因为线程交互而改变原有操作语义,在这种情况下,FLock 只推断一个写锁而不进行锁分解.
4 重构工具实现
FLock 是在Eclipse JDT 框架下设计并以Eclipse 插件的形式实现的,对Eclipse 中的基础类Refactoring 和UserInputWizardPage 等进行扩展,实现相关的重构逻辑设计和可视化的重构工具界面设计.FLock 重构界面截图如图4 所示,展示了重构前后的代码之间的对比,其中,左侧为重构前的代码,右侧为重构后代码的预览.
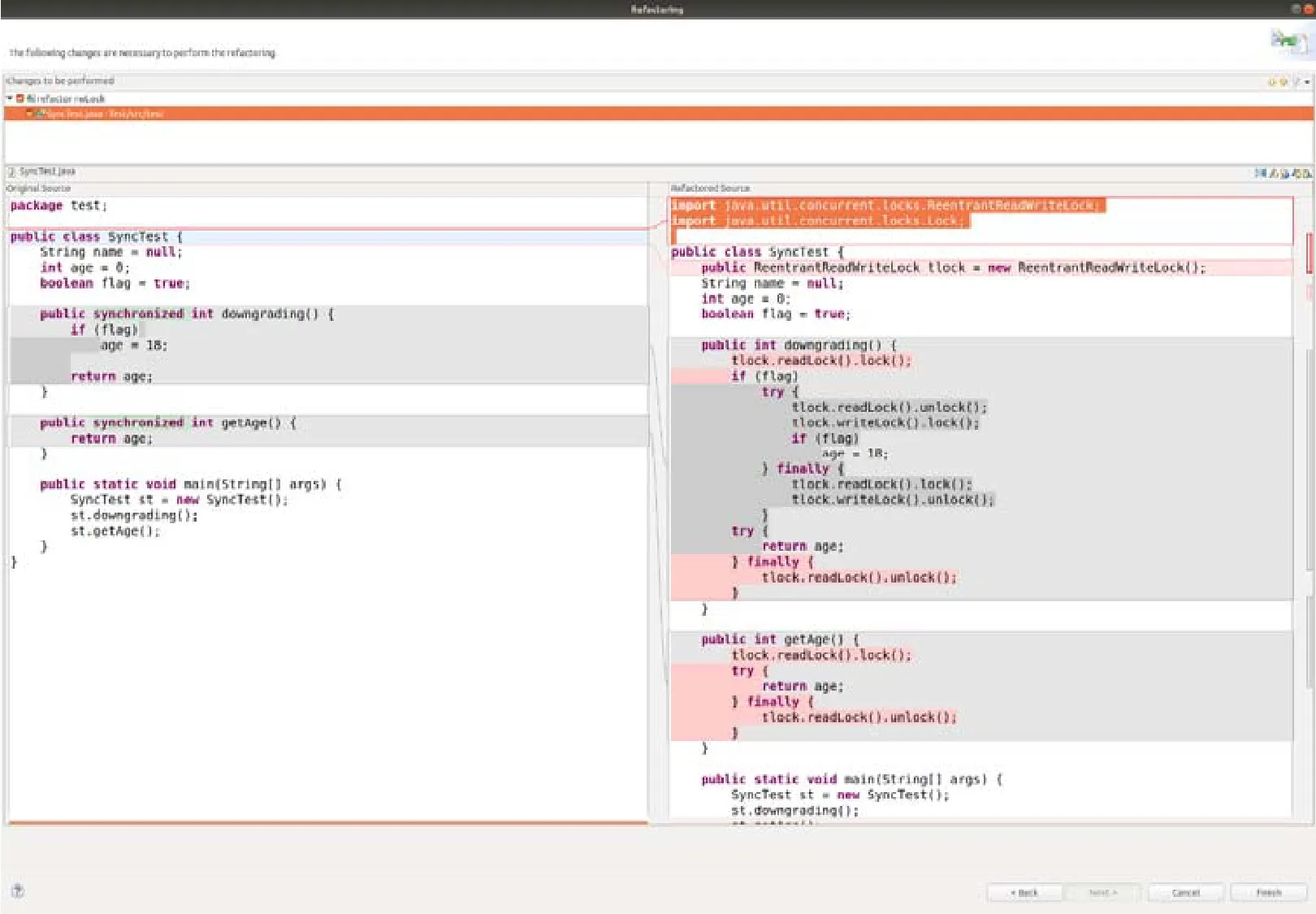
Fig.4 Screenshot of the FLock图4 FLock 重构工具界面
5 实验评估
本节对所提出的方法和工具进行了实验评估.首先对实验配置和测试程序进行介绍,然后从重构数目、改变的代码行数和时间等方面给出了实验结果,并对结果进行了分析[18].
5.1 实验配置
所有实验都是在HP Z240 工作站上完成的,该工作站搭载Intel Core i7-7700 处理器,该处理器主频为3.6GHz,有4 个处理核,均支持超线程技术,可以支持8 个线程同时运行,内存为8GB.软件上,操作系统使用Ubuntu 16.04,使用Eclipse 4.12.0 作为重构工具的开发平台,使用JDK 1.8.0_221 和程序分析工具WALA 1.52.
5.2 测试程序
本文选取了11 个实际应用程序来验证我们重构工具的有效性和适用性,这些应用程序包括HSQLDB[19],Jenkins[20],Cassandra[21],SPECjbb2005[22],JGroups[23],Xalan[24],Fop[25],RxJava[26],Freedomotic[27],Antlr[28],MINA[29].其中,HSQLDB 是一个开源的Java 数据库,Cassandra 是Apache 公司的开源分布式NoSQL 数据库系统,Jenkins是一个开源的自动化服务器,JGroups 是群组通信工具,SPECjbb 2005 是Java 应用服务器测试程序,Xalan 和Fop分别是Apache 公司的XSLT 转换处理器和格式化对象处理器,RxJava 是Netflix 公司的在Java VM 上使用可观测的序列来组成异步的、基于事件的程序的库,Freedomotic 是一个开源的物联网框架,Antlr 是一个解析器生成器,MINA 是Apache 公司的网络应用框架.这些程序的版本号信息、包含同步方法和同步块的个数以及源码行数见表1.
5.3 实验结果及分析
在实验中,使用FLock 对11 个测试程序进行自动重构,对重构个数、代码行数、重构后程序的准确性进行了验证,并与重构工具Relocker 和CLOCK 进行了对比.
5.3.1 锁重构个数
我们首先对FLock 重构后的不同类型锁个数进行了汇总,重构结果见表2.
从实验结果可以看出:在11 个程序中,共有391 个粗粒度锁重构为细粒度锁.内置监视器对象转换为锁降级模式的个数有25 个,其中,HSQLDB 中最多,包含6 个,集中分布在org.hsqldb 包里的Session 类和Table 类中,这两个类分别是用来执行session 和保存数据库表的数据结构和方法;在RxJava 和MINA 中,由于原程序中包含的内置监视器对象较少,在重构之后没有监视器对象转换为锁降级模式.内置监视器对象转换为锁分解模式的个数为127 个,在HSQLDB,Cassandra 和JGroups 测试程序中重构后转换为锁分解模式的个数较多;测试程序Fop 中包含32 个内置监视器对象,重构后没有内置监视器转换为锁分解模式.在重构为读锁方面,有293 个内置监视器对象转换为读锁,在测试程序HSQLDB 和Cassandra 中,读锁的占比相对较高;在程序Antlr 和MINA 中,使用锁分解模式比使用读锁的个数多.
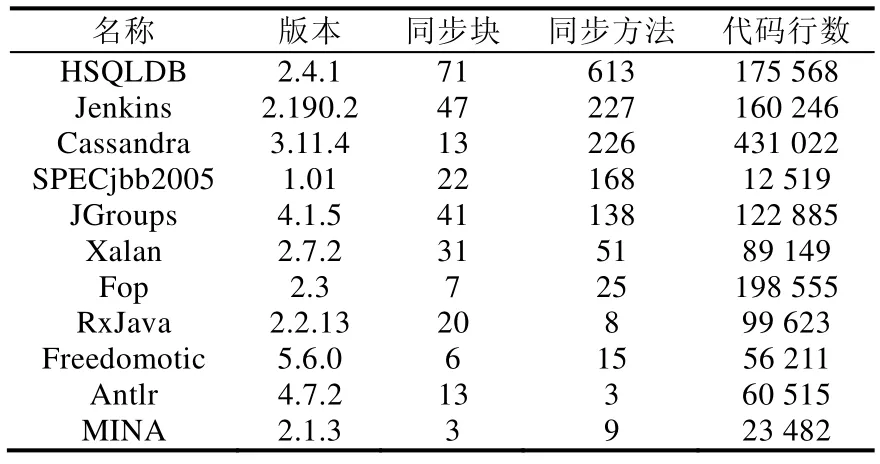
Table 1 Benchmarks and their configuration表1 测试程序及其配置

Table 2 Refactoring results by FLock表2 FLock 重构结果

Table 3 Comparison of Relocker and FLock表3 Relocker 和FLock 重构对比
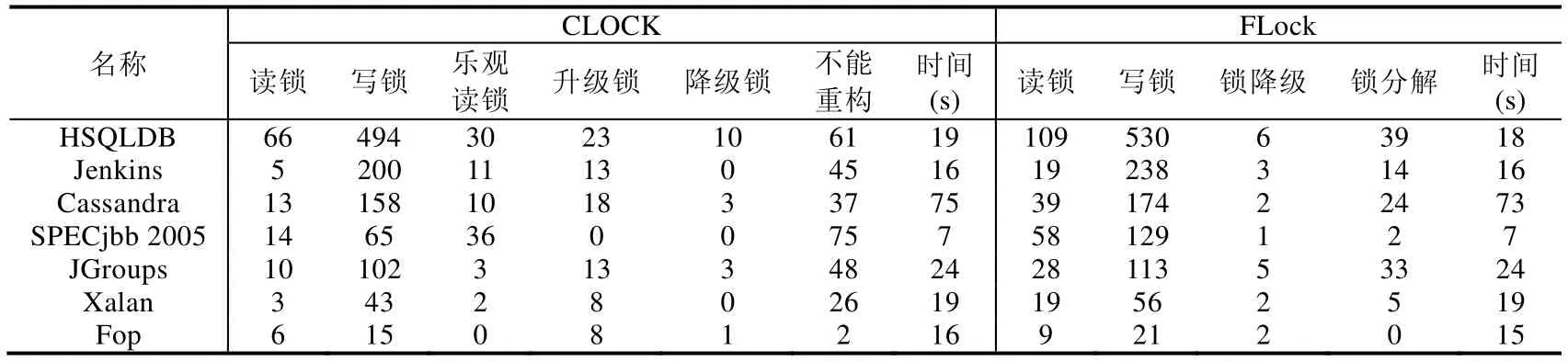
Table 4 Comparison of CLOCK and FLock表4 CLOCK 和FLock 重构对比
在重构工具FLock 中,加入了对临界区的一致性规则检测,表2“违背一致性规则”列展示了不满足一致性检测的临界区数目.对于所有的测试程序,除了MINA 测试程序外,其余10 个程序均存在违背一致性检测规则的情况发生,共有139 个,其中,HSQLDB 中最多,有41 个.对于这些不满足一致性规则的临界区,我们没有对他们进行锁分解,而是采用写锁作为临界区的保护模式.
5.3.2 重构前后改变的代码行数
我们对重构前后改变的代码行数进行了统计,这些代码行数的改变在一定程度上反映了程序员在手动重构时所需要花费的工作量.我们使用SLOCCount(https://dwheeler.com/sloccount/)工具对代码行数进行统计,该工具是由David A.Wheeler 开发的用于精确统计代码行数的工具,不仅适用于多个操作系统平台,而且适合于多种语言.
11 个测试程序共包含1 429 775 行代码,重构后代码行数为1 439 779 行,增加了10 004 行代码.由于重构前使用的是同步锁,重构后使用的读写锁需要显示的加锁和解锁,并且需要使用try-finally 语句块,所以重构后会增加代码行数.对于HSQLDB 测试程序,由于其包含的同步锁数目最多,重构前后改变的代码行数也最多,达到 3 756 行;对于Jenkins,Cassandra,SPECjbb2005 和JGroups 测试程序,由于它们包含的同步锁数目在100 到300之间,代码改变的行数也较多,分别增加了1 762 行、1 420 行、782 行和1 241 行;对于RxJava,Freedomotic,Antlr和MINA 测试程序,由于包含的同步锁较少,代码行数的改变也较少,分别有171 行、274 行、59 行和67 行.
这些代码行数在一定程度上体现了程序开发人员重构程序时的工作量,如果使用手动重构的方式,开发人员需要首先在程序中找到同步锁出现的位置,然后进行修改.例如:在手动重构HSQLDB 测试程序时,需要在17万行的代码中寻找684 个同步锁并进行重构,最终结果会增加3 756 行代码,这种手动重构耗时较长并且容易给程序引入新的错误,对于该测试程序,我们发现同步锁大部分分布在org.hsqldb 包中,分布相对比较集中;在FOP中,32 个内置监视器对象在重构后只增加235 行代码,但32 个监视器对象分布在2 034 个java 文件中,分布非常稀疏,遍历过程十分耗时.在使用我们开发的自动重构工具重构HSQLDB 和FOP 时,分别仅需要18s 和15s 即可完成,可以大大节省程序员的工作量.
5.3.3 重构时间
11 个测试程序重构的总耗时为192s,每个程序平均耗时17.5s,见表2.HSQLDB 中监视器对象较多,有684个监视器对象,重构耗时为18s;程序Cassandra 规模相对较大,源码行数为431 022 行,重构耗时为73s;JGroups和Xalan 重构耗时分别为24s 和19s;SPECjbb2005,RxJava,Freedomotic,Antlr 和MINA 的程序规模相对较小,重构耗时约为2s~8s.通过对这些程序的重构时间进行分析,我们发现:重构工具在重构时的时间消耗主要是用于程序的静态分析上,程序越大,静态分析时间越长,造成总的重构时间也越长.对于FOP 测试程序中,源码行数为198 555 行,虽然其与HSQLDB 程序的代码规模相当,但其中包含同步锁个数非常少,分布相对比较稀疏,通过手动的方式进行重构会花费大量的时间在搜索代码上;而FLock 可以自动地完成重构,用时也仅仅为15s,大大减少重构耗时,有效提高开发效率.
5.3.4 重构的正确性
为了对重构后测试程序的正确性进行验证,我们主要从以下3 个方面进行了验证,包括验证推断锁的类型是否正确、加锁和解锁的位置是否正确、锁结构的使用是否正确.由于目前没有相关的自动验证工具,我们主要采用了手工检查的方式.
在验证推断锁类型的准确性方面,我们手动地检查每一个测试程序中每一个临界区的代码,我们发现:推断出来的每一个锁都符合我们的推断规则,都是正确的类型.此外,我们发现:在Cassandra 测试程序中,部分代码在重构前就使用了读写锁.我们将这些读写锁重构为同步锁,然后使用Flock再对其进行重构,结果发现:Flock推断的锁类型和原有的锁类型基本相同,只有一处存在不同之处.该处发生在CompactionStrategyManager 类的maybeReload 方法中,该方法原本使用写锁,但是Flock 将其推断为锁分解的方式,经过手工检查发现:使用锁分解的方式并未改变程序原逻辑,是正确的细粒度加锁方式.
在判断加锁和解锁位置以及锁的使用方面,我们主要检查了:(1) 每种锁的加锁操作是否对应一个解锁操作;(2) 解锁操作是否被放入finally 语句块中;(3) 细粒度锁的结构是否正确.经过检查,我们并未发现相关错误.我们也通过运行程序的方式检查了程序的正确性,发现这些程序在执行过程中并没有报错,都可以正确运行.
5.3.5 重构前后性能对比
本节选取HSQLDB,Jenkins,Cassandra,JGroups 和SPECjbb2005 进行性能测试.之所以选择这5 个程序,是因为它们在发布的版本中都提供了相应的基准测试程序.
HSQLDB 提供了JDBCBench 测试程序,该程序的测试结果如图5 所示,其中:横坐标为处理事务数,分别给出了事务数为100k,200k,300k 和400k 的情况;纵坐标为事务处理率.从图中可以看出:该测试程序在处理100k个事务时,程序重构后使用细粒度读写锁的事务率比重构前使用同步锁的事务率略有提升,但不明显;在处理事务量达到200k,300k 和400k 时,重构后比重构前的程序在事务率上的提升大约有15%,19%和22%,提升较为明显.总的来说,HSQLDB 使用细粒度的读写锁在事务率方面重构后比重构前平均提升了18%,说明使用细粒度锁有助于提升HSQLDB 的性能,而我们设计的工具可以帮助更快地转换为细粒度锁.
对于Jenkins,我们选取了其中的单元测试程序UpdateCenterTest,FunctionsTest 和FilePathTest 进行了测试.图6 给出了3 个单元测试的执行时间,可以看出:单元测试UpdateCenterTest 在重构前后程序的执行时间基本没有变化,而FunctionsTest 在重构后执行时间缩短了17.3%,FilePathTest 在重构后执行时间缩短了20.9%.
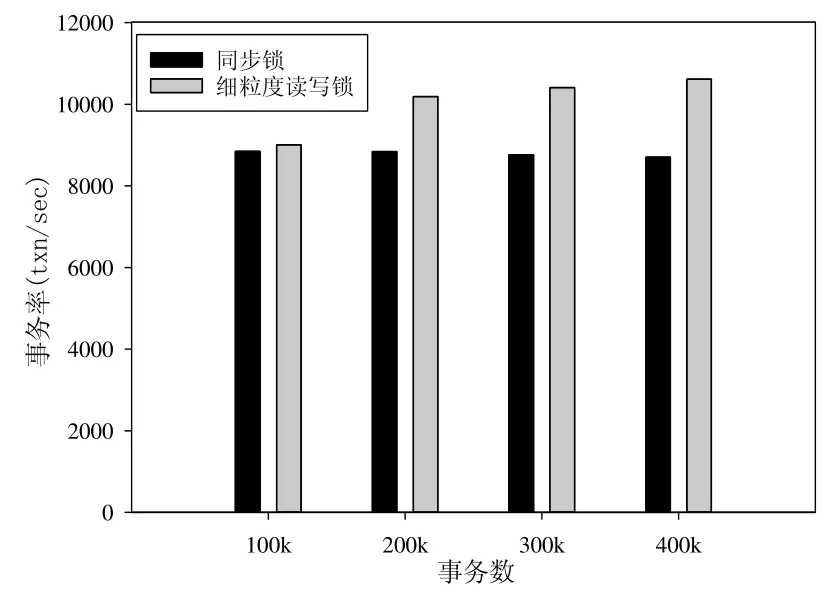
Fig.5 Performance comparison of the HSQLDB benchmark before and after refactoring图5 HSQLDB 重构前后的性能比较
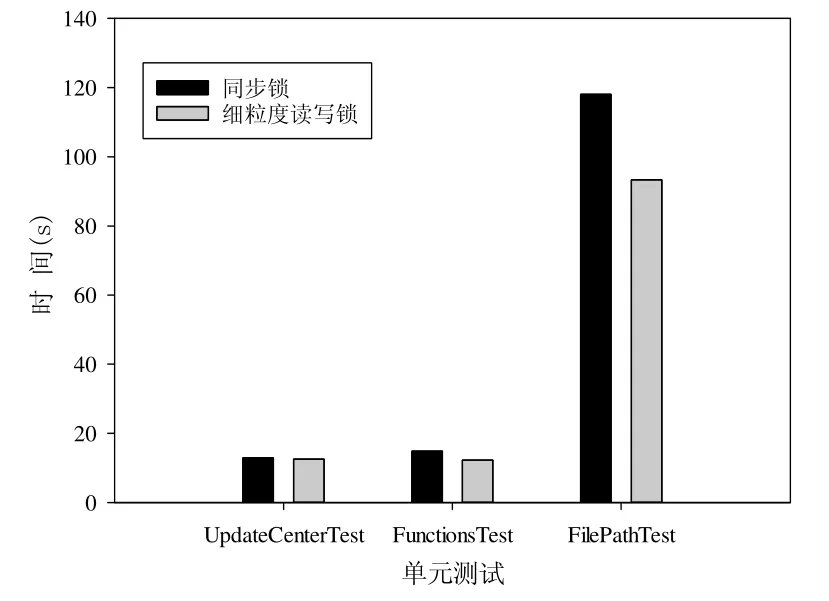
Fig.6 Performance comparison of the Jenkins benchmark before and after refactoring图6 Jenkins 重构前后的性能比较
对于JGroups,我们选取了测试程序RoundTrip,RoundTripRpc,UnicastTest 和UnicastTestRpc 进行测试,这4个测试程序都是测试两个群组之间消息的发送与接收能力.实验结果如图7 所示,其中,横坐标为测试程序,纵坐标为请求处理率.从结果中可以看出:4 个测试在重构后请求处理率都有所提升,分别提升了15.5%,7%,5%和9%.
对于测试程序Cassandra,我们选取了其中的单元测试程序BatchTests,SimpleQueryTest 和ManyRowsTest进行性能测试,图8 给出了3 个单元测试程序重构前后的执行时间.对于单元测试程序BatchTests,Cassandra 重构后程序的执行时间与重构前程序的执行时间基本相同;对于SimpleQueryTest 和ManyRowsTest 这两个单元测试程序,执行时间都有不同程度的下降,都较重构前的执行时间大约缩短了7%.

Fig.7 Performance comparison of the Jgroups benchmark before and after refactoring图7 JGroups 重构前后的性能比较

Fig.8 Performance comparison of the Cassandra benchmark before and after refactoring 图8 Cassandra 重构前后的性能比较
图9 给出了SPECjbb 2005 运行结果,其中,图9(a)给出了吞吐量随线程数变化的情况,图9(b)给出了堆内存使用的百分比随着线程数变化的情况.从图9(a)可以看出:当吞吐量达到峰值之后,使用同步锁的吞吐量要比使用细粒度读写锁的吞吐量稍微高一些.这也说明并不是所有情况下,使用细粒度读写锁性能都比使用同步锁要好.图9(b)给出了在不同线程执行情况下使用的堆内存占总内存的百分比,在线程数为8 时,程序重构前的堆内存使用占比高于程序重构后;而在线程数为12 时,程序重构后的堆内存使用占比高于程序重构前.这说明在不同锁模式和不同线程数下堆内存的使用情况各有不同,而我们设计的重构工具为开发人员提供一种快速的细粒度锁和粗粒度锁重构的方式,开发人员可以通过测试来找到程序堆内存使用最合适的情况.
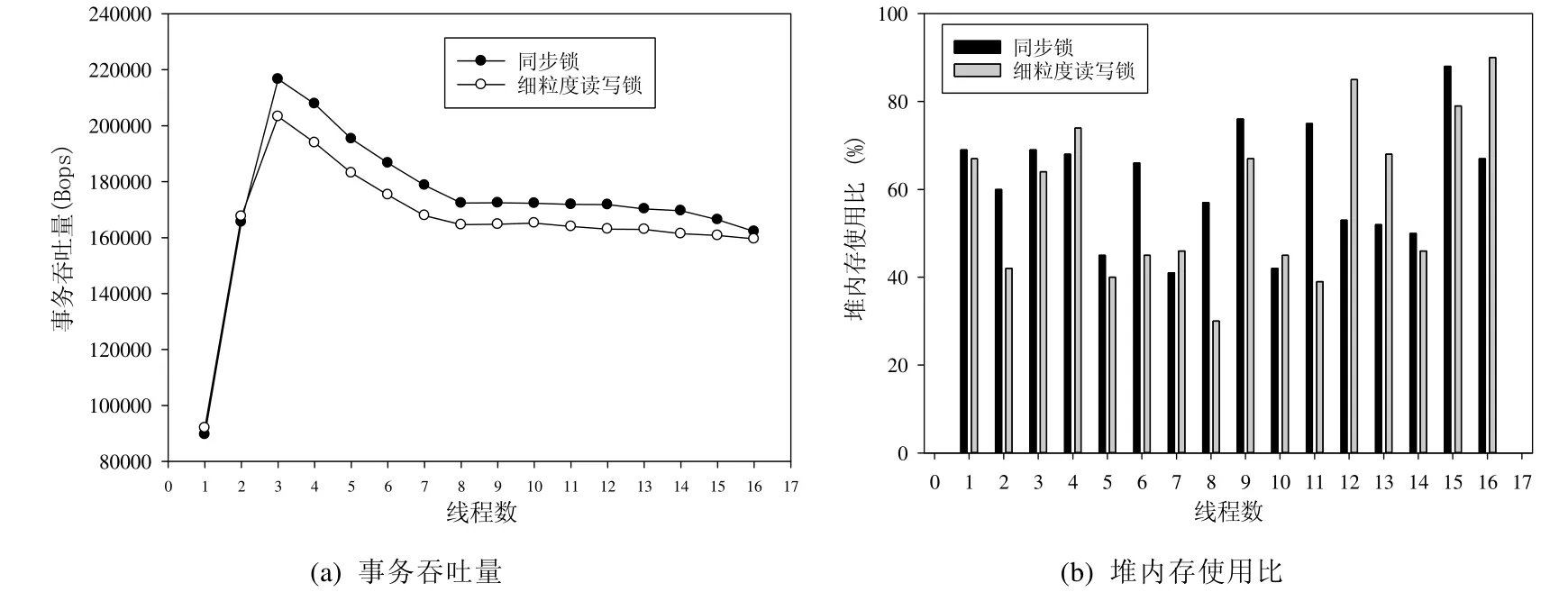
Fig.9 Performance comparison of the SPECjbb2005 benchmark before and after refactoring图9 SPECjbb2005 重构前后的性能比较
5.3.6 工具对比
我们将FLock 和已有的重构工具Relocker[5]进行了对比.Relocker 是Schafer 等人设计实现的一个自动重构工具,可以把同步锁重构为可重入锁或读写锁.该工具是一种粗粒度锁的推断模式,不能实现细粒度的加锁模式.由于Relocker 工具开发较早,不支持高版本的JDK,因此在该实验中使用的JDK 版本为1.6.测试程序选择了HSQLDB 和Cassandra,版本分别为1.8.0.10 和0.4.0(比表1 的版本低),这两个程序中包含的同步锁的数量也较之前实验选取的版本有所不同:HSQLDB 总共包含266 个同步锁,Cassandra 总共包含57 个同步锁.我们也尝试使用Relocker 对其他测试程序进行重构,但由于Relocker 开发较早,均不支持对这些版本进行重构.
表3 给出了Relocker 和FLock 重构结果的对比,可以看出:Relocker 只使用读锁或写锁进行同步保护,而且还存在不能重构的问题;FLock 不仅可以推断读锁和写锁,而且可以实现更为细粒度的锁重构.在读锁的推断上,FLock 比Relocker 推断出了更多的读锁,经人工验证,使用FLock 进行重构后的读锁使用正确.Relocker 的推断结果不准确的原因可能与分析深度有关,这里的分析深度使用的是Relocker 的默认值.在重构时间上,Relocker重构HSQLDB 耗时7s,FLock 耗时6s;Cassandra 程序规模较大,Relocker 重构耗时50s,FLock 重构耗时42s.总体来看,FLock 在重构效率上有所提升.
我们还将FLock 与重构工具CLOCK[7]进行了对比,CLOCK 是一个面向邮戳锁的自动重构工具.这里选取了本文实验中监视器对象相对较多的7 个测试程序进行重构对比,实验结果见表4.由于邮戳锁是不可重入锁,所以CLOCK 对部分临界区不能执行重构,其中,HSQLDB 和SPECjbb 2005 包含较多不能重构的锁,分别为61和75 个;由于CLOCK 在锁推断上和FLock 不同,所以在锁降级重构数量上也有所差异.两个工具在重构效率上,CLOCK 在重构HSQLDB,Cassandra 和Fop 时比FLock 慢1s~2s,其他程序在重构时间上基本一致.
关于重构后程序性能方面,我们对HSQLDB 和SPECjbb2005 这两个程序使用不同重构工具重构后,使用3种锁的性能进行了对比.HSQLDB 的实验结果如图10 所示,结果表明,粗粒度的读写锁和邮戳锁在事务率上要低于使用细粒度读写锁的程序.SPECjbb2005 的实验结果如图11 所示,由于JDK 版本原因,Relocker 不能对SPECjbb2005 进行重构,这里只对比了CLOCK 和FLock 的重构结果.可以看出:程序在使用细粒度读写锁时,相较于使用粗粒度读写锁和邮戳锁的程序,事务率有明显提升.

Fig.10 Performance comparison of the HSQLDB benchmark after refactoring图10 HSQLDB 重构后的性能比较
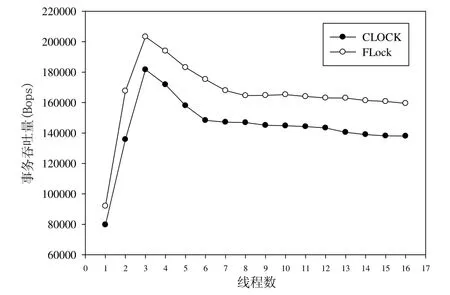
Fig.11 Performance comparison of the SPECjbb2005 benchmark after refactoring图11 SPECjbb2005 重构后的性能比较
5.3.7 有效性威胁
实验中有几个可能威胁有效性的因素.
1) 由于并发程序执行的不确定性,不排除性能测试实验结果可能存在细微的偏差.为了避免误差,我们所有实验结果都是在10 次运行的基础上取平均值得到的;
2) 在实验中,我们采用手工检查的方式对重构后程序的正确性进行验证.手动的检查方式存在着一些不足之处,可能会出现人为验证不准确等问题.为了减少不准确情况的发生概率,我们选取了两组学生分别进行两次检查的方式,尽可能避免出现问题;
3) 本实验只选取了11 个应用程序对FLock 进行了评估,它们并不能代表所有程序,不能完全证明FLock在所有的应用程序中可以成功完成重构.但是我们选取的应用程序涉及数据库、群组通信、物联网等多个领域,具有很好的代表性.未来的工作中,我们也将使用更多应用程序对FLock 进行测试.
6 相关工作
本文实现了面向细粒度读写锁的自动重构工具,我们主要关注的相关工作有两个方面:面向锁的优化和自动化的重构工具.
6.1 面向锁的优化
Emmi 等人[3]提出了一种自动锁分配技术,采用带有原子性规范的注解对程序进行标记,自动推断程序中应该获取锁的位置.Kawachiya 等人[4]提出一种锁保留算法,该算法允许锁被线程保留,当一个线程尝试获得锁操作时,如果线程保留了该锁,它就不用执行获取锁的原子操作;否则,线程使用传统的方法获得锁.Halpert 等人[30]提出了基于组件的锁分配技术,用于分析数据依赖性,自动将具有可调粒度的锁对象分配给临界区.Tamiya Onodera 等人[31]设计了一种基于锁保留的自旋锁,并使用这种自旋锁替换传统的自旋锁.Arbel 等人[8]提出了使用乐观同步替换程序中的一些加锁代码,以减少争用,可以在不牺牲正确性的情况下提高其可扩展性.Bavarsad[9]针对软件事务性内存,提出了两种优化技术来克服全局时钟的开销:第一种技术是读写锁定分配,它不利用任何中央数据结构来保持事务的一致性,仅当事务成功提交时,此方法才能提高软件事务性内存的性能;第二种优化技术是一种动态选择基线方案的自适应技术,用来减小读写锁定分配的成本.Gudka[32]提出了一种针对Java 的锁定推断方法,使用锁定推断来实现原子块,该方法可以全面分析Java 库方法.以上工作的研究目的与我们相似,通过锁分配、锁保留、原子块等技术减少临界区竞争;而我们使用锁降级、锁分解实现对临界区的细粒度保护方式,从而减少临界区竞争.
Hofer 等人[33]提出了一种通过跟踪Java 虚拟机中的锁定事件来分析Java 应用程序中的锁争用的方法,该方法不仅检测线程在锁上被阻塞情况,还检测是哪个其他线程通过持有该锁来阻止它,并记录它们的调用链.Tallent[34]提出了3 种量化锁争用的方法,可以在低开销的前提下,有效提供锁争用检测精度.Inoue[35]提出了一个基于Java 虚拟机,使用硬件性能计数器来检测应用程序获取锁的位置以及阻塞位置的方法.以上研究是用于揭示锁争用的原因以及识别锁性能瓶颈的分析工具,我们的研究提出的是一个解决锁争用问题的重构工具.
6.2 自动化的重构工具
Dig 等人提出了一个软件并行化重构工具CONCURRENCER[36],该工具可以将串行的Java 代码进行并行化重构,以及面向循环并行化重构的重构工具Relooper[37].Wloka 等人[38]提出了一个用于把串行程序转变为可重入的程序的自动重构工具Reentrancer,从而使程序更易并行化实现.Brown 等人[39]提出了一个用于生成并行程序的重构工具ParaPhrase,从而增加并行程序的可编程性.以上研究以各种形式实现了重构工具,并很好地实现了工具的自动化,但都是面向并发程序的自动重构工具,而我们的工具是面向锁的自动重构.
McCloskey[40]提出了悲观的原子块,在不牺牲性能或兼容性的情况下,保留了类似事务性内存中乐观原子块的许多优点,并实现了自动重构工具Autolocker.Schäfer 与IBM T.J.Watson 研究中心合作设计了一种面向Java 显示锁的重构工具Relocker[5],它能将同步锁重构为可重入锁,以及将可重入锁重构为读写锁.与Relocker相比,我们的重构方法引入了锁降级、锁分解模式,使重构的适用性更广.Zhang 等人[6]提出了一种用于在字节码级别锁重构方法,由于在字节码层实现,可视性较差一些;我们的重构工作直接在源代码层实现,转换过程更直观.Zhang 等人[7]提出了一个面向邮戳锁的自动重构工具CLOCK,该重构工具支持优化读锁和锁升级等操作,但是受限于邮戳锁的非可重入性,适用范围有限.我们的研究面向细粒度锁的重构则不受该限制.
Tao 等人[1]提出了针对Java 程序、根据类属性域划分锁保护域的自动锁分解重构方法,并以Eclipse 插件形式实现了自动重构工具.Yu 等人[2]在进行优化同步瓶颈的研究中提出了一种锁分解方法,该方法重新构造锁的依赖关系,使用细粒度的锁来保护不相交的共享变量集,并实现了工具SyncProf.Greenhouse 等人[41]根据类的功能将对象的状态划分为多个子区域,然后通过不同的锁来保护每个分区锁分解方法.在工业界,得到广泛应用的重构工具包括集成在IntelliJ IDEA 上的重构插件LockSmith[10]以及一个基于Eclipse JDT 的并发重构插件[11],这两个插件都可以实现锁分解、锁合并等重构.以上研究均是通过不同锁对象对类中的方法实现锁分解,我们的研究是通过读写锁的分离在方法内实现锁分解.
7 总 结
本文提出了一种面向细粒度锁的自动重构方法,该方法结合借助访问者模式分析、别名分析、负面效应分析等多种程序分析技术对读写模式进行分析,并设计了基于下推自动机的锁模式识别方法.以Eclipse 插件的形式实现了自动重构工具FLock,在HSQLDB,Jenkins 和Cassandra 等11 个开源项目中使用该重构工具,对本文提出的方法进行了验证.实验中总计重构了1 757 个监视器对象,每个程序重构平均用时17.5s.与手动重构相比,可以有效提升重构效率.实验结果表明,该重构工具可以有效地实现粗粒度锁到细粒度锁的转换.我们下一步的工作包括:1) 探索更多的细粒度锁的重构模式,尝试发现更多的可以使用细粒度锁的场景;2) 使用更多实际应用程序对FLock 进行测试;3) 完善重构工具FLock,通过比较使用粗粒度锁和细粒度锁的程序性能,在重构算法中加入性能权衡,帮助程序员在粗粒度锁和细粒度锁之间做出选择,进而决定是否进行重构.
猜你喜欢
红外技术(2022年11期)2022-11-25
安阳工学院学报(2020年2期)2020-06-05
数字技术与应用(2018年4期)2018-08-18
电脑知识与技术(2017年26期)2017-11-20
电脑知识与技术(2017年5期)2017-04-08
信息安全研究(2016年3期)2016-12-01
信息化视听(2016年7期)2016-05-14
中国高新技术企业(2015年24期)2015-06-25
中国交通信息化(2014年4期)2014-06-05
