
基于Word2Vec 的疫情虚假信息检测方法
2021-02-25 03:37:34齐浩翔马莉媛朱翌民
智能计算机与应用 2021年10期
齐浩翔, 马莉媛, 朱翌民
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
互联网的发展催生了微博、推特、贴吧、微信公众号等社交网络,新媒体时代人们获取信息更加便捷,但是随之而来的信息造假、虚假信息传播等问题也不容忽视。 在信息传播的过程中,如若虚假信息传播过甚,并形成一定规模的网络舆情,就可能引发群体性事件,甚至造成不可估量的后果。 在信息爆炸的大数据时代,人工识别虚假信息已然不能够满足当下需求,因此如何快速、精准地识别虚假信息是当前研究的热点之一。
识别虚假信息可以转换为文本分类问题。 对于文本分类问题的研究,大多基于传统的向量空间模型。 Salton 等人[1]提出的向量空间模型是现阶段使用最广泛的一种文本表示模型(VSM),传统的VSM模型的主要问题是维度高或者文本表示向量稀疏。降维一般从2 个方面进行,一是特征选择,二是特征提取,通过这两个方面的改进来提高文本分类的准确率。 近年来,对于文本分类大多采用主题模型(LDA),该模型由Blei 等人提出,主要优点就是能够发现语料库中潜在的主题信息[2-3];方东昊[4]利用LDA 对微博进行分类,取得了不错的效果,但该方法需要大量的外部语料,复杂度相对较高;Kim[5]提出了一种利用卷积神经网络来处理句子分类问题的模型,该方法证明了深度学习相关技术在文本分类中具有很好的效果;Mikolov 等人[6-8]提出了Word2Vec 模型用于计算文本中特征的词的分布式表示,该方法可以很好地表达句子中的语义信息,但却无法区分文本中词汇的重要程度。
针对目前虚假信息检测中存在的问题,本文提出了一种基于Word2Vec 的虚假信息检测方法。 该方法使用Word2Vec 模型表示文本,针对文本间语义相似度难以很好度量的问题,进一步引入TFIDF模型计算Word2Vec 词向量的权重,得到加权的Word2Vec 模型,一个词在不同类别中分布得越不均匀,就应该赋予较高的权值。 再将处理过后的数据输入到SVM 模型,将数据分为2 类,即:真实信息和虚假信息。 最终通过与传统方法相比较可知,本文提出的方法能够有效地提高检测精度。
1 相关工作
检测虚假信息实际是一个映射的过程,将待检测的数据集D ={d1,d2,...,dn} 映射到预定的分类集C ={c1,c2,...,cn} 中,其中n表示数据集的数量,m表示类别的数量,由于虚假信息检测结果只存在真或假,所以m =2。 本文的总体框架如图1 所示。本文采用邻近匹配算法,利用首字母索引的词典,使同一首字母下的特征词按升序排列,该方法避免了每次增加新字就要重新在字典从头匹配的冗余操作。 检测的步骤为:文本预处理、特征选择、文本表示、分类器训练。 本文拟对此展开研究分述如下。
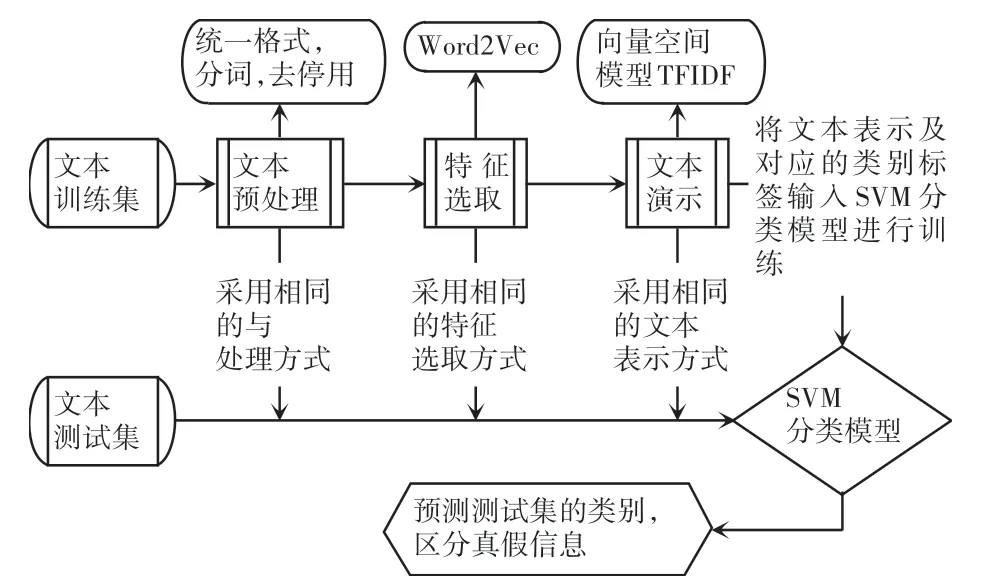
图1 总体框架Fig.1 Overall framework
(1)文本预处理。 对文本的语料库进行处理,主要包括去掉停用词、虚词、标点符号等,接着进行分词处理得到后续可以直接使用的数据。 文本分类前去停用词能够有效改善文本的分类效果,通常是指一些使用频率极高、却没有实际意义的词,例如:“的”、“了”、“我”、“吗”等,以及英文中的“the”、“a”、“of”等,还有一些数字、数学字符、标点字符[9]。
(2)特征选择。 在对文本进行预处理后,得到的数据会有很高的维度且特征相对稀疏,这就需要选出最相关的特征,且降低数据的维度。
(3)文本表示。 这个过程多是与过程(2)相结合,通过选取合适的文本表示模型将文本转化为数字表示,常用的方法是向量空间模型(VSM)。
(4)训练器分类。 选取适合当前数据的分类算法,常用的分类器有SVM,KNN 等。 首先,用训练数据集进行训练;然后,再用测试集对样本数据进行测试;最后,根据选用的评价指标来对分类效果进行衡量。
2 本文算法
2.1 特征选取
数据经过预处理后进行特征提取。 特征提取词袋模型是最早的以词为基本处理单元的文本向量化算法。 该方法容易实现,但却存在很大的问题,当面对词典中包含大量单词的时候,必然会由于维数过多而导致数据稀疏,产生数目可观的无效位置,从而影响计算速度。 由于解码后的数据也会面临词向量过于稀疏的问题,会产生很多无效位置和无标注数据。 针对这个问题,本文提出使用Word2Vec 模型来进行解决。 研究中,利用神经网络从大量的无标注数据中快速地提取有用的信息,将其表达成向量的形式,还可以反映该词汇在上下文中的关系。Word2Vec 可以将离散的单独符号转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词将被映射到向量空间中相近的位置。 而使用神经网络可以灵活地对上下文进行建模。 具体来说,输入层为One-hot vector,隐藏层为线性单元,输出层使用的是Softmax 回归。 由于文本词语之间关联紧密,使用具有上下文情境的Word2Vec 方法将词转化为向量表示,准确度更高。 本文调用gensim函数训练Word2Vec 模型,生成词向量矩阵[10]。 Word2Vec 主要包括2 种模型:Skip-gram 和CBOW。
Skip-Gram 模型设计如图2 所示。 图2 中,Skip-Gram 模型主要通过使用目标词汇来预测当前语境下的上下文词汇,简而言之就是输入为特定的词向量,输出为该词向量对应的上下文,而CBOW 模型则与Skip-Gram 模型相反,就是通过上下文信息,预测目标词汇出现的概率。 Skip-Gram 模型适用于数据集较多的情况,而CBOW 在小型数据库中有着更好的表现。 本文采用Skip-Gram 模型用于特征提取。
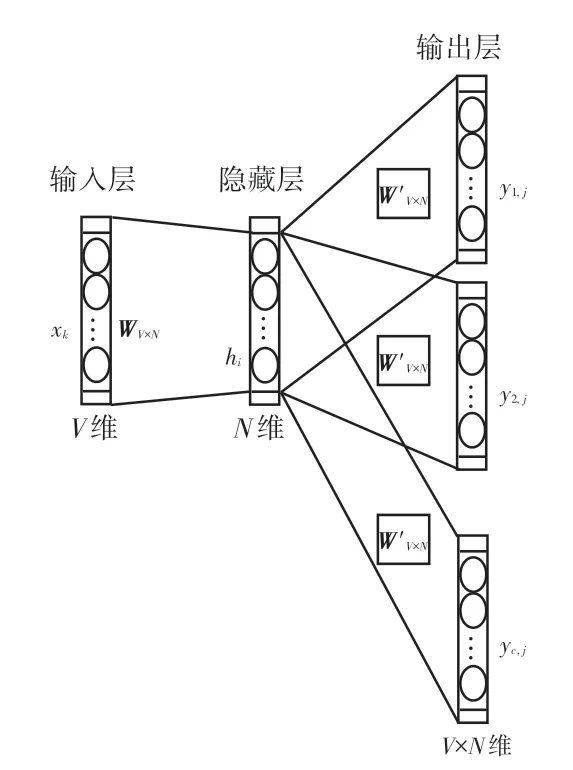
图2 Skip-Gram 模型Fig.2 Skip-Gram model
将模型输出层和隐藏层的权值表示为一个V ×N的矩阵W,W中的每一行是一个N维的向量,词典V中第i个特征词wi在W中相应的表示为vwi,假设输入层的输入x∈Rv[11],其中xk =1,xk'=0,x≠x',则隐含层可以表示为:

输出层共有C个V维向量,wc,j表示第c个向量的第j个特征词,uc,j表示隐含层到输出层第c个向量到第j个单元的线性和,yc,j表示softmax处理后的概率值。 则目标函数定义为:
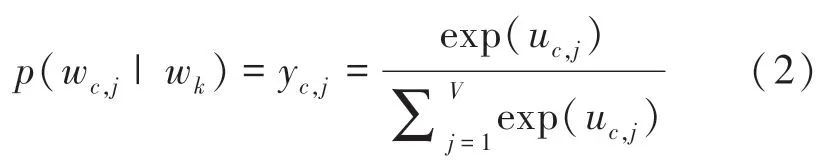
由于隐含层到输出层共享相同的权值W,可以推得:
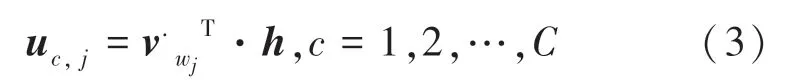
其中,v'wj为特征词wj的输出向量。
此时,目标函数更新为:
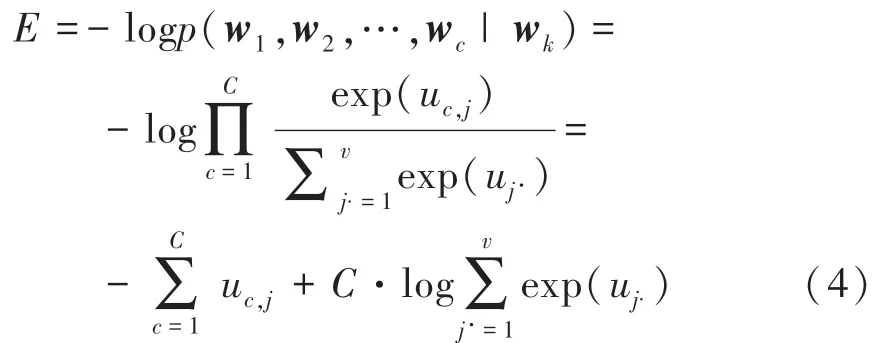
假设语料词典vocab 和文档di ={w1w2,…,wi} 文本经过Word2Vec 模型训练语料后, 得到单词词向量,将文档di的向量表示为:
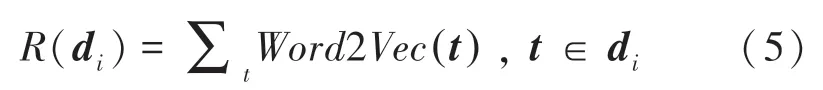
其中,Word2Vec(t) 表示词汇t的Word2Vec词向量[12]。
再引入TFIDF 模型来计算词向量的权重,由于TFIDF 模型本身不具备反映词向量分布情况的能力,所以将其与Word2Vec 模型融合,得到一种TFIDF 加权的Word2Vec 模型,将加权过后的词向量累加得到新的文档向量表示:
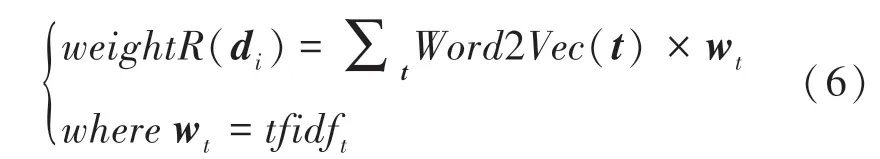
2.2 文本分类
经过数据的预处理、特征选择后,最终得到文本的向量表示。 本文选择支持向量机(SVM)模型进行分类。 SVM 是一种成熟的机器学习中的算法。多用于解决复杂的非线性分类问题,在线性不可分的情况下,SVM 通过某种事先选择的非线性映射(核函数)将输入变量映射到一个高维的特征空间,将其变为高维空间线性可分,在这个高维空间中构造最优分类超平面,因此SVM 也可称为大间距分类器:把正负样本以最大的距离分开[13]。 当训练数据线性不可分时,对每个数据样本引入一个松弛变量ζ≥0 和一个惩罚参数c≥0 后得到以下公式:
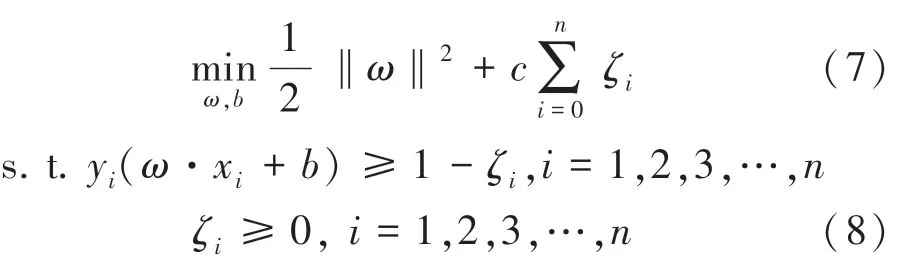
根据对偶性算法得到公式:
再利用核函数通过数据样本和相似性函数来定义新的特征变量,将原空间的数据映射到新的空间,从而训练复杂的非线性边界,本质上是将其转化为了线性问题。 其中K(xi,xj) 为核函数,本文选择高斯核函数[10]。 参数c权衡模型准确性和复杂性,c值越小,会有所下降。 参数ζ用于调整模型复杂度。ζ值越小,高斯分布越窄,模型复杂度越低;ζ值越高,高斯分布越宽,模型复杂度越大。 经过多次参数调整,确定c =2,ζ =0.1 时分类效果最优。
3 实验
3.1 准备工作
本文实验在Windows10 操作系统下进行。 为了验证本文所提出方法(The proposed Model)的有效性,本文选择传统的TFIDF 模型、LDA 主题模型和基于深度学习的Word2Vec 模型进行对比试验。
在数据集的选取基础上,本文从国内腾讯新闻平台针对此次疫情设立的辟谣板块上抓取了10 073条疫情相关样本数据,以上疫情相关数据均已表明该条数据是否属实。
在文本预处理上,本文在去掉文档的标点符号后,提取与正文相关内容,采用THULAC[14]分词工具,对正文进行分词,该分词工具具有识别能力强、准确率高、分词速度快等优点。 分词后将得到的数据输出到一个文件中供实验模型训练,通过预处理将语料库数据转化成相关模型可以直接处理的数据。
词向量的维度方面,本文分别采用S(Size)=[100,200,300,400,500]种维度进行对比实验。 最终数据将被分为2 种主题,即:真或假。
3.2 评价指标
分类的结果一般从分类器的准确度和速度两个方面来评判。 运算速度主要由算法的时间复杂度和空间复杂度决定,准确度的衡量标准为准确率(Precision)、召回率(Recall) 和F1值。 这里需用到的数学公式可写为:

其中,TP(True Positives)表示在标签中为正,实际也被分为正类;TN(True Negatives)表示在标签中为负,实际也被分为负类;FP(False Positives)表示在标签中为负,实际被分为正类;FN(False Positives)表示在标签中为正,实际被分为负类。
3.3 实验结果
各方法的准确率、召回率和F1值结果如图3 ~图5 所示。 各方法在维度为400 的情况下,基本都取得了最优效果。 由图3、图4 可以看出,LDA 主题模型相比传统的TFIDF 模型在各个维度的准确率上均有5%以上的提升,而与Word2Vec 模型相比,LDA 主题模型在准确率、召回率和F1上都有一定的差距,这也说明了,深度学习在文本分类中的有效性。 另外,本文提出的方法对比效果最好的基线方法Word2Vec 在各维度均有一定的优势,在K =400的情况下,本文提出的方法在准确率、召回率和F1上分别有着9.46%、5.47%和5.62%的提升。 这也切实说明了缺乏语义信息的TFIDF 模型与Word2Vec模型结合后,2 种模型相辅相成,能够很好地提升文本表达的效果。 从而证明本文提出的方法在对疫情虚假信息鉴别的准确度上有一定的优势。
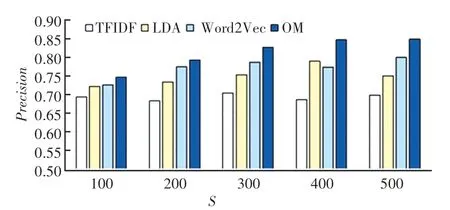
图3 各方法的准确率Fig.3 The accuracy of each method
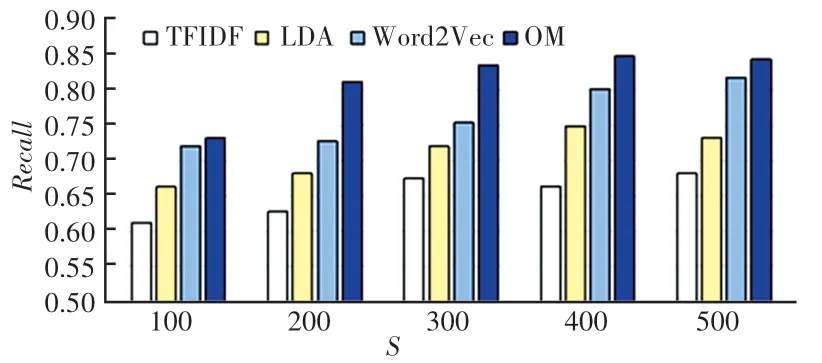
图4 各方法的召回率Fig.4 The recall of each method

图5 各方法的F1Fig.5 F1 of each method
除此之外,本文选取了传统的K 邻近(KNN)和决策树(DTC)[15]两种分类算法作为分类器的对比试验。由上文可知在维度为400 的情况下,各方法相对取得最好的效果,因此选择S =400 时,各方法在不同分类器下的F1进行对比。
各分类方法在不同分类器上的表现见表1。 由表1 可知,传统的TFIDF 模型在3 种分类器上表现的差异并不明显,这与其缺乏语音信息相关;其次可以看出,各模型在SVM 分类器上的总体表现要优于其他2 种分类器,这是由于本文的分类主题较少,对于疫情的相关信息,只能区分其真假,因此分类主题为二,而SVM 模型在面对主题少的数据时具有很好的分类效果;研究同时还发现,本文提出的方法在SVM 随着训练数据集的增加SVM 分类器上得到的准确率。 召回率和F1比KNN 分类器下的效果有5.11%、6.81%、4.19%的改进。 与DTC 分类器相比,分别有12.07%、16.97%、12.50%的提升,这是因为DTC 模型更适用于分类主题多的数据,在面对分类主题少的数据时,其表现较为普通。
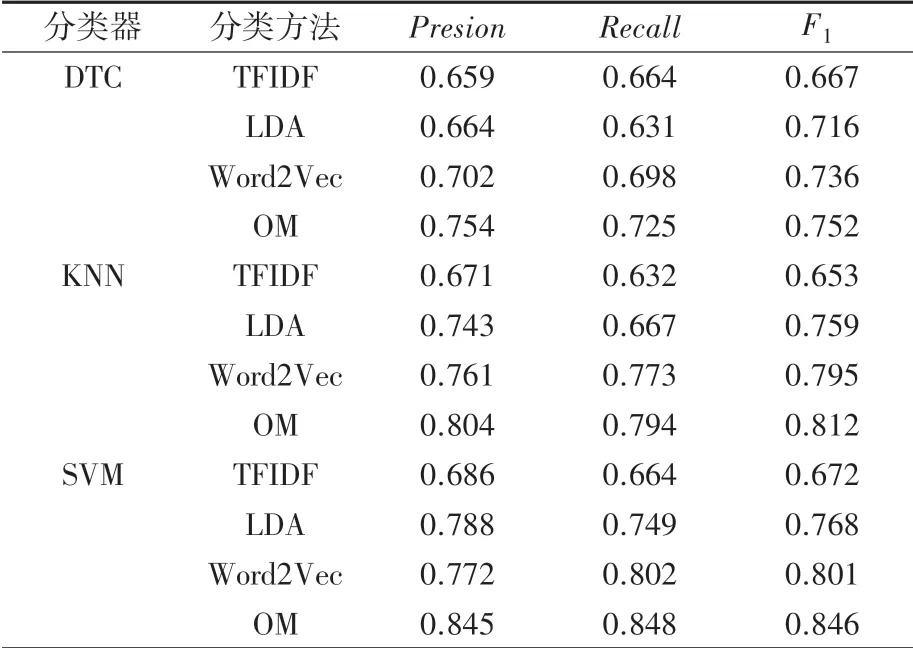
表1 各分类方法在不同分类器上的表现Tab.1 The performance of each classification method on different classifiers
通过大量的实验得出本文提出的方法相较于传统的方法,对虚假信息具有较高的识别率,具体来说在准确率、召回率和F1上均有5%以上的提升,因而具有一定的实用价值。
4 结束语
针对当下虚假信息检测时常出现的识别度低的问题,本文提出了一种基于Word2Vec 的虚假信息检测方法。 该方法利用Word2Vec 模型引入传统向量空间模型不具备的语义特征,同时解决以往向量空间模型特征稀疏的问题。 再针对Word2Vec 模型无法很好地度量文本间的语义相似度的问题,利用TFIDF 模型对Word2Vec 模型进行加权融合,最后再利用SVM 模型优越的二分类能力,以此来区分真假信息。 通过相关实验得出本文方法对虚假信息辨别有着极高的准确率,具有良好的性能。
在接下来的工作中,因为TFIDF 模型具有很强的表示文本能力,因而还需要做进一步的深入研究。所以考虑利用基于词向量距离的文本分类方法,例如用EMD 距离度量方式来平衡词与词之间的相似度。 后续也将继续探索效果更精准的疫情虚假信息的检测方法。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
