
符号序列的预训练HMM 分类方法
2021-01-30 14:00:32陈炳鑫陈黎飞
南京大学学报(自然科学版) 2021年1期
陈炳鑫 ,陈黎飞*
(1.福建师范大学数学与信息学院,福州,350117;2.数字福建环境监测物联网实验室,福建师范大学,福州,350117)
符号序列(symbolic sequences)通常由有限个离散型符号按照特定的规律排列而成,当前许多数据挖掘的应用都基于符号序列的表现形式.例如在生物信息学中,由{'A','T','G','C'} 等代表不同碱基符号构成的基因即为一种符号序列.对基因进行分析是生物信息学极其重要的研究内容之一,生物学家对不同功能的基因进行分类,可以进一步研究同源序列之间的进化关系[1-2].由于符号序列长短不一,且具有特殊的时空顺序关系等特点,针对向量型数据的经典方法无法直接运用于符号序列分类任务中,因此对其进行挖掘仍存在挑战性.目前已经提出了多种序列的分类方法[3],其中基于距离的分类方法因其简单而得到了广泛的研究.
现有的序列距离度量方法大致可分两种:一种是序列对齐(alignment based)方法,如基于动态规划[4-5]或编辑距离[6]等思想进行符号序列的分类挖掘.尽管该方法常用于符号序列分类,但其通常基于较高的计算复杂度.另一种是非对齐(non-alignment)的方法,该方法采取表征学习[7-10]的手段构造出序列的特征.其中子序列法[3]是一种常见的方法,通过一些重要的短子序列来表示序列的特征.但该方法得到的是序列的局部结构特征,且生成的特征维度较高,同时子序列法得到的特征在某些情况下并非统计独立[11],降低了欧几里得距离等度量的有效性.相比之下,隐马尔可夫模型(Hidden Markov Model,HMM)的建模方法可以获取序列的全局结构特征(对应于HMM 的隐状态)[12].然而传统HMM建模方法从每条序列学习到的全局结构特征并不总是“对齐”的,即隶属于不同序列的状态没有对应关系,所以提取的特征在常用的距离度量下无法准确反映序列间的差异.
本文提出一种新的HMM 建模方法来解决不同序列的隐状态共享问题,采取了两阶段的训练过程,称为HMM 预训练(pre-training)方法.新方法使用状态转移矩阵表示序列,并基于共享状态下的概率距离度量来计算序列间的差异,最后运用近邻分类器对符号序列进行分类.在基因、语音、蛋白质三个领域的序列数据上进行了实验验证,实验结果表明,提出的分类方法能够取得较好的分类结果.
1 相关工作
首先约定全文使用的记号.令给定的符号序列集为D={O1,O2,…,OL},其中L为序列样本数.V={v1,v2,…,vM} 是构成符号序列的所有离散符号集合.用O=o1,o2,…,oT表示D中的每条序列,T为该序列的长度,ot∈V,t=1,2,…,T.不同的符号序列其T的值可能不一样,因此如何对序列间的距离进行有效度量成为符号序列分类的关键.当前基于距离的符号序列分类算法中使用的序列距离度量方法大致可分两类,代表性方法介绍如下.
第一类是子序列法.这类方法以n-gram(n-元组)为代表,其基本思想是提取序列中长度为n的子序列为特征[3,7].例如,对于序列“ATCTTG”,可首先提取出“ATC”“TCT”“CTT”和“TTG”等3-gram,再根据元组的频数将其表示为固定长度的特征向量,最后采用一些常用的度量方法计算序列间的距离进行分类.然而该方法所提取的元组仅体现了符号序列的局部结构特征,此外对符号数为M的序列其n-gram 数目将达到Mn维,这样的高维空间降低了常用距离度量的有效性.
第二类是基于概率模型的方法.其基本思想是为每条序列学习一个概率模型,进而利用概率模型之间的差异来衡量序列之间的距离.和子序列法相比,该方法能有效地捕捉序列的全局结构信息,同时获得比其较少的特征维度.其中HMM[13-14]和马尔可夫模型(Markov Model,MM)[15]是最典型的方法.和MM 相比,HMM 由于采用隐变量来刻画序列,更能反映序列的深层特征.本文提出的方法正是基于HMM 模型.
HMM 是一种概率生成模型,它描述一个由隐藏的马尔可夫链生成状态序列,再由状态序列通过随机过程生成观测序列的过程.通常,一个含有N个隐状态(用S1,S2,…,SN表示)的HMM模型可用一个三元组λ=(Π,A,B) 表示,形式定义如下[16]:
(1)A=[aij]N ×N是状态转移矩阵,表示从状态Si转移到状态Sj的概率,即:
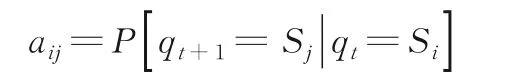
其中,qt表示时刻t的状态.
(2)B=[bjk]N ×M称作观测值概率矩阵,表示当状态为Sj时观测到符号vk∈V的概率(称为发射概率),即:
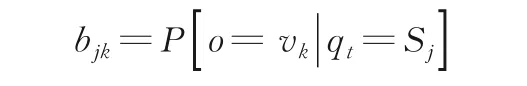
(3)Π={πi} 为初始状态概率分布向量,即:

其中,A和Π用于描述状态序列,B则描述观测序列.在经典HMM 建模中,一般先设定隐状态数N和模型的初始参数λ,进而为符号序列O训练一个令P(O|λ)取得最大值的模型,再基于模型的参数计算序列之间的相似性[12-13].此时,若根据状态转移矩阵的差异计算序列间的距离,则要求不同序列的状态是一一对应的,本文将这样的状态称为所有序列的“共享状态”.然而,经典的HMM 训练算法[16]不能保证状态间的这种对应关系,导致不同序列的状态转移矩阵不具备(直接的)可比性.
针对该问题,一些文献给出了解决方案.郭彦明等[12]对每条序列经HMM 训练后得到的状态转移矩阵进行特征值分解,对每个矩阵的N个特征值排序以体现状态之间的对应关系,并选择特征值对应的特征向量作为序列的特征.然而训练得到的状态转移矩阵通常是非对称的,特征值分解结果因含有复向量而变得难以计算.Blasiak and Rangwala[13]提出一种与主题模型结合的HMM 变体方法(HMM-variant),该方法维护一个唯一的观测值概率矩阵来求解最大化每条序列似然的模型,这样得到的“共享”状态难以准确刻画所有序列的共性特征.本文提出一种两阶段方法,在预训练的第一阶段中通过对所有序列的HMM 建模提取其共享的状态,在第二阶段中再基于共享状态经二次训练得到每条序列个性化的HMM.
2 基于预训练HMM 的序列分类方法
本节详细阐述基于预训练HMM 的序列分类方法.首先构造一种基于状态转移矩阵的序列概率距离度量,再给出预训练方法的过程,最后基于该概率距离度量用近邻分类器对序列进行分类.
2.1 一种新的概率距离度量由于在使用HMM 对序列建模时,得到的状态转移矩阵A在数值上能够体现出不同序列之间的差异[13],因此可将状态转移矩阵A作为符号序列的特征,如定义1 所示.
定义1 基于HMM 模型参数的符号序列特征表示.符号序列集D的特征表示为如下的矩阵集合X:
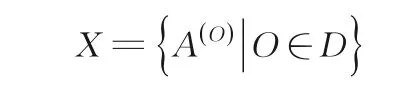
其中,A(O)表示D中每条序列O对应的HMM 状态转移矩阵.
基于定义1 的序列特征表示,序列间距离度量问题即可转化为概率分布之间的差异计算问题.分析可知,状态转移矩阵是一个概率矩阵,即:
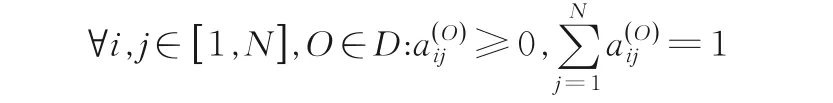
因矩阵的第i行向量可视为状态Si转移到其他状态的概率分布两个状态转移矩阵之间的距离即可用N个概率分布之间的差异来衡量,常用的方法有Kullback-Leibler(KL)散度和概率乘积核(PPK)等[17-18].鉴于KL 散度不满足对称性和三角不等式关系,因此并不是一种严格意义上的距离度量,这里选择基于概率乘积核定义序列间的距离度量.
设有两条符号序列O,O',对应第i个状态的状态转移概率分布分别为P(Si;O)和P(Si;O'),那么,它们的概率乘积核定义为:
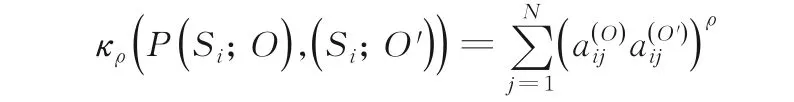
当ρ=0.5 时,上式称为Bhattacharyya 核[18],此时,可以基于概率乘积核定义Hellinger 距离函数:
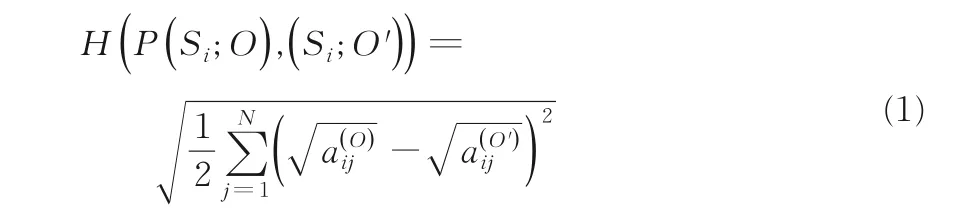
根据Hellinger 距离函数的定义可知,当两个状态转移概率分布相等时H(P(Si;O),(Si;O'))的值为0,否则差异越大其数值就越大.因此,两个状态转移矩阵内第i个状态Si之间的相异度用式(1)表示.由于定义1 已将状态转移矩阵作为序列的特征,故序列O和O'之间的距离即为两个状态转移矩阵A(O),A(O')之间的距离,而A(O),A(O') 之间的距离则可由每个状态之间的相异度组成,因此最终的序列间距离DSEHMM(O,O') 表示如下:
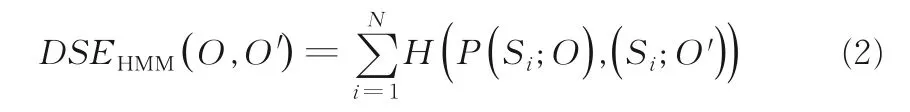
可以看出,基于HMM 的概率距离度量DSEHMM在符号序列的应用中有较好的可解释性.
2.2 预训练HMM 方法本小节描述了预训练HMM 方法.该方法分为两个阶段.第一阶段是序列共享状态的学习过程:给定模型的隐状态数N并对模型进行初始化,先为序列集D中的所有符号序列建立一个HMM,根据多序列HMM 中的Baum-Welch 算法可求得D的最优模型参数.经过第一阶段的训练后,D内的每条序列都拥有相同的模型参数,反映数据集中的每条序列都共享相同的隐状态.进一步,该参数在数值上可以体现出当前的序列数据集是由某个特定概率分布产生的,即以量化的形式刻画出不同数据集之间的差异,如在语音序列应用中,参数的物理含义代表某个人或某个音源.因此这个预先对序列数据集进行整体训练的阶段称为序列的HMM 预训练过程.第二阶段是序列的特征表示:为得到符号序列的特征,使每条序列可通过概率距离度量来区分彼此之间的结构差异,在对整体序列进行预训练后,根据共享的观测值概率矩阵(即在共享状态下),再单独为每条序列用HMM 进行学习,进而得到每条序列各自的状态转移矩阵.
上述方法称为符号序列的预训练HMM 方法,该方法可获得序列共享的状态.实质上该状态是从所有序列中学习得到共同的结构特征,因此序列数越多,所得到的共享状态将越准确.
预训练HMM 方法的过程描述如下:


2.3 基于概率距离度量的序列K 近邻分类本小节提出基于概率距离度量的近邻分类器,用于符号序列的分类.在众多的分类器中,由于KNN理论[20]简单,容易实现,且对异常值和噪声有较高的容忍度,因此将所提出的概率距离度量DSEHMM与KNN 结合,构造一种基于距离新度量的符号序列分类器(简称为DSEHMM-NN).下面给出基于概率距离度量的序列近邻分类算法.

步骤1 是学习序列的共享状态并得到特征表示.对于一个序列数为L且平均长度为T的序列集D,在预训练过程中用隐状态数为N的多序列Baum-Welch 算法对D进行学习的时间复杂度为O(LTN3).在序列的特征表示阶段,对D中每条序列进行训练总的时间复杂度为O(LTN2).综上,步骤1 总体的时间复杂度为O(LTN3)(忽略算法的迭代次数),这里,给定的状态数N是常数且数值通常较小.因此当N一定时,意味着预训练HMM 方法的时间与序列平均长度T和序列数目之间均呈线性关系.
3 实 验
本节通过实验在一些真实数据集上验证所提出的概率距离度量DSEHMM及预训练HMM 方法的有效性,同时与若干相关工作进行比较.
3.1 实验数据与实验设置实验在基因、语音和蛋白质三种不同领域的五个序列数据集上进行,分别用GS1,GS2,SS1,SS2,PS1 表示.其中GS1,GS2 两个数据集为基因序列,分别取自PBIL 的微生物同源基因数据库[21].语音数据集SS1,SS2 是由五个法语元音('a','e','i','o','u')音频转换而来的符号序列[22].PS1 为(α/β)8-barrel蛋白质序列[23].相较于基因序列,语音序列和蛋白质序列的符号数目更多.各数据集的详细信息如表1 所示.
实验使用三种符号序列分类方法作为比较对象.第一种方法是基于子序列的分类法,这里将n-gram 中的n设定为3.第二种方法是基于Markov 模型(MM)的分类法,参数根据Wei et al[21]的建议将阶数设定为1,第三种方法选择HMMvariant 分类法[13].首先检验预训练HMM 方法的有效性,在实验中对每种方法提取的序列特征都使用1-NN(即设定K=1)进行分类.其次评价所提出的概率距离度量,将DSEHMM-NN 与欧氏距离度量下的1-NN 作对比.所有方法在分类精度上均以Macro-F1 作为评价标准.
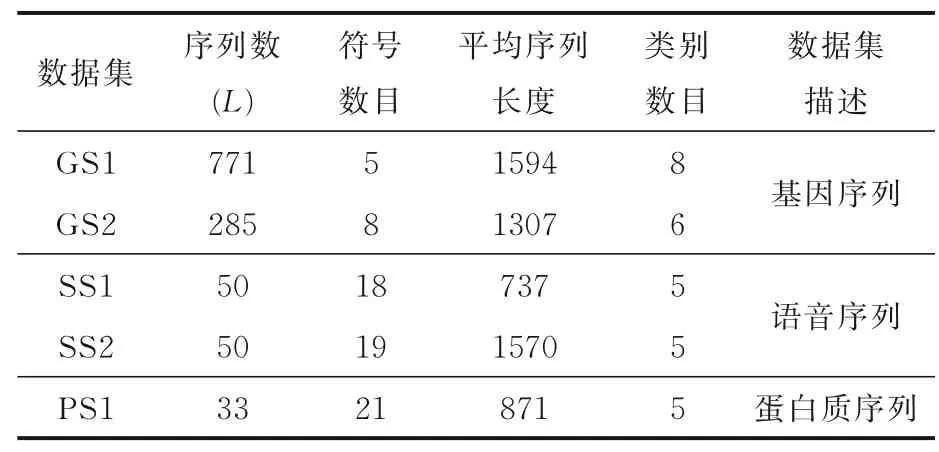
表1 实验使用的数据集相关信息Table 1 Information about the datasets used in the experiment
3.2 分类性能评估实验采用五折检验法.首先将每个数据集通过随机抽样的方式平均分为五个子集.接着每次轮流选择其中一个作为训练集,剩余的四个为测试集.分别为每个数据集进行20 次五折检验法,获得100 组实验结果.表2中给出三种类别的数据集在不同表征方法下用近邻分类器得到的平均分类精度,结果用“平均值±标准差”的形式给出.
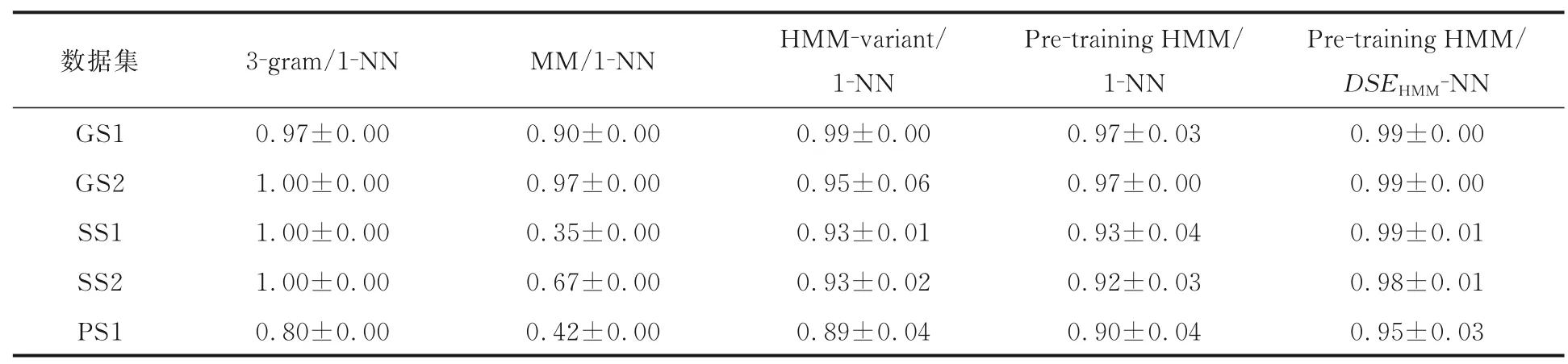
表2 符号序列集上不同方法得到的分类结果Macro-F1 指标对比Table 2 Macro-F1 of the classification results yielded by different methods on the symbolic sequence sets
从表2 可以看出,提出的预训练HMM 方法在三种不同类别的数据集上均能有效表示序列的特征,在语音序列和蛋白质序列上的分类精度明显优于基于Markov 模型的分类法;与子序列分类法和HMM-variant 分类法相比,在所有类别的数据集上均能取得相当或者较高的分类精度.其次,结合了概率距离度量DSEHMM下的预训练HMM 方法所得到的分类精度在所有的数据集中略有提高,这个结果表明该距离度量方法能较好地刻画在预训练HMM 方法下符号序列之间的差异.同时在实验中发现,和蛋白质序列相比,表1所示的基因序列和语音序列由于数量更多,两者的分类精度也更高,说明当数据集较少时,通过预训练的方法得到的共享状态只能获取序列集的部分结构特征,容易出现“欠拟合”现象,无法较为准确地反映序列集的信息.因此这种预训练HMM分类方法并不适用于序列数量较少的数据集.
3.3 预训练数据对序列特征的影响隐状态数是HMM 的一个重要参数.段江娇[24]的模型选择理论表明,HMM 模型的隐状态数N越大,模型的精度就越高.然而在实际建模过程中模型的隐状态数较难确定,而用状态转移矩阵A作为序列特征表示时其特征维度为N×N,当隐状态数N过大时,必然增加分类器的计算量.
为研究预训练数据对序列特征的影响,在实验中设置N为2~20,选择了基因和语音两种类别的数据,以近邻分类器的分类精度为评价标准进行分析.在预训练的过程中采取增加具有相同序列数的同类别数据进行,实验结果如图1 所示.可以看出,当隐状态数超过一定阈值时,该方法下的分类效果趋于稳定,甚至出现下降的情况,继续增加隐状态数只会使训练时间增加,导致模型的性能降低.其次,从图中观察到一个有趣的现象,增加预训练数据后与只使用较少数据进行预训练得到的分类精度相比虽无较大提升,但在状态数低时便可得到较高的分类精度,这表明提出的预训练方法能降低序列特征表示的维度.同时还发现,增加预训练数据后的模型稳定性更好.
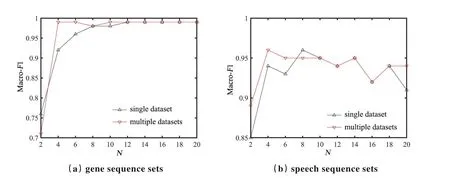
图1 基因序列集(a)和语音序列集(b)上Macro-F1 值随状态数(N)的变化Fig.1 Change of Macro-F1 with various numbers of states (N)on the gene sequence sets (a)and speech sequence sets (b)
4 结论
本文在HMM 的基础上,首先定义了一种序列距离新度量.其次,为得到不同序列在HMM隐状态共享下的状态转移矩阵并将其作为序列的特征,提出一种两阶段的预训练方法.最后在三种不同类别的数据集上用近邻分类器进行验证.实验的结果表明,和现有的一些序列分类方法相比,预训练HMM 分类方法可用较低的特征维度取得较好分类精度.
下一步工作将研究新方法以确定HMM 的最佳状态数,并考虑把“预训练HMM 方法”推广到聚类等无监督应用中,进一步检验该方法的性能.
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
幼儿园(2021年6期)2021-07-28 07:42:14
小学生学习指导(低年级)(2019年11期)2019-11-25 07:31:48
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
小学生导刊(2018年34期)2018-12-18 01:53:14
小学生导刊(2017年13期)2017-06-15 20:29:38
山东青年(2016年3期)2016-02-28 14:25:55
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
天津科技大学学报(2015年4期)2015-04-16 04:55:11
