
异构Flink 集群中负载均衡算法研究与实现
2021-01-30 14:00:48汪志峰赵宇海王国仁
南京大学学报(自然科学版) 2021年1期
汪志峰 ,赵宇海* ,王国仁
(1.东北大学计算机科学与工程学院,沈阳,110169;2.北京理工大学计算机学院,北京,100081)
近年来,由于数据量呈指数式增长,处理大数据[1]的方式也发生了很大变化,迄今已经历三代引擎的改进:第一代以Hadoop[2]为代表,利用MapReduce[3]进行大数据处理;第二代以Spark[4]为代表,是基于RDD(基于内存计算)的微批流处理框架;第三代是以Flink 为代表的面向流,保证Exactly Once 的实时流处理框架.Flink[5]的计算平台可以实现毫秒级延迟下每秒处理上亿次的消息或者事件;同时,Flink 还提供一种Exactlyonce[6]的一致性语义,保证数据的正确性,使Flink大数据引擎可以提供金融级的数据处理能力.高吞吐、低延迟的性能使Flink 成为目前流处理的首选.与此同时,各个公司处理大数据的方式也发生了很大变化,例如阿里巴巴、滴滴出行、美团都大规模使用Flink 集群,阿里巴巴还开源自己的Blink 给Flink 社区,给Flink 带来了更好的性能优化以及方便的SQL 环境.如图1 所示的流程中,上游是事务处理、日志、点击事件等,经过Flink 的流处理到达下游;下游是处理之后的数据存储到数据库里或直接被应用所利用.Flink 在其中可以提供低延迟、高吞吐、Exactly Once 的处理.
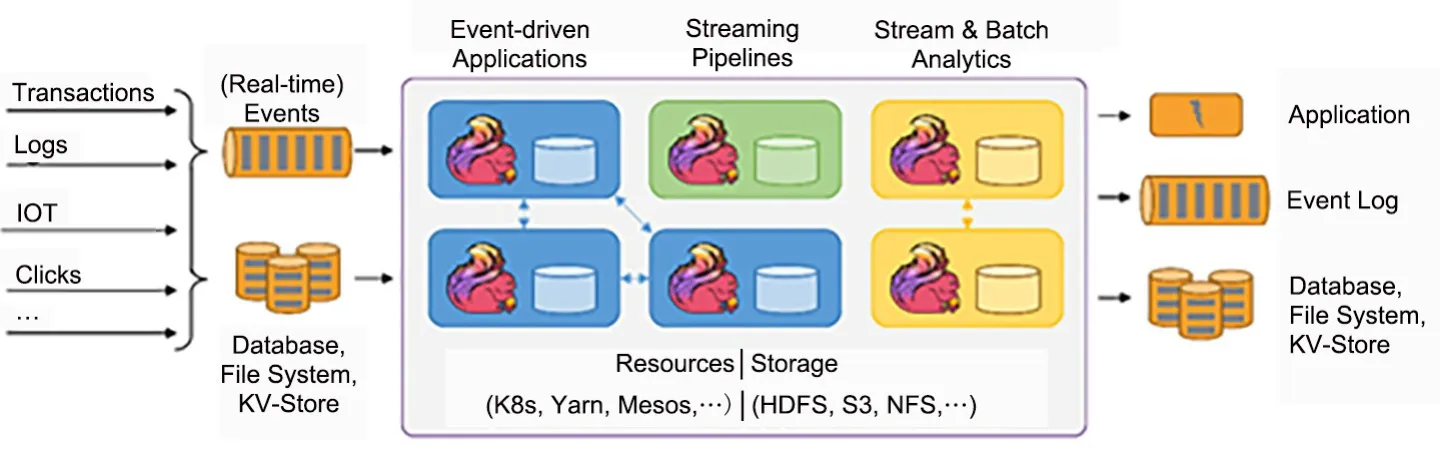
图1 Flink 应用场景Fig.1 Flink application scenario
任务调度是Flink 很重要的功能.Flink 通过JobManger 任务调度器管理Slot,把任务分配到合适的Slot 等待TaskManager 执行.Flink 的任务调度图如图2 所示,Flink 集群启动后首先会启动一个JobManger 和一个或多个TaskManager,Client提交任务给JobManager,JobManager 再调度任务到各个TaskManager 去执行.在这个过程中TaskManager 把心跳和任务处理信息汇报给Job-Manager,TaskManager 之间以流的形式进行数据传输.在集群运行的过程中,如果流任务失败则利用快照加检查点的形式恢复,如果批任务失败则重新开始.在把任务分配到具体的Slot 的过程中,优先选择符合Local 属性的节点.如果有Slot-SharingGroup 限制,则在SlotSharingGroup 里再创建一个SimpleSlot;如果有CoLocationGroup 限制,则必须在同一个CoLocationGroup 里创建一个SimpleSlot;如果没有上述限制,则从Slot 集合里挑一个.

图2 Flink 任务调度图Fig.2 Flink task scheduling diagram
所以,Flink 的默认调度策略是轮询,每个任务需要去可用的Slot 集合顺序选择一个Slot 分配给这个Task.在调度过程中,属于同一个Task 的所有SubTask 不能分配在Slot 里面,因为任务需要分布式运行,所以不同的子任务必须分配在不同的Slot 里.
Flink 默认的调度策略把所有节点认作同等性能(这里的性能指CPU 的处理能力、内存等),但在实际的集群搭建部署过程中,集群中的节点可能性能相差较大.若在这种异构的集群中采用轮询的调度策略就可能因为没有考虑每个节点的不同负载能力,使性能较差的节点和性能较好的节点被分配同样的任务.性能较差的节点负载过多的Task 会影响整体Job 的运行效率,使集群的吞吐降低、延时增加,延长整个Job 的运行时间,因此在异构集群中根据集群各个节点的不同性能调整任务的分配成为提升异构集群整体性能的关键.基于此,本文提出自适应负载均衡算法,提升系统的吞吐量、降低延时、减少Job 的运行时间,使集群的整体性能有较大的提升.
本文的主要贡献:
(1)通过对Hadoop 和Spark 的研究发现,在异构集群中应用默认的轮询调度策略没有考虑节点的处理性能,导致集群执行效率的下降.本文通过实验证明Flink 系统中也会出现这种现象,即异构Flink 集群中可能存在由于任务分配不均衡导致Job 完成时间被拖长、吞吐量降低、延时增加.
(2)提出异构集群中平滑加权轮询任务调度算法(Smooth Weighted Polling Task Scheduling,SWPTS).根据集群中每个节点的性能权重Ew,按从大到小的次序,依次给每个节点的Slot 分配SubTask.与此同时,记录节点当前的权重Cw,降低Cw最大的节点来避免有效权重大的节点被连续多次选中,从而使集群在开始调度时就能保持负载均衡.
(3)提出基于蚁群算法的任务调度算法(Task Scheduling Algorithm Based on Ant Colony Algorithm,ACTS).在集群运行过程中,当集群资源的使用高于预设值ε时则使用ACTS 寻找全局最优任务分配方案,使每个SubTask 被分配到合适的Slot 上,让整个集群的效率达到最高.
(4)在真实数据集和人工数据集上进行了实验分析和验证,结果表明,在Flink 集群里应用SWPTS 和ACTS 确实对缩短Job 运行时间、提高吞吐量、降低延时有很好的效果.
1 相关工作
在流计算框架中任务调度是很重要的一个模块,负责把Task 调度给Slave 的Slot 执行,不同的流计算引擎尽管实现方式不同,但实现的功能都是把任务根据某种算法分配给指定的Slave 执行.
Hadoop 提供可插拔的任务调度器,它根据用户的需求选择合适的调度方案,并可以随时切换.Hadoop 的任务调度算法有三种.(1)FIFO 调度器[7].FIFO 调度器是最开始被集成到Hadoop里的,Task 按FIFO 的顺序进入大工作队列,Job-Tracker 从工作队列里取最先到达的Task.这种调度策略没有考虑作业的优先级和作业的大小,但这种策略最容易实现,也是有效率的.(2)公平调度器(Fair Scheduler)[8].公平调度是一种分配作业资源的策略,目的是让所有的作业随着时间的推移都能平均地获取等同的共享资源,所有Job 享有相同的资源.(3)计算能力调度器(Capacity Scheduler)[9]支持多个队列,每个队列可配置一定的资源量并采用FIFO 调度策略.为防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占的资源量进行限定,优先执行占用最小、优先级高的作业.
Lee and Chung[10]提出一个针对Hadoop 的截止时间约束调度算法,使用统计学方法来测量数据节点的性能,并基于该信息创建检查点来监视作业的进度;根据每个检查点的作业进度,算法将任务分配给不同的作业队列.Kc and Anyanwu[11]提出基于工作执行代价模型来满足用户规定的数据处理截止日期的调度算法,这些工作执行代价包括map 和reduce 两个阶段的运行时间、map 和reduce 输入数据的规模和分布.
Spark 是当下十分流行的流计算框架.默认情况下,Spark 调度器按照FIFO(先进先出)[12]的形式来调度任务,每个工作被分为多个“阶段”(如map 和reduce 语句).对于所有可用的资源,第一个工作的优先级最高,其任务即被启动;之后是第二个,依次类推.如果集群不需要队列头的工作,后面的工作将被立刻启动;如果队列头的工作很大,则后面的工作可能被大大推迟.Spark 后来的版本模仿Hadoop 的公平调度器[13]也添加了公平的调度策池,不同的工作可以被分到不同的组,每组对应一个任务池,不同的任务池设置不同的调度选项(权重).
Mao et al[14]提出用机器学习领域的增强学习和神经网络,在无须手动设置最小工作完成时间的情况下得到一种在指定工作负载情况下的调度算法,在这个过程中设计可扩展的RL 模型,并发明RL 训练方法处理连续到来的随机Job.Ren et al[15]设计了第一个分散感知调度器Hopper,为了提供可拓展性和可预测性,Hopper 被设计成一个分散的Job 调度器,它把资源分配给Job 的同时也能预测拖慢工作进度的子任务,从而采取合理算法降低系统的延时.
Storm 里也有很多对Storm 的调度器进行改进的工作.Peng et al[16]在2015 年提出R-Storm 资源感知调度器,通过增加最大化资源利用率来提升总吞吐量,同时最小化网络延迟,在任务调度时R-Storm 可以满足软资源和硬资源的限制以及最小化组件之间的网络通信代价,在标准的Yahoo基准测试下吞吐量提高30%~47%,CPU 利用率提高69%~350%.Chen and Lee[17]发现Storm 默认使用轮询的算法来分配任务,这对异构计算环境不是最佳,于是提出G-Storm 调度算法.GStorm 利用集群节点GPU 来加速整体性能,实验结果表明,与原始Storm 调度算法相比,G-Storm在轻量级和高负载拓扑上可以实现1.65 倍至2.04 倍的性能提升.
目前针对异构集群的负载均衡算法没有通用的高效算法,大部分还是通过感应集群中某种资源来作出动态调度,或利用集群的其他计算能力(如GPU)来负载均衡,通常存在三个问题:(1)这些算法只从单一的性能指标去实现负载均衡,没有综合多个性能指标来思考;(2)虽然其中有加权轮询的算法,但这种加权在选择节点时没有考虑平滑,导致有些权重大的节点被连续选中,造成短时间内局部负载过重,影响节点效率;(3)这些算法只考虑负载均衡,没有考虑集群负载均衡算法后已使用的资源高于设定的阈值时的处理.
针对以上问题,本文改进和实现如下:(1)考虑CPU 利用率、内存利用率和总内存这三个关键性能指标,而非单一指标,并且动态地监控三个性能指标来作出调度决策;(2)不仅考虑多个性能指标的加权,而且在加权过程中进行平滑处理,即避免让权重大的节点连续被选中造成局部短时间内负载过重;(3)在集群已使用的资源高于设定阈值后采用ACTS,能够在一定的迭代次数内得到全局最优任务分配方案,按照这个方案调度任务来重新负载均衡,也能使集群处于最佳状态.
本研究考虑Flink 集群CPU 利用率和内存利用率等性能指标,在初始调度阶段采用SWPTS,在集群已使用资源高于设定阈值的情况下采用ACTS,经过实验验证,能够在Job 的运行时间、延时、吞吐量等性能指标上有明显提升.
2 基本概念
定义1 内存使用率(Mu)这是描述计算机的重要性能指标之一,可描述集群中已使用的内存占用总内存的比重.定义如下:

其中,memfree表示剩余的内存,memtotal表示总内存大小.
定义2 CPU 使用率(Cu)它描述CPU 当前被占用的情况,使用率越大表示CPU 越忙,在这种情况下CPU 很难空出时钟周期运行即将提交该节点的任务.定义如下:
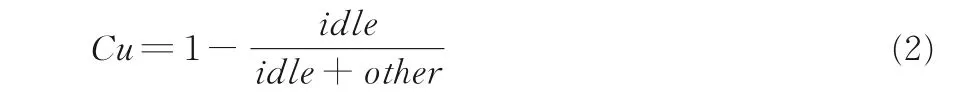
定义3 有效权重(Ew)这是在初始调度时根据CPU 使用率、内存使用率等性能指标得到的一个综合权重,可衡量节点的总体资源使用情况.计算方式如下:

定义4 当前权重(Cw)它可以用来衡量运行过程中每个节点被选中的权重,每经过一次调度当前权重都会发生变化,可以用来挑选最合适的节点.定义如下:

其中,Cwlast表示上次调度时的有效权重.
定义5 任务执行时间(timeMatrix[ i ][ j ])它表示任务i分配给节点j所需的时间,在算法执行的初始时刻初始化.定义如下:
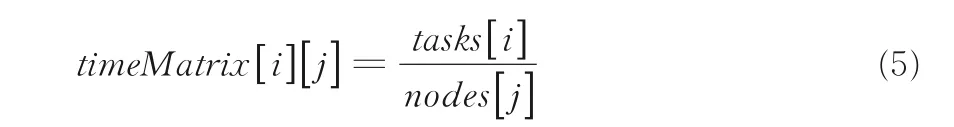
定义6 最大信息素概率(maxphe)它主要用来确定蚂蚁的临界下标(indexbound),即确定一个临界蚂蚁编号,在这个编号之前的蚂蚁选择信息素最大的节点从而把任务分配给该节点,而这个节点之后的蚂蚁选择一个随机的节点,把任务分配给该节点.定义如下:

其中,pheMatrix[i]是节点i的信息素.临界下标的定义如下:

3 算法描述
本节详细介绍集群资源监控、SWPTS 和ACTS.集群资源监控主要负责监控集群中每个节点的CPU 使用率、内存使用率,并把这些数据通过Http 协议[18]发送给Flink 的JobManager 作为性能数据来确定权重.与传统的负载均衡算法不同,SWPTS 和ACTS 是基于集群资源的动态负载均衡算法.
3.1 集群资源监控集群资源监控主要负责为调度器提供性能数据,Flink 集群的JobManager根据性能数据来确定每个Slave 的权重,调度器利用权重来实现整体的调度负载均衡.集群资源监控整体的架构如图3 所示,每个slave 节点利用正则表达式解析/proc 目录下的cpuinfo 和meminfo 这两个文件得到每个时刻CPU 的使用率和内存使用率,然后通过Socket 通信把数据发送给Master.Master 中的Redis[19]完成性能数据的持久化处理,同时通过Web 技术对外提供Http 接口,Flink 集群可以通过RPC 调用获取集群中各个节点的实时性能数据.

图3 资源调度架构图Fig.3 The diagram of resource scheduling architecture
3.2 SWPTS 总览初始化bestInstance和total-Weight.其中bestInstance用来保存最后选中的最好的DataMetric,它在每次循环过程中都记录当前节点为止Cw最大的DataMetric.totalWeight则在每次循环过程中累加每个DataMetric的Ew,循环结束时,totalWeight保存所有节点Ew的和.
在每次循环过程中,每个DataMetric的Cw都会加上它自身的Ew,并用total累加当前Ew.如果当前DataMetric的Cw大于bestInstance的Cw,则记录bestInstance到目前为止具有最大Cw的DataMetric.
在循环完成之后,找到当前的最优的Data-Metric,它有最大的Cw.为使该DataMetric不被重复选中,需要降低它的Cw.即用bestInstance的Cw减去total,并返回这个最优的bestInstance.具体见算法1.

SWPTS 主要是在Job 运行的初始阶段把任务分配给TaskManager 的Slot.为减少频繁Rpc带来的时间影响,在初始的调度过程中JobManager 没有一直请求集群资源监控的性能数据,而是在第一次请求后缓存数据,在后续任务到来时SWPTS 利用初始缓存的性能数据,再用ACTS选择一个节点的Slot 分配给Task.
以一个有三个Slave 节点的集群为例,假设weight(Slave1)∶weight(Slave2)∶weight(Slave3)=3∶1∶2,集群的前六次调度如表1 所示.
可以看到,Slave1 的权重最大,被调度的次数为3;Slave3 的权重次之,被调度的次数为2;Slave2 的权重最小,被调度的次数为1.上述调度体现了加权,即权重大的节点被调度选中的次数也多;同时也体现了平滑的特点,权重大的节点没有被连续选中,而是被间断地选中.综上所述,SWPTS 能使集群调度负载均衡且避免权重较大的节点在局部短时间内负载过重.
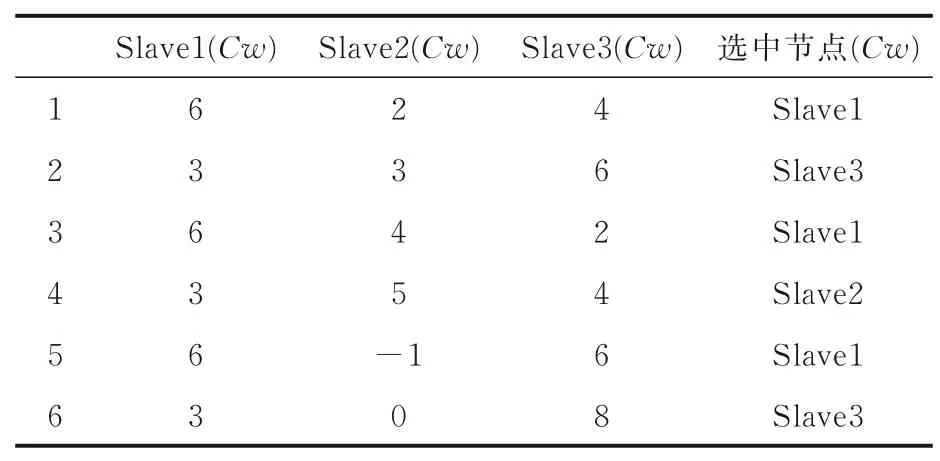
表1 Flink 任务调度过程Table 1 Flink task scheduling process
3.3 ACTS 总览SWPTS 主要用在初始调度,但当集群中已使用资源高于设定阈值ε时,如果不考虑全局的最优调度,则资源有可能进一步降低,负载持续不均衡.此时采用ACTS,可以得到一种全局的任务分配方案,按照这个方案把Task分配给指定的Slot 运行能使集群处于最佳运行状态,此时集群资源的利用率最好.
蚁群算法(Ant Colony Algorithm)是一种模拟蚂蚁觅食行为的模拟优化算法,由意大利学者Dorigo and Gambardella[20]于1991 年首先提出,并首先使用在解决TSP(旅行商问题)[21]上.蚁群算法的基本原理如下:
(1)蚂蚁在随意行走的路径上释放信息素[22],这些信息素有利于后面的蚂蚁继续寻找路径.
(2)碰到没走过的路口就随机挑选一条路走,同时释放与路径长度有关的信息素.
(3)信息素浓度与路径长度成反比.后来的蚂蚁再次碰到该路口时,选择信息素浓度较高的路径.
(4)随着蚂蚁觅食过程中信息素的不断累积,最优路径上的信息素浓度越来越大,让后续的蚂蚁更多地选择信息素浓度高的这条路径.
(5)一段时间后,蚁群找到最优觅食路径,是一条全局的最短路径,即距离食物源最近.

图4 蚁群算法示意图Fig.4 Ant colony algorithm
ACTS 就是根据蚁群算法改造的.经典的蚁群算法是寻找一条最短路径,而ACTS 的目标是寻找一种全局最优分配方案,使Task 的完成时间最短、资源使用率最好、集群重新负载均衡.ACTS 以Task 的运行时间为衡量信息素增减的标准,由每只蚂蚁把每个任务分配给对应的节点.由于分布式并行的特点,每只蚂蚁取运行时间最长的Task 所需要的时间作为Job 的完成时间.
算法的整体框架如算法2 所示,主要包括三部分:第一部分是初始化任务集合,第二部分是初始化信息素矩阵,第三部分是迭代搜索.

步骤1,初始化任务矩阵.timeMatrix[i][j]表示任务i分配给节点j所需的时间.根据任务集合tasks 和节点集合nodes,应用式(5)计算每个任务在每个节点完成需要的时间.表2 是一个示例,Task[ 1 ],Task[ 2 ],Task[ 3 ]对应的数据规模大小分别是10,8,6;Node[ 1 ],Node[ 2 ],Node[ 3 ]对应的处理能力分别为2,2,1;每个任务在每个节点完成需要的时间如表2 所示.

表2 初始化任务矩阵Table 2 Initialization task matrix
步骤2,初始化信息素矩阵.将负载均衡调度过程中的一次任务分配看作一条路径,因此pheromoneMatrix[i][j]表示将任务i分配给节点j这条路径的信息素浓度.初始化信息素矩阵,将所有值置为1,因为初始时所有的路径都没有蚂蚁选择,默认为1.
步骤3,迭代搜索.这是ACTS 最关键的一步,由三部分组成:迭代分配任务、计算每只蚂蚁的任务处理时间、更新信息素.整个迭代搜索的算法框架如算法3 所示.

算法3 中,第2 行表示初始化Path_AllAnt,它是一个三维数组,用来存保第iteratorCount次迭代过程中第antCount只蚂蚁将i个任务分配给j个节点处理.第4 行是初始化Path_OneAnt,表示第antCount只蚂蚁将i任务分配给j节点处理.第5~8 行表示循环每个任务,为每个任务通过任务分配函数asignTask 分配到一个节点node,给相应的Path_OneAnt,Path_AllAnt赋值.第9 行和第10 行是计算本次迭代中所有蚂蚁的任务处理时间,并将所有蚂蚁的任务处理时间加入总结果集resultData.第11 行是更新信息素.最后返回resultData.
在整个蚁群算法中,共进行iteratorNum次迭代.每次迭代都会产生当前的最优分配策略,即“局部最优解”,迭代的次数越多,局部最优解就越接近全局最优解.但迭代次数过多会造成调度器大量的时间和性能开销,无法满足海量任务的调度;而迭代次数太少,则得到的可能不是全局最优解.本文采用固定迭代次数为100 次.
任务分配函数负责将一个指定的任务按照某种策略分配给某一节点处理.分配策略有两种:(1)按信息素浓度分配,即是将任务分配给本行中信息素浓度最高的节点处理.例如:当前的任务编号是taskCount,当前的信息素浓度矩阵是phe-romoneMatrix,则任务会分配给pheromoneMatrix[taskCount]这一行中信息素浓度最高的节点.(2)随机分配,即将任务随意分配给某个节点处理,一般根据蚂蚁的编号antNum来选择.boundPointMatrix[i]=5 表示编号为0~5 的蚂蚁在分配任务i的时候采用“按信息素浓度”的方式分配,即将任务i分配给信息素浓度最高的节点处理;而编号为6~9 的蚂蚁在分配任务i时,采用随机分配策略.
当阀门结构是非平衡式软密封单座结构时,阀芯导向在阀门套筒内且全行程导向,从而可以保证阀门打开的时候介质在阀芯侧向流动,该处阀芯外表面不参与密封。软密封阀芯镶嵌在阀芯体内,阀芯密封面在凹槽底部,阀座密封面使用的是一个凸台,两者接触时为平面密封。当阀门关到底部处于关闭状态时,阀座的凸起表面嵌入软密封环中,该处的密封材料变形包围住阀座凸起表面,由此确保可靠的密封效果,同时阀杆也不用承受过大推力。由于整个密封垫片镶嵌在凹槽内,可以使得阀芯阀座接触后的软密封材料PTFE变形得到有效控制,从而保证阀芯阀座在有效行程内密封可靠。
蚁群算法有三个问题需要注意:
(1)计算任务处理问题.由于Flink 集群里任务都是并行运行的,因此在计算任务处理时通常以最晚完成的任务的时间为整个Job 的完成时间.
(2)更新信息素问题.将所有路径的信息素降低m%,表示信息素的挥发;找出所有蚂蚁的最短路径,则该路径的信息素提升n%,表示该路径是最短路径,信息素不断提升.
(3)更新boundPointMatrix问题.bound-PointMatrix表示临界蚂蚁下标集合,在该下标之前的蚂蚁选择信息素浓度最高的节点分配,在该下标之后的蚂蚁选择随机一个节点分配,计算方式如式(6)和式(7)所示.
4 实验分析
本文的调度器及算法均已在Flink 中实现.通过修改Flink runtime 包下面的调度模块,可添加数据HTTP Api 数据访问和数据解析器.整个系统依赖Redis 和maskmonitor 性能监视应用.使用SWPTS 和使用默认调度算法的Flink 系统在延时、吞吐量、运行时间方面做了对比和分析,并在不同的数据集和不同并行度上进行了实验验证.实验使用Flink 自带的实例WordCount.由于临界资源阈值是个经验值,不同阈值效率对比如图5.根据图5 可以看出阈值为80%效率最高,因此本文实验默认阈值设定为80%.

图5 Flink 临界阈值效率对比Fig.5 Comparison of Flink critical threshold efficiency
4.1 数据集针对WordCount 使用真实数据集和模拟数据集.真实数据集是TPC-C[23],用九个表生成模拟五种事务处理,产生三个大数据集,模拟真实场景下的批计算.此外,自己写程序生成三个只包括字符串的模拟数据集,用以扩充实验测试.数据集的来源和规模如表3 所示.

表3 数据集规模Table 3 The size of datasets
4.2 实验环境及配置SWPTS 和ACTS 均基于Flink1.4.2,编程语言为Java.实验所用的集群硬件配置和参数如下:
实验环境:分布式集群由一台服务器和两台虚拟主机构成,两台虚拟主机模拟异构集群的效果,服务器主机为Master 节点,两台虚拟机为Slave 节点.
Master 节点的配置如下:CPU 为Intel(R)Core(TM)i7-6700,4 Core,主频3.40 GHz;内存为64 GB 2133 MHz;机械硬盘为WDC WD10 EZEX -08WN4A0 1 TB;编程环境为IntelliJ IDEA 2018,Maven,Git;操作系统为Ubuntu 16.04.5;Flink 版本1.4.2,JDK 版本1.8.0_151,Hadoop 版本2.7.5.
Slave1 的配置如下:CPU 为Intel(R)Core(TM)i5-4690,4 Core,主频3.50 GHz;内存为4 GB 2133 MHz;机械硬盘60 GB;编程环境为IntelliJIDEA 2018,Maven,Git;操作系统为Ubuntu 16.04.5;Flink 版本1.4.2,JDK 版本1.8.0_151,Hadoop 版本2.7.5.
Slave2 的配置如下:CPU 为Intel(R)Core(TM)i5-4690,2 Core,主频3.50 GHz;内存为2 GB 2133 MHz;机械硬盘60 GB;编程环境为IntelliJ IDEA 2018,Maven,Git;操作系统为Ubuntu 16.04.5;Flink 版本1.4.2,JDK 版本1.8.0_151,Hadoop 版本2.7.5.
4.3 实验结果及分析通过修改Flink1.4.2 的默认任务调度器为自适应任务调度器,新增SWPTS 和ACTS 两种负载均衡调度算法.在异构集群中不同的数据集下分别与Flink1.4.2 在运行时间、延时、吞吐量[24]方面做性能对比,可以看出改进之后的算法在三个方面都有所提升.
4.3.1 运行时间对比分析通常运行时间是一个可以让用户对比算法性能的最直观的指标.运行快说明算法节省了Job 的完成时间,加快了用户响应时间,对提升性能非常重要.SWPTS 和ACTS 能将任务尽可能多地分配给资源丰富的节点,应用到自适应任务调度器中能使资源丰富的节点更多地接收Task,比Flink 默认调度器的负载更均衡,运行时间也相应缩短.
在并行度为8 和16 时,在自己程序生成的数据集(图6)和TPC-C 数据集(图7)上进行对比实验,可以看到,应用自适应任务调度器(LoadbalanceFlink)之后的运行时间比默认任务调度器(NativeFlink)平均减少8%左右,这是因为前者将任务均匀分配,资源多的节点可以完成尽可能多的Task,缩短了整体的完成时间,而默认任务调度器让资源少的节点完成和其他节点同等的任务,拖慢了整体工作的完成进度.
4.3.2 吞吐量对比分析吞吐量(Throughput)指单位时间内由计算引擎成功处理的数据量,反映系统的负载能力.吞吐量常用于资源规划,也能协助分析系统性能瓶颈,从而进行相应的资源调整以保证系统达到用户要求的处理能力.

图6 Flink 运行时间对比(自定义数据集)Fig.6 Flink runtime on custom dataset
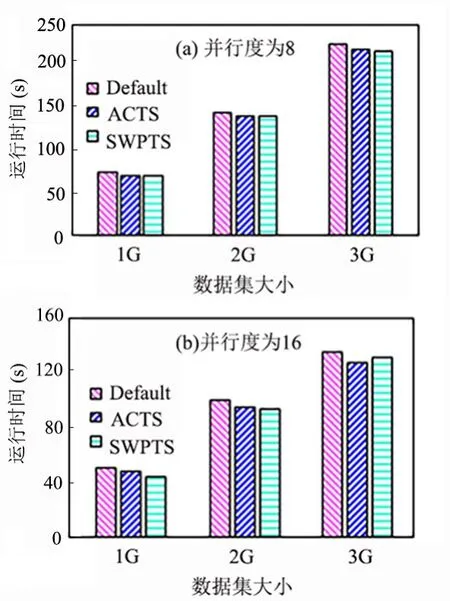
图7 Flink 运行时间对比(TPC-C 数据集)Fig.7 Flink runtime on TPC-C dataset
实验使用阿里巴巴提供的advertising 工具,它是标准流测试工具yahoo stream benchmark 的简化版.测试原理是随机产生两个广告流,把ad_id 相同的join 起来存放到Redis 里,通过单位时间内在Redis 读到多少条数据来计算吞吐量.计算如式(8)所示:

其中,currentNum代表当前读到的数据编号,即已经读到多少条数据;lastNum表示前一次读到的数据编号;currentTime表示当前时间,lastTime表示上一次的时间.
从实验结果(图8)可以看出,改进之后的Flink 自适应负载均衡算法比默认任务调度算法的吞吐量更高,原因同前,本文算法能使负载均衡,即资源多的节点负载较多的任务,则整个集群在单位时间内能完成更多的任务,吞吐量增大.
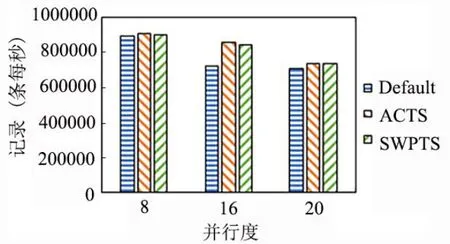
图8 Flink 不同并行度下的吞吐量对比Fig.8 Throughput of Flink with different parallelism
4.3.3 延时对比分析延时(latency)指数据从进入数据窗口的时间到真正被处理的时间间隔,单位为毫秒(ms),反映系统处理的实时性.金融交易分析等大量实时计算业务对延迟要求较高,因为延时越小,数据实时性越强.
实验使用阿里巴巴提供的advertising 工具,原理是随机产生两个广告流,把ad_id 相同的join起来存放到Redis 里.计算如式(9)所示:
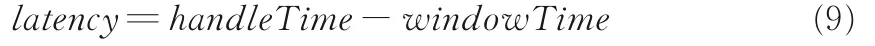
其中,handleTime表示某条记录实际被处理的时间,windowTime表示流里面该记录属于的时间窗口开始时间.
从实验结果(图9)可以看出,本文改进之后的Flink 自适应负载均衡算法比默认的调度算法延时更小,原因亦同前,本文算法能够实现负载均衡,使资源多的节点能负载较多的任务,则每个任务在被处理之前需要等待的时间也相应变短,即延时变小.

图9 Flink 不同并行度的延时对比Fig.9 Delay of Flink with different parallelism
上述在运行时间、吞吐量、延时三方面的实验表明:SWPTS 和ACTS 改变了任务的默认分配策略,可以尽量按动态资源的大小将任务优先分配给资源较多的节点,解决异构集群负载不均衡的问题.
5 总结
本文提出的自适应负载均衡算法由平滑加权轮询任务调度算法(SWPTS)和基于蚁群算法的任务调度算法(ACTS)组成.经过实验验证,在异构Flink 集群的环境下,自适应负载均衡算法的运行时间、吞吐量和延时与默认调度算法相比都有所提升.在运行初期,利用SWPTS 负载均衡,使得任务在初始分配的时候负载均衡.在运行过程中,当集群已使用资源高于设定阈值时,采用ACTS 寻找一种全局最优分配方案,也能重新均衡负载.等已使用资源低于设定阈值时,则继续采用之前的算法进行调度.
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
制造技术与机床(2019年4期)2019-04-04 12:22:06
测控技术(2018年7期)2018-12-09 08:58:00
电子制作(2018年11期)2018-08-04 03:25:40
少儿科学周刊·儿童版(2017年5期)2017-06-29 01:27:44
中国交通信息化(2017年3期)2017-06-08 06:09:28
学苑创造·A版(2017年3期)2017-04-27 13:17:17
知识就是力量(2017年2期)2017-01-21 18:29:36
信息通信技术(2015年6期)2015-12-26 01:16:54
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:45
