
基于深度学习的行人检测技术研究
2021-02-04 06:53
软件导刊 2021年1期
(南京理工大学紫金学院计算机学院,江苏南京 210023)
0 引言
行人检测一直是视频分析领域的研究热点和难点。行人检测技术指计算机对于给定的视频和图像,判断其中是否有行人存在,同时标记出行人位置[1]。行人检测技术具有很强的应用价值,它可以与行人跟踪、行人重识别等技术相结合,广泛应用于自动驾驶、道路监控、智慧城市等领域。传统的行人检测方法依靠人体自身的外观属性进行特征提取和分类。例如,通过颜色、边缘、纹理、运动等属性描述行人态势,并使用支持向量机(Support Vector Ma⁃chines,SVM)[2]、自适应提升(Adaptive Boosting,Ada⁃Boost)[3]等分类器判断特定区域是否存在行人目标。该类方法往往受限于特定环境条件,导致特征表达能力不足,无法满足实际场景应用要求。
长期以来,基于外观属性进行特征提取一直制约着行人检测发展,直到2012 年,Krizhevsky 等[4]应用深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)取得了ILSVRC 比赛冠军,从此开启了基于深度学习的行人检测新篇章;黄同愿等[5]对基于深度学习的行人检测技术研究进展进行了综述。研究人员发现基于深度学习学到的特征具有很强的层次表达能力和很好的鲁棒性,可以更好地解决这类视觉问题。随着深度学习的不断发展,Faster-RCNN(Faster Region-based Convolutional Neural Net⁃works)[6]、FPN(Feature pyramid networks)[7]、SSD(Single Shot Detection)[8]、YOLO(You Only Look Once)[9]等优秀 的目标检测算法相继被提出,使行人检测技术得到了空前发展[10]。本文首先基于深度学习相关技术,分析经典的目标检测网络;然后,从视频分析角度,给出行人检测处理流程,并基于YOLO v3 进行了系统实现与验证;最后,结合实验结果,探讨了行人检测技术未来发展和进一步研究方向。
1 深度学习
深度学习是通过构建一个多层神经网络模型,以原始数据作为输入,由算法在该网络模型上自动学习原始数据隐含在内部的关系,提取出更高维、更抽象的数据特征表示,最后以特征到任务目标的映射作为结束[11]。深度学习已经被广泛应用于语音识别、自然语言处理、图像分类等领域,并取得了巨大成功。例如,谷歌旗下的DeepMind 公司基于深度学习技术开发的人工智能围棋软件—Alpha⁃Go,先后击败李世石、柯洁等世界围棋名将[12];百度研发的无人驾驶汽车,把以深度学习为基础的计算机视觉、听觉等识别技术应用到“百度汽车大脑”系统中,能在厘米级精度上实现车辆定位[13]。
深度学习的核心是深度神经网络(Deep Neural Net⁃work,DNN)。深度神经网络是一种模仿神经网络进行信息分布式并行处理的数学模型。根据网络结构的不同,深度神经网络主要分为以下几种类型:
(1)卷积神经网络(Convolution Neural Network,CNN)。CNN 网络建立在多层感知机(Multi-layer Perceptions,MLP)的基础上,将卷积运算和采样操作引入人工神经网络,使提取出的特征具备一定的空间不变性。卷积神经网络是一种具备高效识别能力的前馈神经网络,一般由多个卷积层、池化层和全连接层组成。卷积操作、稀疏连接、权值共享是卷积神经网络的三大显著特点。对于卷积神经网络而言,不同深度对应着不同层次的语义特征:浅层网络分辨率高,学到的更多是细节特征;深层网络分辨率低,学到的更多是语义特征。CNN 网络主要应用于视频分析、图像处理等领域。
(2)循环神经网络(Recurrent Neural Network,RNN)。RNN 网络是一类以序列数据作为输入的神经网络,其在序列的演进方向上进行递归且所有节点(循环单元)按照链式连接。循环神经网络具有固定的权值和内部状态,通常用来描述动态时间行为序列,是一种能够处理任意长度序列信息的神经网络。RNN 网络主要应用于文本分析、自然语言处理等领域。
(3)生成式对抗网络(Generative Adversarial Network,GAN)。GAN 网络由一个生成器(Generator)和一个判别器(Discriminator)组成[14]。生成器输入一个潜在编码,其输出的生成样本无限逼近真实样本;判别器的输入为真实样本和生成样本,并能够识别出真实样本和生成样本。两个网络以零和博弈的方式交替训练,训练生成器时最大化判别误差,训练判别器时最小化判别误差,最终目的是使判别器无法判别出生成样本和真实样本,使生成器的输出与真实样本分布一致。GAN 网络在图像生成、图像超分辨率、三维建模、图像风格迁移和视频预测等领域得到了广泛应用。
行人检测属于深度学习的典型应用,主要采用卷积神经网络进行。
2 基于深度神经网络的检测技术
2.1 目标检测及其发展历程
目标检测是指给定一张图像,确定其中是否存在多个预定义的类别,如果存在,就返回每个实例的空间位置和覆盖范围(比如返回一个边界框)。行人检测是特定实例的目标检测,其检测的类别是行人,而非其它类别的物体,如车辆、建筑物等。
2014 年,Girshick 等[15]提出了区域卷积神经网络(Re⁃gionswith CNN Features,R-CNN)模型,拉开了深度学习做目标检测的序幕。在R-CNN 的基础上,Girshick 等[16]又提出了进阶版的Fast R-CNN,实现了端到端的检测和卷积操作。Ren 等[17]提出了Faster R-CNN 模型,其最大创新在于设计了区域候选网络(RegionProposalNetwork,RPN),使用锚框(Aanchor)的思想将提取目标候选框的步骤整合到深度神经网络中。2015 年,研究者[18]提出了仅通过一次传导的目标检测模型,称为YOLO(YouOnlyLookOnce),通过无锚框(Anchor-Free)检测,第一次实现了实时的物体检测任务;Liu 等[19]提出的SSD(SingleShotMultiboxDetector)模型吸收了YOLO 快速检测的思想,改善了多尺寸目标的处理方式,提升了小目标检测能力;Lin 等[20]提出的FPN(Fea⁃turePyramidNetworks)模型,使用特征金字塔实现了更为优秀的特征提取网络。
YOLO 模型经过多个版本的发展,当前已经演进到YOLO v5[21-24]。YOLO 模型在原有架构的基础上,采用CNN 研究最新成果,对数据处理、骨干网络、模型训练、激活函数、损失函数等各方面都有着不同程度的优化,大幅提升了目标检测效率。
2.2 检测模型分类
在目标检测模型中,基于是否将目标定位和分类作分离处理,可分为两种类型:两阶段目标检测模型和单阶段目标检测模型。
(1)两阶段目标检测模型(Two-StageObjectDetection)。两阶段检测模型通常在第一阶段专注于找出目标出现的位置,得到建议框(ProposalRegion);然后在第二阶段专注于对建议框进行进行分类和边界框回归,寻找目标的精确位置。两阶段的典型检测模型如R-CNN、Faster R-CNN等。
(2)单阶段目标检测模型(One-StageObjectDetection)。单阶段检测模型将目标定位和分类这两个过程融合在一起,采用“锚点+分类精修”框架,在一个阶段完成寻找目标出现位置和类别预测。单阶段典型检测模型有SSD、YOLO系列等。
两阶段检测模型一般精度更高,但速度较慢;单阶段检测模型一般比两阶段检测模型更快,但精度会有所损失。
2.3 YOLO 检测模型
YOLO 模型由于具有更快的检测速度,在工业界的应用最为广泛。本文使用相对稳定的版本YOLO v3[22]进行行人检测系统实现与评估。相比以往版本,YOLO v3 在整体结构上有较大改动,吸收了当前优秀的检测框架思想,在保持速度优势的情况下,进一步提升了检测精度,尤其是对多尺度目标的检测能力。YOLO v3 网络结构如图1所示。

Fig.1 Detection framework of YOLO v3图1 YOLO v3 网络结构
YOLO v3 在YOLO v2 提出的Darknet-19 基础上引入残差模块,进一步加深网络层次,改进后的网络有53 个卷积层,命名为Darknet-53[5]。网络层次的加深使一些当前先进的模型中比较重要和流行的结构能出现在YOLO v3上,包括残差模块、多尺度检测以及上采样与特征融合过程等。图1 中各模块说明如下:
(1)Input 模块。输入模块默认采用416×416×3 的输入。
(2)Conv2D 模块。代表卷积层、批量归一化层(Batch⁃Normalization,BN)、LeakyReLu 激活层等三层的结合,构成了DarkNet 的基础处理单元。
(3)ResBlock 模块。即残差模块,通过引入一个深度残差框架解决梯度消失问题,使得模型更容易收敛。Res后面的数字表示串联的残差模块数目。
(4)UpSampling2D 模块。即上采样模块,上采样使用的方式为向上池化操作,通过元素复制方式扩展特征尺寸,没有学习参数。
(5)Concat 模块。即拼接模块,上采样后将深层与浅层的特征图进行通道的拼接操作,实现特征融合。
(6)Output 模块。输出模块在图1 中以灰色方框表示。通过上采样与Concat 操作,融合了不同层的特征,最终输出3 种尺寸的特征图,分别对应深层、中层和浅层特征,用于后续目标预测。多层特征图对于多尺度目标则非常有利,深层特征图尺寸小、感受野大,有利于检测大尺度物体;浅层特征图则与之相反,感受野小,有利于检测小尺度物体。
3 行人检测系统实现
3.1 检测流程
行人检测需要将图像中的背景和前景分离,进而实现行人的定位和追踪。行人检测的基本处理流程如图2 所示。
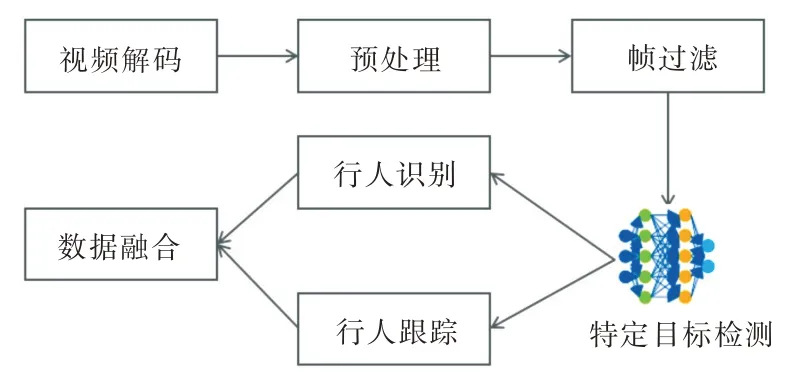
Fig.2 Basic process of pedestrian detection图2 行人检测基本处理流程
(1)视频解码。监控摄像头一般采用RTSP(Real-time Streaming Protocol)或RTMP(Real-time Messaging Protocol)协议传输视频。在边缘设备收到视频流后,需要解码成一系列的视频帧,然后采用H.264/H.265 等重新编码,并传输到视频分析设备。
(2)预处理。预处理阶段是指各种视频的前期操作,如图像增强、降噪、校准等。例如,一台倾斜的摄像头在黑夜拍摄到的视频,需要预先进行光线增强和校正等。
(3)帧过滤。对于每一个视频帧,识别是否存在运动目标。如果是背景帧或者前后无变化的视频帧,则可进行过滤处理,减轻后续视频分析负担。
(4)特定目标检测。借助神经网络模型识别感兴趣区域,例如行人、车辆、火焰、烟雾(smoke)等区域。本系统用于行人检测,主要从视频流中检测行人目标。
(5)行人识别。在特定目标检测基础上,对行人目标进行精确识别。例如,基于面部特征识别行人身份、基于表情特征识别行人心理活动等。
(6)行人跟踪。具有基于区域的跟踪、基于特征的跟踪、多目标跟踪等算法[25]。目前,针对卷积神经网络在目标跟踪中的应用,主要研究方向有两种:一种是先进行离线训练,再进行在线微调;另一种则是构建简化版的卷积神经网络,力求摆脱离线训练,达到完全在线运行要求。
(7)数据融合。基于多个视频源获取特定目标的信息。例如,行人再识别源于多摄像头跟踪,用于判断非重叠视域中拍摄到的不同图像中的行人是否为同一个人。
3.2 软件实现
行人检测系统基于C/S(Client/Server)架构设计,客户端负责视频数据采集,然后上传到服务器端进行视频分析,YOLO v3 模型部署在服务器端。
编程语言采用Python。Python 是一种面向对象的脚本语言,相比其他C++、Java 语言,其在深度学习领域应用最为广泛。
深度学习框架采用PyTorch。PyTorch 是一个动态图框架,拥有自动求导机制,对神经网络有着尽量少的概念抽象。PyTorch 风格与Python 程序类似,这使得使用者很容易理解代码的框架和逻辑。
4 系统验证
本系统实验环境配置如下:
(1)服务器端操作系统为Ubuntu18.04,处理器为英特尔酷睿i9 9900K(8 核16 线程),内存为DDR4 32G 3 000高频闪存。服务器搭载两块英伟达GPU 芯片GeForce RTX 2 080Ti[26],该芯片显存容量为11GB,CUDA 核心数为4 352,加速频率为1 635MHz,具备强大的深度学习处理能力。
(2)客户端采用惠普笔记本HP Elite 848 G4[27],处理器为Inteli7-7500U,内存为8GB。客户端操作系统为Win⁃dows 10。
本文使用F1 分数(F1 Score)作为行人检测评价指标。F1 Score 就是模型的准确率和召回率的调和平均数。准确率指正确的预测框和所有检测出的预测框的比值,是评价准的指标;召回率指正确的预测框与所有标签框的比值,是评价全的指标。
针对YOLO v3 模型,在上述实验环境下对视频图像进行行人检测,可达到37 FPS 的处理速率。基于YOLO v3的行人检测效果如图3 所示。
图3 上边为原始视频帧,下边为检测后的视频帧。可以看出,在视频帧的行人都被完整地检测了出来。

Fig.3 Pedestrian detection effect based on YOLO v3图3 基于YOLO v3 的行人检测效果
5 结语
行人检测在计算机应用领域有着非常广泛的应用,近年来受到学术界和产业界的广泛关注。本文阐述了基于深度学习的行人检测技术,并选取广泛使用的YOLO v3 模型对行人检测系统进行了实现。实验结果表明,卷积神经网络可以描述待检测目标的复杂特征,能够在准确度和实时性等方面满足行人检测要求。
深度学习虽然为行人检测带来了新的契机,但也面临新的问题。首先,行人兼具刚性和柔性物体的特性,外观易受穿着、尺度、遮挡、姿态和视角等影响,由此导致针对复杂场景和特殊环境的行人检测仍有待提高;其次,深度学习训练需要大量数据集,目前标准的大型数据集都基于国外环境和场景,这在一定程度上影响了相关研究进展,国内数据库在大型行人目标检测数据集构建上还有很多发展空间;再者,行人检测当前采用的是通用目标检测模型,在模型训练和推理阶段需要耗费大量时间,如何建立针对行人的特定检测模型也是后续一个重要研究方向。总之,行人检测在很长时间内都将是计算机视觉领域中一个既具有研究价值同时又极具挑战性的热门课题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
电视技术(2014年19期)2014-03-11
