
基于改进的半监督阶梯网络SAR 图像识别
2021-01-30 14:01:10高春永柏业超
南京大学学报(自然科学版) 2021年1期
高春永,柏业超,王 琼
(南京大学电子科学与工程学院,南京,210093)
合成孔径雷达(Synthetic Aperture Radar,SAR)具有全天候、全天时、大幅宽、高分辨等多种优点,并有一定的地表穿透能力,SAR 图像被广泛应用到海洋监测、环境检测、灾害检测和军事等方面[1-2],因其可发挥其他遥感方式不具备的独特优势,越来越受到世界各国的重视.
SAR 图像目标识别是分析和解译SAR 图像的重要环节,主要包括图像数据预处理、特征提取以及分类器的设计.SAR 图像存在大量的相干斑噪声,严重影响SAR 的图像质量,给后续的图像目标识别带来巨大的挑战.预处理是在尽可能保留图像的原始信息的同时,对图像进行滤波和去噪[3];特征提取的目的是从每个图像中提取具有鉴别性的特征,将提取的特征输入已经训练好的分类器进行分类识别.传统SAR 图像特征提取方法是提取图像的高维特征输入训练好的分类器中,而降维方法主要包括线性判别分析(Linear Discriminant Analysis,LDA)[4]、主成分分析(Principal Component Analysis,PCA)[4]、t分布随机邻域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE)[5]等,分类器有支持向量机[6]、随机森林[7]、K 最近邻域[8]以及决策树[9]等.随着深度学习的不断发展与应用,将深度学习应用到图像识别分类成为一大热点.深度学习分有监督学习、半监督学习和无监督学习.监督学习的图像样本是带有标签的数据,根据训练的结果调解分类器.目前主流的监督学习算法是卷积神经网络(Convolutional Neural Networks,CNN)[10-12],它将二维图像作为网络的输入,经过卷积层、池化层及全连接层等操作后,自动从图像中提取抽象的特征,并通过权值共享大大减少权值参数数量,从而减小网络的训练复杂度.无监督学习的数据是无任何标注的图像样本,即没有任何先验信息,通过机器自己学习进行分类,主要包括PCA、局部线性嵌入方法等,算法网络主要包括自编码、稀疏自编码、降噪自编码等.半监督学习的输入目标图像是少量带有标签的数据样本,其主要思想是通过利用数据分布上的模型假设来建立学习分类器对未标签图像样本划分标签.半监督学习需要解决如何利用已标签样本和未标签样本这一问题.随着新理论的出现以及文本分类、计算机视觉和自然语言处理新应用的发展,对半监督学习的应用也更加广泛和深入.在半监督学习成为热门领域之后,利用无类标签的图像样本提高学习算法的识别准确度以及加快学习速度的算法不断出现,涌现出大量改进的半监督学习方法.Nigam et al[13]将最大期望算法和朴素贝叶斯算法相结合,通过引入加权系数来动态调整无类标签的数据样本的影响,提高了分类准确率.Zhou and Goldman[14]提出基于协同训练的改进算法,该算法不需要充分冗余的视图,仅利用两个不同类型的分类器即可完成学习目标.Shang et al[15]提出一种新的半监督学习算法,能解决有类标签图像样本稀疏问题以及无类标签图像样本成对约束的问题.
本文提出一种改进的半监督阶梯网络的SAR 图像目标分类识别算法:首先将半监督阶梯网络和卷积神经网络相结合,在半监督阶梯网络解码器中使用卷积网络代替全连接网络,对图像降噪和深度特征提取,最后完成图像重构.为解决数据集样本不均衡的问题,提高网络的泛化性,对阶梯网络中各类别所占损失函数的权重进行调节,对少数分布不均衡的训练样本增大损失函数权重以改善数据集样本数量不平衡的问题.实验结果显示,改进后的算法在SAR 图像十类目标与四类目标上的分类识别率均远高于原算法,且该算法的识别性能与数据增强后的算法识别性能相当,但处理过程更简单,体现了该算法的优越性.
1 半监督阶梯网络模型
半监督阶梯网络是将阶梯网络在无监督阶梯网络的基础上与监督学习网络相结合来进行目标识别分类.半监督阶梯网络在获得编码最高层特征后使用全连接感知器对含有标签的输入数据进行监督训练,通过计算预测标签和真实标签之间的损失来获得有监督损失函数;通过无噪声通道各层数据与解码器各层数据构建无监督损失函数.有监督损失函数与无监督损失函数相加作为整个网络的损失函数,通过训练使网络损失函数达到最小.
阶梯网络训练模型类似降噪自编码,因阶梯网络中解码器和编码器间存在横向连接,所以网络中的每层解码器对同一层的编码器数据都要去噪和解码,同时恢复同层编码器丢失的部分特征信息.由于解码器不能恢复数据的全部信息,因此每层都会产生相应的损失分别为l层(0≤l≤L,L为阶梯网络层数)的原始样本和估计样本,阶梯网络的训练目标就是使每层叠加的总损失函数最小.
阶梯网络包含两层半监督阶梯网络,如图1所示,在原阶梯网络的顶层加入有监督损失函数.每层都对最后的损失函数有影响,通过训练每层的编码器及解码器来学习降噪函数由于损失函数需要有噪声和无噪声,因此网络中编码器需要运行两次,分别包含有噪声路径和无噪声路径.由于每层编码器网络和解码器网络之间存在横向连接,网络中的高层细节信息可以留给底层的网络结构来表示.

图1 半监督阶梯网络结构图Fig.1 The structure diagram of semi-supervised ladder network
1.1 编码器使用具有修正的线性单元全连接网络作为编码器用于监督学习,对除输入层以外的每个预激活单元进行批量归一化(Batch Normalization),其中包括网络的最顶层,目的是通过减少协移来改善收敛以及防止因减少去噪成本而使编码器输出为常数的情况.对于l=1,…,L,批量归一化表示为:
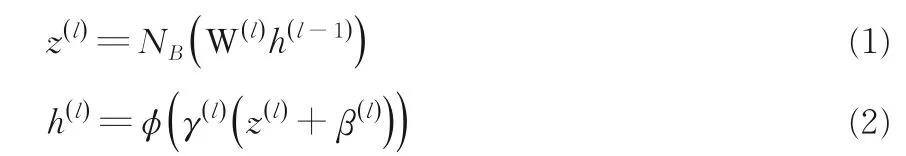
其中,h(0)=x表示输入SAR 图像.
NB表示一个分量的批量归一化,如式(3)所示:

如图1 所示,阶梯网络包括有噪声和无噪声两个路径,有噪声路径生成无噪声路径生成z(l)和h(l).在每层的批量归一化后为输入加各向同性的高斯噪声n.
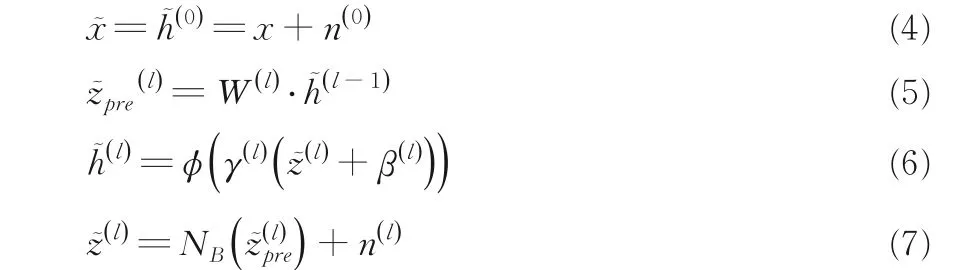
监督学习的损失函数是输入图像x(n),输出噪声标签t(n)匹配概率负对数的平均值,如式(8)所示:
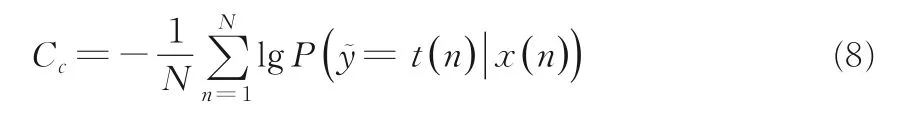
在解码器网络中,原网络使用全连接层对编码器隐藏层数据特征进行提取,通过批量归一化后使用参数法对高斯潜在变量去噪.在降噪过程中,降噪函数g被应用来同时计算z(l+1),最后进行结果的批量归一化:

其中,矩阵V(l)与编码器中W(l)的转置维度相同,且矩阵u(l)与z(l)的维度也相同.
1.2 解码器解码器中无监督学习损失函数是每个神经元的均方重建误差.批量归一化有很多优点,但它会在有噪声路径和无噪声路径上产生噪声,从而使降噪函数产生一定偏差.网络中选定zpre作为降噪目标,且在损失函数中选择批量归一化后的z(l),过程如下所示:

其中,μ和σ分别是批量标准化的均值和方差,将zpre批量标准到z就可以重构得到SAR 图像.无监督降噪损失函数可以表示为式(13):
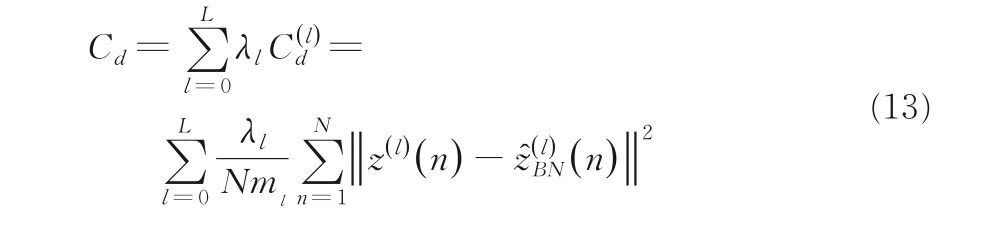
其中,ml表示每一层网络的宽度,N表示训练样本数量,超参数λl决定去噪损失函数的乘数.模型中使用后向传播算法训练参数W(l),γ(l),β(l),V(l)来优化网络总损失函数C=Cc+Cd.
2 基于卷积神经网络的SAR 图像去噪和特征提取
全连接网络在特征提取时会丢失数据的位置信息,从而降低提取特征的参数敏感度,无法更好地恢复同层编码器丢失的特征信息.由于其全相连的特性,该网络容易造成数据训练的过拟合,从而降低网络的泛化性能.
针对全连接网络在解码器网络特征提取以及图像去噪方面存在的弊端,本文提出使用CNN 代替全连接层对数据特征提取,能更好地完成图像重构.和全连接网络相比,CNN 在图像特征提取以及SAR 图像去噪方面有更大优势,主要表现为CNN 属于局部连接网络,且其具有局部连接和全局共享的特性,因此训练过程中大量减少了网络训练参数.CNN 中的每个神经元只对局部图像进行感知,再将局部信息综合来获得全局信息.CNN 在图像特征提取过程中,通过训练不同卷积核的参数,就可以自动提取目标图像的深度特征,更好地恢复数据,完成图像重构.因此,CNN 能在有效抑制SAR 图像相干斑噪声的基础上更精准地保留SAR 图像的细节结构信息.
本文的CNN 解码器的结构如图2 所示,共有五层卷积层,各卷积层参数如图所示,所有卷积层步长(Stride)均为1,经过CNN 最终重构建出64×64 的图像.

图2 卷积神经网络结构图Fig.2 The structure diagram of CNN
为了更好地体现解码层中CNN 在SAR 图像去噪和特征提取方面的优越性,分别在原网络以及改进后的模型对图像可视化.由于真实SAR图像不可避免地存在相干斑噪声,本文采用光学图像模拟SAR 图像训练网络.选择MSTAR4 数据集中的一个测试图像样本进行可视化,如图3所示.利用原始图像(图3a)和SAR 图像的相干斑噪声特性,得到带噪声的仿真SAR 图像(图3b),将仿真带噪声图像样本分别输入已经训练好的原网络和改进后的网络中,分别经过两种算法降噪,最终输出图像(图3c 和图3d).

图3 两种算法在图像样本去噪前后可视化对比Fig.3 The visual comparison of before and after denoising the image sample
为了衡量本文算法去除SAR 图像噪声的效果,分别计算两种算法下峰值信噪比(Peak Signal to Noise Ratio,PSNR).PSNR是一种评价图像质量的客观标准,PSNR越大表明图像去噪的效果越好.结果显示,原算法的PSNR为18.09,本文算法的PSNR为19.27,证明本文算法和原算法相比,去噪后失真较小,说明CNN 在SAR 图像去除相干斑噪声效果以及图像特征提取上确实优于原算法,为CNN 在SAR 图像目标识别上优于原网络提供了理论支撑.
3 实验与分析
采用MSTAR 数据集十类目标和四类目标进行实验来测试改进前后半监督阶梯网络性能.选取俯仰角为17°的图像样本作为训练集,选取俯仰角为15°的图像样本作为测试集.针对数据集不均衡的问题,同时采用旋转和翻转操作对训练图像进行数据增强,并通过实验测试算法在增强后的数据集上的网络性能.表1 给出十类目标原始和数据增强后的训练样本和测试样本.实验同时测试四类目标BMP2,T72,BTR60 和T62 在两种算法上的分类识别率.所有图像样本均为在原始图像中心裁剪64×64 像素模块得到.
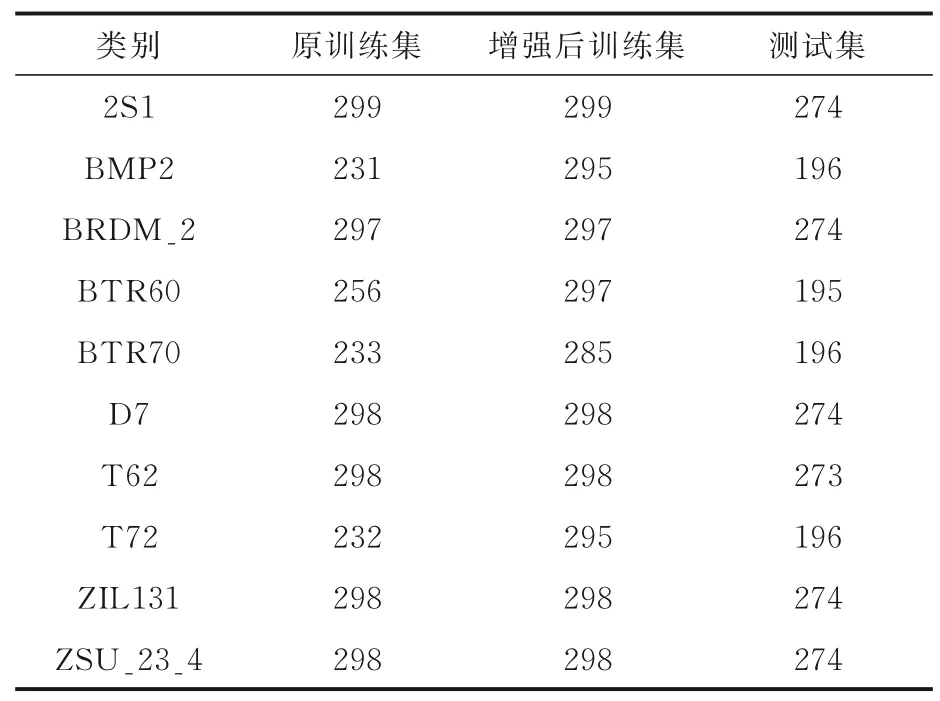
表1 十类目标数据增强前后训练集与测试集Table 1 Training sets and testing sets before and after enhancement of ten kinds of target data
分别选取训练集数量总和的10%,20%,50%以及100%作为标记样本,在原算法以及本文算法中进行监督训练.图4 为十类目标在标记样本数为10%时分类识别混淆矩阵,其中图4a 为SSLN 算法在十类目标下的分类识别混淆矩阵,图4b 为本文算法在十类目标下的分类识别混淆矩阵.表2 为十类目标在标记样本数10%时算法改进前后在不同数据集下的分类识别率.可以看出,使用本文算法后,十类目标中的大多数类别识别率高于原算法,仅有少数类别识别率稍低于原算法,这是由于本文算法以提升平均识别率、提升网络泛化性为目标,个别类别准确率会稍有下降.表3 为十类目标和四类目标在标记样本数10%时算法改进前后的平均分类识别率,表中数据包括分类准确率以及准确率的波动误差,实验数据为多次实验后取平均值所得.从表中数据对比得出,在原数据集下,本文算法平均分类识别率远高于SSLN 算法的平均分类识别率,且网络泛化性能更好.虽然本文算法在十类目标上的分类识别率略低于十类目标数据增强后算法的分类识别率,但总体性能与之相当,且处理过程更加简捷,体现了本文算法的优越性.

图4 十类目标在标记样本数10%时不同算法下分类识别混淆矩阵图Fig.4 The proposed algorithm classifies and identifies confusion matrix graphs under different datasets when the number of labeled samples is 10%
实验还得到标记样本率为20%,50%,80%以及100%时各类目标在不同算法下的分类识别率.如图5 所示,监督率和识别率关系大致可以使用折线图表示,可以看出,改进后算法的识别准确率优于原算法.另外,为了提高网络泛化性,本文算法将数据集不均衡跟网络结合所取得的效果与数据集增强后的结果相当,而且处理简捷方便,也证明了本文算法的优越性.
4 结论
本文提出改进的SSLN 的SAR 图像分类识别方法,使用卷积神经网络代替解码器中全连接网络对编码层输入的数据特征提取且更利于去除SAR 图像相干斑噪声,完成图像重构.针对十类目标训练集数量不均衡的情况,本文结合阶梯网络,调节训练层中各类别损失函数权重以提高网络的泛化性能.实验针对不同算法网络测试得出,使用改进的SSLN 算法在公开数据集MSTAR 上的分类识别准确率优于原算法,并增强了网络的泛化能力.改进后的半监督阶梯网路具有更高的分类精度,同样适用于其他少数标签样本的分类识别.
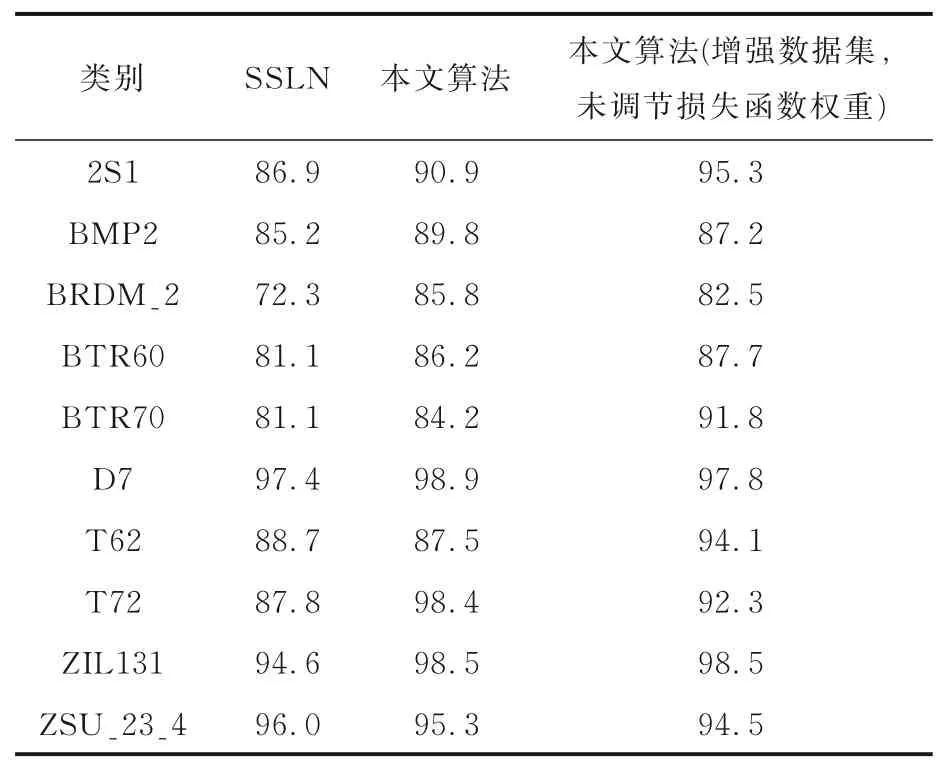
表2 十类目标标记样本数10%时算法改进前后在不同数据集下的分类识别率Table 2 The rates of classification and recognition at different datasets before and after the algorithm is improved,when sample size of ten target markers was 10%
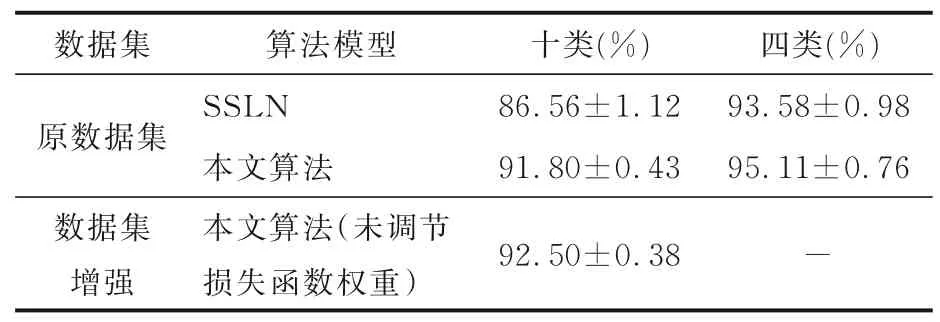
表3 两类目标标记样本数为10%时算法改进前后在不同数据集上的分类识别率Table 3 The classification and recognition rates of the two kinds of target markers on different datasets before and after the algorithm is improved when the number of target markers is 10%
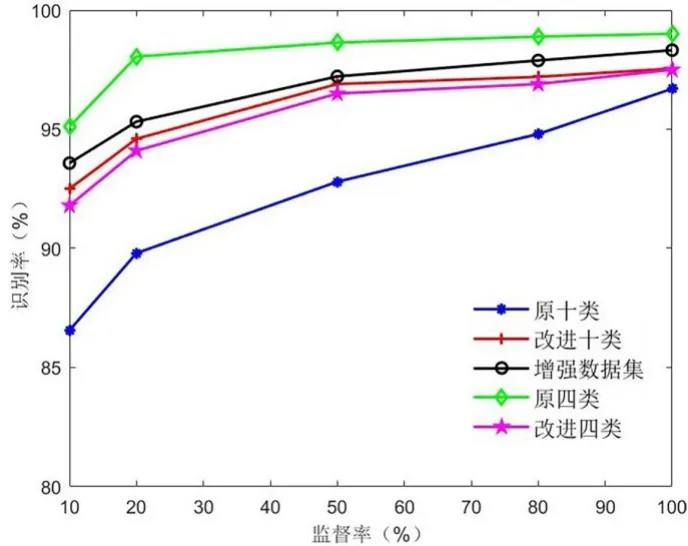
图5 各类目标分类准确率与监督率分布图Fig.5 Distribution of classification accuracy and supervision rate of various targets
猜你喜欢
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
小学生导刊(2016年5期)2016-12-01 06:02:46
幸福(2016年9期)2016-12-01 03:08:50
发明与创新(2016年6期)2016-08-21 13:49:38
中国交通信息化(2016年2期)2016-06-06 07:28:02
噪声与振动控制(2015年4期)2015-01-01 07:08:05
