
DSconv-LSTM:面向边缘环境的轻量化视频行为识别模型
2021-02-24 02:29翟仲毅赵胤铎
中国传媒大学学报(自然科学版) 2021年6期
翟仲毅,赵胤铎
(桂林电子科技大学广西可信软件重点实验室,广西 桂林 541004)
1 引言
随着物联网和边缘计算技术的发展,许多嵌入式设备已经具备了较强的计算能力。边缘计算正在成为物联网数据处理的重要组成部分。此外,随着物联网设备的激增,网络边缘会产生大规模的感知数据。在大数据技术的推动下,边缘智能正在逐渐形成,即通过有效结合边缘数据和AI 技术在本地完成计算并快速有效地提供智能服务[1]。在边缘智能服务中,传感器数据由本地负责收集和处理,从而减少了对网络资源的需求。与云服务相比,边缘智能服务可以提高物联网环境下计算的实时性,避免浪费网络带宽资源。
智能摄像机是具有代表性的智能边缘产品,能够为智能家居、智能交通、智能监控等领域提供视频处理服务。智能摄像机服务通常需要从摄像机获取实时视频数据,并进行一系列视频帧处理操作,然后进行相应的行为识别。这意味着摄像机需要为这些服务提供相应的存储和计算资源。由于智能摄像机的资源限制,较多的行为识别模型[2]-[3]很难在本地托管并进行行为识别。这是由于常见的行为识别模型通常采用重量级的深度学习模型,计算复杂度较高且规模大。为了将行为识别服务引入边缘环境,通常需要降低学习模型的计算复杂度,从而减轻对本地设备的资源消耗。
本文提出了一种轻量级的学习模型,用于对边缘视频流中的目标行为进行识别。该动作识别模型主要基于DSconv-LSTM 和自注意机制(Self-attention Mechanism)。DSconv-LSTM 主要结合卷积LSTM(Conv-LSTM)和深度可分离卷积(Depthwise-Separable convolution,DSconv)进行设计。与Conv-LSTM[12]相比,DSconv-LSTM 采用了一系列轻量级学习单元,通过深度可分离卷积运算[15]处理LSTM 中四个门的时空数据流。
最后,在UCF-11[12]和Olympic-sports[13]两个公共视频数据集上进行了一系列实验来评估DSconv-LSTM 的性能和效果。结果表明:DSconv-LSTM 能快速收敛到最优模型,并保持较高的识别精度。与Conv-LSTM 相比,DSconv-LSTM 的模型规模减小了约三倍,推理时间缩短了约50%。
2 相关工作
行为识别是计算机视觉领域一项常见的研究内容。随着深度学习的快速发展,许多学者都在关注视频行为的深层特征提取,以及行为分类模型和识别方法。双流融合模型(Two-Stream Fusion,TSF)[2]就是一种动作识别框架。TSF结合时空网络,将RGB图像和光流分别用卷积神经网络(Convolutional Neural Network,CNN)进行空间和时间的建模,然后进行融合得到最终结果。双流体系结构具有较好的分类效果,后续有许多工作在此基础上进行了相关的研究。Zheng等人[3]提出了一种用于视频分类的混合深度学习模型,该模型首先使用卷积LSTM 提取空间特征和短时记忆特征,接着通过注意力机制赋予不同权重来区分不同时刻序列的重要性,最后采用双向LSTM 提取周期特征。Wang 等人[4]提出了一种基于随机抽样方案的分类模型,称为时间段网络(Temporal Segment Network,TSN),通过对视频端进行分段和随机窗口采样,降低了提取长程时间关系的计算量。为了进一步提高TSN 的性能,Zhou 等人[5]中提出了一种多尺度采样和融合框架。
为了更直观的捕获视频中的时空特征,基于3D卷积的行为分类模型被较多人研究。文献[6]提出了一种基于3DCNN(3D Convolution,C3D)的分类模型,可以通过卷积操作对空间和时间进行建模。由于额外的核维数,C3D 具有大量的参数和计算开销。文献[7]提出了一种膨胀3D 卷积(Inflated 3D ConvNet,I3D),通过在时域上进行额外的卷积运算,而不是直接使用3D 内核,以减小网络的规模。Fan 等人[8]提出了RubiksNet,通过一种3D 时空移位操作,减少了卷积计算次数。Dong 等人[9]提出了AR3D,通过构建一种注意力残差网络,减少了3D 卷积的计算量,提升了模型的性能。
鉴于光流和3D 卷积都需要较大的计算量,Lin 等人[10]提出了时间移位模型(Temporal shift module,TSM),通过将相邻帧的特征值移位,交换不同时刻视频帧之间的特征图,实现时间特征的提取,进而可以使用2D 卷积来进行行为识别。相较于3D 卷积的模型,TSM 在推理速度和准确率方面都有显著提升。Wang L 人[11]等提出了时间差分网络(Temporal Difference Networks,TDN)模型,采用RGB 差分的方法融合时间特征,并通过2D卷积进行行为识别。
3 DSconv-LSTM
3.1 模型架构设计
本小节主要利用DSconv-LSTM 和自注意力机制设计了一个行为识别模型。图1 给出了分类模型的架构,主要包括:数据源模块、RGB 视频数据模块和DSconv-LSTM 模块三部分。数据源模块负责获取边缘环境(如智慧家居、智慧交通等)下RGB 视频信息,并进行视频帧的预处理。RGB 帧模块主要通过VGG-16[14]或VGG-19[15]进行特征提取。由于视频是一种时空特征数据,需要通过Dsconv-LSTM 模块对时间进行建模,接着通过自注意力模块提取特征映射,最后给出识别结果。

图1 边缘行为识别系统
3.2 Dsconv-LSTM 单元
DSconv-LSTM 单元将深度可分离卷积(DSconv)用于处理Conv-LSTM学习单元四个门的时空数据。
Dsconv 主要有Dconv 和Pconv 两个子操作组成,如图2所示。

图2 DSconv结构
DSconv 首先使用Dconv 进行空间建模,然后使用Pconv 进 行 时 间 建 模。Conv、Pconv、Dconv 和DSconv的数学公式分别如下:

在公式(1)、(2)、(3)和(4)中,W、W p和W d分别是Conv、Pconv 和Dconv 的卷积核。K,L和M分别代表卷积核的宽度,高度和卷积核个数。(i,j)是每次卷积操作的起始位置,x是输入数据,⊙表示矩阵对应元素相乘。虽然DSconv 需要两步来处理所有输入数据,但可以减少卷积的许多参数和计算。
DSconv-LSTM 学习单元也有四个门来处理数据输入,这与Conv-LSTM 学习单元类似,如图3 所示。DSconv-LSTM学习单元的数学表示如下:
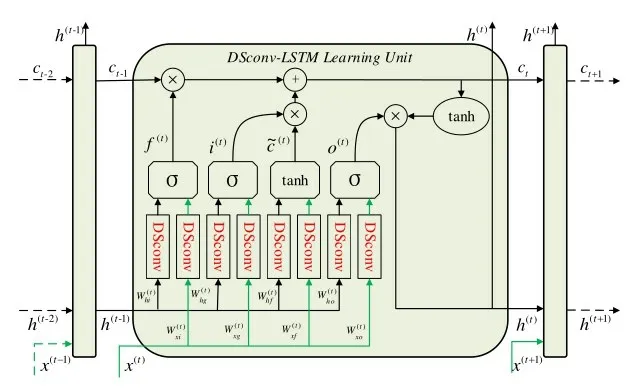
图3 DSconv-LSTM 学习单元
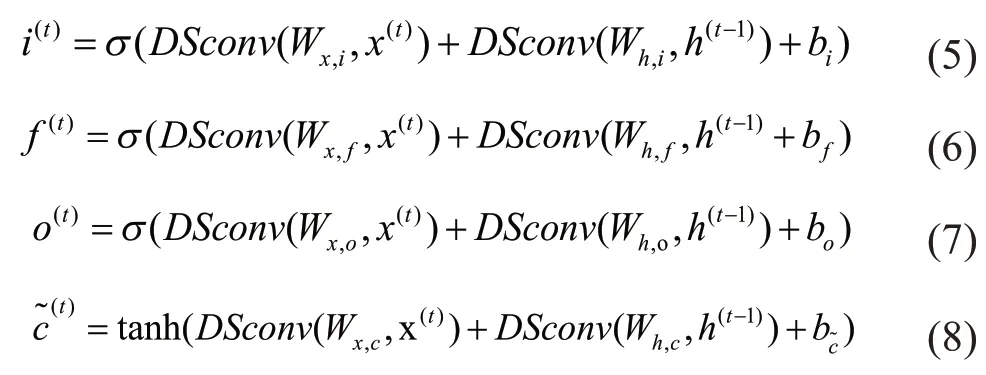
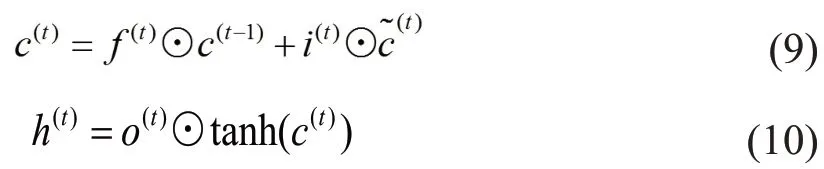
Dsconv-LSTM学习单元在t时刻的四个门分别
表示输入门i(t),遗忘门f(t),输出门o(t)以及输入调整门。x(t),c(t)和h(t)分别表示t时刻的输入数据,细胞状态和隐藏层状态。Wx,i,Wx,f,Wx,o,Wx,c与Wh,i,Wh,o,Wh,c,Wh,f分别代表Dsconv 的i(t),f(t),o(t),关于x(t)和h(t)的卷积核。bi,b f,bo,分别表示i(t),f(t),o(t),的偏置。σ和tanh 分别表示Sigmoid激活函数和双曲正切激活函数。最后,可以将多个DSconv-LSTM学习单元构成单层或多层结构,其中单层结构如图3所示。
3.3 自注意力机制
在传统结构中,LSTM 输出的最后一个特征映射会被用于数据处理的下一阶段。然而,这种方法可能会丢失许多重要的特征图,从而影响行为识别的准确性。这里采用自注意力机制来解决这个问题。自注意力机制可以提取DSconv-LSTM 输出的特征映射中最重要的特征,数学表示如下:
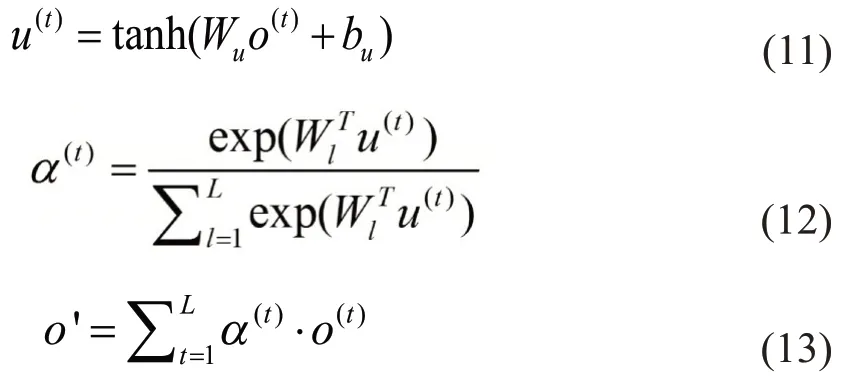
其中,o(t)表示Dsconv-LSTM 学习单元在t时刻的输出。Tanh(·)表示双曲正切激活函数。自注意力机制首先通过公式(12)计算每个输入u(t)的权重α(t)。exp(·)表示指数函数。o'表示自注意力,即权重α(t)和输入u(t)之间的线性组合。
4 实验
4.1 数据集和实验环境
本节主要介绍用到的数据集和实验环境。模型将通过UCF11和Olympic-sports两个公开数据集进行训练,如表1所示。实验中,两个数据集被随机分为70%的训练集和15%的测试集和15%的验证集。基于Tensorflow构建了DSconv-LSTM模型和Conv-LSTM模型,GPU采用了两个16G内存的Tesla P100-PCIE。

表1 UCF-11数据集和Olympic-sports数据集
4.2 模型参数设置
为了减少不同参数设置对结果的影响,实验将两个模型中除了卷积核之外的大多数参数都设置为相同的值,如表2所示。
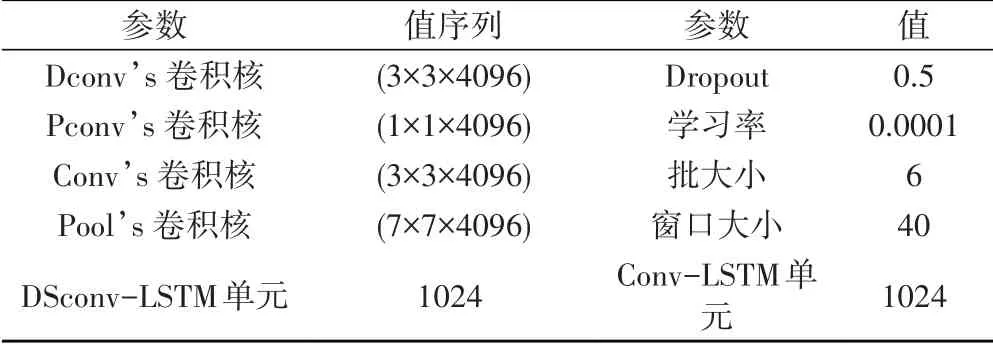
表2 模型参数设置
在DSconv-LSTM 模型中,Dconv 和Pconv 卷积核分别设置为(3×3×4096)和(1×1×4096)。 在Conv-LSTM 模型中,Conv 的滤波器设置为(3×3×4096)。两个模型的Dropout 和最大池的滤波器分别设置为0.5和(7×7×4096)。此外,模型的学习率、批大小和帧窗口大小分别设置为0.0001,6 和40。DSconv-LSTM 单元和Conv-LSTM 单元的个数都设置为1024。本实验使用Vgg-16 和Vgg-19 从视频中提取特征图,以便观测不同预处理方法的影响。
4.3 实验结果与分析
实验从性能和效果两方面对模型进行了评价。其中,表3 展示了DSconv-LSTM 和Conv-LSTM 模型的大小,参数个数和推理时间。相比于Conv-LSTM,DSconv-LSTM 的模型大小和参数个数减少了约3倍,推理时间减少了约50%。

表3 模型性能的对比
图4 展示了不同预处理方法和数据集下Conv-LSTM 模型和DSconv-LSTM 模型对于测试精度和训练时间之间的关系。从图4 可以看到,不同的预处理方法对模型训练有一定影响,但DSconv-LSTM 模型在两种条件下都波动较小,并可以快速收敛到最优模型。此外,与Vgg-16 相比,Vgg-19 的特征提取对模型性能有更高的提升。表4 展示了两种模型在不同预处理模型和数据集下行为识别的准确率。对于UCF-11 数据集和Vgg16 预处理模型,DSconv-LSTM 的识别准确率为92.5466%,与Conv-LSTM 模型相比,准确率高了0.1553%。对于UCF-11 数据集和Vgg-19 预处理模型,DSconv-LSTM 模型的最高测试精度为93.6335%,比Conv-LSTM 提高了1.2421%。对于Olympic-sports 数据集和Vgg16 预处理模型,DSconv-LSTM 模型的识别精度为63.1902%,比Conv-LSTM 提高1.227%。对于Olympic-sports 数据集和Vgg-19 预处理模型,DSconv-LSTM 模型的最高测试精度为71.7791%,比Conv-LSTM 模型提高了3.6809%。这表明DSconv-LSTM 模型识别精度仍保持了较高水平。

表4 识别效果评价
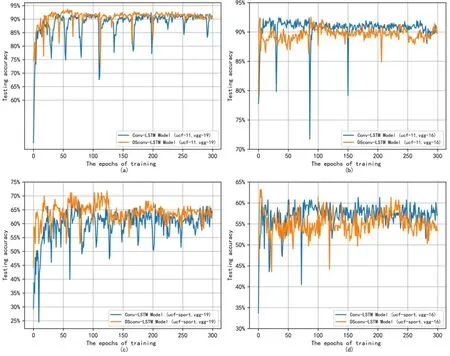
图4 Conv-LSTM 和DSconv-LSTM 模型的准确性。
综上可见,DSconv-LSTM 可以快速收敛到最优模型,并保持较高的识别准确率。与Conv-LSTM 相比,DSconv-LSTM 的模型大小减少了约3 倍,推理时间减少了约50%。
5 结论
本文提出了一种基于DSconv-LSTM 的轻量级视频行为识别模型,可以在边缘设备上进行应用。与Conv-LSTM 模型相比,DSconv-LSTM 不仅可以保证行为识别的准确性,并减小了尺寸和参数数量,而且可以快速收敛,降低模型训练和推理的时间。该框架的不足之处是:预处理方法仍需要大量的时间和计算资源从视频中提取特征图。后续工作将关注预处理优化技术,进一步提高动作识别的实时性,以及减少资源消耗。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
材料与冶金学报(2022年2期)2022-08-10
纺织标准与质量(2022年3期)2022-08-10
健康体检与管理(2022年4期)2022-05-13
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
建材发展导向(2021年23期)2021-03-08
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
