
基于Bagging 异质集成学习的窃电检测
2021-02-03 07:41:00游文霞李清清吴永华李文武
电力系统自动化 2021年2期
游文霞,申 坤,杨 楠,李清清,吴永华,李文武
(1. 三峡大学电气与新能源学院,湖北省宜昌市443002;2. 国网湖北省电力有限公司孝感供电公司,湖北省孝感市432000)
0 引言
电力系统在电能传输中存在能量损失,电力用户的窃电等欺骗性用电行为是原因之一[1]。窃电会造成大量经济损失,因此一直受到供电企业和研究者的关注。随着智能电表的不断普及,过去依靠破坏传统电表等窃电手段已转变为通过信息技术攻击智能电表,通过数据篡改等手段实现窃电[2]。传统人工筛查进行窃电检测效率低下,已无法满足窃电检测需求。充分利用海量数据对窃电用户进行筛查并开展窃电检测成为国内外研究的热点。
窃电检测主要有3 类方法:基于系统状态、基于博弈论和基于数据挖掘技术[3]。基于系统状态的方法通过比较智能电表数据与其他仪器测量数据是否一致[4-5],从而识别是否发生窃电,但需要额外投资。基于博弈论的方法将窃电检测问题描述为窃电者与电力公司之间的博弈[6-7],但参与者的效用函数以及策略不易确定。基于数据挖掘技术的方法则只需要通过挖掘数据中潜在的规律识别窃电[8-17],目前已开展了广泛研究。
文献[10]提出基于误差反向传播(back propagation,BP)神经网络的反窃电方法,通过历史数据和当前数据构建评价模型,采用遗传算法加快收敛速度,并在国网某省公司提供的数据集上得到了验证。文献[11]结合决策树(decision tree,DT)与支持向量机(support vector machine,SVM),将DT 的计算结果输入到SVM 中,从而判断用户属于窃电用户还是正常用户;该算法在爱尔兰智能电表数据集上进行测试,准确率达到了92.5%。此外,以树集成为代表的集成学习(ensemble learning)算法在窃电检测中也取得了良好的应用效果。文献[16]对比极限梯度提升树(eXtreme gradient boosting,XGBoost)和 类 别 提 升 树(categorical boosting,CatBoost)、轻量梯度提升机(light gradient boosting machine,LightGBM),利用梯度提升窃电检测器(gradient boosting theft detector,GBTD)判断是否发生窃电。文献[17]在随机权网络的基础上构建随机森林(random forest,RF)模型来进行窃电检测。
但是上述研究只是采用单一学习器或单一学习器的集合(即同质集成学习)来进行电力用户行为模式辨识,由于不同学习器的预测结果可能存在差异,因此单一学习器可能无法通过取长补短的方式训练出更优异的模型。文献[18]利用多模型融合Stacking 集成学习的方法对瑞士部分用电负荷情况进行预测,其结果表明,基于多学习器融合方法的预测效果与各个体学习器的学习能力以及各学习器间的关联程度有关,且基于多学习器融合的方法相较于传统单学习器有着更高的预测精度。基于此,本文提出基于Bagging 异质集成学习方式对窃电行为进行检测。其中,学习器的选择和各学习器间的集成策略是异质集成的2 个重要研究点。首先,说明Bagging 集成学习方式的训练机理,以及多种学习器结合的多样性度量;然后,在Bagging 集成框架下考虑多种学习器的性能指标以及各学习器之间的多样性,建立基于Bagging 异质集成学习方式的窃电检测模型;最后,在爱尔兰智能电表数据集的居民用电数据上验证算法的有效性。
1 基于Bagging 的集成学习方式
1.1 集成学习
集成学习通过结合多个学习器完成学习任务。集成学习的总体结构为:先通过训练确定多个个体学习器,再用某种策略将这些个体学习器结合。集成学习通过集成多个学习器,常可获得比单一学习器更优越的性能[19]。
根据个体学习器的生成方式,集成学习方法大致分为2 类:一是以Boosting 为代表的、各个体学习器间存在强依赖关系,且必须串行生成的集成学习算法;二是以Bagging 为代表的、各个体学习器间不存在强依赖关系,可以并行生成的集成学习算法。
1.2 Bagging 集成学习方式
Bagging 算法是并行集成学习方法最著名的代表。为了使集成的个体学习器尽可能独立,传统的Bagging 算法通过自助采样法(bootstrap sampling)随机产生多个训练子集,然后基于每个训练子集训练出多个个体学习器,最后将这些个体学习器进行结合,集成为整体。
自助采样法在数据集较小时,通过重采样可以有效划分出训练集和测试集。而窃电检测需要对大量用电客户的长期用电记录进行识别,所用样本集较大。使用自助采样法不仅会使训练集的数据分布和原始数据集不同,还会大大降低计算效率。故与传统Bagging 不同,本文采用相同的训练集分别训练出多个个体学习器,再将其输出进行结合。对于窃电检测这种分类任务,Bagging 在对预测输出进行结合时,通常采用投票法。集成分类器构建完毕后,用测试集中的样本对其性能进行测试。将用电客户的日常用电记录输入到集成分类器中,通过比较预测与实际窃电情况是否一致,对集成分类器进行评价。本文所用Bagging 异质集成学习的结构如图1所示。
2 窃电检测
2.1 窃电检测业务分析
用户窃电的目的是通过减少支付电费从而获得非法收益[2]。窃电用户可通过修改用电数据,根据电量和电价的差异来实现少交电费的目的,即达到式(1)的效果。
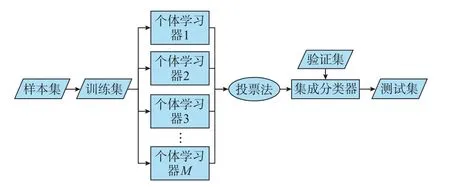
图1 Bagging 异质集成学习结构Fig.1 Structure of Bagging heterogeneous ensemble learning

对于日用电数据而言,可通过削减、置零和移峰这3 类方式篡改数据达到窃电的目的。具体方式如下[3,8,16]。
1)将智能电表的用电数据按一定比例削减,可有以下2 种方法:
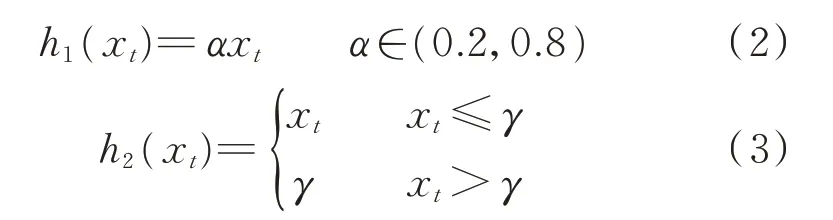
式中:h1(⋅)表示将t时段的用电记录乘以0.2~0.8 之间相同的随机数,可以模拟按相同比例削减用电量的 情 况;h2(⋅) 表 示 随 机 选 择 阈 值γ(0 <γ<max(xt)),如果实际用电量大于γ,则将用电量替换为γ,否则保持不变,可以模拟按不同比例削减用电量的情况。
2)将某些时段的用电数据直接篡改为零,可有以下2 种方法:

式中:h3(⋅)定义当用电记录位于时间段(t1,t2)内,其值记为0,且t2≥t1+4,可以模拟将连续用电量置零的情况;h4(⋅)表示将用电记录减去阈值γ,并取其差值与0 之间的最大值,可以模拟将不连续用电量置零的情况。
3)在不改变用电量的同时将用电曲线移峰,可有以下2 种方法:
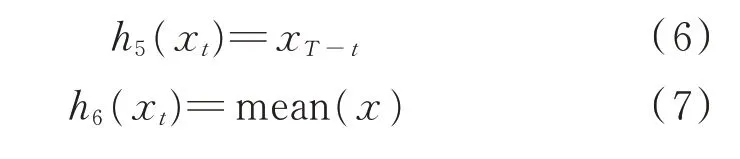
式中:h5(⋅)表示将用电记录倒序排列,可以模拟将用电曲线移峰;h6(⋅)表示取一天用电记录的平均值,可以模拟与用电曲线移峰类似的情况,通过电价差别实现窃电;mean(⋅) 为求平均值函数;x={x1,x2,…,xT}。
供电公司搜集的用电数据,由于包含了为实现窃电而篡改的数据,使得供电公司的电费收益和应得收益不一致,因此需要分析海量用电数据,开展窃电检测,找出窃电用户。从理论上而言,窃电检测是机器学习中的一个分类问题,判别用户是正常用电还是窃电。
2.2 用户用电行为及特征指标
用户的用电行为可能受季节、家庭电器、人口变化以及节假日等因素的影响,使得用户用电曲线有不同的分布,呈现出不同用电行为。窃电检测的目标即根据用户用电行为数据,找出与正常用电行为不符的模式。开展窃电检测,首先需要确定判别用户行为异常的特征指标项。
用户一天的用电记录(x1,x2,…,xT)(T一般为24 的倍数)直接反映用户用电行为,是用户用电的一般特征。但仅仅根据用电记录的一般特征指标项,在进行窃电检测时容易导致较高的误检率和较低的命中率。因此,还需考虑其他特征指标,以提高检测性能[20]。窃电检测常用的爱尔兰智能电表数据集上的试验表明,通过增加最大值、最小值、平均值和标准差几个特征,可改善其所提算法的性能[14]。因此,本文窃电检测的特征指标包括用电记录的一般特征指标项,以及最大值、最小值、平均值和标准差的综合特征指标项。
2.3 检测流程
基于Bagging 异质集成学习的窃电检测流程具体步骤如下。
步骤1:用生成的训练集对常用的窃电检测学习器进行训练对比。单一学习器包括DT,BP,SVM 和k 最近邻(k-nearest neighbor,KNN),其中DT,BP 和SVM 分别为机器学习中符号主义学习、连接主义学习和统计学习的代表。而同质集成学习器包括以树集成为代表的梯度提升决策树(gradient boosting decision tree,GBDT)、RF 和自适应提升器(adaptive boosting,AdaBoost)。综合各个体学习器在训练集上的表现与各个体学习器间的多样性,确定使模型获得最佳预测效果的学习器组合。
步骤2:对比步骤1 得到的最佳学习器组合在不同结合策略下的表现,确定模型中各个体学习间的结合策略。
步骤3:根据步骤1 和2 确定的基于Bagging 异质集成学习的结合策略及个体学习器类型,对模型进行训练。
步骤4:将测试集输入到步骤3 训练好的Bagging 分类模型中,验证基于Bagging 异质集成学习分类器并对分类器进行评估。
2.4 多样性度量
多样性度量(diversity measure)用于量度集成学习中个体学习器的多样化程度。在选择多样性度量方法时,需要根据具体问题的侧重、每种度量方法实现的难易程度进行选择[21]。针对本文的选择性集成,需要计算每对分类器间的多样性,采用双次失败(double failure,DF)度量和Q 统计指标进行多样性度量[22]。其中DF 值和Q 统计量的取值分别为[0,1]和[-1,1]。二者值越小,代表每对分类器之间的多样性程度越大。系统整体的DF 值和Q 统计值可以通过计算每对分类器之间DF 值和Q 统计值的平均值得到。
2.5 评价指标
为了衡量学习器的好坏,在分类问题中常用表1 所示的混淆矩阵。

表1 混淆矩阵Table 1 Confusion matrix
混淆矩阵将所有用户按照真实类别与学习器预测类别的组合划分为TP,FP,TN,FN 这4 类,相应的数量分别为MTP,MFP,MTN,MFP。本文采用准确率(accuracy,ACC)iC、命 中 率(true positive rate,TPR)iT、误检率(false positive rate,FPR)iF、受试者工作特征曲线下面积(area under receiver operating characteristic curve,AUC)iU这4 个分类检测评价指标,定义分别如下:
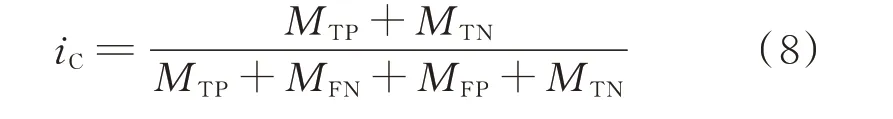
式中:iC表示总样本中有多少被正确预测。但在正、负样本数量严重失衡的情况下,仅使用准确率对模型进行评价缺乏可信度[23]。因此,还需综合其他指标来评价。
iT和iF的值表示为:
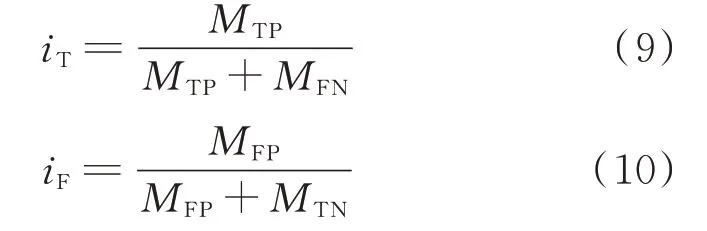
式中:iT和iF的取值范围均为[0,1],iT越高,iF越低,则检测效果越好。
采用受试者工作特征(receiver operating characteristic,ROC)曲线描述iT和iF这2 个指标变化的相对关系[19]。进行学习器比较时,较为合理的是比较iU。iU为1 对应理想分类器。
3 算例分析
本章进行算例对比分析。试验使用Core-TM i5-3470@3.20 GHz 处 理 器 在 Anaconda( 基 于Python 3.6)环境下进行。
3.1 数据集
本试验选用爱尔兰智能电表数据集,该数据集含有爱尔兰6 000 多户家庭和商业用户连续535 天的用电记录(每30 min 采集一次数据)[24]。选用其中1 000 户居民用户进行实验。由于数据集中用户均同意将其用电记录用于研究目的,因此假设所有用户均属于正常用电用户。随机选择10%的用电记录修改后作为窃电样本,窃电样本生成方法按照2.1 节所述式(2)—式(7)进行。

3.2 选择性集成与集成策略
3.2.1 选择性集成
试验研究表明,在已构建的个体学习器中,只挑选一些性能较好的学习器,会得到更好的预测效果[25]。在构建集成学习器时,有效地产生预测能力强、差异大的学习器是关键,即要获得良好的集成,个体学习器应“好而不同”,即个体学习器既要有一定的准确性,各学习器间又要具有一定的差异。以表2 所示3 个个体学习器集成为例,其中“√”表示分类正确,“×”表示分类错误,表中的每个基学习器都只有66.7%的精度,但集成起来却达到了100%。
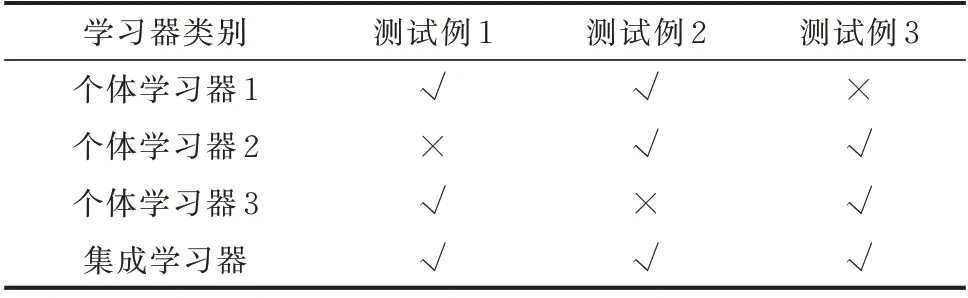
表2 “好而不同”的学习器Table 2 Good and different learners
为了优化异质集成学习模型的性能,有必要分析每个个体学习器的单独预测能力,并全面比较各个体学习器的组合效果。选择性集成的目的是在减少集成系统中分类器数量的同时保持甚至提高系统的预测性能,从而减小存储和计算开销,提高预测速度和精度。
立足于个体学习器的预测能力,设计试验将各个体学习器在6 个只含单一窃电样本数据集上的预测结果进行比较分析,并依据经验选取部分模型参数。得到各个体学习器iC和iU的平均值,如表3所示。
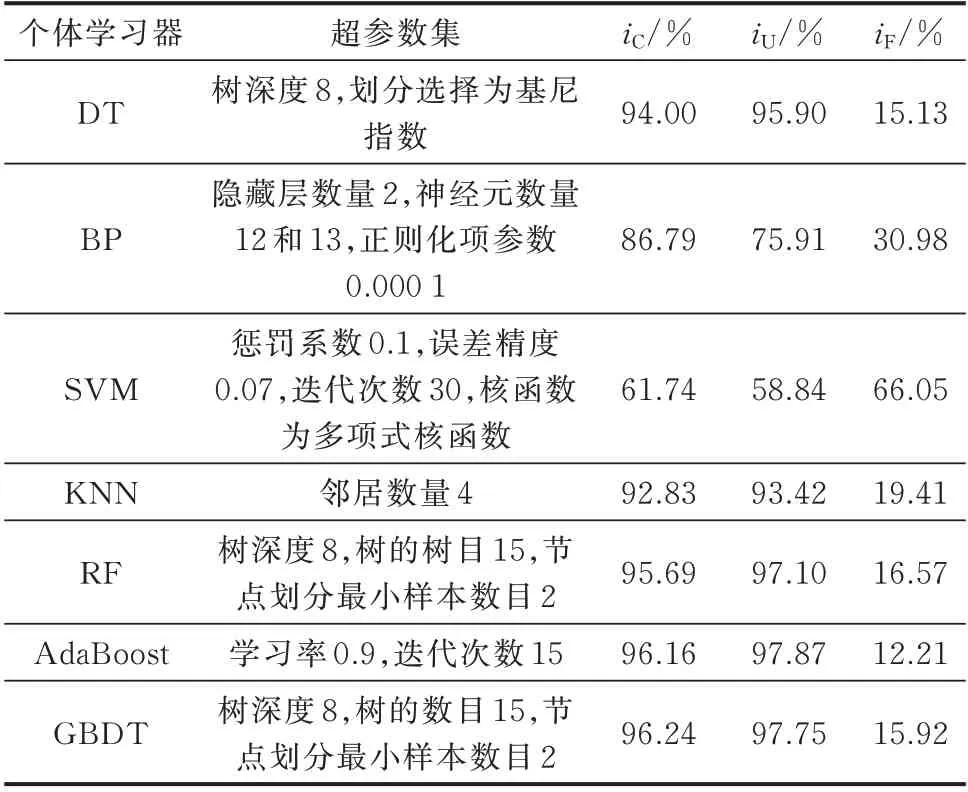
表3 各个体学习器的超参数以及在6 个只含单一窃电样本数据集上的表现Table 3 Hyper-parameters and performance of individual learners on six data sets containing single electricity theft sample
由表4 可知,7 种学习器的iC和iU值皆超过了50%,符合“好而不同”中“好”学习器的特性。但SVM 的iF值达到了66.05%,即有超过65%的概率将窃电检测为正常用电,从而造成大量经济损失。因此,本文Bagging 集成模型中个体学习器的选择初步排除SVM。
另一方面,为了获得最佳预测效果,还需要选择差异度较大的个体学习器。因为不同的学习器是从不同的数据空间角度观测数据。因此,选择差异度较大的算法能够最大程度体现不同算法的优势。表4 和表5 是除SVM 外6 种算法在6 个只含单一窃电样本数据集上的DF 值和Q 统计值。如果选用所有个体学习器作为模型的基学习器,此时系统整体的DF 值和Q 统计值分别为0.047 和0.844。
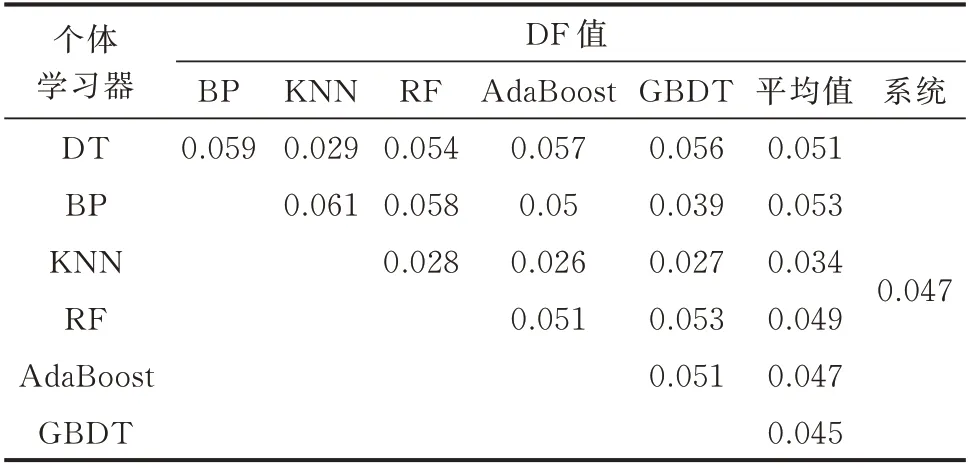
表4 各个体学习器在6 个只含单一窃电样本数据集上的DF 值Table 4 DF values of individual learners on six data sets containing single electricity theft sample
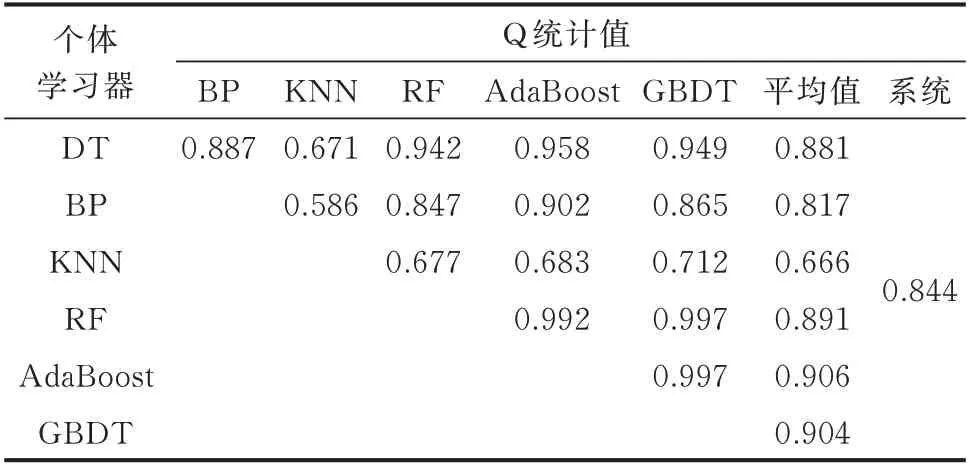
表5 各个体学习器在6 个只含单一窃电样本数据集上的Q 统计值Table 5 Q statistical values of individual learners on six data sets containing single electricity theft sample
由表4 和表5 可知,在各单一学习器中,DT 与其他个体学习器相比,其平均DF 值和Q 统计值均为最高,即多样性最低,且在检测能力上,以DT 为基学习器的RF,GBDT 和AdaBoost 等同质集成学习器都远高于DT。同时,BP 和KNN 的训练机理差距较大,其DF 值和Q 统计值也相对较低。故单一学习器中选择BP 和KNN 作为Bagging 异质集成中的个体学习器。在同质集成学习器中,RF,AdaBoost,GBDT 的DF 值和Q 统计值都较高,这是因为该3 类算法都属于树的集成算法,其数据观测方式存在较强相似性。其中RF 在学习方式上和AdaBoost 和GBDT 又稍有不同,这是因为RF 采用Bagging 方式,为并行集成,而AdaBoost 和GBDT采用Boosting 方式,为串行集成。AdaBoost 和GBDT 在检测能力相当的同时,GBDT 的DF 值和Q 统计值更低,故同质集成学习器中选择RF 和GBDT 作为Bagging 异质集成中的个体学习器。模型最终的个体学习器包括BP,KNN,RF 和GBDT。此时模型中各个体学习器以及系统整体的DF 值和Q 统计值如表6 所示。由表6 可知,此时系统的DF值和Q 统计值分别为0.044 和0.78,较之前均出现了一定程度下降,即系统的多样性较之前增加。

表6 模型中各个体学习器以及系统整体的DF 值 和Q 统 计 值Table 6 DF and Q statistical values of individual learners and system in the model
基于Bagging 异质集成学习的窃电检测在对各个体学习器进行选择性集成前后的性能如图2 所示,此时个体学习器的结合策略为默认的多数投票法。

图2 选择集成前后模型的性能Fig.2 Performance of the model before and after selective ensemble
由图2 可知,在选择性集成后,除iF指标明显降低外,其他指标略有提高。因此,需要对个体学习器的结合策略进一步改进。
3.2.2 集成策略
Bagging 算法在对各个体学习器的输出进行结合时,通常使用投票法。在投票法的选择上,应用最广泛的是多数投票法(majority voting)和加权投票法(weighted voting)。但是多数投票法无法有效使用不同分类器提供的互补信息[26]。因此,加权投票法被广泛应用。文献[27]利用相对准确度作为权重对各分类器进行集成:
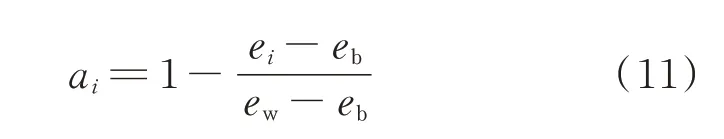
式中:ai为第i个个体学习器的相对准确度;ew和eb分别为所有个体学习器中的最大和最小错误率(错误率=1-准确率);ei为第i个个体学习器的错误率。
则每个分类器所占比重wi为:
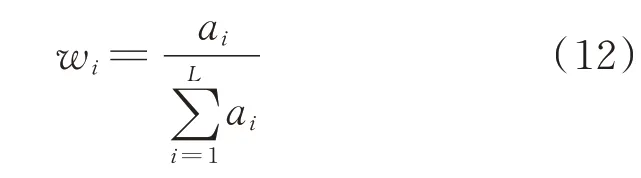
式中:L为个体学习器总数。
但权重可来源于除准确度外的其他角度,故有效性不强。因此,在文献[27]基础上,本文使用准确度和AUC 值的综合作为权重对分类器进行集成:
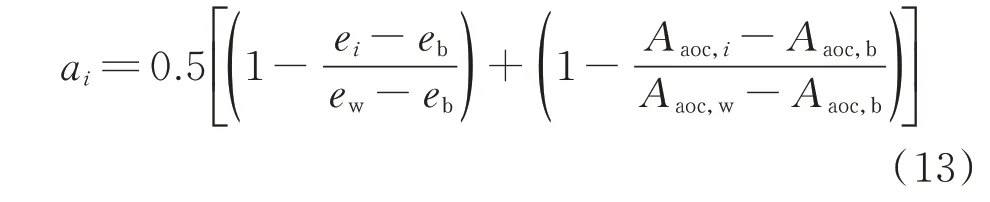
式中:Aaoc,i表示第i个个体学习器的ROC 曲线未覆盖的面积(Aaoc,i=1-iU);Aaoc,w和Aaoc,b分别为所有个体学习器中ROC 曲线未覆盖面积的最大值和最小值。
分别将本文所用投票策略和文献[27]以准确度为基准的加权投票法以及传统的多数投票法命名为Vote 和Vote1,Vote2。为了确定哪种投票策略表现最好,设计试验将3 种投票策略在7 个数据集上的预测结果进行比较分析,结果如图3 所示,各指标值均为在7 个数据集上取得的平均值。
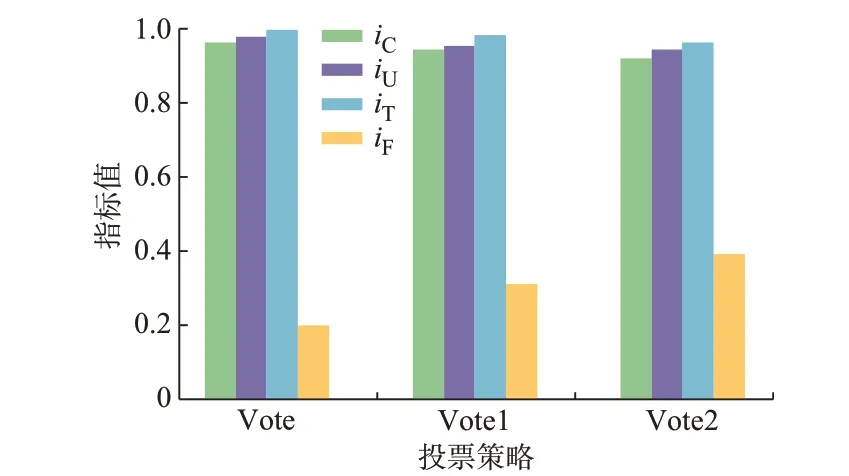
图3 3 种投票策略在7 个数据集上的表现Fig.3 Performance of three voting strategies on seven data sets
由图3 可知,本文所用投票策略的4 个指标均优于另外2 种投票策略。
3.3 与其他算法的对比分析
对比本文所提模型和上文提到的BP[10],DT[11],SVM[11],KNN[12],GBDT[16],RF[17]和AdaBoost 这7 种算法的测试结果,其中BP,DT,SVM 和KNN 属 于 单 一 学 习 器,RF,GBDT 和AdaBoost 属于单一学习器的集成。
3.3.1 与单一学习器的对比分析
将本文所提模型与上述BP,DT,SVM 和KNN这4 种单一算法在7 个数据集的测试集上的结果进行对比,结果如表7 所示。为方便表示,将本文的Bagging 异质集成学习用其结合策略“Vote”代替。
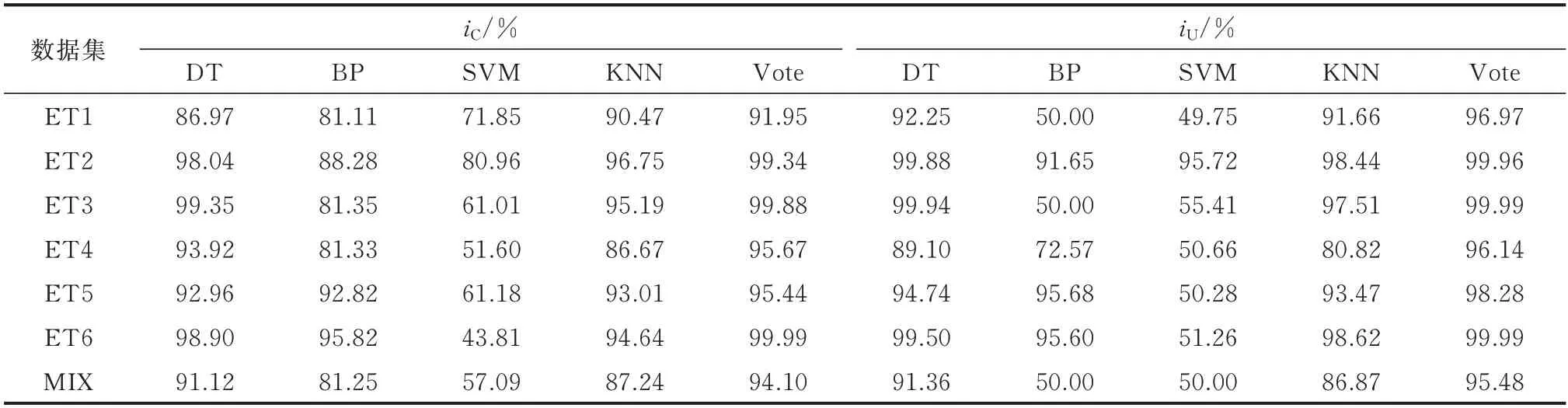
表7 本文所提模型与各单一学习器的对比Table 7 Comparison of the proposed model and single learners
由于部分样本之间不存在显著相关特性,因而SVM 的分类正确率对于不同数据集波动较大,且其iC和iU值均明显低于其他对比算法。此外,虽然BP在每个数据集上的准确率都超过了0.8,但其AUC值波动较大。除SVM 和BP 外,其他算法在7 个数据集上的iC和iU值均大于0.8。相比于其他算法,本文所用基于Bagging 异质集成学习算法在6 个数据集上iU值均为最高的同时,iC值也达到了最大。对于数据集ET1,由于其生成方式为实际用电数据乘以0.2~0.8 之间的一个随机数,即二者在数值之间有一定的相似性,使算法不易区分,造成所有算法在ET1 数据集上的表现较其他数据集差。
相比只含单一窃电样本数据集,包含混合窃电样本数据集上的检测结果在实际应用中更具有意义。与只含单一窃电样本数据集相比,BP 和SVM算法在MIX 上的iC和iU值几乎不变。DT 和KNN与基于Bagging 异质集成学习算法的iC和iU值均出现了一定程度下降,但仍远高于BP 和SVM 算法。3.3.2 与集成学习算法的对比分析
将本文所提模型与上述RF,AdaBoost 和GBDT 这3 种集成学习算法在7 个数据集的测试集上的结果进行对比,结果如表8 所示。
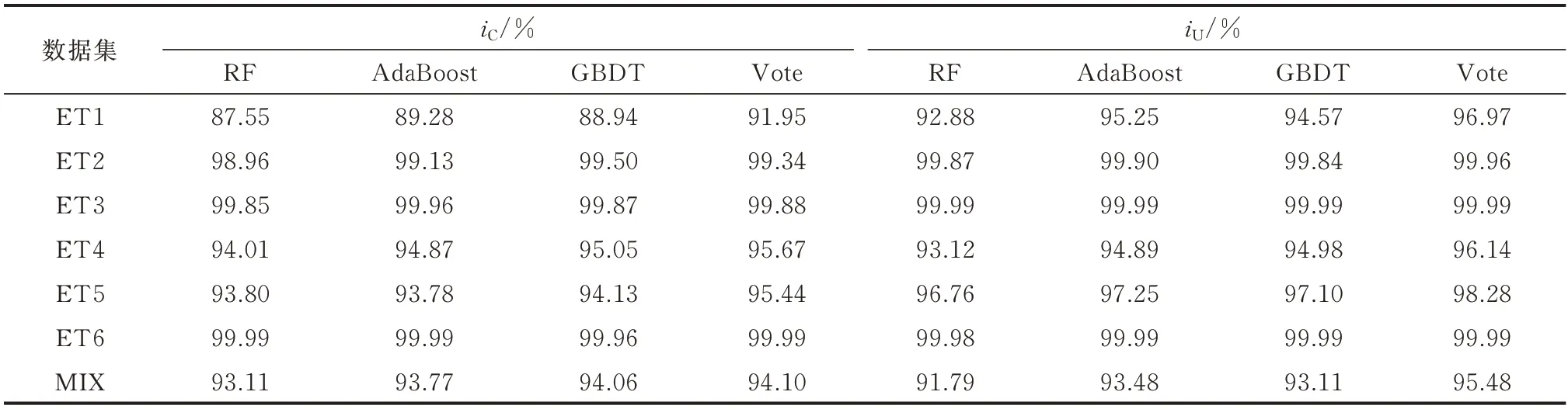
表8 本文所提模型与其他集成学习器的对比Table 8 Comparison of the proposed model and other ensemble learners
由于RF,AdaBoost 以及GBDT 均采用树集成的同质集成学习方式,故相较于DT 和KNN 等单一学习算法,有更出色的学习能力。与单一学习算法相比,3 种同质集成算法有更高的iC和iU值,但同时仍稍逊于基于Bagging 异质集成学习方法。ROC 曲线可直观反映各算法在数据集上的性能,8 种算法在7 个数据集上的ROC 曲线见附录A 图A1。
3.4 灵敏性分析
为了说明窃电样本所占比例的不同对基于Bagging 异质集成学习的窃电检测模型的影响,在不同窃电样本占比的取值下分别针对8 种算法的iC和iU进行了试验,结果分别如图4(a)和(b)所示。
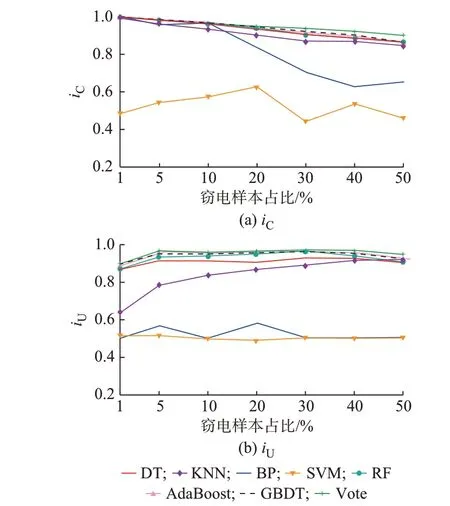
图4 8 种算法在不同窃电样本占比下的iC和iU Fig.4 iC and iU of eight algorithms with different proportions of electricity theft samples
由图4(a)可知,随着窃电样本占比的减少,除SVM 外,其他7 种算法的iC值呈现明显的上升趋势。其中,AdaBoost,DT,KNN,RF 和GBDT 与本文所用算法的iC值较为接近,但本文所用算法的iC值始终最大。
图4(b)显示了8 种算法的iU值。整体上,Vote,GBDT,RF,AdaBoost,DT 和KNN 这6 种算法的iU值明显高于BP 和SVM 算法,而随着窃电样本占比的减小,这6 种算法的iU值也几乎始终在0.8~1.0 之间波动,且Bagging 异质集成学习始终最大。其中,当窃电样本占比从5%降到1%时,Vote,GBDT,RF,AdaBoost,DT 和KNN 等6 种算法的iU值均出现了一定程度下降,这是由于此时正负样本的数量严重失衡,使得算法倾向于将所有样本判定为正样本,导致iU值下降。
4 结语
本文提出了基于Bagging 异质集成学习的窃电检测方法,充分利用不同学习器从不同角度对数据空间与结构进行观测,使得不同学习器能够取长补短。利用爱尔兰智能电表数据集进行对比,验证了本文方法的精确性与有效性。后续将进一步针对实际用电数据,进一步分析和选择正常用电和窃电的特征指标项,对窃电检测开展集成学习应用的深入研究。
本文工作得到国网湖北省电力有限公司2019 年科技项目(5215K018006B)的资助,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子测试(2018年1期)2018-04-18 11:52:35
数学物理学报(2017年5期)2017-11-23 07:51:31
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26
物理实验(2015年10期)2015-02-28 17:36:52
电测与仪表(2014年15期)2014-04-04 12:05:20
