
基于YoLov5的轴承端面表面缺陷检测方法
2021-02-15 03:01刘好斌杨丰玉杨志勇洪贤涛
失效分析与预防 2021年6期
刘好斌, 杨丰玉, 杨志勇, 张 佗, 洪贤涛
(1.南昌航空大学 软件学院, 南昌 330063;2.中国人民解放军第五七一九工厂, 成都 610000)
0 引言
轴承作为汽车、起重机、飞机等大型机械设备的重要组成部分,承担着机械设备的重量,引导转动等重要任务,因此,轴承质量的好坏决定着机械设备能否正常可靠运行[1-3]。然而,轴承端面表面缺陷作为轴承生产制造过程中最常见的轴承缺陷,目前仍然主要采用人工目视检测方法进行缺陷检测。由于人工目视检测方法易受检测人员生理、情绪以及检测持续时间等因素的影响,普遍存在检测精度低、可靠性差等问题。
相对人工目视检测方法而言,基于机器视觉技术的表面缺陷检测方法,因具有较高的计算效率与检测精度,被广泛应用于轴承缺陷检测技术领域。例如,针对滑动轴承表面缺陷检测问题,陈琦等[4]提出一种通用的检测方法,首先使用模板匹配和阈值分割法获取待检测区域,然后针对缺陷形态的不同设计相应特征提取算法,最后利用SVM实现缺陷类别分类。针对轴承表面缺陷检测误检率较高问题,陈昊等[5]通过引入图像光流技术构建一种基于图像光流的轴承滚子表面缺陷检测方法,有效降低了轴承表面缺陷检测误检率。针对轴承表面缺陷检测存在漏检率较高问题,兰叶深等[6]提出一种基于视觉显著性的轴承表面缺陷检测方法,该方法首先对输入图像进行高斯金字塔采样,然后对每层图像执行超像素分割并对分割结果进行显著值提取,最后对获取的显著图进行缺陷检测和定位,大幅降低了检测漏检率。为了进一步实现对轴承表面缺陷的特征分类,宇文旋等[7]提出一种轴承表面缺陷分类的特征选择算法,该方法通过综合利用相关分析、标量特征选择等方法,实现了较高的轴承表面缺陷特征分类精度。由于轴承表面缺陷形态各异且随机多变,上述基于传统机器视觉技术的检测方法往往仅能针对某一种或某一类轴承表面缺陷的检测,因此,传统机器视觉轴承表面缺陷检测方法普遍存在可靠性差的问题。
与传统机器视觉技术不同,基于深度学习的机器视觉技术通过从大量样本数据中学习充分且可靠的深层次图像特征,可实现高精度与实时的目标检测。目前,基于深度学习的目标检测方法可以分为以Faster-RNN[8]为代表的两阶段检测算法和以SSD[9]、YoLo[10]为代表的一阶段检测算法。两者的区别主要在于后者将目标识别与定位集成于一体,并不需要单独先对输入图像提取候选框,然后再基于候选区域修正。其中YoLo算法因具有优越的实时性、检测精度与鲁棒性,而逐渐成为目标建检测领域的主流算法,目前该算法已更新到YoLov5。实际上对轴承表面缺陷检测也可视为目标检测,因此,本研究以YoLov5目标检测算法为基准,构建基于注意力机制的轴承端面表面缺陷检测模型,实现轴承端面表面缺陷检测。
1 联合 Mosaic与 Copy-Pasting策略的数据增强方法
由于深度学习算法模型通常需要从大量具有标签信息的样本数据中学习图像特征参数,因此,在训练深度学习算法模型之前需要构建一个标签样本数据充足且场景丰富的训练数据集,以供深度学习模型训练使用。然而,在工业缺陷检测领域,具有缺陷的样本在日常生产中占比非常小,难以获取充分且可靠具有标签的样本数据集。为了克服该问题,一般使用数据增强技术实现数据集扩充以满足模型训练需求,常用的数据增强技术一般有图像翻转、图像旋转、图像裁剪以及添加噪声等[11]。但是,上述数据增强方法仅能扩充数据的数量,无法增强待检测目标场景丰富度,反而会导致模型过拟合问题。针对该问题,本研究提出一种联合Mosaic与Copy-Pasting策略的数据增强方法。其中Mosaic数据增强策略受CutMix数据增强[12]方法启发,首先从已标注缺陷区域的轴承端面表面缺陷数据集中随机读取4张图像Im1、Im2、Im3、Im4;然后,对取出的 4 张图像进行翻转、缩放以及色域变换等初步数据增强操作,并将增强后图像分别置于4个只具有灰色背景的图像Imnew1、Imnew2、Imnew3、Imnew4上,其中 Im1置于Imnew1左上角,Im2置于 Imnew2右上角,Im3置于Imnew3左下角,Im4置于Imnew4右下角;最后,利用矩阵方式将 4张图像从 Imnew1、Imnew2、Imnew3、Imnew4上截取下来,并将它们拼接成一张新图像。此时,相对于原始数据有效丰富了图像背景,并且图像的拼接也在一定程度提高了批尺寸。图1展示了Mosaic数据增强策略基本流程。

图1 Mosaic 数据增强Fig.1 Mosaic data augmentation
虽然,通过利用Mosaic数据增强策略可以丰富图像背景,但是缺陷数量并未大幅增加,仍然无法为模型训练提供充足缺陷样本。针对该问题,本研究在Mosaic数据增强策略基础上联合Copy-Pasting策略,提出一种联合Mosaic与Copy-Pasting策略的数据增强方法,以扩充缺陷样本数据量进而满足模型训练集需求。Copy-Pasting策略由Ghiasi等[13]提出用于实例分割技术中的数据增强,首先,该方法随机选择2张标签图像,通过随机尺度抖动、缩放、水平翻转等操作进行初步数据增强。然后,再任意选择一张图像中的待检测目标粘贴在另一幅图像中任意位置。
受该方法启发,首先从经Mosaic数据增强后图像中提取待检测缺陷,然后利用Copy-Pasting策略将提取的缺陷粘贴在当前图像的任意位置,并执行多次粘贴操作,以增加缺陷在图像上的数量,进而扩充训练数据集数量。图2展示了联合Mosaic与Copy-Pasting策略的数据增强方法基本流程及增强效果。从图中可以看出,该数据增强策略可以在丰富图像背景的同时显著提高缺陷样本数量。
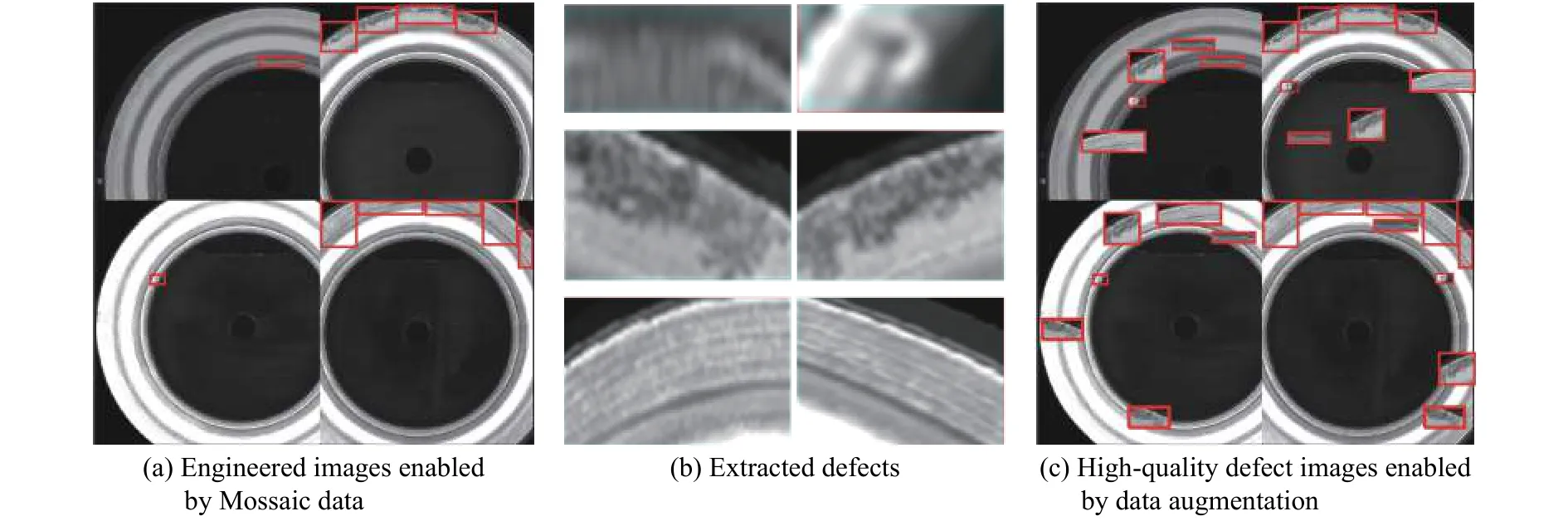
图2 联合 Mosaic 与 Copy-Pasting 策略的数据增强方法Fig.2 Data augmentation method combining Mosaic and Copy-Pasting strategies
2 基于YoLov5的轴承端面表面缺陷检测模型
YoLov5检测模型是YoLo目标检测系列算法中当前精度和可靠性均表现最佳的目标检测算法[14],针对不同类型的目标均能取得较好的检测效果。根据模型网络深度与宽度的不同,YoLov5目标检测模型又可以细分为YoLov5s、YoLov5m、YoLov5l以及YoLov5x等4个版本。由于本研究方法主要针对工业生产制造中轴承端面表面缺陷检测,在考虑计算精度的同时需要兼顾计算速度。因此,使用YoLov5s作为主干检测网络模型,其中YoLv5网络模型架构如图3所示。
从图3可以看出,YoLov5模型主要由3个部分组成,分别为用于特征提取的骨干网络部分、特征融合部分(颈部网络部分)及目标检测部分。其中,BCSP模块具体构成如图4所示,BN表示批正则,add表示加法特征融合,Concat表示图像特征以串联方式融合,HardSwish与Leaky Relu均为激活函数。BCSP模块主要用于多级特征融合以避免由于网络深度的增加而造成的特征损失。SPP模块即空间金字塔池化模块,本研究通过使用不同核尺寸和步长的池化操作捕获不同尺度的图像特征,再通过串联方法实现特征的叠加融合。
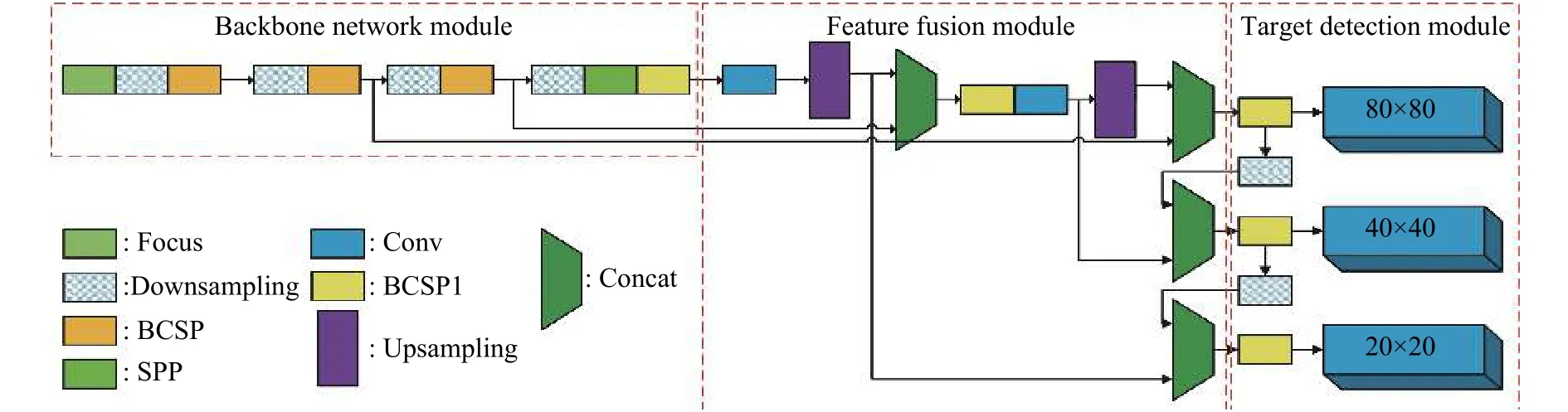
图3 YoLov5 目标检测模型Fig.3 YoLov5 target detection model
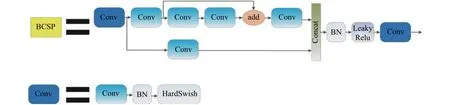
图4 BCSP 模块Fig.4 BCSP module
本研究中,首先对550×550×3通道的轴承端面表面缺陷样本使用联合Mosaic与Copy-Pasting策略进行数据增强。然后,将经数据增强的图像输入Focus模块,在Focus模块中对输入图像进行切片,即将输入图像分割成n×n网格并使用32个卷积核进行特征提取。随后经过4次相同卷积、池化和下采样步骤完成对输入图像的特征提取。在提取图像特征后,利用特征金字塔[15]和感知对抗网络[16]实现自上而下的骨干网络特征融合,以获取更加丰富且充分可靠的特征信息。同时,为了兼顾小缺陷检测,在特征融合部分将输出3个尺度的特征图,分别为 80×80、40×40、20×20 的特征图,它们分别用于检测小、中、大3类缺陷。对于每个图像切片,将对应预测出3个预测框,每个预测框由左上角和右下角坐标以及含有缺陷的置信度组成,置信度由该预测框含有目标的概率大小和该预测框的定位准确度组成。当该预测框是背景时(即不包含目标),记为Pr(obj)=0,当该预测框包含目标时,记为Pr(obj)=1,通过该方法可以检测出当前图像切片中是否存在缺陷。预测框的准确度用预测框与真实框的 IOU(Intersection over union,交并比)表征。当IOU越大,说明预测框与真实框重合度越高,即预测框越准确。为了消除重复预测框和无效预测框,本研究通过利用非极大值抑制方法对冗余预测框进行剔除,保留置信度最高的预测框信息,进而完成缺陷检测过程。非极大值抑制方法首先根据每个预测边界框的置信度得分进行排序,然后选择置信度最高的预测边界框增加到最终输出列表中,并将其从预测边界框列表中删除。接着,计算所有预测边界框的面积。同时,计算置信度最高的边界框与其他预测边界框的IOU并删除IOU大于阈值的边界框。最后,重复上述过程,直至预测边界框列表为空,通过该方法可以有效去除冗余预测边界框。在得到最终所需的预测框后,利用预测框的左上角、右下角坐标以及中心点坐标值即可准确定位缺陷所在位置。
为了使该方法模型训练更加充分,模型损失函数首先利用IOU指标[17]构建目标框与预测框位置损失CIOU_Loss,然后,用FocalLoss评价指标构建目标框与预测框类别损失和置信度损失Focall_Loss,计算公式为:
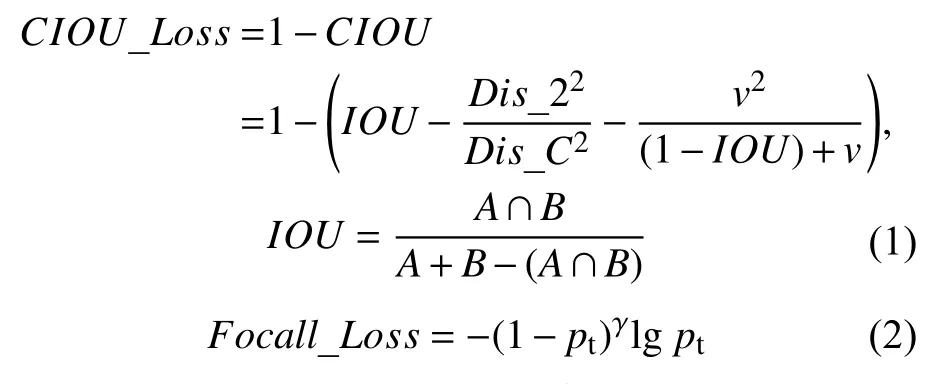
式(1)中:IOU表示预测框与真实框之间的交并比;A表示预测框;B表示真实框;Dis_C表示待检测目标最小外接矩形对角线距离;Dis_2表示待检测目标真实框与预测框中心点欧式距离;v为衡量长宽比一致性参数,可由式(3)计算得到,其中wgt,hgt表示真实框宽度与高度,wp,hp表示预测框宽度与高度。式(2)中,pt表示预测样本概率,γ为常数参数。

3 实验与分析
3.1 实验误差指标
采用精度(Precision)、漏检率(Missed detection rate)和误检率 (False detection rate)作为检测误差量化指标[18],计算公式为:

式中:P表示测试数据集中真实正样本个数,N表示测试数据集中真实负样本个数,TP表示正样本中预测为正样本的个数,FP表示负样本中预测为正样本个数,FN表示样本为真实正样本但是预测为负样本个数,PT表示预测为正样本个数,PN表示预测为负样本个数,Missp表示正样本漏检率,MissN表示负样本漏检率,Falsep表示正样本误检率,FalseN表示负样本误检率。
3.2 网络训练
采用的实验数据来源于轴承生产制造企业日常采集的轴承端面表面缺陷数据集。该数据集共包含1069张轴承端面表面图像,其中包含缺陷的负样本720张,合格样本249张。负样本中轴承端面表面至少包含一处缺陷,轴承端面表面缺陷数据样本如图5所示,其中NG表示包含缺陷的负样本,OK表示合格正样本。由于数据样本较少尚不满足模型训练需求,首先通过使用联合Mosaic与Copy-Pasting策略的数据增强方法将数据集样本数量由原来的1069张扩充为3270张。在实际训练中,随机取样抽取300张图像作为测试集,测试集中包含缺陷的负样本200张,正样本100张,剩余2970张作为训练集,在训练之前,本研究模型超参数配置如下:初始学习率lr=0.01,动量momentum=0.920,权重衰减weight_decay=0.0005,优化器optimizer采用随机梯度下降法SGD,训练次数设置为500个epochs。

图5 轴承端面表面缺陷数据样本Fig.5 Samples of surface defect on bearing end surface
3.3 实验分析
当模型训练完成后,使用事先抽取的300张图像作为测试集,对模型检测效果进行测试,表1展示了轴承端面表面缺陷检测结果。从表中结果可以看出,正样本和负样本中漏检率分别为5%、7.5%,说明该方法存在较低的漏检率。虽然正样本误检率相对负样本误检率较高,但在工业生产环境中,可以允许少数合格品误判为不合格品,而对不合格品误判为合格品的容忍度较低,而本研究方法负样本误检率仅为2.6%,也侧面反映其具有较高的检测精度。此外,在总的精确度指标上,本研究方法也实现了94.7%的检测精度,进一步说明该轴承端面表面缺陷检测方法具有较高的检测精度。

表1 轴承端面表面缺陷检测结果Table 1 Test results of surface defects on bearing end surfaces
图6为利用本研究方法检测轴承端面表面缺陷的效果,其中蓝色框表示检测出的缺陷所在位置。从图中可以看出,该方法可以准确地检测出轴承端面表面缺陷,特别是针对面积较小的缺陷也具有较高的检测精度。

图6 检测结果Fig.6 Test results
4 结论
1)提出一种基于YoLov5的轴承端面表面缺陷检测算法。先提出一种联合Mosaic与Copy-Pasting策略的数据增强方法克服了轴承端面表面缺陷数据样本不足问题,然后基于YoLov5检测模型构建基于YoLov5的轴承端面表面缺陷检测模型,实现了轴承端面表面缺陷检测。
2)轴承端面表面缺陷测试实验的检测精度为94.7%,证明本方法具有较高的检测精度。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
哈尔滨轴承(2021年1期)2021-07-21
中学生数理化·高一版(2021年2期)2021-03-19
领导决策信息(2018年16期)2018-09-27
中国建筑金属结构(2018年6期)2018-08-31
数学学习与研究(2017年3期)2017-03-09
汽车文摘(2015年5期)2015-12-16
