
基于深度森林的高铁站室内热舒适度等级预测
2021-01-21 03:23陈彦如张涂静娃冉茂亮王红军
计算机应用 2021年1期
陈彦如,张涂静娃,杜 千,冉茂亮,王红军
(1.西南交通大学经济管理学院,成都 610031;2.中铁二院工程集团有限责任公司建筑工程设计研究院,成都 610031;3.西南交通大学信息科学与技术学院,成都 611756)
0 引言
城市计算是计算机学科中以城市为背景,与城市规划、交通、能源、环境、社会学和经济等学科融合的新兴领域[1-4]。城市计算的提出对经济、社会、技术等诸多方面产生了重要的影响。作为城市计算中的一类重要空间节点——高铁站,承担着大量乘客的集散功能,是高密度客流聚集的公共建筑场所,其室内的环境舒适度直接影响着乘客的出行体验和心理状态。有效感知高铁站室内环境舒适度特征,并基于城市计算中的人工智能模型,挖掘其环境舒适度的影响因素和变化规律,预测高铁站室内舒适度等级,能够为制定智能的室内温控系统提供重要的决策依据,进而达到城市计算的目标——为人们提供高品质的城市生活。
在室内环境的舒适度研究中,热舒适度是评价室内环境满意度的重要手段。2005 年国际标准化组织制定PMV(Predicted Mean Vote)、PPD (Predicted Percentage of Dissatisfied)等热舒适度指标[5]。目前由于PMV-PPD 已被广泛应用于热舒适度的测度之中,因此本文以PMV-PPD 作为高铁站室内环境的热舒适度评价指标。然而不同于一般的封闭建筑空间,高铁站为了方便大规模客流集散,通常设计为半封闭半开放的建筑空间,因此室内的热舒适度受到诸多因素的影响,并且呈动态变化。此外,影响因素与热舒适度指标之间也呈非线性关系,如果采用传统统计预测模型,则难以完全获取数据的内在特征及数据间复杂的非线性关系。浅层机器学习模型可以较好地描述非线性关系,但容易出现欠学或过学现象。而深度神经网络(Deep Neural Network,DNN)等深度学习算法则存在计算复杂度高、需优化大量超参数等不足。考虑到深度森林(Deep Forest,DF)算法所需参数少、对于超参数的设置不敏感、容易训练等优势,本文采用深度森林来构建高铁站室内热舒适度预测模型,以获取各影响因素与热舒适度之间的非线性关联关系。为了获得海量数据,本文将实地调研与仿真建模相结合,借助Energy Plus软件,构建了能够复现实际高铁站热交换环境的仿真模型,从而产生不同室外气象条件、不同客流密度、不同多联机控制工况以及不同热交换控制工况的大规模数据集,为深度森林提供充足的数据资源。
与已有研究相比,本文的主要贡献如下:
1)研究对象。目前热舒适度的研究对象更多为全封闭式室内环境,而本文主要是针对高铁站这类半开放半封闭式建筑,这类建筑部分自然通风且人流密度高,室内外空气交换频繁,室内热舒适度不稳定性强,其热舒适度等级预测较为困难。
2)研究要素。除了传统热舒适度研究中采用的将室外环境和室内环境因素两类作为模型输入参数之外,本文还将客流密度、多联机台数、多联机设置温度以及热交换机的台数等作为模型输入参数,更加全面地分析室内热舒适度等级的各种影响因素。
3)研究方法。区别于以往的传统预测方法和浅层机器学习方法,本文提出了基于深度森林的室内热舒适度预测方法,以深入挖掘众多因素对热舒适度的影响。
1 相关工作
目前关于热舒适度的研究主要集中在热舒适度的评价、预测及控制方面。随着城市计算概念的普及,越来越多的学者开始将机器学习的思想应用到热舒适度的研究中。
1.1 热舒适度的评价
目前该部分研究主要基于PMV-PPD 模型或相关改进模型对不同环境的热舒适度进行评价:文献[6]中用PMV-PPD指标来评价室内或者车舱内热环境的状况;文献[7]中采用被试人员主观评价和实验测试客观评价相结合的方法,使用PMV-PPD 模型计算人体的热舒适,研究冬夏季住宅空调房间内舒适的温湿度范围、可接受的温度波动及冬季头脚垂直温差范围;文献[8]中利用MTS(Mean Thermal Sensations)-PPD模型对哈尔滨市住宅热环境和个人热舒适进行了评价,并发现男性对温度变化的敏感性低于女性;文献[9]中讨论了居住者在自然条件下对热环境的适应性反应和感知,对实际平均投票和预测平均投票以及实际不满意百分比和预测不满意百分比进行了比较;文献[10]中使用PPD 和PMV 指标衡量了学生对学习环境的热舒适的评价;文献[11]中测量室内环境质量参数,并使用PMV-PPD 模型来评估居住者现有的舒适水平;文献[12]中通过采集大楼内的实验测量数据计算PMVPPD 指数,对伊朗西部Kermanshah 市的一家公立医院的空调系统性能和热舒适水平进行了测定;文献[13]中提出了一种基于PMV-PPD 的方法来评估潜水器客舱的热特性变化和载人深海任务中船员的舒适度。
1.2 热舒适度的预测
文献[14]中提到随着理论数学和计算机科学技术的发展,部分学者尝试将模糊数学和机器学习等领域的方法引入到热舒适度的预测之中。文献[15]中提出了一种基于误差反向传播算法的控制器,该控制器以PMV 指标为控制目标,预测暖通空调系统的最高舒适度。文献[16]中使用决策树的方法预测用户的热舒适感知。文献[17]中使用逻辑回归和支持向量机(Support Vector Machine,SVM)对热感觉和舒适的热接受度和热偏好进行预测。文献[18]中采用模糊模型(Takagi-Sugeno,TS)和高斯-牛顿非线性回归测算法构建了模糊PMV-PPD 模型预测室内热舒适状况。文献[19]中提出了一种用于热感知预测的智能集成机器学习方法——Bagging,该模型综合考虑了气候、环境和人口参数。与神经网络及支持向量机模型相比,Bagging 模型具有更高的热感觉预测精度。文献[20]中提出了一种基于数据驱动的个体水平热舒适实时预测方法,分别运用了支持向量机、人工神经网络等6 种算法对新加坡的自然通风建筑和空调建筑进行了热舒适性预测。文献[21]中应用9 种机器学习算法和3 种数据采样方法来预测美国采暖、制冷与空调工程师学会(American Society of Heating,Refrigerating and Air-Conditioning Engineers,ASHRAE)数据库Ⅱ中的热感觉投票。文献[22]中结合了高保真计算流体动力学模拟和机器学习算法对车辆乘员的热舒适性进行预测。
1.3 热舒适控制
部分研究将热舒适度作为目标用于系统控制。文献[23]采用PMV 和PPD 对室内热环境进行评价,并结合能耗、性能系数、电费等指标提出了热泵供暖系统的最优控制策略。文献[24]中的研究强调需要一种新的空间冷热系统热舒适控制方法,以达到舒适的热条件,同时尽量减少能源消耗。为了实时反映室内环境信息的变化,控制影响温度和热舒适的各种因素(如湿度、风速等),利用高斯回归过程获得的热舒适性能来预测结果。文献[25]中以能耗和PPD为目标对获得建筑围护结构的配置进行优化。文献[26]提出了一个基于深度强化学习的建筑能耗模型-深度强化学习(Building Energy Model-Deep Reinforcement Learning,BEM-DRL)框架用于空调系统的能效和热舒适性优化控制。模型采用利用贝叶斯方法和遗传算法进行多目标边界元法标定,深度强化学习训练采用异步优势动作评价(Asynchronous Advantage Actor Critic,A3C)算法。以现有的一个办公楼为例,通过对供暖系统供水温度的简单控制,所提出的优化控制策略以大于95%的概率将供暖需求降低16.7%。
综上,目前大多研究采用PMV-PPD 指标进行环境热舒适度的评价。对于PMV-PPD 指标的预测主要采用传统的数理统计方法或者浅层机器学习方法,而且预测的环境主要是封闭空间,很少考虑半封闭半开放的建筑空间。
2 问题描述
为了快速且准确地预测人体在高铁站这类半开放半封闭式建筑的热舒适性,判断多联机温度控制和热交换机台数设置等控制策略的合理性,提高高铁站内旅客的体验感和舒适感。本文提出了一种在自然通风条件下高铁站内热舒适度等级预测的方法。
该方法综合采用实地调查与Energy Plus软件仿真采集大量数据,将高铁站室内不满意预测百分比(PPD)作为目标,室外天气、客流密度、室内温度、室内湿度、室内二氧化碳浓度、多联机设置温度、多联机开启台数和热交换机开启台数为模型输入参数,提出了深度森林预测模型,探讨了在不同工况下室内PPD所处等级。
基本定义如下。
1)PMV。
PMV 是基于人体与环境热交换的稳态物理模型建立起来的一个经验指标,它预测的是按照ASHRAE 的冷热感觉尺度衡量的一批人的平均反应。Fanger 认为处于稳定状态下,大多数的冷热感觉只有空气温度、平均辐射温度、相对湿度、空气流速、新陈代谢率(即人体活动量)和服装热阻(即衣着情况)6 个因素起主要影响作用,通过适当选择这6 个影响因子就可以通过式(1)得出相应的PMV指标[5]:

其中:M为人体的新陈代谢量,单位为W/s;W为人体所做的机械功,单位为W/s;Pa为人体周围空气的水蒸气分压力,单位为Pa;ta为人体周围的空气温度,单位为℃;fcl为人体着装后的实际表面积和人体裸身表面积之比,即服装的表面系数;tcl为人体外表面温度,单位为℃;ts为房间的平均辐射温度,单位为℃;hc为对流换热系数,单位为W/s·m2·℃;
2)PPD。
PMV 指数为预计处于热环境中的群体对于热感觉投票的平均值。PPD 指数可对于热不满意的人数给出定量的预计值,当确定PMV值以后,PPD值可由式(2)[5]得出:
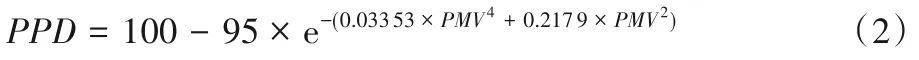
本文采用PMV-PPD 指标对高铁站室内热舒适度进行评价。依据现行国家标准将PPD 分为一级热舒适度、二级热舒适度和不舒适三类,其中:10%以内为一级热舒适度,10%到27%为二级热舒适度,27%以上为不舒适[27]。
3 高铁车站仿真模型构建及数据收集
为了获取海量数据,本研究基于现场调研及Energy Plus平台,建立了成都某高铁站的仿真模型。
3.1 仿真模型构建及参数设置
本文选取了处于夏热冬冷区的成都某高铁站为研究对象,该车站为高架车站,站厅层高6 m,吊顶1 m,室内区域分为办公区、候车区、离站区三个部分,其中候车区的尺寸为74 m×28 m×5 m。该车站共配有5 台多联机和8 台热交换机。仿真模型中的建筑朝向、围护结构构造、建筑结构等参数均严格按照该高铁站实际数据进行设置。
为了全面研究室内室外参数对室内环境热舒适度的影响,本文通过文献调研及实地调研的方式,最终确定了8 个影响因素:室外干球温度、室内客流密度、室内温度、室内湿度、室内二氧化碳浓度、多联机开行台数、多联机设置温度、热交换机开行台数。为了在仿真平台还原真实的热交换环境,本文对该高铁站进行了实地调研,获取了现场的室外室内所有状态参数及客流密度的变化轨迹,据此对仿真模型进行校正与多轮调试,最终确定该高铁站的仿真模型。
3.2 数据收集
本文收集了该高铁站为期一年的室外干球温度数据,其中采集间隔为1 h,共得到24×365=8 760条天气数据。考虑到不同人群对热舒适度体现的差异,本文共设置了8 种多联机夏季温度与冬季温度组合,分别为(15℃,23℃),(16℃,24℃),(17℃,25℃),(18℃,26℃),(19℃,27℃),(20℃,28℃),(21℃,29℃),(22℃,30℃)。温控设备从上午7 点开启至晚上11 点关闭。此外,考虑单独开启多联机、单独开启热交换机以及同时开启多联机热交换机的情况,共有5+8+40=53种工况,结合8种温度设置范围,共获得53×8=424种工况。因此,共生成了424×8 760=3 714 240个实例。
4 高铁站热舒适度等级的深度森林预测模型
4.1 深度森林模型
2017年Zhou等[28]首次提出了深度森林算法,也称作多粒度级联森林算法(multi-grained cascade Forest,gcForest)。
深度森林算法是以随机森林(Random Forest,RF)算法为基础的一种有监督机器集成学习算法[28],其模型框架如图1所示。作为一种具有一定深度的基于决策树的预测算法,深度森林算法将预测过程分为两个阶段:多粒度扫描阶段和级联森林阶段。
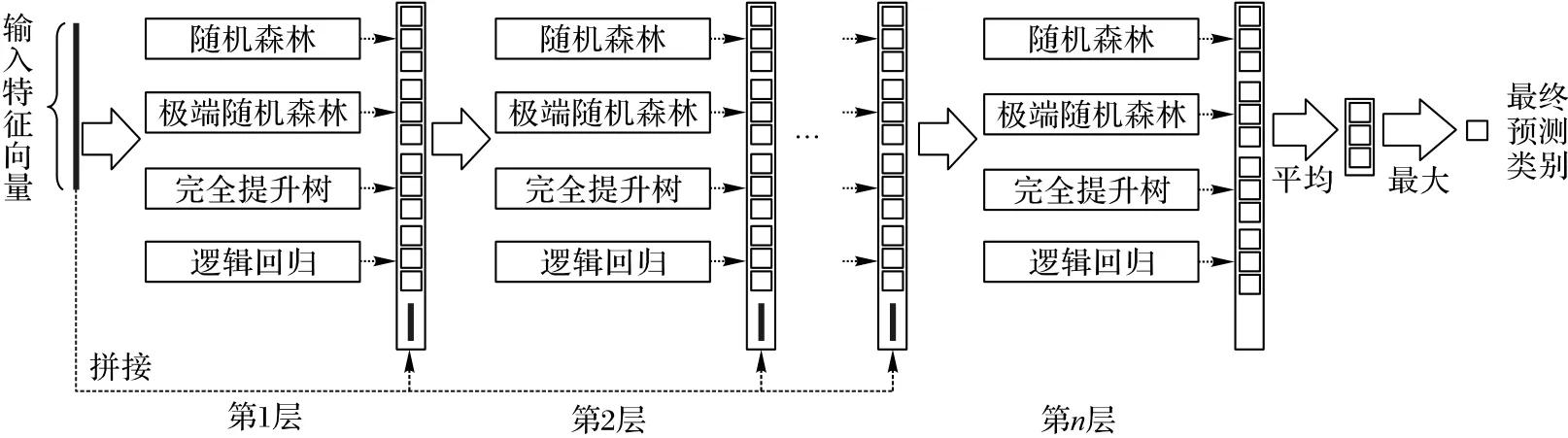
图1 深度森林模型框架Fig.1 Framework of deep forest model
1)随机森林算法。
随机森林算法是一种基于Bagging的集成学习方法,是机器集成学习算法之一[29]。在分类任务中,测试样本的类别由这些决策树输出类别标签的众数决定,包括随机选取样本数据过程和随机选取待选特征过程。
2)多粒度扫描阶段。
深度森林算法中,为了尽可能挖掘序列数据特征的顺序关系,增加集成学习的多样性,设置了多粒度扫描阶段对样本特征进行提取。
3)级联森林阶段。
级联森林的每一层都是由多个森林组成,而每一个森林又是由多个决策树组成,每一层的森林保证了模型的多样性。在级联森林阶段中,其层数是自适应调节的。在特征信息的传递中,除第1 级直接采用经多粒度扫描处理后的特征向量作为输入之外,随后的每一级都将上一级输出的特征结果向量与原始输入特征向量相拼接作为自身的输入[28]。
4.2 基于深度森林的热舒适度等级预测
本文按以下步骤对高铁站室内热舒适度等级进行预测:
步骤1 考虑到不同的月份对室内环境的影响强度不同,根据月份将数据分为12 个子集,一个子集对应一个月份,即Dataset=(D1,D2,…,Dm),m=12。特征集A={a1,a2,…,ad},d=8,即对应8 种影响因素:室外干球温度、室内客流密度、室内温度、室内湿度、室内二氧化碳浓度、多联机开行台数、多联机设置温度、热交换机开行台数。
步骤2 采取10-折交叉验证,将Di各分为10 份,依次将其中的九份作为训练集Pi,另一份作为测试集Ui,,Ui=
步骤3 确定模型参数,如设置最大深度N为16,提前停止层数为3,并开始训练,具体训练流程如图2所示。
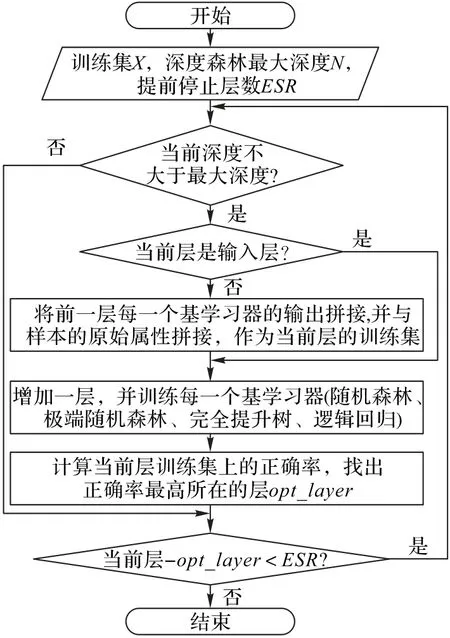
图2 深度森林算法流程Fig.2 Flowchart of deep forest algorithm
5 实验与结果
以成都某高铁站为例,基于仿真模型获取的数据进行其室内热舒适度等级的预测。本文的实验流程如图3所示。
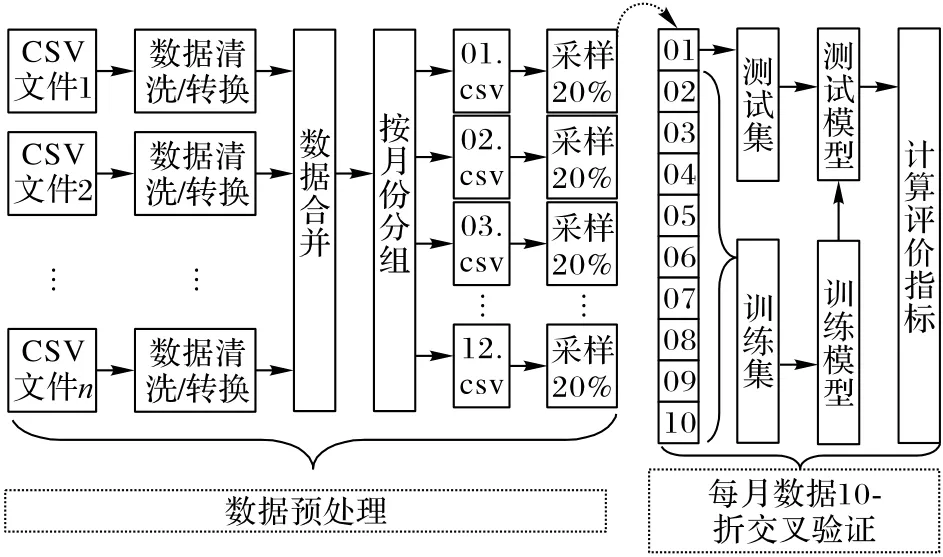
图3 高铁站热舒适度等级预测流程Fig.3 Flowchart of thermal comfort level prediction for high-speed railway stations
5.1 数据处理
数据处理包括3 个部分:数据清洗、数据合并和数据分组。
考虑到不同的月份,诸多因素对室内环境的影响,在对原始经过数据清洗、标准化等之后,按月份将数据分为12 组,综合考虑到计算机的处理能力和实验效果,对每组数据随机抽取20%作为最终实验数据,结果见表1,其中每个示例有8 个特性,PPD 值有3 个类别,即一级热舒适度(10%以内)、二级热舒适度(10%~27%)和不舒适(27%以上)。
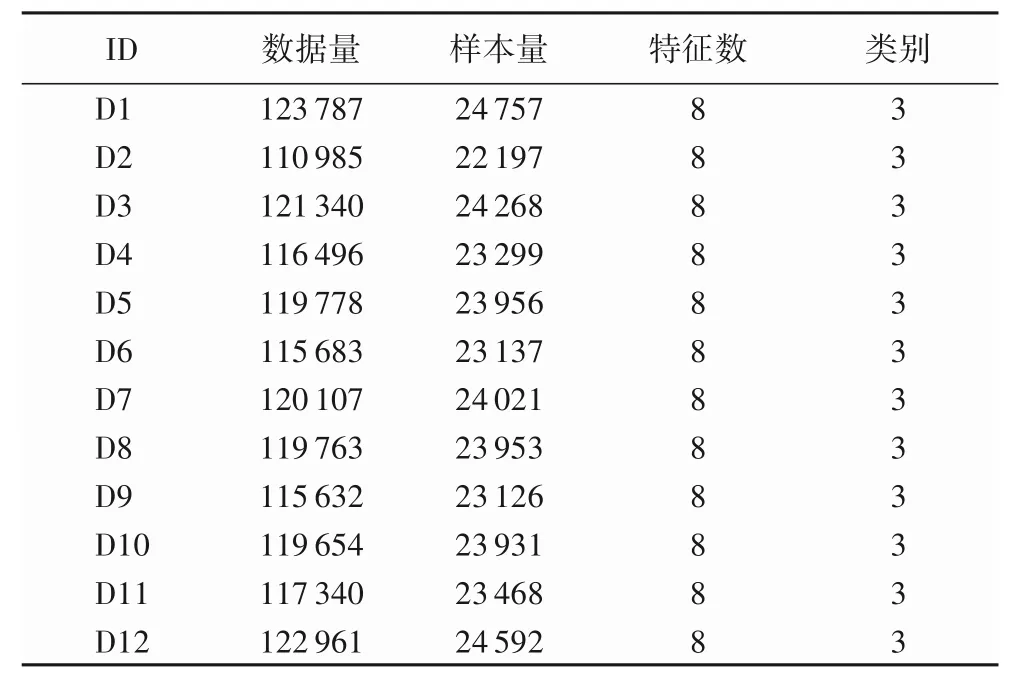
表1 实验数据集描述Tab.1 Description of experimental dataset
5.2 评价指标
本文采用正确率[30]和weighted-F1(加权宏平均)作为模型的性能评估指标。正确率是测试集分类正确的样本数/测试集总的样本数,其定义如式(3)所示:

其中:k表示第k个类别,m表示总的类别数,ak表示第k个类别中分类正确的测试集样本数,N表示测试集的样本数。Acc的取值范围为0 ≤Acc≤1,其中,Acc为0表示所有的样本分到错误的类中,Acc为1表示所有的样本都分到正确的类。
F1为精度和召回率的加权平均值,其中F1值在1 时达到最佳值,在0时达到最差值[31]。本文对于PPD 三分类问题,采用weighted-F1指标。对于每一个类别i,用二分类的公式计算出F1值记为F1i,然后将多个F1i给予不同的权重进行计算。
weighted-F1值的定义如式(4)所示:
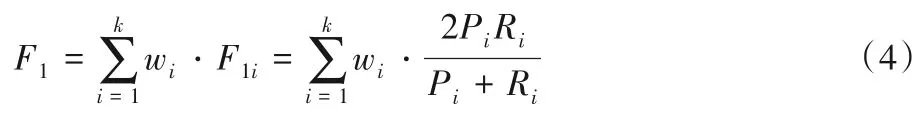
其中,k代表类别数,wi代表每个类别的样本所占的比例,P为精度,R为召回率,两者定义如式(5)~(6)所示:

其中:TP(True Positive)为正例预测正确的个数;FP(False Positive)为负例预测错误的个数;FN(False Negative)为正例预测错误的个数。
5.3 模型参数设置
5.3.1 深度森林模型参数设置
深度森林算法的核心在于决策树,所以决策树的数量和深度的设置对整个算法的分类效果以及计算效率十分重要。本文选择采用完全提升树(Extreme Gradient Boosting,XGB)、随机森林(RF)、极端随机树(Extra Tree,ET)、逻辑回归(Logistic Regression,LR)4 种模型集成,并且针对4 种级联层分别设置不同参数。
针对XGB 模型,在初始参数设置中,每棵树的最大深度范围设置为[4,10],迭代器次数设置5 种,即{8,16,32,64,128},学习率设置为{0.01,0.05,0.1,0.5,0.9},L2 正则化系数为{0.1,0.5,1,2,3},指定节点分裂所需的最小损失函数下降值为{0,0.5,1,1.5,2},选择样本中随机抽取的28 470条数据,对不同参数的模型交叉验证后计算平均正确率和方差,以其作为判断标准选择出最优参数。
通过实验分析,分别得出4 个模型的最优参数组合。对于XGB模型,选取叶子节点分裂的阈值为0,学习率为0.5,最大深度为10,总共迭代次数为128,L2 正则化系数为2;对于RF 模型,选取衡量分裂质量的性能函数为基尼函数,叶子节点分裂的阈值为0.4,最大深度为10,总共迭代次数为128;对于ET 模型,选取衡量分裂质量的性能函数为基尼函数,选取叶子节点分裂的阈值为1,最大深度为10,总共迭代次数为64;对于LR 模型,采用分类方法为一对剩余(One vs Rest,OvR),L2正则化项的系数为0.1。
5.3.2 支持向量机参数设置
支持向量机内置的核函数初始设置为以下4 种:线性核函数、多项式核函数、高斯核函数和sigmoid 核函数;核函数中的参数gamma初始设置为{0.01,0.1,0.5,1,2,5,10};初始惩罚系数C设置为{0.1,1,5,10,15,20},三类参数进行无序排列组合,计算可得,参数设置存在4×7×6=168种情况。
通过28 470 条数据得出的平均正确率和方差结果比较,获得支持向量机最优参数组合:初始惩罚系数C为20,核函数采用高斯核函数,核函数的参数gamma最优值设置为5。
5.3.3 神经网络模型参数设置
神经网络第一层激活函数初始设置为以下4 种,即hard_sigmoid 激活函数、Relu 激活函数、sigmoid 激活函数、tanh双曲正切激活函数;隐藏层层数初始设置为1 到4;第一层神经元个数设置三类{64,128,256},其余隐藏层神经元个数为前一层基础的一半。同理,三类参数进行无序排列组合,计算可得,上述参数设置情况共有4×4×3=48类。
通过实验分析,最终获得深度神经网络(DNN)模型最优参数组合为:第一层神经元个数为128,隐藏层层数为2,激活函数采用ReLU(Rectified Linear Unit)。
5.4 实验结果与分析
为了验证DF 的预测效果,本文同时采用深度神经网络(DNN)和支持向量机(SVM)进行了预测。
1)运行效率。就平均训练时间而言,由于DF是一种集成算法,因此相比于SVM 和DNN,DF 的平均训练时间会更长。三者运行时间结果如图4(a)。
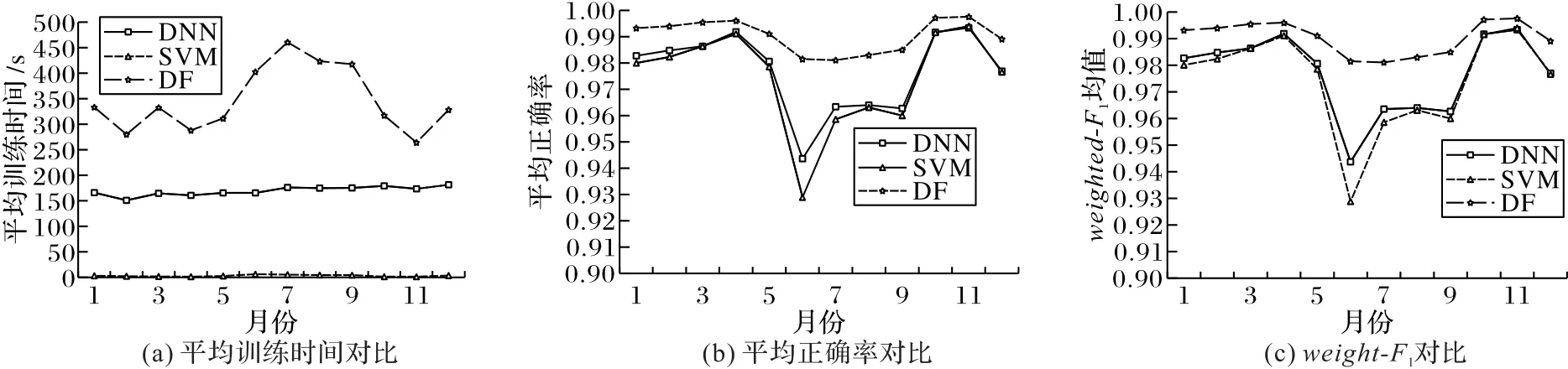
图4 DF、SVM和DNN算法的平均训练时间、平均正确率、weighted-F1对比Fig.4 Comparison of average training time,average accuracy and weighted-F1 of DF,SVM and DNN
2)算法性能。三种算法的预测平均正确率和平均weighted-F1见图4(b)、4(c)及表2。由测试结果可知,12 个数据集中,DF 的预测正确率和weighted-F1均优于DNN 和SVM。其中,DF 模型的最高正确率达到99.76%,最低正确率为98.11%。DF 模型在D10 和D11 两个数据集的正确率超过99.7%,在D4、D10 和D11 三个数据集中的F1值均超过99.6%。此外,DF 模型的预测正确率和weighted-F1值排名在所有数据集中均稳定第一,DNN 的预测正确率和weighted-F1值介于DF和SVM之间。
此外,本文还使用Friedman 统计量[32]全面评估DF 与SVM和DNN算法之间的性能差异,其定义如下:


本文中,DF、SVM和DNN在各个数据集上平均正确率和平均weighted-F1的平均排名都分别为1.000 0,2.833 3和2.166 7。其中最优是DF,第二为DNN,第三为SVM。建立如下假设:
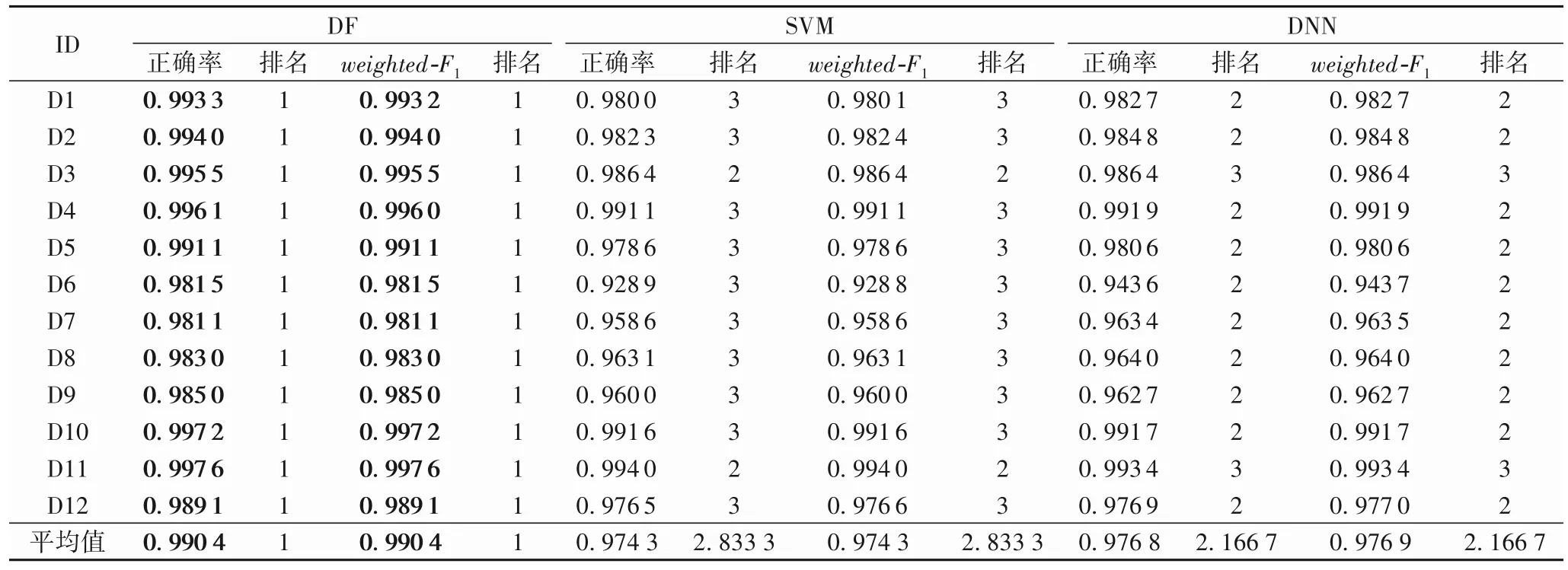
表2 DF、SVM和DNN的实验预测正确率和weighted-F1比较Tab.2 Comparison of DF,SVM and DNN in terms of prediction accuracy and weighted-F1
原假设H03 种算法在热舒适度等级预测上性能无差异。
备择假设H13 种算法在热舒适度等级预测上性能有差异。
Friedman统计量为:
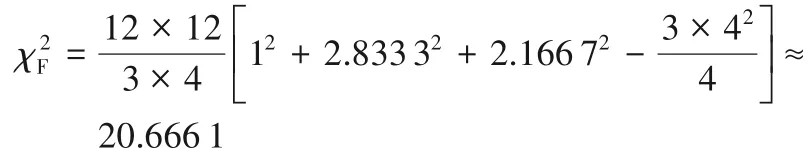
则Iman-Davenport为:

本次实验3 个算法,12 个数据集,服从于自由度为3-1=2和(12 -1)×(3-1)=22的F 分布。由F(2,22)分布计算的p值为3.716 3× 10-10,所以在高显著性水平下拒绝原假设,即DF 算法性能优于其他对比算法。综合图4 的结果可知,从预测性能方面来看,DF算法均优于DNN算法和SVM算法。
6 结语
随着人们生活品质的不断提高,城市室内热舒适度,尤其是具有大量客流聚集的高铁车站内的热舒适度越来越受到人们的重视。由于高铁车站是城市网络的重要节点,其热舒适度可以通过城市计算技术进行研究。
本文提出了影响高铁站室内热舒适度的8 个因素——室外干球温度、室内客流密度、室内温度、室内湿度、室内二氧化碳浓度、多联机开行台数、多联机设置温度、热交换机开行台数。以成都某高铁站为研究对象,通过综合实地调查与Energy Plus 软件仿真采集大量数据,提出了一种基于DF 的室内热舒适度等级预测模型,其本质是一个基于PPD 值的热舒适度三分类问题。为了验证深度森林的有效性,本文还选用DNN模型和SVM模型进行对比。结果表明,在12个数据集中DF 模型的weighted-F1值和预测正确率均优于SVM 和DNN 模型,验证了DF 模型在高铁站室内热舒适度等级预测的有效性。
猜你喜欢
热带农业科学(2022年4期)2022-05-18
医学食疗与健康(2022年3期)2022-04-23
建材发展导向(2022年3期)2022-04-19
能源研究与利用(2022年1期)2022-03-02
健康体检与管理(2021年6期)2021-11-17
中华养生保健(2021年18期)2021-02-13
机电信息(2020年16期)2020-08-31
机电信息(2020年1期)2020-07-04
汽车零部件(2020年1期)2020-03-06
山东工业技术(2019年6期)2019-03-27
