
改进分段线性表示与动态时间弯曲相结合的负荷曲线聚类方法
2021-02-03 07:41:12宋军英崔益伟李欣然刘韬文李培强
电力系统自动化 2021年2期
宋军英,崔益伟,李欣然,钟 伟,刘韬文,李培强
(1. 国网湖南省电力有限公司,湖南省长沙市410077;2. 湖南大学电气与信息工程学院,湖南省长沙市410082)
0 引言
变电站综合负荷是由数量众多、特性各异的电力用户构成的,通过在线掌握用户的负荷特性,可实现变电站综合负荷构成特性的在线解析。其基本思路是:运用聚类分析的方法,对用户的日负荷曲线进行分类与综合,获得典型用电行业的分类负荷特性,进而在线解析得到综合负荷的用电行业构成比例,最终实现在线负荷建模[1-2]。
随着智能电网建设的深入,用户日负荷曲线数据量及维度大幅提高,对电网大数据平台负荷特性提取的准确性、鲁棒性及运算效率提出了更高的要求[3-4]。负荷曲线采样频率的提升虽然能更完整地反映用户的日用电特性,但高维数据集应用于聚类算法时会导致运算效率下降,且由于采样点增多,某一时间段的小幅噪声(以某一采样值水平线为基准上下波动的采样点)会影响曲线动态特性的刻画,从而导致相似度衡量误差。此时如果依然采用传统算法(如K 均值(K-means)算法),直接应用原始数据进行聚类,就会存在以下3 个缺点[5]:①聚类数目需事先划定,初始聚类中心曲线的选取过程完全随机;②相似度衡量方法难以准确估量高维曲线的动态特性;③鲁棒性较差,扰动点对算法聚类质量负面影响较大。因此,对于基于电网大数据平台的在线负荷建模,如何从海量的日负荷曲线中提取有价值的信息,高质量、高效率地进行实时准确聚类,完成变电站综合负荷解析,就成为亟须解决的重要问题[6]。
解决上述问题的有效方法之一就是对用户日负荷曲线集进行降维处理,提取能准确表征用户用电特性的特征点或特征指标进行聚类。文献[7]采用峰谷期负载率、最大最小负荷对应时刻等特征指标对日负荷曲线降维;文献[8]通过对日负荷曲线进行奇异值分解,以提取负荷曲线的负荷特征;文献[9]提出一种基于离散小波变换(discrete wavelet transformation,DWT)的模糊聚类方法;文献[10]基于子空间聚类算法进行负荷曲线集的特征提取,尝试在相同数据集的不同子空间上发现聚类。纵观上述文献,大多采用等分辨率降维方法,强制使数据集统一降至某一维度,一定程度上忽略了某些负荷曲线的斜率、极值点等关键负荷特性[11]。同时,以欧氏距离作为相似度衡量方法,无法准确衡量负荷曲线的动态特性,也不适用于自适应降维所构成的不等维时间序列集的相似度衡量[12-13]。
文献[13]研究表明,以动态时间弯曲(dynamic time warping,DTW)距离代替欧氏距离作为时间序列相似度衡量指标,能更充分地反映序列的整体动态特性,但在效率上存在一定的劣势,因此对于高维度曲线,难以满足在线、实时的应用要求。
本文在文献[13]研究的基础上,提出一种改进分 段 线 性 表 示(improved piecewise linear representation,IPLR)与DTW 距离相结合的基于Canopy 的K-means(CK-means)日负荷曲线聚类方法。首先,该方法以相邻及间隔采样点变化量为依据,对原始曲线集进行基于IPLR 方法的自适应重构,得到一组不等维度的降维数据组;然后,采用Canopy 算法获取聚类数目及初始聚类中心;最后,利用以DTW 距离作为相似度衡量手段的K-means算法对其进行聚类处理。算例结果表明,本文方法所采取的IPLR 自适应降维方法与DTW 距离相似度衡量手段相契合,所得聚类结果与实际相符,且在聚类质量、鲁棒性及运算效率上较传统方法均具有一定的优越性,满足基于电网大数据平台的实时在线负荷建模的要求。
1 IPLR 算法
1.1 基本思路
传 统 分 段 线 性 表 示(piecewise linear representation,PLR)算法基于相邻采样点的采样值变化量对原始时间序列进行重构。首先,计算每个采样点的相邻采样值变化量;然后,根据变化量是否超过给定阈值,以判断其是否为特征点;最后,将所有特征点按先后顺序依次连接,即完成时间序列的降维重构[14]。但是该算法的特征点提取条件过于宽松,仅关注时间序列的局部特性,受扰动影响较大[15-16]。当时间序列中某一时间段的采样点维持某一水平采样值进行近似的等幅小额振动,且此一系列频繁振动导致此时间段的采样点相邻变化量皆超过阈值,则降维重构序列中将包含大量扰动点。为解决这一问题,本文在传统算法的基础上加入对采样点间隔变化量的限制,以达到通过提取少量采样点即可反映序列的关键特性,并增强算法的抗干扰能力的目的。算法流程如图1 所示。
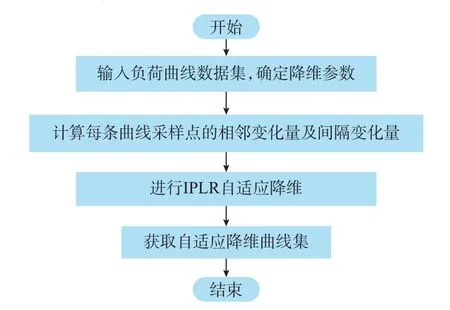
图1 IPLR 算法流程图Fig.1 Flow chart of IPLR algorithm
1.2 算法实现
对于具有m条时间序列的n维数据集G=[G1,G2,…,Gm],其中第i条时间序列为Gi=[gi1,gi2,…,gin]。通过IPLR 算法对Gi进行自适应降维得到u维的降维序列Hi=[hi1,hi2,…,hiu]的具体步骤如下。
步骤1:首先,取原始序列Gi的首尾两端的采样点作为降维序列的首尾两端,即hi1=gi1,hiu=gin;然后,输入相邻采样点变化量阈值参数λ1和λ2[17]及间隔采样点变化量阈值参数σ和ε。其中σ通过设定间隔采样点变化量差阈值,选取间隔变化量绝对值变化较大的特征点;ε通过设定采样点的间隔变化量乘积阈值,选取左右间隔变化量绝对值相近但值较大的特征点。λ1,λ2,σ和ε的取值,由数据集G中随机选取m条时间序列集的每条时间序列的相邻采样点的平均变化量与间隔采样点的平均变化量决定,如式(1)至式(3)所示。
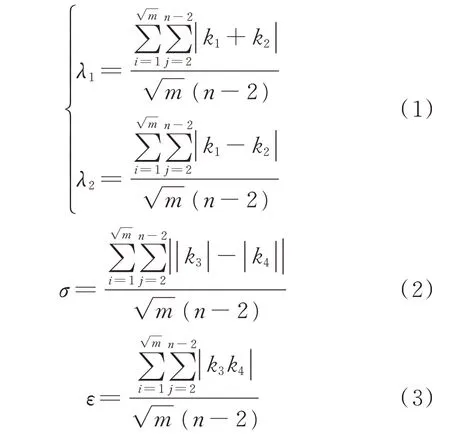
步骤2:计算第j个采样点的相邻变化量k1=xj+1-xj,k2=xj-xj-1,以及间隔变化量k3=xj+2-xj,k4=xj+1-xj-1,其中2 ≤j≤n-2。
步骤3:对于时间序列点gin,若|k1+k2|>λ1或|k1-k2|>λ2,则进入步骤4,否则j=j+1,进入步骤5。
步骤4:若||k3|-|k4||>σ或|k3k4|>ε,则提取该点,进入步骤5,否则j=j+1,进入步骤5。
步骤5:若j=n-2,输出降维重构曲线,否则进入步骤2。
1.3 降维效果分析
现对一条维度为96 的日负荷曲线A进行降维分析,该曲线在0~24 和48~65 采样时段分别维持0.5 和0.85 的负荷水平进行小额波动。若应用基于SEEP 序列的PLR 算法,曲线维度降至49,得到降维曲线A',如图2 所示。不难看到,该方法将负荷低谷期及双峰间谷端的处于波动时间段的采样点采纳为特征点,导致重构的降维曲线维数较高,且含有大量扰动点,无法准确反映原始曲线的动态特性。若应用本文的IPLR 算法对日负荷曲线进行降维重构,得到降维曲线A″,如图3 所示,维度降至39,大部分波动时间段的扰动点被剔除。

图2 PLR 降维示意图Fig.2 Schematic diagram of dimension reduction of PLR
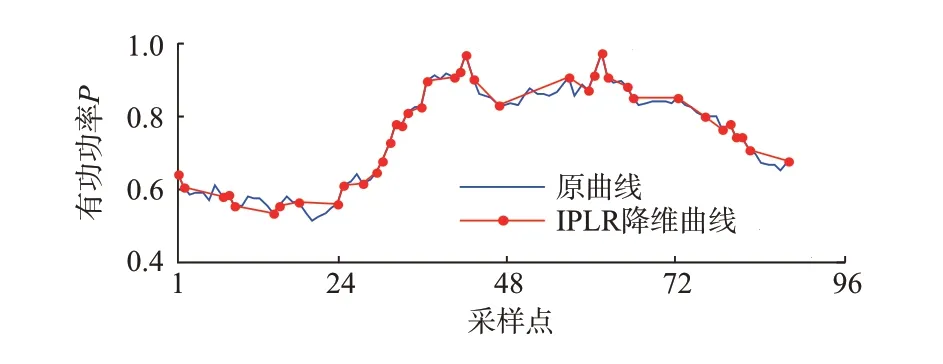
图3 IPLR 降维示意图Fig.3 Schematic diagram of dimension reduction of IPLR
应用文献[14]中的时间序列压缩度计算方法,对2 种降维方法关于原始日负荷曲线A的压缩率进行计算对比分析,可以发现IPLR 降维方法的压缩率较PLR 降维方法高25.64%。定义Ddtw(X,Y)为时间序列X与Y之间基于DTW 距离的相似度。将原始曲线A分别与降维曲线A'与A″进行拟合度分析,则 可 得Ddtw(A,A')=0.024 8,Ddtw(A,A″)=0.017 8。不难发现,IPLR 降维方法所得降维曲线与原始曲线拟合程度更高,更能反映负荷曲线的负荷特性。
现从数据集中随机选取负荷曲线B(B'与B″分别为曲线B经PLR 算法与IPLR 算法所得的降维曲线)与负荷曲线A作相似度分析,以DTW 距离为相似度衡量指标[18],结果如表1 所示。其中,Ⅰ,Ⅱ,Ⅲ分别对应不降维处理、PLR 降维处理及IPLR 降维处理。
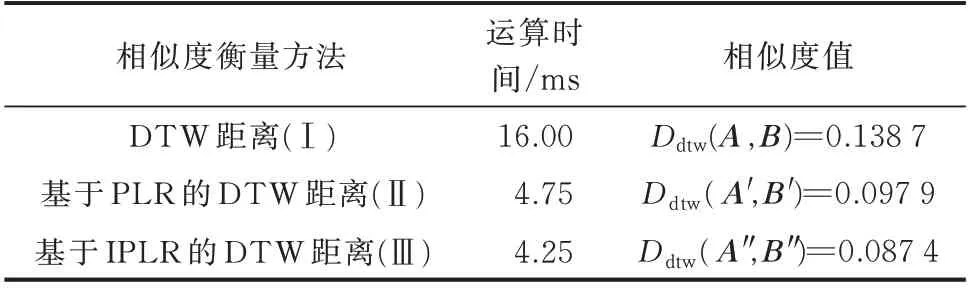
表1 相似度衡量方法对比Table 1 Comparison of similarity measuring methods
由表1 可知,通过对负荷曲线降维,可以显著提升DTW 距离应用于负荷曲线间相似度衡量的运算效率,使运算时间缩减至接近原来的1/4。同时,IPLR 降维方法与原始曲线的相似度指标值及运算时间分别比PLR 降维方法降低近11%和10%。
综上可知,本文所提IPLR 降维方法通过提取负荷曲线的特征点对原始曲线进行自适应降维,能以尽可能低维度的降维曲线反映原始负荷曲线的关键动态特性。该方法所得降维曲线拟合度高、运算时间短、抗干扰能力强,适用于用户日负荷曲线的聚类运算。
2 基于IPLR 与DTW 距离的CK-means算法
2.1 CK-means 算法
CK-means 算法为基于Canopy 聚类结果的Kmeans 聚类算法,相比于K-means 算法,其首先应用Canopy 算法选取聚类数目及初始聚类中心,然后再采用K-means 算法进行聚类。
Canopy 算法是一种快速简单但精准度一般的聚类算法,其最大特点是无须确定聚类数目,适用于预处理阶段对原始数据集进行粗聚类处理,将此聚类结果作为初始聚类中心,虽同样具有一定的随机性,但代表性更强。算法基本运算流程如下[19]。
步骤1:设定阈值T1与T2(一般T2取所有曲线平均距离的2 倍,且T1=2T2),并满足T1>T2。
步骤2:从数据集中任取一点,作为第1 个Canopy(作为Canopy 的数据点应从数据集中删去)。
步骤3:计算数据集中其他每个点Zi与所有Canopy(Rj)的距离Ui-j。若Ui-j<T2,则将其归入此Rj类别;若其关于所有Canopy 的距离满足Ui-j>T1,则将其当作一个新的Canopy;若该点到某个Canopy 距离Ui-j<T1,并在其与所有Canopy距离计算完成后依然未加入任何Canopy,则将其作为一个新的Canopy。
步骤4:重复步骤3,直至数据集为空。
2.2 聚类有效性指标
聚类的有效性一般通过以下2 个方面反映:一是同一种类的对象间相似度较高;二是不同种类的对象间差异性较大。
由文献[20]可知,DBI(Davies-Bouldin index)指标同时考虑聚类结果的类内及类间的聚类效果,如式(4)所示。IDBI为类内距离之和与类外距离的比值,其计算公式简单且指标值变化范围小,能直观反映聚类质量。因此,相比于其他指标,DBI 指标更适用于评定电力用户日负荷曲线聚类的有效性。
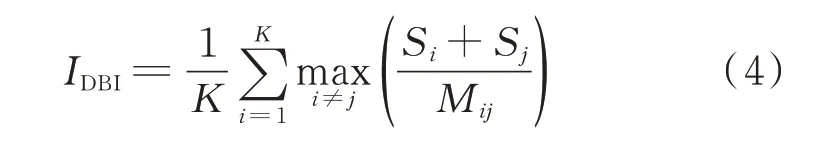
式中:K为聚类个数;Si为第i个类中曲线集与该类聚类中心曲线的平均距离,用于反映第i个类中曲线集的聚拢程度;Mij为第i类中心与第j类聚类中心曲线的距离,以反映类间第i类与第j类曲线集的分散程度。
由于不同相似度衡量手段侧重于衡量曲线的不同特性,故本文以欧氏距离作为相似度的指标定义为I1,以DTW 距离作为相似度的指标定义为I2,分别以负荷曲线的整体分布特性与整体动态特性评估聚类质量[13]。
2.3 算法实现过程
首先,本文算法基于IPLR 对原始数据集进行降维处理;然后,应用Canopy 算法确定算法的聚类数目及初始聚类中心;最后,应用基于DTW 距离的K-means 算法对降维数据集进行聚类运算。具体步骤如下。
步骤1:预处理。首先,对于部分采样点缺失的日负荷曲线进行插值补全,并基于曲线相邻采样点波动量筛除异常波动曲线[21];然后,对日负荷曲线集采取极值归一化处理[22],得到含有m条曲线的归一化数据集Y=[y1,y2,…,ym]T。
步骤2:初始化。对数据集Y进行IPLR 降维处理,得到不等维数据集P=[p1,p2,…,pm]T,并对原始数据组进行基于Canopy 算法的粗聚类运算,得到聚类数目L与初始聚类中心曲线集C=[C1,C2,…,CL]T。
步骤3:相似度的衡量。首先,对不等维数据组P=[p1,p2,…,pm]T中的曲线关于每类聚类中心曲线进行基于DTW 距离的相似度计算,之后,将每条负荷曲线分至与其最相似(即DTW 距离值最小)的类别中[23]。
步骤4:对聚类中心矩阵C=[C1,C2,…,CL]T进行更新,如式(5)所示。当算法进行至满足以下任一条件时,结束运算,本次循环的聚类中心曲线即为最终聚类结果:①2 次迭代所得成本损失函数Serror满 足|Serror(I+1)-Serror(I)| <e(I表 示 算 法 迭 代次数,e为收敛阈值),成本损失函数如式(6)所示[24];②2 次迭代所得聚类中心曲线的误差在阈值范围内[25]。否则,继续进行步骤3 与4,直至完成规定最大迭代次数或满足以上条件之一。

式中:CL(I)为算法进行第I次迭代后的第L类聚类中心曲线;Ddtw(Yn,CL(I))为Yn与CL(I)之间基于DTW 距离的相似度。
3 算例检验
3.1 实例检验与比较
本文随机选取某省区电网110 kV 变电站下属1 200 个典型用户(包含工商业及居民用户)的不同采样频率(采样频率分别为15 min/点和30 min/点)的一天的日负荷曲线数据集作为实验对象。为了验证本文所提降维方法与所采用相似度衡量手段的合理性及优越性,本文对基于欧氏距离的CK-means算法(方法1)、基于DTW 距离的CK-means 算法[13](方法2)、基于PLR 与DTW 距离的CK-means 算法(方法3)和基于IPLR 与DTW 距离的CK-means 算法(本文方法)展开聚类分析,并对这4 种方法的聚类结果(聚类中心曲线)、聚类质量(DBI 指标)及聚类效率(运算时间及迭代次数)进行综合比较。实验所用机器:单台计算机,配置为i5-4570s CPU@2.90 GHz,1050 Ti 4 GB,操作系统为Windows 7,内存为16 GB。
对48 点日负荷曲线数据集展开聚类分析。在预处理步骤中,本算例认为若曲线相邻负荷点变化超过20%,即为异常波动曲线,需排除。本算例降维算法阈值参数取值为:λ1=0.055,λ2=0.035,σ=0.025,ε=0.000 45。
4 种算法所提取的不同行业类别的聚类结果如附录A 图A1 至图A4 所示,可以发现,每一行业的聚类中心曲线相似度较高。其中降维算法(方法3和本文方法)与方法1 和方法2 的分歧点主要集中在第3 类负荷的划分上。附录A 图A1 与图A2 中第3 类负荷特征体现为白天负荷水平较高,负荷高峰期主要集中于11:30—12:30 与17:00—20:00,且晚高峰负荷远大于午间负荷;图A3 与图A4 的第3 类负荷特征体现为三峰负荷曲线,3 段峰值集中在07:30—09:00,11:30—12:30 与17:00—20:00,同样,晚高峰负荷远大于前2 段峰值负荷,这一类负荷的负荷特征属于市政生活用电类型。定义Ic为类内距离指标,以衡量各算法第3 类聚类中心曲线的聚类质量,公式如式(7)所示,结果如附录A 图A5所示,可知本文方法的类内聚拢效果最佳。
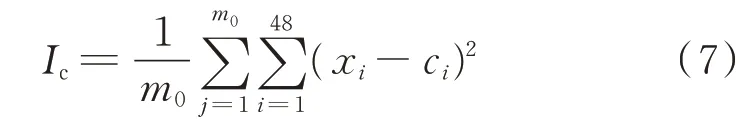
式 中:m0为 属 于 第3 类 的 负 荷 曲 线 数 目;xi为 第j条曲线第i个采样点的采样值;ci为第3 类聚类中心曲线第i个采样时刻的对应值。
分析另外3 类聚类中心曲线:第1 类负荷曲线白天除午间出现相对低谷期,整体变化较平缓,晚间负荷水平较低,反映的是采用单班制的轻工业企业的用电行为;第2 类负荷曲线全天基本保持在一个高负荷水平,反映的是以采矿、炼钢行业为代表,一般采用三班制作业的重工业企业的用电行为;第4 类负荷曲线从08:00—22:00 变化较平缓,反映的是以服务业为代表的第三产业用电行为。因此,这4 种算法聚类结果均与实际相符,具有一定的实际工程参考价值。
附录A 图A6 所示为4 种算法的聚类指标随迭代次数变化的曲线;表2 所示为4 种算法对日负荷曲线数据进行聚类分析的耗时、迭代次数及最终聚类指标的性能对比。由附录A 图A6 与表2 可知,通过对原始负荷曲线集进行降维重构,本文方法的算法性能得到显著提升,相比于方法2,聚类指标优化明显,运算时间降低近50%;相比于方法1,虽然牺牲了一定的运算效率,但也因此获得了更高的聚类质量(I1指标下降16.51%、I2指标下降53.02%);而相比于同样对原始负荷曲线集进行了降维重构的方法3,本文方法由于采用了更为严格的特征点筛选条件,在运算效率及聚类质量上都得到了进一步提升。因此,本文方法相比于其他3 种方法,具有最优的综合性能。
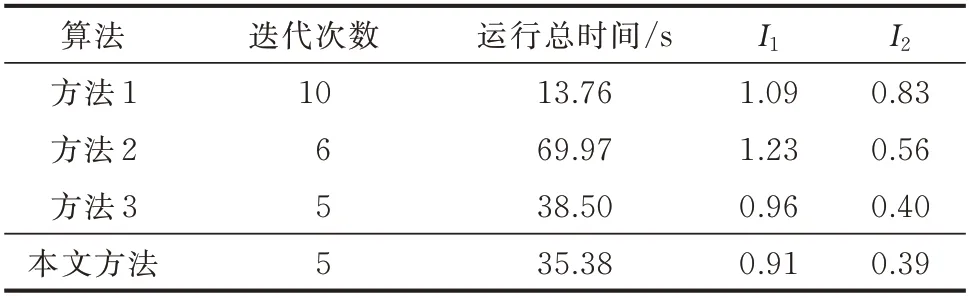
表2 不同算法的48 点曲线集聚类指标Table 2 Clustering indices of 48-point curves of different algorithms
对96 点日负荷曲线数据集展开聚类分析。在预处理步骤中,本算例认为若曲线相邻负荷点变化超过15%,即为异常波动曲线,需排除。本算例中,降维算法阈值参数取值为:λ1=0.05,λ2=0.03,σ=0.025,ε=0.000 45。
在该工况下,4 种算法的聚类结果与48 点负荷曲线数据集的聚类结果基本一致,限于篇幅,此处不再展示。聚类指标如表3 所示。由表可知,本文方法的综合性能相比于其他3 种方法依然为最优,但其相比于对48 点负荷曲线数据集进行聚类,算法运算效率出现显著下滑,耗时增长170.89%。这是因为对于一个维度为n的负荷曲线集,DTW 距离算法复杂度为o(n2),当数据集的维度翻倍时,运算效率将大幅下降。
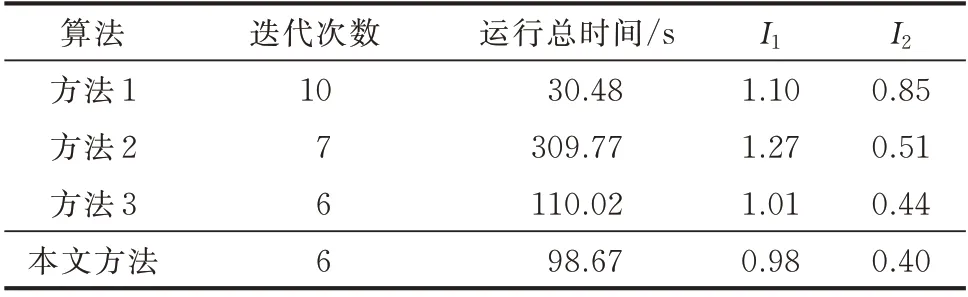
表3 不同算法的96 点曲线集聚类指标Table 3 Clustering indices of 96-point curves of different algorithms
综上可知,本文算法得到的聚类结果符合工程实际,且相比于其他方法综合性能更优,但受限于算法运算效率,所以更适用于48 点负荷曲线数据集的聚类运算。
3.2 算法鲁棒性分析
为检验本文方法的鲁棒性,对3.1 节所选曲线集加入大小为r(r=5%,10%,15%,20%,25%)的随机扰动,以模拟实际用户负荷曲线采样过程中因天气等随机因素造成的负荷波动。然后,本节分别采用3.1 节中的4 种方法对扰动曲线集进行聚类对比分析,并以聚类质量指标DBI 作为鲁棒性考量指标。
由表4 可知,随着对负荷曲线所加扰动的增加,各类方法的聚类质量指标基本呈下降趋势。方法1与方法2 在小扰动干扰下,聚类质量指标尚可,但当扰动r≥10%时,聚类质量指标出现大幅下降,且方法2 的I2指标下降速度要低于方法1。这是因为,方法1 与方法2 直接应用原始负荷曲线数据集进行聚类,导致每个采样点的采样值都会对聚类结果产生直接影响,从而使其无法准确提取曲线的动态特性,产生较大的聚类偏差,但方法2 由于采取DTW 距离作为相似度衡量手段,所以在动态特性指标I2上表现出更强的鲁棒性。方法3 和本文方法由于对原始曲线进行了特征点提取,并以DTW 距离作为相似度衡量方法,综合考虑负荷曲线的动态特性,因此受扰动影响较前两者小,故在中小扰动工况下(r≤20%)都能表现出较好的鲁棒性。但在大扰动工况下,方法3 和本文方法鲁棒性出现了较大幅度下滑,这主要是因为阈值参数是按照一般工况进行的设定,取的是日负荷曲线相关特性参数的平均值,当扰动过大时,部分扰动点将被误提取为特征点。但是,本文方法在中小扰动及大扰动工况下的鲁棒性,依然略优于方法3,这主要得益于其更严格的特征点提取方法,进一步降低了扰动的负面影响。

表4 不同算法的聚类指标Table 4 Clustering indices of different algorithms
综上可知,本文方法鲁棒性较强,在一般工况(中小扰动工况)下依然能以较高质量提取用户原始负荷曲线的负荷特性;但在大扰动的极端工况下,鲁棒性会出现一定程度的下降。总体而言,本文方法能够满足基于大数据的在线负荷建模要求。
4 结语
为准确提取负荷曲线的特征点,并提升现有聚类算法的聚类质量,本文提出一种基于IPLR 降维与DTW 距离相似度衡量的CK-means 算法。首先,该算法基于IPLR,根据原始数据集中负荷曲线自身负荷特性进行自适应分辨率降维;然后,应用基于DTW 距离相似度衡量方法的CK-means 算法对此不等维降维数据组进行聚类运算分析,以准确提取不同用电特性用户的用电特征。本文算例得到如下结论。
1)IPLR 降维方法采用合理。其可在一定程度上过滤负荷曲线的扰动采样点,准确提取出负荷曲线的关键特征点。
2)DTW 距离相似度衡量手段采用合理。此相似度衡量方法能较准确地衡量负荷曲线间的动态特性相似度,且其可衡量不等维时间序列间相似度的特点与IPLR 降维方法可对数据组进行自适应降维的优点相契合。
3)本文所提聚类方法较传统方法具有更高的综合性能,满足基于电网大数据平台的实时在线负荷建模的要求,对变电站综合负荷构成比例解析具有重要参考价值。
但本文方法对数据预处理要求较高,且运算效率有进一步提升的空间。下一步工作将在现有工作基础上,针对大扰动工况下鲁棒性较低及DTW 距离算法计算耗时较长的问题,对本文算法做进一步研究改进。
本文得到湖南省电力公司重点计划项目(5216A5180018)的资助,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
数学物理学报(2022年4期)2022-08-22 04:06:36
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
海峡姐妹(2019年12期)2020-01-14 03:24:40
数学物理学报(2019年4期)2019-10-10 02:38:56
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
贵州师范学院学报(2016年3期)2016-12-01 03:53:52
电源技术(2015年11期)2015-08-22 08:50:38
