
基于自增强泊松过程的COVID-19疫情预测
2021-02-24 02:29:44刘元浩曹婍沈华伟黄俊杰程学旗
中国传媒大学学报(自然科学版) 2021年6期
刘元浩,曹婍,沈华伟,黄俊杰,程学旗
(中国科学院计算技术研究所数据智能系统研究中心,北京 100190)
1 引言
自2019年底以来的几个月内,新型冠状病毒肺炎COVID-19 在全世界范围内广泛流行,截至2020 年4月7 日,全球COVID-19 累计确诊人数已达1,279,722例,并仍在持续快速增长。疫情的持续蔓延对人们的生命安全造成巨大威胁,也对国家医疗建设、物资调配、隔离管控等方面带来挑战。在此背景下,采用数学方法对疫情传播进行建模并对确诊病例数的增长进行及时准确地预测对于疫情防控具有重要意义。一方面,对疫情传播进行准确预测,对于医疗卫生资源的分配、防控重点的调整等具有重要的参考价值。另一方面,在防疫工作进行过程中的重要时间节点前后,对确诊病例数增长趋势的变化进行对比,能够有效地对防控措施有效性进行合理评估。
对于疫情传播预测,最常用的研究框架是传染病模型。传统的常微分方程传染病模型假设人群总数恒定且人群均匀混合[1],通过对人群中处于各个状态的人数及各状态间的相互转换速率进行建模,推算疫情发展走势。常见的传染病模型根据人群划分的不同及人群转换的不同,包括SI[2]、SIS[3]、SIR[4]、SEIR[5]等。传染病模型从传染病传播动力学的角度进行考虑,能对疫情短期内发展趋势进行较好的模拟,但其总人数恒定且人群均匀混合的理想化假设使其应用场景受到局限。
疫情感染人数预测的另一方法是时间序列预测。疫情传播情况会随着时间推移而不断演变,疫情感染人群数可以形式化为一种时间序列,并采用时间序列分析与建模的方式进行预测。线性时间序列分析模型包括自回归(Auto-regression)模型和移动平均(Moving Average)模型[6],以及基于两者组合而成的自回归移动平均(Auto-regression Moving Average)模型[7]。向量自回归(Vector Autoregressive)模型等非线性时间序列模型以及基于深度神经网络的RNN[8],LSTM[9],TCN[10]等模型也在时间序列分析问题上有优秀的表现。采用时间序列分析模型进行疫情预测,能够通过简单的模型建模疫情发展的时间序列当前值与序列历史信息间的关系,对疫情走势做出预测。但由于缺乏对疫情的传染性、爆发性、衰减性等特性的认识与建模,对疫情确诊人数的预测仍有一定的局限。此外疫情前期可用数据有限,也给时间序列模型的学习造成了很大困难。
本文采用自增强泊松过程(RPP)模型[11]对疫情确诊人数变化趋势进行预测,该模型将病毒感染人群的动态过程建模为不均匀泊松过程,通过对病毒传染性、级联传染的自增强效应和病毒传播的时效性等三个因子进行建模,对疫情传播过程中的关键因子进行刻画,以解决上述模型中出现的问题,并使用本次COVID-19 疫情传播数据进行实验,证明模型的有效性。
2 相关工作
自COVID-19 疫情发生以来,世界各地学者纷纷尝试对疫情的发展趋势展开研究和分析。其中以SEIR 模型为代表的微分方程传染病模型占据了疫情趋势预测工作的主要部分。SEIR 模型将人群划分为易感者(Susceptible)、潜伏期感染者(Exposed)、感染者(Infected)、治愈者(Recovered)四个群体,以微分方程描述四个状态间的转换关系。2020年1月31日,香港大学学者Joseph T Wu 应用SEIR 模型,利用武汉早期病例数,推测疫情会在4 月达到高峰[12]。肖燕妮教授团队同样基于SEIR 模型,考虑跟踪隔离等管控措施,对疫情的走势和管控举措的有效性进行了分析[13]。2 月28 日,钟南山院士团队考虑地区间人口流动对SEIR 模型进行改进,通过对实施管控措施时间的调整,论证了控制措施对于减少最终COVID-19 流行病的规模是必不可少的[14]。西安交通大学[15]、北京邮电大学[16]等国内研究机构也通过传染病动力学建模对COVID-19疫情走势做出了预测。上述基于传染病模型对疫情预测分析的工作被证明可以较准确地反映小范围空间在短期内的疫情走势,但由于这类模型对初始参数敏感,且基于人群均匀接触的理想假设,难以应对不同地区不同时间带来的复杂疫情发展趋势变化。
基于时间序列分析的疫情预测分析在流感等传染病预测领域多有应用[17][18][19]。线性时间序列模型如Pinto[20]模型假设未来的序列值为历史序列值的线性组合,从而通过历史确诊人数对未来的确诊人数进行预测。然而线性时间序列模型在应用中面临诸多局限,基于深度学习技术的循环神经网络(Recurrent Neural Network,RNN)[8]模型解决了这一问题,但也因对长序列进行学习时会出现梯度爆炸或梯度消失现象,从而无法对长序列建模。时序卷积网络(Temporal Convolutional Networks,TCN)[10]模型通过因果空洞卷积的设计,提取序列局部特征的同时增大感受野,实现了对长时间序列的有效处理。上述提到的时间序列模型,能对时间序列进行建模并预测。然而这些时间序列模型对疫情传播的传染性、爆发性、衰减性的关键性质缺乏认识,且要求有足够的训练数据用来学习模型参数,这使得其在疫情预测应用领域存在一定局限。
3 模型方法
3.1 问题形式化
我们使用疫情传播的动态过程刻画人群中个体被病毒感染并发病这一事件的发生过程。对于某传染病d,我们将其在时间段[0,T]内的疾病感染人群动态变化过程表示为个体染病事件发生的时间序列:

其中nd表示T时刻内被疾病感染的人群总人数,表示第i个染病事件发生的时间。不失一般性,令0 ≤≤T。
3.2 事件发生速率建模
为了建模疫情传播的动态过程中个体染病事件发生的速率,我们考察疾病传播过程中的三大现象:(1)病毒传染性,即病毒自身的传染性对最终的感染人数起决定作用;(2)级联传播所带来的自增强效应,即病毒当前的感染人数越多越容易进行新的传播感染;(3)病毒传播的时效性,即随着时间推移,病毒感染人群继续感染他人的可能性会下降。综合考虑这三个现象,我们采用自增强泊松过程(Reinforced Poisson Process,RPP)[11]来建模疾病感染人群的动态过程。具体而言,对于某个传染病d,其感染人群的动态过程建模为一个速率为的泊松过程。其中,λd是病毒自身的传染性,松弛函数fd(t;θd)刻画病毒传播的速率随时间演变过程。θd是松弛函数的参数,id(t) 表示病毒d在时刻t已经感染的人群数量。我们假定所有的病毒在开始感染前,都有一定初始感染人数m。因此,在第i- 1 次真实感染事件发生后到第i次真实感染事件发生前的时间段内,我们有id(t) =m+i- 1(1 ≤i≤nd)。相应地,在第nd次真实感染事件发生后到时刻T之前,我们有id(t) =m+nd。
对于疫情预测,我们采用对数正态松弛函数
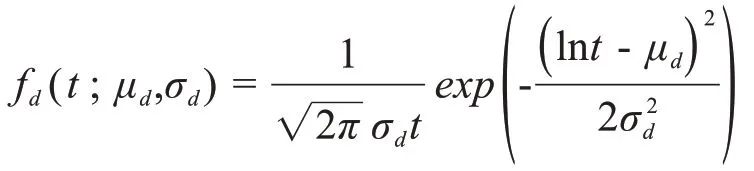
作为刻画病毒传播时效性的松弛函数。此时松弛函数的参数θd被替换为对数正态函数的均值μd和方差σd。
整个疾病感染人群的动态过程可以表示为如图1所示的产生式概率图模型。
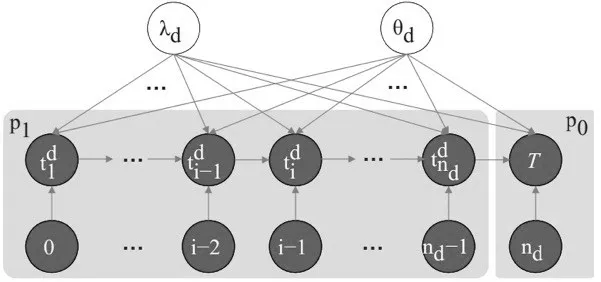
图1 疾病感染人群动态过程的产生式概率图模型[11]
3.3 参数学习
两次连续感染事件之间的时间间隔长度服从不均匀泊松过程。因此,设第i- 1 次真实感染事件的发生时刻为,那么第i次真实感染事件在时刻发生的概率满足:
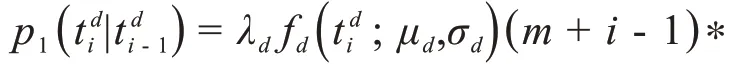

在第nd次真实感染事件发生时刻和观测时刻T之间没有感染事件发生的概率为:
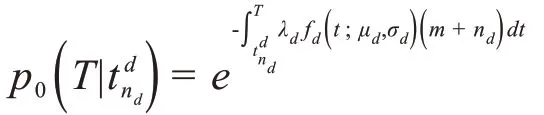
那么,在时间间隔[0,T]内观测到病毒d的染病人群动态过程的似然为
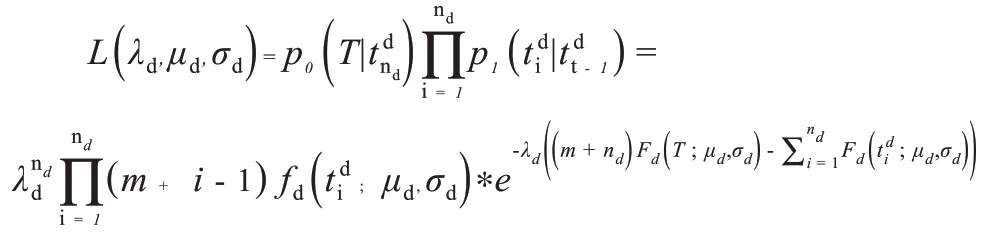
其中,Fd(t; μd,σd )是松弛函数fd(t;μd,σd)的累积分布函数。
我们通过最大似然估计,学习病毒d的参数λd,μd和σd。令似然函数导数为零,可直接求得参数λd的最大似然估计值
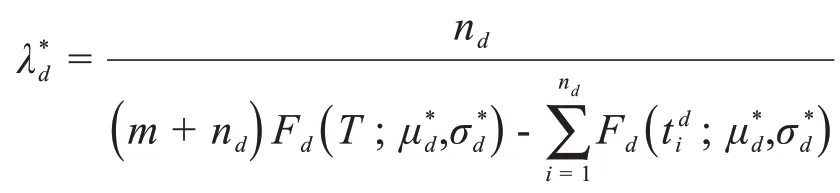
对于μd和σd,我们使用梯度下降法最大化似然函数,梯度
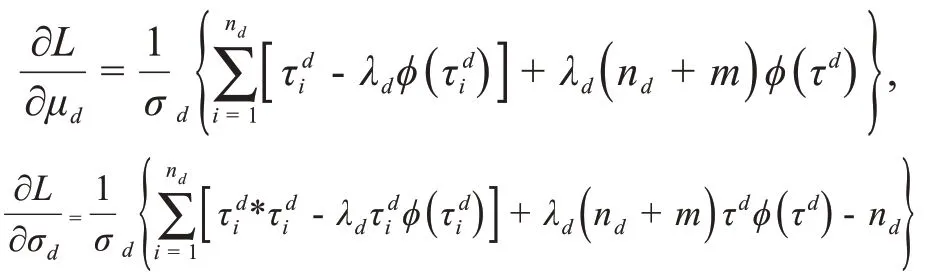
其中,φ是标准正态分布的概率密度函数,
3.4 疫情预测
根据泊松过程的速率函数和对应的微分方程求解,我们得到病毒感染人群的预测函数:
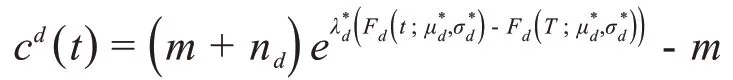
4 实验设置
4.1 对照模型
4.1.1 SEIR型流行病模型
传染病学模型采用肖燕妮教授团队的工作[13],该模型在传统SEIR模型对人群的“易感者-暴露者-感染者-治愈者”划分的基础上,结合COVID-19 的实际情况与诸如检疫,隔离和治疗等干预措施,将人群分为易感者(S),暴露者(E),潜伏传染者(未表现出症状但有传染性)(A),具有症状的传染者(I),住院患者(H)和康复者(R),并进一步划分出被隔离的易感者(Sq)和被隔离的暴露者(Eq)。不同人群间的状态转换方程如下:
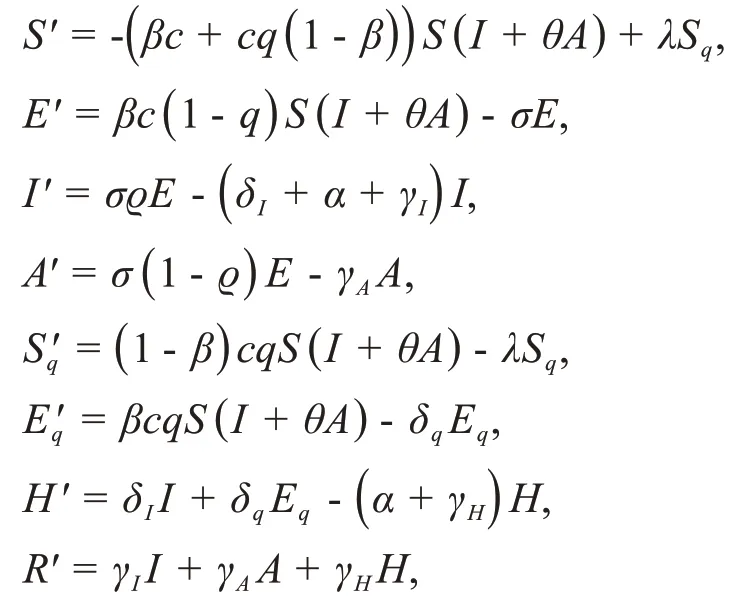
通过对模型设定合适的参数和初始值来推算疫情累计确诊人数C=I+H+R。
4.1.2 时间序列模型
Pinto模型:采用该模型作为线性时间序列模型的代表。该模型划定待预测时刻前的一段时间T 作为观测窗口,将采样窗口划分为大量的采样间隔,采用每个采样间隔内的新增确诊人数作为模型的输入,通过简单的多元线性组合给出模型的预测值[20]。
TCN模型:非线性时间序列模型采用时序卷积网络(TCN)模型。该模型通过卷积神经网络自动提取疫情发展历史序列中的重要特征,并通过因果空洞卷积提升增大了感受野,从而可以观测更久的历史序列[10]。
4.2 实验数据
本文实验采用中国1 月20 日至3 月15 日共计56天的COVID-19 每日确诊人数[21][22]作为实验数据。数据范围基本涵盖了全国自疫情开始流行至爆发到基本得到控制的全过程。同时考虑到3 月16 日后国内新增确诊病例来源以境外输入为主,因此将其排除,最大程度上避免了境外输入病例对实验结果的影响。
考虑到疫情传播具有地区性,不同地区疫情出现时间存在先后差异,疫情发展速度也可能不相同。我国的疫情传播呈现出明显的“武汉市-湖北省-全国其他地区”地区划分:一方面体现在地区间的隔离上,自1 月23 日起武汉开始全面封城,而湖北省也率先实行了较为严格的出入管制措施,最大程度上减少了感染病例的流入和流出;另一方面体现在疫情传播的时间先后和传播的规模上,国内疫情最先发现于湖北省武汉市,随后蔓延至湖北省和全国其他地区,我国及时采取措施将疫情大规模传播范围尽可能地控制在了小范围内,截至3 月15 日,全国近84%的确诊病例发现于湖北省,而其中又有近74%的病例位于武汉市。
因此本文将全国确诊人数数据划分为“全国”、“全国(除湖北)”、“湖北(除武汉)”、“武汉”四个地区层次。
图2是四个地区的累计确诊人数随时间变化的曲线(为保证模型预测结果体现疫情发展的真正趋势,我们排除掉2月12日新增确诊人数中的临床诊断病例数[22])。不难发现各个地区划分下,疫情整体发展趋势基本一致,但存在总量和增长速度等方面的明显差异。
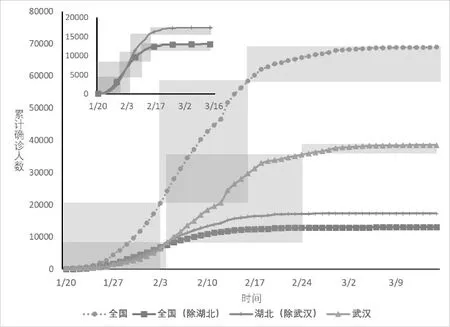
图2 各地区确诊人数随时间变化曲线
除了地区划分,疫情趋势在不同时间阶段的表现也有差异。如图中矩形框所标识,累计确诊人数的变化在时间上较为明显地呈现出三个阶段:(1)前期——加速增长阶段,在疫情流行初期,累计确诊人数增速持续上升,图线呈下凸经过矩形框的右下部分;(2)中期——增速稳定阶段,随着疫情发展与防控措施的实行,每日新增确诊人数基本维持不变,图线基本沿矩形对角线呈直线;(3)后期——增速放缓阶段,后期疫情得以控制,确诊人数增速迅速放缓,图线从扁平矩形框的左上部分经过。为量化表示三个阶段的特点,我们对地区a的疫情发展阶段u计算平均增长系数,

其中ca(i)为地区a第i天的新增确诊人数,Tu为阶段u的天数。在计算时,我们将累计确诊人数曲线进行了平滑处理以避免每日新增确诊病例数波动的影响。四个地区的各阶段划分与平均增长系数见表1。
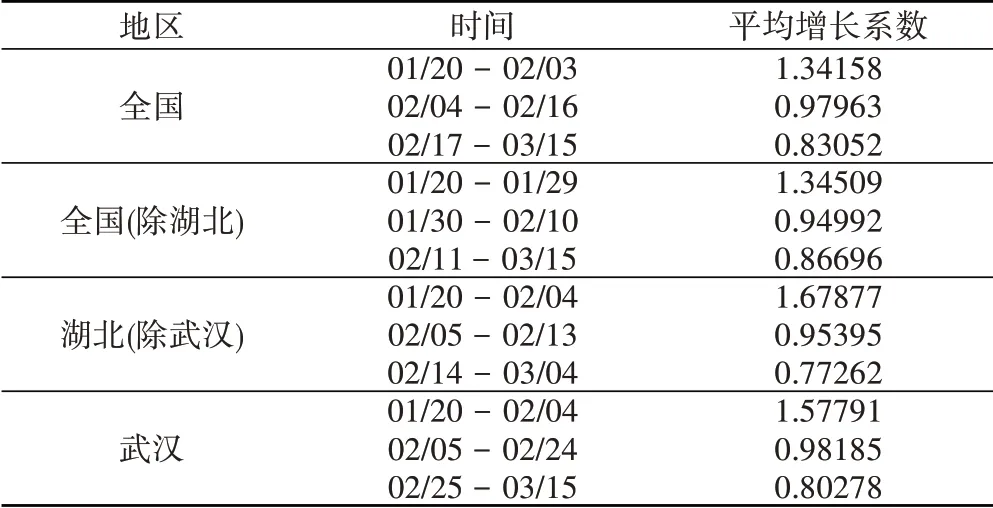
表1 各地区疫情发展趋势的阶段划分
我们分别考察模型在各地区不同时间阶段的预测表现,作为衡量模型在不同环境下预测能力的依据。
4.3 实验参数设置
由于确诊病例数以1天为单位时间统计,因此RPP模型的最小时间单位为1天,当天所有新增病例计为同时发生。由于疫情发展的情况会随时间变化,为保证模型较好地反映近期疫情的走势,我们没有使用预测时间之前的所有数据,而是在4 ≤T≤15范围内通过搜索确定观测窗口T大小。初始感染人数m= 20。
SEIR模型参数值设定采用文献[13]中的取值,该文参数由武汉市早期疫情数据模拟获得。我们使用原文方法求取了不同地区划分下的模型参数,取值见表2。模型的初始值获取自国家卫健委的报道数据[22],未明确报道的状态初值由预测时间前一段时间疫情相关数据通过最大似然估计得出。
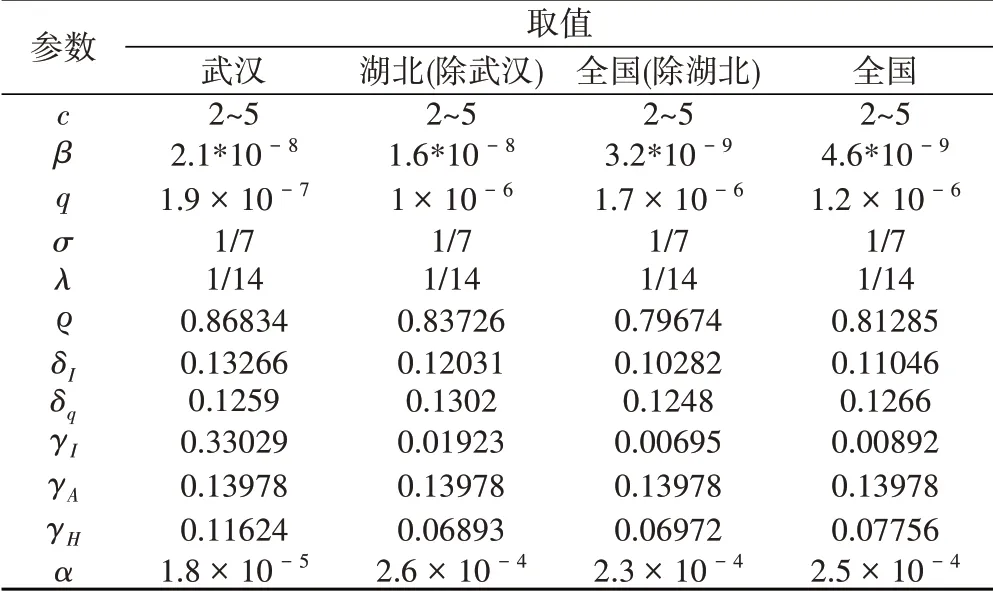
表2 SEIR模型参数取值
时间序列模型的观测窗口大小同样通过搜索确定,从而选取合适的观测历史长度同时保证一定的训练集体量。采样间隔设置为1天。
4.4 评价方法
我们计算预测结果的MAPE(Mean Absolute Percentage Error,平均绝对百分比误差)以衡量模型的预测能力。MAPE的计算公式为
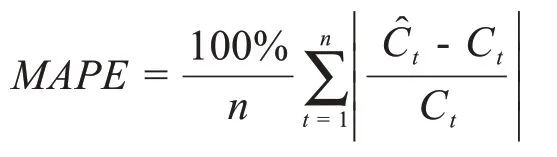
其中n 为预测时间段的天数,Ct为第t天的累计确诊人数,为其预测值。
5 实验结果
5.1 地区间差异对预测效果的影响
我们使用不同模型在全国、全国(除湖北)、湖北(除武汉)、武汉四个数据集上进行实验,对比不同地区间的差异对模型预测效果的影响。考虑到训练数据量和预测时段可能对各模型的预测效果产生不同的影响,因此我们分别在疫情前半段与后半段进行实验,使用1月31日之前和2月10日之前的数据训练模型,分别对随后一周(即2 月1 日至2 月7 日和2 月11日至2 月17 日)的累计确诊人数进行预测,误差结果如表3、表4。

表3 各模型2月1日至2月7日预测结果MAPE
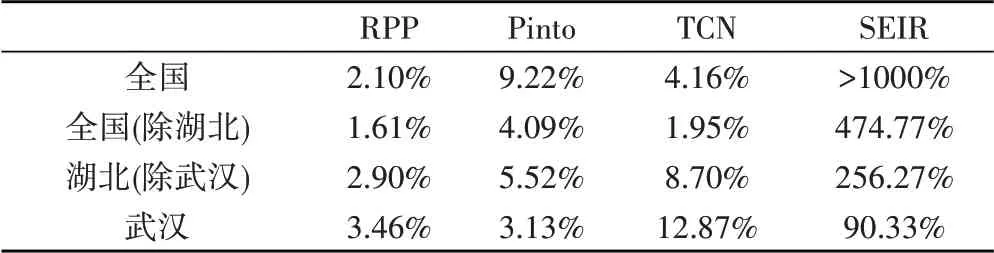
表4 各模型2月11日至2月17日预测结果MAPE
RPP 模型、Pinto 模型与TCN 模型对不同地区的疫情预测效果均比较稳定。相较于Pinto 模型与TCN模型仅对历史确诊人数序列进行分析,RPP 模型对疫情传播的关键因子进行了建模,其预测结果明显优于其他模型。
SEIR 模型的预测效果在不同地区差异较大。这是由于SEIR 模型假设人群均匀混合,在全国各地采取封城措施相互隔离的情况下,绝大多数的感染人群的活动实际上被限制在了湖北省和武汉市内,这与人群均匀混合的假设高度不符,从源头上限制了SEIR模型的表现。
5.2 不同时间阶段对预测效果的影响
根据表1,我们从时间上将疫情的发展过程划分为前期、中期和后期三个阶段。这一部分我们从时间划分的角度,考察模型“阶段内预测”和“跨阶段预测”的效果。
5.2.1 阶段内预测
疫情发展的每一个阶段都有其特定的发展趋势和规律,对这些规律的把握能力是模型完成精准预测的基本要求。这一部分实验分别使用前期,中期,后期的前半段数据作为训练数据,预测同时期后半段的累计确诊人数。以武汉地区为例,各模型预测结果如图3、图4、图5。

图3 武汉市前期累计确诊人数预测结果
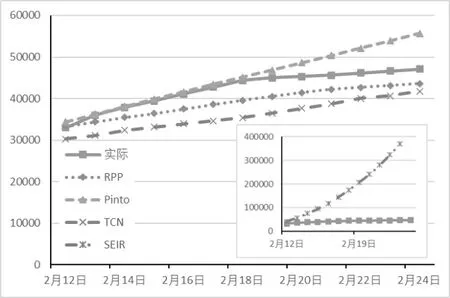
图4 武汉市中期累计确诊人数预测结果

图5 武汉市后期累计确诊人数预测结果
由图可以看出,在疫情前期数据量较少、数据规律性较弱时,Pinto 模型与TCN 模型难以通过少量数据掌握疫情发展的整体趋势,因此预测效果较差。而RPP 模型与SEIR 模型通过对疫情发展固有性质的建模,可以较好地模拟确诊人数加速增长的趋势。
中后期RPP、Pinto 与TCN 模型对确诊人数增速保持稳定至减缓的趋势能够进行较好地模拟。SEIR 模型由于其模型假设所有人都会暴露在被传染的风险下,因此在人口总数很大时,最终累计确诊人数也会变得过高。因此我们在中后期不再对其进行对比。
我们在各地区数据集上进行了相同的阶段内预测实验,综合平均误差结果如表5。
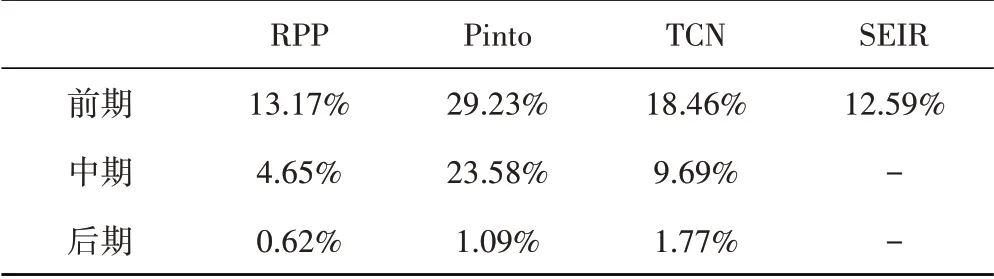
表5 各模型阶段内实验累计确诊人数预测MAPE
可以看出RPP 模型在各个时间阶段内都能准确地对确诊人数进行预测,对阶段内疫情发展趋势能够进行较好地把握。
5.2.2 跨阶段预测
由于疫情发展的不同阶段趋势各不相同,从而意味着应该采取不同的防疫措施。也就是说,模型对于趋势转换的准确预测能力十分重要。因此这一部分实验分别使用前期和中期的确诊人数训练模型,预测其下一个时期的疫情趋势。
同样以武汉地区为例,各模型预测结果如图6、图7。
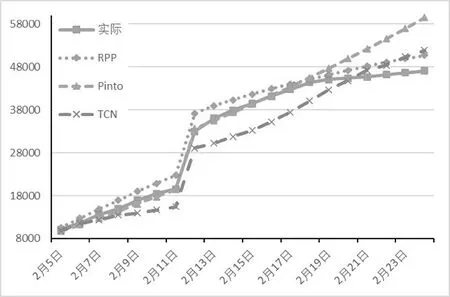
图6 武汉市前期-中期累计确诊人数预测结果

图7 武汉市中期-后期累计确诊人数预测结果
由图6、图7 可知,相较于Pinto 和TCN 模型,RPP模型在中期更能把握确诊人数增速保持稳定随后趋于下降的趋势。而后期RPP 和Pinto 模型都能较好地模拟增速迅速下降的趋势,而TCN模型的预测结果则倾向于保持增速持续增长。
我们在各地区数据集上进行相同的跨阶段预测实验,计算预测结果的平均增长系数(p ̂_u^a ) ̅,再与表1中的实际值进行对比,计算MAPE,结果如表6。

表6 各模型跨阶段实验平均增长系数的MAPE
可知RPP 模型在判断阶段变化时表现明显优于Pinto 与TCN 模型,在各时间阶段都能很好地预测疫情发展趋势的阶段性变化。
6 实践应用
我们将本文方法投入实际应用,自1 月29 日起先后对中国、日本、韩国、意大利、美国等九个国家共12个地区的疫情确诊人数进行预测,累计确诊人数平均误差率小于0.5%。预测结果发布于中科天玑智疫通线上平台(https://ncov.ictbda.com/#/,效果如图8)

图8 在线系统疫情预测效果
7 总结与展望
本文应用基于自增强泊松过程(RPP)的模型来预测COVID-19的疫情确诊病例数。我们的实验结果表明,RPP模型在预测疫情确诊人数的任务中明显优于传统的传染病模型和时间序列分析模型。在空间上,RPP模型克服了SEIR模型基于人群均匀混合的局限,在各尺度的地理区域都有稳定且准确的预测结果。在时间上,一方面,RPP模型解决了SEIR模型在人口总数很大时累计确诊数持续增长的问题;另一方面,RPP模型通过建模疫情发展过程中的关键因素,摆脱了时间序列分析模型仅对历史数据建模的局限性,从而对疫情发展各个阶段的疫情走势能够进行更精确的预测,并且能准确把握疫情发展的重要阶段性变化,其结果在实际应用更具有参考价值。
本文的方法也存在进一步优化的空间,本文假设感染速率与当前感染人数成正比,并使用松弛函数从整体上描述部分感染者被隔离或被治愈等情况造成的感染者总体影响力下降。未来将考虑使用Hawkes过程进行建模,细化不同状态感染者对疾病感染速率的影响。
猜你喜欢
科普童话·神秘大侦探(2022年11期)2022-05-30 03:21:35
科学与社会(2022年1期)2022-04-19 11:38:42
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
恋爱婚姻家庭(2020年27期)2020-10-09 04:16:18
莫愁(2019年36期)2019-11-13 20:26:16
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
百花洲(2018年1期)2018-02-07 16:34:52
瞭望东方周刊(2017年45期)2017-12-08 21:37:48
营销界(2015年22期)2015-02-28 22:05:18
