
利用深度学习对托福听力部分进行机器理解
2021-01-28 03:35胡蓉田时宇
微型电脑应用 2021年1期
胡蓉, 田时宇
(湖南信息学院 通识教育学院, 湖南 长沙 410151)
0 引言
随着共享视频、社交网络和在线课程等的普及,多媒体或音频内容的数量增长速度远远快于人们可以观看或收听的内容。用户可以轻松地浏览文本,但音频内容则不是这样,因为它们不能直接显示在屏幕上,因此,访问大量的多媒体或音频内容对人类来说是困难和耗时的。因此,利用机器实现自动理解语音内容,并为人类提取甚至可视化关键信息是非常必要的。尽管文本和视觉内容的机器理解已经得到了广泛的研究,但是口语内容的机器理解仍然是一个研究较少的问题[1-2]。因此本文对口语内容的机器理解进行了初步尝试。
本文以托福考试为研究目标,针对托福考试中的听力部分,利用深度学习进行机器理解。本研究提出了一种新的框架TAL,利用基于注意力的Tree-LSTM来构造考虑词序的句子表示[3]。本文利用自然语言的层次结构和注意机制的选择能力,证明了该模型优于朴素方法和其他基于神经网络的模型。
1 对听力的机器理解
1.1 系统架构
TAL网络架构,如图1所示。
由图1可知,模型中有两个关键模块:第一个是Tree-LSTM[4],它将句子编码成连续的表示形式,由依赖解析器提供层次结构,而不是简单的顺序结构,因此它利用了人类语言的内在属性;第二个关键模块是注意模块(attention module)。在接下来的实验中,发现将这两个模块结合在一起比以前仅使用Tree-LSTM和注意力机制(attention mechanism)更为出色。
模型不同组件的详细信息如下所示。在图1的左侧,基于Tree-LSTM的句子表示模块用于根据问题的单词序列生成问题向量的表示;ASR系统转录音频故事,图1底部的故事模块以ASR转录本为输入,将转录本中的句子转换成一个向量序列,每个向量代表一个短语或一个句子;注意力模块在中间,注意机制可以应用多次。在图的右侧,这四个选项也由句子表示模块表示为向量。最后,评估答案选择的置信度得分,并生成答案。系统是端到端学习的,除了ASR模块。
1.2 句子表征
句子表示模块的目标是通过捕获句子语义的向量来表示句子。输入问题Q和选择C都是一个单词组成的序列。在句子表示模块中,问题Q表示为向量VQ0,选择C表示为VC。一个问题可以由多个句子Si组成,每个句子首先可以表示为VSi。那么问题向量VQ是问题中所有Si的VSi之和。使用递归神经网络Tree-LSTM获得句子表示。Tree-LSTM基于其子节点的向量表示为依赖树中的每个节点生成向量表示。
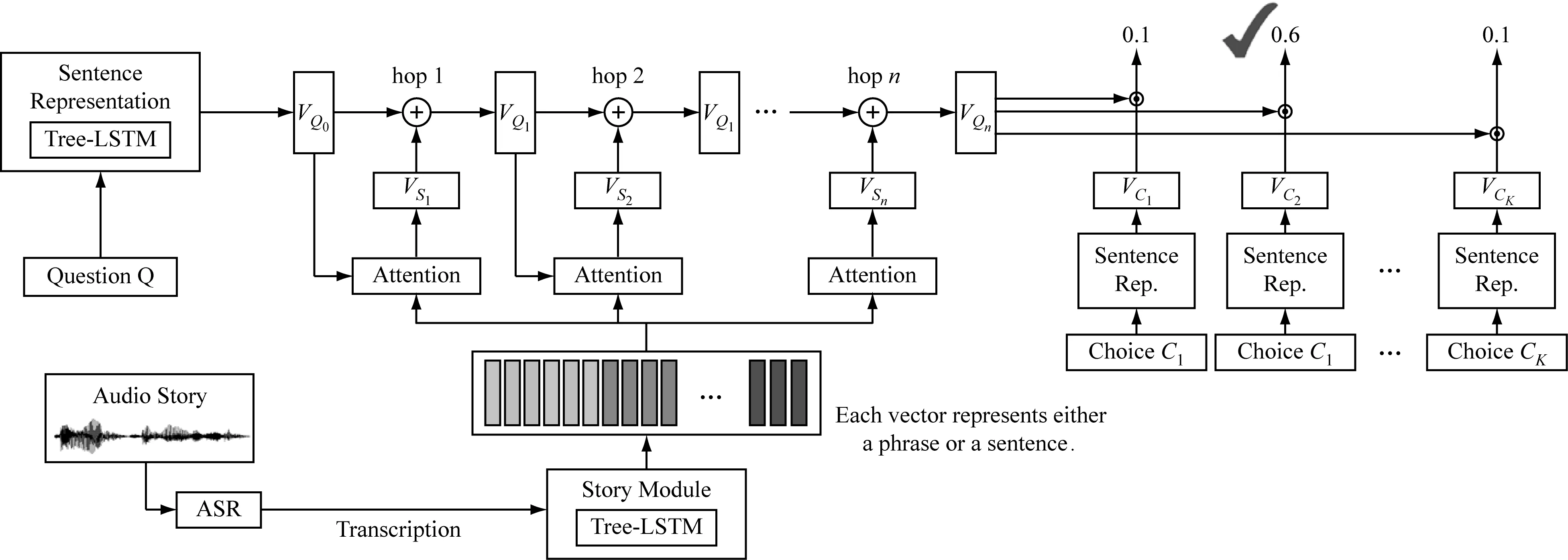
图1 TAL网络架构
1.3 故事表征
故事抄写是一个很长的单词序列,有很多句子。故事模块的目标是将单词序列表示为一组向量表示O={o1,o2,…,ot},其中ot表示Tree-LSTM的短语或句子。
短语层次:O={o1,o2,…,ot}中,每个ot是句子的Tree-LSTM中节点的隐藏状态,或者每个ot表示一个短语。因此,t大于故事中的句子数。
句子层次:每一个ot是故事中某个句子上Tree-LSTM的根节点的隐藏状态,或者每一个ot代表一个句子。在这种情况下,t等于句子数。
1.4 注意力机制
存储模块基于从故事模块获得的表示来提取故事中与问题VQ相关的信息。设O={o1,o2,…,ot}为故事的向量表示集。集合O中的向量首先由嵌入矩阵W(m)和W(c)转换成记忆向量M={m1,m2,…,mt}和证据向量C={c1,c2,…,ct},如式(1)。
(1)

(2)
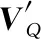
(3)
式中,⊙表示余弦相似性。每个注意权重αt对应于一个证据向量ct。故事向量Vs是以注意力为权重的证据向量ct的加权和,如式(4)。
(4)
式中,Vs可以看作是从音频故事中提取的与查询相关的信息。
1.5 多跳
在图1的左侧,首先使用句子表示模块将输入问题转换为问题向量VQ0。该VQ0用于计算注意值αt以获得故事向量VS1。然后将VQ0和VS1相加形成新的问题向量VQ1。在图1中,该处理是第一跳(1跳)。第一跳VQ1的输出可用于计算新的注意以获得新的故事向量VS1。这可以被看作是机器再次遍历故事,用一个新的问题向量重新聚焦故事。再次,VQ1和VS1相加形成VQ2(2跳)。在n跳(n是预定义的)之后,最后一跳VQn的输出将用于下一小节中的答案选择。
1.6 应答模块

(5)
2 实验与评估
2.1 实验设置
对于听力评估使用了预训练的300维GloVe矢量模型[5],以获得每个单词的矢量表示。为了减少词汇量,在这里使用了斯坦福大学自然语言处理小组[6]的工具来对问题选择和故事抄写中的单词进行词素化。在训练之前,删减了故事中的那些话语,这些话语的矢量表示与问题之间的余弦距离很远,删减话语的百分比由开发集上模型的性能决定。
2.2 结果与评估
对于前文描述的模型,前向和后向GRU网络的隐藏层的大小都是128。为了避免过度拟合,模型中的所有双向GRU网络和树LSTM共享同一组参数。使用RmsProp[7],初始学习率为1e-5,动量为0.9。辍学率为0.2。Tree-LSTM的隐藏层大小和内存模块的嵌入大小均为75。使用AdaGrad[8],初始学习率为0.002。梯度裁剪的阈值为20,批量大小为40,使用开发集将跳数从1调整到3。
使用准确性(正确回答的问题的百分比)作为评估指标。在训练集的故事和问题/答案的手动转录上对模型进行了训练,并在测试集(Manual)和ASR转录(ASR)上进行了测试,为了进行公平的比较,统计了10次运行的平均准确度和标准差,如表1所示。
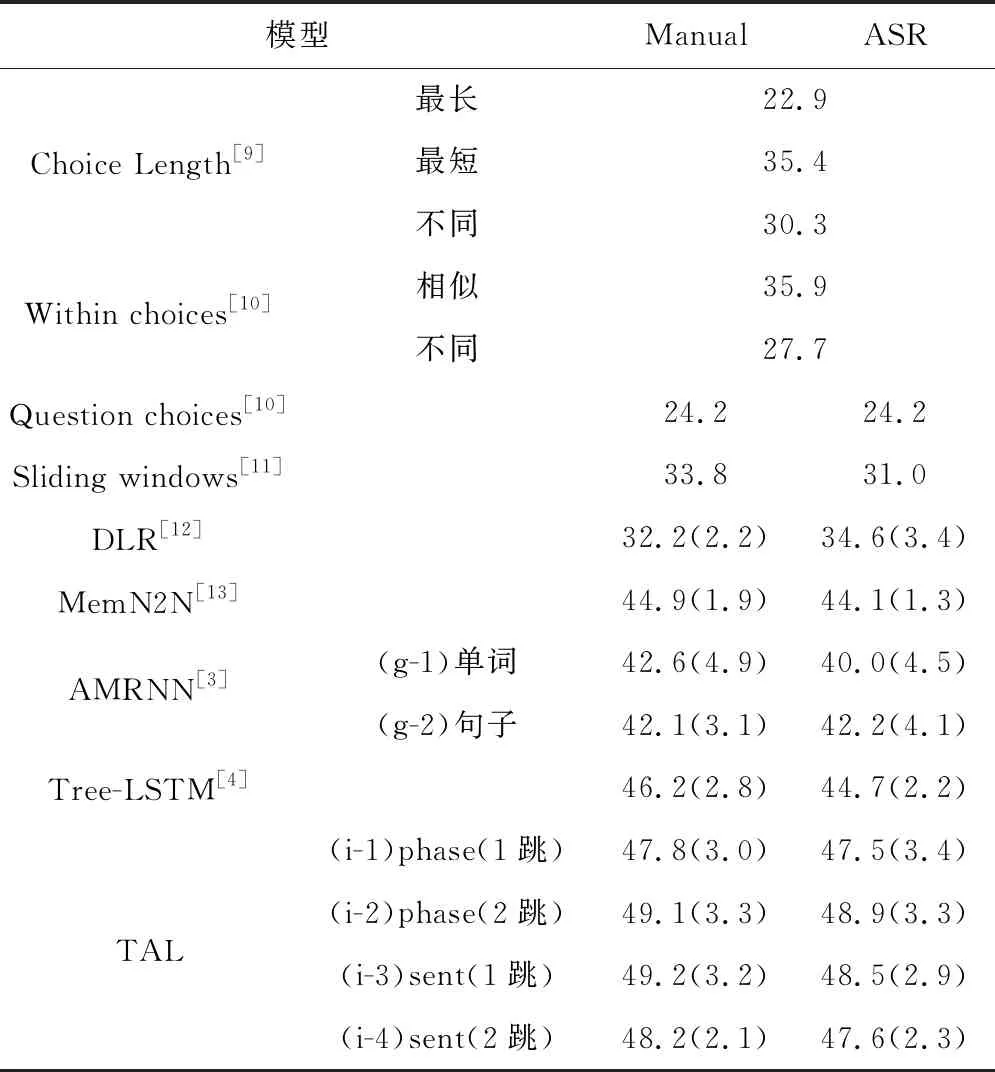
表1 不同方法比较结果
本文提出的TAL分别用于1跳和2跳的短语/句子级的注意力模型,其准确度比其他方法都要高很多。1跳句子级注意力模型在manual中的平均准确率最高,达到49.2%,显著高于其他方法的结果;2跳短语级注意模型在ASR结果中的平均准确率最高,达到48.9%,仅略低于1跳。还可以观察到,增加跳数会提高短语级注意的表现,但不会提高句子级注意的表现,这可能是因为对于短语级推理,模型首先在1跳中选择关键短语,然后在2跳中根据这些关键短语改变其注意力。对于句子级推理,在1跳中只选择了几个关键句子,而更多的跳则无法找到额外的关键句子。
令人惊讶的是,ASR错误对听力理解的影响很小。为了进一步分析结果,进行了额外的实验。在测试阶段,用一个概率为34.3%(与WER相同)的随机词替换了manual中的每个词。结果显示在标有随机的列中。通过比较ASR和随即两栏的结果,我们发现ASR错误对听力理解准确性的影响小于随即替换,如表2所示。
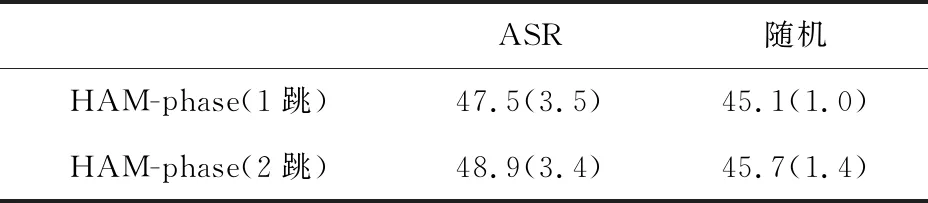
表2 ASR和随机的结果
3 总结
在本文中,提出了两个与语音内容的机器理解有关的目标——托福听力和口语理解。在托福听力理解中,提出的TAL框架在树状结构的LSTM网络中结合了多跳注意力机制,其准确性为48.8%;在对口语理解中,利用CNN网络改进现有的模型,证明了ASR错误会大大降低阅读理解模型的性能,并建议使用不同种类的子字单元来减轻这些错误的影响。
猜你喜欢
环球时报(2022-07-13)2022-07-13
小雪花·成长指南(2022年1期)2022-04-09
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
海峡姐妹(2016年2期)2016-02-27
