
档案领域本体数据集衍生证据价值实现机理探析
2021-02-06 03:50赵生辉西藏民族大学管理学院
浙江档案 2021年1期
赵生辉/西藏民族大学管理学院
胡 莹/云南大学历史与档案学院
1 问题提出
伴随着人工智能时代的到来,档案管理和利用的模式正面临一系列重大变革:档案管理对象由“文献”转向“内容(知识)”;档案信息获取由基于文献的“碎片式获取”转向基于本体的“聚合态获取”;档案信息服务由“档案文献检索”转向“社会记忆问答”[1]。上述变化对传统档案信息组织形态提出了全面挑战。建设具有整体性特征,可以支持大规模档案文献内容检索和语义推理的档案数据服务基础设施成为大势所趋。“档案领域本体数据集”是随着人类进入智能社会而出现的一种具有融合特征的新型档案信息资源组织形态,是由大量从档案文献当中抽取的数据元素,按照语义网络模型融合而成的,用来模拟和反映社会历史领域各类实体属性之间的语义关系及其运动变化过程的大规模关联数据集合[2],其生成原理如图1所示。
图1中,人类的档案管理活动总体分为“实物档案管理”“电子档案管理”“本体档案管理”三个阶段,由计算机和互联网技术驱动的“档案数字化”标志着“实物档案管理”向“电子档案管理”的迁跃,由人工智能技术驱动的“档案数据化”则标志着“电子档案管理”向“本体档案管理”的迁跃。“档案数字化”成果体现为支持档案文献检索的原生电子档案、再生电子档案及其管理元数据;“档案数据化”成果则体现为由档案文献内容数据融合而成的“档案领域本体数据集”。与“档案数字化”可以通过高精度扫描最大限度保留档案文献外在形式特征所不同的是,档案领域本体数据集与作为其来源的档案文献在外在形式上已经发生了极为显著的变化。例如,文书档案的内容通常表现为具有特定结构的自然语言文本,而从中抽取的关键内容信息则表现为参照资源描述框架RDF生成的语义三元组数据,上述数据分别与相关实体建立关联之后就融入了本体,数据之间的“边界”将不复存在,已经无法直接通过呈现形式来直观判断两者是否具有一致性。然而,无论是旨在为用户提供精准档案内容服务的社会记忆问答系统,还是为用户提供基础业务数据验证服务的档案智能应用系统,用户都不再需要逐一查阅档案文献,所利用的对象仅限于计算机按照特定算法从档案领域本体数据集中检索的数据或生成的答案,双方建立信任的前提就是必须通过某种形式确认作为数据源的本体数据集本身是真实可靠的,具有与其来源文献类似的证据价值。
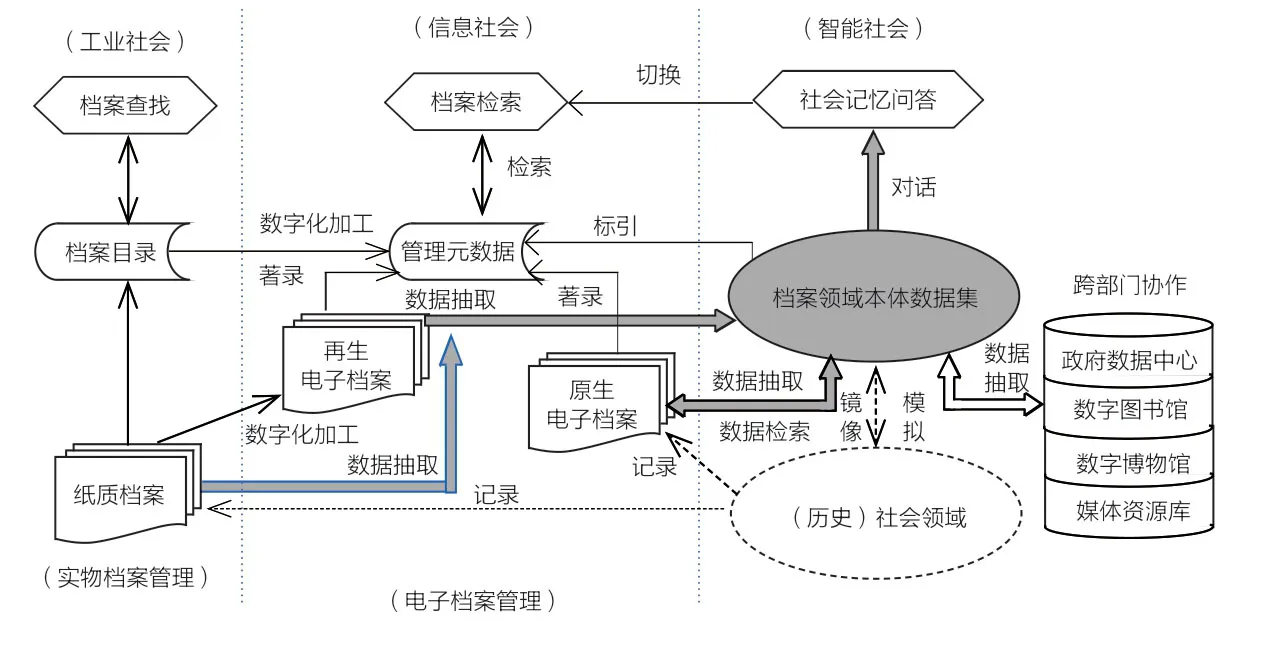
图1:“档案领域本体数据集”的生成原理
档案的证据价值源于其原始记录性,维护档案文献的原始记录性是档案管理的核心任务[3]。由纸质档案文献经过数字化加工形成的“再生型电子档案”和由档案文献数据抽取融合而成的“档案领域本体数据集”本质上都是为了更好地利用原始档案文献而对其进行二次加工生成的“二次资源”,本身并不具备原始记录属性,其在档案服务当中直接作为证据使用的效力是受限的[4]。实践中,档案数字化成果的可信性主要是通过对档案数字化加工过程的严格规范控制来实现的。如果所有加工处理环节都是受控的,扫描件最大化保留了原始档案文献的外在特征且核心内容经过严格的人工比对和确认,所有背景信息都在元数据中进行了详细著录,则可以认为该再生型电子档案具备与原始文献证据属性类似的“证据价值”。本文将这种从原始档案文献继承而来与原始档案文献证据价值相类似的准证据价值称为“衍生证据价值(Quasi Evidence Value)”。“衍生证据价值”并不是真正的证据价值,其产生是以原始档案文献的证据属性为前提和基础,并依附于原始档案文献而存在:当再生电子档案和来源纸质档案文献同时出现时,默认为以原始纸质档案文献为准;如果来源档案文献证据属性被确认不成立,衍生证据属性也会随之消失。“衍生证据价值”也不是完全的证据价值,而只是从原始档案文献当中继承的一部分属性,纸张、墨迹等纸质档案所独有的属性无法传递给再生电子档案,因而被认为证据属性不足时,通常需要向纸质档案回溯,即由相关机构提供档案文献的纸质原件。随着我国各类数字档案馆建设的推进,作为档案数字化成果的再生型电子档案衍生证据价值保障已有相对成熟的解决方案,而作为档案数据化加工成果的“档案领域本体数据集”的“衍生证据价值”的内涵及其实现机理、保障机制等问题目前尚无定论,亟待学界进行深入探索。
2 价值解析
电子档案证据价值主要来源于其真实性(Authenticity)、完整性(Integrity)和可读性(Availability)等作为证据向相关机构或个人提供时所必须具备的特征[5]。“档案领域本体数据集”的衍生证据价值来源于电子档案,在继承上述特征的同时,由于信息组织形式的差异性,每一种属性都会有新的内涵。
2.1 档案领域本体数据集的真实性
电子档案的真实性指文件的核心内容、逻辑结构和背景信息始终维持着形成之初的状态,作为证据使用时必须具备的各类要素在导出、传输、迁移等操作过程中始终保持完好,没有被任何人做任何改动。电子档案的真实性是针对整个文献而言的,如果档案文献被确认具有真实性,经过规范化流程和方法对文献各个组成部分进行解析和抽取之后形成的所有数据元素也就相应地具有真实性。“档案领域本体数据集”是从档案文献当中抽取的具有真实性的数据元素经过关联与融合而成的,因而“档案领域本体数据集”的真实性是由构成它的大量语义数据元素的真实性来保障的,如果构成档案领域本体数据集的每一条数据记录的真实性都有可靠证据来证明,则可以推论出整个数据集也是真实可信的,对该数据集中的部分数据元素进行重新组合生成的子集也是具有真实性的,可以作为组合态的证据使用。
2.2 档案领域本体数据集的完整性
电子档案的完整性指电子档案在作为证据使用时,其所应该具备的各类要素同时具备且保存完好。档案领域本体数据集作为通过数据进行特定领域社会系统实体关系网络的数字态模型,其完整性主要取决于数据集所录入实体和关系的覆盖面,即特定领域绝大多数实体关系都在本体数据集当中进行了相对完整的描述和表达。档案领域本体数据集反映的是人们以档案为依据对特定领域知识结构的认知结果,而这种认知能力始终是处于动态发展过程中的,现阶段还没有认识到的实体和关系就无法在本体当中进行描述,因而不存在完全意义上“完整”的本体数据集。档案领域本体数据集的完整性维护主要是在现有认知范围内,通过人工或者机器方式,把对应社会领域真实存在的实体和关系尽可能全面地在本体当中予以体现。
2.3 档案领域本体数据集的可读性
电子档案的可读性指作为证据使用时,可以通过相关设备和软件顺利读取和显示的属性。档案领域本体数据集的可读性主要是指其作为社会记忆数据基础设施时,具有被其他相关应用程序顺利读取和计算的能力。为此,数据集应当尽可能遵循标准规范,使用具有通用性的技术方案,以便可以与其它应用程序实现“互操作”。目前国际互联网联盟推荐的本体描述语言为OWL(Ontology Web Language),底层代码采用可扩展标记语言XML,按照资源描述框架RDF进行数据关联,整个本体数据集形式上表现为纯文本代码,独立于任何专门硬件和软件,跨系统读取、传输和互操作等功能均可实现。
3 实现机理
“档案领域本体数据集”的“衍生证据价值”是其作为人工智能时代智慧档案服务基础设施可以被社会大众所信任和接受的前提条件,必须通过系统性的解决方案予以全面保障。鉴于“档案领域本体数据集”可读性的保障相对容易,本文重点讨论其真实性的衍生机理和完整性的扩展机理两方面的问题。
3.1 档案领域本体数据集真实性的衍生机理
“档案领域本体数据集”真实性来源于电子档案的真实性。如果电子档案的真实性已经得到确认,则可以认为档案文献的内容信息也具有真实性,即自形成之初就保持着其原有的状态。如果构成档案领域本体数据集的所有数据元素都来源于可信电子档案,虽然数据元素的组合形态已经发生变化,由于每一条数据都“有据可查”,则可以推论档案领域本体数据集也具有真实性。基于可信本体数据集,从其中检索到的任何一条数据记录或者若干数据记录的组合都具有证据价值,经过档案领域本体数据集的建设与管理机构签章确认,在司法和其他社会活动当中就可以直接作为证据使用,如图2所示。
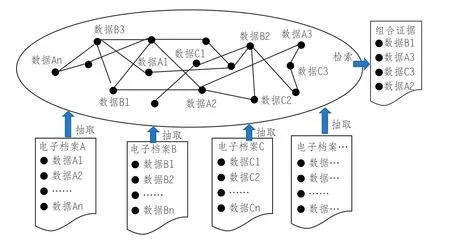
图2:档案领域本体数据集真实性的衍生机理
图2当中,电子档案所蕴含的内容信息通过抽取被描述RDF格式的语义三元组。例如,电子档案A所蕴含的数据包括A1,A2,……,An。来自不同档案文献的数据参照本体数据框架进行重新组合,逐渐由少到多,最终融合成为囊括所有来源文献核心内容的大规模语义数据集。在上述过程中,只要确保所有电子档案数据抽取和本体录入过程是符合规范的,本体数据集当中的任何一条数据都有据可查,则可以认为本体数据集整体上是具有真实性的,其中的部分数据经过组合之后形成的“子集”在特定的社会活动当中可以作为证据来使用,如来源于不同档案文献的数据B1、A3、C3、A2可组成整体性的证据文档。上述过程中,档案领域本体数据集本身不具备原始记录性,其真实性是由档案文献本身的原始记录性所决定的。正是由于档案本体数据集的真实性具有衍生性质,在司法或其他社会活动中,机构或个人对其真实性可以采信也可以质疑。当档案领域本体数据集的真实性受到挑战时,通常情况下需要对档案管理系统进行回溯,通过提供电子版的档案文献甚至纸质版档案文献原件,证明从档案本体数据集当中检索的结果是真实可信的。
3.2 档案领域本体数据集完整性的扩展机理
提高档案领域本体数据集完整性的措施主要有以下方面。第一,扩大档案文献抽取数据元素的范围,在国家档案法规允许的范围内,尽可能多地将已经依法公开的相关档案文献全部纳入数据抽取范围。在特殊情况下,如果档案文献还没有对公众开放,但是对其内容的总体性统计分析结果事关公共利益,可先进行档案文献的数据抽取和关联,再通过程序限制数据使用范围,在不向用户显示具体数据内容的情况下把总体性的数据统计结果反馈给用户。第二,加大与图书馆、博物馆、方志馆、文史馆、文化馆等公共文化服务机构的协作,按照互利共赢原则,将保存在上述机构当中具有档案属性的藏品也纳入数据抽取的范围,从而使有关同一实体的数据属性可以基于唯一的统一资源标识URI进行关联,用户一次性就可以获取之前需要到多个机构查阅文献之后才能获取的全局信息[6]。第三,充分利用语义推理技术,发掘人工抽取所没有识别出的隐含语义关系,进行本体数据集的补全。 第四,利用社会记忆问答平台的用户提问记录进行需求倒推,实现档案领域本体数据集的反向补全。
4 实践路径
4.1 制定行业标准《档案领域本体数据集建设与认证规范》
行业标准《档案领域本体数据集建设与认证规范》的核心价值在于确立档案数据服务的认证原则,即只有在严格受控的条件下建立的档案本体数据集才具有衍生证据价值,才可以在业务、司法和其他类型社会活动中被作为“准证据”使用。建议我国档案行政机关对智能社会背景下档案智能化服务数据基础设施建设的目标、原则、机制、原理、实施和认证等方面做出明确规定,尤其是对档案领域本体数据集的系统技术架构、顶层本体模型、本体描述语言、数据抽取方法、数据鉴定方法、数据集认证方法等给出较为详细的指导性意见,以便各层级的档案管理机构根据各自实际建设本体数据集时参考。
4.2 组建全国性的第三方档案领域本体数据集建设认证专业组织
与企业产品质量管理、环境保护控制等领域的认证类似,档案领域本体数据集可信性认证也是引导各级各类档案机构提升档案数据化加工的规范化程度,提高档案本体数据集质量的重要手段。建议在中国档案学会等中介组织的推动下,建立第三方专业组织“全国档案数据服务研究与认证中心”,并推动全国范围内档案领域本体数据集认证组织网络建设。“全国档案数据服务研究与认证中心”既是档案领域本体数据集建成后的质量认证机构,又是以全生命周期介入数据集建设的专业性的服务机构。作为第三方中介组织,“全国档案数据服务研究与认证中心”可以适度收取认证费用,以维持机构日常运转。
4.3 建设全国一体化的档案领域本体数据集关联融合平台
在全国范围内的档案领域本体数据集建设还没有启动的情况下,一开始就高起点规划,按照“云计算”架构建设全国一体化的“国家档案数据服务基础设施平台”,不仅可以减轻地方政府的财政负担,而且可以对涉及全国范围的公共实体及其语义关系作出统一描述。各层级档案管理机构的档案数据化加工只需要依托国家档案数据服务基础设施平台,按照模板录入各自领域或权限范围内的数据即可。在全国各层级、各部门的档案文献数据都录入基础设施平台的情况下,全国范围内有关同一实体的各类档案文献所蕴含的信息就依托平台融为一体,用户不再需要去查阅大量档案文献就可以一次性获取实体对象的全方位属性数据。
4.4 构建档案领域本体数据集全生命周期质量保障体系
档案领域本体数据集的衍生证据价值是由其建设过程的规范性来确认的,需要从软件架构设计到来源文献选取、数据抽取、数据关联、数据服务、数据维护的全生命周期进行整体性控制。建议从“档案领域本体数据集”立项开始就由第三方专业认证机构参与,对于技术架构、领域本体顶层模型、数据模板等方面的规范性进行确认。基础平台建成之后,需要对作为数据来源的档案文献的范围和质量进行重新确认。数据抽取过程中,需要确保抽取原则和方法的一致性,由机器自动抽取的结果必须由人工确认之后才能录入本体数据集,并通过建模软件或者权威机构提供的逻辑一致性测试工具进行测试,确保关联到数据集当中的所有数据语义关系的明确性和一致性。基于档案领域本体数据集提供智能化档案服务时,需要在遵守国家档案开放和利用相关法律规章的前提下,尽可能满足用户的档案需求。
猜你喜欢
齐鲁艺苑(2022年1期)2022-04-19
哈哈画报(2021年10期)2021-02-28
安徽文学·下半月(2018年5期)2018-08-18
幼儿智力世界(2016年6期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
小雪花·初中高分作文(2015年10期)2015-10-24
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
雕塑(1998年3期)1998-06-28
