
医学影像处理的深度学习可解释性研究进展
2021-01-26 07:22:16陈园琼邹北骥张美华廖望旻黄嘉儿朱承璋
浙江大学学报(理学版) 2021年1期
陈园琼 ,邹北骥 ,张美华 ,廖望旻 ,黄嘉儿 ,朱承璋
(1.中南大学计算机学院,湖南长沙410083;2.吉首大学软件学院,湖南张家界427000;3.“移动医疗”教育部-中国移动联合实验室,湖南长沙410083;4.机器视觉与智慧医疗工程技术中心,湖南长沙410083;5.中南大学文学与新闻传播学院,湖南长沙410083)
0 引 言
医学影像在临床应用、生命科学研究等方面具有重要作用。不同形态的医学成像技术通过采样或重建产生离散型图像,将数值映射到空域,形成表达解剖区域内部结构或功能的医学图像。从X射线、超声到计算机断层扫描(computed tomography,CT)、磁 共 振 成 像(magnetic resonance imaging,MRI)、正电子发射型计算机断层成像(positron emission computed tomography,PECT),成像技术的每次创新都是对医疗对象观察手段的丰富和观察能力的提高,在改进医疗手段、提高医疗水平等方面发挥了至关重要的作用。计算机科学的发展和进步极大地提高了医学影像的解读能力,深度学习[1]是机器学习的重要研究方向之一。近年来,深度学习在计算机视觉领域取得了令人瞩目的成就,将深度学习应用于医学影像的病灶目标分割、定位、检测、图像配准和融合等亦取得了显著进展,已实现对病灶的快速诊断,诊断时间大大缩短。
基于深度学习的医疗诊断虽然已取得巨大进展[2],但在临床实践中尚面临一些亟待解决的难题。
(1)数据驱动的深度学习算法,其泛化能力经常受质疑与挑战。样本数据不足、训练样本分布与真实样本分布不一致,均会导致算法性能急剧下降。不同于有强大数据集的自然图像处理,在极少医学样本场景下训练得到的模型能否用于高精度敏感的医学影像分析是其中被质疑的点之一[3]。据《华尔街日报》于2019年1月26日的报道,谷歌用于诊断糖尿病视网膜病变的深度学习算法,在印度的实验室与医院遭遇了挑战,其原因是印度医院的成像设备较差,谷歌开发的算法无法有效识别低质量影像。
(2)对抗样本引发人们对深度学习稳健性的深层次担忧。对抗样本是指受轻微扰动的样本,其可导致模型以高置信度输出错误结果。这一“荒谬”现象的出现迫使人们探寻深度学习方法,以得到稳健的输出结果。

图1 青光眼筛查时医生诊断与系统诊断的差别Fig.1 The difference between doctor diagnosis and system diagnosis
(3)深度学习可自动提取抽象特征,其预测过程是端到端的,只有直接结果,无法提供诊断依据和病因病理,不能被完全信任和接受。比如对青光眼的筛查(见图1),医生可通过眼压检测、视野检测和人工检查视盘(optic disc)等检测方式,结合患者的临床症状和病理报告诊断病症,给出病因病理;然而深度学习通过神经网络学习大量有标记的样本数据,提取特征,得到的模型在临床实践中难以解释其输入与输出间的关联性或因果关系,缺乏过程的可解释性,难以支持医疗诊断或医学研究中的因果推理[4]。
可解释性已成为深度学习在医学影像处理领域发展与应用的难题。结合深度学习在医学影像处理中的发展趋势,首先综述了深度学习在医学领域的应用现状及面临的问题,然后探讨了深度学习可解释性的内涵,并重点关注深度学习可解释性研究方法的进展和具有特殊性的医学影像处理的深度学习可解释性研究进展,最后探讨了医学影像处理深度学习可解释性研究的发展趋势。
1 深度学习可解释性的问题与机遇
深度学习的很多模型,如卷积神经网络(convolutional neural networks,CNN)、深度信念网络(deep belief nets,DBN)等已被广泛应用于医学影像处理。研究者通过深度学习方法自动提取脑部图像中阿尔兹海默症(Alzheimer disease,AD)的特征信息,捕捉由AD引起的脑部变化[5],结合其他多模态信息诊断轻度认知障碍(AD/MCI)[6]。通过深度学习自动检测肺癌细胞[7],将影像块和预训练的CNN相结合,完成乳腺癌组织分类[8]。通过CNN将低级影像数据转化为与非影像模态数据相融合的特征向量[9],共同学习神经网络所有模态之间的非线性相关性,完成对子宫颈发育不良的诊断预测。通过CNN自动提取微动脉瘤特征[10],进行视网膜血管分割[11]、视网膜病变分类[12]等。这些辅助诊断系统均通过深度学习完成对疾病的快速筛查和诊断,大大缩短了诊断时间,在降低诊断成本的同时,准确率亦有较大提升。
基于深度学习的医学影像处理技术取得了巨大进展,与此同时,引发人们对深度学习可解释性的思考与研究。笔者调研了2016—2020年发表在机器学习与人工智能(artifical intelligence,AI)相关会议(CVPR,ICML,NIPS,AAAI,ICCV,IJCAI)以及国际顶级医学影像学术会议MICCAI上的关于深度学习可解释性以及医学影像处理的深度学习可解释性的研究论文,对题目中包含关键词explain,interpretable,understanding的相关论文做了统计分析,结果如表1所示。

表1 2016—2020年会议论文统计Table 1 Statistics of conference papers from 2016 to 2020单位:篇
经筛选,共得到相关研究论文212篇。总体来说,深度学习可解释性正逐渐被认为是亟须解决的重要问题。2015年之前,几乎无深度学习可解释性相关研究论文,2016年,相关研究论文仅11篇,2018年,增至78篇,2019年,深度学习可解释性依旧是研究热点。在MICCAI上,医学影像处理的深度学习可解释性也逐渐受关注。2018年,MICCAI录用了3篇与深度学习可解释性相关的论文,2019年,MICCAI专门设置工作组,讨论医学影像处理的深度学习可解释性。
2 深度学习可解释性的内涵
目前,对可解释性并没有统一的定义,广义的可解释性是指在需要了解或解决一件事情时,可获得足够多可被理解的所需信息。BIRAN等[13]和MILLER[14]将可解释性定义为人类理解决策原因的程度。模型的可解释性越高,所做的决定或预测越容易被人理解。在机器学习的国际顶级会议上,有学者从方法和目标等角度给出了对深度学习可解释性的多种理解。如在2017年第三十一届神经信息处理系统进展大会(NIPS)上,时间检验奖获得者RAHIMI提出,将深度学习应用于某些领域会引发对透明度和信任度的质疑。BIRAN等[13]认为,AI的关键是解释决策、推荐、预测或行为的能力和过程,如果系统的操作被理解,那么系统是可解释的。另外,可解释性是以人类为核心的解释过程,最终目的是使人类理解,所以,人脑神经元的连接方式、运作模式以及信息处理方式都可能影响对深度学习可解释性的研究。
传统的基于统计分析的机器学习模型,其可解释性较好,如传统的线性模型可以从权重的角度理解神经网络中的参数含义及其重要程度和波动范围;用户友好的决策树模型在做每个决策时都会通过决策序列展示其决策依据;基于信息理论的变量筛选标准有助于理解模型决策过程中哪些变量的作用更显著;基于规则的专家系统依赖特定领域的分类知识库和单独的策略库,根据上下文逻辑关系进行解释[13]。然而,深度学习模型的结构越来越复杂,对于由多个非线性函数叠加的多层神经网络模型,很难解释其决策依据,难以直接理解神经网络的“脑回路”。因此,通常将AI可解释性的目标[15]分为以模型为导向和以用户为导向两种。

图2 人工智能可解释性的两大目标[15]Fig.2 Explain two goals of AI
2.1 以模型为导向的可解释性
研究者在对机器学习模型进行调试时,将其看作黑匣子。只看到输入和输出,很难理解黑匣子内部的工作原理,造成难以预测和调试机器学习模型的输出结果等,最终影响对机器学习模型的深入理解及结果的进一步提升。模型的可解释性重点关注透明度和信任度。
2.2 以用户为导向的解释质量
在很多领域,当将结果呈现给普通用户时,需要进行解释。普通推荐系统[16]通过收集各用户的信息偏好,利用不同的信息源为其提供项目预测和推荐,通常只给出简单又直观的理由,无法令用户信任。为使用户更好地理解预测结果和推荐结果,一些可解释性推荐系统[14,17]将用户纳入可解释范畴,让用户了解做相应决策的原因,从而极大提高推荐结果的有效性,增强决策的说服力。在计算机辅助诊断系统中,复杂的深度学习模型解释决策的能力虽令人满意[18],但其对结果的可读性、有效性的解释质量尚不高。
人类认识世界、探索事物的客观规律主要基于因果推断的思维模式。基于小样本得到的规律[19]可较好地被推广至复杂环境。实践证明,科学探索中基于因果推断所发现的客观规律具有极强的泛化能力。
基于上述理解,笔者尝试将特定领域的深度学习可解释性概括为:具备特定领域知识的人在认知负担可承受的范围内,掌握深度学习模型输入与输出之间因果关系的程度,包括主观、认知和客观3个因素,其内涵如表2所示。
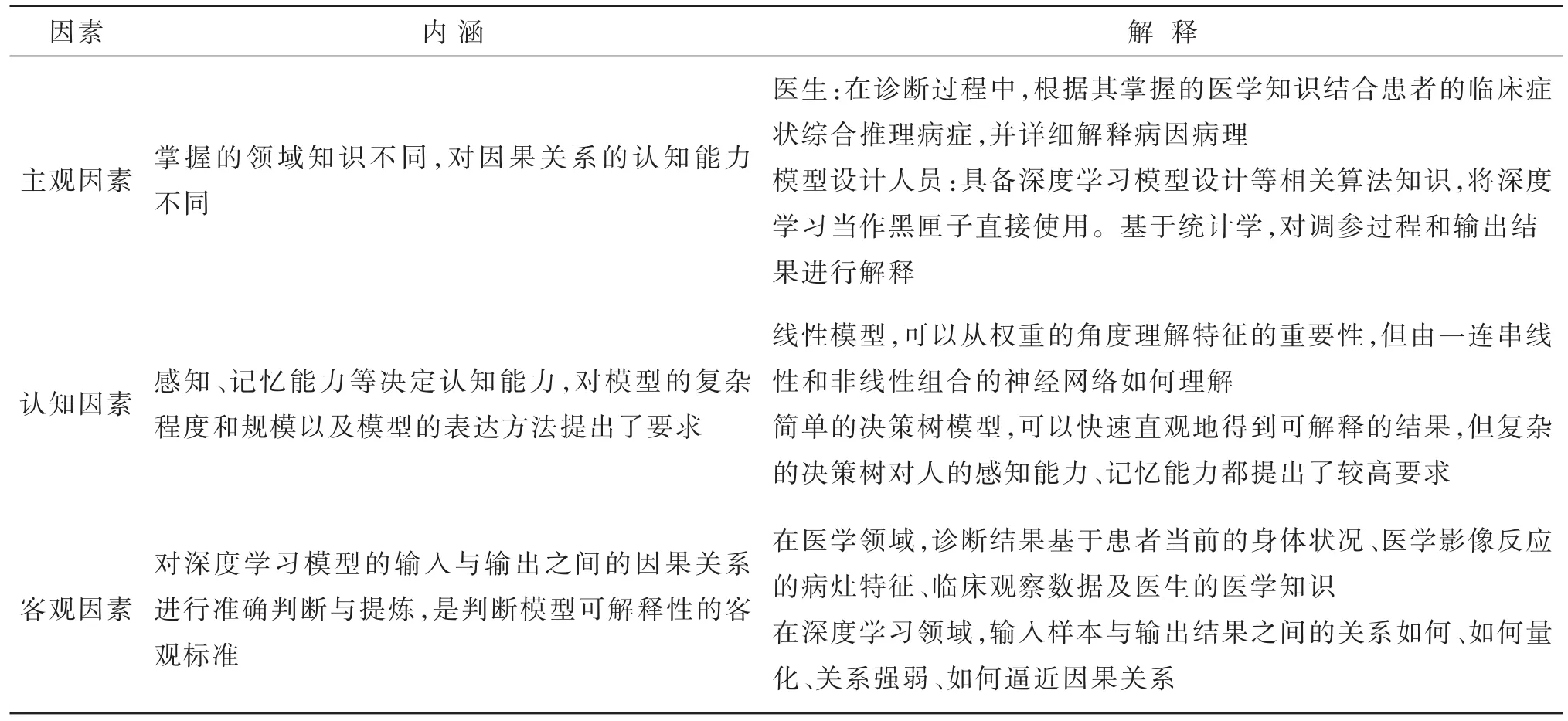
表2 可解释性内涵Table 2 Three factors involved in interpretability
3 深度学习可解释性的研究方法
深度学习模型由输入、中间隐层、输出3部分组成,其中,中间隐层的每个神经元均由上一层的线性组合和一个非线性函数组成,虽然已知参数的值和训练过程,但因中间隐层高度非线性,无法理解深度学习模型的具体含义和行为。深度学习的目的是从样本数据中发现知识和规律并解决实际问题,而神经网络神经元的分层组合形式,则从物质组成的视角理解神经网络的运作方式,在此过程中,如果能提供可被理解的数据信息或模型信息,则有助于找到理解和解决问题的方法。以上均可归纳为可解释性研究方法,深度学习可解释性研究方法的主流方向见表3。

表3 深度学习可解释性研究方法的主流方向Table 3 The mainstream direction of interpretability in deep learning
3.1 可视化
可视化是将大型数据集中的数据以图形、图像、动画等易于理解的方式展示,是探索深度学习可解释认知因素最直观的方法之一。通过将抽象数据映射为图像,建立模型的可视表达,降低研究人员对深度学习模型的认知难度,理解深度学习的内部表达,从而降低模型的复杂度,提高透明度。现有研究主要集中于输入数据可视化和模型内部可视化两方面。
3.1.1 输入数据可视化
深度学习可从数据中发现知识和规律,在建模之前对输入的样本数据进行可视化分析,可快速、全面了解数据的分布特征,便于理解问题。MIKOLAJ等[20]用最大均值差异(maximum mean discrepancy,MMD)方法,分别找到具有代表性和不具代表性的数据样本,更好地理解数据分布。
3.1.2 模型内部可视化
深度学习的黑箱性主要在于中间隐层的高度非线性。现有研究通过可视化内部神经元[21-23]、可视化滤波器[24,25]、可视化中间隐层[21,26]提升黑匣子的透明度。ZEILER等[21]通过激活最大化和采样2种方法,对深度神经网络内部神经元进行可视化,尽可能找到被激活的过滤器的最大化输入图像,该图像可有效显示特定像素区域,且是可解释的。同时,通过反池化-反激活-反卷积的逆过程对卷积网络内部进行可视化,发现低层次对应边角或色彩特征、纹理特征,高层次对应狗脸、车轮等局部部位,对物体整体识别能力较强。MAHENDRA等[22]通过特征反演学习图像,利用自然图像先验的视觉清晰度重建网络的中间激活。清华大学朱军团队提出的可视化系统 CNNVis[23],通过提取神经元的特征,将各神经元连接,对神经元集群进行可视化。谷歌大脑的特征可视化工具Lucid[25]能展示深度学习网络内各个神经元及其分工,帮助了解网络内神经元如何用作物体(如按钮、衣服和建筑)检测器、如何在网络层之间堆积以及如何变复杂。这些可视化方法不仅能展示检测结果,还可供直观地观察神经网络中各神经元的输出贡献大小。
可视化的直观表达在一定程度上降低了深度学习模型的复杂度,提升了模型的透明度,但无法与更高级的语义相关联,对人类的认知能力要求很高,仍存在一定的解释难度。
3.2 语义化
语义是指数据的解释和逻辑表示。语义化是指通过量化或学习等方法解释深度学习模型中隐藏层神经元具有的语义。
3.2.1 神经元或层与语义相关性的量化
为理解网络所学到的语义,通过分析神经网络内部神经元或中间隐藏层与人类语义的相关性,并对其进行量化,BAU等[26]提出了网络切割(network dissection,ND)方法,首先,通过收集来自不同数据源的分层语义标注数据,建立包含大量视觉语义的数据集;然后,利用交并比(intersection over union,IoU)对隐层单元与语义的相关性进行量化,最终从中间隐藏层学习关于颜色、材质、材料、部分、物体、场景等语义。FONG等[27]通过研究语义与相应过滤器的向量嵌入关系,探讨多个过滤器组合表示的语义。KIM等[28]通过概念激活向量最大化识别过滤器所编码的语义。OLAH等[29]将特征可视化与语义词典相结合,研究了决策网络以及神经网络内部对输出的影响机制。
3.2.2 编码学习语义
神经网络内部神经元通过学习语义,在语义层面对神经网络进行诊断和修改,使其与人类的知识框架相匹配,具有清晰的符号化内部知识表达。SABOUR等[30]创建了胶囊网络,其内部神经元活动表示图像中出现的特定实体的各种属性,并在MNIST数据集上对其进行了训练,证明胶囊网络能编码一些特定的语义,如笔画的尺度、厚度、倾斜角度、宽度和平移等。信息最大化生成对抗网(information maximizing generative adversarial net,InfoGAN)[31],将网络的生成器输入变量分为不可压缩噪声和潜在语义代码。MNIST数据集[32]成功编码了数字类型、旋转和宽度语义信息,CelebA数据集[33]编码了面部数据集中的情感部分,SVHN数据集[34]编码了照明条件和平板环境,3D face数据集[35]编码了方位、眼镜、发型和情绪,3D chair数据集[36]编码了宽度和三维旋转信息。上述数据集均通过编码内部神经元学习语义,较容易理解模型内部的表达。
深度学习模型实现端到端学习,要求解释深度学习模型从低级语义到高级语义的生成过程,这不仅有利于理解神经网络的具体结构,而且可辅助深度学习将调参真正变得可控、可解释。
3.3 逻辑关系量化
逻辑关系量化是研究事物之间关系的一种判断方法。事物内部或各事物间的关系有相关、并列、主次、递进以及因果等,关系的强弱可说明事物内部或各事物间的逻辑推理能力。比如输入与输出之间的因果关系具有极强的推理能力,比普通的相关性更能展现可解释性。目前从逻辑关系出发的研究主要有端-端逻辑关系、中-端逻辑关系和模型内部神经元的相关性3种。
3.3.1 端-端逻辑关系
为找到图像中对深度学习结果影响最大的像素,通过研究输入层变化对输出结果的影响,判断输入与输出之间的逻辑关系;利用反向传播[21],结合梯度、网络权值或特定层上的激活[37-38]跟踪信息,由网络输出跟踪其输入或中间隐层;SELVARAJU等[38]通过优化过程过滤梯度,进一步提取用于特定预测证据的细粒度区域。这些方法的核心是通过详细搜索或优化找到最具代表性的扰动。另外,通过输入扰动网络、有规则或随机遮挡[21,43]部分样本,分析 遮 挡 对 各 方 法 输 出 的 影 响[21,39-41]。 例 如 FONG等[40]以元学习作为解释因子建立扰动,以优化空间扰动掩码,通过扰动试验,找到对输出结果影响较大的特征,从而逐步建立线性可分模型[41]。由于不可能看到所有扰动,因此需找到具有代表性的扰动,KOH等[42]利用统计学影响函数,分析了增加训练样本权重或对训练样本施加轻微扰动对特定测试样本损失函数的影响,以更好地理解深度学习模型的预测效果。
以上方法均是通过探究输入与输出的映射关系解释结果的。这种衡量变量/样本重要性的敏感性方法将可解释性归于输入特征或样本,更容易被理解,但也易导致相同预测结果的不同可解释理由,且稳定性较差。这些方法均基于模型不可知,未考虑模型的内部结构,也未打开黑匣子,忽视了对中间隐层结构的研究,无法了解模型内部的工作机理,其逻辑推理基于两端,对内部的可解释能力不足。
3.3.2 中-端逻辑关系
研究深度学习模型的中间隐层与输出之间的逻辑关系是进一步挖掘模型内部工作机理的必要过程。一些研究用更简单、可解释的模型通过局部逼近深度学习的中间隐层,与输出建立逻辑关系。如RIBEJRU等[43]提出的基于梯度方法及局部可解释模型不可知论解释(local interpretable modelagnostic explanations,LIME)方法,通过线性模型在预测结果附近建立局部中-端逻辑关系。WU等[44]利用学习网络,通过决策树的正则化逼近进行深度神经网络学习。ZHANG等[45]提出端-端学习的可解释CNN,用过滤器添加先验约束,实现训练后自动回归某特定对象(如鸟的头、喙、腿),在卷积层顶层中通过分离式表征进行目标分类,并将神经网络的表征提炼为决策树结构[46],由粗到精对隐藏在CNN全连接层中的各决策模式编码,用决策树逼近最终决策结果。HOU等[47]利用具有解释序列数据的有限状态机(finite-state machine,FSA)学习循环神经网络(recurrent neural network,RNN),将学习结果作为可解释结构。WU等[48]用与或图(ANDOR graph,AOG)解析算子代替在CNN特征区域(regions with CNN features,RCNN)中常用的池化算子。在检测过程中,用从AOG中实时得到的最佳解析树解释包围框(bounding box)。另外,有研究在强化学习过程中,通过学习因果模型[49]结构,对感兴趣的变量的因果关系进行编码,并用基于因果模型的反事实分析方法解释强化学习。
通过以上可解释的方法逼近各深度学习模型的内部机理,建立局部与输出的逻辑关系,客观解释性较强。
3.3.3 神经元之间的关系
研究内部神经元之间的关系对理解深度学习模型的内部机理具有重要意义。通过识别关键数据路径[50]和利用分段线性函数[51]分析模型相应层的功能,检测训练过程中神经元的激活情况,寻找不同神经元之间的关系。ZHANG等[52-53]将CNN转化为图模型,通过自动学习具有上万个节点的解释图,解释CNN的层次与知识结构。解释图中的每个节点表示CNN中某卷积层对象的部分模式,用知识图谱解释决策。这类方法通过探求复杂网络内部神经元的相互关系,了解深度学习内部的训练过程和决策过程,探究未知神经网络组件之间的关系,但此关系仅是潜在因果关系的一部分,神经网络的拓扑结构依然复杂。
深度学习模型结构复杂,参数庞大,认知负担重,可视化方法以及语义量化方法并不能有效解释模型所做决策的因果推理,因此,用因果推理关系的方法分析客观因素,有助于了解深度学习模型的训练和决策过程,实现模型内部的透明化。
3.4 交互式
交互式指通过领域专家与深度学习过程的交互,理解深度学习内部的决策过程。通过可视化工具[26,43]进行人机交互。人对物体、环境的交互逻辑比对颜色、纹理等低级语义的交互更敏感。将深度学习系统模块化和定制化,先单独训练各类高级语义的深度学习模块[54-55],再根据认知逻辑将这些模块进行组合,最终完成特定任务。BAU等[55]提出深度干预神经网络内部的训练和验证,以GAN为基础,在自然图像中对神经网络的内部神经元进行模块化处理,在模型诊断时,结合可视化工具直接激活深度网络或先激活深度网络中的神经元或神经元组,通过交互式的可解释性实验探索,一定程度上实现了深度学习模型内部的模块化和定制化。
4 医学影像处理的深度学习可解释性研究
在医学领域,病症的检查诊断大多需参考医学影像,而医学影像高度依赖成像设备和成像环境。相对于自然图像,医学影像更复杂,具体表现在:(1)影像种类多,差异大,难以融合;(2)影像大多是非可见光成像(如X射线),通常显示某种特殊信号的强度值,信噪比较低;(3)病灶等目标与非目标区域之间的颜色、灰度、纹理等外观差异较小;(4)影像像素大,目标自身缺乏固定的大小、形状、灰度和纹理等外观特征,且因个体、成像原理、成像环境等不同差异较大;(5)因受成像原理和成像环境的影响,影像中含多种伪影。
同时,医学数据以多种模态呈现,每种模态各有所长、相互关联,如不同疾病之间,不同病症之间,一种疾病与多种病症之间,多种疾病与同一病症之间等,极大地限制了对病症的预测和诊断。
将深度学习引入医学领域,极大地提高了对医学影像的特征提取能力、筛查水平和诊断效率。但受数据驱动的深度学习辅助疾病诊断与筛查系统只能输出单一的诊断结果或筛查结果,无法给出决策依据,难以被采纳,且对算法人员不友好。尽管深度学习可解释性研究已取得大量令人瞩目的成果,但大多聚焦于特定模型,其可解释性也侧重于算法设计人员而非医生、医学研究者和患者,极大地限制了医疗诊断系统的临床应用。
面向医学影像处理的深度学习可解释性研究能够为医学知识和疾病辅助诊断与大规模筛查系统的深度融合提供有效且可交互的途径,有力推动医疗的智能化。不同于常用的深度学习可解释性研究方法,医学影像处理的深度学习可解释性研究方法不仅受数据的影响,还与医生的学识有关,因此,两者在研究方法上既相似又有区别,主要区别有:
(1)在可视化方法上,深度学习的可解释性重点关注样本数据规律的可视化以及模型内部的可视化。而医学影像重点关注的是病灶区域,要求读片直观。
(2)在语义化方法上,深度学习的可解释性重点关注模型内部神经元或中间隐藏层所表征的语义信息,而医学影像大多需要用自然语言模拟医生的决策过程,在输出诊断结果的同时需生成可理解的决策过程和决策结果,如初级诊断报告等。
(3)在逻辑关系量化上,深度学习的可解释性重点关注输入样本数据与输出结果之间、模型内部神经元之间、模型内部神经元与输出结果之间的逻辑关系,而医学影像更多地关注用医学知识解释诊断结果。
最近,对医学影像处理的深度学习可解释性研究趋势主要有:
4.1 病灶区域可视化
病灶区域可视化主要指通过热力图[56]、注意力机制[57-59]等方法,结合其他手段[60-61],找出病灶区域并提供可视化证据,探究为决策提供依据的医学影像像素。如PASCHALI等[56]利用模型激活细粒度的Logit热力图解释医学影像决策过程。LEE等[57]根据头部CT扫描数据检测急性颅内出血,提出了一个可解释的深度学习框架,通过模拟放射科工作流程并进行迭代,生成注意力图,利用类激活映射[37]从训练数据中检索预测基础。LIAO 等[58]基于注意力机制的弱监督诊断青光眼(见图3),为青光眼的自动检测提供了可视化解释依据(见图4),在自动检测青光眼过程中,系统给出了3种类型的输出:预测结果、注意力图和预测基础,增强了结果的可解释性。GARCIA-PERAZA-HERRERA 等[59]在检测早期鳞片状细胞肿瘤时,以嵌入式激活图表示侧重结果的可解释性并以其作为约束,通过可视化方法,提供较详细的注意力图。在基底细胞癌变检测过程中,设计了一个解释层作为数字染色方法,将在诊断决策中起重要作用的图像区域聚集在一起[60]。BIFFI等[61]在原始图像上通过可视化方法量化学习病理的特异性,用特定任务的可解释特征区分临床条件,使决策过程透明化。
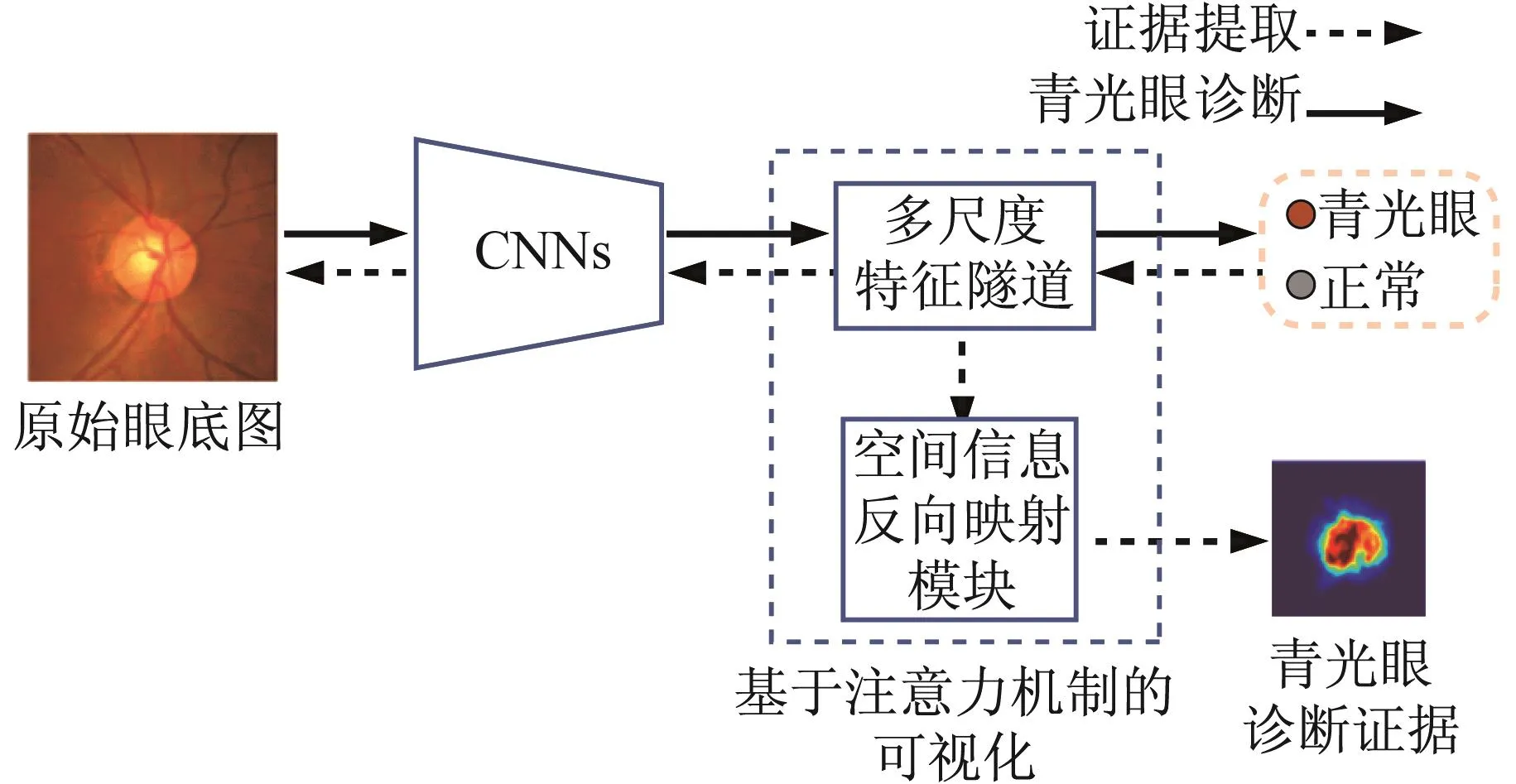
图3 青光眼诊断可视化模型[58]Fig.3 Diagnosable visual models of glaucoma
通过可视化方法在真实图像中定位或量化区域,提供可视化证据,提升对深度学习模型内部表征能力的感知,理解模型的决策依据。

图4 青光眼可解释性的定性与定量表达[58]Fig.4 Qualitative and quantitative expression of glaucoma interpretability
4.2 病历语义化
目前,将医学知识引入模型,并与神经元相关联的研究尚不多见,大多用自然语言处理方法将病历信息[62-67]融入图像处理过程,通过多模态医学信息,将医学影像直接映射为诊断报告,给出可理解的诊断依据,见图5。
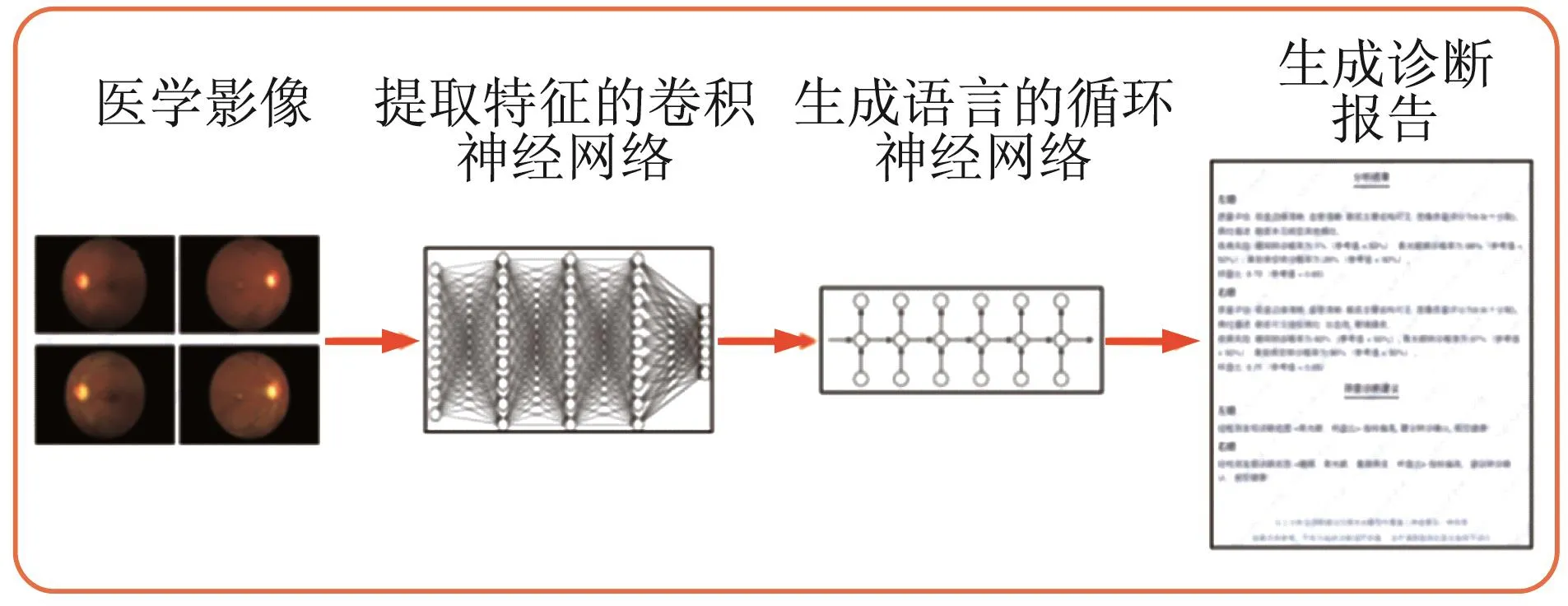
图5 医学影像与诊断报告生成可解释的诊断报告Fig.5 Medical imaging and diagnostic reports generate interpretable diagnostic reports
ZHANG等[62]提出多模态医学影像诊断模型,将影像模型和语言模型统一在深度学习框架中,在医学影像和诊断报告2个模态间建立映射关系,这样,深度学习模型不仅能根据影像给出诊断结果,还能模拟医生诊断并编写诊断报告,提供可理解的诊断依据。基于相同方法,WANG等[63]注意到放射科医生在阅片时,会观察不同疾病的症状,例如肝转移会蔓延至局部淋巴结或身体其他部位,所以在诊断报告中包含与其他疾病的关联关系,基于此,首先从文本中获取先验领域知识,然后与这些症状进行关联,开发了多目标CAD框架,用于检测多种疾病,不仅改进了深度学习模型的性能,而且提供了更精准的诊断报告。在预测高恶性肿瘤时,SHEN等[64]通过量化诊断特征解释了以专家知识驱动的方式形成的低级放射科医师模型的语义特征。KIM等[65]利用GAN(由可解释的诊断网络和合成病变生成网络组成)学习肿瘤与标准化描述之间的关系,完成可解释的乳腺肿块计算机辅助诊断。ZHANG等[66]提出的MDNet模型集合多种网络,设计了一种基于语义和视觉可解释的医学影像诊断网络,生成影像的表达,用长短期记忆网络(LSTM)提取语义信息,并生成更加细致的逐字影像关注区,但模型复杂度较高。FAUW等[67]进一步改进了该模型,在2个不同的神经网络间插入可解释的表征,并将二者结合起来,先利用分割网络从频域光相干断层扫描(OCT)影像中找出病灶特征,输出分割特征图,然后,将分割特征图作为输入,利用带有确诊和最佳转诊的组织图训练分类网络,进行分类,输出诊断概率和转诊建议,实验结果与专家临床诊断结果相当,是医学影像可解释性研究取得的一个重要里程碑成果。
在对疾病进行辅助诊断和筛查时,将不同的深度学习模型与医学知识深度融合,不仅能输出诊断结果,还能提供诊断决策依据,供验证和对比。若诊断决策与深度学习不一致或与所依据的医学知识不一致,则可通过进一步分析做出更好的决策;若医生的决策更好,可对深度学习模型进行调整,若深度学习模型的决策更好,则可丰富医生的知识,使其做出更好的决策。
4.3 因果推理病因
深度学习可解释性的逻辑关系在于针对模型设计人员进行数据的因果推理,但是基于哪些因素得到的辅助诊断结果无人知晓。
NIU等[68]借鉴传染病学原理中的科赫法则探索医学影像卷积神经网络的可解释性,科赫法则(Koch’s postulates)(见图 6)通过将某种病变与特定的病原体建立联系,鉴定传染病,是传染病病原学鉴定的金标准。

图6 科赫法则[68]Fig.6 Koch"s postulates
另外,还有一些学者将其他领域的方法引入医学影像的可解释性研究。如LI等[69]在功能性核磁共振成像(fMRI)识别自闭症谱系障碍的检测中,结合影像结构和博弈论中的shapely值解释了如何通过共享变量引擎(SVE)查看单个特征;ALAA等[70]利用深概率模型获取复杂的疾病进展,同时利用注意力机制提高临床可解释性。GOHORBANI等[71]提出用基于语义的神经网络内部状态进行解释,用方向导数量化模型,预测由激活向量学习的底层高级语义。通过眼底影像预测糖尿病视网膜病变(DR)级别,测试微动脉瘤(MA)、全视网膜光凝术(PRP)等治疗方法在不同DR级别上的重要性。
以上方法大多通过引入其他领域判断因果关系的方式建立模型的可解释基础,具有一定的可解释性,但其与医学知识的融合尚不够。基于医学知识的因果判断方法尚需进一步探讨。
5 总结与展望
现阶段,深度学习模型的性能得到极大提升,但模型的复杂性几乎同步提高,可解释性成为AI发展的一大难题,虽然深度学习的可解释性研究取得了一定进展,但仍待进一步探索,特别是对医学影像深度学习的可解释性研究还处于初级阶段。因此,基于对当前研究实践的分析和理解,笔者认为医学影像深度学习的可解释性研究未来可从以下几个方面展开。
5.1 可视化病灶特征
研究深度学习的透明度,目前可视化输入数据、可视化中间隐层、可视化高卷积层的特征图等方法在一定程度上均增加了深度学习模型的透明度。通过改进深度学习模型内部的可视化,并将可视化特征图与医学知识融合,对模型所做决策的依据进行深入挖掘,以提高医学影像处理的深度学习可解释性,这对降低模型的认知难度,提高认知能力具有非常重要的意义。
5.2 语义化医学图像
现有的大多数语义可解释方法都将图像识别与自然语言处理相结合,生成可被理解的诊断报告。自然语言处理用的是深度学习方法,相当于用黑匣子解释黑匣子,虽然可以得到语义信息,但模型不可知。目前在迁移学习、语义分割等方向上的发展极大促进了深度学习的可解释研究,同时,将模型内部的语义化方法与多模态的医学数据相结合,可能是语义化医学影像的另一发展途径。
5.3 医学规则上的因果推理
在逻辑推理基础上,知识图谱作为可读性高的外部知识载体,为提高算法的可解释性提供了极大可能。用影像神经网络构建医学诊断知识图谱,与深度卷积神经网络的影像特征提取能力相结合,提升模型的领域知识匹配能力和知识逻辑推理能力,有可能将AI医学诊断从直觉学习向逻辑学习推进。
5.4 交互式研究
如何在领域专家和模型设计人员与深度学习模型之间建立交互,对提升可解释性至关重要。深度干预神经网络内部训练阶段和验证阶段的设计,通过模块化神经网络内部神经元,利用可视化工具,通过交互探查深度学习的各阶段,找寻交互式操作对模型诊断的影响,实现深度学习模型内部模块化和定制化。通过模块化进行深度特征提取,如果高级语义定义可顺利完成,特别是由医生完成,则将在贴近认知层次基础上丰富因果逻辑的客观性,从而极大提高深度学习的可解释性。
6 结 语
深度学习的超强性能促进AI应用的巨大发展,AI模型可帮助医生缩短阅片时间,加快诊断,然而,算法结论的可解释性变得越来越重要,对算法决策过程的了解,有助于建立人机间最大程度的理解和信任。近年来,可解释性问题广受政府、工业界和学术界的关注。美国国防部高级研究计划署(DARPA)对可解释 AI项目(explainable AI,XAI)给予了资助,我国国务院在《新一代人工智能规划》中提出,实现具备高可解释性、强泛化的人工智能。可以预料,当AI具有可解释性时,其高效的诊断速度和精准的诊断水平,可使医疗从业人员从重复繁杂的诊疗任务中解脱出来,智能诊断系统在为病人提供快速诊断的同时,提供可解释的诊断依据。
基于可解释性的定义,介绍和分析了医学影像深度学习可解释性的研究现状和进展,重点讨论了现有的深度学习可解释性研究方法和医学影像处理的深度学习可解释性研究方法,并简单讨论了医学影像处理深度学习可解释性研究的发展方向,希望对相关领域研究人员提供一定帮助。
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09 13:54:24
自然杂志(2021年6期)2021-12-23 08:24:46
中国临床医学影像杂志(2021年10期)2021-11-22 07:46:38
中国医学影像学杂志(2021年6期)2021-08-13 08:43:08
法律方法(2021年4期)2021-03-16 05:35:16
现代装饰(2018年5期)2018-05-26 09:09:01
文教资料(2018年30期)2018-01-15 10:25:06
传播力研究(2017年5期)2017-03-28 09:08:30
中国宪法年刊(2016年0期)2016-05-20 09:17:00
电源技术(2015年5期)2015-08-22 11:18:38
