
基于Sentinel-2与机载激光雷达数据的误差变量联立方程组森林蓄积量反演研究
2021-01-29 08:18:48
中南林业科技大学学报 2020年12期
(中南林业科技大学 a.林业遥感信息工程研究中心;b.林业遥感大数据与生态安全湖南省重点实验室;c.南方森林资源经营与监测国家林业与草原局重点实验室,湖南 长沙 410004)
森林蓄积量是衡量森林质量、评价森林经营能力的关键指标,也是评价森林固碳能力的主要因子[1-2],因此实现森林蓄积量有效监测是一项至关重要的工作[3-6]。传统调查森林蓄积量的方法主要是地面实测,即利用所测量的单木参数结合当地的立木材积表对单木的材积进行计算,进而估算整个林分的蓄积量[7-8]。但该方法耗时费力,且效率较低。随着遥感技术地推广与应用,采用光学遥感影像结合地面抽样样地实测数据建立各种反演模型对森林蓄积量进行大尺度估测已逐渐成为森林蓄积量估算的主要手段。该方法主要是通过从遥感影像中提取与森林蓄积量相关的光学遥感信息,如植被指数、纹理特征等,建立特征变量与森林蓄积量之间的关系模型进行森林蓄积量反演[9-11]。其中植被指数是根据植被的光谱特性,将传感器获取的可见光与近红外波段进行组合而得到的,通过构建植被指数可以简单、有效和经验地度量植被生长状况,从而有效地反映区域植被与森林结构参数[12-13]。而纹理特征是以刻画图像中重复出现的局部模式与它们的排列规则的表现方式,从视觉特征上反映图像中的同质现象,纹理特征是在包含多个像素点的区域中统计计算得到的,它具有旋转不变性与较好的抗噪声、抗干扰性,对于图像的解译和特征地提取有着重要的作用[14]。使用光学遥感信息反演森林蓄积量的方法具有耗时短,效率高,且能提供多时态、多尺度、多维度的森林结构信息等特点[15-17]。
但是在使用光学遥感信息对森林蓄积量进行估测时,只能获取水平结构信息而无法获得垂直结构层面的信息,同时光学遥感影像中提取的光谱信息易出现饱和,导致对蓄积量估测的精度存在一定的限制[18-19]。LiDAR 是近年来快速兴起的一种主动式遥感技术,与传统的光学遥感相比,其优势在于LiDAR 发射出的激光脉冲能穿透森林冠层从而获取森林垂直结构信息,包括冠层形状、树木高度、枝叶剖面等。冠层垂直结构特征变量可以体现树木的生长状态和外在特征[20-21],因此在使用LiDAR 数据进行蓄积量、生物量等林分特征反演时,先对LiDAR 点云进行去噪、滤波等预处理,再从预处理后的点云中提取相关LiDAR 特征变量,最后使用提取得到的特征变量与林分特征建立反演模型[22-23]。但LiDAR 数据具有覆盖区域较小、成本高、数据处理量较大等缺点,不利于大尺度上的研究。因此将机载LiDAR 数据的垂直结构信息和光学遥感影像的水平结构信息结合起来,优势互补地进行研究是目前林业领域的热门研究方向[24-27]。然而目前在利用光学遥感特征变量与LiDAR 特征变量进行蓄积量反演研究中,大多都只是直接使用多种特征变量直接进行建模估测,当某种关键因子缺失时,则使用其他因子进行代替。误差变量联立方程组(Simultaneous equations of error variables,SEEV)方法是根据其他外生变量推测出关键因子变量作为内生变量即误差变量再去与其他变量进行建模估测,但联立方程组方法之前都只是建立模型,对研究区的蓄积量总体进行估计,很少与遥感影像结合生成研究区范围内的蓄积量空间分布图。因此研究以广西壮族自治区国有高峰林场的界牌、东升分场为研究区,借助地面调查样地数据,探索结合Sentinel-2 与LiDAR 数据的误差变量联立方程组反演整个研究区蓄积量制图的新方法,并与普通回归模型方法(General regression model,GRM)、随机森林和kNN 方法进行精度比较,从而验证新方法的有效性,并为森林蓄积量估测与连续分布制图研究提供实验参考与行之有效的思路。
1 材料与方法
1.1 研究区概况
研究区位于广西壮族自治区国有高峰林场中,地理坐标为108°05′—108°40′E,22°49′—23°10′N,主要经营树种为桉树、杉木等。地处亚热带,北回归线穿域而过,属于中温带半湿润大陆性季风气候,春季干旱少雨多风,夏季降水集中,气候温热湿润,秋季降温剧烈、多早霜,冬季寒冷干燥。研究区位置及样地分布如图1所示。

图1 研究区位置与样地分布Fig.1 Location and plot distribution of study area
1.2 数据源
1.2.1 地面样地调查数据
地面实测数据采集时间为2018年1月,采用分层抽样的方式在研究区内共设置164 块样地,其中20 m×20 m 的样地57 块,25 m×25 m 的样地8 块,25 m×50 m 的样地9 块,30 m×30 m 的样地90 块。在样地调查过程中,使用实时动态差分(Real - time kinematic,RTK)GPS 测定每个样地的中心坐标,对胸径大于5 cm 的树木,逐一测量其胸径(Diameter at breast height,DBH)、树高、冠幅、枝下高,并对胸径小于5 cm 的树木与枯死木进行计数(不参与计算蓄积量)。根据单木实测胸径和树高数据结合二元材积公式计算出样地级蓄积量值,再换算为公顷级蓄积量值。根据地面实测调查数据汇总成样地尺度的林分相关特征,包括林分密度(株·hm-2)、算术平均高(m)、平均胸径(cm)、蓄积量(m3·hm-2)。最后根据RTK 所获取的每个样地中心坐标与实测样地方向,统一样地尺寸,获得164 块方形样地(大小:20 m×20 m)与样地尺度实测林分特征参数,样地每公顷蓄积量计算结果及分布如表1所示,并随机提取99 块样地数据作为训练样本参与森林蓄积量反演,余下的55 块样地数据作为验证样本检验其蓄积量反演精度。
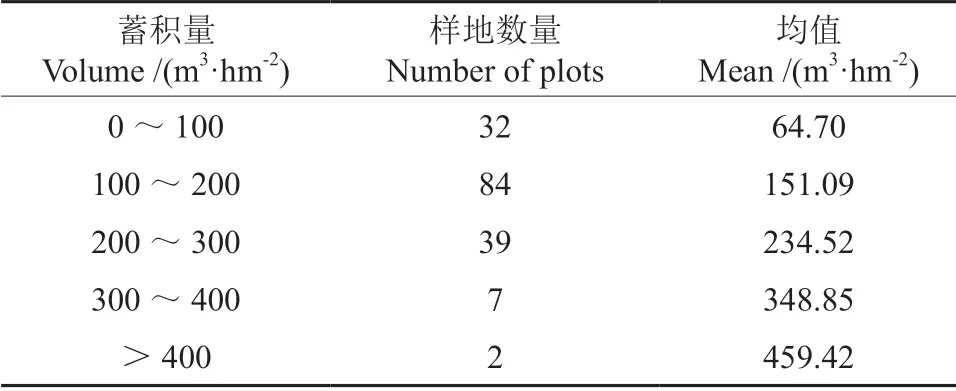
表1 样地蓄积量统计结果Table 1 Volume results of 164 plots
1.2.2 Sentinel-2 光学数据
研究以2017年12月获取的Sentinel-2 影像为数据源,使用其2~9 波段。Sentinel-2 是高分辨率多光谱成像卫星,携带一枚多光谱成像仪,用于陆地监测,可提供植被、土壤和水覆盖、内陆水路及海岸区域等,还可用于紧急救援服务。
利用ESA 官方发布的Sen2Cor 2.5.5 模块对获取的Sentinel-2 影像进行辐射定标、大气校正等预处理。为了更好地获取影像信息,将影像分辨率与样地大小匹配,在ESA SNAP 软件中将影像空间分辨率重采样至与样地大小一致。
对经过预处理后的Sentinel-2 影像进行多种植被指数变换与纹理信息提取,共提取277 个特征变量,分别为8 个单波段反射率,5 种常见植被指数包括归一化植被指数(Normalized difference vegetation index,NDVI)、土壤调节植被指数(Soil adjusted vegetation index,SAVI)、修改型土壤调整植被指数(Modified soil adjusted vegetation index,MSAVI)、差值植被指数(Difference vegetation index,DVI)、增强植被指数(Enhanced vegetation index,EVI),两波段比值植被指数56 个,三波段比值植被指数168 个,8 波段纹理信息变量包括数据范围(Data Range)、平均值(Mean)、方差(Variance)、信息熵(Entropy)和偏斜(Skewness)共40 个。
1.2.3 机载LiDAR 数据
研究使用的机载LiDAR 数据收集时间为2018年3月。遥感平台飞行高度为600 m,飞行速度为65 m/s,光束发散角为0.5 mrad,光斑直径约为0.3 m,返回波形记录的时间采样间隔为1 ns(约15 cm),脉冲发射频率为200 kHz,扫描频率为80 Hz,最大扫描角为±30°,点密度约为8.7 点·m-2,平均地面点距约为0.48 m。
为了获取更加准确的高度冠层模型,首先对获取的点云通过设定的高度阈值进行去噪处理,然后基于Kraus 滤波算法[28]结合中值滤波分离出地面点,最后由收集到的地面点插值生成分辨率为20 m×20 m 的数字高程模型(Digital elevation model,DEM)。收集去噪后的第一次回波点插值生成20 m×20 m 的数字表面模型(Digital surface model,DSM),利用DSM 减去DEM 获得研究区的CHM[29-30]。
1.3 蓄积量反演方法
1.3.1 变量选择
研究选用皮尔森(Pearson)相关系数对所获取的特征变量进行筛选,Pearson 相关系数可以用于描述Sentinel-2 遥感影像特征变量与地面实测数据之间的相关性。分别选择与蓄积量、样地算术平均高相关性较高的变量开展变量筛选,为了保证变量筛选的有效性,引入方差膨胀系数进行共线性分析。VIF 是衡量多元线性回归模型中复(多重)共线性严重程度的一种度量。它表示回归系数估计量的方差与假设自变量间不线性相关时方差相比的比值,VIF 越小,共线性程度越低。采用线性逐步回归对经过Pearson 相关系数筛选与共线性诊断后保留的显著变量进行筛选,最终保留的变量与CHM 共同作为反演蓄积量的建模因子与推测算术平均高的外生变量。
1.3.2 蓄积量反演
误差变量联立方程组是利用提取Sentinel-2 号的光学遥感特征与LiDAR 数据提取的高度特征变量作为外生变量去推算样地平均树高并作为内生变量,再使用内生变量与其他外生变量去反演蓄积量的一种方法。公式为:

式(1)中:TF 为纹理因子;Ⅵ为植被指数;C HM 为冠层高度模型;为样地算术平均高;V为样地单位面积蓄积量。
建立联立方程组模型分为两步,首先需要利用筛选出的外生变量推测出内生变量算术平均高,再利用得到的内生变量与筛选出的建模因子反演蓄积量。在建立联立方程组模型的过程中,每一步都可以选用不同的模型,因此在本研究中,共有4 种不同的联立建模方式,分别为MLR-MLR、logistic-logistic、MLR-logistic 与logistic-MLR 联立模型。
从4 种误差联立方程组模型中,选择反演效果最好的模型与普通回归模型(MLR、logistic)、随机森林、kNN 反演方法进行比较,分析不同方法的制图效果。
1.3.3 精度检验
采用留置样本的方式对蓄积量反演结果进行检验,选用决定系数(Coefficient of determination,R2)、校正决定系数(Adjust coefficient of determination,AdjustR2)、均方根误差(Root mean squared error,RMSE)与相对均方根误差(Relative root mean squared error,RRMSE)作为反演结果精度的评价指标。
2 结果与分析
2.1 变量选择
对Sentinel-2 影像共提取出277 个光学特征变量,经过相关系数矩阵计算,在0.01 水平上与蓄积量相关的特征变量共24 个,相关系数最高的5 个光学特征变量为SR537、SR547、SR536、SR527、SR546,相关系数分别为-0.24、-0.24、-0.24、-0.23、-0.23,说明绿光和植被红边区间波段组合得到的植被指数与蓄积量的相关性显著;在0.01水平上与样地算术平均高显著相关的特征变量共28 个,相关系数最高的5 个光学特征变量为SR546、SR549、SR526、SR65、SR34,相关系数分别为-0.19、-0.18、-0.18、0.18、-0.18,说明蓝光和近红外区间波段组合得到的植被指数与算术平均高的相关性显著。在使用特征变量建模时应考虑变量间的自相关性,选取VIF 指数较低的变量。
选择与森林蓄积量和树高显著相关的因子与CHM,结合VIF 指数,建立线性逐步回归模型进行变量筛选,得到用于反演蓄积量的特征变量组合 为CHM、Mean_Band5、SR526、SR579、SR549与SR65,得到多元线性回归模型方程为:

式(2)中:x1为CHM,x2为Mean_Band5,x3为SR526,x4为SR579,x5为SR549,x6为SR65,Y为蓄积量(表2)。
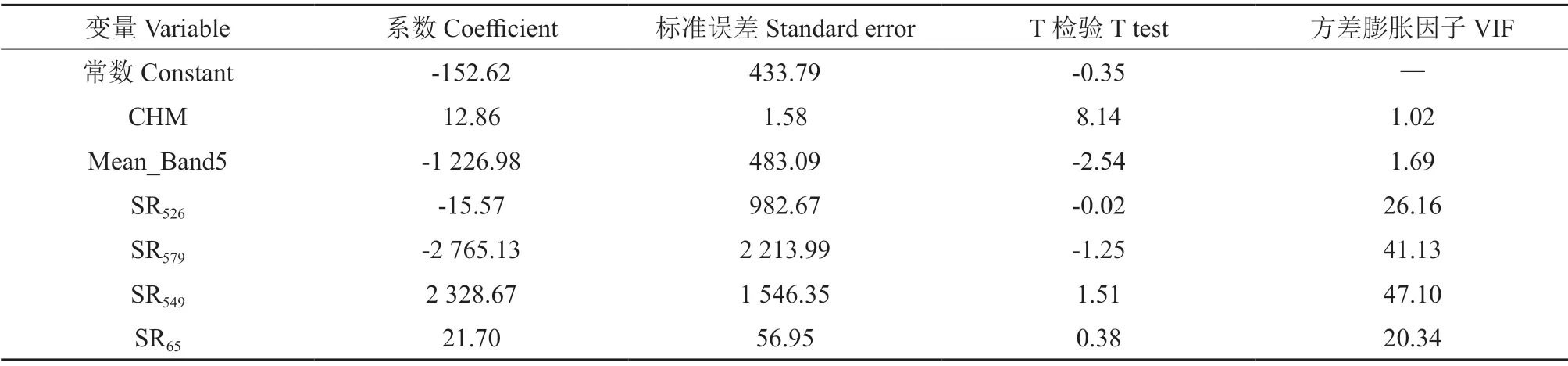
表2 多元逐步回归模型统计量(蓄积量)Table 2 Multivariate stepwise regression model statistics (volume)
选择相关性较高的因子与CHM,结合VIF 指数,采用多元逐步回归模型建立线性模型进行变量筛选,得到用于推测内生变量样地算术平均高的特征变量分别为CHM、SR34、SR547、Entropy_Band3、SR569与SR635,得到多元线性回归模型方程为:
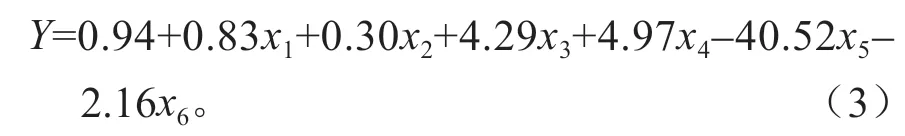
式(3)中:x1为CHM,x2为SR34,x3为SR547,x4为Entropy_Band3,x5为SR569,x6为SR635,Y为算术平均高(表3)。

表3 多元逐步回归模型统计量(算术平均高)Table 3 Multivariate stepwise regression model statistics (High arithmetic average)
2.2 模型结果及精度比较
利用Pearson 相关系数法进行特征变量选择,选取合适的变量,结合普通回归模型、误差变量联立方程组、随机森林和kNN 反演方法分别建立反演模型,并对模型进行精度评价。选择R2、RMSE 以及RRMSE 等3 个指标进行不同模型预测结果的比较与分析,结果如表4所示。
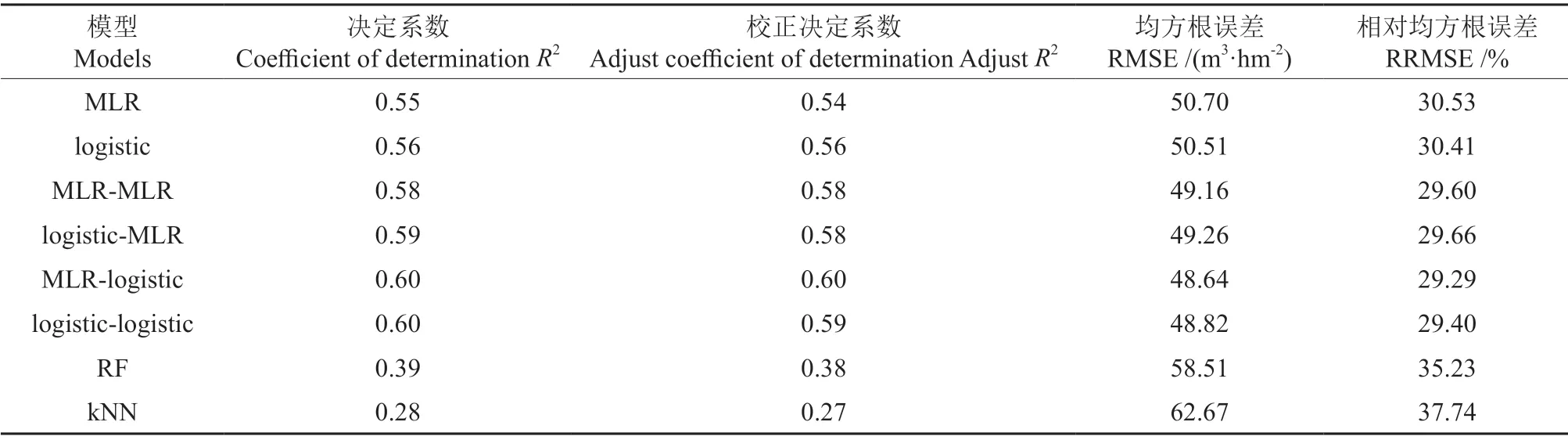
表4 不同方法预测结果Table 4 Prediction results of different methods
从表4中可以看出,在4 种反演方法中,误差变量联立方程组反演方法效果最好,其中MLRlogistic 联立方式的联立方程组模型精度最高,决定系数R2为0.60,RMSE 为48.64 m3·hm-2,RRMSE=29.29%;普通回归模型方法效果次之,logistic 模型的R2为0.56,RMSE 为50.51 m3·hm-2,RRMSE=30.41%;其次是随机森林模型,R2为0.39,RMSE 为58.51 m3·hm-2,RRMSE=35.23%;kNN 方法的反演效果最差,R2为0.28,RMSE 为62.67 m3·hm-2,RRMSE=37.74%。误差变量联立方程组方法的R2相对于kNN 方法提高了53.3%,RMSE 下降了22.4%,RRMSE 减少了8.5%,反演精度显著提升。
2.3 残差分析
利用4 种反演方法得到的预测值与样地实测值分别进行残差计算,残差分布如图2所示,对4种反演方法中最优模型的残差绝对值进行显著性检验,得到显著性检验结果如表5所示。

图2 残差分布Fig.2 Residual distribution

续图2Continuation of Fig.2

表5 残差绝对值的显著性检验结果Table 5 Significance test results of absolute value of residuals
由图2和表5可知,kNN 与随机森林方法的残差随机性较差,分布在±150 m3·hm-2以内,效果较差;普通回归模型方法残差绝对值大于100 的样地较多,模型的拟合效果一般;误差变量联立方程组反演方法残差绝对值大于100 的样地较少,基本呈随机、无规律分布,效果最好,且误差变量联立方程组反演方法的预测结果显著优于普通回归模型、随机森林与kNN 反演方法(P<0.05)。
2.4 蓄积量空间分布制图
图3是根据4 种蓄积量反演方法获得的研究区蓄积量空间分布。从图中可以看出,使用普通回归模型、误差变量联立方程组与kNN 反演得到的蓄积量空间分布图(图3a—h)比随机森林方法反演得到的蓄积量空间分布图(图3g)更为平滑、层次更多,效果更好,而随机森林方法获取的蓄积量空间分布图存在大量的高估值和低估值,不能准确地反映研究区的蓄积量分布情况,模型可靠性较差;kNN 反演方法得到的蓄积量空间分布图(图3h)中,对研究区蓄积量处于200~300 m3·hm-2之间的部分存在大范围的过高估计,与实际情况不符,制图效果较差;误差变量联立方程组反演方法得到的蓄积量空间分布图(图3c—f)与普通回归模型方法得到的蓄积量空间分布图(图3a—b)相比,0~100 m3·hm-2范围内的蓄积量分布更少,其蓄积主要分布在100~200 m3·hm-2之间,与表1中样地蓄积量分布状况一致,较为真实地反映了研究区的森林蓄积分布情况。所有反演方法中,误差变量联立方程组反演蓄积量制图效果最优,证实了误差变量联立方程组反演蓄积量制图的可行性。
3 结论与讨论
3.1 结 论
以广西壮族自治区国有高峰林场的界牌、东升分场为研究区,利用Sentinel-2 数据提取的光学遥感信息,通过特征变量筛选后结合机载激光雷达数据提取的CHM 建立普通回归模型、误差变量联立方程组、随机森林回归与kNN 回归反演方法分别对研究区进行森林蓄积量估测,并利用地面实测数据进行交叉验证,最终获得了研究区森林蓄积量空间连续分布图。结果表明:
1)在普通回归模型方法中,logistic 模型精度优于MLR 模型。logistic 模型的R2为0.56,RMSE=50.51 m3·hm-2,RRMSE=30.41%,MLR 模型 的R2为0.55,RMSE=50.70 m3·hm-2,RRMSE=30.53%。

图3 研究区蓄积量信息空间分布Fig.3 Spatial distribution of volume information in study area
2)在建立的误差变量联立方程组中,MLRlogistic 联立方式的联立方程组模型优于其他3 种联立模型。MLR-logistic 联立模型精度最高,R2为0.60,RMSE=48.64 m3·hm-2,RRMSE =29.29%;logisticlogistic 联立模型精度次之,R2为0.60,RMSE=48.82 m3·hm-2,RRMSE =29.40%;其次是MLR-MLR联立模型,R2为0.58,RMSE=49.16 m3·hm-2,RRMSE=29.60%;logistic-MLR 联立模型效果最差,R2为0.59,RMSE=49.26 m3·hm-2,RRMSE=29.66%。
3)误差变量联立方程组反演方法预测效果优于其他3 种方法,在所有通过Sentinel-2 影像建立的模型中,误差变量联立方程组反演方法拟合度最高,误差最小,预测精度最好。误差变量联立方程组反演方法的决定系数R2最高为0.60,RMSE=48.64 m3·hm-2,RRMSE =29.29%;普通模型方法次之,R2为0.56,RMSE=50.51 m3·hm-2,RRMSE=30.41%;其次是随机森林方法,R2为0.39,RMSE=58.51 m3·hm-2,RRMSE=35.23%;kNN 反演方法效果最差,R2为0.28,RMSE=62.67 m3·hm-2,RRMSE=37.74%。
4)误差变量联立方程组森林蓄积量反演结果与研究区实际森林蓄积量情况分布一致,森林蓄积量主要分布在100~200 m3·hm-2,西南部地区蓄积量分布较多,东北部地区蓄积量分布较少。反演结果与实地调查情况基本一致,能满足反演需求,制图效果最好,因此应用误差变量联立方程组反演森林蓄积量制图方法是可行的。
3.2 讨 论
随机森林模型通过建立多棵决策树对样本进行训练并预测,它在学习过程与误差平衡等方面具有优势[31],与kNN 模型都是使用广泛的非线性模型。但在本研究中的反演效果较差,与所使用的特征变量有密切关系。
Pearson 相关系数法结合线性逐步回归分析能最大限度利用变量组合,选出使模型拟合度较高、误差较低的变量组合,但所提取的纹理、植被指数等277 个光学遥感特征变量与森林蓄积量和样地算术平均高相关性都较低,导致整体反演精度较低与使用随机森林和kNN 反演方法获得的森林蓄积量空间分布图效果较差,其原因可能是桉树的生长特性导致。
桉树具有生长快、树冠变化不显著等特点,而光学遥感所获取的信息是水平结构层面的,这就导致了使用光学遥感无法获取森林垂直结构层面的信息。桉树的树冠小,相较于树高变化不明显,因此所获得的光学遥感特征变量与蓄积量之间难以建立直接联系。但LiDAR 数据恰好可以满足光学遥感对林分垂直结构层面信息的需求,它为整个蓄积量反演过程提供了一些可以参考的垂直结构层面的特征变量。
CHM 就是其中一个重要的特征变量。因此在本研究中,结合CHM 进行森林蓄积量反演,有利于提高反演精度。误差变量联立方程组反演空间蓄积量制图方法,即用CHM 作为外生变量去推测内生变量研究区林分平均高,再用内生变量结合其他特征变量联合反演森林蓄积量的方法可以较好地估算森林蓄积量,相较于普通回归模型方法、随机森林反演方法与kNN 反演方法,误差变量联立方程组方法反演的精度更高,整体效果更好,而且在4 种联立模型(MLR-MLR,MLRlogistic,logistic-MLR,logistic-logistic)中,交叉验证的结果变化都很小,说明误差变量联立方程组反演森林蓄积量制图方法具有一定的可靠性,为后续研究中使用误差变量联立方程组反演森林蓄积量制图方法提供了切实可行的借鉴思路。
猜你喜欢
现代园艺(2021年23期)2021-12-01 07:47:44
林业勘查设计(2020年1期)2021-01-18 02:40:48
新农业(2020年18期)2021-01-07 02:17:08
山东林业科技(2018年6期)2019-01-08 09:48:04
山东林业科技(2017年1期)2017-06-29 07:54:06
河北经贸大学学报(2017年2期)2017-02-15 22:38:35
林业与生态(2016年2期)2016-02-27 14:23:42
管理现代化(2016年6期)2016-01-23 02:10:52
华侨大学学报·哲学社会科学版(2015年2期)2015-05-13 05:59:30
经济与管理(2015年4期)2015-03-20 14:15:31
