
基于改进YOLO-v3的眼机交互模型研究及实现
2021-02-24 02:20陈亚晨白雪剑陈友华赵俊奇
科学技术与工程 2021年3期
陈亚晨, 韩 伟, 白雪剑, 陈友华,3*, 赵俊奇, 阎 洁
(1.中北大学信息与通信工程学院, 太原 030051; 2.山西省视光学生物诊疗设备工程研究中心, 太原 030051;3.生物医学成像与影像大数据山西省重点实验室, 太原 030051)
随着计算机、人工智能的发展,人机交互(human-computer interaction, HCI)技术在军事、工业等领域应用愈加广泛[1]。人机交互的方式从打字、触屏、语音到视觉,交互方式的发展给人们的操作带来了便利,其中,视觉是获取信息、感知外部世界最重要的途径之一,这种交互方式具有直接性、自然性与双向性的特点[2],可以在特定场合中解放双手。因此,基于眼动信息的人机交互成为近些年人机交互领域的研究热点。按硬件结构不同,可以将眼机交互系统分为桌面式和穿戴式两类[3]。桌面式眼机交互系统对头部转动较为敏感,轻微的偏移都会导致系统精度显著下降,需要复杂的补偿算法进行头动修正;穿戴式眼机交互系统[4]具有便携性,系统与头部相对位置固定,允许头部自由运动,降低了对用户的约束,更适合室外等环境。随着应用场景的不断变化及嵌入式技术的发展,智能化、嵌入式、可穿戴的眼机交互系统在实际应用领域受到越来越多研究者关注。
在眼机交互技术中,人眼定位精度对眼行为识别的结果有显著的影响。传统的人眼定位的方法有基于几何特征、基于模板匹配、基于Hough变换等。文献[5]提出了一种基于改进Hough变换的人眼定位方法,其定位精度达到92.5%,平均耗时为178.8 ms;文献[6]提出了一种基于积分投影和模板匹配的人眼定位方法,其定位平均精度达95%,平均耗时55.78 ms;文献[7]提出了一种灰度积分投影和圆形标记法结合的人眼定位方法,其定位精度达90%,平均耗时4.05 s。以上方法在准确率方面取得了较好的结果,但要满足穿戴式眼行为的实时识别要求,定位速度和准确率都需要进一步提高。除此之外,传统的人眼定位方法描述特征过程十分烦琐,很难挖掘更深维度的图像信息,导致传统的人眼定位方法泛化性差,很难达到实时检测的目的。
随着深度学习的发展,卷积神经网络(convolutional neural networks, CNN)已经具有较强的鲁棒性,能够较强地学习图像的深层特征。文献[8]中,将R-CNN算法应用于人脸的检测,该算法的网络复杂度过高,即使使用运算速度较高的GPU也仍然运行缓慢;而以YOLO-v2、YOLO-v3为代表的YOLO(you only look once)[9]系列的算法,它是通过回归预测目标区域。该算法解决了网络复杂度过高的问题。其中,YOLO-v3是在YOLO-v2[10]的基础上提出的,是目前较为优秀的目标检测算法,在检测实时性方面表现突出。YOLO-v2已经成功应用于行人检测[11]、皮肤诊断[12]等领域,作为YOLO-v2的改进版,YOLO-v3的检测速度更快、检测精度更高。
现通过对YOLO-v3网络结构进行改进,并采用K-means聚类算法计算该模型的初始先验框参数,提高模型的特征提取细粒度,以及模型检测的速度,再结合人眼特征参数提取方法和眼行为识别算法构建了眼机交互模型并进行了实验验证。
1 眼机交互模型
由于穿戴式眼机交互系统需要具备实时性、高效等特点,现提出一种基于改进YOLO-v3的眼机交互模型,实现实时的眼行为识别。该方法的总体流程如图1所示,其包括训练和检测两个模块,检测模块包括人眼检测和眼行为识别两部分。其中,训练模块是改进的YOLO-v3网络在自制数据集上的训练过程;检测模块是实现眼行为识别的过程。该模块首先采用红外摄像头采集人眼区域图像;之后将采集的图像输入到训练好的模型中进行检测,获得人眼坐标参数及人眼图像;然后通过人眼特征参数提取获得人眼的宽和高,最后计算人眼开合度并与相对应的阈值进行判别,从而实现眼行为的识别。
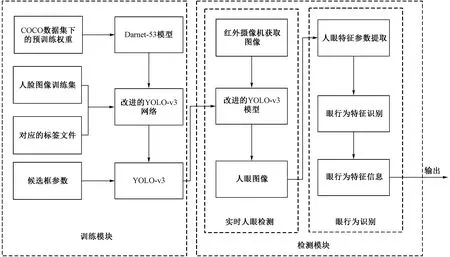
图1 模型总体流程图Fig.1 Overall flow chart of the model
1.1 改进的YOLO-v3人眼检测模型
1.1.1 网络结构
网络结构如图2所示。其骨干模型框架使用由一系列3×3和1×1的卷积层组成的Darnet-53结构。该网络结构划分了大小为104×104、52×52、26×26的特征图,删减了大型尺度特征。其中包括20个残差模块,分别为4×、4×、4×、8×残差块的4组网络,与原YOLO-v3中1×,2×,8×,8×,4×残差块的5组网络相比,增加了残差连接结构的数量,提升了深层网络的细粒度,通过深层网络通道向上采样,丰富浅层的特征信息,提升人眼目标检测的精度。
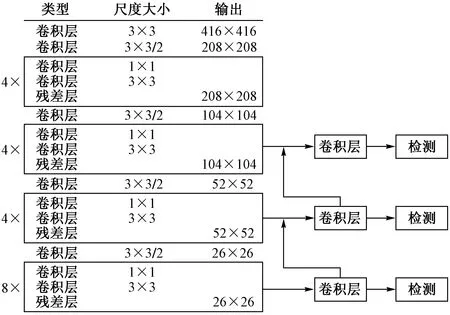
图2 改进YOLO-v3网络结构Fig.2 The improved network structure of YOLO-v3
1.1.2 优化初始先验框
YOLO-v3在目标检测过程中引入初始先验框(anchor box),其性能优劣直接影响到目标框位置的精度。为了得到最优的初始先验框参数,采用K-means聚类算法在自制数据集上计算初始先验框。K-means 聚类算法是以距离作为数据对象间相似性度量的标准, 从而实现数据划分的聚类算法。其中,典型的是以欧式距离作为相似度测度。该算法首先在数据集中随机选取k个聚类中心;之后遍历数据集中所有数据与每个聚类中心点的距离,将每个数据分别划分到距离最近的中心点所在的集合中[13];然后求每个聚类集合的所有数据各个维度[14],求得的值为新的聚类中心;重复上述过程直到聚类中心位置不再发生改变或者到达设定的迭代次数。
而在YOLO-v3算法中,从数据集的标注框中聚类出的初始候选框并不是使用欧式距离获得,而是通过交并比(intersection over union,IOU)计算标注框之间的距离,IOU越大代表标注框之间的距离越小。计算公式为
d(box,centroid)=1-IOU(box,centroid) (1)
由K-means聚类算法得到平均IOU与锚点框(anchor)个数的关系,如图3所示。
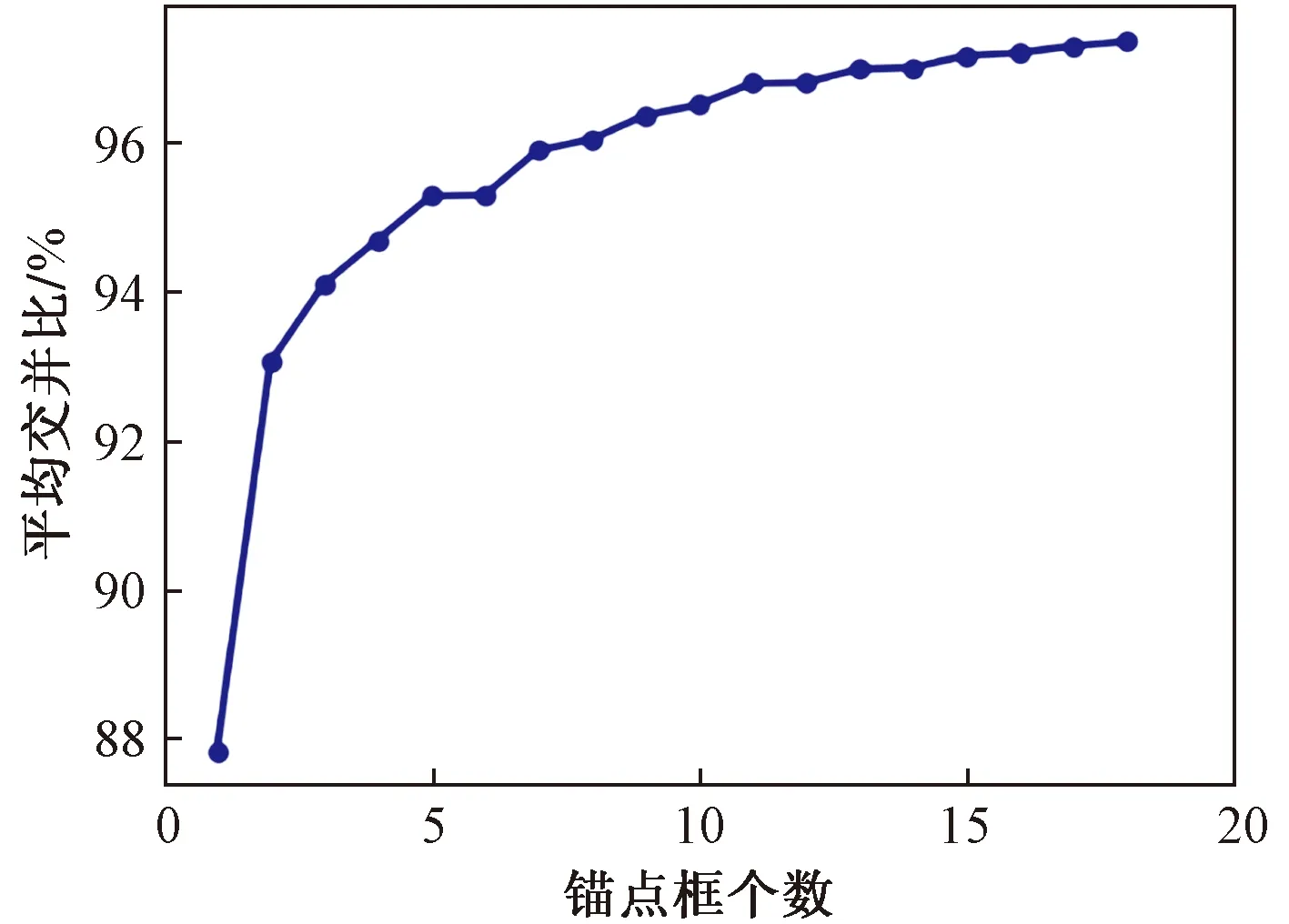
图3 平均交并比与锚点个数的关系Fig.3 The relationship between the average IOU and the number of anchor points
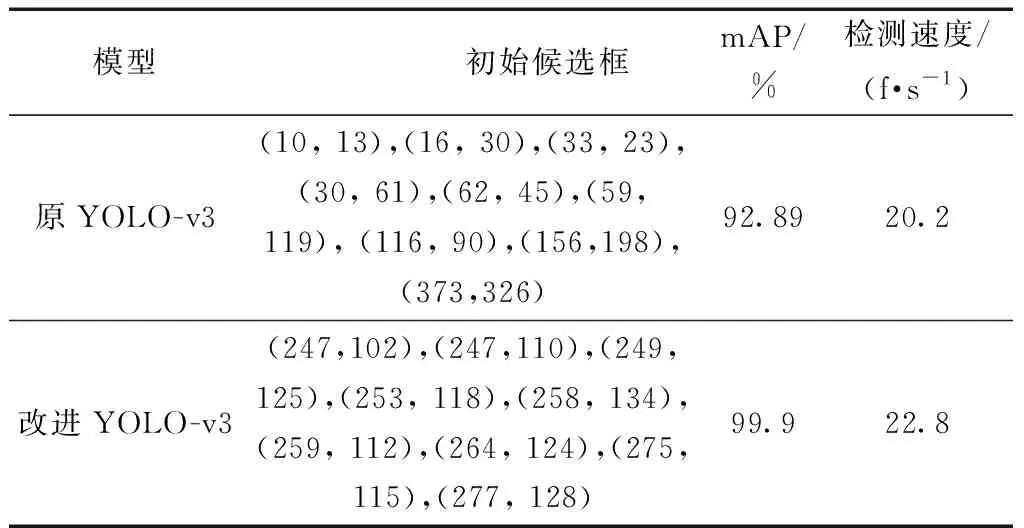
由图3可见,平均交并比随锚点个数(k)增大而增大。在锚点框个数大于9之后,曲线增长趋势相对平缓,考虑网络的计算成本,将初始先验框个数设置为9。经计算,初始候选框分别为(247,102)、(247,110)、(249,125)、(253,118)、(258,134)、(259,112)、(264,124)、(275,115)、(277,128)。
1.1.3 模型训练
1)训练环境配置及数据集制作
本文模型训练环境配置如表1所示。制作数据集的具体步骤如下:①使用外接USB红外摄像头实时拍摄,获得基础图象,共1 600张。②对其中采集的1 200张基础图象采用翻转、缩放、亮度变换等方法进行数据增强[13],生成1 800张图像。③使用LabelImg工具按VOC格式对基础图像进行标记,生成XML文件。④读取XML文件,计算经过数据增强的图像的标注数据。⑤将生成的所有的数据按照90%、10%的比例分割为训练集和验证集;将剩余的400张基础图像作为测试集。人眼数据集如表2所示。

表1 模型训练实验环境配置Table 1 Configuration of model training experimental environment

表2 人眼目标检测数据集
2)训练过程
由于目前公开的不同眼行为数据集较少,故在数据增强的基础上使用迁移学习提高算法的泛化性。现将YOLO-v3在COCO数据集上训练获得的预训练权重模型加载到改进的YOLO-v3网络中并在自制数据集上进行训练。在训练过程中,以416×416的图像作为输入,经多次实验分析,设置batch size为4,初始学习率为0.001,权重衰减正则项为0.005,最优化动量参数为0.9。首先冻结前228层进行训练,迭代500次。经过一段时间训练后,损失值降到15附近。然后在此基础上解冻所有层继续训练,进行微调,再迭代50次。当迭代到520次时,如图4所示,Loss曲线降到7附近并趋于平缓。
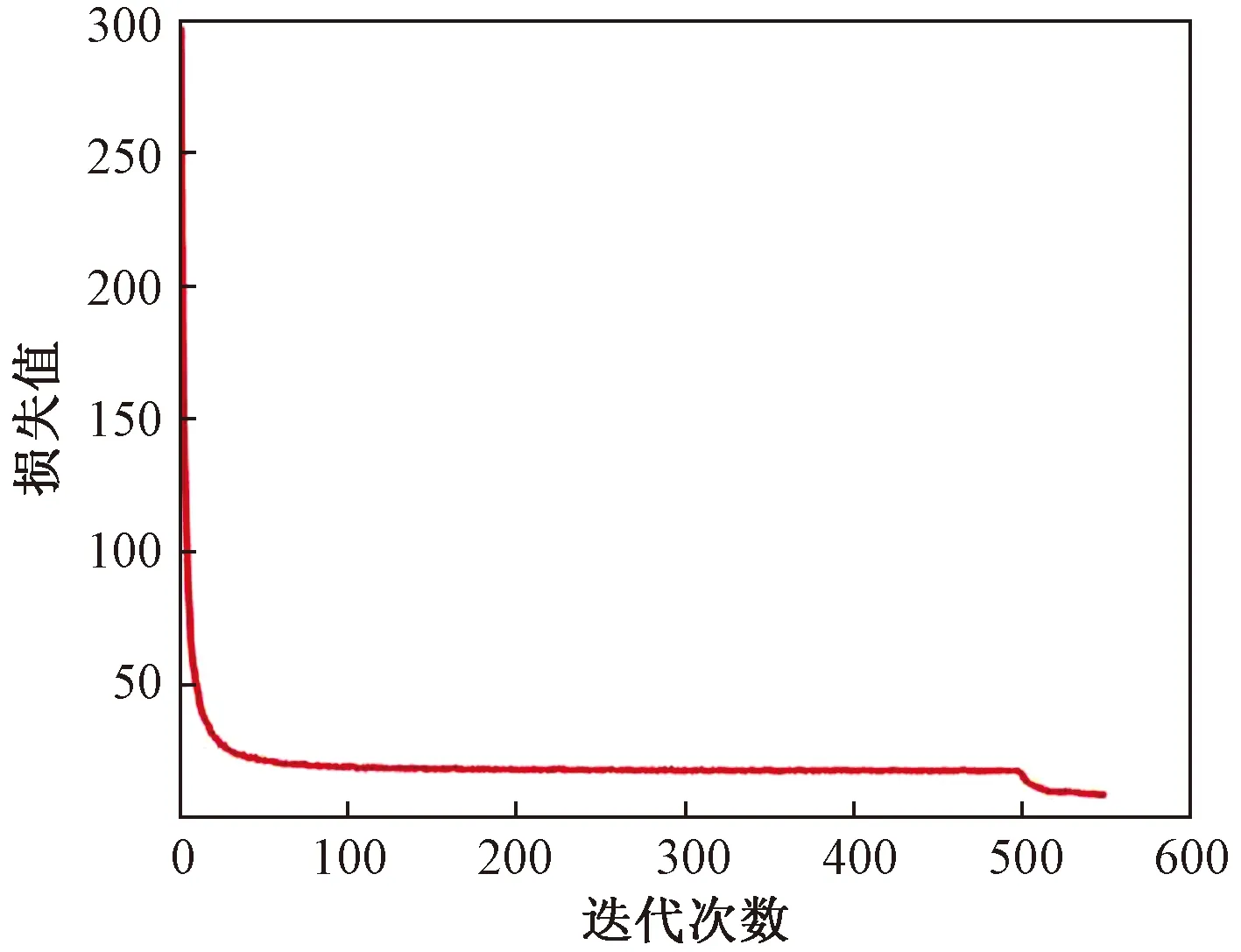
图4 网络训练损失曲线Fig.4 Network training loss curve
1.2 人眼特征参数提取
在上述训练好的模型的基础上,将采集的图像作为模型的输入进行检测,获得人眼图像。基于图像灰度特征的特点,采用矩阵遍历法提取人眼特征参数。该方法通过扫描二值图像的每个像素点获取人眼边界点,并利用边界点计算人眼的宽和高。其中,二值图像是对上述人眼图像采用最大类间方差和腐蚀运算的预处理方法获得[15]。
如图5所示,具体步骤如下。
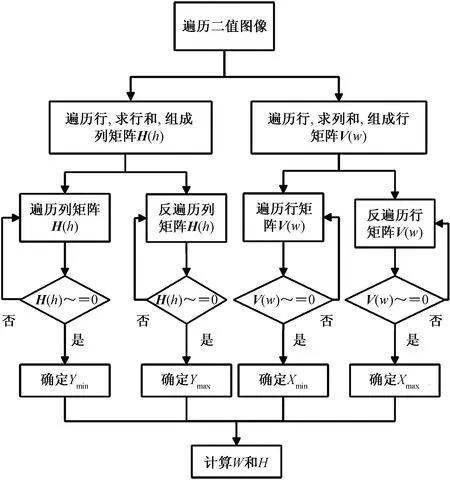
图5 提取人眼特征参数流程图Fig.5 Flowchart for extracting eye feature parameters
(1)将所述图像矩阵设为A(m,n)。遍历图像矩阵A(m,n)的行时,计算行和,组成新的列矩阵H(h);遍历图像矩阵A(m,n)的列时,计算列和,组成新的行矩阵V(w)。
(2)根据列矩阵H(h)得到其逆矩阵q(h),根据行矩阵V(w)得到其逆矩阵p(w),分别遍历矩阵H(h)、q(h)、V(w)和p(w)。
(3)遍历过程中,作如下判断:
当H(h)≠0,则Ymin=h;
当q(h)≠0,则Ymax=m-h+1;
当V(w)≠0,则Xmin=w;
当p(w)≠0,则Xmax=n-w+1。
此时,可以获得人眼的边界坐标Ymin、Ymax、Xmin、Xmax。
根据上述坐标及式(2)计算人眼宽和高,即

式(2)中:H为人眼上下眼睑垂直距离,即为人眼的高;W为人眼两个眼角间的水平距离,即人眼的宽。
1.3 眼行为识别
将人眼行为分为睁眼、眯眼和闭眼三种,并将其特征抽象成开合度(RHW),以便进行量化处理。采用眼行为识别算法对不同眼行为特征进行识别,具体过程如下。
(1)阈值T1、T2的选取。通过系统刚打开时采集连续若干帧图像,统计所有的睁眼的开合度和闭眼的开合度,计算其最小值与最大值,T1、T2的计算方法为
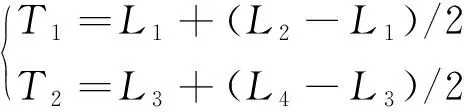
式(3)中:L1为睁眼的开合度的最小值;L2和L3为眯眼的开合度的最小值和最大值;L4为闭眼状态的开合度的极大值。
(2)开合度的计算。根据上述所获得的人眼的宽(W)和高(H)计算人眼的宽高比,即开合度(RHW),计算方法如式(4)所示。
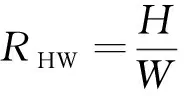
(3)不同眼特征行为的判别。根据(1)、(2)获得的阈值及人眼开合度,做如下判断:
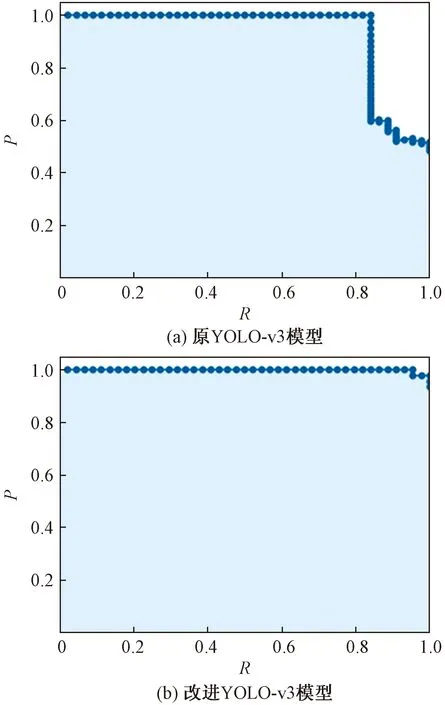
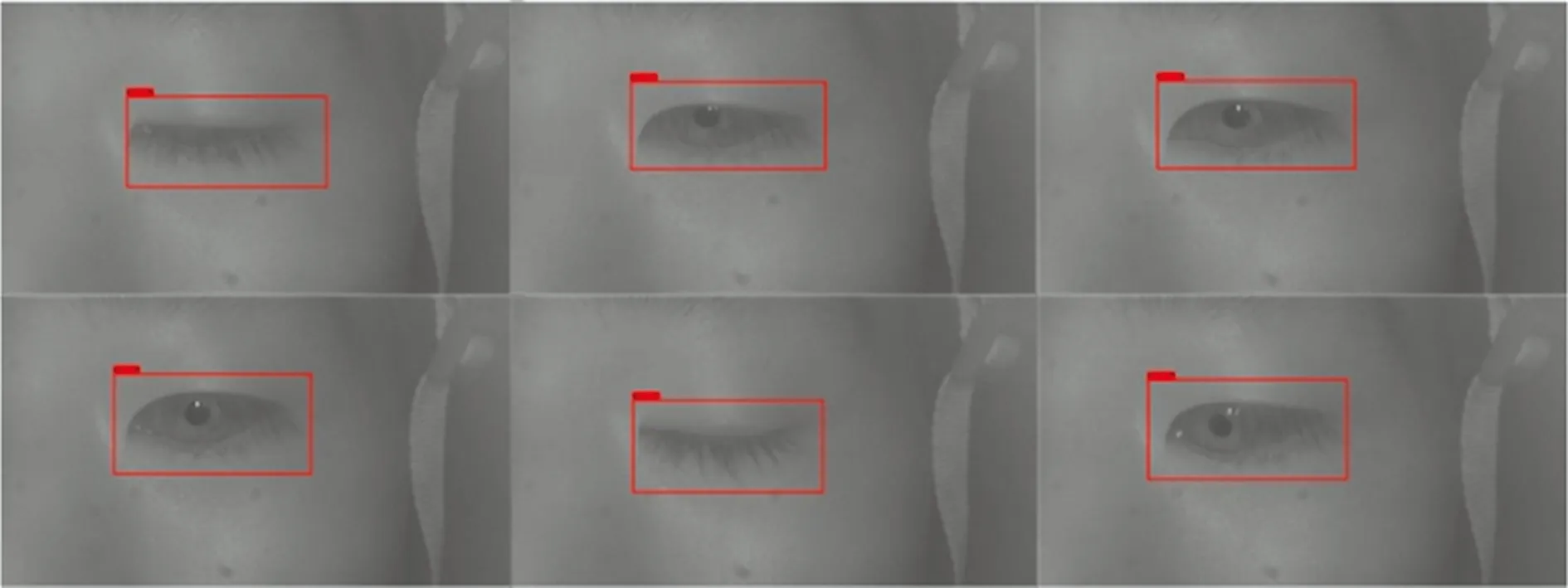
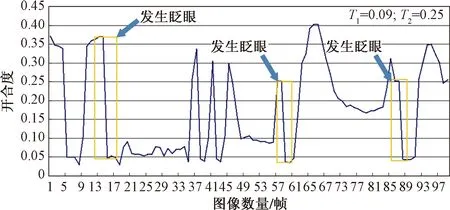
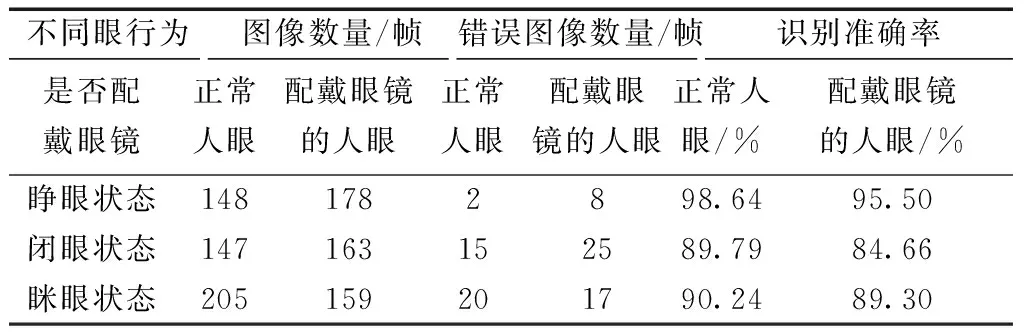
①当RHW ②当T1 ③当RHW 另外,判别眼特征行为过程中,人眼的自然眨眼行为也会产生开合度的变化,从而对人眼特征产生干扰和误判。因此,在人眼识别过程中,需要对眨眼行为进行检测与剔除。眨眼被定义为上眼睑的快速闭合和打开,在这个过程中人眼的开合度会发生明显的变化。因此,通过相邻3~4帧左右图像的对比,即可进行剔除,最终实现眼行为的识别。 2.1.1 评价指标 在实验中,采用平均检测准确率(mean average precision,mAP)和检测速度评判模型的检测效果。 FPS是评估模型检测速度的常用指标,FPS越大代表模型检测速度越快,计算方法如式(5)所示。mAP是目标检测中衡量检测精度的常用指标[16],指多个类别的平均精确度的平均值,该值越大代表模型的总体检测准确率越高,计算方法如式(6)所示。其中,AP指单个类别的平均精度。同时,AP是P-R(precision-recall)曲线围成的面积,P-R曲线是以准确率(precision)和召回率(recall) 作为横、纵坐标的二维曲线,计算方法如式(7)所示。 式中:c为分类个数;当c=1时,mAP=AP。 2.1.2 测试结果 为了测试改进YOLO-v3模型人眼检测的效果,将原YOLO-v3模型作为对比模型,分别使用原YOLO-v3模型和改进YOLO-v3模型在自制人眼数据集上进行测试,测试结果如表3所示,在自制人眼数据集上的P-R曲线如图6所示。其中,设置IOU阈值为0.5,置信度阈值为0.45。 表3 检测对比结果 图6 在数据集上的P-R曲线Fig.6 P-R curve on datasets 由表3可知,改进YOLO-v3在单目标检测速度上提高了2.6 f/s,同时获得99.9%的mAP,比YOLO-v3提高了7.19%。可以看出改进YOLO-v3模型在平均精度上和检测速度上均有所提高,满足实时性的要求。 随后,输入300帧640×480的视频数据到本文模型中,对每帧图像进行人眼检测,部分检测结果如图7所示。 图7 模型测试效果图Fig.7 Model test effect diagram 完成上述模型性能评估,获得性能较好的模型之后,穿戴式眼机交互设备采用基于RK3399嵌入式平台的Linux操作系统,选用60°无畸变的外置USB红外摄像机采集不同情况(是否佩戴眼镜)的视频数据,之后将图像输入训练好的模型进行人眼检测获得人眼位置坐标以及人眼图像,然后对人眼图像进行眼行为特征识别。 识别眼特征行为过程中,由于人眼的自然眨眼行为也会产生开合度的变化,因此实验过程中对眨眼行为进行检测。图8为其中连续100帧图像的人眼开合度变化曲线,黄色的框表示发生了眨眼行为;开合度大于0.25的区域为睁眼状态;开合度小于0.09的区域为闭眼状态;当相邻3~4帧图像的开合度突然发生变化时,则发生了眨眼。图8中发生了3次眨眼行为。 图8 眨眼检测结果Fig.8 Blink detection result 在上述实现眨眼检测与剔除的基础上,分别对正常人眼图像和配戴眼镜的人眼图像进行识别。识别结果如表4所示。部分识别结果如图9、图10所示。图9(a)、图9(b)和图9(c)分别代表睁眼、眯眼、闭眼三种不同状态下的眼行为的识别结果;图10为被测者配戴眼镜的情况下,对不同状态的眼行为(睁眼、眯眼、闭眼)的识别结果。蓝色的方框表示识别到人眼区域。图9、图10体现了该眼机交互模型可以实现对佩戴眼镜的人眼图像和正常人眼图像的不同的状态的眼行为的识别。 表4 不同情况下识别准确率结果 图9 不同状态正常人眼的识别结果Fig.9 Recognition result of normal eye in different states 图10 不同状态佩戴眼镜的识别结果Fig.10 Recognition results of glasses-wearing eye in different states 由表4可知,本文模型检测不同情况下的睁眼状态的识别准确率为96.93%;眯眼状态的识别准确率为87.09%;闭眼状态的识别准确率为89.83%;总体识别准确率达到91.30%。综上,该模型可以较好地识别不同眼行为。 研究了YOLO-v3网络的特点,根据所检测图像特点,通过对其进行改进并进行训练获得改进YOLO-v3模型,再将其与人眼特征参数提取方法和眼行为识别算法结合,构建一种眼机交互模型并进行实验。实验结果表明,改进YOLO-v3模型的mAP为98.6%,识别速度达22.8 f/s,相比原YOLO-v3方法训练时间缩短了11.4%。同时,该模型的总体识别准确率达到91.30%。本文模型为嵌入式眼-机交互设备提供了必要的算法保证。2 实验结果及分析
2.1 模型检测结果及分析



2.2 眼机交互模型检测结果


3 结论
猜你喜欢
东坡赤壁诗词(2022年3期)2022-05-29健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27健康体检与管理(2021年10期)2021-01-03现代计算机(2018年27期)2018-10-25舰船电子对抗(2017年6期)2018-01-11优雅(2016年12期)2017-02-28电影故事(2016年5期)2016-06-15互联网天地(2016年1期)2016-05-04
