
基于BERT的实体关系抽取研究
2021-02-11 05:57刘成汉童斌斌
时代人物 2021年32期
刘成汉 何 庆 童斌斌
(1.贵州大学大数据与工程学院 贵州贵阳 550025;2.贵州省公共大数据重点实验室 贵州贵阳 550025)
信息抽取(Information Extraction,IE)目的是从大量非结构或半结构的文本中抽取结构化信息[1],其主要任务包括:实体消歧、时间抽取、命名实体识别和实体关系抽取等。关系抽取任务是将目标实体的关系抽取出来,为下游复杂系统的构建提供数据支撑[2],其应用包括,自动问答、机器翻译等。随着近年来研究的深入,关系抽取问题得到广泛的关注。
近年来,深度学习方法被广泛地应用到实体关系抽取任务中。徐跃峰等人[3]通过卷积深度神经网络(CDNN)提取原始文本中词级和句级特征,解决了传统抽取方法在特征提取过程中的错误传播问题。王凯等人[4]提出了基于长短期记忆网络的方法,在句法依存树的最短路径基础上,融入词性、句法等特征进行关系分类。以上学者在文本表征模块主要采用了Word2Vec语言模型,但这种表征方法对于后续任务的效果提升非常有限,因为该方法只能学习到文本无关上下文的浅层表征。为了解决Word2Vec为代表的文本表征方法的缺陷,BERT语言模继出现并得到广泛的应用,例如,赵旸等人[5]利用BERT进行中文医学文献分类研究,体现了BERT模型的分类优越性;王昆等人[6]针对长文本噪声大和冗余性为标题,提出了一种基于文本筛选和改进BERT的情感分析模型。虽然上述方法取得了较好的效果,但目前针对关系抽取任务的性能有待进一步提高。
综上所述,本文提出了一种BERT-BiLSTM-Attention模型,首先通过研究BERT微调的方法学习到文本的深层次特征,然后引入字级注意力机制提高对关系抽取任务和情感分类任务起决定性作用的字权重,降低无关词的作用,同时避免了在静态词向量上直接添加注意力机制导致无法充分理解句子语义的问题,进而提升整个分类模型的性能。通过在英文公共数据集SemEval2010 Task8上的实验结果表明,与BiLTSM-Attention主流模型相比,本文所提出的模型具有更高的性能。
BERT-BiLSTM-Attention模型
BERT-BiLSTM-Attention模型如图1所示,主要分为三部分:先通过BERT模型训练获取每则文本的语义表示;再将文本中每个字的向量表示输入到BiLSTM-Attention模型中,进行进一步语义分析;最后利用softmax层进行输出。
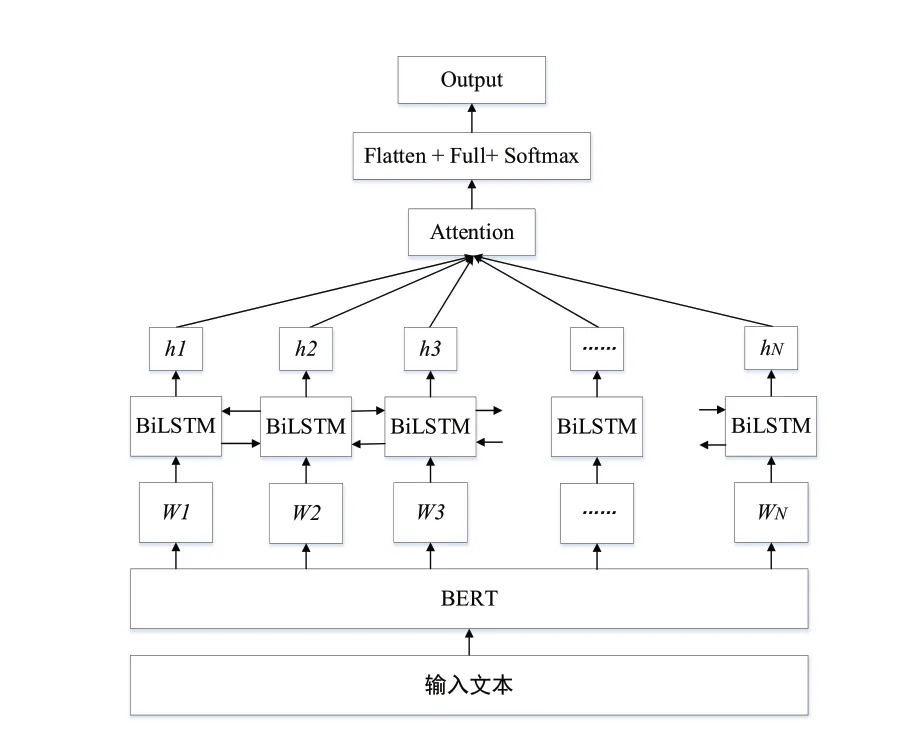
图1 本文模型
BERT
对于自然语言处理任务,首先要将文本向量化,这一过程称为词嵌入,但之前提出的word2Vec模型只能学到本文的表层特征,用静态的词向量来表示词的多个语义,所以不能更好的理解文本语义。与Word2Vec相比,BERT模型(如图2所示)采用的编码方式为双向的Transformer结构,“双向”代表了模型在处理一个词时,会根据该词的上下文关系来表征该词在本文中的具体语义信息。
BERT的训练是BERT模型最关键的阶段,通过对海量的文本进行训练,学到到每个词的表征,用向量W表示,如公式1所示:

式中,W(i)表示第i个文本的向量矩阵,N代表每则本文的最大句子长度,WN(i)表示文本中每个单词的表征向量。在英文数据集上,本文采用的是BERT预训练的模型表征,在其基础上进行微调。
BiLSTM
长短期记忆网络(LSTM)作为一种序列模型,在众多的NLP任务中都取得了较好的效果,它解决了循环神经网络(RNN)的梯度消失以及无法获取长距离文本信息的问题。但是,LSTM只能获取单向的语义信息,无法同时得到文本的上下文信息,而在实际的文本中,前后信息都蕴含着丰富的语义信息。为此,本章引入了LSTM的扩展模型双向长短期记忆网络(BiLSTM),它可以充分的利用前向和后向的上下文信息,使得模型能够更好的理解句子语义特征。在本章模型中,BiLSTM作为动态预训练模型BERT的下一层,能对BERT输出的文本向量进行双向学习并拼接,以得到句子进行更深层次的理解,下述公式2~公式12详细的阐述了BiLSTM的计算过程。

式中,→和←分别表示神经网络的前向计算和后向计算的过程,it、ft和ot分别表示在t时刻神经网络的输入门、遗忘门和输出门。ct表示的是在t时刻细胞状态中的计算公式,ht是t时刻双向长短期记忆网络的完整输出,它是由t时刻前向输出和后向输出进行向量拼接得到的。
Attention
在经过Embedding层和解码层之后,由于长短期记忆网络信息传递的梯度消失和信息传递的容量限制问题,只能够提取到输入信息的局部依赖关系。所以为了增强模型对于长句的建模能力,同时增强信息之间的依赖关系,本章在模型的顶层加入Attention层,目的是为了提高模型捕捉句子内部语义信息的相互联系,同时增强对关系抽取任务起关键性作用的字的权重,从而降低无关字词的权重值,通常注意力机制中的权重采用公式13进行计算:

式中,f是一个将待计算向量mt和影响权重因子n联系起来的函数,l表示需要分配权重的向量个数,at是注意力机制中自动计算的mt向量的权重,采用Softmax归一化,使得所有权重的和为1。
本节模型中注意力计算公式如公式14~公式17所示,在得到BiLSTM隐层输出H={h1,h2,…,hn}之后,字级注意力层可以通过下述公式进行计算:
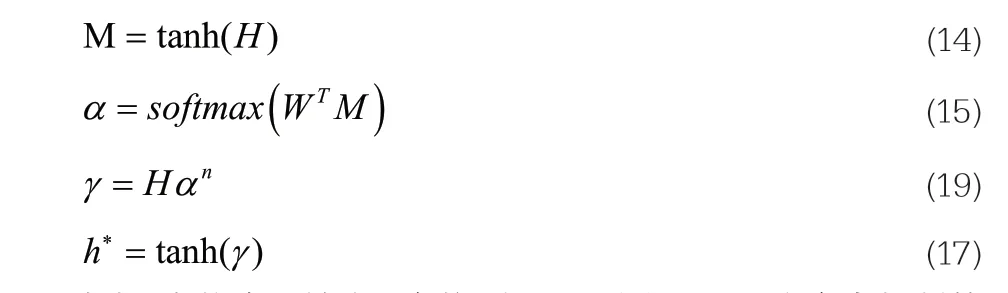
式中,先将隐层输出H变换到[-1,1]之间,W是注意力机制的权重参数,是一个可训练参数,h*则是通过注意力层加权求和后的句子表示。
实验和分析
数据集。本文采用的英文数据集SemEval2010 Task8包含了12717条数据。其中,训练集包含8000个样例,测试集包含2717个样例。
实验环境与参数。本文所有的实验均在 Ubuntu Server 18.04操作系统,显卡为TITAN-XP 12G * 6,内存为32GB * 4的计算机上进行,本文中所有模型都是基于TensorFlow1.15.0搭建的,同时为了增强模型之间的可比性,所有模型的参数均保持一致,其中,包括最大句子长度设置为90,词向量维度设置为768维,batchsize大小设置为64等。
实验结果和分析。为了检验本文所提关系抽取方法的有效性,将BiLSTM-Attention、BERT-Fine-tuning、BERTBiLSTM、BERT-BiLSTM-Attention、At_LSTM和PNAtt_LSTM模型进行对比,实验结果如表4所示。

表2 实验结果对比
本文实验部分的目的一方面是为了证明基于BERT微调方法可以得到更好的词向量表征,同时有效地提高模型的性能上限;另一方面是为了验证字级注意力机制对于实体关系抽取的有效性。
从表4结果可以看出,与文献[7]的At_LSTM模型相比,本章模型在准确率、召回率和F1值上比At_LSTM改进算法都高近4%,证明了本文算法与其他优化算法相比,具有更优越的性能;与文献[8]的PNAtt_LSTM改进算法相比,本文模型的性能在准确率上与PNAtt_LSTM改进算法相近,但是在召回率和F1值上比PNAtt_LSTM改进算法高1%。
本文针对常见的文本表征模型不能很好地处理不同语境下多义词,以及无法涵盖上下文语义信息问题,提出了一种基于BERT的关系抽取模型,利用BERT微调后的词向量作为双向长短期记忆网络的词嵌入层,通过字级注意力机制对双向长短期记忆网络解码后的输出进行注意力计算,提升神经元之间的关联性。从实验结果可以看出,字级注意力机制有效提升了模型的性能,同时也证明了基于BERT微调方法可以有效地提高模型的性能上限。本文方法先是在关系抽取英文数据集上证明了模型有较好的性能,但本文在数据收集方面未能考虑事件的时序性,后续将着重针对不同时段某一舆情事件的发展趋势。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
