
基于MobileNet-SSD的红外人脸检测算法
2021-02-07 12:52:56张骏,朱标,吉涛
激光与红外 2021年1期
张 骏,朱 标,吉 涛
(中航华东光电有限公司 国家特种显示工程技术研究中心 特种显示国家实验室,安徽 芜湖 241002)
1 引 言
2019年,武汉市爆发新型冠状病毒疫情,疫情扩展速度快,短短2周便传播到全国各地。该病毒的主要症状之一就是体温异常,因此体温检测成为监控疫情的重要手段。人工智能与热红外测温相结合的各种检测系统纷纷亮相,旷视科技将可见光条件下检测戴口罩遮挡的人脸技术和热红外技术相集合,推出了“旷视AI测温系统”,商汤科技也相应的推出了人脸识别、无感测温与无感通行结合的出入口通行模块,通过该模块可以快速的检测出人员有无佩戴口罩,规范员工佩戴口罩进出。目前提出的智能监控系统,更多的是基于可见光下的人脸检测(包括戴口罩遮挡),再通过可见光图像和红外图像的配准,将可见光下检测到的人脸区域应用到红外图像中。而这类智能监控系统,对于硬件依赖较大,必须使用配准好的双光(可见光+热红外)采集设备。针对此种局限本文提出了一种基于MobileNet-SSD网络的红外人脸检测算法,可直接检测出热红外图像中的人脸区域。
2 SSD网络
SSD(Single Shot MultiBox Detector)算法,是一种端到端的单次多框实时检测的深度神经网络模型[1],融合了YOLO的回归思想[2]和Faster RCNN[3]的候选框机制。该算法利用回归的思想极大的减少了神经网络的计算量,提升了算法的运行速度。算法中不需要生产候选框,而是直接提取输入图像的特征信息,然后直接在特征图上回归这个位置的边界框以及对物体进行分类;运用局部特征提取的方法得到不同的位置,不同的宽高比、尺寸的特征,对比YOLO算法特征提取更加高效[1],此外,为了增加模型检测不同大小物体的鲁棒形,算法选取了网络中多个层次的特征图进行预测。
SSD的网络模型基于一个前馈卷积网络,大致可以分为:前端的特征提取网络和后端的多尺度特征检测网络,通过池化操作将前端提取网络产生的特征图尺寸逐层减小,再通过后端的检测网络的检测,实现多个尺度特征图的检测[1]。网络的结构如图1所示。
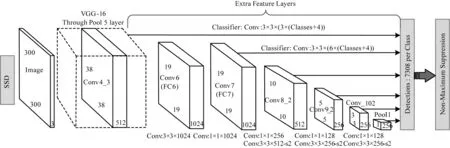
图1 SSD网络结构
3 MobileNet网络
2019年,Google公司在MobileNet-V2之后提出了MobileNet-V3网络[4],作为MobileNet系列的新成员,MobileNet-V3继承了MobileNet的一贯轻量化的特点,MobileNet网络在V1模型中,采用直筒结构,利用分组卷积降低网络的计算量,使得网络的计算量降到最低,同时使用Point-Wise Conv进行通道直接的融合[5]。V2模型在V1模型的基础上,引入了bottleneck结构[6],将bottleneck结构变成了纺锤型,即resnet先缩小为原来的1/4,再放大到原来的6倍,再缩小[6],最后将Residual Block[7]中最后的ReLU操作取消。V3模型在V2的基础上进行了4处优化:①引入了SE(Squeeze-and-Excite)结构,再bottleneck结构中增加SE结构,文献[4]中,作者给出了改进后的结构图,并详细解释了增加SE结构后,不仅提高了网络的精度,同时也没有增加时间的消耗;②修改了V2模型的尾部结构,直接去掉了V2结构中Avg Pooling操作前纺锤型卷积的3×3以及1×1卷积,进一步减少了计算量,同时精度也没有损失[4];③修改头部卷积核通道数量,由V2模型中的32×3×3,修改为16×3×3;④非线性变化的改变,使用了h-swish替代了swish操作。
4 基于MobileNet-SSD的热红外人脸检测算法
热红外图像,因为其特殊的成像特点,使其应用领域广泛,尤其在军事、工业、医疗领域[8]。热红外图像成像的原理是通过采集热红外波段8~14 μm,来探测物体发出的热辐射,热成像将热辐射转化为灰度值,通过黑体辐射源标定得到的测温算法模型(温度灰度曲线)建立灰度与温度的对应关系[9]。其图像的灰度分布与目标反射特征无线性关系。如图2所示。
从第2节中可以了解到SSD算法是有前端的特征提取网络和后期的特征检测网络组成,在文献[1]中作者指出前端特征提取网络,可以是一个去除全连接层的分类网络,如 AlexNet[10],VGG[11]等,作者使用了VGG16网络,文献[4]中,作者将MobileNetV3应用于SSD-Lite在COCO测试集上,对比基于VGG的SSD-Lite,运行速度要快五六倍之多,虽然MobileNetSSD在精度有所下降,但可以满足使用需求[4,12-15]。

4.1 基础模型的训练
可见光条件下SSD算法通常采用VGG16作为基础模型,在VGG16的基础上通过新增卷积层来获得更多的特征图用来检测。通常使用的VGG16是在相关数据集的预训练模型,如ImageNet数据集、ILSVRC CLS-LOC数据集等,这些数据集往往都提供了大量的可见光数据和预训练模型供大家使用。因此在可见光条件下,更多的研究重点集中在SSD特征搜索网络,而忽略了前期基础模型的训练。文献[16]中,Zhiqiang Shen提出了3个观点,首先是预训练模型一般都是在分类图像数据集上训练,不一定可以迁移到检测模型的数据上;其次,预训练的模型,其结构是固定的,修改比较麻烦;最后,预训练的分类网络的训练目标一般和检测目标不一致,因此预训练模型对于检测算法而言不一定是最优的选择[16]。而本算法针对的热红外图像,恰好满足了上述的观点,首先是热红外的分类图像数据集,很难获得,无法进行预训练模型迁移,其次,训练目标与检测目标不一致,因此本算法需要构建自己的训练数据集,并进行基础模型的训练。
本文采用了文献[4]中的MobileNetV3-Large网络作为基础模型,该模型对比Small模型增加了特征提取力度,极大程度的保证了浅层特征的提取。其网络结构在文献[4]中有描述,这里不在阐述。文献[4]中用h-swish函数代替了swish函数,其公式如式(1)所示:
c∈[1,C]
(1)
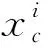
(2)
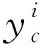
4.2 MobileNet-SSD模型
目前,SSD在车牌检测、人脸检测中有广泛的使用[1]。从2015年被提出以后,SSD算法便一直被用来与YOLO算法进行比较,但是实际上SSD算法(除了SSD512)在速度和精度上都要优于YOLO算法,原因在于,SSD采用了不同尺度的特征图进行检测,大尺度特征图(较靠前的特征图)用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。同时使用了不同尺度和长宽比的先验框[2]。因此这些特点决定了SSD算法可以很好的兼顾不同尺寸的目标检测。
MobileNet-SSD用MobileNetV3-Large网络替代VGG16作为基础网络,借鉴文献[12]~[15]中对于SSD网络的改变,本算法相应的对网络进行了适当的改变,首先使用Residual Block[7]代替了文献[1]给出的Conv2d操作;以提升网络的检测精度;其次对预测框(Prior Box)的尺寸进行了改变,使用了19,10,5,3,2,1尺寸的先验框代替文献[1]中使用了38,19,10,5,3,1尺寸的先验框,这样虽然降低了算法对于极小尺寸目标的检测精度,但是却提升了网络的运算速度。网络的损失函数均采用文献[1]提出的方法,这里不在进行阐述。
4.3 热红外人脸分类数据集
因本算法针对于热红外图像中的人脸检测,而目前没有开源的热红外图像数据集,所以本文收集了1000张热红外人脸图像作为基础分类模型训练的数据集,同时收集了550张不同环境下的热红外图像作为检测训练集。其中1000张热红外人脸图像,采集了“黑热”、“白热”、“伪彩”、“是/否佩戴口罩”、“是/否佩戴眼镜”等多种图像,如图3所示。

图3 热红外人脸图像训练集
可见光图像的数据增强方法大致为颜色变换、几何变换和裁剪变换,而红外图像自身的特点,决定了颜色变换对于热红外图像的增强作用不是很大。本文采用了缩放操作、随机翻转(水平,垂直方向)、旋转操作、镜像操作作为数据增强的方法。同时随机抽取部分图像进行剪切操作,用来模拟可能出现的人脸大比例被遮挡的情况。
4.4 热红外人脸检测数据集
热红外人脸检测,往往是在一幅热红外图像中出现单个或多个人脸,同时因为不同人脸在图像中的位置和尺寸的大小,使得4.3节中的人脸图像不在适用于人脸检测,因此,本文在室内环境下,又采集了550张不同情况下的人脸图像,这些图像包括单个人脸,多个人脸、同时出现尺寸大小不一的人脸等场景,采用缩放、随机翻转(水平,垂直)、图像旋转、镜像以及对随机图像进行图像裁剪等系列操作方式作为数据增强手段。如图4所示。

图4 热红外人脸检测数据集
5 实验对比及数据分析
本算法采用3组不同的实验,以验证算法的可行性及性能。对比实验分别为:1)随机抽取热红外人脸图测试本算法的可行性;2)对比可见光人脸检测精度分析本算法的性能;3)利用OpenVINO ToolKit加速本算法,测试算法的实时性。
5.1 前期实验准备
在实验前期,需要对MobileNet V3-Large分类网络进行训练,为后续的MobileNet-SSD网络提供特征提取模型。首先是数据集的准备,我们收集了1000张不同环境下的热红外人脸图像,后续又添加了1000张可见光条件下的猫脸图像和1000张可见光条件下的狗脸图像。采用7∶2∶1的分配比例分为训练样本,验证样本及测试样本。实验环境为Window10+Anaconda3(64 bit),采用Pytorch 1.1.0+OpenCV3.3(No Contrib)作为深度学习框架,CPU 为Inter Core i7-7700HQ,内存为16G,GPU为NVIDIA GeForce GTX1050Ti 4 GB。MobuleNet_V3-Large参数为学习率(Learning-rate)为1×10-3;输入图像尺寸(Input Size)为224×224;批次规模(Batch Size)为10;迭代次数(Epochs)为200;分类种类(Classes)为3类。迭代160次后,模型准确率收敛到99.45 %,结束训练,模型大小为14.9 M。
5.2 可行性实验
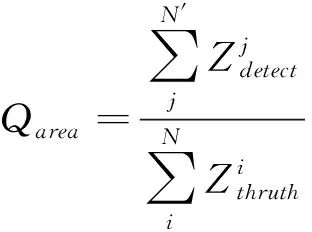
实验平台的硬件指标与5.1节的硬件指标一致。本实验随机抽取了“黑热”,“白热”,“伪彩”的单一人脸和多人脸进行了实验,使用“标记框面积比”,“误检测率”作为对比指标。公式分别如(3)、(4)所示:
(3)
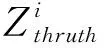
“误检测率”如(4)所示:
(4)
式(4)中,Qerror表示“误检测率”;Ndetect表示预测人脸框个数;Nthruth表示人工标记框个数。当Qerror>1时,表示多预测出人脸;当Qerror<1时,表示出现漏检测人脸;当Qerror=1表示预测人脸框的数量和人工标记的数量一致。可行性实验结果图如图5所示。其中图5(a)、(b)、(c)为“白热”图像检测结果,图5(d)、(e)、(f)为“黑热”图像检测结果;图5(g)、(h)、(i)为伪彩图像检测结果。
表1、表2、表3中A、B、C、D分别为Nthruth、Ndetect、Qerror、Qarea,“-”表示没有对应值,从实验结果中不难发现3种不同形式的图像,均出现了“漏检测”的情况,在“单人近距离”条件下,3种图像均出现了漏检测,尤其在“黑热”图像中,几乎检测不到人脸,从图5(i),(j)不难看出,“黑热”的人脸图像特征信息(除去眼镜部分)较少,所以很难完成检测任务。相对而言,“白热”、“伪彩”图像提取的特征信息较为丰富,如图5(d),(e),(o)。但因为基础网络的训练集数量过少,极大程度限制了网络的性能,导致出现了大量漏检测的情况;“多人中远距离”条件下,检测效果对比“单人”情况有了大幅提高,也验证了MobileNet-SSD算法的多尺度特点,但是漏检测的情况也依然存在。在Qarea指标上,只有图5(d)中的预测框要大于标记框,其他的预测框基本与标记框大小一致。通过图5和表1、表2和表3的数据对比,本算法完全可以适用于热红外图像中的人脸检测。

图5 本算法检测结果
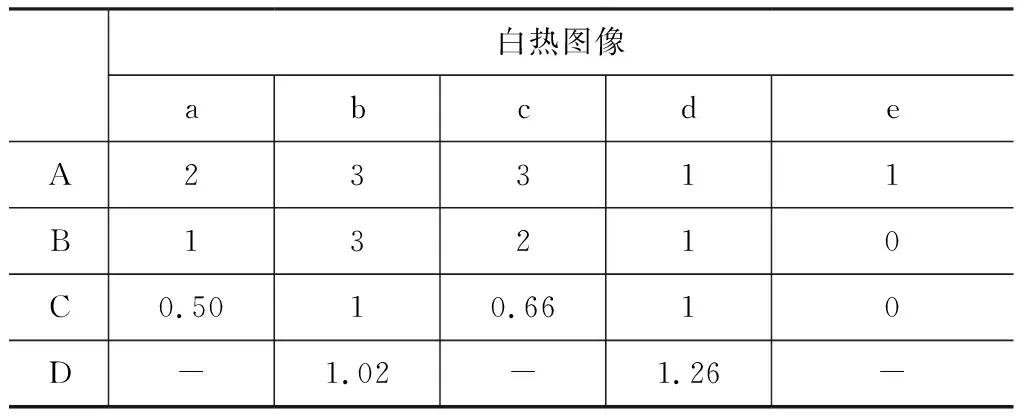
表1 白热图像“可行性”实验指标分析表
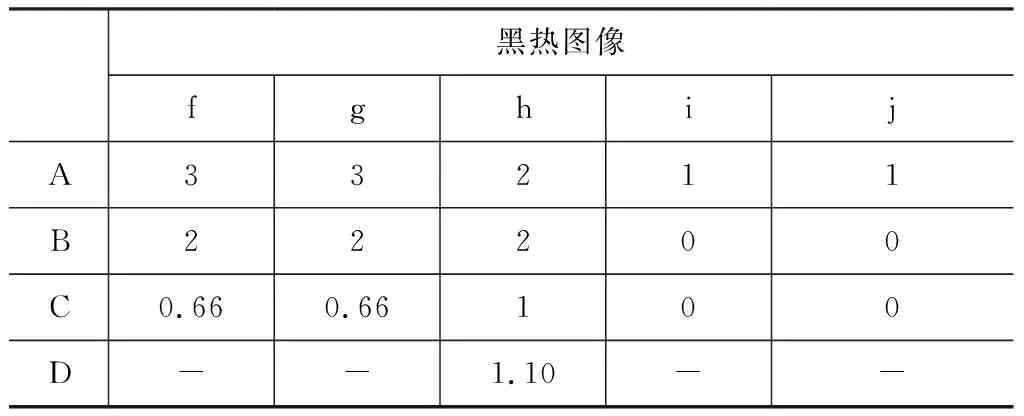
表2 黑热图像“可行性”实验指标分析表
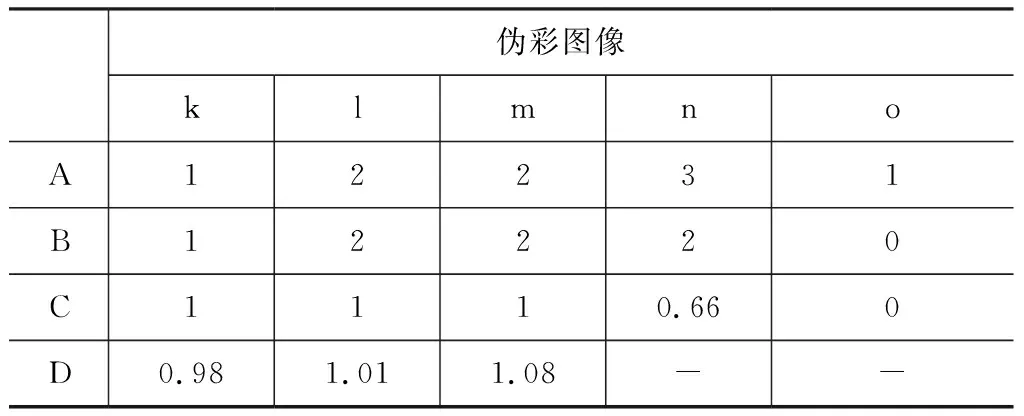
表3 伪彩图像“可行性”实验指标分析表
5.3 性能对比实验
5.2节中验证了本算法的可行性。在本节中,我们将对比于“可见光条件”下的检测精度。实验环境,采用双光采集设备(可见光+热红外),同步采集可见光和热红外图像,在通过相关算法预测出可见光下的人脸区域,并将该区域,同步到热红外图像中,绘制出区域A,再通过本算法以标记了区域A的热红外图像作为测试图像,绘制预测区域B,对比区域A和区域B,以测试本算法的精确度Acczones。其公式如下:
(5)
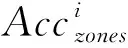

图6 性能对比实验图
图6中粗框为通过可见光同步并标记温度的预测框,细框为本算法预测框,文字信息为算法的实时帧率;本次将市面上使用的一种“疫情监控系统”相关算法作为对比对象。从图6(b)、(d)中明显可以发现,对比算法的预测框位置偏差较大,考虑到双光设备之间的偏差,我们默认预测框标记在合适的位置。
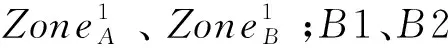
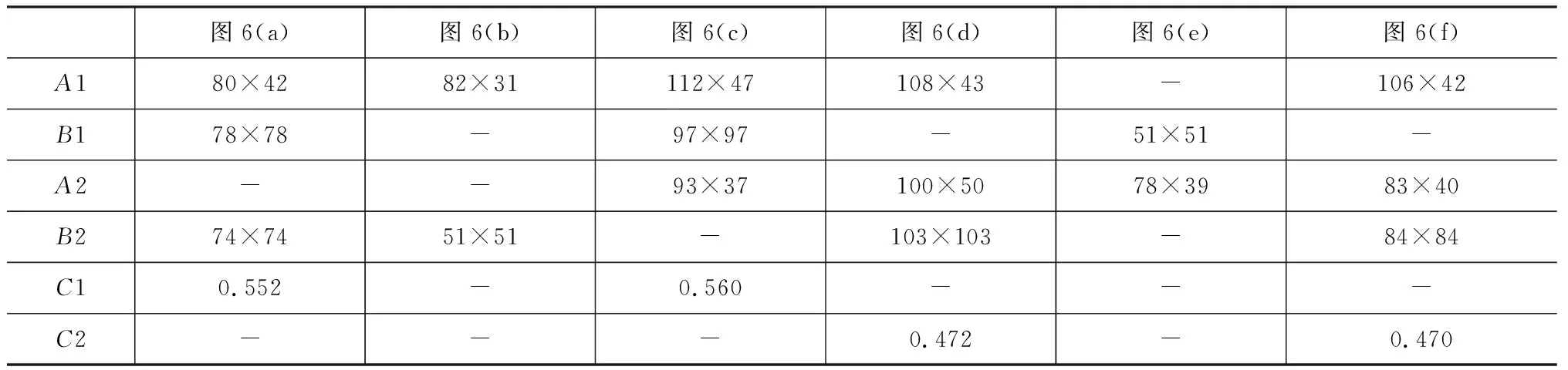
表4 可见光预测框与本算法预测框Acczones 对比
通过本次实验的结果图和相关数据对比,可以得出对比市面上特定的双光算法,本算法对于硬件依赖性更小。同时本算法在对于中、小尺寸的人脸检测上,具有一定优势,检测精准度也与特定双光算法精度相当。但在大尺寸的人脸检测上本算法显示出不足。
5.4 实时性测试
因深度学习模型的高计算量很难实时应用,所以深度学习模型的优化和硬件加速也成为了当前重要的研究方向。OpenVINO ToolKit是Intel发布的一套深度学习推断引擎,支持各种网络框架。在Intel平台上可以提升计算机视觉相关深度学习性能达19倍以上,解除CNN-based的网络在边界设备的性能瓶颈,对于OpenCV,OpenXV*等视觉库实现了加速和优化[17]。我们利用OpenVINO提供的工具,对算法模型进行了转换,生成可供OpenVINO使用的相关文件,在硬件平台上进行了相关测试。硬件平台于5.1节的测试平台相同。在CPU模式下,本算法的实时性达到30~33 f/s,可实现实时检测。如图6中记录实时帧率。
6 总 结
针对疫情期间的“体温监控”系统中双光(可见+热红外)人脸检测算法对硬件依赖性较强,本文提出了一种基于MobileNet-SSD网络的红外人脸检测算法,该算法直接对热红外图像进行人脸检测,极大程度的降低了热红外人脸检测对于采集设备的依赖。对比市面上使用的“测温监控系统”中双光人脸检测算法,本算法在中/小尺寸的人脸检测上,具有一定的优势,同时检测精确度也接近双光检测精度。通过OpenVINO加速,该算法可以实现实时检测。但是本算法也存在不足之处,如大尺寸单人检测条件下,检测率较低;训练数据集样本较少等问题。后期将针对这些不足之处,继续进行深入的研究。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
金桥(2021年4期)2021-05-21 08:19:20
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2019年7期)2019-04-25 13:17:14
动漫星空(2018年9期)2018-10-26 01:17:14
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
光学精密工程(2016年3期)2016-11-07 09:03:43
发明与创新(2015年33期)2015-02-27 10:40:09
