
一种基于同类融合的工业数据扩充算法
2021-02-02 08:50邵桂芳高凤强刘暾东
厦门大学学报(自然科学版) 2021年1期
邵桂芳,黄 梦,高凤强,刘暾东
(厦门大学航空航天学院,厦门市大数据智能分析与决策重点实验室,福建厦门361005)
数字图像处理技术广泛应用于生物医学图像分析[1]、工业机器人视觉[2]以及目标分类与检测[3-4]等领域.特别是基于机器视觉的工业缺陷检测有效解决了人工检测效率低及误检和漏检等问题,从而提升后续产品的性能.但其处理精度取决于缺陷图像数据量与相应处理方法,而工业生产过程中缺陷属于小概率事件,缺陷特征的出现具有一定的随机性,导致原始样本数据量不足.同时,受工业生产工艺和原材料的影响,表面缺陷可能是多样且形态各异的,例如,板材生产过程中,其表面偶尔会出现斑块、裂纹、麻点、夹杂、划伤及轧入氧化皮等多种缺陷[5].数据的部分内容缺失、可信性低、不同类之间的数据不平衡、特种环境下数据获取困难导致的数据样本少等问题给基于机器视觉的缺陷检测带来了很大挑战[6-8].
为提高缺陷图像样本的数量和多样性,研究者针对数据扩充技术开展了大量研究,主要有常规的数据扩充方法、基于数据增强策略的扩充方法和基于数据生成的扩充方法等3类.常规的图像数据扩充方法包括旋转、填充、平移、插值、翻转、高斯噪声、翻折、裁剪、几何变换、缩放、弹性形变和主成分分析抖动以及其组合,例如,Alex等[9]提出将水平翻转和主成分分析这两个不同的常规数据扩充方法结合起来改善模型性能;Zeiler等[10]提出将多个不同的翻转和裁剪用在每个训练集图像上以提升训练集质量.常规的扩充方法虽然通用性很好,可以使用在更多任务的数据预处理中,但是这些方法大部分是针对单幅图像进行处理,并且不具有针对性,无法针对图像局部的目标特征进行有效地扩充.另外,有研究表明,针对性地设计数据扩充策略比随机的数据扩充更能提高训练集图像质量,从而提升模型的泛化性能[9-11].因此,出现了将几何变换、图像增强、随时遮挡和噪声干扰等方式相结合生成扩充数据集的最佳扩充策略[12]和基于强化学习从数据集中自动寻找有效扩充策略的自动探索扩充策略[13-14].但是,基于策略的扩充方法独立性太强,从某一类特定任务中得到的扩充策略无法有效地应用在其他任务的数据扩充中.常规的扩充和基于策略的扩充方法主要是间接地改变数据,无法有效地改变图像目标语义特征.针对目标图像颜色、形状、大小、空间位置等各个方面的视觉语义特征,有研究者开始考虑利用直接生成数据的方法进行数据扩充.Tran等[15]提出基于训练集分布的贝叶斯生成方法以生成扩充数据,该方法将生成模型和蒙特卡洛期望最大化算法结合起来扩充训练集分布中缺失数据点.Lemley等[16]提出智能扩充方法即通过合并多个样本来生成新的数据.基于数据生成的扩充方法虽然能够直接捕捉并学习到目标特征来扩充数据,但是生成模型的自由度有时过大,可能会生成一些含有未知特征的缺陷数据,而且有效地训练生成模型是耗时的,并且对原始数据的质量要求较高.
上述方法虽然一定程度上可以解决数据量不足和样本类型不丰富的问题,但是常规扩充方法主要是从图像整体进行扩充数据,无法满足一些特殊场景的具体任务需求.另外,由于不同任务具有各自特色,不同的方法适用的场景任务也有限,所以,不同任务的数据扩充需要进一步研究,如目标检测的扩充研究[17]及图像分类的扩充研究[18].在工业表面缺陷图像的分类或检测过程[6]中,一般都会采用常规图像扩充方法对图像进行预处理,如平移、翻转、旋转、缩放和剪切等,然后再将数据输入到模型中进行训练,以避免模型的过拟合,从而达到提升模型性能的效果.在常规图像扩充过程中,扩充的样本数量与常规图像扩充方法的参数选择密切有关,如在缩放的处理过程中,若设置10种不同的缩放因子,就会得到10倍扩充数据,如{0.30,0.40,0.50,0.60,0.65,0.70,0.75,0.80,0.85,0.90}.但是,这些方法大多是针对整张图像进行处理的,并不关心图像内是否有缺陷.而对于缺陷检测应用而言,图像内是否存有缺陷特征很重要,而且缺陷的位置和类型也很重要.但是目前常规扩充方法仅对单个样本进行操作,不会增加更多的样本特征,而且很容易改变缺陷的位置,这给后期标签位置信息重新获取带来了很大的困难,导致成本急剧增加.另外,对于工业表面缺陷图像而言,缺陷在整幅图像里仅是较小的一部分,且其局部的细节特征对后续检测与分类更为重要,因此上述已有的扩充方案并不一定适合,并且效果有限.
综上所述,为保证扩充包含更多样本缺陷特征的数据,并且确保扩充缺陷图像的类别一致性,需要考虑在多个同类样本间进行融合以获取更多的缺陷特征信息,从而保证多个原始样本中的位置标签信息是可以重复利用的.因此,本文考虑同类缺陷样本具有相似的缺陷特征信息,提出了针对表面缺陷特征的多样本同类融合数据扩充(homogeneous fusion data augmentation,HFDA)方法,来解决工业表面缺陷图像的数量不足和类别不平衡的问题.本文提出的方法采用了多样本融合处理,避免了常规数据扩充方法仅针对单个样本处理的缺点,而且比基于策略的扩充方法的适用范围更广,在实际运用中有更好的通用性.更重要的是,本文提出的方法确定性地对多个样本进行融合来获取更多的图像特征,避免了生成模型因自由度过大,生成含有未知特征的缺陷数据等问题.
1 同类融合扩充方法
1.1 同类缺陷多样本融合
由于多个样本间的特征会有多种形式,采用多样本扩充要比单一样本的传统扩充方式更加有利于得到多样化数据.同时,在选择多样本前,先对不同的缺陷样本进行分类,然后在同类别的样本中随机选择一定数量的图像进行融合,有利于保证同一类别样本的本质信息一致.即本文所提的HFDA方法,主要包括6个部分:缺陷样本分类、同类样本组选取、多样本选择、数据融合、扩充数据及目标模型训练,如图1所示.

Dk为原始图像,Nk为融合处理后的图像.图1 HFDA的框架Fig.1The framework of HFDA
1) 缺陷样本分类.将来自表面缺陷数据的缺陷样本按一定标准进行分类,如将钢材表面缺陷图像按照缺陷类型可分为破裂、斑块、划痕、表面夹杂、表面斑点以及轧入氧化皮等多种类型.本文借鉴有序样本分类[19-20]的方式来定义原始样本,这种方式不仅能够处理无序样本,而且还能利用样本的有序信息.本文设Ωori={x1,x2,…,xn}表示采集的所有缺陷样本的集合,那么sn,k,kj表示将n个样本分成k类,每类包含j个样本的分类方式,具体的数学描述如下:
sn,k,kj={{xi1=x1,xi1+1=x2,xi1+1j-1=
x1j},{xi2=x1j+1,xi2+1=x1j+2,…,xi2+2j-1=
x2j},…,{xik=x(k-1)j+1,xik+1=
x(k-1)j+2,…,xik+kj-1=xkj=xn}},
(1)
其中:n是样本总数;k是预设的样本类别数;kj是指第k类样本有j个,那么ik就表示第k类的第一个样本,ik+kj-1表示第k类的最后一个样本.
可以按照样本缺陷类型、位置及采集的先后顺序等不同标准进行分类.例如,当选择按照表面缺陷样本的类别对钢材表面缺陷图像分类时,表面缺陷图像的样本总数n按实际数量可为1 260,有6类缺陷则k=6,若其中第k类的样本数为210,则kj为210,此时相应的sn,k,kj表示其对应的分类方式.若按照样本中缺陷的位置分类,那么将缺陷图像等分四小块区域,则k=4表示缺陷出现位置的可能性类型,其余参数和按照表面缺陷样本类别进行分类的参数相似.若按照缺陷样本采集的先后顺序分类,那么将采集缺陷图像的24 h等分为4个时间范围,则k=4表示缺陷何时出现的可能性类型,而且ik以及ik+kj-1能够按照时间先后来有序地表示样本,其余参数和按照表面缺陷样本类别进行分类的参数相似.因此此种分类方式不仅能够表示包含缺陷种类的无序样本的划分,而且还能表示包含时间属性的有序样本划分.
2) 同类样本组选取.在样本分类完成之后,选择其中一组同类别的样本.例如,可以先按照缺陷样本类别设置k=1表示破裂的缺陷图像,k=2表示斑块的缺陷图像,k=3表示划痕的缺陷图像,k=4表示表面夹杂的缺陷图像,k=5表示表面斑点的缺陷图像,k=6表示轧入氧化皮的缺陷图像.若在样本总数n为1 260的钢材表面缺陷数据中选取数量为210的表面夹杂类型的一组样本,则k=4,kj=210则s1 260,4,210就表示选取的同属表面夹杂类型的样本组,具体表达如下:
sn,k,kj=s1 260,4,210={xi4=x3j+1,xi4+1=
x3j+2,…,xi4+210-1=x4j}={xi4=
x3j+1,xi4+1=x3j+2,…,xi4+209=x4j}.
(2)
3) 多样本选择.在已经确定的同类缺陷样本组的每个样本映射中依次随机选择多个样本.例如,确定表面夹杂缺陷图像的随机样本数为2,那么在表面夹杂的钢材缺陷图像中,依次不重复的选择两个样本成为一组,对已有的同类缺陷样本标签z进行随机选择组成新序列,如下所示:
{(z1,z2),(z3,z4),…,(z2n-1,z2n)}.
(3)
其中,zk为每个样本标签,random是随机函数.那么,zi对于表面夹杂缺陷图像的样本组而言,由表面夹杂缺陷样本标签z进行随机选择组成的新样本序列为:
(xi4+208,xi4+209)}.
(4)
4) 数据融合.将多样本选择过程中确定的某一缺陷类别的多个样本经过缺陷特征融合的处理操作得到对应的融合样本,如依次将每组对应的两个表面夹杂的缺陷图像融合为新样本.当随机样本数为2时,z是标签对应的样本序列,设待融合随机量分别为x和y,令x=z和y=z,那么第k类的所有不重合缺陷样本组的融合关系如下所示:
(5)
其中,blend是本文提出的表面缺陷特征的融合处理机制,包括缺陷图像分割、缺陷特征的定义及提取、缺陷特征区域初步扩充、缺陷区域融合扩充4个部分.
(i) 缺陷图像分割.采用基于k-means聚类的方式对表面缺陷图像进行分割来初步定位缺陷特征.基本的步骤是:
第1步:确定聚类的类别数量k(如k=3),选择k个中心点.初始点选择的策略是它们之间的间距要足够大.首先计算缺陷图像中所有像素点之间的距离,然后将距离最大的两个样本点C1和C2设置为2个初始的中心点,接着在像素点集中删除这两个点.此时,如果已经有初始k个中心点,则终止.否则,在其他的像素点中,根据以下优化规则选取另一个点C3,依次迭代优化,一直到确定k个中心点.优化目标的规则如下所示:
(6)
第2步:对于每个像素点,找到它最近距离的中心点,那么在同一个中心点周围的点自动归为同一类别,最终就完成了一次聚类.
第3步:对于聚类后的像素点要判断其类别是否与聚类前相同,若相同,则结束算法,否则进入下一步.
第4步:对于每个类中的像素点,计算这些像素点的中心点,将它视为此类的新中心点继续第2步.
(ii) 缺陷特征定义及提取.为了更好地捕捉到表面缺陷的特征信息,本文通过对表面缺陷图像的观察和分析,提出了表面缺陷样本的形状特征、空间特征及强度特征,然后根据指定的模板对缺陷图像的所有像素样本点进行扫描,建立出表面缺陷图像的特征空间,特征的定义如表1所示.

表1 表面缺陷图像的特征定义Tab.1 The feature definition of surface defect images

最后,需要进行缺陷特征提取.根据特征定义获得了缺陷样本图像中所有像素点的八维特征向量,由于不同的特征维度有重合,在空间上有很大的相关性,而且在较高的维度空间上,数据的分布也相对稀疏,所以本文将采用主成分分析方法对八维特征去相关得到三维特征.因为根据大量实验可知,三维特征能够大部分很好地表征原始的八维特征,所以通过降维后的数据可以完成特征提取.
(iii) 缺陷特征区域初步扩充.在通过提取的缺陷特征定位到缺陷区域后,可以对相应的缺陷位置区域按照一定的标准进行常规的扩充操作.因为不同的缺陷类型对常规扩充方法适应性不同,例如,如果对划痕缺陷特征执行缩放操作,那么缩放之后得到偏大或偏小的划痕都和原始划痕缺陷相差过大,造成缺陷不一致的影响.所以,本文设定破裂、斑块、表面斑点以及轧入氧化皮等图像的缺陷提取区域可执行旋转、缩放及翻折的组合操作,划痕和表面夹杂等图像的缺陷提取区域可执行旋转、翻转及高斯噪声的组合操作.最终,可以获得表面缺陷图像的不同缺陷区域的扩充结果.
(iv) 缺陷区域融合扩充.如式(5)所示,每次的处理对象是相同类别缺陷图像集中的两个样本,这就表明需要将样本x中缺陷特征区域初步扩充的结果任意合并到样本y中,同时将样本y中缺陷特征区域初步扩充的结果任意合并到样本x中,最终完成同类缺陷图像中的不同样本间相互融合的结果.因此,从式(4)对应的第4类表面夹杂缺陷样本随机组成的新样本序列可知,它的同类融合结果为
(7)
所以,每个类别的缺陷样本进行融合扩充组成的数据集合为
(8)
其中,k是类别数.
5) 扩充数据.将经过数据融合处理后得到的扩充样本和原始对应的同类数据重新组合为新的数据集,如下所示:
Ωnew=Ωori+Ωaug,
(9)
其中,Ωori是所有表面缺陷数据,Ωaug是所有类别的缺陷样本融合扩充后的数据.
6) 目标模型训练.将重新组合的训练集数据Ωnew用于训练表面缺陷图像分类及检测的模型.
1.2 工业同类缺陷融合数据的应用
如图2所示的框架流程,在工业表面缺陷数据扩充之后,需要将扩充后的数据Ωaug与原始训练集Ωori组合作为新的训练集Ωori+Ωaug一起输入到目标任务模型中,如缺陷图像分类或缺陷目标检测的模型,具体的同类融合缺陷数据扩充算法应用如算法1所示.

图2 同类融合数据的应用流程Fig.2The application process of homogeneous fusion data
算法1同类融合的工业数据扩充算法
按照一定标准对工业表面缺陷样本数据集进行分类;
for 样本类别数cdo
根据式(3)对样本进行随机顺序排列;
选择多个样本进行分组,如可设置随机样本数为2;
根据式(5)对每个类别中组合的样本对进行融合;
end
根据式(8)得到扩充数据样本集Ωaug;
将根据式(9)得到新训练集Ωnew;
for 迭代次数 do
在新训练集Ωnew中,按要求取出训练样本数据;
将取出的训练样本输入到目标模型中,如缺陷分类或检测模型;
获得训练完成的目标模型.
end
2 实验方法与结果分析
2.1 实验数据
本文利用来自东北大学的表面缺陷数据库(Northeastern University surface defect database, NEU-sda)验证表面缺陷数据扩充的有效性,该数据库包括用于缺陷分类的NEU-CLS数据集和缺陷检测的NEU-DET数据集.NEU-sda里有6种的典型钢材缺陷数据,共有1 800张像素大小为200×200的灰度图像.本文按照7∶3比例将NEU-sda分为训练集和测试集.这些缺陷存在如下难点:首先,同类样本的缺陷之间存在着很大的形状差异,如图3(a)所示,划痕缺陷特征存在垂直划痕、水平划痕以及斜划痕;其次,同一缺陷图像中灰度变化不一,如图3(b)和(c)所示,这主要是由于光线和钢材材质的变化带来的影响;再次,如图3(d)~(f)所示,不同缺陷类型的样本之间具有相似的特征.总之,NEU-sda数据主要存有两个挑战,即同类缺陷的样本在表面上存有很大的区别(尺寸、数量及灰度),而不同类缺陷的样本具有相似的特征.这些问题无疑对表面缺陷图像的分类和检测造成了困难.
在针对NEU-sda训练集数据扩充的过程中,设置:同类多样本融合的随机样本数量参数k=2,如式(1)和(2)所示;同类中的每个缺陷样本仅参与一次融合处理.

图3 NEU-CLS数据集的缺陷样本示意Fig.3The illustration of defect samples in the NEU-CLS dataset
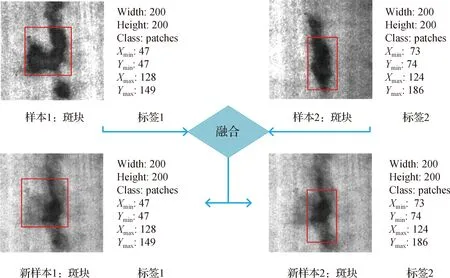
图4 NEU-DET数据集中的两个斑块缺陷样本及标签的融合Fig.4The fusion of two patches defect samples and labels in the NEU-DET dataset
实际上,这也就意味着NEU-CLS训练集中的每两个样本可以扩充为一个新样本.另外,如图4所示,当扩充NEU-DET的训练集用于缺陷目标检测时,可以将每两个样本扩充为两个相同新样本,并将这两个新样本的标签设置为两个原始样本分别对应的标签.这样可以将用于表面缺陷检测的NEU-DET训练集数据量翻倍.
最终,将原始数据和扩充数据输入到普通的图像分类网络和TensorFlow的目标检测网络中用于模型训练,并与卷积生成对抗网络(DCGAN)和循环一致生成对抗网络(CycleGAN)扩充的数据比较.由于无法保证这些生成方法扩充数据中的缺陷特征类型和准确位置信息,所以仅将本文方法、生成方法以及原始数据在表面缺陷图像分类任务上进行比较.并进一步在表面缺陷图像检测任务上,验证本文方法的有效性.所有的实验都是在Ubuntu16系统中,Anaconda的Tensorflow-GPU计算框架下,使用多个NVIDIA GeForce GTX 1080 GPU完成的.
2.2 评价指标
针对扩充的图像数据采用直接性评价和间接性评价两种方式,其中,直接性评价包括主观定性评价和客观定量评价.客观定量评价利用峰值信噪比(peak signal to noise rate,PSNR)和结构相似性(structural similarity,SSIM)[21].
为了进一步评价扩充数据在实际任务中的作用,将扩充的工业钢材表面缺陷图像应用在图像分类和图像检测任务中.
在图像多分类中,其准确率(Aaccuracy)按下式计算:
Aaccuracy=(S1+S2+…+Sk)/Sall,
(10)
其中,S1是第1类样本预测正确的个数,S2是第2类样本预测正确的个数,Sk是第k类样本预测正确的个数,Sall是参与预测的所有样本个数.
在图像目标检测中,多类别平均目标精度(mean average precision,MAP)计算如下:
(11)

图5 在NEU-std中不同方法扩充缺陷图像的结果Fig.5The results of defect image augmented by different methods in NEU-std
其中,n是类别个数,mAP是每个类别对应的平均目标精度,即召回率(R)和精确度(P)曲线下表示的面积(area under curve,AUC),P和R按下式计算:
(12)
(13)
其中,tp为检测出的正确目标数量,fp为误检测的目标数量,fn表示漏检测的目标数量;即tp+fp为检测出的目标总数,tp+fn为真实的目标数量.
2.3 实验结果与分析
本文将从直接性评价和间接性评价两个角度对实验结果展开分析.随机选择了不同方法所扩充的6类钢材表面缺陷图像,并与原始图像进行比较.图5中方框标记的是缺陷特征及对应区域放大180%的结果.如图5第1行所示,DCGAN扩充的划痕缺陷图像背景区域与原始图像相差过大,而且缺陷特征也明显变形;虽然CycleGAN可以扩充类似的缺陷,但是其背景的灰度等级明显差异过大;本文方法不仅能够扩充灰度背景一致的缺陷图像,而且还能够产生相似的缺陷特征.如图5第2行所示,本文方法扩充斑块缺陷图像中的缺陷与原始缺陷特征大小及形状类似,并且还有一致的背景,但是DCGAN扩充的缺陷尺寸过大,CycleGAN扩充的缺陷特征偏小,散乱不成块并布满整幅图像,并且其背景区域出现密集点状的异常特征.
如图5第3行所示,DCGAN扩充的破裂缺陷图像表面粗糙,CycleGAN扩充的图像表面光滑均匀,但都未能与原始缺陷特征相似,而本文方法扩充图像的背景区域与原始图像一致,缺陷特征虽然不够明显,但是有原始缺陷特征相似的特性.如图5第4行所示,为了扩充轧入氧化皮缺陷的图像,由于生成模型的固有缺陷,所以DCGAN和CycleGAN生成的图像中都出现了网格和未知的缺陷特征,本文方法可以扩充不够明显但相似的缺陷特征.
如图6所示,在表面夹杂和表面斑点缺陷图像扩充中,DCGAN和CycleGAN扩充的缺陷图像的背景信息差别较大,而且生成的斑点和夹杂缺陷特征明显与原始特征不相同.而本文方法扩充的缺陷图像在背景和缺陷特征上都有很好的效果.最后,从所有的表面缺陷图像扩充结果中可以看出,本文方法不仅能在表面缺陷图像中扩充与原始缺陷类型一致的新缺陷特征,而且还能在整体背景上维持与原始图像的最大相似性.
为了进一步衡量本文方法的实验效果,从PSNR和SSIM两个方面来定量分析不同方法扩充图像的质量.如表2和3所示,在大部分的表面缺陷扩充图像中,本文方法扩充缺陷图像的PSNR和SSIM值超过了其他方法,这说明本文方法扩充的图像与其他方法扩充的图像相比,具有较小的失真和较高的相似性.另外,从本文方法的物体结构属性与原始图像相似度更高可知,HFDA扩充图像中的缺陷特征与原始缺陷特征更相似.
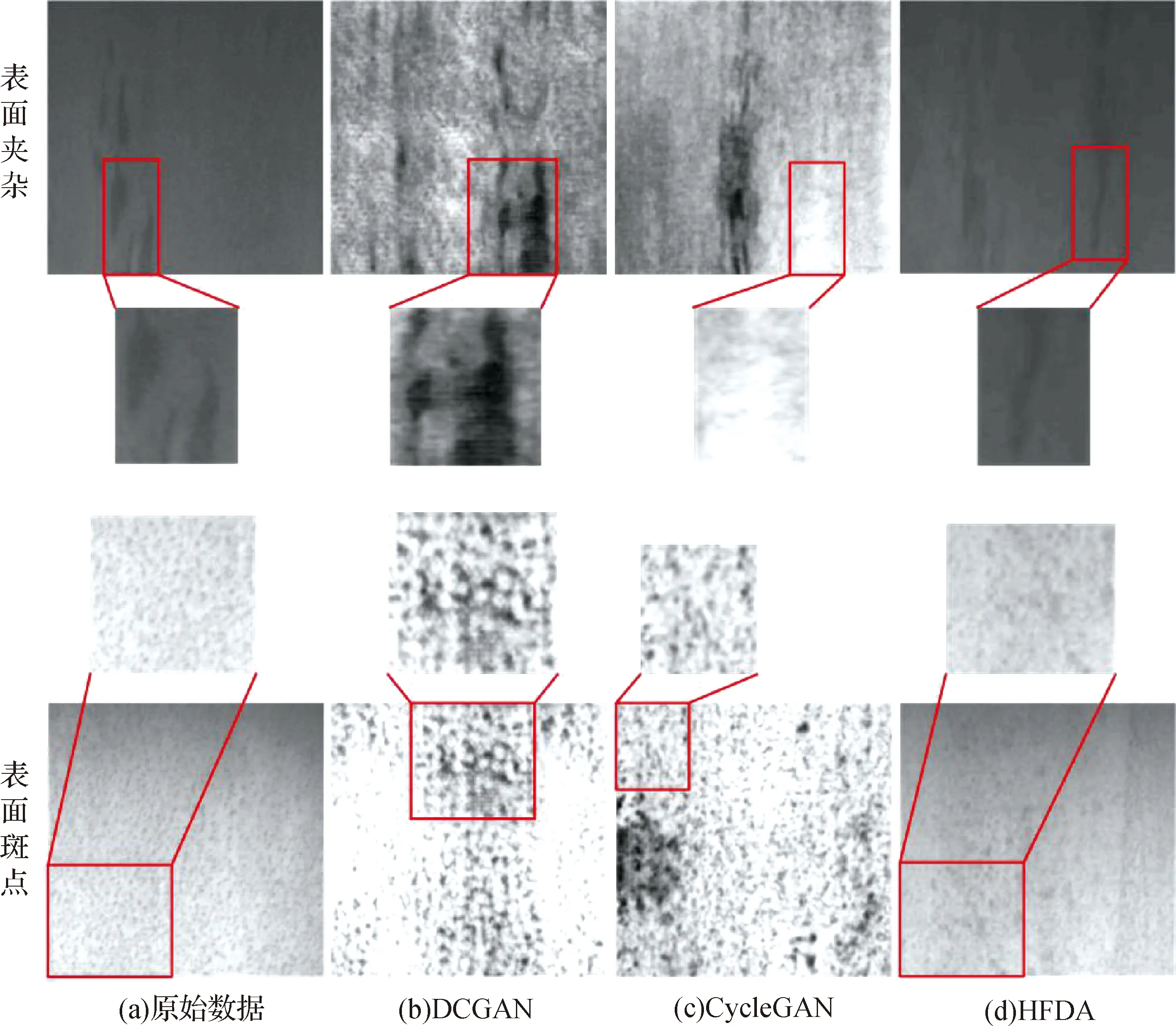
图6 在NEU-std中不同方法扩充表面夹杂及斑点缺陷图像的结果Fig.6The results of inclusion and pitted surface defect image augmented by different methods in NEU-std
但是,对于表面斑点图像,如图6(a)和(d)所示,因为表面斑点的缺陷特征形态相比于其他5类缺陷较小,那么在本文方法对表面斑点样本特征进行定义、提取、扩充及融合的过程中,小尺寸的缺陷特征容易被覆盖,最终导致生成的图像中包含此种缺陷类型的有效特征信息较少.所以,本文方法HFDA生成数据的PSNR和SSIM值相比于其他方法的数据值较低.

表2 在NEU-sda中不同方法扩充图像的PSNR结果Tab.2 The PSNR results of image augmented by different methods in NEU-std

表3 在NEU-sda中不同方法扩充图像的SSIM结果Tab.3 The SSIM results of image augmented by different methods in NEU-std
扩充工业表面缺陷图像的主要目标是解决工业表面缺陷图像数据量不足和类别不平衡的问题.因此,需要将不同方法扩充的缺陷数据应用在表面缺陷图像分类和检测任务中来间接性地验证本文方法的有效性.如图7所示,将原始缺陷数据和不同方法扩充缺陷数据进行组合以丰富训练集,然后再分别输入到普通的表面缺陷图像分类网络中,得到不同训练阶段的分类准确率.从图7(a)可以看出,在初始训练期间,本文扩充方法所组合的训练集数据经过一轮的迭代训练后,测试准确率达到了100%,然而同批次的原始数据与DCGAN和CycleGAN方法扩充的组合数据的分类测试准确率在95%~97%之间.在模型参数进一步的优化过程中,缺陷图像分类的准确率进一步提高.但是,从整个训练过程来看,本文HFDA方法扩充的表面缺陷图像在缺陷分类中的性能超过了其他方法.
另外,为了进一步证明本文方法扩充数据的效果,将原始图像数据、本文方法扩充数据以及本文方法扩充数据与原始数据的组合进行了比较,如图7(b)所示.HFDA的表面缺陷图像分类准确率直接性地表明了本文方法对模型泛化性能的影响.表明本文的HFDA方法所扩充的数据更能够有效地提高表面缺陷图像分类模型的泛化性能,避免出现过拟合问题,减少了工业表面缺陷数据在缺陷分类任务中数据量不足和类别不平衡所带来的影响.
为了进一步验证本文方法的有效性,分别在原始数据、本文方法扩充以及本文方法扩充数据和原始数据的组合上开展表面缺陷图像检测任务,结果如图8所示.首先,图8(a)~(c)展示了在表面缺陷检测的过程中,处于标记的候选框和原标记框完全重合、重合度大于 0.75 以及重合度大于0.50条件下,不同数据集对应的多类别平均目标精度结果.在训练的初期,3种不同重合度的条件下,本文方法扩充数据前后的mMAP分别从0.17提升到0.23、0.14提升到0.19 以及0.39提升到0.48.总体上来说,在每一轮的迭代中,本文方法扩充的数据确实有效提高了原始数据训练的mMAP的结果.另外,如图8(d)~(f)所示,为了验证本文方法扩充的表面缺陷数据能够有效地包含各类大中小目标缺陷特征,在标记的候选框和原标记框完全重合的条件下,比较了表面缺陷检测的模型训练过程中的大中小3类目标缺陷检测的mMAP.图8(d)表明,在训练初期,较大目标缺陷检测mMAP从原始数据的0.25提高到了本文方法扩充缺陷数据组合的0.37,并且在后续训练优化过程中,本文方法的组合数据一直保持着较好的效果.图8(e)表明,在迭代优化中期,本文方法组合数据的中等目标缺陷特征检测mMAP为0.32,高于原始数据的0.25,总的来看,本文方法的有效性开始在中后期显现.最后,从图8(f)可以看出,在小目标缺陷检测模型训练过程中,虽然初期本文方法扩充缺陷数据组合的mMAP为0.27,高于原始数据的0.19,但是在中后期的优化过程中,本文方法和原始数据的mMAP都出现了波动,这说明小目标缺陷检测本身就有一定困难,以及在扩充缺陷数据的融合过程中,本文方法未能很好地保留和扩充小目标缺陷的特征.所以,本文提出的工业表面缺陷数据扩充的方法能够对原始表面缺陷图像中的中等和较大缺陷特征有更好的适应性.
3 结 论
针对工业表面缺陷图像数量不足和类型不平衡等问题,本文提出了基于同类融合的工业数据扩充算法.此算法扩充的数据不仅能够保持原有缺陷图像的同类特征,还能够在同一缺陷样本中扩充新的同类特征.与其他方法相比,本文提出的方法能更高质量地扩充表面缺陷图像.而且将不同方法的扩充结果应用在实际的表面缺陷图像分类和检测任务中比较,间接性表明本文方法扩充表面缺陷图像的有效性.

图7 在NEU-CLS中表面缺陷图像扩充的分类结果Fig.7The classification results of augmented surface defect images in NEU-CLS
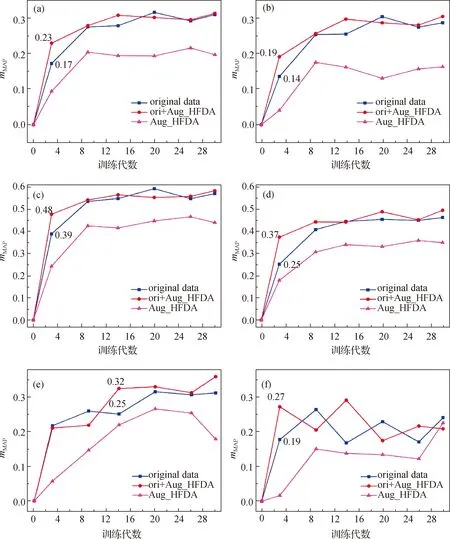
(a)完全重叠;(b)重合度>0.75;(c)重合度>0.50;(d)完全重叠,大物体;(e)完全重叠,中等物体;(f)完全重叠,小物体.图8 在NEU-DET中不同条件下的表面缺陷图像扩充的多类别MAPFig.8The multi-class MAP of augmented surface defect images under different conditions in NEU-DET
猜你喜欢
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
小学阅读指南·低年级版(2020年11期)2020-11-16
领导决策信息(2018年16期)2018-09-27
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
数学学习与研究(2017年3期)2017-03-09
少儿科学周刊·少年版(2015年3期)2015-07-07
新青年(2015年2期)2015-05-26
意林(2014年17期)2014-09-23
