
面向自然场景图像的三阶段文字识别框架
2021-01-26 07:22:00邹北骥杨文君刘姝姜灵子
浙江大学学报(理学版) 2021年1期
邹北骥 ,杨文君 ,刘姝 *,姜灵子
(1.中南大学计算机学院,湖南长沙410083;2.湖南省机器视觉与智慧医疗工程技术研究中心,湖南长沙410083)
自然场景下的文字识别技术可广泛应用于众多移动端设备。例如,应用于智能手机,实时识别并翻译照片中的文字,帮助用户理解图像内容;应用于文档管理系统,将大量纸质文档快速电子化,提高管理人员的工作效率;应用于盲人视觉辅助设备,支持视觉障碍人群进行文字阅读。自然场景文字识别这一研究课题,越来越受研究者的关注。
传统的文字识别算法通常针对如图1(a)所示的合成图像,其文字方向单一、大小均匀,图像背景较简单。然而自然场景中的文字具有排列随意、形状不一、字体多样、背景复杂等特点,如图1(b)所示,给文字识别带来很大挑战。
1 相关工作
文字检测是文字识别的重要前提。传统的自然场景文字检测方法主要依赖于人工设计特征,可以分为两类:基于滑动窗口的方法和基于连通域的方法[1]。前者使用多尺度滑动窗口提取候选文字,但其中包含大量非文字区域,加重了后续分类器对正确文字检测的计算负担;后者通过一系列字符像素特征提取候选字符连通域,其对背景较为复杂的自然场景图像,检测效果不佳。
当前流行的文字检测方法大多基于深度学习技术,无须手动提取特征,大致分为基于锚点框回归的方法和基于实例分割的方法。前者[2-5]利用多尺度锚点框检测不同笔画、大小和尺寸的文字,但锚点框的设计需人工参与;后者[6-8]不考虑文字的排列方向,直接分割多方向文字实例,但有时难以区分不同的实例对象,即多个文字实例可能被误判为同一个。针对以上问题,笔者通过实例分割方法对单个字符(非完整单词级文字)进行分割,再将孤立字符组合成单词行,实现从自然场景图像中直接分离任意排列的文字实例,避免分割过程中对多个单词级文字的误判。
现有的文字识别方法主要分三类:基于文字矫正的方法、基于注意力机制的方法和基于字符识别的方法。基于文字矫正的方法将方向倾斜的文字矫正至水平排列,以便后续识别。SHI等[9]提出包含矫正模块和识别模块的文字识别描述子,其中矫正模块专门对不规则文字进行水平矫正。LUO等[10]提出用多目标矫正注意力网络识别自然场景图像中的文字,其中通过多目标矫正子网络计算原图中每个文字像素的补偿值,即位移,以矫正畸变文字。ZHAN等[11]通过循环迭代矫正网络逐步矫正不规则排列的文字。基于注意力机制的方法能够更精准地选取字符区域特征,忽略背景信息。LIAO等[12]设计了二维注意编码器网络,探索字符二维空间关系,从而更好地识别不规则文字。基于字符识别的方法对单个字符而非完整单词级文字进行识别,可有效规避单词级文字排列方向不同等带来的识别问题。LI等[13]提出一种字符感知神经网络,采用分层注意力机制检测并纠正单个字符,有效识别失真的场景文字。
上述文字识别方法大多针对已分割的单词级文字图像,在现实应用中适用性不强。本文面向实拍的自然场景,建立包括文字检测、文字矫正、文字识别3个阶段的文字识别框架。首先,针对定位场景中的文字区域,用特征金字塔网络(feature pyramid network,FPN)[14]分割单个字符实例,将局部与全局特征相结合,以更好地提取字符,同时避免实例误分问题。然后,利用双向长短期记忆网络(bidirectionallong short-term memory network,BLSTMN)[15]预测字符间的亲和度,即相邻字符之间能够组合为文字行的概率,连接孤立字符构建单词行。考虑自然场景图像中文字的无规则性,通过多目标矫正网络(multi-object rectification network,MORN)[10]矫正被检测出的单词级文字,提高文字的阅读性和识别率。最后,将矫正后的单词级文字输入注意力序列识别网络(attention-based sequence recognition network,ASRN)[10],按序输出预测结果,实现单词级识别。
2 本文方法
以原始自然场景图像作为输入,分文字检测、文字矫正和文字识别3个阶段,文字识别框架如图2所示。
2.1 文字检测
在自然场景图像中,文字区域的定位与检测是文字识别过程的基础。通过实例分割方法,可轻松将任意方向的文字从图像背景中剥离出来,但现有方法大多面向单词级文字实例,可能出现分割精度不高、实例误分的情形。本文提出一种字符实例分割方法,其流程如图3所示,利用FPN分割单个字符实例,并基于BLSTMN提取上下文信息,获得字符间的亲和度,并据此连接孤立字符组成单词行。
2.1.1 字符实例分割

图2 文字识别整体框架Fig.2 The framework of text recognition
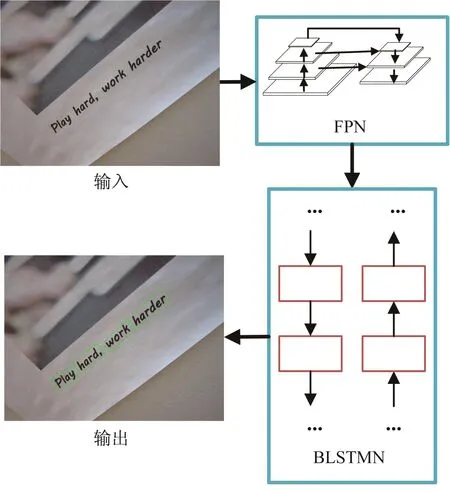
图3 文字检测流程Fig.3 Text detection process
字符实例分割是指利用实例分割方法从图像中分离字符像素与背景像素的过程。本文通过基于ResNet-50[16]的 FPN 实现。如图 4 所示,骨架网络包含5个阶段卷积,每个阶段均有越层连接。从第2阶段起进行特征图上采样与融合操作,特征图上采样是指利用双线性插值算法放大图像,特征图融合是指相同尺寸特征图之间的元素按位相加。对每一层融合的特征图进行字符实例预测,并将预测结果融合输出。
2.1.2 单词行构建
因图像中的文字行比单个字符更具实际意义,故将分割出的字符组合成单词。传统方法通常通过一些预定义的组合规则将孤立字符连接起来,如字符间的间隙、宽高比、颜色等。本文通过FPNBLSTMN结构(见图4)预测字符之间组合为单词的可能性,即亲和度,并据此连接相邻字符,构建单词级文字行,如图5所示。
此外,公共数据集大多只标定字符级别,字符间的关系需重新标定。将相邻字符标定框的宽度与高度的一半作为字符间亲和度标定框的宽度与高度,将相邻字符标定框中心连线的中点作为字符间亲和度标定框的中心,标定效果如图6所示。

图4 FPN-BLSTMN结构Fig.4 The structure of FPN-BLSTMN

图5 单词级文字行构建Fig.5 Construction of word-level text line
2.1.3 损失函数
为优化FPN-BLSTMN模型,将损失函数定义为

图6 字符间亲和度标定Fig.6 Annotation of affinity between characters
其中,Ltotal,Lclass和 Lconnect分别表示网络总损失、当前像素p是否为字符像素的分类损失以及字符对是否相邻的分类损失,λ=2,是平衡2个分类损失的权值。
利用文献[6]中的交叉熵损失计算Lclass,即

2.2 文字矫正
自然场景中的文字往往是不规则排列的(水平、垂直、倾斜、扭曲),而传统方法无法很好地识别非水平排列的文字。本文采用MORN[10]方法矫正被检测文字行,将垂直、倾斜或扭曲的文字矫正至水平排列。文字矫正流程如图7所示,将分割后的单词级文字图像输入多目标矫正网络,预测其补偿图,补偿值即为每个文字像素的位移,由此移动初始图像中的字符像素,实现文字矫正,提高场景文字的阅读性和识别率。

图7 文字矫正流程Fig.7 Text rectification process
2.3 文字识别
常用的文字识别算法通常包括3个步骤:预处理、特征提取和分类器识别。预处理是对图像进行去噪、增强、缩放等操作,尽可能减少噪声及背景干扰,突出文字区域;特征提取指提取文字边缘、笔画、结构等特征,供分类器学习;分类器识别是通过已训练的分类器对文字进行识别。本文采用基于注意力机制和循环神经网络的ASRN[10]模型。如图8所示,首先,将矫正后的单词级文字图像作为输入,通过注意力机制聚集文字区域,利用卷积神经网络提取文字特征并输出特征序列。然后,将其输至BLSTMN,结合上下文信息生成目标预测序列。最后,将每帧预测通过转换层转换为标签序列,获得文字识别结果。

图8 文字识别流程Fig.8 Text recognition process
3 实验结果与分析
3.1 数据集
采 用 的 实 验 数据集包括 SynthText[17]、ICDAR 2013[18]和 ICDAR 2015[19]3 个 标 准 集 。 SynthText为合成图像数据集,包含85万余幅合成文字图像,样本量充足且文字属性多样化,用于算法模型预训练,以获得丰富的文字特征。ICDAR 2013和ICDAR 2015为自然场景图像数据集,前者包含452幅自然场景文字图像,其中229幅作为训练集,223幅作为测试集;后者包含1 500幅自然场景文字图像,其中1 000幅作为训练集,500幅作为测试集。此2个数据集样本较少,但均面向自然场景,故用其对算法模型进行微调和测试。
3.2 评价指标
实验中采用召回率R、精度P和F分数评价文字检测算法,采用正确识别率Acc评价文字识别框架的最终效果。计算式分别为

3.3 文字检测结果分析
在SynthText数据集上对文字检测部分进行了模型预训练。初始学习率设置为0.000 030,经20 000次迭代,学习率降至0.000 024。图像批处理尺寸设置为128,所有图像大小归一化为768×768。用0.000 050的权值下降,并且在训练过程中用ADAM优化器[20]优化,预训练模型在4块GPU上迭代了50 000次。
文字检测阶段包括字符实例分割和字符间亲和度预测两个过程。图9展示了字符实例在不同训练时期的分割结果,其输出为字符所在区域,图10展示了字符间亲和度在不同训练时期的预测结果,其输出为字符之间的区域;epoch1,epoch10和epoch190分别表示模型使用训练集全部样本训练1次、10次和190次。随着训练过程的推进,本文方法能很好地分离字符实例与图像背景,感知上下文信息,从而预测亲和度。

图9 不同epoch下的字符实例分割Fig.9 Character instance extraction at different epochs

图10 不同epoch下的字符间亲和度预测Fig.10 Character affinity prediction at different epochs
为验证本文方法对文字检测的有效性,选取几个较新的典型方法,在ICDAR 2013和ICDAR 2015数据集上进行定量比较,实验结果如表1和表2所示。由表1和表2知,本文方法在R,P和F分数指标上都表现较好。锚点框回归方法(如RRPN[4]、TextBoxes++[5])依赖大量人工设计匹配文字特征区域的锚点,还需考虑随机排列文字的方向特性;而本文通过FPN直接分割文字像素,通过BLSTMN捕获字符间的上下文信息,显著改进了对随机排版文字的识别。相较一般的实例分割方法(如SegLink[7]、PixelLink[6]),本文方法通过 FPN 将局部与全局的文字特征相融合,实现对不同大小文字的分割,从而获得更高的文字字符召回率和检测精度。值得一提的是,CRAFT方法[8]凭借弱监督学习和像素级字符连接获得了最佳的检测性能。
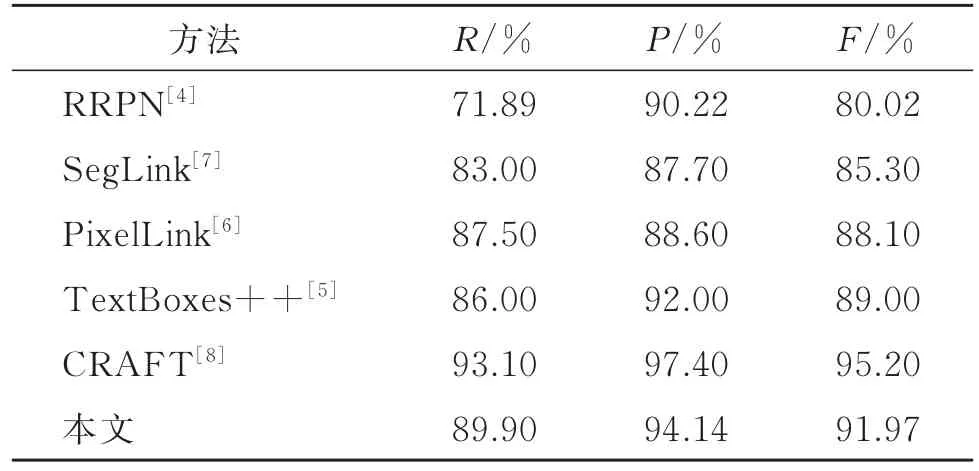
表1 文字检测方法在ICDAR 2013上的性能对比Table 1 Comparison of different text detection methods on ICDAR 2013

表2 文字检测方法在ICDAR 2015上的性能对比Table 2 Comparison of different text detection methods on ICDAR 2015
3.4 文字矫正结果分析
文字矫正方法可直接应用于原始自然场景图像,检测并矫正扭曲、被遮挡或随意排列的场景文字。ICDAR 2015数据集不仅包含倾斜和被遮挡的文字,也包含大量扭曲的文字,图11直观展示了本文方法对这些文字图像的检测与矫正结果。

图11 倾斜、扭曲文字的矫正结果示例Fig.11 Examples of inclined and distorted text rectification
3.5 文字识别结果分析
在SynthText数据集上对文字识别部分进行了模型预训练。初始学习率设置为0.01,图像批处理尺寸设置为64,所有图像大小归一化为64×200。用0.000 050的权值下降,并且在训练过程中用ADADELTA 优化器[21]优化,预训练模型在 4块GPU上共迭代了60 000次。
为验证本文方法的有效性,将其与较新的典型方法在2个ICDAR数据集上做定量比较,实验结果如表3所示。由表3可知,本文方法在ICDAR 2013上取得了较高的准确率,性能优于文献[22]和[23]中方法,这是因为通过矫正过程有效矫正了文字的不规则形变,进而增强了其阅读性和识别率。值得注意的是,表3中所列方法大多是针对分割后的单词图像进行的识别,其值为文字检测率在100%时的正确识别率。本框架直接用原始自然场景图像作为输入,先进行单词级文字检测与分割,再进行文字识别,此时的检测误差将累积至最终的识别结果中。因此,即便本文方法在数值上并非最优,但仍具较强竞争力,且其实用性更强。文献[9]也是面向自然场景开展的文字识别研究,并获得了较好的识别效果,但其文字检测模块采用的是设计成熟的文字检测网络,需要经过一定的预处理才能与矫正网络和识别网络融合。本文方法的文字检测模块包含FPN和BLSTMN,获得了更高的检测精度,且与后续的文字矫正模块、文字识别模块在同一框架中,算法更完整。

表3 文字识别方法在2个ICDAR上的识别正确率对比Table 3 Comparison of different text recognition methods on two ICDAR datasets
图12和图13分别更直观地展示了本文方法在ICDAR 2013和ICDAR 2015数据集上的文字识别效果,可以看出,在不同排列方向、不同形状大小、不同光照条件下的自然场景文字均能很好地被检测与识别。图13(d)中标红处为识别错误的文字,由原始图像中的文字过于模糊或尺寸过小使算法难以区分文字区域与背景所致。

图12 本文方法在ICDAR 2013上的结果示例Fig.12 Visualization of our method on ICDAR 2013

图13 本文方法在ICDAR 2015上的结果示例Fig.13 Visualization of our method on ICDAR 2015
3.6 时间分析
本文方法在处理不同的自然场景图像时,耗时不同,影响耗时的主要因素有图像大小、分辨率和图像中的文字量。输入原始自然场景图像,定位并矫正图像中的单词级文字,最后输出文字识别结果,对大小为640×480的图像,平均运行时间为1.25 s,对大小为1 280×720的图像,平均运行时间为1.38 s。
4 结 语
针对自然场景图像中的不规则文字,提出了包括文字检测、文字矫正和文字识别3个阶段的文字识别框架。用FPN-BLSTMN检测图像中的单词行,用MORN对不规则单词进行矫正,最后通过ASRN实现单词级识别。实验结果表明,本文方法能有效检测并识别扭曲、被遮挡、随意排列的场景文字,且其框架直接面向原始自然场景图像,与一般文字识别算法相比,本文方法的实用性更强。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
中国自行车(2018年2期)2018-05-09 07:03:05
福建人(2016年6期)2016-10-25 05:44:15
Coco薇(2015年7期)2015-08-13 22:47:12
中国医疗美容(2015年2期)2015-07-19 10:11:59
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
