
基于相似日和Elman神经网络的逐时太阳总辐射预测
2021-01-26 03:13王小洁陈珍莉施晨晓刘霄燕
海南大学学报(自然科学版) 2020年4期
王小洁,陈珍莉,王 旭,施晨晓,刘霄燕
(海南省气象信息中心,海南省南海气象防灾减灾重点实验室,海南 海口 570203)
太阳辐射是地球大气系统中主要的能量来源,也是影响气候变化的重要因子.下垫面和大气之间的热量平衡由辐射收支平衡决定,其在大气环流和调节气候特征起到主要决定性作用.太阳辐射能是具有清洁、可再生的新能源,研究太阳总辐射的特征可以为辐射能源的开发利用提供科学理论基础.
从十九世纪开始太阳辐射观测至今已有180多年的历史,随着辐射数据在各个领域的广泛应用,对辐射数据可靠性和连续性的要求越来越高.辐射观测存在由于仪器故障、设备断电等原因造成数据缺测和异常,此外太阳辐射设备观测仪器造价昂贵,导致辐射站点分布稀疏,使研究和数据应用存在问题.因此,国内外许多专家学者对辐射数据构建预测、模拟模型进行诸多研究.蔡元刚[1]等基于气象常规观测资料建立四川省日总辐射模拟模型.敖银银[2]等利用经验公式构建太阳总辐射模拟模型分析并插值法随州区太阳辐射空间分布特征.曹其梦[3]等根据辐射数据的时间序列中存在的相关关系,即将某一时次的辐射量是过去辐射量基础上的随机波动,通过自协方差函数和自相关函数来表示.Benmouiza[4]等利用自回归-滑动平均(ARMA)和非线性自回归(NAR)神经网络方法预报辐射预报模型.Colak[5]等利用ARMA和累积式自回归-滑动平均方法(ARIMA)对太阳辐射进行在不同时效上的预报.
二十世纪,随着卫星遥感技术不断完善,遥感数据得到了广泛的应用,学者们开始结合卫星数据应用经典气候学模型或者辐射传输理论反演太阳辐射量,获取更高精度的太阳辐射分布[6-7].卫星数据存在时效性不高、数据处理量的问题,导致预测数据时效性较差.随着人工智能算法研究的兴起,庄述鹏[8]等和冯姣姣[9]等利用神经网络、支持向量机等对太阳辐射进行预报和模拟,此预测方法不仅可以结合气象要素对辐射数据的影响来进行复杂的非线性拟合,同时还克服了太阳辐射序列的随机性.目前大部分研究集中在逐日辐射量和月辐射量的预测模拟上,对于海口地区逐时总辐射预测的研究较少,且辐射数据逐小时变化特征明显,与多个要素之间相互影响.黄海静[10]等结合天气预报、天气现象和日照时数,建立不同天气类型的分型标准,以天气类型、气温日较差和历史辐射值作为输入因子利用小波神经网络预测海口地区太阳总辐射量,但历史天气预报获取复杂且辐射站点分布稀疏不利于辐射空间分布分析.因此,笔者利用辐射及其相关气象要素,针对辐射时间序列数据中非线性、非平稳性的特征,建立基于相似日选取和Elman神经网络的海口地区逐时总辐射预测模型,旨在找到精确的辐射预测模型,以期提高辐射数据预测精度,为辐射数据的质量控制和缺少辐射观测地区提供精确的预测模型,满足业务服务需求,进一步提高辐射数据的使用率.
1 研究资料
海南省从二十世纪50年代开始辐射观测.在二十世纪90年代建立起全省辐射自动观测网络,分别建立在海口站、三亚站和西沙站,其中海口辐射观测站属于二级站,观测项目为总辐射和净全辐射.辐射量与多个气象要素之间相互影响,其中气压、气温、相对湿度、降水、日照和云量等要素对辐射量的影响较大.由于云量没有逐时观测,获取逐时云量数据不便.考虑到数据可靠性,采用2009~2019年海口逐时本站气压、气温、相对湿度、降水量、日照、太阳高度角和太阳总辐射曝辐量数据.其中2009~2018年共10 y数据为训练测试样本集,2019年为验证集.因通常日出之前、日落之后辐照量为零,研究时段只选取了6~19时逐时总辐射曝辐量.经过数据质量控制后的样本集数据共有52 181条,其中2019年作为验证数据共5 110条.
2 研究方法
2.1 数据质量控制对选取的气象数据和总辐射曝辐量进行质量控制,首先剔除缺测值和超出气候阈值的奇异值记录.剔除总辐射曝辐量小于0的记录;剔除总辐射曝辐量小于净全辐射曝辐量的记录;剔除日照时数大于可日照时数的记录.
2.2 数据归一化不同的要素之间单位和量级不同,为了消除各气象要素与总辐射曝辐量之间的数量级和单位给预测模型带来的误差,采用离差归一化方法对数据进行线性变化,将数据结果压缩到0~1之间,具体公式为
(1)
其中,xi为某时次归一化后的数据,xn为同一时次未做归一化的数据,xmax,xmin分别为该要素序列的最大值最小值.
2.3 模型构建
2.3.1 输入因子筛选地面太阳总辐射主要受到日照时数,天文辐射量等要素影响.综合分析后,选取与辐射数据相互影响的本站气压、气温、相对湿度、降水量、日照和太阳高度角等气象要素.气温是总辐射量强弱的侧面表达,气压反映了大气层中空气分子的密集程度,降水量和相对湿度反应空气中的水汽含量.分析其与太阳总辐射的相关关系,选取通过显著性检验的要素作为模型的输入变量,气象要素与总辐射曝辐量间的相关关系详见表1.

表1 2009~2019年不同气象因子与逐日太阳总辐射相关关系
通过相关性分析和显著性检验,本站气压、气温、相对湿度、降水量、日照和太阳高度角6个要素与总辐射曝辐量之间都呈显著相关关系,其中气压、降水、相对湿度呈负相关关系,说明气压、降水和相对湿度对海口地区的辐射具有削弱作用,其中以相对湿度对太阳辐射的削弱效果最明显.太阳高度角、日照时数和气温与总辐射曝辐量呈显著的正相关关系,与施红[11]等的结论相符.
根据相关性分析的结果,选取2009~2018年海口地区本站气压、气温、相对湿度、降水量、日照时数和太阳高度角6个要素为模型输入因子,总辐射曝辐量为输出参考因子,选取2019年数据为验证集.结合相似日算法改进模型构建小时总辐射预测模型.
2.3.2 相似日原理相似日是指与研究日气象特征相似的样本历史日,将一段时间内的历史日作为待筛选样本,通过构建气象要素特征向量,分析待筛选样本日的历史气象要素特征向量与待预测日气象要素特征向量之间的相似程度,两者之间相似程度越高则表明历史日与待预测日的气象要素特征越相近,通过分析历史时间序列,选取相似程度最高或者相似度达到阈值要求的历史日即为相似日,若干符合条件的相似日组成相似日时间序列.
由于神经网络算法中普遍存在的泛化能力差等问题,且太阳辐射的变化受多种气象因素的相互影响,又存在日变化和季节变化规律,辐射数据的预测精度受到这些因素的影响.当预测日与样本日的气象环境如气温、日照时数和相对湿度等要素较为相近时,辐射也会出现相应的规律.为了找到气象因素和变化规律与预测时次相似的时段,通常采用欧式距离[12]、相关系数公式[13]、灰色关联分析法[14]和模糊聚类[15]等方法来挑取相似日.为避免辐射量随季节变化的因素对预测精度造成误差,选取根据预测时的气象状况筛选预测日历年同期前30 d的相似性达0.8以上的若干天组成相似日时间序列,选取灰色关联分析法分析特征向量之间的相似程度.
构建相似日时间序列的步骤分为3个部分,首先构建表征预测日和待筛选样本日气象特征的气象日特征向量,再根据灰色关联分析法分析两两特征向量之间的相似程度,根据总关联度筛选最后组成相似日特征矩阵.
1) 构建特征向量 首先将与总辐射变化相关的气象要素量化表达,通过对辐射及其影响要素进行相关性分析,选取重要影响因素,构建预测日的日特征向量.
通过对气象要素和总辐射曝辐量的相关性分析,可以看出总辐射曝辐量与日照时数、相对湿度和太阳高度角之间的相关性较大.考虑太阳高度角的变化与站点经纬度和季节变化有关,受实际天气变化影响较小,因此选取日照时数和相对湿度2个气象要素来体现日特征.由于在日出之前和日落之后的太阳辐射量为0,而海口全年的最大可日照时间为14 h,实际最大可日照时间受季节的变化呈现明显的夏季长冬季短的季节变化规律.为了研究方便选取6~19时共14 h的数据进行研究,将日照不足14 h时次的辐射值以0补齐,将研究的数据时间序列统一,构建基于最大可日照时数的逐时辐射时间序列.因此,设定每日的特征向量包括6~19时逐时日照时数和逐时相对湿度,共28个元素.特征向量T为
T=[SiRhi],
(2)
其中,i为时次,S为日照时数,Rh为相对湿度.以上数据都经过归一化处理,降低量纲对模型精度的影响.以相似度ri作为筛选标准,将两者间相似度大于0.8的筛选日的本站气压、气温、相对湿度、降水、日照时数和太阳高度角构建新的时间序列作为预测模型的输入数据.
2) 相似度分析 通过定量计算预测日和筛选日的相似度,计算待预测日特征向量中第k个气象要素与待预测日天气现象特征向量间的关联系数公式
(3)
其中,ρ为分辨系数,取0.5;x0为待预测日特征向量;xi为待筛选日特征向量;i=1,2,…,m;k=1,2,…,n;m为特征向量内元素数,n为待筛选日个数.
3) 总关联度分析 通过计算获得待筛选日和待预测日特征向量之间的关联系数,计算待预测日与第i个待筛选日的总关联度
(4)
选取相似度ri大于某一标准的若干个相似日,对应的气象要素组成的时间序列作为待预测日的相似日时间序列.
2.3.3 Elman神经网络大气中各个要素之间相互影响,是一个复杂非线性关系,传统的回归方法和逐时总辐射气象计算方法难以解决这一非线性问题.神经网络具有高度学习能力,用于解决传统算法中不能解决的非线性关系问题,可以通过动态学习行为学习复杂模型,文献[16-18]都已证明其逼近能力能够解决大多数的非线性问题.
Elman神经网络是一种反馈型神经网络,一般分为4层:输入层、中间层、承接层和输出层[19].承接层作为一次训练的延时算子,通过承接层的延迟和存储,使隐含层的输出关联到输入,使系统具有适应时变特征,可以不考虑外部噪声对系统影响,以任意精度逼近任意非线性映射[20].与传统的BP神经网络等算法相比,Elman的学习速度更快,具有更好地泛化能力.
研究数据具有强的非线性特征,基于普通的多元回归方法、经验公式方法预测辐射数据难以解决这一问题造成的误差.为了减少数据时间序列的随机性对预测结果的影响,采用基于相似日分类的Elman神经网络预测算法,以期消除时间序列中非平稳特性造成的预测误差.首先将数据集分为训练数据集和验证数据集,其中2009~2018年在算法中分别随机选取不同数据构建训练数据集和测试数据集,2019年为验证数据集,对各个输入输出数据进行归一化处理.根据相关性分析,选取对总辐射变化影响较大的6个气象因素作为模型的输入数据集,同时为了加快模型的训练时间和提高模型精度,以相关性最高的相对湿度和日照时数2个表征气象特征的数据构建特征向量,引入灰色关联分析法选取相似日,组成基于相似日的6个要素特征矩阵作为输入因子,总辐射曝辐量作为模型期望输出进行训练,预测2019年总辐射曝辐量,最后与实际观测总辐射曝辐量对比,进行误差分析.
3 结果分析
3.1 误差分析
3.1.1 误差评价指标根据相关系数(R)、均方根误差(RMSE)和平均绝对误差(MAE)3个误差统计评价指标验证2个模型的预测结果的精度,并进行误差分析.RMSE和MAE越小表示模型预测的效果越好,反之,说明模型预测效果越差.相关系数R表示预测值和实测值拟合度,R越接近与1,表示预测拟合程度越高.
(5)
(6)
(7)
其中,xi代表预测值,Xi为实测值,n为样本数.
3.1.2 模型误差分析利用Elman神经网络算法、相似日-Elman神经网络算法对海口地区逐时总辐射曝辐量进行预测,拟合结果如图1和表2.
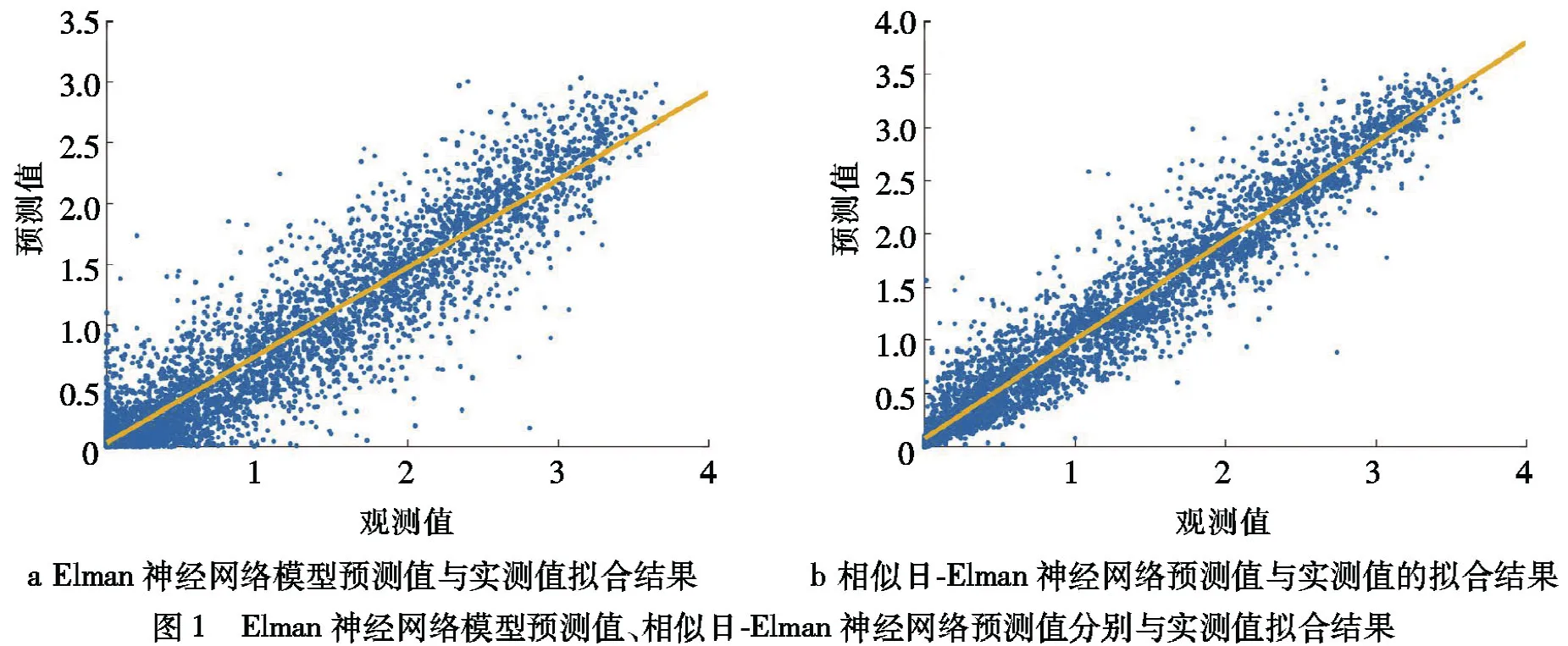
a Elman神经网络模型预测值与实测值拟合结果b 相似日-Elman神经网络预测值与实测值的拟合结果图1 Elman神经网络模型预测值、相似日-Elman神经网络预测值分别与实测值拟合结果

表2 2个模型误差统计指标
从图1和表2中可以看出,基于相似日改进的Elman神经网络算法模型的预测值相较于未改进的Elman算法预测值更接近真值.从表2中的R,MAE和RMSE,通过相似日筛选的算法模型预测结果相对较好,真值和预测值之间具有较高的拟合度,拟合趋势线斜距接近于1,R为0.97,MAE为0.16 MJ·m-2,RMSE为0.24 MJ·m-2;未改进Elman算法模型,R为0.93,MAE为0.35 MJ·m-2,RMSE为0.47 MJ·m-2.未改进Elman算法模型的预测结果相关性虽然通过0.01的显著性检验,但预测出来的结果相对离散,MAE和RMSE相对偏大.尤其当总辐射曝辐量观测值低于1 MJ·m-2时或者曝辐量大于2 MJ·m-2时,未经相似日筛选的模型预测结果与真值偏离较大,存在若干奇异点,说明未改进的模型在曝辐量较低时的模拟效果较差,与算法的泛化能力较弱有关.在曝辐量数值较低,且有较多要素影响太阳辐射到达地面的辐射的时候,基于相似日筛选的模型可以更好地识别能力,更高地预报精度.
根据2个模型结果计算的RMSE绘制预测误差箱型图,如图2所示.在反应误差分布的箱形图上,改进后的Elman算法预测的总辐射曝辐量箱体较窄,预测误差的中位数和平均数也更接近于0,平均预测误差在±0.5 MJ·m-2范围内.未经过相似日筛选的Elman算法模型预测值相对观测真值整体偏低,平均预测误差在-1.4~0.7 MJ·m-2之间,中位数和平均值远离0,表明改进后基于相似日筛选的Elman算法预测精度比未改进的算法精度好,准确度更高,更好的预测了海口地区的总辐射曝辐量.
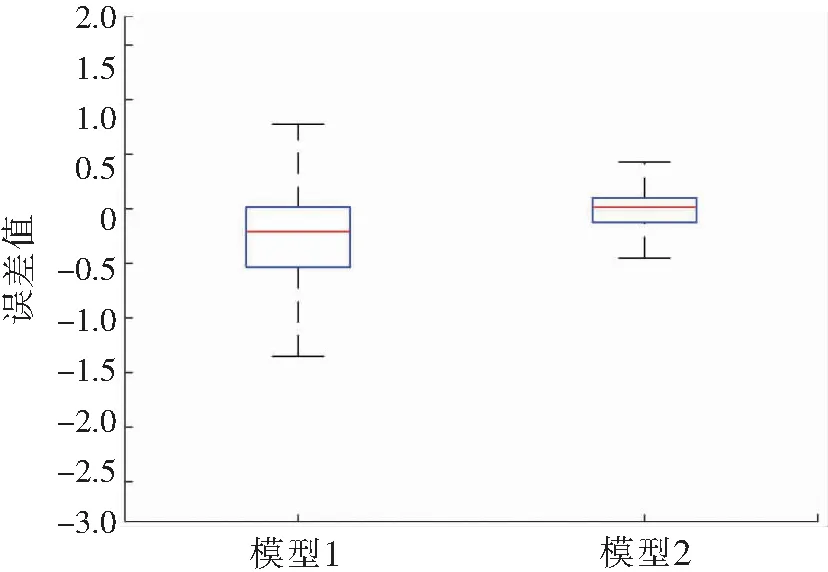
图2 预测相对误差箱形图
为数据清晰展示方便分析和验证不同季节状况下的预测效果,从四季中分别选取2019年2月、5月、8月、12月中旬的Elman神经网络预测值、基于相似日筛选的Elman神经网络预测值以及实际观测值就预测结果精度进行分析.
从图3和图4中可以看出,2个模型的整体预测结果都比真值偏低,在日极值上的预测效果都不太理想,但基于相似日筛选的模型预测值相对未经过筛选的预测值结果更接近于观测真值,能够精确预测总辐射随时间的变化趋势,具有明显优势.夏季5月中旬2个模型的预测精度较差,海口夏季多短时暴雨,大气中水汽含量和云量的变化受影响较大,从而影响太阳辐射,加大了模型的预报难度,导致夏季模型预测效果较差.冬季12月中旬总辐射曝辐量2个模型基本能预报准确,但研究时段内曝辐量出现2次突变,而2个模型都没有很好的拟合出来,需结合实际天气情况进一步分析此变化的成因精进模型.未经筛选的预测模型虽然能预测出真值的大致趋势,但与真值相差较大,且会出现奇异值.说明通过相似日筛选之后的模型有效的提高了预测的精准度,进一步优化总辐射预测算法的精确度.

图3 2019年2月、5月、8月、12月中旬太阳总辐射曝辐量预测结果
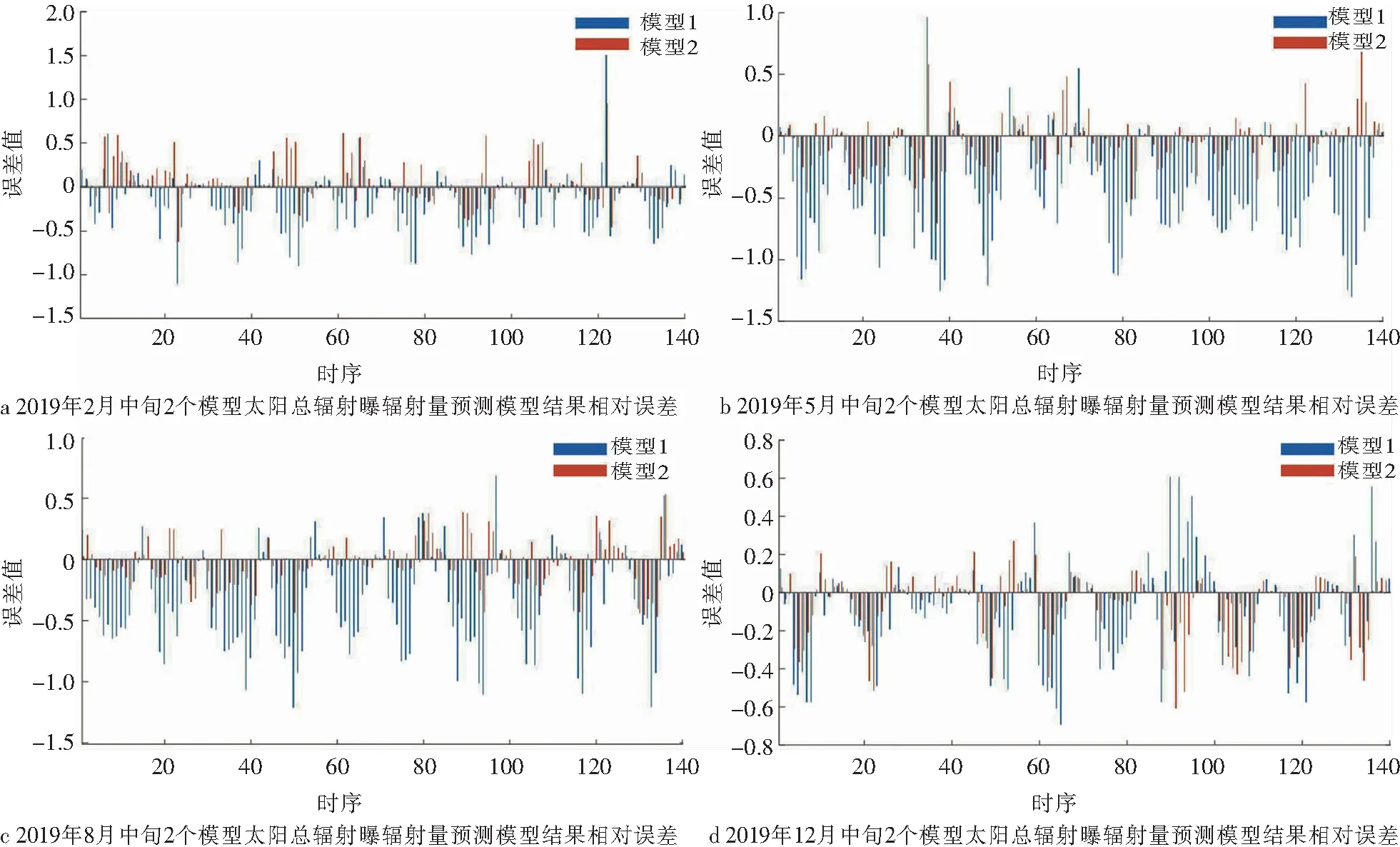
图4 2019年2月、5月、8月、12月中旬2个模型太阳总辐射曝辐量预测模型结果相对误差分析
3.2 总辐射时空变化特征分析由于辐射观测仪器造价昂贵,就海南省来说,省内只部署了3个辐射站,分别位于海口站、三亚站、西沙站.考虑到海南岛经纬辐射跨度小,太阳可能辐射量差异不大,具有可参照性,利用气象要素对没有辐射观测仪器站点进行预测,分析辐射的空间分布[21].经过验证分析,基于相似日筛选的Elman神经网络算法预测太阳总辐射具有更高的精度,可以通过该算法利用各个观测站的气象要素数据预报当地的辐射值,为分析海南辐射分布特征提供科学依据.

图5 2019年琼北地区年小时平均总辐射空间分布
以琼北地区为例,选取琼山、文昌、定安、澄迈、临高5个琼北市县的气象要素结合模型预测2019年琼北地区太阳总辐射数据,并根据海口站观测的太阳总辐射数据,分析琼北地区小时平均太阳总辐射的空间分布.
从年平均分布图上来看,琼北地区的年平均小时总辐射值在1.05 ~1.14 MJ·m-2之间,空间分布较为均匀,具体呈现南高北低,东西辐射高的特征,其中东部的总辐射值最高,北部的总辐射值最低.因为北部地理位置偏北,易受到冷空气的影响导致辐射值偏低.南部受到冷空气影响较弱.
为了进一步研究琼北地区总辐射各季节的空间分布情况,对研究区2019年四季小时平均总辐射进行分析,其中2~4月为春季,5~7月为夏季,8~10月为秋季,11~次年1月为冬季.
从图6中可以看出,夏季辐射最强,冬季辐射最弱,春季小时平均总辐射在1.03 ~1.15 MJ·m-2,夏季小时平均总辐射在1.30~1.45 MJ·m-2之间,秋季小时平均总辐射在0.9~1.18 MJ·m-2之间,冬季小时平均总辐射在0.75~0.81 M·m-2之间.四季辐射资源的空间分布均匀,具体呈现东西高,南北低的特征.春季北部和南部的辐射分布相对较少;夏季总辐射较其他季节较高,最大出现在文昌,约为1.45 MJ·m-2,海口和定安太阳总辐射相对较弱;秋季总辐射值与春季相近,西部总辐射值相对其他区域较高.冬季相对其他季节总辐射较弱,西部总辐射相对其他区域较强,北部和南部受冷空气影响较弱.在秋冬2季,西部较为干燥,水汽含量较低,日照时数较长,辐射相对较强.
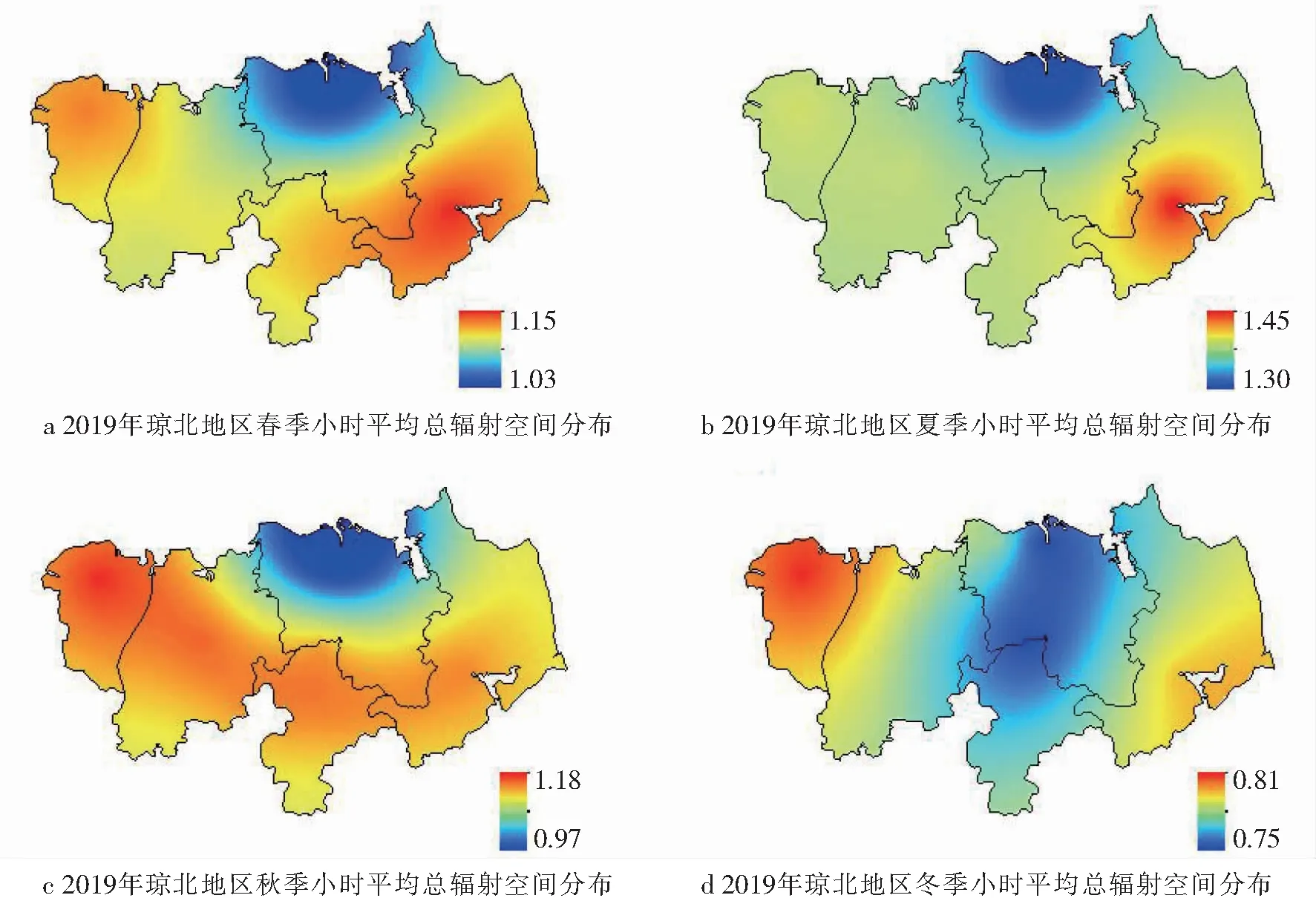
图6 2019年琼北地区春、夏、秋、冬季小时平均总辐射空间分布
辐射是地球的能量主要来源,是影响作物生长发育的主要因素,不同作物习性对辐射强弱变化要求不同,因此研究区域内辐射的日变化具有重要意义.由于夜间没有太阳辐射,对2019年平均日辐射最大值空间分布进行研究,如图7所示.

图7 2019年琼北地区年日平均小时最大值总辐射空间分布
从图7可以看出,总辐射日最大值的空间分布也呈现了北部低东西高的特征,日最大值均值在2.09~2.28 MJ·m-2范围内;在北部和南部的辐射日最大值较小,东西部辐射日最大值较大,其中澄迈和文昌的辐射日最大值较大,几乎都大于2.25 MJ·m-2,临高的辐射日最大值相对澄迈和文昌较小,在2.19~2.20 MJ·m-2之间.说明琼北地区日较差呈现北部和南部偏小,东部和西部偏大的特征.
4 结束语
通过对可能影响辐射变化的气压、气温和相对湿度等气象要素和辐射值的进行相关性分析.选取与总辐射相关系数较高,能表征天气特征的相对湿度和日照时数,构建预测时次当日和历史每日特征向量,并通过灰色关联分析法选取两者间相似度大于0.8当日的本站气压、气温、相对湿度、降水、日照时数和太阳高度角6个气象要素作为模型输入向量,太阳总辐射曝辐量作为输出真值.结果表明,通过相似日筛选的Elman神经网络辐射预测算法对总辐射的预测效果显著,是一种有效的太阳辐射预测算法.根据建立的辐射预测模型,利用气象要素对没有辐射观测仪器站点进行预测,分析海口站周围市县即琼北地区的辐射空间分布,琼北地区辐射空间分布均匀,具体呈现南多北少特征;时间分布上总辐射呈现冬季低夏季高,春秋季居中的特征.
通过相似日筛选输入数据集构建的Elman神经网络模型增加了模型预测的精度,但是在不连续阴天,或者持续无日照太阳辐射较低的时候,模型预测精度有所下降.下一步工作可以考虑接入实况数据,例如三维云数据,进一步提高模型的预测精度,减少预测值与真值之间的相对误差.此外,只选取了琼北地区的国家站的气象数据作为模型输入数据,预报琼北地区的太阳总辐射.在后续研究中,可以考虑区域站数据结合卫星数据预报当地的太阳总辐射量,精细化分析地区的太阳总辐射分布,同时可以结合其他2个辐射站的数据,根据地形特征等因素,预报全省太阳总辐射分布,研究海南省太阳总辐射空间分布.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
现代电力(2022年2期)2022-05-23
保定学院学报(2022年2期)2022-04-07
成都信息工程大学学报(2021年3期)2021-11-22
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
数学学习与研究(2018年15期)2018-11-12
北京航空航天大学学报(2017年12期)2017-04-23
现代农业科技(2016年22期)2017-03-24
现代农业科技(2016年21期)2017-03-06
