
基于可变向卷积网络的语义分割算法*
2021-02-25 06:27胡朝阳汪国有
计算机与数字工程 2021年1期
胡朝阳 汪国有
(华中科技大学人工智能与自动化学院 武汉 430074)
1 引言
语义分割是计算机视觉领域一个基本的命题,其思路就是为图像中每一个像素打类别标签。2012 年,随着Hinton 在目标识别领域应用深度神经网络(CNN[1]),CNN 在计算机视觉领域得到了广泛的应用。相比于传统特征如HOG[2]、SIFT[3]、Surf[4],深度特征表达能力更强,但CNN 只提供了更加强有力的特征表述,无法对场景中对象的上下文有效的建模,而上下文无处不在,上下文是一个对象与其相邻对象或图像块之间的语义相容关系,这种相容关系表示视觉模式的共存,例如,汽车可能会出现在道路上,玻璃杯可能会出现在桌子上。
随着CNN的发展,FCN[5]率先将CNN应用到语义 分 割 领 域 ,随 之 SegNet[6]、U-Net[7]、LDN[8]、PSPNet[9]等都取得了很好的分割结果。FCN 是将普通CNN 的全连接层转换为一个个卷积层,网络是一个全卷积网络,模型对经过卷积及池化下采样之后的特征图上的每一个点进行分类。FCN 的优势在于可以接受任意大小的图像,但是每个点在分类时没有考虑像素之间的关系,忽略了像素的空间一致性,缺乏上下文信息。为了利用上下文信息,SegNet 采用特征下采样-上采样的流程,下采样过程使得深度特征拥有更大的感受野,包含更多的上下文信息,而上采样则是提高了特征的分辨率。网络的整体结构呈U型。类似的还有U-Net、LDN,和SegNet非常相似,都是利用U 型结构来获取上下文信息。PSPNet 则是在未采用U 型结构的前提下提出了空间金字塔池化模块,该模块融合多个尺度上下文信息,辅助网络做更加精准的判断,但获取上下文的方式过于生硬,没有考虑目标本身的外观特征。
对于上下文的提取,本文则是提出了可变向卷积网络,算法的主要思想是在特征图的每一个像素使用卷积预测特征需要观测的方向,然后在该方向上通过普通卷积操作实现像素类别的预测,这样模型会挑选出更加显著可分的上下文来辅助类别的判定。由于对象本身存在尺度的多样性,因此在预测对象类别时,我们在多个尺度下使用多方向卷积,保证了多个尺度对象的预测。模型在PASCAL VOC2012公开数据集进行了测试实验,实验表明我们提出的可变向卷积网络取得的效果优于目前经典算法。
2 可变向卷积网络
本节我们首先介绍可变向卷积的核心思想,然后介绍可变向卷积网络的整体模型,最后针对网络中的每一个模块做详细的介绍。
2.1 可变向卷积
可变向卷积受可变形卷积[10]的启发而形成,因此先介绍其思想来源。

图1 四种不同的卷积操作
可变形卷积如图1(b)是在普通的规则卷积如图1(a)基础上通过学习一个偏移特征变成的不规则卷积。该操作首先需要学习偏移特征,然后再在普通的卷积中叠加偏移特征以提取更加有效的表达特征。可变形卷积的数学表达式为

可变形卷积增大感受野的同时会根据需要在周围的不规则区域提取任意单个点的特征。但是由于训练的权值包含变形权值(Δp及Δq)及普通卷积参数两部分,因此模型参数多,训练复杂、不稳定。空洞卷积[11]如图1(c)则是在不增加参数的同时增大了感受野,但是增大感受野是同时向四周扩张,扩张方式单一。
而本文提出的可变向卷积如图1(d),相比于可变形卷积则需要更少的参数量,在训练网络较为简单、稳定易收敛,相比于空洞卷积,同样可以增大感受野,相对空洞卷积,可通过注意力机制获取更加显著可分的特征。
可变向卷积是一种提取对象上下文的有效手段,图2 展示了可变向卷积提取上下文提取的流程,图2(a)中展示了像素A在不同的感受野下面卷积时所用到特征区域,可以发现,很多区域特征是干扰上下文,所以图2(b)中网络预测出模型注意的方向:右上方向、右下方向,如图2(b)红色和黄色箭头所示,其区域的上下文特征分别是墙、马路地面。所以可变卷积网络将干扰区域的特征去除,剩下有用区域上下文特征,如图2(c)所示的矩形框。

图2 可变向卷积网络提取上下文流程
2.2 可变向卷积网络
可变向卷积网络(Variable Direction Convolution Network,VDCNet)主要包括多方向卷积模块(Multi Directional Convolution Module,MDCM)、多方向特征选择模块(Multi Directional feature Selection Module,MDSM)、多尺度卷积模块(Multi Scale Convolution Module,MSCM),具体如图3所示。
MDCM 是在特征图上的每一个像素点的左上、右上、左下、右下及中心五个方向的邻域做卷积运算。为了适应特征的多尺度变化,将空洞卷积加入到模型中实现MSCM。为方便起见,我们将MDCM镶嵌到MSCM中用来提取多尺度的上下文。

图3 可变向卷积网络,x表示特征相乘,CONCAT表示特征级联
网络在五个方向上产生上下文特征的同时MDSM 通过卷积以及Softmax 获得每一个特征点网络注意的方向特征,将该特征和五个方向上产生的上下文特征相乘,激活显著特征抑制干扰特征。最后将缩放后的特征和基准网络产生的特征级联进而判定类别。最后将结果上采样到原图大小得到最后的分割结果。
2.3 多方向卷积模块
多方向卷积模块(MDCM)如图4 所示,针对特征图上的每一个像素,利用卷积运算分别提取其左上、右上、左下、右下、中心方向的区域特征,每一个方向上的特征单独存储,最后将五个区域中的特征级联,得到的特征供网络后续的筛选。
假 定wc,m,n是 卷 积 核 权 重 ,x是 输 入 特 征 ,2*d+1 是感受野的大小,p 是通道数,普通的卷积操作都是中心卷积,其计算公式为
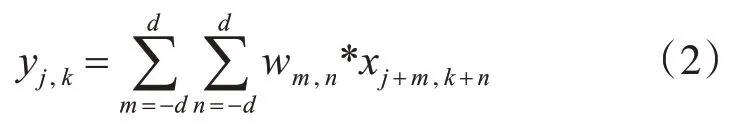

图4 MDCM模块示意图,共五个卷积分支,包括左上方向(红),右上方向(蓝),左下方向(绿),右下方向(黄),中心方向(黑色),CONV表示卷积,CONCATE表示特征级联
本文提出的多方向卷积则稍有不同,其中
左上方向的卷积计算公式为

右上方向上的卷积计算公式为

左下方向上的卷积计算公式为

右下方向上的卷积计算公式为

而中心方向上的卷积计算就是普通卷积。
相比于普通的3*3 卷积,我们在每个像素的多个方向进行3*3 卷积,扩大了特征的感受野,同时也提取了多个方向的上更丰富的上下文信息。
2.4 多尺度卷积模块
多方向卷积模块是利用一个固定尺寸的卷积核在多个方向上卷积,提取到的特征仅是单一尺度特征。为了考虑多尺度的上下文,我们提出多尺度卷积模块(MSCM)使用多种尺寸的卷积核卷积得到多种尺度的上下文,如图3中MSCM所示。
表1 多尺度卷积的卷积核参数,其中kernel size 表示卷积核的尺寸,dilation rate 表示空洞卷积的空洞比率,group 表示卷积的分组数目,field 表示感受野的大小。

表1 多尺度卷积的卷积核参数
但是较大尺寸卷积核会使模型参数急剧上升。因此,我们使用空洞卷积和分组卷积两种方式来改变这个困境,表1 给出了网络所使用的卷积核的参数信息以及卷积的感受野。
多尺度卷积模块充分考虑了对象的尺度多样性,使用多尺度卷积使得模型对尺度变化的更加鲁棒。但是多尺度卷积很有可能会带入干扰判别的上下文,所以后续提出了方向预测模块来帮助显著特征的筛选。
2.5 多方向特征选择模块
多方向特征选择模块(MDSM)是对多方向特征进行选择。特征的选择是为了更好地筛选出更加显著的上下文信息。在该模块中,模块需要预测注意的方向权重因子,方向权重因子预测完全是无监督的。通过模型自我监督实现。预测结果采用了软权重,即利用softmax 作为预测权重的后处理,将权重映射到区间(0,1)。
现设定网络的预测的权重因子张量为W,其大小为c*w*h,其中的一个像素特征e为{e1,e2,…,e3} ,那么模块的方向预测变成了对权重像素e取softmax操作,即

由于softmax 本身可微,所以模型可以实现端对端以及参数的更新。
方向权重因子预测时考虑到对象存在的尺度的多样性,加入了不同dilation rate的空洞卷积实现提取不同尺度的上下文信息帮助网络预测每一个像素点模型需要注意的方向的显著特征,具体的实现如图3 MDSM所示。
3 实验结果
3.1 数据集
实验采用PASCAL VOC2012数据集,其中包含了20 个种类的目标以及1 个背景类。数据集有1464 张图像作为训练集,1449 张图像作为验证集,以及1456 张图像作为测试集,三个数据集中各个类别数目相对平衡,数据分布相同。
3.2 实验细节
基础特征网络为resnet101[12],并在ImageNet上面预训练。学习率按照衰减,power=0.9 ,初始学习率baselr=0.0001,iter为当前已迭代次数,总迭代次数max_iter=80。模型参数的优化方法为SGD[13],采用随机水平翻转及随机缩放图像的尺寸以增广数据,输入图像采用5个尺寸,分别是[0.5,0.75,1,1.5,1.75]。
3.3 实验结果对比
实验使用 mIoU[14]作为评价标准,在 PASCAL VOC2012 上进行测试。结果本文算法在各个类别上都取得了优异的结果,具体结果如表2所示。
我们和分割领域的其他经典算法包括FCN[5]、CRF-RNN[15]、Dilation8[16]、DPN[17]、Piecewise[18]、DLC[19]、DUC[20]做了对比,对比结果如表3所示。

表2 Pascal VOC2012上的测试结果

表3 经典算法在PASCAL VOC12 测试集的分割结果对比
实验对比发现,我们的算法效果优于目前绝大部分分割算法,但是测试结果没有达到最优,PSPNet[9]是目前比较领先的算法。它们在minibatch size 为16 时,mIou 是 85.4%,由于实验条件所限导致实验的mini-batch 过小。mini-batch 的大小对网络训练结果影响较大,所以我们使用同样的mini-batch 分别在验证集进行了测试,结果如表4所示。

表4 PASCAL VOC12 数据集上的验证集上的分割结果对比
通过以上对比发现,在同等条件下,我们的算法相对目前最优的算法取得了更优的效果。
3.4 实验结果可视化
我们的算法在PASCAL VOC2012 上取得了较为优异的效果,我们在该数据集中随机挑选出几张图像和FCN对比,对比结果如图5所示。

图5 实验结果可视化对比
4 结语
本文为了更好地利用分割场景中的上下文信息,提出了基于上下文的语义分割方案:可变向卷积网络。可变向卷积网络包含三个模块:多方向卷积模块、多尺度卷积模块以及多方向特征选择模块。模型通过改变卷积的方向获取了更加显著的特征,提高了分割的效果。通过在PASCAL VOC2012上测试显示,我们的算法性能优于目前经典的分割算法。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
小哥白尼(军事科学)(2022年2期)2022-05-25
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
