
基于语境分类与遗传算法的微博情感分析方法
2021-02-04 06:53
软件导刊 2021年1期
(广西大学计算机与电子信息学院,广西南宁 530004)
0 引言
微博是基于互联网的应用,在其上发布和浏览信息具有低成本、便捷和及时等特征,随着互联网的蓬勃发展,微博逐渐发展成为主流社交平台之一。目前,微博拥有大量的活跃用户,这些用户随时随地发布或更新他们的状态、感悟和评论等信息。这些信息涉及面广,蕴含了大量价值。对微博文本进行情感倾向分析是当前微博数据挖掘研究的热点内容之一。挖掘微博文本情感倾向可得到用户对产品的喜爱程度[1]、政策支持度[2]、热点话题倾向[3]和立场[4]等相关信息,对产品生产和销售改进、政策研究及民众热点立场把握等问题都有重要参考价值。
文本情感倾向分析属于自然语言研究范畴,自然语言描述观点的多样性是影响文本情感倾向分析精度的主要因素之一。与新闻、论坛和贴吧等具备良好内容分类的媒体相比,微博内容宽泛,分类性差。当前,文本情感分析主要有基于情感词典和基于机器学习两种方法,均是在对文本进行分词的基础上通过某种算法进行文本情感极性计算。大量研究结果表明,这两种研究方法进行情感分析的精度均受到文本内容领域相关度的制约。由于同一词语在不同语境中可能表现出不同的情感极性,因此不区分词语语境对微博文本进行情感分析使得其精度难以保证。采用LDA 扩展模型是当前文本情感分析重要方法之一,但该方法的当前研究未能考虑同一词语在不同语境下情感极性差异及非特征情感词对微博文本情感极性的影响,若能将此二者加以考虑,则基于LDA 扩展模型的文本情感分析精度将得到进一步提升。因此,本文提出一种基于语境分类和遗传算法的微博情感分析方法。
1 相关工作
当前,文本情感分析主要有基于情感词典和基于机器学习两种方法。基于情感词典的方法是先抽取文本的情感特征词[5],然后将情感特征词和情感词典中的词语进行比对,运用情感词典中标注词语的情感极性计算微博情感倾向。该方法的分类精度依赖于情感词典,情感词典的好坏直接影响情感倾向计算结果。基于机器学习的方法是先提取文本特征,然后对特征运用某种算法进行分类[6],从而得到文本情感倾向。基于机器学习的方法分为强监督、弱监督和无监督3 种方法。强监督方法主要有支持向量机[7]、朴素贝叶斯[8]和决策树[9]等,这类方法的精度依赖于标签数据的准确率。弱监督方法主要有长短期记忆网络[10]、卷积神经网络[11]、循环神经网络[12]等,这类方法需要海量的标签数据对模型进行训练才能保证精度。无监督方法主要有LDA[13]、K-近邻算法[14]、随机森林[15]等,与有监督方法相比,无监督方法不依赖于标签数据,受数据量大小影响较小。在无监督方法中,LDA 得到研究者的广泛关注。LDA 是一种具有良好可扩展性的主题分类模型,一方面能发现语料文档的隐含主题,在机器学习方法中无需标签数据便可自动获得与情感词典相似的语义直接关联效果,另一方面能得到“文本—主题—词语”关系,具有良好降维性能。因此,越来越多的研究者将LDA 模型扩展应用于文本情感分析。孙艳等[16]在LDA 模型中融入情感模型,用LDA 得到情感特征词的情感极性,用情感特征词的情感极性分类表达微博的情感倾向;欧阳继红等[17]在LDA 模型中引入情感层,联合微博情感倾向的整体分布和情感特征词的局部分布进行计算,从而获得文档级别的情感倾向;苏莹等[18]引入朴素贝叶斯改进LDA,得到了篇章级和句子级情感倾向;李勇敢等[19]通过LDA 和句子依存关系计算微博情感倾向;黄良发等[20]将表情符号和用户性格特征融入LDA 中计算微博情感倾向;García 等[21]将LDA 与Word2vec 相结合,通过词的相似性判断新词极性,以获得句子情感倾向。
上述LDA 扩展模型是先提取文本情感特征词,然后利用情感特征词的极性计算句子或篇章的情感极性,在情感极性分类计算速度和精度上获得了良好效果,但仍然存在两个问题未能解决:一是同一词语在不同语境下的情感极性可能存在差异,例如有两条微博:“新买的U 盘,内存真的很大”和“楼上装修的声音未免太大了吧”。因这两条微博内容上分别属于不同的主题语境,“大”在第一条微博中有容量大的含义,极性表现为正极,而在第二条微博中有吵闹之意,极性表现为负极;二是没有考虑非情感特征词对句子或篇章情感极性的影响,例如对于微博文本“我们单位是一个好单位、我们虽然下班晚、但是我们上班早啊!”,用上述LDA 扩展方法得到的情感特征词是“好”、“晚”和“早”,微博文本情感倾向计算结果为正向极性,但如果将“好”+“单位”、“晚”+“下班”、“早”+“上班”结合起来,即将情感特征词“好”、“晚”、“早”和非特征情感词“单位”、“下班”、“上班”一起考虑,微博文本情感极性实为负极。
针对以上两个问题,为进一步提高采用LDA 模型扩展方法进行文本情感极性分析精度,本文提出一种基于语境分类和遗传算法的微博情感分析方法。该方法先用LDA模型对微博进行语境主题分类,并将微博词语划分到不同语境主题中,形成微博主题集和微博主题词集,然后对每个主题的微博和主题词集,采用遗传算法计算所有词语(包括情感特征词和非情感特征词)的情感值,最后利用词语情感值计算微博情感倾向。
2 微博情感分析方法
2.1 整体流程
基于语境分类和遗传算法的微博情感分类方法整体流程如下:①微博数据预处理,对微博数据进行筛选、分词;②LDA 微博主题语境词集构建,利用LDA 对微博进行主题语境分类,构建微博主题词集;③基于遗传算法的主题微博情感倾向计算。整体流程如图1 所示。

Fig.1 Overall flow chart图1 整体流程
2.2 微博数据预处理
微博平台面向大众人群,有些用户发布的信息目的性并不明确,其中有相当多的句子并不带有观点倾向。因此,先去除非观点句,只保留带有情感倾向的句子,再进行分词。中文分词工具主要有Jieba、SnowNLP、THULAC、NL⁃PIR 和PKU-SEG 等,微博内容较为简短,选择PKU-SEG 进行分词能较好地保持句子原有的组词关系。
2.3 LDA 微博主题语境词集构建
微博是相对开放和自由的媒体,相较于新闻、论坛等具备良好主题分类性能的媒体,其内容范围更宽泛和随意,没有严格的分类结构,因此在微博文本集中有相当多的词语在不同的语境中表现出不同的情感倾向。针对此种情况,本文首先对微博中的词语进行主题语境分类,按照不同语境对同一词语的情感极性加以区分,以提升微博情感分类判别精度。LDA 是一种文档主题生成概率模型,能够得到“文档—主题”、“主题—词语”分布,本文应用LDA 模型对微博文档集及其词语进行主题语境归类,依据主题语境划分构造微博主题集和微博主题语境词集。
2.3.1 LDA 微博主题语境分类
LDA 微博主题模型如图2 所示。LDA 微博主题模型是人工设定k 个主题,预处理后的语料库D 有m条微博,记为D={d1,d2,…,dm},微博分词后去重的词语个数为c,词集记为W={word1,word2,…wordc}。微博i的主题条件分布记为,i∈(1,2,…,m),采用LDA 微博主题模型可得到所有文档的主题条件分布,归一化后如公式(1)所示。
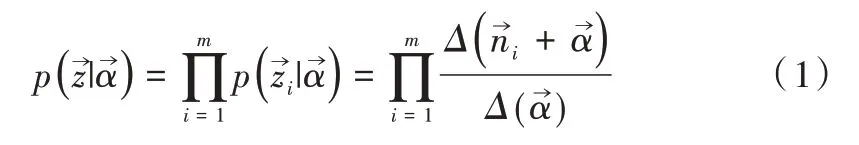

Fig.2 LDA Microblog theme model图2 LDA 微博主题模型
同样可得到词语wordt的主题条件分布记为,t∈(1,2,…,c),归一化后如式(2)所示。

结合式(1)和式(2),可得到主题和词语的联合分布如式(3)所示。
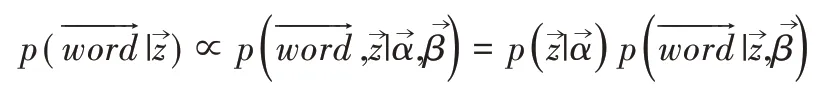

用¬(t)代表去掉第t个词语后的主题分布。用Gibbs 采样法得到第t个词语对应主题的条件概率如式(4)所示。
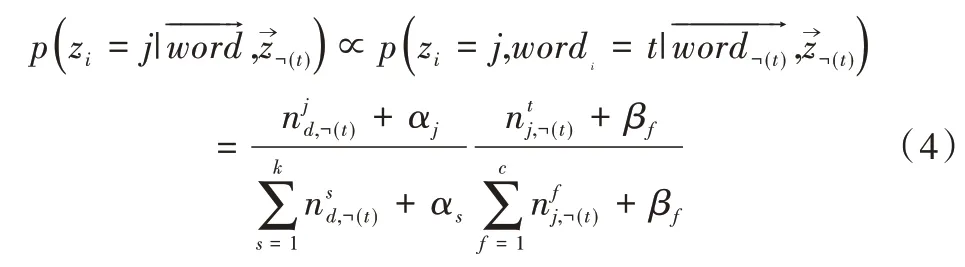
将微博d中所有词语的主题概率分布相加后得到该微博在k个主题下的概率分布Ad=,选择概率最大的值作为第d条微博所属主题语境归类pdMax=。
2.3.2 微博主题语境词集构建
按照上述最大概率划分方法,完成微博集合的主题语境分类,形成微博主题集T={T1,T2,…,Tk},其中Tj={dj1,dj2,…,djy},j∈(1,2,…k),y表示主题j的微博数量。对Tj中的微博进行分词、去重得到主题j的词集Zj,Zj=(vj1,vj2,…,vjn),n表示第j个主题词语去重后的个数。全部k个主题的词集就构成LDA 微博主题词集Z={Z1,Z2,…,Zk},LDA 微博主题词集构建算法伪代码如算法1 所示。

2.4 基于遗传算法的微博情感倾向计算
考虑到非特征情感词对微博文本情感倾向的影响,本文在计算出LDA 微博主题词集后,分别计算每个主题语境中所有词语的情感值,这些词语包括非特征情感词和特征情感词,最后利用词语的情感值计算出微博情感倾向。各主题词集词语的情感值用人工标注情感倾向的微博(标签数据)通过遗传算法计算自动获得。词语情感值计算方法首先在预先设定范围内给词语赋一个随机初始情感值;然后通过设计与标签数据相关的目标函数和适应度函数实现词语情感值自我优化,得到词语最优情感值;最后利用主题词语的最优情感值计算微博最优情感倾向值。用主题语境词集Zj作为遗传算法中的个体,个体Chromx对应Zj中所有词语的情感值,记作Chromx={wx1,wx2,…,wx3}。其中,wxt是个体x中第t个词语的情感值,每个词语的情感值对应个体的染色体编码。
种群由M个个体组成,记为P={Chrom1,Chrom2,…,ChromM},个体初始词语情感值为[-10,10]的一个随机值,如图3 所示。种群在遗传算法中不断迭代优化,当迭代次数达到预先设定值时所计算出的个体词语情感值为主题语境下所有词语的最优情感值。
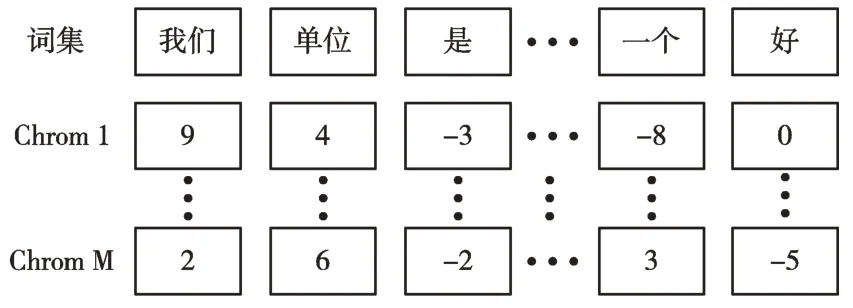
Fig.3 The emotional score of some initial words corresponds to the graph图3 部分初始词语情感分值对应情况
2.4.1 遗传算法目标优化函数
实际上,有些词语在不同语境中的情感倾向并不相同,因此与这种情况相对应,本文设置同一词语在不同个体中的情感值不同,将词语划到不同主题语境就是为了考虑这种差异性。为使个体中微博的情感倾向向标签数据情感倾向靠拢,即为了应用标签数据自动获得词语的情感倾向,本文设计遗传算法的目标函数实现词语情感值优化。利用式(5)计算主题j下第s条微博的情感值。

其中,wordt是微博djs中的词语,wjt(Chromx(wordt))表示词语wordt在个体Chromx中的情感值。当Senti(Zj,Tj,Chromx,djs)大于等于0 表示为正极(positive),反之则表示为负极(negative)。class(djs)表示微博djs的情感倾向,如式(6)所示。

本文设定Acc(Chromx,Tj)为:在主题j下,个体Chromx中微博的情感倾向与标签数据情感倾向的差异度,如式(7)所示,该值越小则个体Chromx中微博的情感倾向越靠近标签数据的情感倾向。

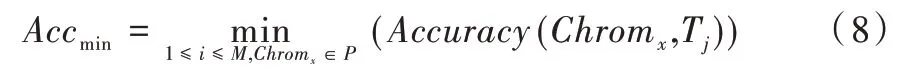
2.4.2 基于遗传算法的词语情感值计算
为使差异度越小的个体被保留的概率越大,本文设定适应度函数如式(9)所示。



Fig.4 Multi-point crossover图4 多点交叉

Fig.5 Gene mutation图5 基因变异
2.4.3 微博情感倾向计算
通过遗传算法得到最小差异度个体Chrommin,个体中染色体的编码对应主题词集词语的最优情感值。在最小差异度个体Chrommin中,先用式(5)将微博中所有词语的情感值相加,得到微博情感值,再用式(6)进行判断,若情感值大于等于0,表示该微博具有正极的情感倾向,反之表示具有负极的情感倾向。计算实例如图6 所示。
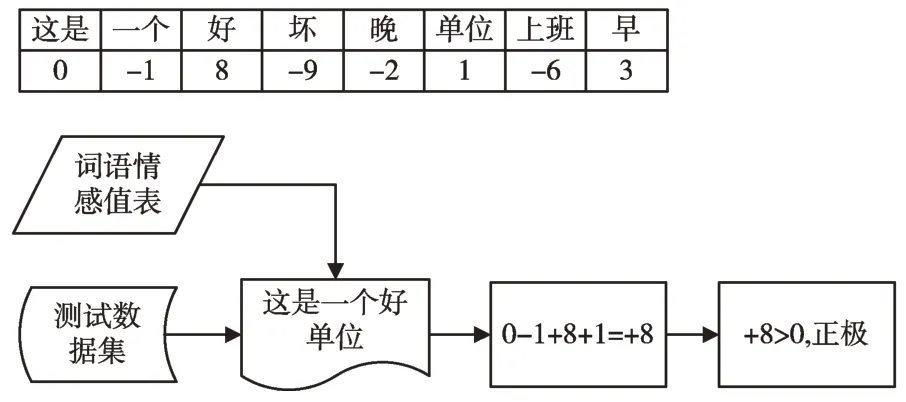
Fig.6 An example of sentiment compute图6 情感倾向计算实例
3 实验结果与分析
3.1 实验数据集
数据来源于2012-2014 年NLPCC 公开的数据集[22],共17 253 条微博。删除非观点句后有7 188 条微博,将该数据作为微博情感倾向计算的语料库,其中积极的有3 314 条,消极的有3 874 条,采用十折交叉验证对本文方法进行训练和测试。
NLPCC 数据集有none、happiness、like、sadness、disgust、anger、fear 和surprise 8 种标签。将8 种标签简化为正极和负极两种标签,如表1 所示。

Table 1 Label classification表1 标签分类
标签归类后,将微博内容按照统一格式存放,数据格式如表2 所示,微博的极性1 表示正极,-1 表示负极。

Table 2 Samples of Microblog表2 微博文本样例
3.2 实验过程与结果
在本文中,所有词语对微博情感极性的影响均参与计算,对微博进行分词后保留微博中的所有词语,PKU-SEG分词结果样例如表3 所示。

Table 3 Samples of PKU-SEG segmentation result on Microblog表3 微博PKU-SEG 分词结果样例
微博分词后,采用LDA 微博主题模型构建主题词集。LDA 微博主题模型中需要预先设置主题数目k值,选择适合的k值有利于主题分类。本文设置k值为5(收集的数据分为5 个主题),微博主题语境分类样例如表4 所示。

Table 4 Samples of Microblog topic context classification表4 微博主题语境分类样例
微博主题语境分类结果是:主题一与产品和产品评论相关;主题二与个人情绪表达相关;主题三是社会现状评论和事件描述;主题四是关于社会知名人士的微博动态评论;主题五是比较口语化的流行网络用语,分类结果与实际相符。完成微博主题语境分类后构建微博主题词集,如表5 所示。

Table 5 Part of the subject word sets表5 部分主题词集
得到主题词集后,利用基于遗传算法的微博情感倾向计算方法计算词语情感值。在算法中随机产生种群P,种群大小设定为1 000,对个体进行选择、交叉和变异操作。在本文中,将当前主题微博词语去重后的词语个数作为个体编码长度,染色体编码采用实数整数编码,编码范围在[-10,10]区间,初始词语情感值如表6 所示。用标签数据、目标函数和适应度函数对每个主题中的词集运行遗传算法,使情感值不断迭代优化,直到达到预定迭代次数后停止计算(本文设定迭代阈值为2 000),得到词语情感值优化结果如表7 所示。

Table 6 Word initial sentiment score表6 初始词语情感值
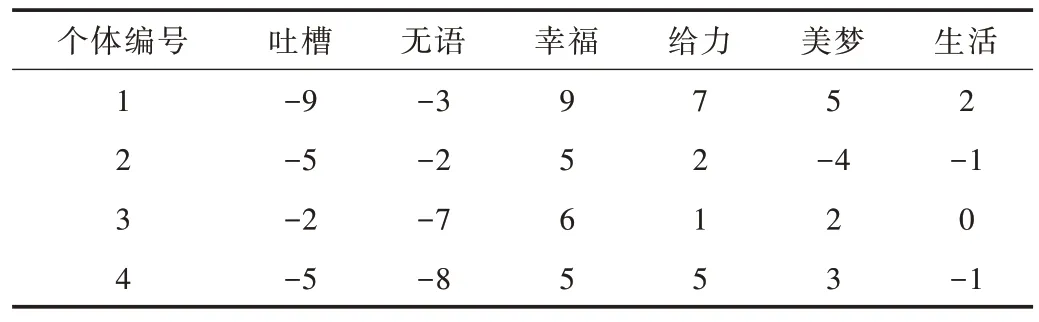
Table 7 Optimization results of words sentiment score表7 词语情感值优化结果
在基于遗传算法的微博情感倾向计算方法中,用目标函数在优化后的种群中选择差异度最小的个体作为当前主题词语情感值,如表8 所示。

Table 8 Examples of the optimal sentiment score of a word表8 最优词语情感值示例
微博主题语境分类后,不同的主题中可能有相同词语,这种分类方法与同一个词语在不同主题语境下情感倾向存在差异的实际相符,同一词语在不同主题下的情感值如表9 所示。
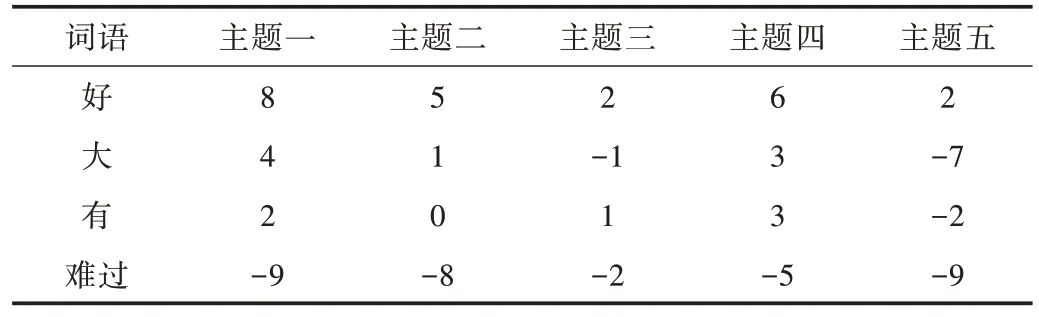
Table 9 Examples of the sentiment score of the same word in different topics表9 同一词语在不同主题的情感值示例
主题分类后,通过计算该主题下微博分词对应情感值之和判断微博情感倾向,当微博分词情感值之和大于等于0 时,微博的情感倾向为正极,小于0 时微博的情感倾向为负极。
3.3 方法对比
将本文方法(LDA-GA)与LDA、朴素贝叶斯分类(NB)、随机森林(RF)、决策树(DT)分别进行微博情感倾向计算对比。将精确度(P)、召回率(R)和F1 值作为评价指标,对比结果如表10 所示。
实验结果表明,LDA 方法的F1 值高于DT、NB 和RF 算法。原因在于,采用LDA 方法进行微博情感分析是基于语义的“文本—词语”主题分类进行情感计算,而DT、NB 和RF 算法将词语转换成词向量,未考虑词语的语义信息,从而导致微博情感倾向计算效果并不够理想。本文方法LDA-GA 的精确度、召回率和F1 值均高于LDA 方法。原因在于,LDA 方法仅利用特征情感词计算微博情感极性,而本文方法利用遗传算法计算所有词语情感值,将特征情感词和非特征情感词联合起来计算微博情感极性,并且根据不同主题语境计算词语情感值,对不同主题语境下同一词语的情感极性加以区分。
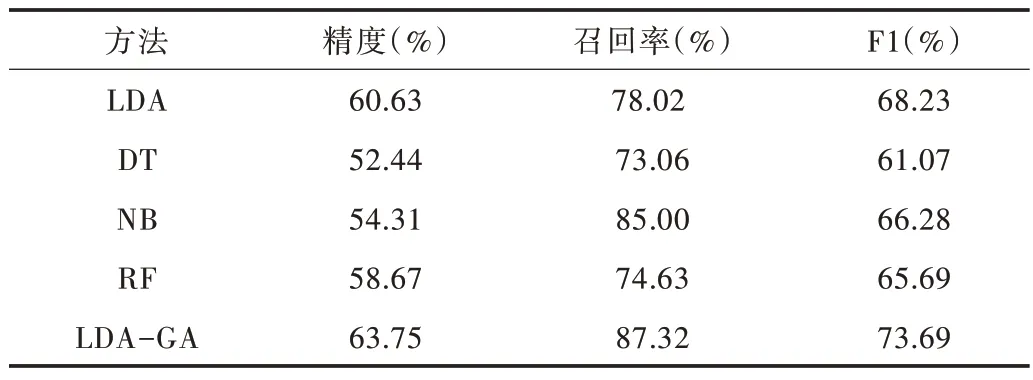
Table 10 The experimental results of emotional tendency comparation表10 情感倾向计算对比实验结果
4 结语
采用LDA 扩展模型是当前文本情感分析的重要方法之一,该方法存在两个问题未能解决:一是同一词语在不同语境下情感极性可能存在差异,二是没有考虑非情感特征词对句子或篇章情感倾向的影响。针对这两个问题,本文提出一种基于语境分类和遗传算法的微博情感分析方法。该方法首先利用LDA 模型构造微博主题集及微博主题词集,然后用微博标签数据逐一对各微博主题词集应用遗传算法自动迭代计算出词集中词语的情感值,最后通过主题词集词语的情感值计算微博文本情感极性。实验结果表明,与基于LDA、朴素贝叶斯分类、随机森林、决策树的微博情感分析方法对比,本文方法的精确度、召回率和F1 均得到提高。本文方法在遗传算法中需要反复进行迭代计算,耗时大,下一步研究工作是考虑遗传算法加速问题。
猜你喜欢
时代英语·高一(2019年5期)2019-09-03
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
电测与仪表(2016年11期)2016-04-11
智能系统学报(2015年4期)2015-12-27
电源技术(2015年5期)2015-08-22
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
沈阳医学院学报(2014年4期)2014-12-27
