
贝叶斯个性化排序的代码评审员推荐方法
2021-02-05 03:25赵海燕陈庆奎
小型微型计算机系统 2021年1期
李 敏,赵海燕,陈庆奎,曹 健
1(上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海理工大学光电信息与计算机工程学院,上海 200093) 2(上海交通大学 计算机科学与技术系,上海 200030)
1 引 言
代码评审是指让其他团队成员检查软件质量的过程,其目的是用来提高工作的质量.目前代码评审分为两种方式:1)传统代码评审;2)现代代码评审.由于传统代码评审整个流程比较繁琐和费时,一定程度上阻碍了它在实践中的运用.现代代码评审是一种作为非正式的、轻量级的、基于工具的代码评审方法,比传统评审更节约成本和时间,因而在专有软件和开源软件开发中得到广泛使用[1].
在开源软件开发中,经常以Pull请求的方式提交代码,然后Pull请求需要被评审以确定是否可以合并到软件中.找到积极且在对应的专业知识领域具有丰富经验的评审人员成为一大难题.从开发者的角度来说,每个软件开发者希望自己提交的代码能够在最短的时间内得到有效的评审;从候选评审者的角度来说,在安排合适工作量的前提下,更倾向于评审属于自己擅长领域的代码.然而事实并非如此,Thongtanunam等人员发现在进行代码评审时,相比不进行评审人员分配,进行评审人员分配往往还需要多消耗12天的时间[2,3].所以,在代码评审中,自动推荐合适的代码评审人员,具有重要意义.
近年来,研究代码评审人员的自动推荐受到了学术界广泛的关注.例如,某些研究者提出基于文件路径相似度、基于社交关系、基于信息检索及基于活跃度等推荐算法.这些算法通过分析Pull请求历史评论信息,在历史记录中,挑选出和新Pull请求最相似的Pull请求,将挑选出Pull请求的评论者作为推荐人选.这些算法归根到底是以不同方面的相似度作为推荐的最终条件,但并没有考虑到不同候选评审者在这些方面有不同的兴趣偏好.
基于以上推荐算法存在的不足,本文提出了基于贝叶斯个性化排序(Bayesian Personalized Ranking简称BPR)的评审者偏好获取模型,以更为个性化的的方式对代码评审人员进行推荐.该算法的思想是当评审人员评审了Pull请求i,却没有评审Pull请求j,则表明相比j,用户更愿意评审i.此模型从评审者的专业知识、积极性、社交关系和对相关代码的熟悉程度4个维度出发,获取评审者的个性化兴趣,以实现更为准确的推荐.
2 相关工作
在早期的代码评审人员推荐研究中,THONGTANUNAM等人提出基于文件路径相似度算法[4].该算法假设基于同一个目录下的文件密切相关且函数功能相似,则工作相似文件路径下的评审人员适合作为代码评审候选人.此算法的优点简单易行,缺点是对于那些虽然工作在不同目录、但是从技能上看也是合适的评审用户容易被忽略.JEONG等人利用开发者和候选评审者之间的社会关系进行推荐[5].通过分析开发者和代码评审人员的历史互动情况,得知两人之间的关系密切程度,关系越密切越适合作为候选人.该算法的不足是所利用的社交信息并不那么容易获取且存在信息不全等因素,导致并未将某些潜在的评审者纳入推荐的范围.Huzefa Kagdi1等人提出基于开发者所提交的内容信息进行推荐,该方法称之为信息检索的方法[6-8].通过TF-IDF及SVM支持向量机等方法将重要信息提取并进行向量化,最终根据文本相似度进行推荐.但是这些算法的考虑比较单一,没有结合开发者和评审人员本身属性,导致泛化性能不是很好.Jiang等人根据候选评审人员的活跃度进行推荐,该方法假设如果评审人员在某段时间内参与代码评审越多,认为此评审者在这段时间内越活跃,也就越愿意进行更多的评审[8,9].该算法只考虑评审者在某段时间内是否活跃,并没有考虑到代码评审领域与候选人所擅长的专业知识领域是否符合.
显然,在推荐算法中把多种因素结合起来可以提高推荐效果.如Xia等人提出基于文件路径和文本信息相结合的TIE算法[10],Yu等人提出基于社交关系与文本内容相结合的算法[11,12].进一步,Ouni等人把评审人员推荐问题定义为优化问题,提出RevRec算法[13].YANG Chen等人提出基于文件路径和文本内容信息和评审人经验相混合的二层推荐混合算法Hybrid mendth[14],Zhengli,n Xia等人提出混合模型PR-CF算法[15].Emre S 等根据对特定程序的熟悉程度自动推荐最适合的审阅者[16].这些混合型的算法虽然综合考虑了不同方面因素的影响,但并没有从评审人员的角度深入分析.不同评审人员的兴趣偏好不同,会对相同的Pull请求作出不同的反应,并且兴趣偏好作为评审人员的内在属性,并不会因Pull请求的变化而发生相应的改变,因此把掌握评审用户的兴趣偏好显得至关重要,所以在本文中提出了基于贝叶斯个性化排序模型的推荐算法来改进代码评审人员的推荐效果.
3 基于贝叶斯个性化排序模型的评审者推荐方法
3.1 BPR-CR2模型概述
在代码评审者推荐时,必须综合考虑各方面因素,影响推荐效果有许多因素[17],本文考虑选出具有代表性的因素进行获取:
1)评审者的知识领域与Pull请求的匹配性:Pull请求中的代码涉及的知识应该是评审者比较熟悉的.由于Pull请求涉及的知识难以直接刻画,我们利用Pull请求的文本对其涉及的知识进行表示;
2)评审者本身的活跃性:评审者是否积极是推荐能够成功的重要因素;
3)评审者与Pull请求提出者的社交关系:一般而言,人们更愿意评审熟人的Pull请求;
4)评审者对代码的熟悉程度:在大多数大型系统中,具有类似功能的文件通常位于相同或相接近的目录,所以通过文件路径之间的相似性能够反映评审者对代码的熟悉程度.
评审者在选择Pull请求时,将综合考虑以上因素,通过一定的系数对这些因素进行加权并不能反映不同评审者对这些因素具有不同的敏感性.因此,本文提出了一种基于贝叶斯个性化排序思想,学习评审者对不同因素的选择偏好,从而能够计算评审者对某一Pull请求的意愿的模型BPR-CR2(Bayesian Personalized Ranking based Code Reviewer Recommendation Model).整个模型分为参数学习阶段和预测阶段组成,参数学习阶段的目标是根据历史数据学习出每个评审者的选择偏好,为预测阶段做准备,而预测阶段是针对每个Pull请求推荐评审者.
3.2 BPR-CR2模型的构建
3.2.1 Pull请求的评审者因素度量
正如前文所述,我们从4个方面对评审Pull请求的因素进行衡量.
1)评审者的知识领域与Pull请求的匹配性
我们将Pull请求的历史数据作为输入,并提取出每个Pull请求的描述及标题并形成语料库,然后使用TF-IDF算法将Pull请求进行向量化处理,其中TF-IDF算法如公式(1)所示:
tfidf(t,pr,corpusPR)=
(1)
其中,t是某个Pull请求中抽取的技术术语,pr为某个Pull请求,corpusPR是由历史数据的Pull请求的描述及标题形成的语料库,nt是技术术语t在pr中出现的总次数,Npr是技术术语在语料库中出现的总的次数.
利用余弦相似度衡量评审者之前评审过的Pull请求与目标Pull请求之间的相似性如公式(2)所示:
(2)
其中,pnew及p′分别代表目标Pull请求和历史记录中的Pull请求,vnew及v′分别为pnew及p′对应的向量.
则评审人员的兴趣与pnew的内容的相似性值记为SimCont(Revieweri,pnew)如公式(3)所示:
(3)
上式中Revieweri表示第i个候选评审者,PRi是候选评审者Revieweri以前审核过的Pull请求集合.
2)评审者本身的活跃性
据调查显示,候选评审者的积极性会随时间的变化而变化,某些代码评审者可能不活跃或短期时间内不活跃,最近活跃的代码评审者倾向于对新的Pull请求做出评论[18].
本文中使用最近的评论来衡量用户的活跃度,如公式(4)所示:
Act(Revieweri,pnew)=
(4)
其中,ComSi为评审者Revieweri各个Pull请求中的所有评论集合,γ是时间窗口的长度,λ是时间衰减因子,timepnew为新Pull请求的创建时间,timeCj为代码评审者Revieweri的某条评论Cj的创建时间.
3)评审者与Pull请求提出者的社交关系
通过社交关系可以快速获取具有参考价值的候选代码评审者.开发人员之间的社交关系紧密程度可直接通过评审者和贡献者之间的评论关系来体现,其社交关系影响程度如公式(5)所示:
(5)
提交新Pull请求的贡献者为Submitter,由贡献者Submitter提交且处于新Pull请求之前的所有Pull请求集合定义为PRSubmitter,PRi是包含用户Revieweri发表过评论的所有Pull请求集合,nij表示代码评审者Revieweri在Pull请求pj中一共留下第nij条评论.β是其中的调节参数,经实验将值设置为0.8最为合适.
4)评审者对代码的熟悉程度
基于同一个目录下的文件密切相关且代码功能相关的思想,计算用户评审过的Pull请求与新Pull请求的文件路径相关性如公式(6)所示:
FileRel(Revieweri,pnew)=
(6)
其中,Fp′表示历史Pull请求p′更改的相关文件,Fpnew表示为新Pull请求pnew更改的相关文件,similarity(f,f′)表示两个文件之间相似度.可以采用字符串比较具体计算文件目录的相似性,具体如公式(7)所示:
(7)
上式中f,f′分别表示在历史Pull请求和新Pull请求涉及到的两个文件,max(Length(f),Length(f′))取两个文件的长度的最大值,其中commonPath(f,f′)计算两个文件路径中的公共目录的数量,具体计算方法如下:首先,根据文件路径,将路径字符串其目录分隔符进行切分,得到该文件所处位置的目录层次列表;然后比较两文件的目录前缀,取重合的公共目录数为得到的结果.例如,对于某安卓项目,有以下两个文件,分别为/src/camera/photo/a.java和/src/camera/video/a.java,则可得两者公共祖先目录为/src/camera文件夹,因而两路径的公共目录数量为2.
对于评审者集U和Pull请求集PR,其中的某一评审用户Revieweru与某一Pull请求p,将Revieweru与p之间的相关性用向量spu表示,由上文中的Pull请求的文本特征相似度、评审者活跃度、社交关系影响程度及文件路径相似性值组成,具体表达式如公式(8)所示:
(8)
3.2.2 基于BPR的评审者选择偏好建模
BPR是基于贝叶斯理论在先验知识下极大化后验概率,由Steffen Rendle提出的一种面向隐式反馈偏好数据的排序模型[19].这种排序模型能够较好的对用户的正负反馈进行建模,且可以与传统的协同过滤模型如矩阵分解模型相互结合[20].
将评审者的偏好用权重矩阵记作W,其维度为4×‖U‖,4代表评审者特征维数:
(9)
wu是矩阵W的第u列元素构成的列向量(u=1,2,3,…,‖U‖),表示Revieweru在文本特征相似度、评审者活跃度、社交关系影响程度及文件路径相似性值四个维度上的权重,具体表示如公式(10)所示:
(10)
其中,代码评审者的偏好权重,属于评审者的自身属性,不会因Pull请求的更改发生相应的变化.
评审者的偏好信息可从评审者是否参与评审的行为直接体现.因此,在求解用户偏好向量前,需对评审者的行为进行记录,用来作为求解模型参数W.具体记录方式为当评审者参与过目标Pull请求的评审,记为数字1,反之记为0,整个记录用矩阵A表示,该矩阵是一个‖PR‖×‖U‖的二维矩阵,其值由0、1组成.使用变量S代表评审者对不同pull请求之间的关系矩阵,其维度为‖PR‖×‖U‖×4,具体表达式形式如公式(11)所示:
(11)
其中,各个元素spu(p=1,2,3,…,‖PR‖;u=1,2,3,…,‖U‖)代表pull请求PRp和用户Revieweru之间的特征向量,定义于公式(8).
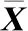
(12)

(13)
针对某个特定的Pull请求,需满足评审者分数高于未评审者分数,这里借助贝叶斯个性化排序思想,从已记录的矩阵A中将评审者对Pull请求的评论进行标记,如果评审者Revieweru同时面对pri和prj时,评论了pri却没有评论prj,则记录一个三元组
这里有两个假设:1)每个代码候选评审者的偏好行为相互独立即代码评审者Revieweru在pri和prj之间的偏好和其他代码评审者无关;2)同一代码评审者对不同pri和prj之间的偏好和其他的Pull请求无关.对用户Revieweru的偏好用符号>u表示,则
完整性:∀i,j∈I:i≠j⟹i>uj∪j>ui
对称性:∀i,j∈I:i>uj∩j>ui⟹i=j
反对称:∀i,j,k∈I:i>uj∩j>uk⟹i>uk
基于最大后验估计P(wu|>u),用>u表示候选代码评审者Revieweru对应的所有Pull请求的全序关系,则优化目标是P(wu|>u).根据贝叶斯公式可知公式(14):
(14)
由每个代码评审者的偏好行为相互独立,则对于任意一位代码评审者Revieweru来说,P(>u)对所有的Pull请求一样,则有如公式(15):
P(wu|>u)∝P(>u|wu)P(wu)
(15)
根据公式(15)可将优化目标转化为两部分.第1部分和样本数据集D有关,第2部分和样本数据集D无关.针对第1部分,根据代码评审者的偏好行为相互独立及同一候选评审者对不同Pull请求的偏序相互独立,可推到公式(16):

(16)
其中δ(b)公式(17)如下:

(17)
由排序关系满足的完整性和反对称性,将第1部分优化目标简化为公式(18):
(18)
为进一步优化计算及满足排序的3个性质,将优化目标转化为公式(19):
(19)

(20)
基于贝叶斯假设,可知第2部分P(wu)符合正态分布,其均值为0,协方差矩阵是λwS,λwu是模型中的正则化参数,如公式(21)所示:
P(wu)~N(0,λwS)
(21)
P(wu)的对数和‖wu‖2成正比,如公式(22)所示:
lnP(wu)=λ‖wu‖2
(22)
最终根据最大对数后验估计函数将优化目标成公式(23):
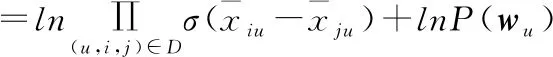
(23)
将优化目标函数推导之后,使用梯度上升法求解参数,对W求导如公式(24)所示:
(24)
由于
(25)

(26)
在优化过程中,对矩阵W进行随机初始化,并迭代更新模型参数,当W达到收敛状态可得用户权重矩阵W,设α为梯度步长,正则化参数λ,由公式(24)-公式(26)可得W参数梯度迭代如公式(27)所示:
(27)
3.3 评审者推荐
以上阶段为本模型的训练阶段,从训练阶段可得评审者权重向量wu,针对模型预测阶段,本文使用预测阶段的数据集作为模型的输入,从输入的数据集中提取出评审者与目标Pull请求之间的关系向量spu,则评审者Revieweru对目标Pull请求的得分为:
(28)
通过对所有的评审者计算该得分,分数越高的评审12者越适合作为推荐人员,最终使用降序排序,取前top-K作为推荐候选人选.
4 实验结果分析
4.1 实验数据
为了验证本模型的有效性,本文使用Github提供的REST API,通过调用这些API接口,获取了目前流行的angular、ipython、netty、salt及symfony的5个大型项目的原始数据.其中angular/angular.js项目是一种构建动态Web应用的结构化框架,ipython项目是一个升级版的交互式python命令行工具,netty项目是由JBOSS提供的一个java开源框架,saltstack项目是一个服务器基础架构集中化管理平台,具备配置管理、远程执行、监控等功能,symfony项目是一款基于MVC架构的PHP框架.所有这些项目都是各自领域的代表性项目.这些项目在Github平台非常受欢迎,每个项目平均有1643个人进行关注,19850个人进行点赞,9017个人进行拷贝,另外,这些项目开发的软件被得到广泛的应用,在各自领域发挥着重要作用.
获得的数据中包含了近9年的信息,即2010年12月-2019年6月.在实验过程中,针对Pull请求数据,将其评论数量小于2和未合并的数据给剔除,经筛选之后的统计实验数据如表1所示.
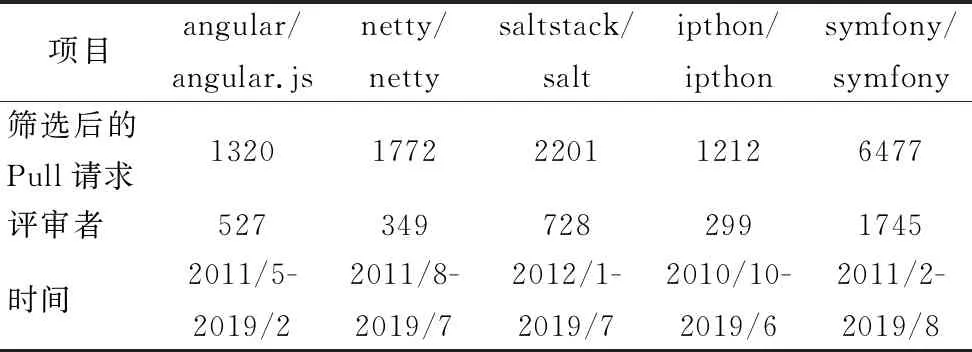
表1 实验数据统计Table1 Experimental data statistics
4.2 评价指标
对于评审者推荐结果的评价,研究者们主要使用精确率(Precision)、召回率(Recall)、综合评价指标(F-Measure)等[22-24].当模型返回的是排序的K个推荐结果,然后可以根据Top1到TopK的精确率和召回率以及F-Measure来得到对模型的进行评价.
1)精确率:又称查准率,正确推荐的评审者数目占模型预测的评审者总数的比例.其计算公式如公式(29)所示:
(29)
上式中,Recom_Reviewers(i)代表给第i个Pull请求推荐的评审者,Actual_Reviewers(i)是第i个Pull请求的实际评审员,m是每个项目中测试Pull请求的数量.
2)召回率:又称查全率,正确推荐的评审者数目占所有评审者数目的比例.其计算公式如公式(30)所示:
(30)
上式中的各变量含义同上.
3)F-Measure:是Precision和Recall加权调和平均.综合了以上两个指标的结果,当F值较高时则说明实验方法比较有效.
(31)
4.3 实验结果及分析
为了验证该算法的性能,选取近年来较流行的Hybrid Method算法[14]、Actiness算法[10]、IR+CN算法[12]、IR-based算法[7]、File-Path[4]算法作为对比实验.
为方便查看,在统计实验结果时,将性能指标值表现最佳的用粗体显示,如表2所示.

表2 不同算法间性能对比Table 2 Performance comparison results between different algorithms
同时为直观显示BPR-CR2算法的性能,本文给出不同算法在不同项目topK推荐的性能指标统计图,指标分别包括精确率,召回率及f值,5个项目分别为图1-图5所示.
从实验结果可以看出,BPR-CR2算法在不同项目中的性能表现不一样,从图1-图5显示BPR-CR2算法在5不同项目中的指标性能均比对比算法高.

图1 Symfony项目Fig.1 Symfony project

图2 Saltstack项目Fig.2 Saltstack project
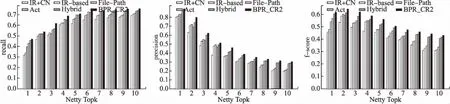
图3 Netty项目Fig.3 Netty project
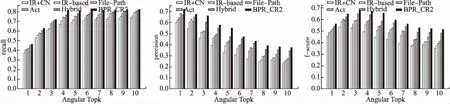
图4 Angular项目Fig.4 Angular project

图5 Ipython项目Fig.5 Ipython project
实验结果表明,BPR-CR2算法优于其他算法.具体而言,从表2中观察可知,BPR-CR2算法在25次模型预测中获得23次最佳的结果.从图1-图5可以观察出BPR-CR2算法性能在不同项目之间表现不同,同时其他算法也类似,并且BPR-CR2算法总处于最上端,并且在这些项目中,随着推荐个数均匀上升,项目的推荐召回率和准确率都会达到收敛的状态.与推荐前2名的IR+CN算法、IR-based算法、File-Path算法、Act算法、Hybrid算法提高了8.3%、5.8%、4.7%、3%、2%的召回率.由此可见,本文提出的BPR-CR2推荐模型可以达到较高准确率,证明本模型的有效性.
本实验结果较好可以追溯为两个方面的原因.第1个方面是本模型考虑的因素较为全面.分别涉及到评审者的专业知识、评审者对代码的熟悉程度、评审者的社交关系、评审者在某段时间内的活跃度,通过将这些因素有效的结合,最终实验结果比考虑单一因素的实验结果要好.第2个方面是本文从评审人员的角度出发,考虑到每个评审者在不同因素方面占据不同的偏好权重,并且不会因目标pull request的更改发生变化,本模型利用基于贝叶斯个性化排序的思想,求取每位用户在不同兴趣方面的权重偏好,相比其他的实验模型,本实验更能体现出个性化,从而实验结果比其他实验结果要好.由此可见,综合上述两方面原因,本文提出的BPR-CR2推荐模型可以达到较高准确率,证明本模型的有效性.
5 总结和未来展望
本文针对如何提高代码评审效率的问题,提出BPR-CR2推荐模型,该模型借助贝叶斯个性化排序的思想,融入了评审者在专业知识领域、活跃度、社交相关性、及文件路径相关性四个维度的偏好,同时,根据历史数据信息,将评审者与目标Pull请求之间的关系进行了量化.通过在5个流行的开源项目数据集上进行的对比实验,实验结果表明本模型比IR+CN算法、IR-based算法、File-Path算法、Act算法、Hybrid算法要好,分别提高了9.1%、7.0%、5.2%,4%,2.3%的召回率,证明本模型能够有效的提高代码评审的效率以及完成更为准确的推荐.
本模型首先使用的数据集来自Github平台,但不清楚该模型应用在其他平台效果如何,所以在后续工作可以进一步优化本模型和验证其他平台的项目的数据.其次,本模型对专业知识领域、活跃度、社交相关性、及文件路径相关性及评审者的选择偏好因素进行了考量,在未来工作中,可以从多方面角度分析,将其他有效因素也纳入考量的范围内.
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
数学学习与研究(2017年10期)2017-06-22
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
