
排序支持的交互数据分类算法及其应用
2021-01-26 07:22邓惠俊
浙江大学学报(理学版) 2021年1期
邓惠俊
(万博科技职业学院智能信息学院,安徽合肥230031)
0 引 言
在大数据时代,数据分类是最基础的数据分析技术和任务之一。虽然相关学者已经提出了很多自动数据分类算法,但这些算法并不适合所有应用场景,而且以“黑盒系统”形式存在的自动分类算法影响其可解释性和可信度,对诸如图像、视频等高维复杂数据更是如此[1]。由于用户倾向于根据高层特征解读信息、度量相识度,而自动分类算法则依赖底层特征,所以二者间易形成语义鸿沟。允许用户参与分类过程,将用户的领域知识融入分类算法,有助于提高分类的可解释性和可信度[2-4]。
近年来,基于机器学习的分类算法,尤其是基于深度学习的分类算法在很多领域表现优异,已经成为主流分类算法[5]。基于机器学习的分类算法从训练样本中学习构建分类规则,首先,依据用户的领域知识制作训练样本,使其蕴含用于分类的领域知识,然后,通过训练将领域知识间接融入分类算法,从而部分克服语义鸿沟问题。但基于机器学习的分类算法需要足够多的高质量训练样本,而大量高质量训练样本并不易得,甚至对很多探索式数据的分析,起初根本无训练样本。所以如何获取高质量训练样本备受关注。
对于难以获得大量标注数据的问题,主动学习有助于通过仅标注信息量较高的数据,达到减少标注工作量的目的[6]。文献[7]提出基于主动学习的交互式分类算法构建过程,首先,在初始分类算法基础上,通过主动学习不断推送对学习算法有价值的数据供标注,然后,进一步优化分类算法,接着,推送新的数据,如此循环直到获得满意的分类算法。其基本思想是用少量高质量训练数据获得与大量随机选择的训练数据性能相当的分类算法,减轻标注数据的工作量和计算负担[8],而且通过交互参与分类算法的构造过程,可将领域知识融入分类算法。
文献[7]中的基于主动学习的分类算法虽然具有交互性,但只能通过简单的数据列表标注类别,或挑选相关/不相关样本等做简单交互。如果能以更有意义和有效的方式呈现数据,则可更好地了解数据集的结构及相互关系,更好地进行决策和交互,进而完成分类。文献[1]提出了一套完整的可视分类算法(visual classification methodology,VCM),将点可视化等技术融入分类流水线,以支持和控制分类过程。
在某些分类问题中,类别和待分类数据都是可排序的,如交警根据基本车况、交通违法记录、交通事故记录等信息将相关车辆分为高危车辆、中危车辆、低危车辆3类,车辆和车辆类别均可根据危险度排序。在某些场合,用户较易确定数据之间的相对顺序关系,但较难确定其具体类别,比如知道车辆A比车辆B危险,但并不清楚车辆的具体类别。基于上述观察,笔者认为将数据顺序关系认知融入分类过程能减轻认知负担,优化分类效果,然而文献[1,7]中的交互分类算法都不支持此模式,为此,本文提出一种排序支持的交互分类算法,该算法同时支持标注数据类别信息和改变数据间的相对顺序关系,充分利用数据类别认知和数据顺序关系认知,达到减轻认知负担、优化分类结果的目的。
论文的主要贡献有:(1)提出排序支持的交互式分类流程,将对数据顺序关系的认知融入分类过程。(2)提出一种候选样本推荐策略,允许在推荐的少量样本中进行类别或顺序标注。(3)提出一种评估分类算法性能的可视化方法,可直观地观察分类算法的性能,帮助决策所需的迭代次数。(4)基于基本车况、交通违法记录、交通事故记录等信息,将车辆分为高危车辆、中危车辆、低危车辆3类,验证了本文算法的有效性。
1 相关工作
1.1 可视交互分类
文献[9-10]提出的交互构建决策树方法,提供了决策树的优化和剪枝算法,并通过关联视图和交互技术综合分析了决策树及相关数据。但这些算法只针对决策树,且采用的是基于属性的可视化方法,难以处理高维数据。
文献[11]提出了基于线性判别分析(linear discriminant analysis,LDA)的 iVisClassifier系统,以提升不同类别之间的分离度,经重新标注后,进行LDA投影,从而允许增量插入用户的领域知识;针对在图像或视频搜索时缺少合适的训练集和难以进行充分标注等问题,文献[12]开发了可视反馈的可视分析系统,允许用户接受或拒绝某个/某些数据用于训练模型,从而将用户知识融入模型,是一种较有效的用户分析工具。
文献[13]用级联散点图展示了分类算法各阶段不同类别数据的分布情况;文献[14]用t-SNE投影算法在2D散点图中展示数据,并提供了标注数据、评估分类结果质量、发现误标注区域(数据)的工具;文献[1]提出了一套通用的交互分类框架,该框架支持渐进式分类各阶段,并创造性地用相似树表达数据间的相似度。
与文献[1,11-12,14]等类似,本文提出一种交互分类流程。基于LDA算法在2D散点图中展示高维数据及其相关性,供观察和交互,从而逐步优化模型。这是由于LDA算法具有监督降维功能,能够在投影结果中体现当前的分类情况,便于观察分类结果的渐进优化过程。本文算法与其他交互分类算法的最大区别在于,本文算法支持输入数据之间的顺序关系,并将其用于优化交互分类。
1.2 可视交互排序
常见系统大多支持交互排序,如微软的Excel和苹果的Numbers均可基于用户定义的公式对表格进行排序,但这类系统主要用于数据的生成、修改和展示,其可根据某列(属性)对所有行(数据)进行排序,并不直接支持多属性排序。
不少系统专门设计了排序交互界面。Table Lens[15]是基于鱼眼的专用高维数据可视化技术,可在单个视图中展示大量数据。与Table Lens类似,ValueCharts[16]和 LineUp[17]可 通 过点 击 、拖 拉 调 整属性权重,创建自定义排序,快速得到排序结果。但这类系统均要求指定相关属性的权重,以创建合适的排序。
也有为特定领域/应用专门设计的排序系统。如文献[18]为增强时序数据的可视化效果设计了相应的排序方法;文献[19]基于文档搜索结果的相关分数进行了可视化排序;文献[20]用node-link同时展示了多种方法的排序结果。
文献[21]在已知数据的相对顺序未知其影响属性时,允许输入部分数据的顺序关系,并基于ranking-SVM将输入的顺序关系应用于全部数据。笔者认同文献[21]的观点,并将文献[21]的方法集成为分类流程,进一步发展了排序支持的交互分类算法。
2 排序支持的交互数据分类算法
为支持同时输入数据类别认知和顺序关系认知,本文设计了如图1所示的界面。在视图(a)中选中实例可标注相应类别,在视图(b)中通过拖拽可指定实例的顺序关系。无论视图(a)还是(b),均只需指定少量实例的类别属性和顺序关系,通过训练SVM和ranking-SVM分别得到分类模型和排序模型,并将分类模型和排序模型应用于所有数据。如果出现数据分类结果与排序结果不一致的情况,则意味着数据分类和(或)排序存在错误,可挑出错误数据将其作为候选标注数据,并在视图(c)中显示,通过颜色编码的方式在视图(a)和(b)中标注,同时,对3个视图中所需标注数据的类别属性或顺序关系给予提示,输入后进一步更新分类模型和排序模型。重复上述过程,直到获得满意的分类模型,交互分类流程如图2所示。为帮助用户更好地判断当前分类模型的性能,还定义了一系列评估指标,如图1(d)所示。

图1 系统总界面Fig.1 System general interface
2.1 数据类别属性展示和交互
通过降维算法将高维数据投影至二维空间,并在2D散点图中展示,帮助了解数据的总体情况。散点图中每个圆圈表示一条数据记录,圆圈颜色表示数据类别。采用半透明方式绘制圆圈,以减少视觉遮挡,改善视觉效果;对系统推荐的候选标注数据,以加粗圆圈轮廓线方式凸显(如图3所示)。在2D散点图中,通过点击选中的某个数据实例进行类别属性标注,完成标注后,点击“更新分类模型”按钮更新。系统将更新后的分类模型应用于所有数据,进而更新推荐数据,刷新视图。

图2 排序支持的交互分类流程Fig.2 Interactive classification process supported by sorting

图3 基于散点图的类别属性展示与交互Fig.3 Display and interaction of category attributes based on scatter plot
2.1.1 高维数据投影
高维数据投影是实现在低维空间(如2D散点图)中进行高维数据可视化的常用方法。常用的投影技术有主成分分析(PCA)、多维尺度变换(MDS)、线 性 判 别 分 析(LDA)、核 判 别 分 析(KDA)、随机近邻嵌入(SNE)、t分布随机近邻嵌入(t-SNE)等[22]。本文采用迭代式分类算法观察分类结果及其变化,并做出相应决策。利用LDA算法的监督性,可基于每轮迭代的分类结果进行新一轮投影。
本文还支持t-SNE投影。考虑初始状态下无分类信息,无法进行LDA投影,只能观察数据本身,并可在LDA和t-SNE 2种投影方式之间切换。图4展示了t-SNE及2种不同分类情况下的LAD投影效果。

图4 投影效果对比Fig.4 Comparison of projection effects
2.1.2 基于SVM的分类模型
支持向量机(supported vector machine,SVM)是一种小样本学习方法,训练和预测的速度都较快,常被用于交互分类。如文献[1,13]采用的均为SVM模型。本文也采用基于SVM的分类模型,当点击“更新分类模型”按钮后,系统基于所标注的类别属性数据训练SVM,最终获得的SVM模型即为分类模型,再将其应用于所有数据。
因没有采用增量式SVM模型[23],本文方法每次都需重新训练SVM。未来可采用增量式SVM模型,以加快训练速度,保持模型的一致性。
2.2 顺序关系可视化和交互
文献[22]提出一种交互式高维数据排序系统Podium,本文借鉴Podium的界面设计和排序方法,采用如图5所示的排序视图展示和交互。主体采用电子表格展示数据的详细属性,通过拖拽调整顺序关系,通过点击“更新排序模型”按钮进行更新。与更新分类模型类似,系统将更新后的排序模型应用于所有数据,进而更新推荐数据,刷新视图。

图5 基于表格的顺序关系展示和交互Fig.5 Table-based order relationship display and interaction
与Podium不同,本文方法在电子表格中用不同的字体颜色编码类别属性,用浅背景色标注推荐数据(见图5)。另外,也可在视图中直接选中数据实例标注类别属性,散点图随之同步更新。
Ranking-SVM[24]直观地将经典二分类SVM模型应用于排序。标准SVM模型的训练集由一个二元 组 (di,yi)构 成 ,其 中 di∈Rm,是 m 维 向 量 ,yi∈{1,-1}表示类别。在排序问题中,因为已知di和dj的顺序关系,所以ranking-SVM构造二元组的方式通常为

根据di和dj,判断SVM模型的优劣,进而将排序问题转换为二分类问题。本文采用康奈尔大学JOACHIMS[24]所实现的 ranking-SVM 模型[25]。
与SVM模型类似,ranking-SVM模型也不支持增量训练。
2.3 候选标注数据的挑选、排序和可视化
候选标注数据指系统推荐标注的数据。标注这类数据能最大限度地优化分类模型和(或)排序模型,不用直接面对大量原始数据,仅需关注少量候选标注数据,可极大地减轻对模型的认知负担。
本文面向类别之间有顺序关系的分类问题,比如按危险度将车辆分为高危车辆、中危车辆、低危车辆3类,此处隐含高危车辆>中危车辆>低危车辆的关系。
2.3.1 候选标注数据的挑选
假设当前有数据集 D={d0,d1,…,dn},数据将被划分为类别 C={c1,c2,…,cL},其中 ci满足 c1>c2>…>cL。如果数据di和dj之间的顺序关系与其所述类别间的顺序关系不一致,即满足
采用SPSS13.0统计分析软件。计量资料均以±s表示。采用配对t检验比较不同测量方法所得的数据,P<0.05为差异具有统计学意义。

则认为当前分类模型和(或)排序模型对数据di和dj的处理不正确,需要将数据di和dj推送给用户,以进一步确认其类别和(或)顺序关系。
如果直接采用式(2)所示的关系,则可能导致推荐的数据过多。如表1所示,假设所有数据的类别都为c1,但数据d1被错误地标注为类别c2,那么所有数据 d1,d2,…,d5都会被选作候选标注数据,导致推荐数据冗余。因此,本文要求di和dj在满足式(2)的同时满足在顺序队列中彼此相邻。具体推荐算法伪代码如下:
输 入 。 二 元 组 序 列 (d1,y1),(d2,y2),… ,(dn,yn),其 中d1>d2>…>dn

表1 候选标注数据例子Table 1 Candidate labeled data example
输出。候选数据点对 (di1,di2),(di3,di4),…
开始
for(i=1;i<n;i++)
{
j=i+1;
{
将(di,dj)加入候选数据点对;
}
}
结束;
2.3.2 候选标注数据的排序
上述算法在迭代之初可能会出现较多候选标注数据,因此需对候选标注数据进行排序。本文算法基于以下2个假设。
①边界点聚集效应假设。由于分类模型易错分处于分类边界点的数据,因此多数候选标注数据应聚集于分类边界点附近。
由于真实分类边界的未知性,本文提出边界点聚集效应假设:如果某一候选标注数据在分类边界周围,那么附近应该有很多其他候选标注数据。基于以上认识,本文用候选标注数据聚集度评估其与边界的距离,计算式为

其中,{d1,d2,…,dL}表示所有候选标注数据点。
②边界点标注困难假设。由于有时难以确定处于边界点的数据的具体类别或顺序,因此更倾向于标注其他可确定的数据。基于此假设,在迭代初期,优先处理远离边界点的数据有利于降低认知难度,实现模型的快速迭代。
2.3.3 候选标注数据的可视化
分类视图与排序视图展示的候选标注数据点并不突出,为将注意力聚焦于候选标注数据,本文设计了如图6所示的候选标注数据视图。为更好地观察候选标注数据间的顺序关系,用数据对(di,dj)的方式展示,用 max(I(di),I(dj))定义(di,dj)的优先级,其含义为数据对中越远离分类边界的数据,受到关注的优先级越高。所有候选标注数据均按优先级顺序在候选标注数据视图中展示。

图6 候选标注数据视图Fig.6 Candidate annotation data view
2.4 分类结果质量的评估和可视化
交互分类算法是由用户驱动的迭代过程,通过观察到的信息评估当前分类结果,进而决定是否继续迭代。虽然可根据散点图、电子表格观察分类结果,但难以对分类结果的质量形成直观认识,为此,设计了如图7所示的评估视图。由图7可知,A区域展示模型一致度P,P表示分类结果与排序结果的一致程度,P越大,表示分类结果质量越高,P∈ [0,1],计算式为

其中,D表示数据点集,C表示候选点集。

图7 分类结果质量评估视图Fig.7 Classification result quality measurement view
以高危车辆、中危车辆、低危车辆的分类问题为例,由式(4),低危车辆-中危车辆与低危车辆-高危车辆不一致对P的影响相同,而实际上二者存在差别,因此,采用如图8所示的(m-1)×(m-1)三角阵展示不同类别之间出现混淆的候选数据点,三角阵的横坐标从左到右依次为c1,c2,…,cm,纵坐标从上到下依次为c2,c3,…,cm,在第 (i,j)区域中展示ci和cj之间出现混淆的候选数据点,落在同一区域的多个候选数据点用t-SNE投影布局,根据候选点聚集度I(di)进行着色,有助于深入了解当前分类结果的质量。在图7所示的分类结果中,B、C、D区域分别对应低危车辆-高危车辆、低危车辆-中危车辆、中危车辆-高危车辆。

图8 分类结果质量评估视图布局策略示意Fig.8 Schematic diagram of layout strategy for classification result quality measurement view
3 应用案例
随着社会上汽车保有量的不断增加,道路交通拥堵、交通事故频发等问题日益严重。部分车况不佳、司机不遵守交通法规的车辆更加剧了问题的严重性。为便于精准关注和管理高危车辆,提高管理效率,实现基于基本车况、交通违法记录、交通事故记录等信息对车辆进行评估,本文算法专用于解决此问题,但也适用于其他领域中蕴含类别与顺序信息的数据集,如癌症分期判断等。
3.1 数据来源
本案例中所用数据来源于合作公司提供的车辆脱敏数据,其中基本车况、交通违法记录、交通事故记录等信息经整合与处理,最终得到包含9个字段的数据,具体如表2所示。
虽然原始数据中含148 500条记录,但其中有大量数据相同,通过层次聚类法将数据分为98个类簇,从每个类簇中随机选取1条数据构成新的数据集,将新数据集中的98条数据作为案例进行分析。为检验方法的有效性,还邀请了2名交通部门的技术专家,分别对该98条数据进行标注,对不一致的结果经讨论统一后标注,最终形成Ground Truth数据。
3.2 交互分类过程
在载入数据之初,采用t-SNE法将所有数据投影至散点图(如图9所示),同时根据2名技术专家提供的经验公式对数据进行排序,将初始排序结果显示在电子表格中(见图10)。

表2 车辆数据各属性编码及其含义Table 2 Coding and meaning of each attribute of vehicle data

图9 初始分类视图Fig.9 Initial category view
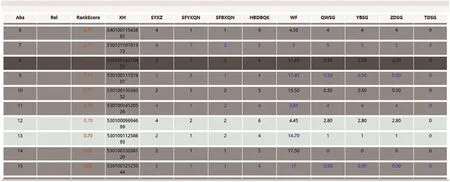
图10 初始排序视图Fig.10 Initial sort view
经验公式虽不一定准确,但可提供初步参考。首先,观察电子表格顶部,将相关数据标注为“高危车辆”,类似地,观察表格的中部和底部,将相关数据标注为“中危车辆”和“低危车辆”,表格中所标注的信息可在散点图中同步显示。然后,观察散点图中被标注数据的周边情况,做进一步标注,最后点击“更新分类模型”按钮,便可自动更新数据分类结果、选择候选标注数据、评估当前分类结果质量,并刷新相应视图。中间候选标注数据视图和中间分类结果质量评估视图分别如图11和图12所示。

图11 中间候选标注数据视图Fig.11 Intermediate candidate annotation data view

图12 中间分类结果质量评估视图Fig.12 Quality measurement view of intermediate classification results
由图12可知,中间分类结果模型一致度仅74%,需进一步优化。继续观察候选标注数据视图顶部,调整数据对的类别属性或相对顺序关系,选择性地挑选并标注部分候选标注数据,便可更新分类模型和(或)排序模型,如此迭代,直至获得满意的分类结果。经6轮迭代,合计进行18次类别属性标注、25次顺序关系标注,得到的最终分类结果质量评估视图如图13所示。由图13可知,最终分类结果质量较好。

图13 最终分类结果质量评估视图Fig.13 Final classification result quality measurement view
与Ground Truth数据对比发现,98条数据中有96条分类结果一致,模型一致度近98%。其中不一致的2条数据在Ground Truth中被标注为“高危车辆”,而在本文算法中被分为“中危车辆”。进一步分析发现,这2条数据处于“高危车辆-中危车辆”的边缘,所以该分类结果可以被理解和接受。
4 结 语
在大数据时代,分类是最基本的数据分析任务之一,交互分类是解决复杂分类问题最有效的方法之一。在某些分类应用场景中,用户易于感知数据类别间的相对顺序关系。基于此,笔者借助用户对数据间相对顺序关系的认知,改进交互分类算法,提出排序支持的交互分类算法。另外,进一步给出了候选标注数据的推荐和排序问题、分类结果质量评估问题的相应解决方案,并以包括基本车况、交通违法记录、交通事故记录等信息的车辆数据集为例,将车辆分为高危车辆、中危车辆、低危车辆3类,分类结果模型一致度达近98%,验证了本文算法的有效性。
本文算法将散点图和电子表格作为主要可视化界面,由于视觉遮挡问题难以扩展,且难以应用于更大规模的数据集,未来可进一步探索多尺度可视化、鱼眼可视化等技术,以提高视觉空间的利用效率;另外,目前排序模型信息仅用于辅助选择候选标注数据和评估分类结果质量,未来可将排序信息直接融入分类模型,以充分利用排序信息。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
名家名作(2021年4期)2021-05-12
少儿画王(3-6岁)(2020年4期)2020-09-13
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
电脑知识与技术(2016年13期)2016-06-29
微型计算机(2009年4期)2009-12-23
