
面向学科新兴主题探测的多源科技文献时滞计算及启示
——以农业学科领域为例
2021-02-25 10:37杨金庆吴乐艳
情报学报 2021年1期
杨金庆,陆 伟,吴乐艳
(1.武汉大学信息管理学院,武汉430072;2.武汉大学信息检索与知识挖掘研究所,武汉430072)
1 引言
学科大数据时代的开启使得数据洪流不断冲击着各学科领域,科学研究正从“目标驱动”“模型驱动”迈向“数据驱动”为特征的研究范式,其动态性、客观性和敏捷性逐渐增强[1]。近年来,以期刊文献、基金项目文档、专利文本、会议资料等为代表的科技文献发表数量庞大,例如,仅2018年SCI数据库收录206.97万篇科技论文,其中我国学者贡献41.82万篇[2]。科技战略决策者及科研人员将面临科技文献数量庞大、增长迅速的新局面,及时、准确地把握科学研究的新动向变得愈发困难,智能化探测学科新兴主题逐渐成为科技情报人员的重要研究领域。
新兴主题探测,由美国国防部高级研究计划局(DARPA)于1998年首次提出[3],并初步用于对新闻报道主题的探测。随后,新兴主题探测被引入科学研究领域,并逐渐形成新兴主题探测的研究范式,其内容主要包括:科技文献数据获取、学科主题识别、学科主题阶段判定、可视化分析[4]。其中,科技文献数据的全面性与新颖性是保证新兴主题探测准确性的基础,同时,科技文献的多样性也为多源科技文献的融合带来挑战。“多源信息”与“多源方法”既可保证情报分析的全面性,又可进一步提高情报分析结果的有效性[5]。面对格式多样、分布广泛、种类繁多的科技文献,融合多源科技文献可以全面发掘学科主题,进而深入了解学科领域发展态势,辅助科研工作与科技政策制定。
由此可见,多源科技文献融合逐渐成为新兴主题探测研究领域的重要问题之一,一些学者正不断寻求多源科技文献融合的新策略。目前,融合多源科技文献用于新兴主题探测的主要策略为:相同年份内多源科技文献相互融合[6-7],并未考虑多源科技文献间知识传播的时滞性问题。考虑到期刊论文是探测学科新兴主题的主要来源数据,本文以期刊论文为中心,探究基金项目文本、专利文献、会议论文与期刊论文所承载的学科主题间的时滞问题,以期对科技文献融合策略的制定有所启发和借鉴。
2 相关研究述评
2.1 面向单一科技文献
科技文献格式多样、分布广泛,种类繁多,学科主题隐含于不同的科技文献数据,如基金项目文本、专利文献、期刊论文、会议资料等。不同种类的科技文献所承载的知识功能也存在一定差异。基金项目文本前瞻性强,承载着研究人员针对学科困境和难题给出的解决思路或技术方案。专利承载着某一具体问题的研究成果,是科技创新知识的重要结晶和载体[8]。会议论文是与会人员广泛交流讨论的思想来源。期刊论文是承载国内外最新研究成果和学科发展动向的主要载体形式。
针对不同类型科技文献,研究者借助其特有的内部和外部特征制定新兴主题探测的评判指标。基金项目文本资助时长和资助金额外部特征可以用来衡量所承载学科主题的重要性程度,徐路路等[6]以此探测石墨烯领域学科新兴主题。王凌燕等[9]结合专利申请量和引证数外部特征识别工业生物领域的新兴技术主题。以期刊论文为数据源的学科主题探测研究相对较多,发文量和被引量是较为常用的外部特征[4,10-12]。学科主题在重要学术会议资料中的出现次数反映其在该领域中所受关注程度,研究者结合主题会议出现率、主题强度等内部特征识别学科新兴主题[13]。
综上所述,相较于面向期刊论文的学科新兴主题探测,基金项目文本涉及较少,而专利文献和会议资料有待研究。各类科技文献具有独特的内、外部文本特征,相较于外部特征,科技文献的内部特征具有较高的相似性,一般包含标题(title)、摘要(abstract)、内容(content)等[14],这为多源科技文献融合提供了条件。
2.2 融合多源科技文献
学科大数据环境下,单数据源科技文献难以满足科技信息挖掘、科技智能决策对数据完整性的要求。融合多源科技文献是科技信息挖掘智能化的重要步骤,也是全面、深入探测学科新兴主题的必要保障。
虽然多源信息融合的研究取得一些成果[15-16],但是仍处于发展阶段。多源信息融合可划分为前期融合、中期融合和后期融合[17]。其中,前期融合是将不同数据源汇聚到同一对象。目前,多源科技文献融合研究正处于探索的前期阶段,研究者正探索不同的科技文献融合策略,力求优化新兴主题探测方案。徐路路等[6]分析基金项目文本、期刊论文、专利文献发展趋势的相关性,进而探究基金项目文本与期刊论文、专利文献间的滞后性趋势。周群等[18]融合相同时间跨度内科技部机构用户数据、大众媒体数据等多源数据,准确识别细粒度的用户需求主题。白如江等[7]从主题层次通过相似度计算融合科技规划文本和基金项目文本所蕴含的学科主题,再汇聚、识别学科新兴主题。刘自强等[19]采用自回归分布滞后模型,从外部数量特征、内部主题特征两个层面分析基金项目文本和学术论文主题的扩散滞后效应,并计算出两者之间滞后期为2年。
因此,多源科技文献融合仍处于前期阶段。为满足新兴主题探测所需数据的全面性,研究者将相同时间跨度内的科技文献与特定分析目标相融合,忽略了科技文献间存在时滞性。随着学科新兴主题探测研究的不断深入,部分研究者逐渐关注不同种类科技文献间存在明显的时滞问题。不同种类科技文献之间的时滞分析计算逐步成为当下重要的研究点。
3 研究方案
为探索多源科技文献时滞性、寻求多源数据融合新方案,本文以学科主题为知识单元设计时滞计算方案。首先,从浩繁的学术数据中获取多源科技文献数据集,抽取科技文献摘要,基于主题模型识别学科主题,计算学科主题相似度构建学科主题相似矩阵;其次,采用匈牙利算法寻求科技文献最优匹配组合,以最优匹配组合数据为依据构建线性方程,拟合计算多源科技文献时滞程度;最后,探讨多源科技文献时滞性对多源科技文献数据融合的启示。时滞计算方案流程如图1所示。
3.1 数据来源
本文获取基金项目文本、专利文献、期刊论文和会议论文共4种多源科技文献数据集。科技文献内部特征源于内容结构,主要包含标题(title)、摘要(abstract)、内容(content)等,相较于外部特征,多源科技文献内部结构特征相似度较高。本文从微软学术(MAG)、中国知网(CNKI)、美国国家科学基金(NSF)、中国国家基金(CNSF)等数据集抽取农业学科领域2009—2016年基金项目文本、专利文献、期刊论文、会议论文摘要语料数据集,具体内容如表1所示。
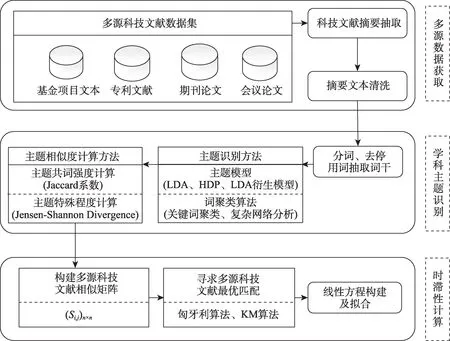
图1 时滞计算方案流程

表1 多源科技文献数据集
3.2 学科主题识别
学科主题识别是多源科技文献粒化处理的重要方法,主题模型是一种语义降维技术,可将文献所表达的含义作为隐含变量,借助文档建模,发掘文档所含主题。本文学科主题识别过程包含以下步骤:抽取摘要文本、跨语言摘要翻译、去除停用词、抽取词干生成词袋,然后输入主题模型识别多源科技文献学科主题。
本文利用困惑度确定LDA主题模型的超参数K值(预设主题数)。困惑度(perplexity)是衡量一个语言模型优劣常用指标,其计算方法[20]为
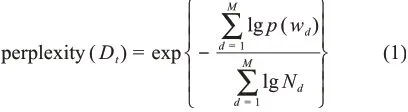
其中,p(wd)表示LDA模型生成d篇文档的概率;M代表文档数;N是第d篇文档的单词个数。
3.3 学科主题相似度计算
目前,多源数据融合领域的相似度计算方法多采用余弦相似度算法[6,21]、word2vec词向量算法、Jaccard系数[18]等。其中,Jaccard系数利用词共现比率表示主题相似度,其值越大,相似度越高。对于LDA生成概率模型难以避免高频词对主题词共现比率的影响,Lu等[22]验证了主题词中高频词占比越高,学科主题特殊性(topic distinctiveness)越低。为了避免低特殊性情况下高相似度对时滞计算的影响,本文采用Jaccard系数计算学科主题共词强度,同时融合主题特殊性指标优化学科主题相似度计算过程,具体方法如下。
(1)Modified Jaccard's Coefficient(MJC)。MJC主题相似度计算方法改进于Jaccard系数(J=|A∩B||A∪B|)。本文以LDA抽取主题的主题词概率为权重计算学科主题共词强度,以此表达主题相似度,表达式构造为其中,αq表示主题q中主题词wq的概率权重;βr表示主题r中主题词wr的概率权重。
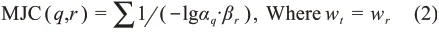
(2)Jensen-Shannon Divergence(JSD)。鉴 于LDA抽取的学科主题难以避免高频词对主题词共现比率的影响,本文利用主题特殊性(topic distinctiveness)指标降低高频词的影响,计算公式[23]为

其中,q和r分别代表两个分布,D(q1(V)||q2(V))表示q1(V)和q2(V)概率分布的相对熵。
3.4 多源科技文献时滞计算
多源科技文献时滞性是一种科技文献的学科主题相对于另一种文献学科主题的滞后程度。如果X表示一种科技文献的年份,Y表示另一种科技文献的年份,普遍存在连续多年Y-X=B,那么B表示两种科技文献之间存在的时滞程度。
首先,计算学科主题相似度,构建相似矩阵;其次,借助匈牙利最优匹配算法寻求相似矩阵二分图最优匹配组合;最后,采取线性规划思想,通过计算点到直线距离最小,拟合线性方程(Y-X=B),计算多源科技文献时滞程度,主要内容如下:
1)匈牙利最优匹配算法。
本文考虑数据噪声的影响,采用匈牙利算法[24]寻求科技文献间充分相似条件下的最优匹配组合,构建学科主题相似矩阵为(si,j)n×n,si,j表示i年科技文献学科主题与j年科技文献学科主题的相似度,n表示科技文献时间跨度,结合匈牙利算法基本思想构建多源科技文献充分相似最优匹配数学模型,

其中,Los表示相似度损耗最小,即表达最大充分相似;n表示科技文献的时间跨度;sij表示多源科技文献i,j年对应的相似度;xij表示对i年对应j年的匹配标记。
2)线性方程模型构建及拟合方法
本文的研究问题是计算两种科技文献的时滞程度,若X表示一种科技文献的年份值,Y表示另一种科技文献的年份值,存在连续多年Y-X=B,那么B表示对应于两种科技文献的年份之间存在的固定差值,即时滞程度。同时,考虑到年份值为整数,且各年份相似矩阵为方形对称矩阵,结合理论分析确定线性方程模型为y=x+b,且b为整数,具体推演如图2所示。

图2 线性方程模型推演图
针对线性方程y=x+b模型,考虑到b值为整数,本文通过最优匹配组合的坐标点到直线方程的距离和最小来求得此模型的参数b值,计算公式为
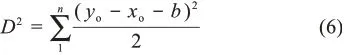
其中,n表示数据的时间跨度;yo和xo表示多源科技文献的年份值;b为多源科技文献的时滞程度值。
衡量数据拟合模型好坏的程度称为拟合优度,R2是拟合优度的一个重要统计量,也称为决定系数。R2计算公式为
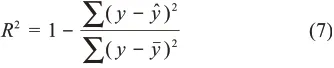
其中,y表示观测值;y^表示线性方程的拟合值;yˉ表示观测值的平均值。
4 实证及结果分析
4.1 数据准备
首先,从获取的基金项目文本、专利文献、期刊论文、会议论文中抽取摘要文本,按年份拆分2009—2016年摘要文档,共分为32份数据集。实验数据的具体情况如表2所示。
4.2 学科主题识别
本文对科技文献摘要语料进行分词、提取词干,将摘要的原始表达转化为稀疏向量,然后在LDA主题模型中输入稀疏向量的语料,通过困惑度指标计算预设主题数,最后识别学科主题。
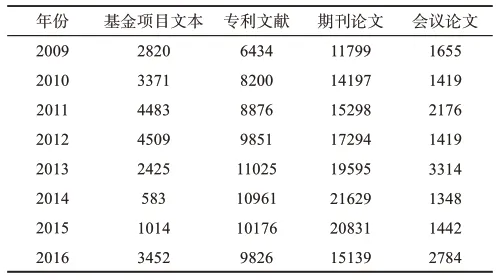
表2 实验数据准备
为了提高主题识别的准确度,本文通过实验确定主题数据K值和困惑度perplexity(Dt)的对应关系,如图3所示,以2009—2016年期刊论文8份数据集为例,其中横坐标代表主题数(number of topic),纵坐标为困惑度(perplexity)。
本文分别计算基金项目文本、专利文献、期刊论文、会议论文各年份困惑度,以主题数和困惑度所构成曲线的拐点处的主题数作为LDA参数K的值,抽取的多源科技文献学科主题数量如表3所示。
4.3 学科主题相似度计算与矩阵构建
本文利用第3.2节中的MJC和JSD计算方法,从主题共词相似和主题特殊性角度计算学科主题相似度,以构建多源科技文献年相似矩阵。本文以同年学科主题相似度的均值来表达该年份对应的相似度,并以求积的方式MJC×JSD×100计算学科主题相似度,计算结果如表4~表6所示。
4.4 基于匈牙利算法的科技文献时滞分析
由于匈牙利最优匹配是以组合和最小为条件寻求最优匹配组合,本文采用定值取反(0.5-MJC×JSD×100)转换矩阵输入匈牙利最优匹配算法从40320种组合中探寻出损耗最小组合。基金项目文本-期刊论文、专利文献-期刊论文、会议论文-期刊论文科技文献组合的最优匹配组合,分别如表7~表9中灰色加粗标记所示。
根据最优匹配组合得出xo、yo观测值并清除异常值,通过利用第3.4节中公式(5)计算观测值到线性方程模型的距离。在使得距离和最小的条件下,计算出时滞程度b的值,如表10所示(灰色加粗表示距离和最小值)。

图3 以“期刊论文”为例的困惑度图

表3 学科主题数量
最后,利用R2计算公式衡量线性方程模型的拟合程度,拟合结果如图4所示。
从图4可知,时滞计算结果为基金项目文本-期刊论文、专利文献-期刊论文、会议论文-期刊论文的时滞值分别为1、-1、1,即基金项目文本的学科主题一般早于期刊论文1年呈现,专利文献中的学科主题滞后于期刊论文1年,会议论文中的学科主题普遍早于期刊论文1年发布。该实证结果分别与文献[6]得出的在石墨烯领域“基金项目文本与期刊论文间存在正相关”和“专利数据与基金项目文本呈现明显的滞后性”,文献[19]计算出在人工智能领域“期刊论文对基金项目文本的滞后期为2年”,文献[4]统计发现的“we find that conferences lead journals by 87.64%”等结果趋势相互印证,同时也说明了本文时滞性计算方法可行且有效。
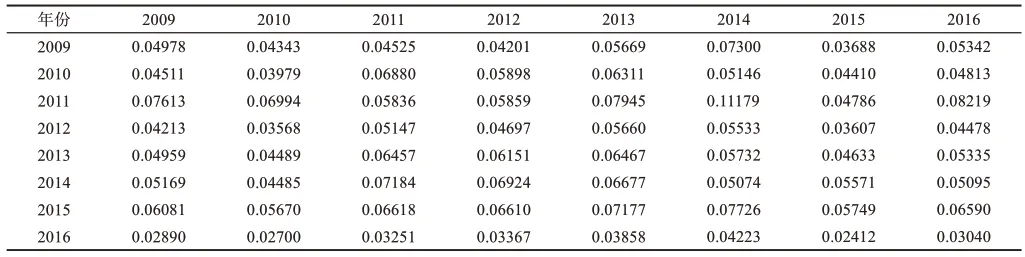
表4 基金项目文本-期刊论文主题相似矩阵
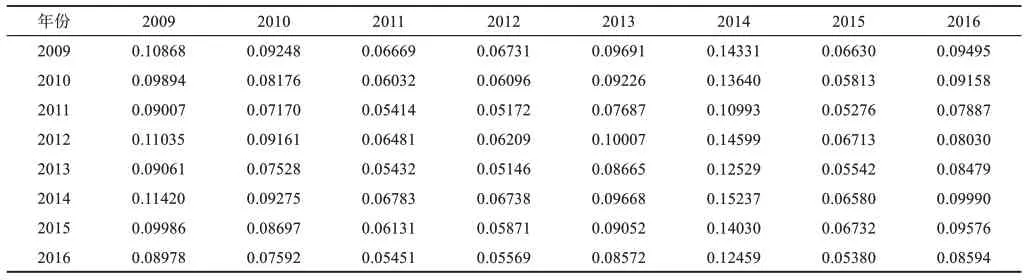
表5 专利文献-期刊论文主题相似矩阵

表6 会议论文-期刊论文主题相似矩阵

表7 基金项目文本-期刊论文最优组合
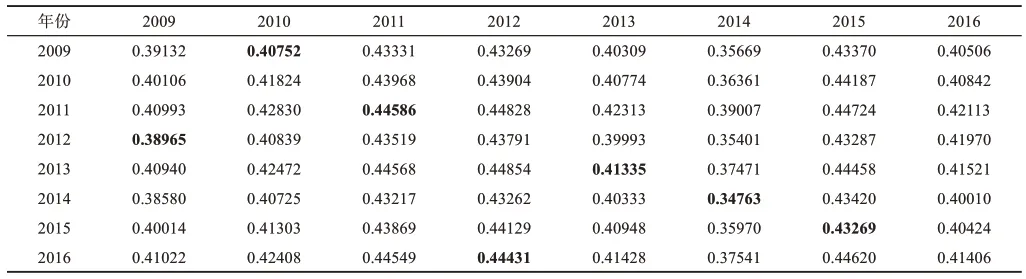
表8 专利文献-期刊论文相似矩阵最优组合

表9 会议论文-期刊论文相似矩阵最优组合
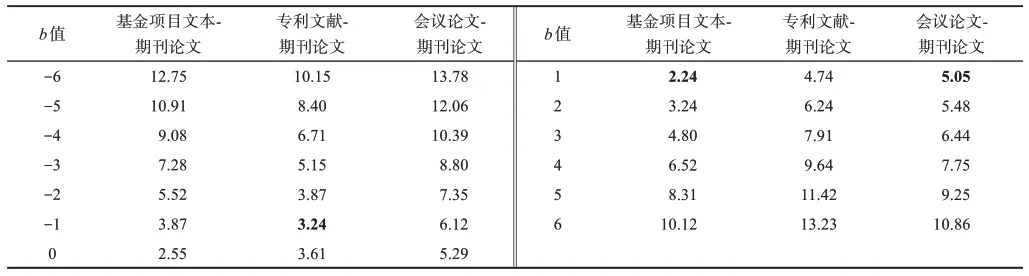
表10 时滞程度b对应的距离和最小值
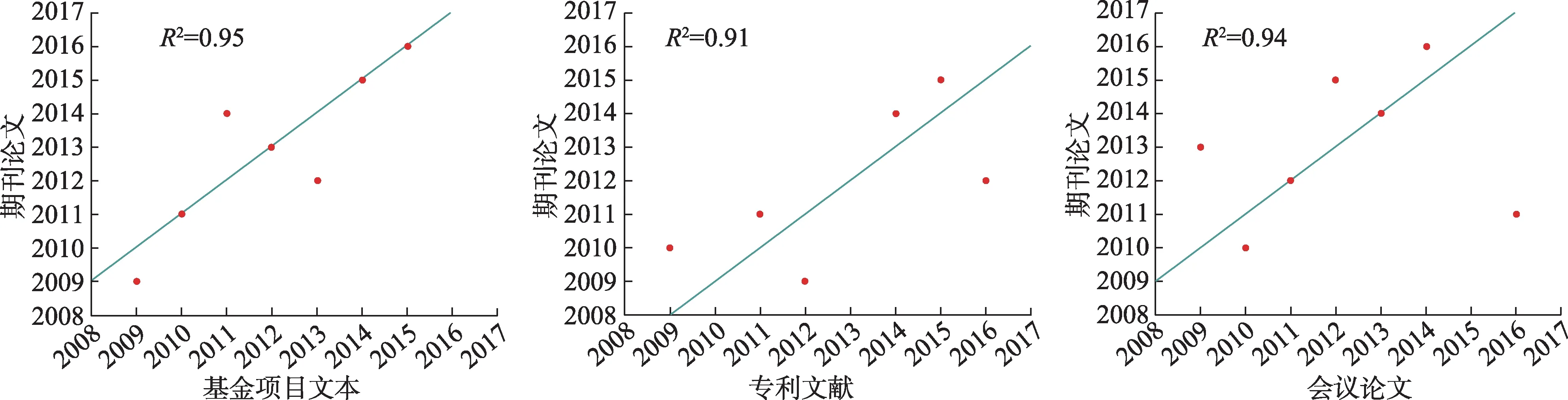
图4 拟合后的线性方程图
5 面向新兴主题探测领域的启示
多源科技文献是新兴主题探测的重要数据来源,以往汇聚同年份多源科技文献抽取学科主题的方式缺乏考虑多源科技文献间的时滞性。信息的载体形式、信息生产方式、传播途径等因素都可带来多源科技文献之间的时滞性问题。多源科技文献时滞计算方法的探索为新兴主题探测过程中的数据获取、学科主题识别提供新思路、新启示,具体如下:
(1)学科新兴主题探测的基本任务是获取全面、完整的多源数据,及时探测学科领域未来科学研究与技术的发展趋势。单一来源科技文献数据难以保证数据的完整性,但多源科技文献在提升数据完整性的同时,也带来了多源数据融合问题。
(2)新颖性(novelty)是新兴主题判定的重要依据,多源科技文献时滞计算将指引学科新兴主题探测过程中数据集的获取方向,掌握前沿数据。同时,探究不同地域、科研体制对多源科技文献之间时滞性的影响,以便紧跟国际科技前沿。
(3)学科主题识别是学科新兴主题探测的基础,影响多源科技文献融合策略的制定。融入时滞计算的多源科技文献融合策略包括两种方式:其一,从学科主题知识单元层面,根据学科主题知识关联强度设定关联强度阈值,以此对不同数据源的学科主题进行融合;其二,以时滞程度为归类标准,直接汇聚不同年份多源科技文献数据集,然后识别学科主题。
6 总结
本文面向新兴主题探测领域探究多源科技文献时滞性,以基金项目文本、专利文献、期刊论文、会议论文摘要数据为驱动,构建科技文献时滞计算流程:首先,选取主题模型借助困惑度评价指标,以年为单位识别科技文献学科主题,然后综合利用MJC和JSD方法计算相似度,构建多源科技文献学科主题相似矩阵;其次,在相似矩阵二分图匹配和最大条件下,利用匈牙利最优匹配算法求得最优匹配组合;再次,通过线性回归与推演分析,构建线性方程y=x+b,进而拟合计算多源科技文献的时滞程度;最后,与前人研究结论进行对比分析,尽管面向不同的学科领域,但不同种类科技文献间的时滞趋势相同,即期刊论文滞后于基金项目文本和会议论文,专利文献滞后于期刊论文。
多源科技文献时滞性将影响多源科技文献融合效果,同时也为多源科技文献融合策略的制定提供新思路和新方法。本文引入多源科技文献时滞性计算方法,对多源科技文献数据集获取方向以及学科主题融合策略的制定有所启示。
猜你喜欢
体育科技文献通报(2022年5期)2022-06-05
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
北京航空航天大学学报(2020年10期)2020-11-14
校园英语·上旬(2020年2期)2020-05-11
校园英语·上旬(2020年2期)2020-05-11
校园英语·中旬(2019年5期)2019-07-16
北方工业大学学报(2019年5期)2019-03-30
校园英语·上旬(2018年11期)2018-11-30
上海师范大学学报·自然科学版(2018年3期)2018-05-14
合作经济与科技(2016年24期)2016-12-07
